記事のディレクトリ
1はじめに
コンテンツ
- 正規表現自体には多くのコンテンツが含まれています。実験のこのセクションでは、grep、sed、awkの3つのコマンドのみを紹介します。
知識のポイント
- 基本的なコマンドをマスターする:sed、grep、awkの使用法
- 正規表現の記号と文法をマスターする
2つの正規表現
正規表現とは何ですか?
正規表現、正規表現、正規表現、正規表現、正規表現、正規表現(英語:正規表現、コードではregex、regexp、またはREと略されることが多い)、コンピューターサイエンスの概念。正規表現は、単一の文字列を使用して、特定の構文規則に準拠する一連の文字列を記述および照合します。多くのテキストエディタでは、通常、正規表現を使用して、特定のパターンを満たすテキストを取得および置換します。
簡単に言えば、形式と機能の正規表現は前述のワイルドカードと非常に似ていますが、特にいくつかの特別に一致する文字の意味において、それらの間には大きな違いがあります。
2.1例
同じ式の2つの文字列「shiyanlou」と「shilouyan」を含むテキストファイルがあるとします。
shi*
これを正規表現として使用すると、shiのみに一致し、*をワイルドカードとして使用すると、両方の文字列に一致します。どうしてこれなの?正規表現では、*は前の部分式(ここではその前の文字)に0回以上一致することを意味するため、たとえば、「sh」、「shii」、「shish」、「shiishi」などに一致する可能性があります。 。、ワイルドカードとしては、ワイルドカードの後の任意の数の文字に一致することを意味するため、「shiyanlou」と「shilouyan」の2文字に一致させることができます。
体験が終わったら、正規表現を正式に学びましょう。
2.2基本構文
正規表現は通常、パターンと呼ばれ、特定の構文規則に準拠する一連の文字列を記述または照合するために使用されます。
選択
|垂直区切り文字は選択を意味します。たとえば、「男の子|女の子」は「男の子」または「女の子」と一致します。
数量制限
この例で使用されている*に加えて、数量制限には+プラス記号と?疑問符も含まれます。数量修飾子がパターンに追加されていない場合は、次のように1回だけ表示されます。
- +前の文字が少なくとも1回(1回以上)出現する必要があることを意味します。たとえば、「goo + gle」は「gooogle」、「goooogle」などと一致します。
- ?前の文字が最大で1回(0回または1回)表示されることを意味します。たとえば、「colou?r」は「color」または「color」と一致します。
- *アスタリスクは、前の文字が表示されないか、1回以上表示される可能性があることを示します(0回、1回、または複数回)。たとえば、「0 * 42」は42、042、0042、00042と一致します。 、など。
範囲と優先度
()括弧を使用して、パターン文字列の範囲と優先度を定義できます。これは、括弧内のパターン文字列が全体として使用されるかどうかとして簡単に理解できます。たとえば、「gr(a | e)y」は「gray | grey」と同等です(優先順位はここに反映され、垂直区切り記号はaまたはeを選択するために使用されます)、「(grand)?father」はfatherに一致し、祖父(ここでは、の範囲を反映?カッコ内全体の一致などのコンテンツを)。
文法的(部分的)
正規表現にはさまざまなスタイルがあります。perlおよびpythonプログラミング言語とPCREのサブセットであるgrepまたはegrepで一般的に使用される正規表現マッチングルールを次に示します。
PCRE(Perl互換正規表現中国語の意味:Perl言語互換正規表現)は、PhilipHazelによって作成されたC言語で記述された正規表現ライブラリです。PCREは軽量のライブラリであり、Boostなどの正規表現ライブラリよりもはるかに小さいです。PCREは非常に使いやすいだけでなく、非常に強力です。そのパフォーマンスは、POSIX正規表現ライブラリおよび一部の従来の正規表現ライブラリを上回っています。
| キャラクター | 説明 |
|---|---|
| \ | 次の文字を特殊文字またはリテラル文字としてマークします。たとえば、「n」は文字「n」と一致します。「\ N」は改行文字と一致します。シーケンス「\\」は「\」に一致し、「\(」は「(」に一致します。 |
| ^ | 入力文字列の先頭に一致します。 |
| $ | 入力文字列の終了位置と一致します。 |
| {n} | nは負でない整数です。特定のn回一致します。たとえば、「o {2}」は「Bob」の「o」と一致することはできませんが、「food」の2つのoと一致することはできます。 |
| {n、} | nは負でない整数です。少なくともn回一致します。たとえば、「o {2、}」は「Bob」の「o」と一致することはできませんが、「foooood」のすべてのoと一致することはできます。「O {1、}」は「o +」と同等です。「O {0、}」は「o *」と同等です。 |
| {n、m} | mとnはどちらも非負の整数であり、n <= mです。少なくともn回一致し、最大m回一致します。たとえば、「o {1,3}」は、「fooooood」の最初の3つのoと一致します。「O {0,1}」は「o?」と同等です。カンマと2つの数字の間にスペースを入れることはできないことに注意してください。 |
| * | 前の部分式に0回以上一致します。たとえば、zo *は「z」、「zo」、「zoo」と一致します。* {0、}と同等です。 |
| + | 前の部分式に1回以上一致します。たとえば、「zo +」は「zo」と「zoo」に一致できますが、「z」には一致しません。+ {1、}に相当します。 |
| ? | 前の部分式に0回または1回一致します。たとえば、「do(es)?」は「does」の「do」または「do」と一致します。?{0,1}と同等です。 |
| ? | 文字が他の修飾子(*、+、?、{n}、{n、}、{n、m})の直後に続く場合、マッチングモードは貪欲ではありません。非欲張りモードは検索された文字列にできるだけ一致しませんが、デフォルトの欲張りモードは検索された文字列にできるだけ一致します。たとえば、文字列「oooo」の場合、「o +?」は単一の「o」に一致し、「o +」はすべての「o」に一致します。 |
| 。 | 「\ n」以外の任意の1文字に一致します。「\ n」を含む任意の文字に一致させるには、「(。{2} \ n)」のようなパターンを使用します。 |
| (パターン) | パターンを一致させ、一致した部分文字列を取得します。この部分文字列は、後方参照に使用されます。括弧文字を一致させるには、右括弧と同じ「\(」を使用します。 |
| x {2} y | xまたはyに一致します。たとえば、「z❤food」は「z」または「food」と一致します。「(Z ++ f)ood」は「zood」または「food」と一致します。 |
| [xyz] | キャラクタークラス(キャラクタークラス)。含まれている文字のいずれかに一致します。たとえば、「[abc]」は「plain」の「a」と一致させることができます。特殊文字の中で、バックスラッシュ\のみが特別な意味を維持し、文字をエスケープするために使用されます。アスタリスク、プラス記号、さまざまな角かっこなどの他の特殊文字は、通常の文字と見なされます。キャレット^が最初の位置にある場合は、負の文字のセットを意味します。文字列の中央にある場合は、通常の文字としてのみ見なされます。ハイフン-文字列の中央に表示される場合は、文字範囲の説明を意味します。最初の位置に表示される場合は、通常の文字のみです。 |
| [^ xyz] | 負の文字セット。リストされていない任意の文字に一致します。たとえば、「[^ abc]」は「plain」の「plin」と一致します。 |
| [az] | 文字範囲。指定された範囲内の任意の文字に一致します。たとえば、「[az]」は「a」から「z」までの任意の小文字の英字に一致します。 |
| [^ az] | 除外される文字範囲。指定された範囲内にない任意の文字に一致します。たとえば、「[^ az]」は、「a」から「z」の範囲外の任意の文字に一致できます。 |
優先
度優先度は上から下、左から右で、次の順序で減少します。
| オペレーター | 説明 |
|---|---|
| \ | エスケープ |
| ()、(?:)、(?=)、[] | 角かっこと角かっこ |
| *、+、?、{n}、{n、}、{n、m} | 修飾子 |
| ^、$、\任意のメタ文字 | アンカーポイントとシーケンス |
| !! | 選択する |
3grepパターンマッチングコマンド
正規表現についてはたくさん話しましたが、使い方については触れませんでした。これは本当に退屈です。
3.1基本操作
grepコマンドは、一致したパターン文字列を出力テキストに出力するために使用されます。パターンマッチングの条件として正規表現を使用します。grepは、次の3つのパラメーターで指定される3つの正規表現エンジンをサポートします。
| パラメータ | 説明 |
|---|---|
| -E | POSIX拡張正規表現、ERE |
| -G | POSIX基本正規表現、BRE |
| -P | Perl正規表現、PCRE |
以下ではEREとBREのみが使用されます
grepコマンドで正規表現を使用する前に、その一般的なパラメーターを紹介しましょう。
| パラメータ | 説明 |
|---|---|
| -b | バイナリファイルをテキストとして照合する |
| -c | パターン一致の数を数える |
| -私 | ケースを無視する |
| -n | 一致したテキストが配置されている行の行番号を表示します |
| -v | 選択を反転し、一致しない行の内容を出力します |
| -r | 再帰的マッチング検索 |
| -A n | nは正の整数です。つまり、一致する行をリストするだけでなく、次のn行もリストします。 |
| -B n | nは正の整数です。つまり、一致する行を一覧表示するだけでなく、前のn行も一覧表示します。 |
| –color = auto | 出力の一致を自動カラー表示に設定します |
注:ほとんどのディストリビューションでは、grepの色はデフォルトで設定されています。パラメーターを使用して、GREP_COLOR環境変数を指定または変更できます。
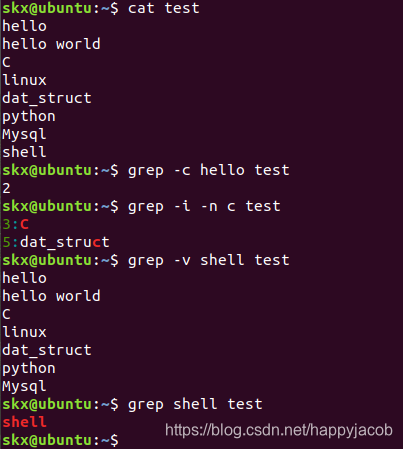
3.2正規表現を使用する
(1)基本的な正規表現BREを使用する
- 場所/ etc / groupファイルで「skx」で始まる行
を見つけます
# 包含skx的行
$ grep 'skx' /etc/group
# 以skx开始的行
$ grep '^skx' /etc/group
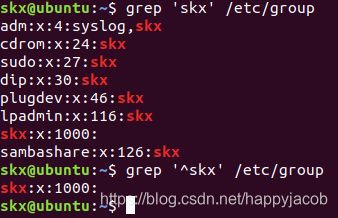
- 量
# 将匹配以'z'开头以'o'结尾的所有字符串
$ grep 'z.*o' test
# 将匹配以'z'开头以'o'结尾,中间包含一个任意字符的字符串
$ grep 'z.o' test
# 将匹配以'z'开头,以任意多个'o'结尾的字符串
$ grep 'zo*' test
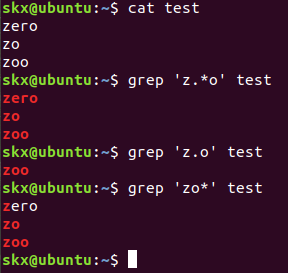
- 選択する
# grep默认是区分大小写的,这里将匹配所有的小写字母
$ cat test | grep '[a-z]'
# 将匹配所有的数字
$ cat test | grep '[0-9]'
# 将匹配所有的数字
$ cat test | grep '[[:digit:]]'
# 将匹配所有的小写字母
$ cat test | grep '[[:lower:]]'
# 将匹配所有的大写字母
$ echo '1234ABCD' | grep '[[:upper:]]'
# 将匹配所有的字母和数字,包括0-9,a-z,A-Z
$ grep '[[:alnum:]]' test
# 将匹配所有的字母
$ grep '[[:alpha:]]' test

以下に、完全な特殊記号と説明を示します。
| 特別なシンボル | 説明 |
|---|---|
| [:すくう] | 代表英文大小写字母及数字,亦即 0-9, A-Z, a-z |
| [:alpha:] | 代表任何英文大小写字母,亦即 A-Z, a-z |
| [:blank:] | 代表空白键与 [Tab] 按键两者 |
| [:cntrl:] | 代表键盘上面的控制按键,亦即包括 CR, LF, Tab, Del… 等等 |
| [:digit:] | 代表数字而已,亦即 0-9 |
| [:graph:] | 除了空白字节 (空白键与 [Tab] 按键) 外的其他所有按键 |
| [:lower:] | 代表小写字母,亦即 a-z |
| [:print:] | 代表任何可以被列印出来的字符 |
| [:punct:] | 代表标点符号 (punctuation symbol),亦即:" ’ ? ! ; : # $… |
| [:upper:] | 代表大写字母,亦即 A-Z |
| [:space:] | 任何会产生空白的字符,包括空白键, [Tab], CR 等等 |
| [:xdigit:] | 代表 16 进位的数字类型,因此包括: 0-9, A-F, a-f 的数字与字节 |
注意:之所以要使用特殊符号,是因为上面的[a-z]不是在所有情况下都管用,这还与主机当前的语系有关,即设置在LANG环境变量的值,zh_CN.UTF-8 的话[a-z],即为所有小写字母,其它语系可能是大小写交替的如,“a A b B…z Z”,[a-z]中就可能包含大写字母。所以在使用[a-z]时请确保当前语系的影响,使用[:lower:]则不会有这个问题。
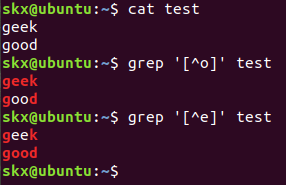
# test 文件中排除字符 'o'
$ grep '[^o]' test
(2)使用扩展正则表达式,ERE
要通过 grep 使用扩展正则表达式需要加上-E 参数,或使用 egrep。
- 数量
# 只匹配"zo"
$ grep -E 'zo{1}' test
# 匹配以"zo"开头的所有单词
$ cat test | grep -E 'zo{1,}'
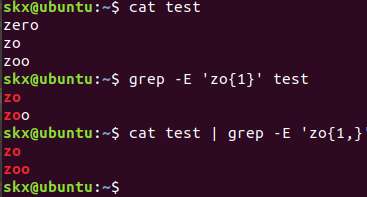
注意:推荐掌握{n,m}即可,+,?,*,这几个不太直观,且容易弄混淆。
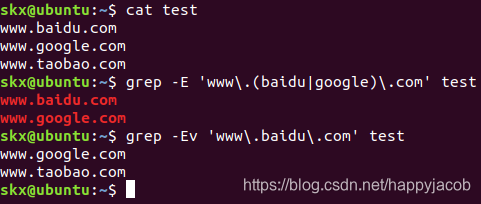
- 选择
注意:因为 . 号有特殊含义,所以需要转义。
# 匹配"www.shiyanlou.com"和"www.google.com"
$ grep -E 'www\.(baidu|google)\.com' test
# 或者匹配不包含"baidu"的内容
$ grep -Ev 'www\.baidu\.com' test
4 sed 流编辑器
sed 工具在 man 手册里面的全名为 "sed - stream editor for filtering and transforming text ",意即,用于过滤和转换文本的流编辑器。
4.1 sed 常用参数介绍
sed 命令基本格式:
sed [参数]... [执行命令] [输入文件]...
# 形如:
$ sed -i 's/sad/happy/' test # 表示将test文件中的"sad"替换为"happy"
| 参数 | 说明 |
|---|---|
| -n | 安静模式,只打印受影响的行,默认打印输入数据的全部内容 |
| -e | 用于在脚本中添加多个执行命令一次执行,在命令行中执行多个命令通常不需要加该参数 |
| -f filename | 指定执行 filename 文件中的命令 |
| -r | 使用扩展正则表达式,默认为标准正则表达式 |
| -i | 将直接修改输入文件内容,而不是打印到标准输出设备 |
4.2 sed 编辑器的执行命令(这里”执行“解释为名词)
sed 执行命令格式:
[n1][,n2]command
[n1][~step]command
# 其中一些命令可以在后面加上作用范围,形如:
$ sed -i 's/sad/happy/g' test # g表示全局范围
$ sed -i 's/sad/happy/4' test # 4表示指定行中的第四个匹配字符串
其中 n1,n2 表示输入内容的行号,它们之间为 , 逗号则表示从 n1 到 n2 行,如果为~波浪号则表示从 n1 开始以 step 为步进的所有行;command 为执行动作,下面为一些常用动作指令:
| 命令 | 说明 |
|---|---|
| s | 行内替换 |
| c | 整行替换 |
| a | 插入到指定行的后面 |
| i | 插入到指定行的前面 |
| p | 打印指定行,通常与-n参数配合使用 |
| d | 删除指定行 |
4.3 sed 操作举例
我们先找一个用于练习的文本文件:
$ cp /etc/passwd ~
打印指定行
# 打印2-5行
$ nl passwd | sed -n '2,5p'
# 打印奇数行
$ nl passwd | sed -n '1~2p'
行内替换
# 将输入文本中"skx" 全局替换为"hehe",并只打印替换的那一行,注意这里不能省略最后的"p"命令
$ sed -n 's/skx/hehe/gp' passwd
删除某行
$ nl passwd | grep "skx"
# 删除第30行
$ sed -i '30d' passwd
5 awk 文本处理语言
看到上面的标题,你可能会感到惊异,难道我们这里要学习的是一门“语言”么,确切的说,我们是要在这里学习 awk 文本处理语言,只是我们并不会在这里学习到比较完整的关于 awk 的内容,因为它太强大了,下面就进行关于 awk 的入门体验。
5.1 awk 介绍
AWK 是一种优良的文本处理工具。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。最简单地说,AWK 是一种用于处理文本的编程语言工具。
在大多数 linux 发行版上面,实际我们使用的是 gawk(GNU awk,awk 的 GNU 版本),在我们的环境中 ubuntu 上,默认提供的是 mawk,不过我们通常可以直接使用 awk 命令(awk 语言的解释器),因为系统已经为我们创建好了 awk 指向 mawk 的符号链接。
$ ll /usr/bin/awk

5.2 awk 的一些基础概念
awk 所有的操作都是基于 pattern(模式)—action(动作)对来完成的,如下面的形式:
$ pattern {
action}
你可以看到就如同很多编程语言一样,它将所有的动作操作用一对 {} 花括号包围起来。其中 pattern 通常是表示用于匹配输入的文本的“关系式”或“正则表达式”,action 则是表示匹配后将执行的动作。在一个完整 awk 操作中,这两者可以只有其中一个,如果没有 pattern 则默认匹配输入的全部文本,如果没有 action 则默认为打印匹配内容到屏幕。
awk 处理文本的方式,是将文本分割成一些“字段”,然后再对这些字段进行处理,默认情况下,awk 以空格作为一个字段的分割符,不过这不是固定的,你可以任意指定分隔符,下面将告诉你如何做到这一点。
5.3 awk 命令基本格式
awk [-F fs] [-v var=value] [-f prog-file | 'program text'] [file...]
其中 -F 参数用于预先指定前面提到的字段分隔符(还有其他指定字段的方式) ,-v 用于预先为 awk 程序指定变量,-f 参数用于指定 awk 命令要执行的程序文件,或者在不加 -f 参数的情况下直接将程序语句放在这里,最后为 awk 需要处理的文本输入,且可以同时输入多个文本文件。现在我们还是直接来具体体验一下吧。
5.4 awk 操作体验
先用 vim 新建一个文本文档 test,包含一下内容
I like linux
www.baidu.com
- 使用 awk 将文本内容打印到终端
# "quote>" 不用输入
$ awk '{
> print
> }' test
# 或者写到一行
$ awk '{print}' test
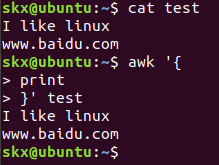
说明:在这个操作中省略了 pattern,所以 awk 会默认匹配输入文本的全部内容,然后在"{}"花括号中执行动作,即 print 打印所有匹配项,这里是全部文本内容
- 将 test 的第一行的每个字段单独显示为一行
$ awk '{
> if(NR==1){
> print $1 "\n" $2 "\n" $3
> } else {
> print}
> }' test
# 或者
$ awk '{
> if(NR==1){
> OFS="\n"
> print $1, $2, $3
> } else {
> print}
> }' test
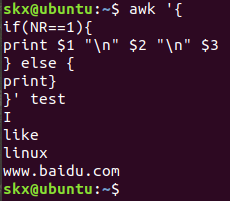
说明:里我使用了 awk 语言的分支选择语句 if,它的使用和很多高级语言如C/C++语言基本一致。NR 与 OFS 这两个是 awk 内建的变量,NR 表示当前读入的记录数,可以简单的理解为当前处理的行数,OFS 表示输出时的字段分隔符,默认为" "空格,如上图所见,我们将字段分隔符设置为 \n 换行符,所以第一行原本以空格为字段分隔的内容就分别输出到单独一行了。然后是 $N 其中 N 为相应的字段号,这也是 awk 的内建变量,它表示引用相应的字段,因为我们这里第一行只有三个字段,所以只引用到了 $3。除此之外另一个这里没有出现的 $0,它表示引用当前记录(当前行)的全部内容。
- 将 test 的第二行的以点为分段的字段换成以空格为分隔
$ awk -F'.' '{
> if(NR==2){
> print $1 "\t" $2 "\t" $3
> }}' test
# 或者
$ awk '
> BEGIN{
> FS="."
> OFS="\t" # 如果写为一行,两个动作语句之间应该以";"号分开
> }{
> if(NR==2){
> print $1, $2, $3
> }}' test
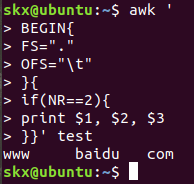
说明:这里的 -F 参数,前面已经介绍过,它是用来预先指定待处理记录的字段分隔符。我们需要注意的是除了指定 OFS 我们还可以在 print 语句中直接打印特殊符号如这里的 \t,print 打印的非变量内容都需要用""一对引号包围起来。上面另一个版本,展示了实现预先指定变量分隔符的另一种方式,即使用 BEGIN,就这个表达式指示了,其后的动作将在所有动作之前执行,这里是 FS 赋值了新的".“点号代替默认的” "空格。
5.5 awk 常用的内置变量
| 变量名 | 说明 |
|---|---|
| FILENAME | 当前输入文件名,若有多个文件,则只表示第一个。如果输入是来自标准输入,则为空字符串 |
| $0 | 当前记录的内容 |
| $N | N 表示字段号,最大值为 NF 变量的值 |
| FS | 字段分隔符,由正则表达式表示,默认为" "空格 |
| RS | 输入记录分隔符,默认为"\n",即一行为一个记录 |
| NF | 当前记录字段数 |
| NR | 已经读入的记录数 |
| FNR | 当前输入文件的记录数,请注意它与 NR 的区别 |
| OFS | 输出字段分隔符,默认为" "空格 |
| ORS | 输出记录分隔符,默认为"\n" |