論文のアドレス: http://papers.nips.cc/paper/7358-kdgan-knowledge-distillation-with-generative-adversarial-networks.pdf
github アドレス: https://github.com/xiaojiew1/KDGAN/
モチベーション
軽量な分類器を訓練する場合、少ないサンプル数と訓練時間で知識の蒸留は収束しますが、教師から実際のデータ分布(実データ)を学習することは困難であり、GAN を通じて分類器を分類する方法もあります。トレーニングはデータの真の分布を学習しますが、分散が大きい勾配更新のため平衡に達するまでに長い時間がかかります。上記の制限を解決するために、本論文は、分類器 (学生ネット)、教師ネット、および識別器から構成される KDGAN のフレームワークを提案します。分類器と教師は蒸留損失を通じて相互に学習し、分類器は敵対的損失を通じて敵対的にトレーニングされます。
方法
この記事では、研究を実行するための例としてマルチラベル分類タスクを取り上げます。KDGANのフレームワークを図に示します。KD における教師ネットから分類器までの蒸留損失と NaGAN (naive gan) における分類器と識別器の間の対立損失に加えて、著者は分類器から教師ネットまでおよび教師間の蒸留損失も定義します。ネットとディスクリミネーター、敵対的な損失。つまり、分類器と教師ネットの両方が生成器として使用され、生成されたラベルは識別器によって偽と見なされます。同時に、分類器と教師ネットは、どのような疑似ラベルを生成するかについて合意するために、ソフトラベルを相互に抽出することによって互いの知識を学習します。

KDGAN のトレーニングを高速化するために、一方で、著者は経験的に、教師の勾配から分類器が受け取る勾配の分散は弁別器の勾配の分散よりも小さいため、加重平均は小さくなると考えています。 GAN トレーニングの元の勾配分散よりも大きいため、迅速に収束できます。一方で、分類器と教師によって生成された離散サンプルは微分できないため、著者はガンベルマックス手法を使用して離散サンプルの分布を連続分布に変換します。したがって、勾配値を渡すことができます。
モデルの具体的なアルゴリズム ステップは次のとおりです。そのうち 3 つの部分は事前トレーニングする必要があり、その後、3 つの部分は各エポックで数回更新されます。

実験
KD 損失: L2loss、KL Divergence
実験数: 10
アプリケーション シナリオ: モデル圧縮、画像ラベルの推奨
データセット: MNIST、CIFAR-10、YFCC100M
結果
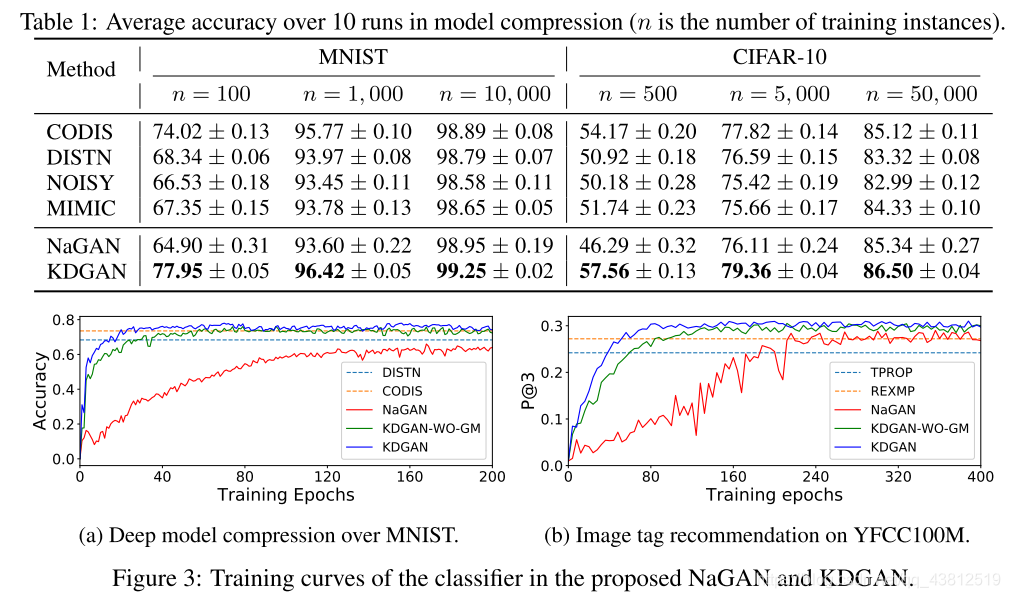
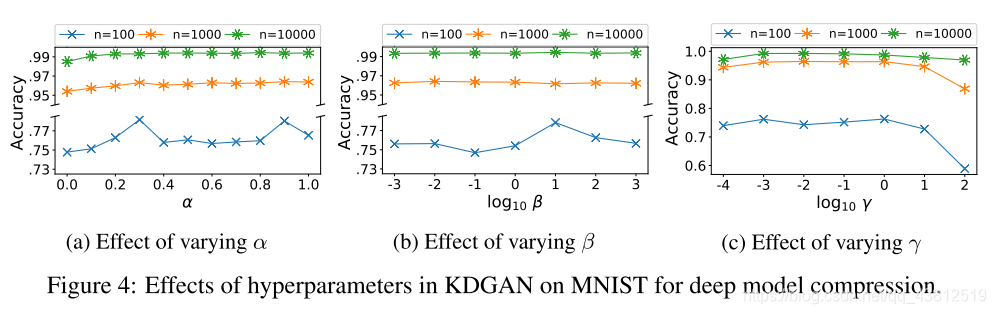
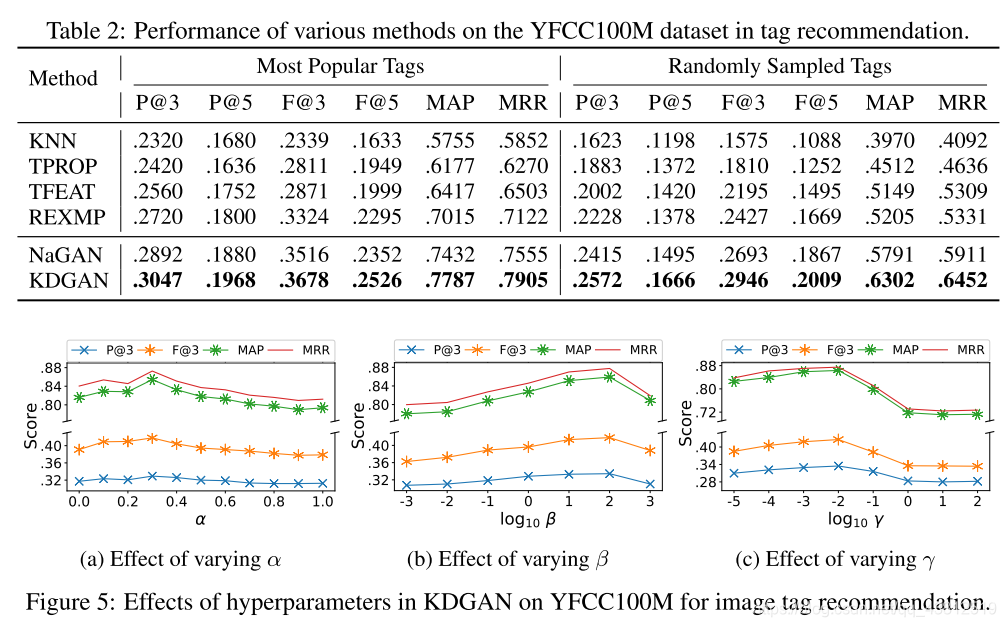
思い
私が想像していた KDGAN と同じではないので、再現する必要があります。