私はLoadrunnerに慣れている人です。Loadrunnerは重すぎてクラウドにデプロイして使用するには不便なので、この点で通常Jmeterを選択します。Jmeterのオープンソースと軽量が私のお気に入りの場所ですが、Jmeterのスクリプト開発モードは私の最も嫌いな部分です:jmxスクリプトに対応するXML形式は直感的でなく、保守と管理に不便であり、コードのデバッグは不便です(スクリプトの記録に依存したくない私たちにとって、これは非常に(重要)、私が気に入らないもう1つの点は、Jmeterのパフォーマンスと安定性です。非GUI +分散ストレステストモードを使用しても、マスターノードの許容範囲はLoadrunnerほど良くありません。
そのため、Loadrunnerのような高性能と高い安定性、無料のコード保守と管理だけでなく、Jmeterのような軽量で高いスケーラビリティも備えたテストツールを見つける傾向があります。現在、そのようなツールはないようですが、ガトリングというパフォーマンステストツールがあります。分析してJmeterと比較しました。大きな可能性があると思います。いつか、Jmeterの利点のいくつかを利用できるようになるでしょう。リクエスト、またはJmeterはそれから学び、変革を起こすことができます。
インターネット上のガトリングには多くの利点があり、私はあまり言いませんが、テストシナリオの構成に関しては、ガトリングはLoadrunnerを失うことはありません。例を挙げて説明します。
setUp(
scn.inject(
nothingFor(4 seconds)、//シーン1
atOnceUsers(10)、//シーン2
ランプユーザー(10)over(5秒)、//シーン3
ConstantUsersPerSec(20)during(15秒)、/ /シーン4constantUsersPerSec
(20)during(15秒)ランダム化//シーン
5rampUsersPerSec(10)から(20)中(10分)//シーン
6rampUsersPerSec(10)から(20)中(10分)ランダム化、//シーン7
splitUsers(100)into(rampUsers(10)over(10秒))separatedBy(10秒)、//シーン8
splitUsers(100)into(rampUsers(10)over(10秒))separatedBy(atOnceUsers (30))、//シーン9
heavisideUsers(100)over(20秒)//シーン10
).protocols(httpConf)
)
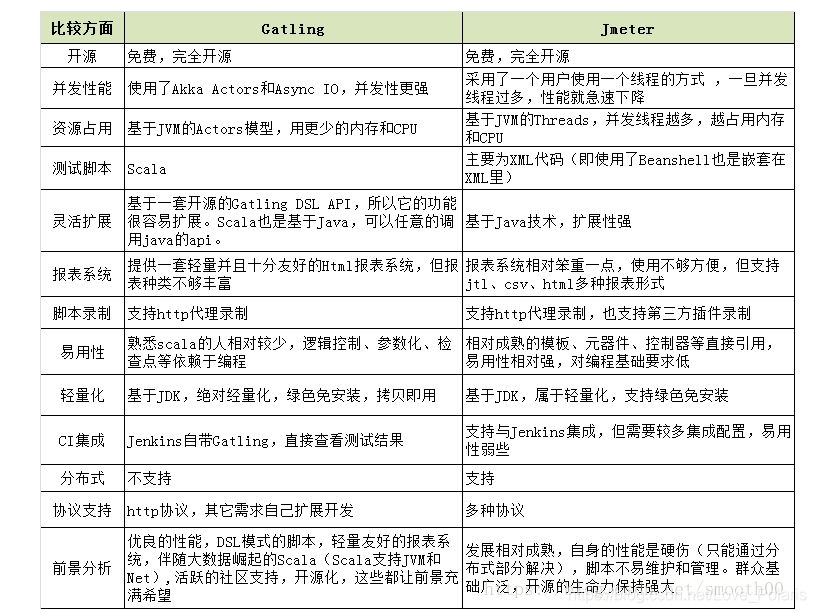
上記のコードには10個のシーンの例が含まれています。
- noneFor(4秒)
指定した時間(4秒)は何もしません - atOnceUsers(10)一度に
シミュレートされたユーザーの数(10)。 - rpmUsers(10)over(5秒)
指定された期間(5秒)内に、ユーザー数を指定された数(10)まで徐々に増やします。 - constantUsersPerSec(10)during(20 seconds)
固定速度でユーザーをシミュレートし、1秒あたりにシミュレートされるユーザー数(10)を指定し、シミュレーションテストの長さ(20秒)を指定します。 - ランダム化
されたconstantUsersPerSec(10)は、固定速度でユーザーをシミュレートし、1秒あたりにシミュレートされるユーザー数(10)を指定し、シミュレーション期間(20秒)を指定します。ユーザー数はランダムにシミュレートされます(ミリ秒レベル)。
指定された時間(20秒)内の(20秒)の間にrampUsersPerSec(10)から(20)に、一定の速度で1秒あたりにシミュレートされるユーザーの数を1(10)から2(20)に徐々に増やします。
指定された時間(20秒)内にランダム化された(20秒)中のrampUsersPerSec(10)から(20)は、ランダムな速度で1秒あたりにシミュレートされるユーザーの数を1(10)から2(20)に増やします。- splitUsers(100)into(rampUsers(10)over(10秒))separatedBy(10秒)
は、定義されたシミュレーションステップ(rampUsers(10)over(10秒))を繰り返し実行し、毎回指定された時間(10秒)一時停止します)合計が指定された数(100)に達するまで - splitUsers(100)into(rampUsers(10)over(10 seconds))separatedBy(atOnceUsers(30))
は、定義されたシミュレーションステップ1(rampUsers(10)over(10 seconds))とシミュレーションステップ2(atOnceUsers(30))を繰り返し実行します。 )合計が指定された数(100)程度に達するまで - heavisideUsers(100)over(10秒)
同様の単位ステップ関数法を使用して、指定された時間(10秒)内にシミュレートされた同時ユーザーを徐々に増やし、合計数が指定された数(100)に達するまで続けます。秒数が増えています。
シナリオ8を例にとると、波状の圧力を作成できます。これは、以下に示すように、パルス圧力テストまたは特定のタイプの安定性テスト(圧力は山と谷に応じて規則的に分布します)のシミュレーションに非常に適しています。 :
ガトリングは非常に驚きですが、今のところ最善の選択にはほど遠いですが、それを研究する必要があります。結局のところ、優れたツールの普及は1日か2日ではありません。Jmeterには不十分な場所がたくさんありますが、引き続き使用する必要があります。スクリプトのメンテナンスのしやすさは最も重要な問題ではありません。最も緊急の問題は、Jmeterの負担を軽減して安定した超高水準を実現する方法です。同時テスト。次の方法を検討できます。
負担を軽減し、監視を最適化します(GUIモード、考慮しないでください)
1。「結果ツリーを表示する」、「エラーのみをログに記録する」をチェックする必要があります。これにより、エラーログのみがメモリに保存され、データは保存されません。たくさんあります。すべてを保存すると、各リクエスト情報と関連情報が保存され、これらのデータがjvmメモリに保存され、常駐データを復元できなくなり、数万のリクエストがすぐにjmeterを圧倒します。
2.中小規模(100以内)の「集計レポート」を保持できます。高い同時実行性を削除し、「Simple Data Writer」を追加して、csv形式のデータを保存します。「集計レポート」はCPUを非常に消費します。
3.他のすべての監視コンポーネントを削除できます。テスト後、保存した結果を使用して、オフラインでグラフレポートを生成できます。
負担を軽減し、監視を最適化します(非GUIコマンドラインモード)
1。「結果ツリーを表示」、「エラーのみをログに記録」をチェックする必要があり、パスを設定し、エラー情報をファイルに保存し、すべてを保存する必要があります情報([構成]をクリックし、[CSV以外のすべてのオプション]をオンにします)
2。[レポートの集計]コマンドラインが無効です。3
。他の監視コンポーネントを削除できます。基本的に、非GUIでは無効です。
負担軽減3、結果ファイルの最適化
- 結果データはCSV形式で保存する必要があります(xml形式と比較すると、各データははるかに少なくなります)(非GUIコマンドを使用して保存するcsvログを指定できます)
2。に保存されたエラー情報「結果ツリーの表示」はxmlとして保存する必要があります。エラー分析を容易にするために、完全な結果情報を保存してください。
負担の軽減4、超高並行性が必要な場合は、分散ストレステストを直接使用しないことをお勧めします
- jmeterの分散展開は問題を軽減するだけで、根本的に問題を解決するわけではありません。マスターマシンは、同時実行性が高い場合は大きなプレッシャーに耐え、単一のポイントを形成し、同時実行性が高い場合は安定した負荷を提供できません。
- データが書き込まれ、失われる可能性があります
- 解決策:スレーブを手動で実行するか、jenkinsを使用して複数のスレーブを同時にトリガーする必要があります
負担を5つ減らします。また、非GUIコマンドラインモードで実行することをお勧めします。また、Jmeterを実行するにはLinux環境を選択する必要があります。
- 非GUIを使用してjmeterを実行してcsvレポートを生成しますが、htmlレポートは出力しません(完了するには高いjvmメモリが必要なため、2つのステップに分かれています)
- jmeterのjvmメモリを変更し(物理メモリの半分を推奨、HEAPのxmsとxmx、2Gxmxサイズに対応するために1Gcsvレポートを推奨)、高いjvmメモリを使用してcsvレポートをhtmlレポートに変換します(変換するマシンを変更します)メモリが十分でない場合のレポート)
負担軽減6、レポートファイル生成の代わりにJmeter + Grafana + InfluxDBを使用することを選択できます。他の記事「Jmeter長期圧力テストに関する視覚的モニタリングレポート」を参照してください。
- Jmeter分散クラスターを分散化すると、マスターノードはテストデータの収集と処理を担当しなくなり、スレーブノードのスケジューリングのみを担当します。
- 複数のマスタースレーブをサポートして、マルチチャネルJmeterテストクラスターを形成します(Jenkinsまたは他のスケジューリングツールを使用して、スケジューリングテストを同時にトリガーします)
オリジナル:https://blog.csdn.net/smooth00/article/details/80014622