要約: この記事は元々、Grape City の技術チームによって CSDN に公開されたものです。転載元を明記してください:グレープシティ公式ウェブサイト、グレープシティは、開発者に力を与えるための専門的な開発ツール、ソリューション、サービスを開発者に提供します。
序文
この記事では、Go 言語、プロセス、スレッド、コルーチンの背景を中心に、コルーチンの問題を Go 言語がどのように解決して同時プログラミングを実現するのかについて紹介します。この記事の所要時間は約 15 ~ 20 分です。お読みください。適度な時間。
1. 囲碁の過去と現在
1.1. Go言語誕生の過程
2007 年 9 月のある日、Google エンジニアのロブ・パイク氏はいつものように C++ プロジェクトの構築を開始したと言われていますが、これまでの経験によれば、この構築には 1 時間ほどかかるはずです。この時、彼と他の 2 人の Google 同僚、ケン トンプソンとロバート グリーズマーは不平を言い始め、新しい言語についてのアイデアを表明しました。当時、Google は社内でさまざまなシステムを構築するために主に C++ を使用していましたが、C++ の複雑さと並行性のネイティブ サポートの欠如により、3 つの大きな上司は非常に悩みました。

初日の雑談は有意義で、プログラマに喜びをもたらし、将来のハードウェア開発トレンドに適合し、Google 社内の大規模ネットワーク サービスを満足させる新しい言語をすぐに思いつきました。そして二日目に彼らは再び集まり、新しい言語について真剣に考え始めました。翌日の会議の後、ロバート・グリーズマーは次のような電子メールを送信しました。
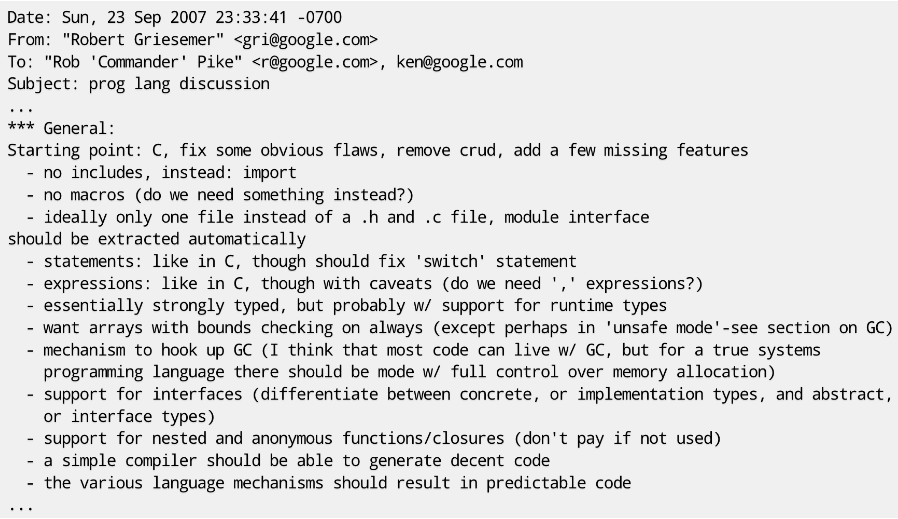
電子メールから、この新しい言語に対する彼らの期待は次のとおりであることがわかります。 **C 言語をベースにして、いくつかのエラーを修正し、いくつかの批判された機能を削除し、いくつかの不足している機能を追加します。**Switch ステートメントの修復、import ステートメントの追加、ガベージ コレクションの追加、インターフェイスのサポートなど。そして、このメールが Go の設計の最初の草案となりました。
この数日後、ロブ・パイクは車で帰宅する途中、新しい言語に Go という名前を思いつきました。彼の頭の中では、「Go」という単語は短く、入力しやすく、Go のツールチェーン (goc コンパイラー、goa アセンブラ、gol リンカーなど) など、その後の他の文字と簡単に組み合わせることができます。また、この単語は彼らの言葉にも適合します。言語設計の本来の意図: シンプル。
1.2. ステップバイステップの形成
Go の設計思想を統一した後、Go 言語は言語の設計の反復と実装を正式に開始しました。2008 年に、C 言語の父である Ken Thompson が Go コンパイラの最初のバージョンを実装しました。このバージョンの Go コンパイラは今でも C 言語で開発されています。その主な動作原理は、Go を C にコンパイルしてからコンパイルすることです。 C をバイナリに変換します。2008 年半ばまでに、Go の設計の最初のバージョンはほぼ完成しました。このとき、同じく Google で働いていた Ian Lance Taylor は、Go 言語の 2 番目のコンパイラでもある Go 言語用の gcc フロントエンドを実装しました。イアン・テイラーのこの功績は励ましであるだけでなく、新しい言語である Go の実現可能性の証明でもあります。言語の 2 番目の実装では、Go の言語仕様と標準ライブラリを確立することも重要です。その後、Ian Taylor は Go 言語開発チームの 4 人目のメンバーとして正式に加わり、後に Go 言語の設計と実装における中心人物の 1 人になりました。Russ Cox は Go コア開発チームの 5 人目のメンバーで、これも 2008 年に加わりました。チームに参加した後、Ross Cox は、関数型が「第一級市民」であり、独自のメソッドを持つこともできるという特徴を利用して、http パッケージの HandlerFunc 型を巧みに設計しました。このようにして、明示的な変換を通じて、通常の関数を http.Handler インターフェイスを満たす型にすることができます。それだけでなく、Ross Cox は、Go 言語の I/O 構造モデルを確立した io.Reader インターフェイスや io.Writer インターフェイスなど、当時の設計に基づいたより一般的なアイデアもいくつか提案しました。その後、Ross Cox は Go コア技術チームの責任者となり、Go 言語の継続的な進化を推進しました。この時点で、Go 言語の初期コアチームが形成され、Go 言語は安定した進化の道を歩み始めました。
1.3. 正式リリース
2009 年 10 月 30 日、Rob Parker は Google Techtalk で Go 言語に関する講演を行い、これが Go 言語が初めて公開されました。10 日後の 2009 年 11 月 10 日、Google は Go 言語プロジェクトがオープンソースであることを正式に発表し、この日が Go によって Go 言語の誕生の日として正式に指定されました。

(Go言語マスコット Gopher)
1.4. Go インストールガイド
1. Go言語インストールパッケージのダウンロード
Go公式サイト:https://golang.google.cn/
対応するインストール バージョンを選択するだけです (.msi ファイルを選択することをお勧めします)。
2. インストールが成功したかどうか、および環境が正常に構成されているかを確認します。
コマンド ラインを開きます: win + R を押して実行ボックスを開き、cmd コマンドを入力してコマンド ライン ウィンドウを開きます。
コマンドラインに go version と入力するとインストールされているバージョンが表示され、以下の内容が表示されればインストール成功です。

2. プロセス、スレッド、コルーチン
インターネット クラウドの時代では、Docker、Kubernetes、Dapr など、名前付きコンポーネントのほぼすべてが Go で開発されています。数えきれないほどありますが、これらの単純な文法だけでこれらの大手メーカーを捉えることは不可能です。心の。Go はインターネット時代に非常に人気があるため、独自の基盤が必要です。そうです、それは Go の同時プログラミング機能、Go 言語の最大のキラーGoroutineです。
Goroutine は、コルーチンを意味する元の単語 Coroutine から取られた複合語です。
Goroutine は Go におけるコルーチンの実装ですが、コルーチンとは正確には何でしょうか? なぜ近年人気が出てきたのでしょうか?C# のコルーチンの概念なしで Web 開発を行うことは可能ではないでしょうか? なぜ大企業は Java などの人気言語のコルーチンを使用した Go に専念するのでしょうか? 上記の疑問を念頭に置いて、コルーチンとは何なのかを一から理解し始めました。
2.1. プロセスの出現
コルーチンの概念については昔から聞いており、このコルーチンが何を意味するのか何度か理解しようとしましたが、予備知識が不足しているため、有用な知識チェーンを形成することができません。忘れて。したがって、コルーチンの概念の誕生と、それがなぜ今これほど注目されているのかを理解して、最終的に知識を自分の経験に変えることができるようにする必要があると思います。
最初から始めなければいけないので、そもそもなぜプロセスがあるのかという概念から始めるべきだと思います。
その昔、コンピュータは単一チャネルのバッチ処理マシンであったと言われており、プログラマー(ホールパンチャーとも言う)が書いたプログラムを紙袋を通してコンピュータに入力すると、やがてコンピュータは計算後、結果をコンピュータに返します。この時代には、実際にはプロセスという概念がありません。
技術の継続的な発展により、コンピュータは最も原始的な形式からマルチチャネルのバッチ処理システムへと徐々に進化してきました。この時点で、コンピュータはすでに複数のプログラムを同時に実行できるようになり、オペレーティングシステムの概念も登場しました。この時点で、人々は、プログラムの概念だけを使用しても、コンピューター内で実行されているプログラムをうまく記述することができなくなっていることに気づきました。プログラムは同時に複数回実行される可能性があるため、コンピューターにとって、同じコードを持つプログラムは異なるプログラムを表すため、賢い頭脳がプロセスという概念を発明しました。
当時、プロセスはプログラムの存在を示す唯一の識別子でした。プロセスはプログラムの実行スケジュール単位であるだけでなく、プログラム情報の記憶単位でもありました。各プロセスにはプロセス制御ブロック PCB があり、そこにはいくつかの情報が保存されていました。プロセスに関する情報 (例: ページ テーブル、レジスタ、プログラム カウンター、ヒープ、スタックなど)。
さらに、プロセスは互いに分離されており、独自の独立した PCB やメモリなどを備えており、いくつかのプロセスは互いに干渉せず、コンピュータ システム内で完全に独立して実行されます。
この期間中、すべてが何の問題もなく完璧に実行されていました。
2.2. スレッドの出現
しかし、テクノロジーのさらなる発展により、MP3 オーディオ ファイルの再生など、プロセスだけを使用するだけではいくつかの問題を解決できないことがわかりました。
MP3 オーディオ ファイルを再生するための疑似コードは、おおよそ次のとおりです。
main() {
while(true) {
/*IO读取音频流*/
Read();
/*解压音频流*/
Decompress();
/*播放*/
Play();
}
}
Read() {
...}
Decompress() {
...}
Play() {
...}
プロセス内でのこのコードの実行には非常に深刻な問題があります。3 つの関数を同時に実行することはできません。これは、Read 関数が呼び出されると、ユーザー モード コードがシステム コールを発行して IO 操作を実行するためです。IO 集中型の操作の場合、オペレーティング システムは通常、そのプロセスを直接ブロックします。IO 操作が完了して割り込みがトリガーされると、オペレーティング システムは以前にブロックされたプロセスをアクティブにして実行を継続します。
すべてのファイルを読み込んでデコードしていない場合、プログラムはオーディオ ファイルを再生できません。ユーザーへの直接的な影響は、再生されるサウンドがセグメントごとに変化することです。なぜセグメントごとなのでしょうか?IO 操作にはバッファがあるため、毎回 1 つのバッファのデータしか IO できず、プログラムのロジックに従って、バッファ内のデータがデコードされてから再生されます。次に IO... ユーザーが聞くのは音楽です。
複数のプロセスで実装することは可能ですか? これは、IO プロセスが 1 つ、デコードプロセスが 1 つ、再生プロセスが 1 つです。これは解決策のように見えますが、プロセス間通信という問題がまだ残っています。前のセクションでは、プロセス間のメモリが互いに分離されており、3 つのプロセスが互いのコンテンツに直接アクセスできないことを学びました。そのためには IO プロセスを実行する必要があり、それ自身のメモリを伝える方法を見つける必要があります。データをデコードプロセスに送ります。言うまでもなく、プロセス間通信によるパフォーマンスの消費は膨大であり、3 つのプロセスが完全に連携して動作することは実際には困難です。
したがって、メモリを共有するという前提の下では、単一のプロセスが複数の異なるプログラムを同時に実行できないことがわかります。そこで、スレッドという概念が登場しました。
上記の問題を解決するために、スマートブレインはプロセスのリソース管理モジュールとスケジューリングモジュールをより詳細に分割し、スレッドの概念を作成しました。現時点では、プロセスは依然としてプログラムのすべてのリソースの制御センターですが、プログラムの実行はプロセスによってではなく、複数の内部スレッドによって実行されます。これらのスレッドはメモリを共有し、複数の異なるプログラムを同時に実行するように CPU によってスケジュールすることができ、上記の問題はスレッドによって完全に解決されます。
プロセス内のスレッドはメモリを共有しますが、スレッドの実行は互いに独立しているため、各スレッドには独自のレジスタ、プログラム カウンター、スタック、その他のリソースが必要です。したがって、プロセス制御ブロック PCB と同様に、スレッドも独自のスレッド制御ブロック TCB を持ち、前述の排他的リソースの一部を記録します。プロセスとスレッドのモデルは次のとおりです。

2.3. インターネット時代
スレッドの概念はインターネット時代まで順調に動作していましたが、この時点で次のような新たな問題が発生しています。
インターネットの急速な発展に伴い、高い同時実行性はすでにすべてのインターネット企業が直面しなければならない問題となっています。高い同時実行性があってこそトラフィックが存在し、トラフィックがあってこそ自社のビジネスの基盤を確立できるからです。同時実行性が高い時代では、スレッドが需要を満たすのは困難です。
サーバーが 1 秒あたり最大 10,000 個の同時リクエストを処理できる場合、対応するサーバーはこれらの同時リクエストに対応するために少なくとも 10,000 個のスレッドを開く必要があります。スレッドの作成にもリソースが必要です。Linux を例にとると、POSIX スレッドの作成コストは 1 ~ 8MB の範囲にあり、1秒間に 10,000 リクエストを実行すると、1 秒間に 10 ~ 80GB のメモリ リソースを消費する必要があります。とても怖い。
さらに、あるスレッドから別のスレッドへの CPU スケジューリングにはスレッド コンテキストの切り替えが必要ですが、これもパフォーマンスの低下点になります。コンテキストスイッチとは何ですか? 上で述べたように、スレッドには独自のスタックおよびプログラム カウンタ レジスタを記録するための独自の TCB もあります。オペレーティング システムがスレッド スケジューリングを実行する場合、実行前に、前述のすべてのリソースをスレッドの TCB から CPU によって実行されるレジスタおよびメモリにロードする必要があります。1 つのスレッドのタイム スライスが終了して別のスレッドに切り替わるとき、オペレーティング システムは、前のプログラムの最終リソース情報を前のスレッド TCB に記録し、新しいスレッドの TCB にリソースをロードする必要もあります。このプロセスはスレッド コンテキスト スイッチングと呼ばれ、オーバーヘッドは通常3 ~ 5us 程度です。
さらに、現在のインターネット リクエストのほとんどは、データを読み取り、表示のためにユーザーに返す必要があります。データの読み取りには IO 操作が必要です。IO 操作中、オペレーティング システムは対応するスレッドをブロックします。そのため、テストを行った人もいます。同時実行性が高い場合、スレッドの 80% が実際にブロックされ、リソースを占有するだけです。 . 仕事がなければ、無駄にシステムリソースを消費します。また、メモリが不十分な場合、オペレーティング システムがプロセスを一時停止する可能性があるため、ページ フォールト割り込みが頻繁にトリガーされ、すでに不足している IO 帯域幅がさらに圧迫され、より深刻な悪循環が形成されます。
初期の Web サーバー Apache は、マルチスレッド応答モデルを通じて Web リクエストを処理しました。しかし、Apache サーバーを使用するモデルは上記の問題を解決できないため、現在ではほとんど誰も使用していません。
このとき、賢明な頭脳は、IO 多重化テクノロジという新しいソリューションを考え出しました。Nginx はこのテクノロジーを使用して、同時多発リクエストを処理します。では、IO多重化とは何でしょうか?
IO 多重化は、1 つのリクエストに対してスレッドを開くこととは異なります。Nginx などのサーバーは、無限ループ スレッドを通じてすべての Web リクエストをリッスンします。リクエストが到着すると、Linux の一部の IO 多重化テクノロジ select、poll、epoll、および kqueue は複数のファイルを監視できますいずれかのファイル記述子の読み取りおよび書き込み操作の準備が完了すると、対応する処理を実行するようにプログラムに通知されるため、効率的なイベント駆動型プログラミングが実現します。さらに、これらのリクエストの実行スレッドはノンブロッキング IO 操作です。つまり、IO 操作を待機せず、他の処理を行うために停止するため、サーバーへの負荷が大幅に軽減されます。
しかし、これには新たな問題があります。IO 多重化技術では、複数のリクエストに対する応答はイベント コールバック機構であり、これらのプログラムを処理するプログラマはコールバックのタイミングを見つけることが困難であり、プログラムの開発者は困難を伴います。精神的ストレスが無限に大きくなり、コードを書くのが非常に難しくなります。
2.4. コルーチンの出現
上記の問題を解決するために、主役のコルーチンが登場しました。
コルーチンの本質は実際にはユーザーモード スレッドです。ここで新しい概念が登場します。ユーザー モードとは何ですか? 現在市販されているすべてのCPU命令セットは実はレベル分けされており、一般的にリング0~リング3の4つのレベルに分かれており、リング0に近づくほどCPU命令の権限が大きくなり、できることが増えます。しかし、それに応じて不安のリスクも高くなります。このことから、ユーザー モードとカーネル モードが実際には完全に分離されていることがわかります。
したがって、現在のオペレーティング システムはユーザー モードとカーネル モードに分かれています。Linux を例にとると、ring0 はカーネル モード、ring3 はユーザー モードです。私たちが日々開発しているプログラムはすべてユーザー モード プログラムです。ユーザー モード プログラムでは、コンピューターの機能のごく一部しか操作できません。IO の読み取りと書き込み、メモリの割り当て、さまざまなハードウェアの相互作用など、ほとんどの機能が操作できます。 、などはカーネルプログラムによって実行されます。
この時、何人かの学生は「おい、それは違う、私のコードはファイルを読み取ったり、画面上にさまざまな情報を書き込んだりすることもできるのではないか?」と尋ねたに違いありません。そんなことがあるものか?
これらの機能は、実際にはユーザーモードのプログラムからカーネルモードのプログラムに各種システムコールを送信することで実現されます。システム コールを送信すると、ユーザー モードからカーネル モードへのコンテキスト スイッチがトリガーされ、パフォーマンスの低下も発生します。
昨年、インターネット上で Alibaba の 2 面面接の質問があり、「RocketMQ と Kafka はなぜそれほど速いのか?」という質問がありました。実際、RocketMQ と Kafka は両方とも、IO 操作を実行するときに Linux でゼロコピー テクノロジ mmap を使用するため、システム コールの切り替えによって発生するメモリ コピーは、データの読み取りおよび書き込みプロセス中に削減されますが、同じものにマッピングされます。メモリ領域を増やし、高速化を実現します。この問題に興味のある学生は、mmap が何であるかを確認してください。
したがって、スレッドの概念が登場する前に、ユーザーモードスレッドの概念がすでに登場していました。つまり、ユーザーモードプログラムは内部でマルチスレッドスケジューリングをシミュレートし、オペレーティングシステムは対応するプロセスをスケジュールするだけで、スレッドのスケジューリングは認識しません。スレッドとコルーチンによってもたらされる直接的な利点は、TCB を作成する必要がないことであり 、スレッド作成時に対応するメモリ オーバーヘッドを節約できることです。
しかし、このように考えると、コルーチンは古いボトルに新しいワインを入れる Docker のような別のテクノロジーなのでしょうか? 本当にありません。
初期のユーザー モード スレッドにはパフォーマンス上の利点がありますが、システムの中断を認識できないという問題はまだ解決できません。現在のオペレーティング システムはプリエンプティブであることがわかっており、オペレーティング システムはデフォルトで優先度の高いプログラムの実行を優先します。優先度の低いプログラムが現在スケジュールされている場合、オペレーティング システムは優先度の高いプログラムを実行できるようにするために割り込みをトリガーします。 -優先プログラムがそれをプリエンプトします。プリエンプションは、オペレーティング システムがシステム割り込みを送信することによって実現されますが、オペレーティング システムはコルーチンの存在を認識できないため、コルーチン自体はプリエンプトされた割り込みイベントを処理できません。さらに、ユーザー モード スレッドが IO 操作を実行すると、オペレーティング システムはスレッド全体をブロックし、IO を呼び出さない対応するコルーチンもブロックされます。最後に、オペレーティング システムのスケジューリング単位がプロセスであるため、毎回コルーチンに割り当てられるタイム スライスが少なくなり、CPU の計算能力も解決すべき問題になります。また、これらの問題のため、各オペレーティング システムが独自のシステム レベルのスレッドをさらに導入します。
3.ゴルーチン
Goroutine は実際には、上記の一般的なコルーチンの問題を解決するために Go によって作成された高レベルのカプセル化です。
Go の作者である Rob Pike は、Goroutine を次のように説明しています。Goroutine は、同じアドレス空間内の他の Goroutine と並行して実行される Go 関数またはメソッドです。実行中のプログラムは 1 つ以上のゴルーチンで構成されます。スレッド、コルーチン、プロセスなどとは異なります。ゴルーチンです。
前のセクションで説明した初期のコルーチンの場合、基本モデルとスレッドのマッチング モデルはN:1です。つまり、1 つのスレッドが同時に複数のコルーチンを維持する必要があります。このような構造モデルでは、上記の問題を解決することはできない。このため、Goでは言語上でGMモデルを提供しています(その後徐々にGMPモデルへと進化していきます) 一般的にはユーザーモードのスレッドであるGoroutine(G)とリアルスレッドMachine(M)をN化することです。 :M モデル、次のように図に示すように:

Goroutine がシステム スレッドにアタッチされて実行されていることがわかります。これらは Go Runtime によって統一的に管理されるため、実際には Go の核となるのはそのランタイムであり、Goroutine の作成と破棄を統一的に管理し、メモリ管理を含めて Goroutine へのメモリの割り当てやシステム コールへの応答などを均一に行います。 、プロセス管理、デバイス管理の主要機能であり、実際のオペレーティング システムにはそのような機能しかありません。go ランタイムはすでに小さなオペレーティング システムであると言えます。
Github には Baidu の Go エンジニアである偉人がいて、彼は Go で小さなオペレーティング システムの Eggos を書き、それをオペレーティング システムのないベアメタル マシンにインストールすることに成功し、その中でスーパー マリオもプレイできます。興味のある学生は学習して理解することができますが、このようなことを .net プラットフォームで達成するのはほぼ不可能です。

上の図は、Goroutine の初期 (Go1.2 バージョン) Go スケジューリング モデルです。プログラム内で新しく作成されたゴルーチンは、実際には最初にグローバル キューに追加され、その後プログラムの実際の実行者 M がこのキューからスケジュールされるゴルーチンを引き出して実行します。実行中の Goroutine が IO などのシステム スケジューリングをトリガーすると、ランタイムはそれをグローバル キューに戻します。同様に、実行中の Goroutine 内に新しい Goroutine が作成されると、その Goroutine もスケジュール用のグローバル キューに入れられます。さらに、ランタイムはこれらの実行中のゴルーチンを監視する監視スレッドも開始し、指定されたタイム スライスを超えると、これらのゴルーチンはグローバル キューに戻されます。
GM モデルには実際には多くの問題があることがわかります。たとえば、グローバル ロックの均一な使用、ゴルーチンのスケジューリングがグローバル キューに依存していること、プログラムの実行プログラムとゴルーチンの間に強い依存関係がないことなどが挙げられます。局所性の原則を満たさない場合 M や拡張子のメモリ割り当てなど したがって、Go チームは後の段階でプロセッサを追加して GMP モデルにさらに進化し、興味のある学生は GMP モデルの理解を学ぶことができます。
要約すると、スレッドと比較して、Goroutine には次の利点があります。
- 初期リソースが非常に少ない。Goroutine の作成コストは、スレッドの 1 ~ 8MB からデフォルトの 2KB に直接削減されます。TCB を作成する必要がないため、Goroutine は、TCB の場所を記録するプログラム カウンターへのポインターを作成するだけで済みます。現在実行中の関数スタック。
- コンテキスト切り替えのオーバーヘッドはほとんどありません。Goroutine は GoRuntime によってスケジュールされ、スケジューリングのオーバーヘッドは完全にエンキューとデキューの操作であり、コンテキストを切り替える必要はありません。スレッドの 3.5us と比較すると、Goroutine のスイッチング オーバーヘッドは約 100ns です。
- 実行中のスレッドはブロックされません。Goroutine がシステム コールを発行すると、ランタイムによって M から直接転送され、対応する M が新しい Goroutine プログラムを実行し続けるため、スレッドの使用率が大幅に向上します。
同時に、IO 多重化テクノロジとランタイム スケジューリングと組み合わせることで、初期のコルーチンのいくつかの深刻な問題が解決され、インターネット時代から抜け出すことに成功し、さまざまな主要なファクトリや基礎となるコンポーネントの主要言語になりました。
4.トークが安い
さて、Goroutine のさまざまな利点を理解したところで、最後に Go の同時プログラミング モデルがどのように実装されているかを見てみましょう。
func say(s string) {
for i := 0; i < 5; i++ {
time.Sleep(100 \* time.Millisecond)
fmt.Println(s)
}
}
func sayHello() {
go say("hello")
say("world")
}
以下は、Go の公式ドキュメントの Goroutine セクションからの例です。Goroutine を実行する構文は非常に単純で、必要なgo キーワードは1 つだけであることがわかります。上記の例では、最終的には「hello world」が出力されます。C# の伝染性とは異なり、Go コードは非同期で実装されているかどうかは外部からはまったく見えないため、開発者に対する心理的プレッシャーが軽減されます。
C# によって設計された複雑なasync/awaitモデルは、実際には、非同期メソッドのコールバックを取得するのが難しいという問題を解決するためのものであることがわかっています。したがって、非同期ステート マシンの結果を監視し、最終的に非同期スレッドのコンテキストで結果を返すために await キーワードが追加されます。しかし、Go には await がないので、コンテキスト同期を行うにはどうすればよいでしょうか?
func calN(n int, ch chan<- int) {
// 模拟复杂的N计算
time.Sleep(time.Second)
// 返回结果
ch <- n \ n
}
func main() {
ch := make(chan int, 1)
go calN(12345, ch)
select {
case ans := <-ch: {
fmt.Printf("answer is: %d", ans)
}
default {
time.Sleep(time.Millisecond \ 100)
}
}
}
ここでようやく最後のキーワード select と最後の参照型 chan を学びました。
ちゃん
まず chan について話しましょう. Chan はチャンネルを意味し、複数のゴルーチンがデータを送信するためのチャネルです. その機能は C# の Pipe に似ており、同時に実行される複数のゴルーチンに穴を掘ってデータを送信することに相当します。
ポインタと同様に、 chan は参照型で、 make() 関数によって初期化され、2 番目のパラメータはチャネルのサイズです。チャネルは実際には両端のキューであり、複数のゴルーチンがチャネルにデータを読み書きできることがわかります。チャネル バッファーがいっぱいになると、チャネルに書き込むゴルーチンはブロックされます。
チャネルに書き込むための構文は非常に単純です。矢印記号 <- (左矢印は 1 種類のみで、右矢印はないことに注意してください)、ch<- はチャネルへのデータの書き込みを意味し、<-ch はデータの読み取りを意味します。チャンネルから。
選択する
select キーワードをもう一度見てください。ここでの select は、実際には Linux オペレーティング システムの IO 多重化テクノロジの命令であり、その目的は、非同期イベントを受信したときに各イベントの結果をポーリングすることです。
Go は言語レベルで select 関数を実装しており、その機能は Linux の関数と似ており、現在の goroutine をブロックして chan の戻りを待ちます。
通常、select は case およびdefault とともに使用されます。使用法は switch-case ステートメントと似ており、満たされたものがトリガーされます。上記のコードでは、select キーワードを使用してチャネル内のデータを読み取ると、最初にcaN 関数が返されていないため、main のゴルーチンはデフォルトに入り、100 ミリ秒スリープします。次に、特定の場合に return などのステートメントが存在するまで、前の操作を再度ループします。
複数のケースが同時に満たされた場合、Go Runtime は実行するケースをランダムに選択します。通常、Goroutine のタイムアウトは、次のコードのようなタイムアウト関数を記述することで実装されます。
func makeNum(ch chan<- int) {
time.Sleep(5 * time.Second)
ch <- 10
}
func timeout(ch chan<- int) {
time.Sleep(3 time.Second)
ch <- 0
}
func chanBlock() {
ch := make(chan int, 1)
timeoutCh := make(chan int, 1)
go makeNum(ch)
go timeout(timeoutCh)
select {
case <-ch:
fmt.Println(ch)
case <-timeoutCh:
fmt.Println("timeout")
}
}
生産者・消費者モデル
さて、Goroutine のプログラミング スタイルをよりよく理解するために、最後に Goroutine を使用して、オペレーティング システムの同期相互排他問題における古典的な生産者/消費者モデルを実装してみましょう。
// 需求:创建生产者消费者模型,其中生产者和消费者分别是N和M个
// 生产者每隔一段时间生产X产品,消费者同样也每隔一段时间消费Y产品
// 生产者如果将产品容器填满应该被阻塞,多次阻塞之后将会退出
// 每个消费者需要消费满Z个产品才能退出,否则就要一直消费产品
const (
ProducerCount = 3 // 生产者数量
ConsumerCount = 5 // 消费者数量
FullCount = 15 // 消费者需求数量,消费者吃够了应该回家
TimeFactor = 5 // 时间间隔因子,每生产/消费一个产品,需要休息一段时间
QuitTimes = 3 // 生产者退出次数,如果生产者阻塞了多次,则会下班
SleepFactor = 3 // 睡眠时间因子,如果生产者被阻塞应该睡眠一段时间
)
var (
waitGroup = sync.WaitGroup{
}
)
func producer(n int, ch chan<- int) {
defer waitGroup.Done()
times := createFactor()
asleepTimes := 0
for true {
p := createFactor()
select {
case ch <- p:
{
t := time.Duration(times) \ time.Second
fmt.Printf("Producer: %d produced a %d, then will sleep %d s\\n", n, p, times)
time.Sleep(t)
}
default:
{
time.Sleep(time.Second \ SleepFactor)
asleepTimes++
fmt.Println("I need consumers!")
if asleepTimes == QuitTimes {
fmt.Printf("Producer %d will go home\\n", n)
return
}
}
}
}
}
func consumer(n int, ch chan int) {
waitGroup.Done()
s := make([]int, 0, FullCount)
times := createFactor()
for len(s) < FullCount {
select {
case c := <-ch:
{
s = append(s, c)
fmt.Printf("Consumer: %d consume a %d, remains %d, then will sleep %d s\\n", n, c, FullCount-len(s), times)
time.Sleep(time.Duration(times) \ time.Second)
}
default:
{
fmt.Println("Producers need to hurry up, I'm hungry!")
time.Sleep(time.Second \ SleepFactor)
}
}
}
fmt.Printf("Consumer: %d already full\\n", n)
}
func createFactor() int {
times := 0
for times == 0 {
times = rand.Intn(TimeFactor)
}
return times
}
func main() {
rand.Seed(time.Now().UnixNano())
ch := make(chan int, FullCount)
waitGroup.Add(ProducerCount)
for i := 0; i \< ProducerCount; i++ {
go producer(i, ch)
}
waitGroup.Add(ConsumerCount)
for i := 0; i \< ConsumerCount; i++ {
go consumer(i, ch)
}
waitGroup.Wait()
}
ここでは、Goroutine の別の一般的なパッケージ同期が使用されています。上記の例では、WaitGroup が使用されています。その目的は、すべての goroutine の実行が完了するのを待つために使用される C# の Task.WaitAll に似ています。基本的にセマフォに基づいて実装されているため、ゴルーチンを作成するたびにAdd関数を実行する必要があることがわかります。
最後に、コードの各行を自分で実装したToy-Webを提供します。この手作業で練習する小さなプロジェクトを完了するには、多大な努力が必要でした。本当に自分で実装したい場合は、アルゴリズムのスキルが少し必要です。たとえば、ルーティングにはトライ ツリーを使用する必要があります。ワイルドカードのマッチングには BFS の知識が必要です。ルーティング ノードの拡張が必要な場合は、バックトラックするアルゴリズムが必要です。つまり、超高層ビルが地面からそびえ立っています、さあ、新しいゴーファーの皆さん、私たち全員の明るい未来を祈っています。
拡張リンク:
Spring Boot フレームワークでの Excel サーバー側のインポートとエクスポートの実装
Project Combat: オンライン見積調達システム (React +SpreadJS+Echarts)
SpreadJS と組み合わせた洗練されたフレームワークにより、純粋なフロントエンド Excel オンライン レポート デザインを実現