1。概要
Sparkは、インメモリコンピューティングに基づく汎用のビッグデータ並列コンピューティングフレームワークであり、バッチ処理、ストリーム処理、機械学習、グラフ処理などのさまざまな組み込みコンポーネントを備えています。Hiveは、SQLのようなコマンドクエリをサポートするHadoopベースのデータウェアハウスであり、Hadoopの使いやすさを向上させます。Sparkは通常HiveおよびHadoopと組み合わせて使用され、Hiveのデータパーティショニングを使用してデータを簡単に管理およびフィルタリングし、クエリの効率を向上させることができます。
DolphinDBは、C ++で記述された高性能の分散時系列データベースです。高スループット、低レイテンシのカラムメモリエンジンが組み込まれています。強力なプログラミング言語を統合し、PythonやSQLなどのスクリプト言語をサポートしています。データベースで複雑なプログラミングやプログラミングを直接実行できます。操作。DolphinDBは、データソースを内部的に使用してパーティションデータを抽象化します。データソースでは、SQL、機械学習、バッチ処理、ストリーム処理などのコンピューティングタスクを完了できます。データソースは、組み込みのデータベースパーティションまたは外部データのいずれかです。データソースが組み込みデータベースのパーティションである場合、ほとんどの計算はローカルで実行できるため、計算とクエリの効率が大幅に向上します。
このレポートでは、DolphinDB、HDFSに直接アクセスするSpark(Spark + Hadoop、以下、Sparkと呼びます)、およびHiveコンポーネントを介してHDFSにアクセスするSpark(Spark + Hive + Hadoop、以下、Spark + Hiveと呼びます)のパフォーマンス比較テストを実施します。テストの内容には、データのインポート、ディスクスペースの占有、データクエリ、およびマルチユーザー同時クエリが含まれます。比較テストを通じて、パフォーマンスに影響を与える主な要因と、さまざまなツールの最適なアプリケーションシナリオをより深く理解できます。
2.環境構成
2.1ハードウェア構成
このテストでは、まったく同じ構成の2つのサーバー(マシン1、マシン2)を使用し、構成パラメーターは次のとおりです。
ホスト:DELL PowerEdge R730xd
CPU:Intel Xeon(R)CPU E5-2650 v4(24コア48スレッド2.20GHz)
メモリ:512 GB(32GB×16、2666 MHz)
ハードディスク:17T HDD(1.7T×10、222 MB / s読み取り、210 MB / s書き込み)
ネットワーク:10ギガビットイーサネット
OS:CentOS Linuxリリース7.6.1810(コア)
2.2クラスター構成
テストされたDolphinDBのバージョンはLinuxv0.95です。テストクラスターの制御ノードはマシン1にデプロイされ、各マシンに3つのデータノードがデプロイされ、合計6つのデータノードになります。各データノードは、8つのワーカー、7つのエグゼキュータ、および24Gメモリで構成されています。
テストされたSparkバージョンは2.3.3で、Apache Hadoop2.9.0を搭載しています。HadoopとSparkは完全分散モードで構成されています。マシン1がマスターであり、マシン1と2の両方にスレーブがあります。Hiveのバージョンは1.2.2で、マシン1と2の両方にHiveがあります。メタデータは、マシン1のMySqlデータベースに保存されます。SparkおよびSpark + Hiveは、スタンドアロンモードのクライアントメソッドを使用してアプリケーションを送信します。
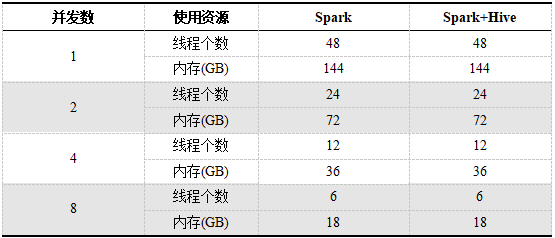
テスト中、DolphinDB、Spark、およびSpark + Hiveにはすべて6つのハードディスクが装備されており、異なる同時実行数で使用されるCPUとメモリの合計は同じで、48スレッドと144Gメモリがあります。SparkとSpark + Hiveが使用するリソースは、特定のアプリケーション専用です。各アプリケーションには6つのエグゼキュータがあります。マルチユーザー同時の場合、SparkとSpark + Hiveの1人のユーザーが使用するリソースは、ユーザー数が増えるにつれて減少します。異なる同時実行数で各ユーザーが使用するリソースを表1に示します。
表1.SparkとSpark + Hiveの同時数が異なる単一ユーザーが使用するリソース
3.データセットとデータベースの設計
3.1データセット
テストデータセットは、ニューヨーク証券取引所(NYSE)が提供するTAQデータセットです。2007.08.01から2007.08.31までの1か月間に8,000を超える株式のレベル1見積もりデータが含まれています。これには、取引時間、在庫コード、購入価格、販売価格、購入量、販売量などの見積もり情報。データセットには合計65億(6,561,693,704)の見積もりレコードがあります。1つのCSVには1つの取引日のレコードが含まれます。1か月に23の取引日があります。23の非圧縮CSVファイルは合計277GBです。
データソース:HTTPS:// WWW nyse.com/market-data/hi storical
3.2データベースの設計
表2.さまざまなシステムのTAQデータタイプ。

DolphinDBデータベースでは、日付とシンボルの列の組み合わせに従ってパーティションを作成します。最初のパーティションは値のパーティションに日付DATEを使用し、合計23のパーティションを使用し、2番目のパーティションは範囲のパーティションにストックコードSYMBOLを使用します。パーティションの数は100で、各パーティションは100です。約1億2000万。
SparkによってHDFSに保存されるデータは、23のディレクトリに対応する23csvです。Spark + Hiveは2層パーティションを使用します。第1層パーティションは静的パーティションに日付DATE列を使用し、第2層パーティションは動的パーティションにストックコードSYMBOLを使用します。
特定のスクリプトについては、付録を参照してください。
4.データのインポートとクエリのテスト
4.1データインポートテスト
元のデータは2つのサーバーの6つのハードディスクに均等に分散されるため、クラスター内のすべてのリソースを十分に活用できます。DolphinDBは、非同期マルチノード方式でデータを並列にインポートします。SparkとSpark + Hiveは、6つのアプリケーションを並列に起動して、データを読み取り、HDFSに保存します。各システムがデータをインポートする時間は、表3に示されています。各システムのデータが占めるディスク容量を表4に示します。データインポートスクリプトについては、付録を参照してください。
表3.DolphinDB、Spark、Spark + Hiveのインポートデータ時間
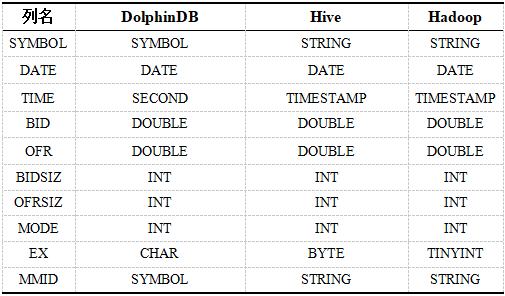
表4.DolphinDB、Spark、Spark + Hiveのデータが占めるディスク容量

DolphinDBのインポートパフォーマンスは、SparkおよびSpark + Hiveよりも大幅に優れています。これはSparkの約4倍、Spark + Hiveの約6倍です。DolphinDBはC ++で記述されており、ディスクIOを最大限に活用する多くの内部最適化があります。
DolphinDBは、SparkおよびSpark + Hiveよりも多くのディスクスペースを占有します。これは、SparkとSpark + Hiveの両方がHadoopでParquet形式を使用し、Parquet形式がデフォルトでスナッピー圧縮を使用してSparkを介してHadoopに書き込まれるためです。
4.2データクエリテスト
テストの公平性を確保するために、各クエリステートメントは複数回テストする必要があり、システムのページキャッシュ、ディレクトリアイテムキャッシュ、およびハードディスクキャッシュは、各テストの前にLinuxシステムコマンドを介してそれぞれクリアされます。DolphinDBは、組み込みのキャッシュもクリアします。
表5のクエリステートメントは、グループ化、並べ替え、条件、集計計算、ポイントクエリ、さまざまなユーザー数でのDolphinDB、Spark、Spark + Hiveのパフォーマンスを評価するための完全なテーブルクエリなど、ほとんどのクエリシナリオをカバーしています。
表5.DolphinDB、Spark、Spark + Hiveクエリステートメント

4.2.1DolphinDBおよびSparkシングルユーザークエリテスト
以下は、DolphinDBとSparkのシングルユーザークエリの結果です。結果の時間は、8つのクエリの平均時間です。
表6.DolphinDB、Sparkシングルユーザークエリの結果
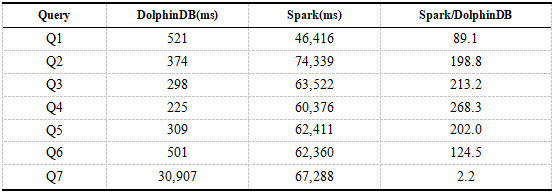
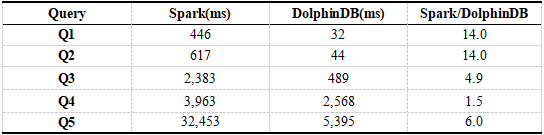
結果から、DolphinDBのクエリパフォーマンスはSpark + HDFSの約200倍であることがわかります。クエリQ1からQ6はすべて、フィルタ条件としてDolphinDBのパーティションフィールドに基づいています。DolphinDBは、フルテーブルスキャンなしで指定されたパーティションのデータをロードするだけで済みます。SparkはQ1からQ6までのフルテーブルスキャンを必要とし、これには多くの時間がかかります。クエリQ7の場合、DolphinDBとSparkの両方でテーブル全体のスキャンが必要ですが、DolphinDBはすべての列ではなく関連する列のみをロードし、Sparkはすべてのデータをロードする必要があります。クエリランタイムはデータの読み込みが支配的であるため、DolphinDBとSparkの間のパフォーマンスギャップは前のクエリステートメントほど大きくありません。
4.2.2DolphinDBおよびSpark + Hiveシングルユーザークエリテスト
DolphinDBのデータはパーティション化されており、クエリ中に述語がプッシュダウンされるため、効率はSparkよりも大幅に高くなります。ここでは、Spark with Hiveコンポーネントを使用してHDFSにアクセスし、DolphinDBとSpark + Hiveのクエリパフォーマンスを比較します。以下は、DolphinDBおよびSpark + Hiveシングルユーザークエリの結果です。結果の時間は、8つのクエリの平均時間です。
表7.DolphinDB、Spark + Hiveシングルユーザークエリの結果
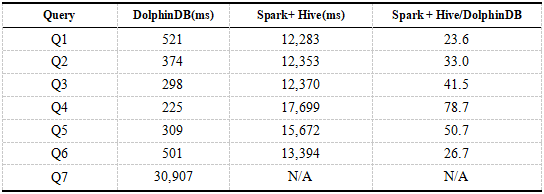
結果は、DolphinDBのクエリパフォーマンスがSpark + Hiveよりも大幅に優れていることを示しています。Spark+ HiveはSpark + Hiveの数十倍です。表6の結果と比較すると、Spark + Hiveのクエリ速度はSparkよりもはるかに高速であり、DolphinDBの利点は大幅に低下しています。これは、Hiveがデータをパーティション分割し、クエリステートメントの条件にパーティションフィールドが含まれている場合にデータの一部のみがロードされるためです。これにより、データフィルタリングが実現され、効率が向上します。クエリステートメントQ7がテーブル全体をスキャンすると、メモリオーバーフローが発生します。
DolphinDBとSpark + Hiveはどちらもデータを分割し、データのロード時に述語のプッシュダウンを実現してデータフィルタリングの効果を実現できますが、DolphinDBのクエリ速度はSpark + Hiveよりも優れています。これは、Spark + Hive領域が異なるシステム間のアクセスを介してHDFS上のデータを読み取るためです。データは、シリアル化、ネットワーク送信、および逆シリアル化のプロセスを経る必要があり、これは非常に時間がかかり、パフォーマンスに影響します。DolphinDBの計算のほとんどはローカルで行われるため、データ送信が減り、より効率的になります。
4.2.3DolphinDBとSparkの計算能力の比較
上記のDolphinDBのクエリパフォーマンスは、SparkおよびSpark + Hiveと比較されます。クエリ中のデータ分割、データフィルタリング、および送信はSparkのパフォーマンスに影響するため、ここでは、最初にデータをメモリにロードしてから、関連する計算を実行し、DolphinDBを比較します。そしてSpark + Hive。Hiveはデータフィルタリングにのみ使用されるため、Spark + Hiveを省略しました。HDFSでデータを読み取る方が効率的です。ここでのテストデータは、すでにメモリにあります。
表8は、計算能力をテストするための文です。各テストには2つのステートメントが含まれ、最初のステートメントはデータをメモリにロードすることであり、2番目のステートメントはメモリ内のデータを計算することです。DolphinDBはデータを自動的にキャッシュし、Sparkはデフォルトのキャッシュメカニズムを介して一時テーブルTmpTblを再作成します。
表8.DolphinDBとSparkの計算能力の比較
以下は、DolphinDBとSparkの計算能力のテスト結果です。結果の時間は、5回のテストの平均時間です。
表9.DolphinDBおよびSparkコンピューティングパワーテストの結果
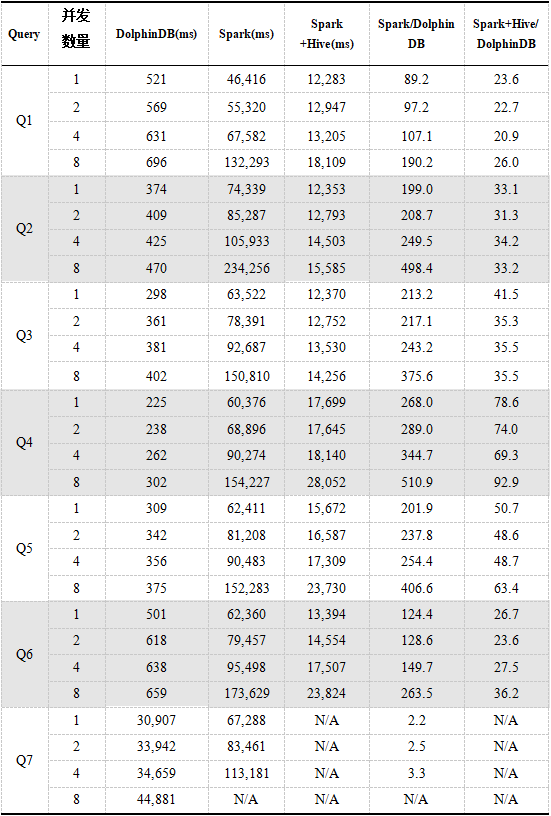
表6と比較して、データはすでにメモリ内にあるため、Sparkの使用時間は大幅に短縮されていますが、DolphinDBの計算能力はSparkの計算能力よりも優れています。DolphinDBはC ++で記述されており、メモリを単独で管理します。これは、JVMを使用してメモリを管理するSparkよりも効率的です。さらに、DolphinDBには、コンピューティングパフォーマンスを向上させるためのより効率的なアルゴリズムが組み込まれています。
DolphinDBの分散コンピューティングは、パーティションを1つの単位として使用して、指定されたメモリ内のデータを計算します。Sparkはブロック全体をHDFSにロードします。データブロックには異なるシンボル値のデータが含まれます。キャッシュされますが、フィルタリングする必要があるため、Q1とQ2の比率が大きくなります。Sparkの計算で使用されるブロードキャスト変数は、圧縮されて他のエグゼキュータに送信され、パフォーマンスに影響を与えるために解凍されます。
4.2.4マルチユーザー同時クエリ
表5のクエリステートメントを使用して、マルチユーザー同時クエリのDolphinDB、Spark、およびSpark + Hiveをテストします。テスト結果は以下のとおりです。結果の時間は8回のクエリの平均時間です。
表10.DolphinDB、Spark、Spark + Hiveマルチユーザー同時クエリの結果
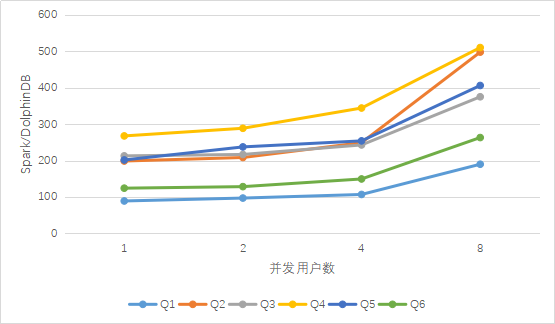
図1.DolphinDBとSparkのマルチユーザークエリ結果の比較

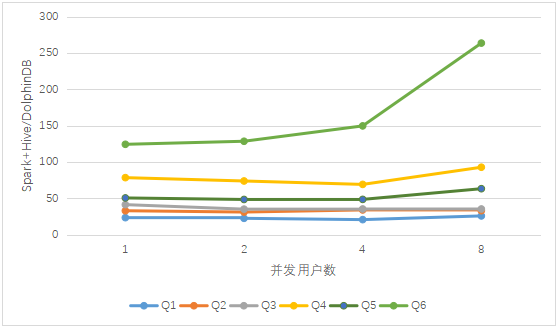
図2.DolphinDBとSpark + Hiveのマルチユーザークエリ結果の比較
上記の結果からわかるように、同時実行数が増えると、3つのクエリ時間は徐々に増加します。同時ユーザー数が8人に達すると、Sparkのパフォーマンスは、以前の少数の同時ユーザーの場合と比較して大幅に低下します。Sparkは、Q7の実行時にワーカーを停止させます。Spark + Hiveは、複数のユーザーがアクセスした場合、基本的にDolphinDBのように安定していますが、Q7クエリステートメントが実行されると、メモリオーバーフロー例外が常に発生します。
Spark + Hiveのクエリ構成はSparkと同じですが、パーティショニング機能があり、データをフィルタリングできるため、クエリデータ量が比較的少なく、Sparkが全データをスキャンするよりも効率が良くなります。
同時クエリでのDolphinDBのパフォーマンスは、SparkおよびSpark + Hiveよりも大幅に優れています。上の図から、複数のユーザーによる同時アクセスの場合、ユーザー数が増えると、Sparkに対するDolphinDBの利点は、Spark +と比較してほぼ直線的に増加することがわかります。 Hiveの利点は基本的に変更されていません。これは、クエリ時にデータフィルタリングを実現するためのデータパーティショニングの重要性を反映しています。
DolphinDBは、Sparkのデータが特定のアプリケーション専用であるのとは異なり、マルチユーザー同時実行の場合にマルチユーザーデータ共有を実現します。したがって、8人の同時ユーザーの場合、Sparkは各ユーザーに割り当てるリソースが少なくなり、パフォーマンスが大幅に低下します。DolphinDBのデータ共有により、リソースの使用を減らすことができます。リソースが限られているため、ユーザーが計算して使用するために予約されるリソースが増えるため、ユーザーの同時実行の効率が向上し、同時にユーザーの数が増えます。
5.まとめ
データのインポートに関しては、DolphinDBを並行してロードできますが、SparkとSpark + Hiveは、複数のアプリケーションを同時にロードしてデータをインポートできます。DolphinDBのインポート速度は、SparkおよびSpark + Hiveの4〜6倍です。ディスクスペースに関しては、DolphinDBが占有するディスクスペースは、Hadoop上のSparkおよびSpark + Hiveが占有するディスクスペースの約2倍です。SparkおよびSpark + Hiveは、スナップ圧縮を使用します。
データSQLクエリに関して、DolphinDBにはより明白な利点があります。利点は主に、(1)ローカライズされたコンピューティング、(2)パーティションフィルタリング、(3)最適化されたメモリコンピューティング、(4)クロスセッションデータ共有の4つの側面からもたらされます。シングルユーザークエリの場合、DolphinDBのクエリ速度はSparkの数倍から数百倍、Spark + Hiveの数十倍です。Spark Reading HDFSは、データのシリアル化、ネットワーク、および逆シリアル化を含む、異なるシステム間の呼び出しであり、非常に時間がかかり、多くのリソースを占有します。DolphinDBのSQLクエリのほとんどはローカライズされた計算であるため、データの送信と読み込みにかかる時間が大幅に短縮されます。Spark + HiveはSparkよりも比較的高速です。主な理由は、Spark + Hiveが関連するパーティション内のデータのみをスキャンし、データフィルタリングを実現するためです。ローカリゼーションとパーティションフィルタリングの要素を取り除いた後(つまり、すべてのデータがすでにメモリにある)、DolphinDBの計算能力はSparkよりも数倍優れています。DolphinDBのパーティションベースの分散コンピューティングは非常に効率的であり、そのメモリ管理はSparkのJVMベースの管理よりも優れています。Sparkのマルチユーザー同時実行性は、ユーザー数が増えるにつれて効率が徐々に低下します。大量のデータをクエリする場合、ユーザーが多すぎるとワーカーが死亡します。Spark + Hiveのマルチユーザー同時実行性は比較的安定していますが、データが多すぎるとメモリオーバーフローエラーが発生します。複数のユーザーの場合、DolphinDBはデータを共有できるため、データのロードに使用されるリソースを削減できます。クエリ速度は、Sparkの数百倍、Spark + Hiveの数十倍です。ユーザー数が増えると、Sparkに対するDolphinDBのパフォーマンス上の利点がより明白になります。パーティション化されたクエリの場合、Spark + HiveとDolphinDBはクエリのパフォーマンスを大幅に向上させます。
Sparkは、SQLクエリ、バッチ処理、ストリーム処理、およびマシン学習で優れたパフォーマンスを発揮する、優れた汎用分散コンピューティングエンジンです。ただし、SQLクエリは通常、データを1回だけ計算する必要があるため、機械学習に必要な数百回の反復と比較して、メモリコンピューティングの利点を完全に実現することはできません。したがって、計算量の多い機械学習にはSparkを使用することをお勧めします。
テスト中に、DolphinDBは非常に軽量な実装であり、クラスターはシンプルで高速に構築でき、Spark + Hive + Hadoopクラスターのインストールと構成は非常に複雑であることがわかりました。
付録
付録1.データプレビュー
付録2.Hive CreateTableステートメント
CREATE TABLE IF NOT EXISTS TAQ(time TIMESTAMP、bid DOUBLE、ofr DOUBLE、bidsiz INT、ofrsiz INT、mode INT、ex TINYINT、mmid STRING)PARTITIONED BY(date DATE、symbol STRING)STORED AS PARQUET;
付録3。
DolphinDBインポートデータスクリプト:
fps1とfps2は、それぞれマシン1と2のすべてのcsvパスのベクトル
を
表します
。fpsはfps1とfps2を含むベクトルです。allSites1とallSites2は、マシン1と2のデータノード名のベクトルを表します。allSiteは、allSites1とallSites2を含むベクトルです。DATE_RANGE
= 2007.07 .01..2007.09.01
date_schema = database( ''、VALUE、DATE_RANGE)
symbol_schema = database( ''、RANGE、buckets)
db = database(FP_DB、COMPO、[date_schema、symbol_schema])
taq = db.createPartitionedTable(schema 、 `taq、` date`symbol)
for(i in 0..1){
for(j in 0 ..(size(fps [i])-1)){
rpc(allSites [i] [j]%size (allSite [i])]、submitJob、 "loadData"、 "loadData"、loadTextEx {database(FP_DB)、 "taq"、 `date`symbol、fps [i] [j]})
}
}
SparkとHiveのインポートデータ構成:
--master local [8] --executor-memory 24G