目次
1.StreamSetの概要
Streamsetsは、ビッグデータのリアルタイム収集およびETLツールであり、コードを1行も記述せずにデータの収集と循環を実現できます。ドラッグアンドドロップのビジュアルインターフェイスを介して、データパイプライン(パイプライン)の設計とスケジュールされたタスクのスケジューリングが実現されます。Kettleの欠点は、定期的に実行され、リアルタイムのパフォーマンスが比較的低いことです。
要件:パイプラインフローを定期的に開き、定期的に閉じることを希望します。これまでに見つかった方法は次のコンポーネントであり、次のケースもこのコンポーネントに基づいています。

Cronスケジューラで使用される公式ドキュメント:前面をクリックします
2、タイミングスケジューリングの場合
2.1全体的なパイプラインフロー設計
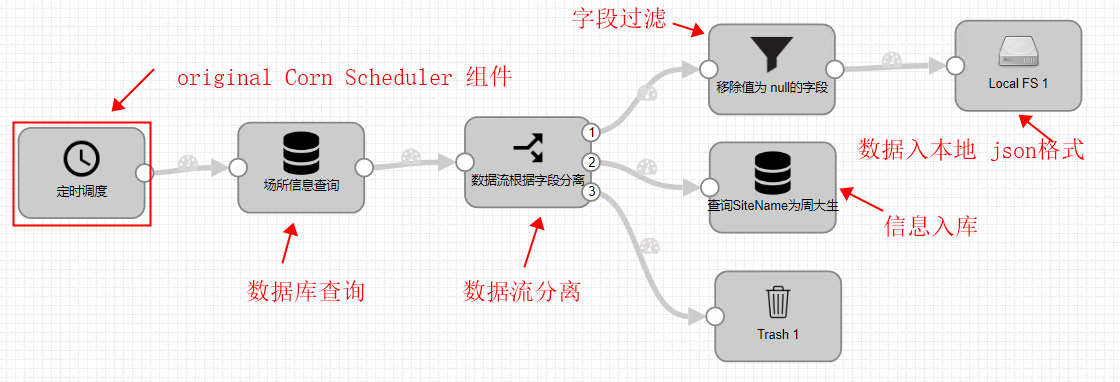
2.2特定の手順
1.origins-コーンスケジューラー
タイミングコンポーネントを選択します。起点はパイプラインフローに1つしか含めることができず、他のコンポーネントはプロセス、宛先、およびエグゼキュータから選択できます。

注:ここでは、デモンストレーションを容易にするために1時間ごとの実行が選択されています。これは自由に調整できます。式は、Javaによって開発されたスケジューリングフレームワークQuartzで定義されています。
式の使用については、http://www.quartz-scheduler.org/documentation/quartz-2.3.0/tutorials/crontrigger.htmlを参照してください。
2.process-JDBCルックアップ
(1)JDBC接続アドレス

(2)データベースのユーザーとパスワード

(3)MySQLドライバー、事前にmysqlドライバーをここにアップロードします

3.ストリームセレクター

4.パイプラインフローブランチ1-データはローカルディスクに分類されます
(1)出力ファイルは、ファイル出力タイプ、ファイルプレフィックスとサフィックス、入力フォルダー、入力ファイルサイズ、ファイル形成時間間隔を選択します。ここでは、Flumeに似ているはずですが、ファイル形成のローリング時間間隔とサイズを構成できます。制御する要因。

(2)ここでデータ形式のデータ型にJSONを選択します

5.パイプラインフローフィルタリングブランチ2-フィルタリングされたデータはデータベースに保存されます
(1)宛先、JDBC接続でJDBCプロデューサーを選択し、データベース名を指定して、データの挿入を選択します

(2)データベースのユーザー名とパスワード、およびドライバー
6.パイプラインフローフィルタリングブランチ3ゴミ箱
言うことは何もありませんが、他のデータは必要ありません。
2.3操作
1. [開始]をクリックして、パイプラインフローを開始します

2.タイミングポイントに到達する
パイプラインフローデータの流入時間に達しておらず、パイプラインフローは静かに待機し、時間切れになるとデータが流入します。

3.データはローカルディスクに分類されます
パイプラインストリームデータはtmpの一時ファイルに流れ込み、ファイルの最終生成はファイルサイズと時間間隔によって制御する必要があります。

データストリームによって形成されたファイルには、現時点ではtmpマークがありません

4.フィルタリングされたデータを新しいテーブルに書き込みます

2番目のデータベースのOutput2に7つのデータがあることがわかります。2番目のデータベースのデータレコードの数も7です。

上記はStreamSetsスケジューリングの簡単な例ですが、まだ学習中であり、参照を学習するためだけに欠陥があるはずです。
既存の問題:
- データベースデータの同期とデータの重複の問題が発生しました。これは、ExecutorsのPipeline Finisherを使用して一度実行されましたが、検証していません。
- パイプラインフロー開始時間スケジューラも開始されますが、毎日この時間に実行できるように、どのように終了できますか?このコアスケジューラの式式は解決可能である必要があります