Pythonの爬虫類 - 英語名や正規表現で登るの紹介
英語名をクロール:
I.クローラモジュール詳細設計
(1)全体的なアイデア
爬虫類は英語名を達成クロールこのデータについては、私の最初のアイデアは、AZは、csvファイルに保存され、うちクロールすべての英語名を接続することで、その後、巡回を使用して、CSVファイルの中から、各リンクの英語名を読みますこの方法は、各リンクは、各リンクの英語名に従ってデータをクロール、すべての英語名のリンクを読み込む新しいCSVファイルに保存します。
関数名を記述する必要があるが、英語をクロールリンクされ、コンテンツのクロールは、機能の英語名の詳細ページのコンテンツをクロール、csvファイルの内容を読み取るためにcsvファイル機能と機能に保存されます。
表5.3.1
| 関数名 |
効果 |
| デフget_nameLink(): |
英語クロールリンク |
| デフsave_to_csv(dictの、ファイル名): |
csvファイルに保存されている辞書の形でコンテンツのクロール |
| デフget_WebLinkcsv(名): |
csvファイルの内容を読みます |
| デフget_namedata(): |
各英語名をクロールデータリンクに応じて、 |
(2)英語名のリンクをクロール
まず、AZの英語名の目次ページを観察し、ウェブサイトへの各文字が対応していることを見つけ、ちょうどサイトは英語名を3つのモジュール、各モジュール30の英語名が表示されます開き、英語名の文字の上にもっとありますその後、動的にロードされたマウスの動きに基づいて、ページ上に表示されます。しかし、英語名の各文字のために別のページに表示されます。図:
5.3.2(1)
英語名の各文字は、すべてのページの数に応じて決定することができることが観察され、動的な方法は、各文字を観察する英語のページに基づいてリンクをクロールの英語名の各文字の数を決定するためにクロールすることはできません。リンク・フォーマット:
https://www.thebump.com/b/baby-girl-names-that-start-with-{letter}?sort_by=popular&page={number}&page_size=30&gender=&request-by-ajax=true
手紙AZ表現文字は、数がページ数を表し、PAGE_SIZEは英語名の数は、ページごとに表示されて表して30です。
コードは以下の通りであります:
5.3.2(2)
(3)詳細ページをクロール
詳細ページに対応する英語名を開き、ポイント解像度に対応する各モジュールのタグの内容を観察し、評価要素の内容を表示するには、右クロールの必要性を開きます。空の飛びがあるように見える、csvファイルに保存されて解析することがあれば、いくつかの英語が存在セレブモジュール、およびセレブモジュールは存在しないいくつかの英語名は、あなたが、裁判官に必要なことを観察し、次のコンテンツを解決するために続けています。図:
そこに有名人のコンテンツモジュール内の名前アビゲイル、アナベルはこの中に有名人の名前を指定していない、この場合には、それが空のコンテンツ入金されるだろう。
図5.3.3(1)
コードは以下の通りであります:
例外処理を使用することを除いてみてください。
図5.3.3(2)
(4)コンテンツを格納
コンテンツの中に辞書形式を使用すると、CSVファイル、それらに保存されています。辞書(辞書)別の有用なPythonは組み込みデータ型、オブジェクトリストを結合注文されている、辞書は、オブジェクトの順不同のコレクションです。辞書の要素のうち鍵ではなく、アクセスをシフトすることによってアクセスされ、辞書マッピングタイプ、キー順不同である辞書「{}」識別子、2つの違いはあります(キー)、キー(鍵)の組の値(値)は不変でなければなりません。
(辞書、ファイル名)がデータを格納する機能を表し、辞書が格納されているDEF save_to_csv、データは、使い捨てクロールすることができないため、コンテンツをクロールするときに、別ので、登りであるこの実験大きなは、データを格納するためにも使用されます追加のアクセス方法。
図:
図5.3.4
(5)ファイルを読み込みます
主に名のリンクをクロール下のファイル名のリンク、詳細ページを読むために読み取るために使用されます
図5.3.5
II。デバッグとテスト
問題(1)試運転中に遭遇しました
唯一の90のリンクに登場した英語名へのリンク、および約クロールする場合(1)は、登るうちの残りの部分が、英語名の残りの部分は、スライドにマウスに基づいてWebページ内の負荷にWebページに表示されます観察はhttps://www.thebump.com/b/baby-girl-names-that-start-with-{letter}?sort_by=popular&page={number}&page_size=30&gender=&request-by-ajaxリンクすることができます= trueの場合、取得され、確認の各文字のためにクロール各英語名英語名の数;このフォームを使用したURLは、各ページのみ30英語名ページめくり操作に相当します。
エラーが表示されます締めの動作中(2)が、観測過程、およびインデントエラーなしで、オンラインチェックあなたは関数を定義する場合、関数は何のコンテンツがこのエラーを報告しませんがあるという理由だけでした。
クロールプロセス中の(3)数回、しばしば特定の固定された場所クロール、修正いくつかの時点で停止し、最終的に問題のリクエストヘッダを発見されました。
(2)表示クロール
クロールコンテンツが示すように、csvファイルに保存されます。
図5.2
3つのコースの経験を持つデザインの経験
(1)このカリキュラムの設計を通じて、最終的に見つかったを確認するために再びかかわらず、いくつかの問題が発生したが、再び思考の後にして、もう一度、何度も繰り返して、私の設計プロセスのPythonの側面についての知識をさらに固体把握可能その理由は、私も早くこの分野での知識の欠如や経験不足を明らかにしました。練習は、ハンズオン設計により、完璧になりますので、私たちは紙の上で、もはや私の知識にあなたの兄弟を探しています。
(2)すぎと地獄を変更することができます。コース設計プロセスでは、我々は、エラーを発見していき、正しい絶えず、常に理解し、取得し続けます。知り、最終テスト、デバッグセッションをやって、練習自体は「それ自体は驚くべき成果は、あまりにもなく、変更することができます」です。コース設計は最終的に成功し、設計に多くの問題に遭遇した、最終的には学生のヘルプで解決し、それはまた、出会い、将来の社会の発展にと実践を学び、私たちは絶え間ない努力をしなければならないことを私たちにはできません伝えます問題は、問題を見つけるために手間を取るために必ず、バックであると考えられ、そして、成功するための唯一の方法は、前方の方法ですべての障害を克服したいがために行うために作るために、すべてのソリューションで、終了ではなく、やったことはありません成功した収穫、喜びの収穫、だけでなく、社会や他者が認識したことがない可能性が高いです。
(3)それは私に専門的な知識と専門技能を強化するために多くを与える、コース設計のコースであることは事実ですが、それはまた、投機的なクラスであり、彼は、私の思考の多くを道路の多くを与えました。私は抽象的な理論の具体的な理解を持っています。このカリキュラムの設計を通して、表現は私が深いデータを照会することによって、正の応用の理解だけでなく、爬虫類のPythonの原理を理解する必要があります。私はこの学期は、ハンズオン他の機能の多様上の能力は、さらに改善されている、独立した思考を養うだけでなく、実験では、と思います。さらに重要なのは、コース設計の研究では、利益は本当に、私は学習の多くのことを学びましたが、これは将来的に最も実用的です。唯一絶えず学び、実践により、社会の課題に直面して。実際に学習。これが私たちの未来が、また、大きな助けです。
ワン:正規表現とは何ですか
正規表現とも呼ばれる正規表現は、多くの場合、取得モデル(ルール)のものと行のテキストを置き換えるために使用されます。
正規表現は、文字を表現するために使用され、この「ルール列」、文字列操作の論理式であり、特定の事前定義された文字の組み合わせ、及びこれらの特定の文字を使用し、「文字列ルール」を形成することです文字列フィルタ・ロジックのため。
正規表現と別の文字列を考えると、我々は、以下の目的を達成することができます:
- 与えられた文字列は、論理(「マッチング」)をフィルタリングする正規表現を満たすかどうか。
- 正規表現、我々はテキスト文字列から必要な特定の部分(「フィルタリング」)へのアクセス。
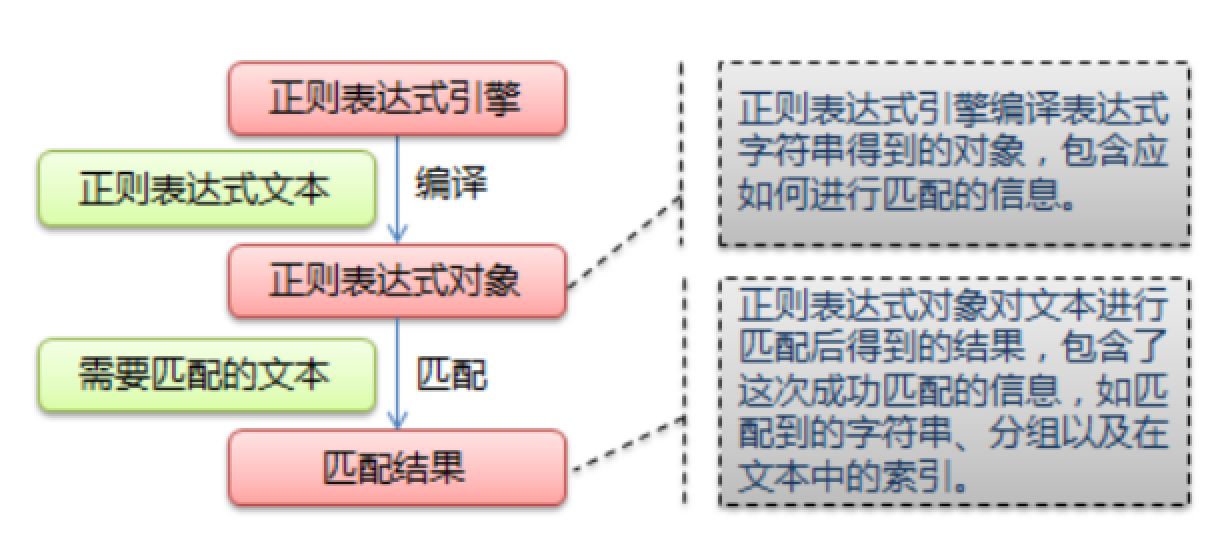
2:4つの主要な段階の爬虫類
- 明確な目標(あなたが範囲またはサイト検索へ行くしようとしているかを知ります)
- クライム(サイトの全体の登り下りのすべての内容)
- (私たちは無駄なデータを削除するために必要なデータをフィルタリングし、マッチング)を取ります
- データの処理(方法に従って、私たちは店と使用したいです)
3:ルールにマッチする正規表現
| メタキャラクタ | 説明 |
|---|---|
| 。 | 任意の文字を表し |
| \ | |
| [] | 任意の文字またはサブパターンにマッチします |
| [^] | 文字セットと否定 |
| - | 範囲を定義します。 |
| \ | 否定される次の文字(通常は特殊変数の一般的な、通常の特殊なバリアント) |
| * | 直前の文字または部分式と0回以上一致します |
| *? | マッチング不活性 |
| + | 直前の文字または部分式と1回以上一致し |
| +? | マッチング不活性 |
| ? | ゼロまたは1回の繰り返し試合前の文字または部分式 |
| {N} | 直前の文字または部分式にマッチします |
| {M、N} | 前または部分式は、少なくとも文字にマッチしn回、最大で倍のm個 |
| {N} | 少なくとも直前の文字または部分式にマッチn回 |
| {N}? | マッチングの不活性になる前に |
| ^ | 文字列の先頭にマッチします |
| \ A | 文字列の先頭にマッチします |
| $ | 一致文字列の末尾 |
| [\ B] | バックスペース文字 |
| \ C | 制御文字にマッチします |
| \ dは | 任意の数字と一致 |
| \ D | 番号が一致以外の文字 |
| \トン | マッチングタブ |
| \ワット | 任意の英数字、アンダースコアにマッチします |
| \ W | 英数字、アンダースコアと一致していません |
IV。正規表現の例
基本を学ぶの例として、あなたがブログを参照してくださいすることができ、個人的に私はより詳細なと感じている:https://blog.csdn.net/weixin_44258187/article/details/85307979