クラウドネイティブの概念は本格化していますが、実際に大規模な着陸を実装している企業はまだほんの一握りです。中国での初期のトライアルカンパニーとしてのAntは、2年以上の調査の結果、一連の実用的なソリューションが寄託され、最終的に合格しました。ダブルイレブンのテスト。
1.なぜサービスメッシュが必要なのですか?

なぜサービスメッシュが必要なのですか。ビジネスにとっての価値はどこにありますか。3つのポイントを要約しました。
1.マイクロサービスガバナンスとビジネスロジックを分離します。
2.異種システムの統一されたガバナンス。
3.財務レベルのネットワークセキュリティ。
以下に別途説明します。
1.マイクロサービスガバナンスとビジネスロジックの分離
Service Meshの前は、ミドルウェアチームが従来のマイクロサービスシステムを使用して、ビジネスアプリケーション用のSDKを提供していました。SDKでは、サービスディスカバリ、負荷分散、電流制限、サービスルーティングなどのさまざまなサービスガバナンス機能が使用されていました。
実行時に、SDKとビジネスアプリケーションコードは実際には同じプロセスで混合されて実行され、結合が非常に高いため、一連の問題が発生します。
-
アップグレードコストが高い。アップグレードするたびに、ビジネスアプリケーションでSDKのバージョン番号を変更して再リリースする必要があります。Antを例にとると、過去には、ミドルウェアのバージョンのアップグレードに毎年数千人の時間を費やしていました。
-
深刻なバージョンの断片化。アップグレードのコストが高いため、ミドルウェアは前進し続けます。時間の経過とともに、オンラインSDKのバージョンと機能に一貫性がなくなり、均一に管理することが困難になります。
-
ミドルウェアの進化は困難です。深刻なバージョンの断片化のため、ミドルウェアは、「ヨーク」で前進するようなものであり、迅速な反復を達成できないフォワードエボリューションプロセス中に、コード内のさまざまな古いバージョンのロジックと互換性がある必要があります。
Service Meshを使用すると、SDKのほとんどの機能をアプリケーションから取り除き、独立したプロセスに分解して、サイドカーモードで実行できます。サービスガバナンス機能をインフラストラクチャにシンクすることで、企業はビジネスロジックにさらに集中でき、ミドルウェアチームは、さまざまな一般的な機能、真に独立した進化、透過的なアップグレード、および全体的な効率の構築に集中できます。

2.異種システムの統合ガバナンス
新しいテクノロジーの開発に伴い、さまざまな言語とさまざまなフレームワークのアプリケーションとサービスが同じ会社に登場することがよくあります。Antを例にとると、社内ビジネスも開花しています。フロントエンド、検索推奨、人工知能、セキュリティなど、さまざまなビジネスがあります。使用するテクノロジースタックも非常に多様です。Javaに加えて、NodeJSもあります。 、Golang、Python、C ++など。これらのサービスを統一された方法で管理および制御できるようにするには、言語およびフレームワークごとに完全なSDKを再開発する必要があります。メンテナンスコストが非常に高く、また、人事構造に大きな課題をもたらします。

Service Meshを使用すると、本体のサービスガバナンス機能をインフラストラクチャに組み込むことで、多言語サポートがはるかに簡単になります。非常に軽量なSDKを提供するだけでよく、多くの場合、個別のSDKは必要ありません。多言語、マルチプロトコルの統合フロー制御、監視、およびその他のガバナンス要件を簡単に実装できます。
3.金融グレードのサイバーセキュリティ
現在、多くの企業のマイクロサービスシステムの構築は「イントラネットの信頼性」の仮定に基づいていますが、この仮定は、現在の大規模なクラウド移行のコンテキストでは、特にいくつかの財務シナリオを伴う場合、適切でない可能性があります。
サービスメッシュを使用すると、アプリケーションの識別とアクセス制御をより簡単に実装できます。データ暗号化の助けを借りて、完全なリンクの信頼性を実現できるため、サービスを信頼性のないネットワークで実行し、全体的なセキュリティレベルを向上させることができます。

2.Antサービスメッシュの大規模な実装

サービスメッシュが上記のメリットをもたらしたからこそ、2018年の初めから技術調査と小規模着陸パイロットを開始しました。しかし、ビジネスチームとの最初の昇進では、魂の拷問に直面しました。
1.企業はコードを変更する必要がありますか?ビジネスチームは日常的に非常に大きなビジネスプレッシャーに直面しており、技術的な変革のためのエネルギーがあまりありません。
2.アップグレードプロセスは私のビジネスに影響を与えるべきではありません。会社の事業に関しては、安定性を最優先する必要があり、新しい構造が事業に影響を与えることはありません。
3.あなたが望む他のもの。つまり、変換コストが十分に低く、安定性が十分に良好であることが保証できる限り、ビジネスチームは引き続きサービスメッシュを実装するために協力してくれます。

これは、有名な製品価値の公式を思い出させます。

この式から:
「新しい経験-古い経験」は、前述のサービスメッシュによってもたらされるさまざまな利点であり、価値のこの部分を最大化する必要があります
「移行コスト」とは、新しいサービスメッシュアーキテクチャに移行する過程でのビジネスのさまざまなコストを指します。コストのこの部分は、主に以下を含めて最小限に抑える必要があります。
-
アクセスコスト:既存のシステムはどのようにサービスメッシュにアクセスしますか?ビジネストランスフォーメーションはありますか?
-
スムーズな移行:多くのビジネスシステムはすでに実稼働環境で実行されていますが、サービスメッシュアーキテクチャにスムーズに移行できますか?
-
安定性:サービスメッシュはまったく新しいアーキテクチャシステムです。ビジネス移行後の安定性を確保するにはどうすればよいですか?
次に、アリがどのようにそれを行うかを見てみましょう。
アクセスコスト
AntのサービスはSOFAフレームワークを均一に使用するため、ビジネスのアクセスコストを最小限に抑えるために、SOFA SDKのロジックを変更して、動作モードを自動的に識別します。動作環境でサービスメッシュが有効になっていることが判明した場合、自動的にサイドカードドッキングします。サービスメッシュが有効になっていない場合は、非サービスメッシュモードで動作し続けます。ビジネス側の場合、ビジネスコードを変更せずにアクセスを完了するには、SDKを1回アップグレードするだけで済みます。
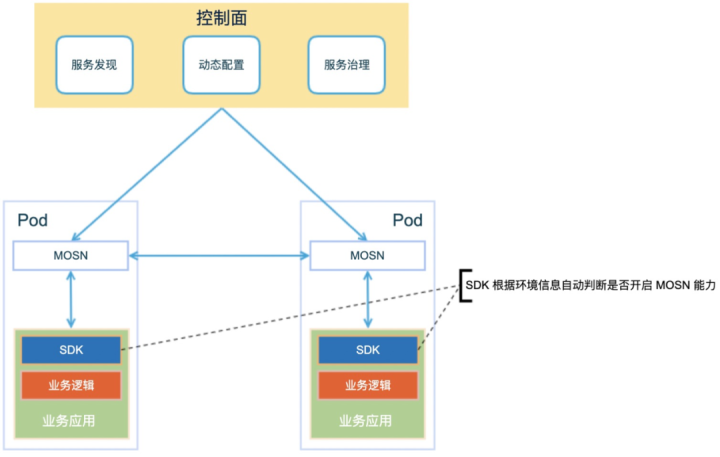
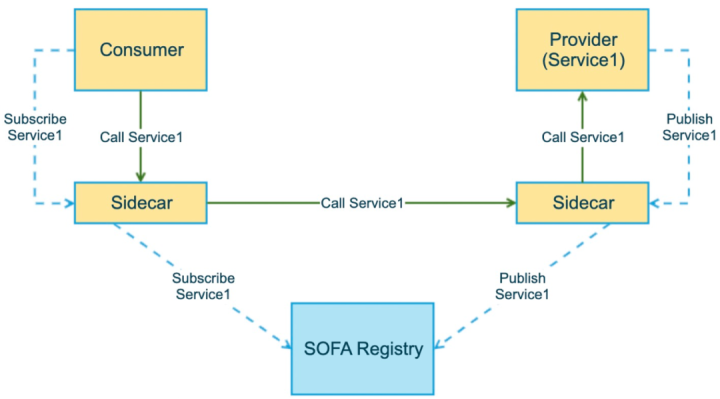
SDKがSidecarとどのように接続するかを見てみましょう。最初に、サービス検出のプロセスを見てみましょう。
1.サーバーがマシン1.2.3.4で実行され、ポート20880でリッスンしていると仮定すると、サーバーは最初にサイドカーへのサービス登録要求を開始し、登録する必要のあるサービスとIP +ポートをサイドカーに通知します。 (1.2.3.4:20880)
2.サーバー側のサイドカーは、登録センターへのサービス登録要求を開始し、サービスとIP +ポートを通知します。ただし、登録はビジネスアプリケーションのポートではないことに注意してください(20880 )、ただしサイドカー自体のポートによって監視されているもの(例:20881)
3.発信者は、サイドカーへのサービスサブスクリプション要求を開始して、サブスクライブする必要のあるサービス情報を通知します
4.呼び出し側のサイドカーがサービスアドレスを呼び出し側にプッシュします。プッシュされたIPはローカルマシンであり、ポートは呼び出し側のサイドカーによって監視されるポートであることに注意してください(例:20882)。
5.呼び出し側のサイドカーは、登録センターへのサービスサブスクリプション要求を開始して、サブスクライブする必要のあるサービス情報を通知します。
6.登録センターは、サービスアドレスを発信者のサイドカーにプッシュします(1.2.3.4:20881)

サービス通信プロセスを見てみましょう。
1.呼び出し元が取得した「サーバー」アドレスは127.0.0.1:20882であるため、このアドレスに対してサービス呼び出しが開始されます。
2.要求を受信した後、呼び出し側のサイドカーは、要求ヘッダーを解析することによって呼び出される特定のサービス情報を知ることができ、サービスレジストリから返されたアドレスを取得した後、実際の呼び出しを開始できます(1.2。 3.4:20881)
3.サーバーのサイドカーはリクエストを受信した後、一連の処理(127.0.0.1:20880)の後、最終的にサーバーにリクエストを送信します。

上記のプロセスにより、SDKとSidecarのドッキングが完了します。一部の人々は、なぜiptablesソリューションを採用しないのかと尋ねるかもしれません。主な理由は、一方で、ルール構成が多いとiptablesのパフォーマンスが大幅に低下することです。もう1つの重要な側面は、制御と可観測性が低く、問題のトラブルシューティングが難しいことです。
スムーズな移行
Antの本番環境は、複雑なアップストリームとダウンストリームの依存関係を持つ多くのビジネスシステムを実行します。一部は非常にコアなアプリケーションです。わずかなジッターにより障害が発生します。したがって、Service Meshのような大規模なアーキテクチャ変換では、スムーズな移行が必須のオプションですが、グレースケールとロールバックをサポートします。
アーキテクチャシステムに保持されている登録センターのおかげで、スムーズな移行ソリューションは比較的シンプルで簡単です。
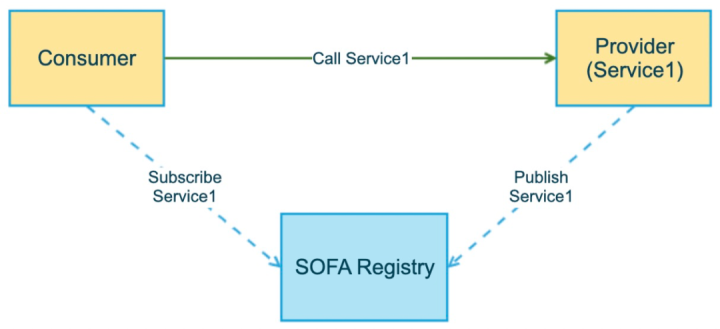
1.初期状態
次の図は例です。最初は、サービスプロバイダーとサービス呼び出し元があります。
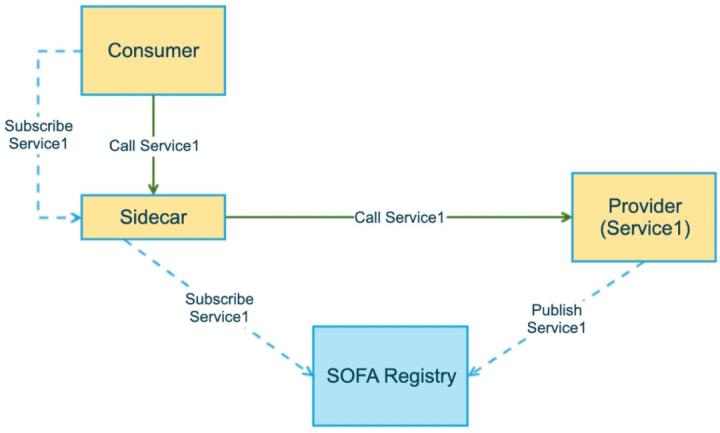
2.発信者を透過的に移行します
このソリューションでは、発信者またはサービスパーティを最初に移行する必要はありません。発信者でサイドカーインジェクションが有効になっている限り、発信者は最初にサービスメッシュに移行することを想定しています。SDKは自動的に移行します。現在のサービスメッシュを認識するサービスメッシュが有効になっている場合、SidecarはサブスクライブしてSidecarと通信し、Sidecarはサービスをサブスクライブして実際のサービスパーティと通信しますが、サービスパーティは発信者が移行したかどうかを完全に認識しません。したがって、発信者はサイドカーをグレースケールで1つずつオンにし、問題が発生した場合はロールバックすることができます。
3.透過的な移行サービスプロバイダー
サーバーが最初にServiceMeshに移行することを想定し、サーバーでサイドカーインジェクションがオンになっている限り、SDKはService Meshが現在有効になっていることを自動的に認識し、Sidecar、Sidecarの順に登録して通信します。サービスプロバイダーがレジストリに登録しても、呼び出し元は引き続きレジストリからサービスにサブスクライブし、サービスプロバイダーが移行したかどうかを完全に認識しません。したがって、サービスパーティは、サイドカーを1つずつグレースケールでオンにし、問題が発生した場合はロールバックすることができます。

4.最終状態
最後に、最終状態に到達し、次の図に示すように、呼び出し元とサーバーの両方がサービスメッシュにスムーズに移行します。
安定
サービスメッシュアーキテクチャの導入により、最初はアプリケーションとインフラストラクチャの分離を実現し、インフラストラクチャの反復速度を大幅に高速化しましたが、これは安定性にとってどのような意味がありますか?
SDKモードでは、ミドルウェアのクラスメートがSDKをリリースした後、ビジネスアプリケーションが徐々にアップグレードされ、開発、テスト、プレリリース、グレースケール、本番環境などの環境と完全な機能検証に従って徐々に昇格されます。実際、ミドルウェア製品のテストを手伝っているビジネス学生が多く、徐々に小規模にアップグレードしているため、リスクは非常に小さいです。
ただし、サービスメッシュアーキテクチャでは、ビジネスアプリケーションとインフラストラクチャが分離されているため、反復速度が大幅に向上しますが、安定性を確保するために以前のモデルを使用できなくなることも意味します。R&Dフェーズでそれを確保する必要があるだけではありません。オンラインでの変更時には、製品の品質も管理する必要があります。
アリのクラスターの規模を考えると、オンラインでの変更には数十万のコンテナーが関係することがよくあります。このような大規模なアップグレードの安定性を確保するにはどうすればよいでしょうか。私たちが提供する解決策は、無人の変更です。
無人運転を理解する前に、無人運転を見てみましょう。次の図は、L0からL5までの無人運転の成熟度を定義しています。L0は現在のほとんどの運転モードに対応しています。車自体には自動化機能がなく、ドライバーが完全に制御する必要がありますが、L5は最高レベルであり、真の無人運転を実現できます。私たちが知っているテスラのように、その自動運転はL2とL3の間にあり、特定のシナリオで自動運転する機能があります。
次の図に示すように、このシステムを参照して、無人変更のレベルを定義します。
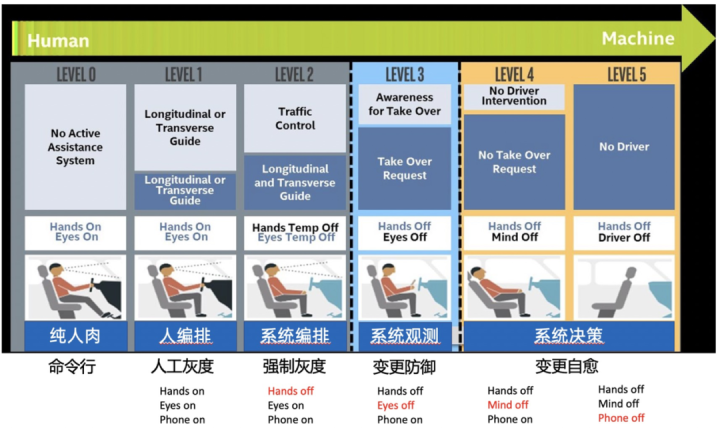
L0:純粋な人間の肉体の変化、黒い画面の操作、ツールの支援なし
L1:いくつかのツールがありますが、それらは体系的に接続されていません。人工的なグレースケールを確保するために、変更を完了するにはさまざまなツールを配置する必要があります。
L2:予備自動化機能により、システムは変更プロセス全体を単独で調整でき、グレースケールを強制する機能を備えています。したがって、L1レベルと比較して、人間の手は自由であり、1回の変更で1つの作業指示のみが必要です。
L3:システムは監視機能を備えています。変更プロセス中に異常が見つかった場合は、ユーザーに通知され、変更がブロックされます。したがって、L2レベルと比較して、人間の目も解放されます。変更プロセスを常に監視する必要がありますが、電話をかける必要があります。問題が発生したら、時間内にオンラインにする必要があります。
L4:さらに一歩進んで、システムには意思決定能力があります。変更に問題があることが判明した場合、システムは自動的に処理して自己回復を実現できるため、L3レベルと比較して人間の脳も解放されます。 、深夜に変更が可能です。問題が発生した場合は、事前に設定された計画に従ってシステムが自動的に処理します。解決できない場合は、担当者に連絡してください。処理のためにオンライン。
L5:それは究極の状態です。変更を送信した後、人々は去ることができ、システムは自動的に実行され、問題がないことを確認します
現在、私たちの自己評価はL3レベルを達成しており、これは主に次のことに反映されています。
1.システムは、必須のグレースケールを達成するためにバッチ戦略を自動的に調整します
2.変更防御を導入し、事前チェックと事後チェックを追加し、問題が発生したときに時間の変更をブロックできる
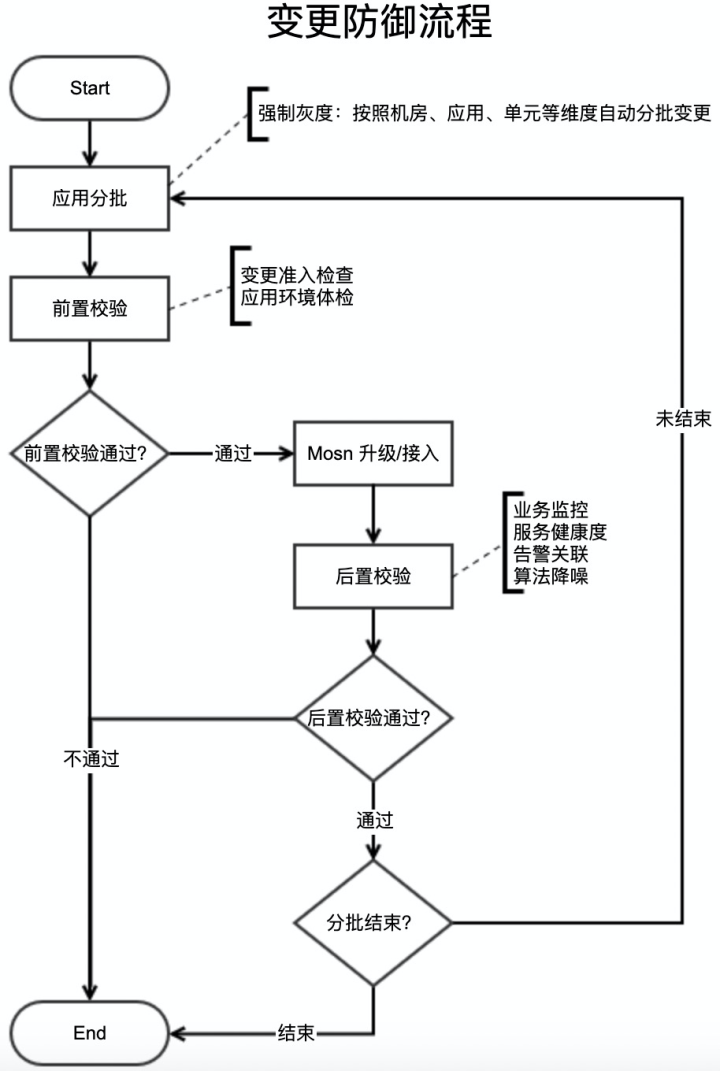
変更防御プロセスを次の図に示します。
-
変更要求を送信した後、システムは変更をバッチに分割し、コンピュータールーム、アプリケーション、およびユニットの寸法に従ってバッチ変更を開きます。
-
各バッチ変更を開始する前に、現在の時刻がビジネスのピーク期間であるかどうか、障害期間であるかどうかのチェック、システム容量のチェックなどの事前チェックが最初に実行されます。
-
事前チェックに合格しなかった場合、変更は終了し、変更した学生に通知されます。合格した場合、Mosnのアップグレードまたはアクセスプロセスが開始されます。
-
変更完了後、トランザクションや支払いの成功率が低下したかどうかなどのビジネス監視や、RT、エラー率、アップストリームおよびダウンストリームシステムなどのサービスの状態などの事後検証が実行されます。 。、変更中などに不具合がないか確認するためのアラームにも関連付けられます。
-
事後チェックに合格しなかった場合、変更は終了し、変更した学生に通知されます。合格した場合、次の変更のバッチが開始されます。
全体構造
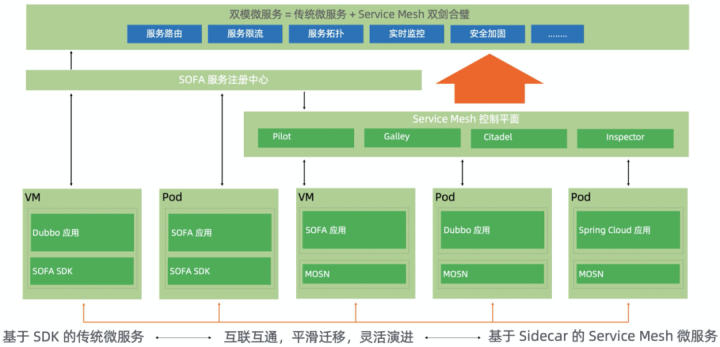
Ant SOFAMeshの全体的なアーキテクチャを見てみましょう。ここでの「デュアルモードマイクロサービス」とは、従来のSDKベースのマイクロサービスとサービスメッシュマイクロサービスの組み合わせを指します。
-
相互運用性:2つのシステムのアプリケーションは相互にアクセスできます
-
スムーズな移行:アプリケーションは2つのシステム間でスムーズに移行でき、アップストリームとダウンストリームの依存関係に対して透過的で認識できない場合があります
-
柔軟な進化:相互接続とスムーズな移行が実現した後、実際の状況に応じて柔軟なアプリケーションの変換とアーキテクチャの進化を実行できます
コントロールサーフェスでは、構成の配布(サービスルーティングルールなど)を実装するためにPilotを導入し、スムーズな移行と大規模な着陸を実現するために、サービス検出用の独立したレジストリを保持しました。
データ側では、SOFAアプリケーションだけでなく、DubboおよびSpringCloudアプリケーションもサポートする自社開発のMosnを使用しています。
デプロイモードに関しては、コンテナー/ k8だけでなく、仮想マシンのシナリオもサポートします。
着陸規模と事業価値
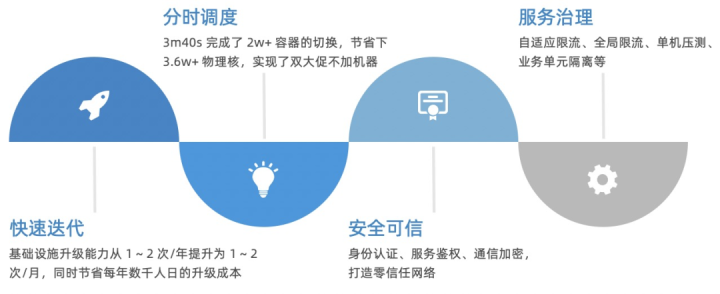
現在、Service Meshは数千のAntアプリケーションをカバーし、コアリンクを完全にカバーしています。本番環境には数十万のポッドがあります。DoubleElevenで処理されるQPSは数千万に達し、平均処理応答時間は0.2ミリ秒未満でした。良好な技術的結果が達成されました。

ビジネス価値の面では、サービスメッシュアーキテクチャを通じて、インフラストラクチャとビジネスアプリケーションの分離を最初に実現し、インフラストラクチャのアップグレード機能は、年に1〜2回から月に1〜2回に増加しましたが、反復速度を大幅に加速するだけであると同時に、ステーション全体の数千人日のアップグレードコストを毎年節約します。Mosnのトラフィック割り当ての助けを借りて、時分割スケジューリングシナリオが実現されます。所要時間はわずか3分40秒です。 2w +コンテナの切り替えを完了し、3.6w +物理コアを節約し、マシンを追加せずにダブルプロモーションを実現します。セキュリティと信頼性の観点から、ID認証、サービス認証、通信暗号化を実現し、サービスをゼロで実行できるようにします。全体的なセキュリティレベルを向上させる信頼ネットワーク。サービスガバナンスの観点から、迅速にオンラインになります。適応型電流制限、グローバル電流制限、スタンドアロンストレステスト、ビジネスユニットの分離などの機能により、洗練されたサービスガバナンスのレベルが大幅に向上しました。そしてビジネスに大きな価値をもたらしました。
3.将来を見据えて

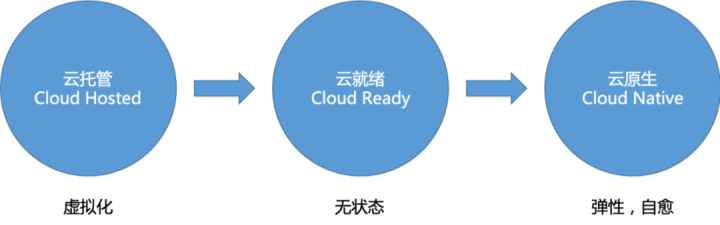
現在、業界全体がCloudHostedからCloudReady、CloudNativeまでのプロセスを経ていることがすでにはっきりとわかります。
しかし、ここで強調したいのは、私たちは技術のための技術ではないということです。技術の開発は本質的に事業開発のためです。同じことがクラウドネイティブにも当てはまります。これは基本的に効率を改善し、コストを削減することです。したがって、クラウドネイティブはそれ自体が目的ではなく、手段です。
Service Meshの大規模な実装を通じて、クラウドネイティブに向けた確固たる一歩を踏み出し、実現可能性を検証しました。同時に、インフラストラクチャの沈下後、ビジネスチームとインフラストラクチャチームの両方がR&Dと運用をもたらしました。メンテナンス効率の向上。
現在、Mosnは主にRPCとMQの機能を提供していますが、SDKとしてビジネスシステムに組み込まれているインフラストラクチャロジックはまだたくさんあります。インフラストラクチャとビジネスを切り離すにはまだ長い道のりがあるため、サービスメッシュからメッシュへの進化を実現するための将来のSinkinto Mosn(トランザクション、キャッシュ、構成、タスクスケジューリングなど)。ビジネスアプリケーションの場合、将来的には、標準化されたインターフェイスを介してMosnと対話し、さまざまな重いSDKを導入する必要がないため、Mosnは単純なトラフィックプロキシから次世代のミドルウェアランタイムに進化します。
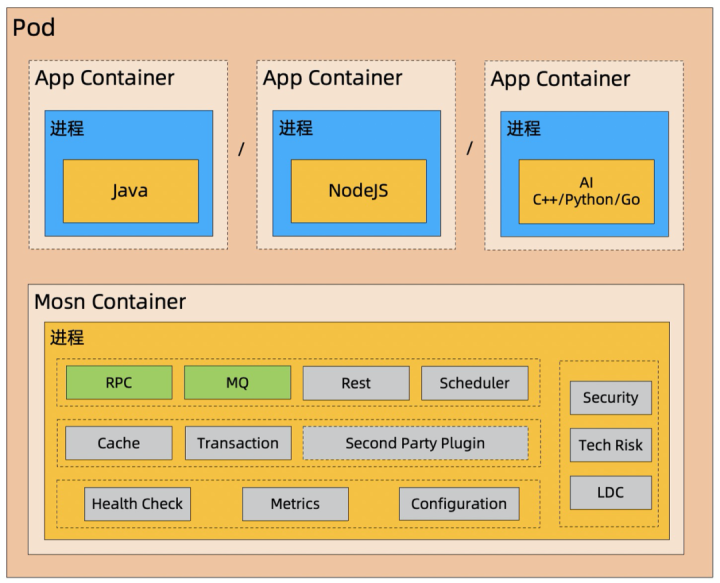
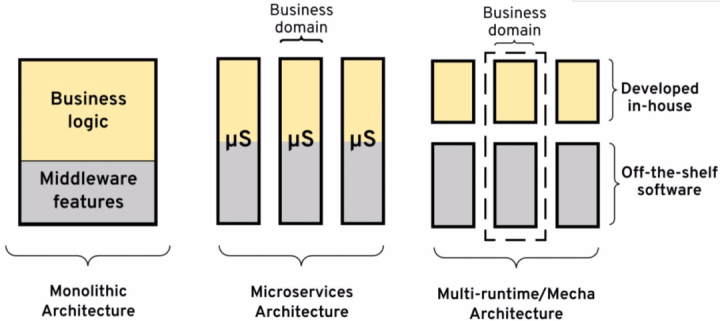
このようにして、ビジネスアプリケーションとインフラストラクチャ間の結合をさらに減らすことができ、ビジネスアプリケーションをより軽量にすることができます。図に示すように、初期のモノリシックアプリケーションからマイクロサービスへの進化により、ビジネスチーム間の分離は実現しましたが、ビジネスチームとインフラストラクチャチーム間の結合は分離されていません。将来の方向性は、図に示すように3番目の方向です。 、ビジネスアプリケーションが純粋なビジネスロジック(Micrologic)の方向に移動し、すべての非ビジネスロジックをSidecarにシンクして、ビジネスとインフラストラクチャの独立した進化を真に実現し、全体的な効率を向上させることを期待しています。
もう1つの傾向はサーバーレスです。これは現在、アプリケーションのサイズや起動速度などの要因によって制限されています。サーバーレスの主なアプリケーションシナリオは、まだ機能上にあります。
ただし、サーバーレスは機能シナリオに限定されないことを常に信じています。その柔軟性、無料の運用と保守、およびオンデマンドの使用は、通常のビジネスアプリケーションにとって明らかに大きな価値があります。
したがって、ビジネスアプリケーションがMicrologic + Sidecarに進化すると、一方ではビジネスアプリケーション自体の量が少なくなり、起動速度が速くなります。他方では、インフラストラクチャをより最適化することもできます(通常のビジネスアプリケーションもサーバーレスシステムに統合できるように、データベースを事前に準備し、データをキャッシュするなど)、サーバーレスによってもたらされる効率とコストのメリットを真に享受できます。