1.原則
バイナリ検索(バイナリ検索とも呼ばれます)は、比較の数が少ないという利点、高速な検索速度、平均的なパフォーマンスです。欠点は、順序付けられたルックアップテーブルが必要であり、挿入の削除が難しいことです。したがって、二分探索法は、頻繁に変更されない頻繁に順序付けられたリストを検索するのに適しています。まず、テーブル内の要素が昇順で配置されているとします。テーブルの中央の位置にあるキーを検索キーと比較します。2つが等しい場合は検索が成功します。それ以外の場合は、中央の位置のレコードを使用してテーブルを2つのサブテーブルに分割します。中央の位置のレコードのキーが検索キーより大きい場合は、前のサブテーブルがさらに検索されます。それ以外の場合は、後者のサブテーブルがさらに検索されます。条件を満たすレコードが見つかり、検索が成功するまで、またはサブテーブルが存在しなくなるまで、この時点で検索が失敗するまで、上記のプロセスを繰り返します。
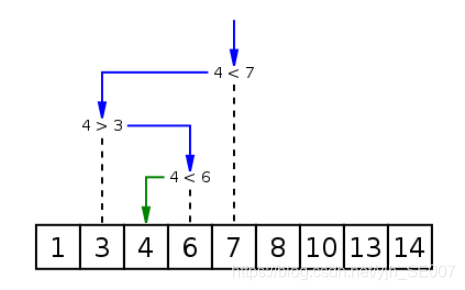
2.適用条件
二分探索は条件付きです。最初に順序付けられます。次に、二分探索操作が添え字であるため、要件は順序です。
最適な時間計算量:O(1)
最悪の時間計算量:O(logn)
コード
"""
1. 二分查找是有条件的,首先是有序,其次因为二分查找操作的是下标,所以要求是顺序表
2. 最优时间复杂度:O(1)
3. 最坏时间复杂度:O(logn)
"""
# def binary_chop(alist, data):
# """
# 递归解决二分查找
# :param alist:
# :return:
# """
# n = len(alist)
# if n < 1:
# return False
# mid = n // 2
# if alist[mid] > data:
# return binary_chop(alist[0:mid], data)
# elif alist[mid] < data:
# return binary_chop(alist[mid+1:], data)
# else:
# return True
def binary_chop(alist, data):
"""
非递归解决二分查找
:param alist:
:return:
"""
n = len(alist)
first = 0
last = n - 1
while first <= last:
mid = (last + first) // 2
if alist[mid] > data:
last = mid - 1
elif alist[mid] < data:
first = mid + 1
else:
return True
return False
if __name__ == '__main__':
lis = [2,4, 5, 12, 14, 23]
if binary_chop(lis, 14):
print('查找成功!')