序文
しばらく前に、著者はHDFSの大規模ディレクトリ削除のパフォーマンスの問題について投げかけ、INodeDirectlyの内部子リスト構造の変更やスナップショットレベルの改善と最適化など、大規模ディレクトリ削除のパフォーマンスへの影響を減らすためのさまざまなソリューションを試しました。 (詳細については、この記事:HDFSラージディレクトリファイル削除プログラムの実用的な考え方を参照してください)。しかし、HDFSの削除操作と新世代のストレージオゾンシステム内の削除操作を比較したところ、両者にはまだ多くの違いがあり、後者の方が設計が大幅に改善されていることがわかりました。この記事の著者は、HDFSとオゾンの削除操作の比較、およびHDFSの既存の削除操作に関するいくつかのブレインストーミングの考えについて説明します。
既存のHDFS削除操作のパフォーマンスの問題
この昔ながらの質問に戻る-HDFS削除操作のパフォーマンスの問題。これは、2つの簡単な言葉で簡単に要約できます。最初の操作は重いもので、2番目の操作が最も大きな影響を及ぼします。
プロセスは簡単に次のとおりです。
- 1)ディレクトリツリー構造を再帰的にトラバースし、クリアする必要のあるINodeインスタンス(INodeディレクトリとINodeファイルを含む)、およびINodeFileの下のブロックブロック、つまり削除するブロックを収集します。
- 2)次に、ブロックのバッチ削除操作を実行します。各バッチが処理された後、途中でロックが解除され、ロックが処理されます。
上記のプロセスはNameNodeメタデータの変更を伴うため、FSNグローバルロックを保持したまま実行されるため、このプロセスは非常に重くなります。
次の図は、HDFS内部データ削除プロセスの簡単な概略図です。
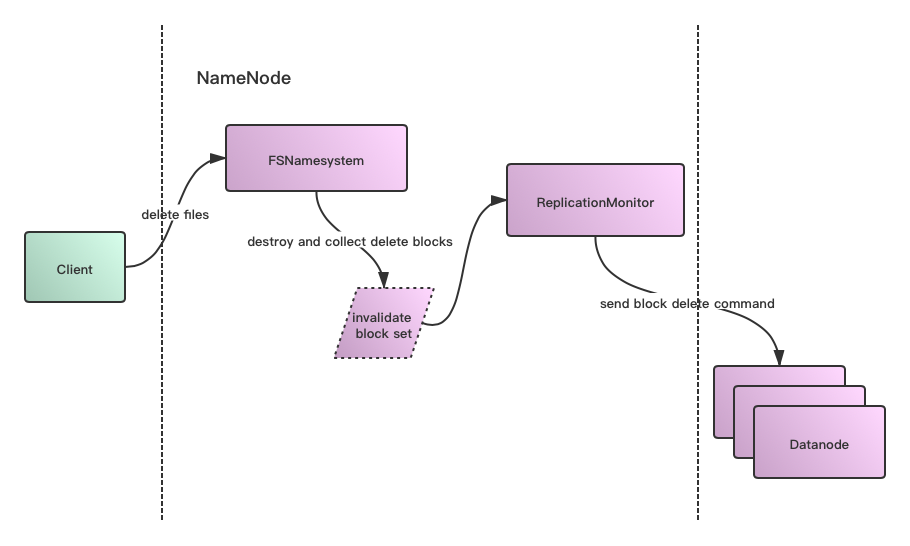
上記のプロセスでは、途中で削除するデータブロックの情報を照会した後、それを永続化せず、すべてプロセスで実行するため、自然な最適化ポイントは次のようになります。
このプロセスを非同期にすることはできますか?さらに、ディレクトリのこの1回限りのクリーンアップ方法を、複数のバッチ削除動作に変換できますか?RemoveBlockはすでにバッチ処理されていますが、INodeをクリーンアップするときに、トラバースする方法ではなく、バッチ処理することもできますか?
さて、上記の提案の出発点はすべて良いですが、上記の改善を達成するには、次の問題を解決する必要があります。
- 削除操作は非同期で処理されます。HDFSは、クォータが解放される前にINodeのみが実際にクリーンアップされていると見なします。ここでクォータの一貫性を確保するにはどうすればよいですか?もちろん、より少ない血液の割り当て精度を犠牲にして非同期削除を許可する場合、それも許容されます。
- INodeディレクトリツリーで削除された場合はバッチ処理され、特定のINodeが削除された場合は終了して終了します。次に復元するにはどうすればよいですか?一部の子INodeに親INodeインスタンスがない場合があります。中断されたINodeのバッチはダーティデータになり、NameNodeに存在します。もう1つの質問は、INodeが削除の途中で終了することです。別の同時操作が、削除されたディレクトリの読み取りと書き込みを行っている可能性はありますか?
HDFS削除操作の改善アイデアをブレインストーミングする
前節で述べた厄介な問題を考えると、解決できないのでしょうか。いいえ、常に実行可能な解決策があります。
まず、クォータの不整合の問題です。上記によれば、削除操作の非同期化を行うために、クォータのリアルタイムの精度を少し犠牲にすることができます。このトレードオフはまだ問題ないと思います。
次に、2番目のINode削除バッチ処理に関して、要約すると2つの小さな問題があります。
- 中間INode出口処理の回復の問題。INodeの削除数が途中でしきい値に達した後、ロックを解放するために処理を強制的に終了すると、実際にいくつかの問題が発生します。ただし、これに変換することはできます。最初にこの電話番号を再帰的にトラバースし、すべてのINodeインスタンスのみを収集して、リスト構造に格納します。次に、INodeリストのバッチ削除操作処理を実行します。元のディレクトリツリーで削除操作の中断を復元することは困難です。
- 2番目の小さな問題は、削除操作がバッチによって中断および解放された瞬間に、削除されるディレクトリが読み書きされる可能性があることです。この処理方法は比較的簡単です。バッチ削除INodeの開始時に、最初に削除するディレクトリファイルの名前を予約済みの名前に変更します。この名前は、.trashなどの既存のディレクトリ形式など、ユーザーがアクセスすることはありません。簡単に言うと、最初に名前を変更してから削除します。
上記の処理により、バックグラウンドスレッドを再開して、カタログファイルの非同期バッチ処理を正式に実行できます。新しい処理プロセス図は次のように想像されます。
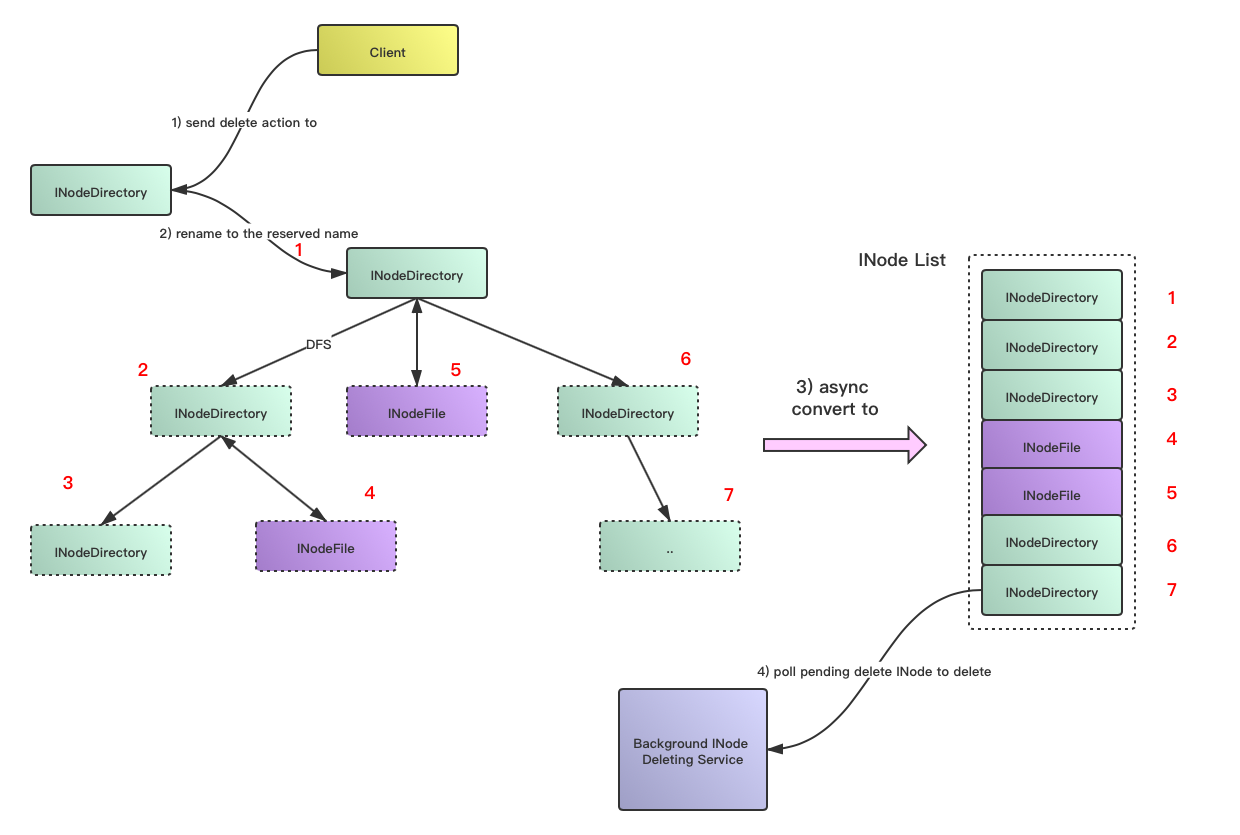
実際、上の図に示されているプロセスと現在のHDFSゴミ箱データクリーンアップメカニズムは非常に近いです。ゴミ箱メカニズムは、予約名への名前変更とバックグラウンド削除の2つの段階を満たしています。改善できる唯一のことは、NameNodeの削除操作方法を直接調整するのではなく、バッチプロセスとしてINodeを削除することです。著者の個人的なより積極的な考えは、HDFSの削除操作を単純な名前変更操作に変えることができ、実際の操作動作はすべて、バックグラウンドで特別なサービスによって非同期的に処理される必要があるというものです。特に分散ストレージシステムでは、クライアントが削除動作の同期実行の完了を強制する必要はありません。
関連設計:オゾンシステムでの削除操作処理
この領域の別のオブジェクトストレージシステムオゾンの設計を見てみましょう。
まず、オゾンはストレージシステムとしても使用されており、大量のデータが削除される状況にも直面しています。ただし、その名前付けは比較的単純で、すべてKVであり、現在、ディレクトリツリーの削除状況はありません。したがって、その削除動作はバッチ処理が簡単であり、キーのバッチをバッチで削除することができます。
また、予約名への名前変更+バックグラウンド削除スレッドモデルの処理方法を使用しています。オゾンの現在の削除プロセス図は次のとおりです。

上の図は、オゾンの内部削除プロセスがHDFSよりも少し複雑であることを示しています。背景の理由:
- Ozoneは、HDFSのような完全に統合された管理ではなく、OMSCMサービスの対話型通信を含むコンテナベースのストレージを内部的に使用します。
- Ozoneは、純粋なメモリではなく、サードパーティのKV dbストレージを使用するため、削除された情報の永続処理を実行できるため、システムの再起動時に削除された動作を簡単に復元できます。
さらに、OMおよびSCMサービス内では、削除が実行されるたびにデータのバッチを削除する制限があるため、削除動作全体がオゾンシステムに与える影響はわずかです。
オゾンの削除メカニズムとHDFSの既存の削除動作を比較すると、前者は後者よりもスケーラビリティとパフォーマンスの点で優れており、後者は処理設計が単純であるため、ボリュームが大きい場合に明らかになります。欠点。オゾンとHDFSの削除の原則に関心のある学生は、著者が書いた関連記事を引き続き読むことができます。リンクは記事の最後にあります。
関連記事
[1]、https://blog.csdn.net/Androidlushangderen/article/details/105778885
[2] .https://blog.csdn.net/Androidlushangderen/article/details/77619513