セグメント化されたログ
大きなファイルを、扱いやすい複数の小さなファイルに分割します。
問題の背景
単一のログファイルが大きくなり、プログラムの起動時に読み取られる可能性があるため、パフォーマンスのボトルネックになります。古いログは定期的にクリーンアップする必要がありますが、大きなファイルをクリーンアップするのは非常に面倒です。
解決
1つのログを複数に分割し、ログが特定のサイズに達すると、新しいファイルに切り替えて書き込みを続行します。
//写入日志
public Long writeEntry(WALEntry entry) {
//判断是否需要另起新文件
maybeRoll();
//写入文件
return openSegment.writeEntry(entry);
}
private void maybeRoll() {
//如果当前文件大小超过最大日志文件大小
if (openSegment.
size() >= config.getMaxLogSize()) {
//强制刷盘
openSegment.flush();
//存入保存好的排序好的老日志文件列表
sortedSavedSegments.add(openSegment);
//获取文件最后一个日志id
long lastId = openSegment.getLastLogEntryId();
//根据日志id,另起一个新文件,打开
openSegment = WALSegment.open(lastId, config.getWalDir());
}
}ログがセグメント化されている場合は、ログの場所(またはログシーケンス番号)を使用してファイルをすばやく見つけるためのメカニズムが必要です。これは、次の2つの方法で実現できます。
- 各ログ分割ファイルの名前には、特定の開始およびログ位置オフセット(またはログシーケンス番号)が含まれます
- 各ログシーケンス番号には、ファイル名とトランザクションオフセットが含まれています。
//创建文件名称
public static String createFileName(Long startIndex) {
//特定日志前缀_起始位置_日志后缀
return logPrefix + "_" + startIndex + "_" + logSuffix;
}
//从文件名称中提取日志偏移量
public static Long getBaseOffsetFromFileName(String fileName) {
String[] nameAndSuffix = fileName.split(logSuffix);
String[] prefixAndOffset = nameAndSuffix[0].split("_");
if (prefixAndOffset[0].equals(logPrefix))
return Long.parseLong(prefixAndOffset[1]);
return -1l;
}ファイル名にこの情報が含まれた後、読み取り操作は2つのステップに分割されます。
- オフセット(またはトランザクションID)を指定して、ログがこのオフセットよりも大きいファイルを取得します
- このオフセットより大きいすべてのログをファイルから読み取ります
//给定偏移量,读取所有日志
public List<WALEntry> readFrom(Long startIndex) {
List<WALSegment> segments = getAllSegmentsContainingLogGreaterThan(startIndex);
return readWalEntriesFrom(startIndex, segments);
}
//给定偏移量,获取所有包含大于这个偏移量的日志文件
private List<WALSegment> getAllSegmentsContainingLogGreaterThan(Long startIndex) {
List<WALSegment> segments = new ArrayList<>();
//Start from the last segment to the first segment with starting offset less than startIndex
//This will get all the segments which have log entries more than the startIndex
for (int i = sortedSavedSegments.size() - 1; i >= 0; i--) {
WALSegment walSegment = sortedSavedSegments.get(i);
segments.add(walSegment);
if (walSegment.getBaseOffset() <= startIndex) {
break; // break for the first segment with baseoffset less than startIndex
}
}
if (openSegment.getBaseOffset() <= startIndex) {
segments.add(openSegment);
}
return segments;
}例えば
基本的に、RocketMQ、Kafka、Pulsarの基盤となるストレージBookKeeperなど、すべての主流のMQストレージは、セグメント化されたログを使用します。
RocketMQ: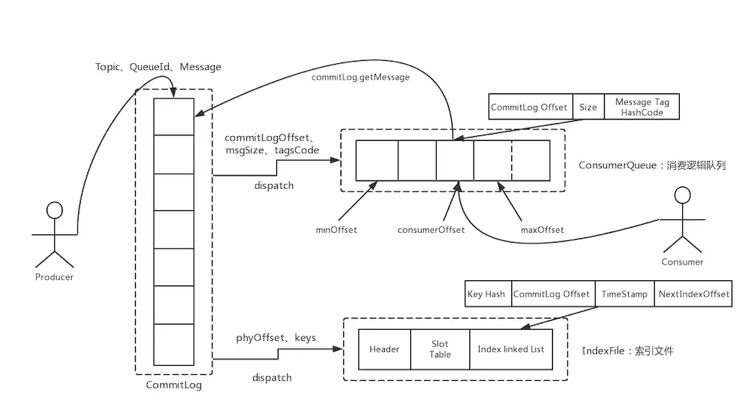
カフカ:
パルサーストレージはBookKeeperを実装しています。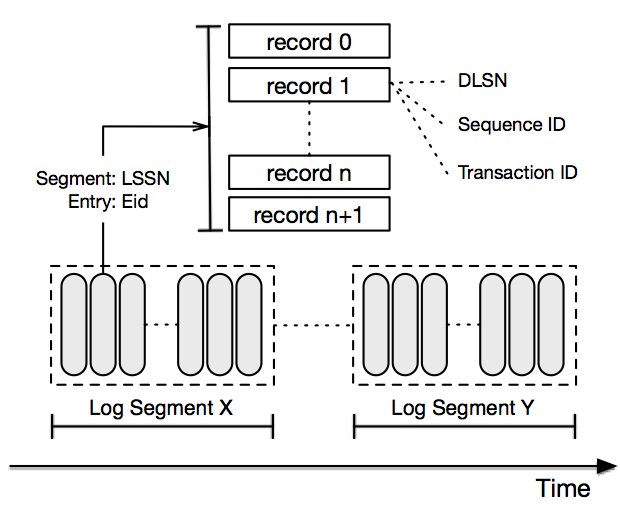
さらに、整合性プロトコルPaxosまたはRaftに基づくストレージは、通常、ZookeeperやTiDBなどのセグメント化されたログを使用します。
毎日1回スワイプすると、スキルを簡単にアップグレードして、さまざまなオファーを得ることができます。
