1.サポートベクターマシン(SVM)
サポートベクターマシンは、線形または非線形の分類、回帰、さらには異常値検出タスクを実行できる強力で包括的な機械学習モデルです。SVMは、中小規模の複雑なデータセットの分類に特に適しています。
機械とは?ベクトルとは何ですか?サポートとは何ですか?機械とはアルゴリズムを意味します。歴史的な理由からそれを呼び出さないでください。ベクトルはベクトルであり、分類を行う場合、各サンプルはベクトルで表されます。サポートとは、支持して決定することを意味します。分類を行うと、通常、分類超平面(2つの緯度の場合は線)が見つかり、超平面側が正のクラス側と負のクラスになります。サポートベクトルとは、この分類超平面を決定するベクトルです。したがって、サポートベクターマシンは次のように理解できます:これは分類アルゴリズムであり、このアルゴリズムはサポートベクトルによって決定される超平面によって分類されます。
SVMモデルには2つの非常に重要なパラメーターCとガンマがあります。ここで、Cはペナルティ係数であり、エラーの許容範囲です。cが高いほど、エラーは許容できなくなり、オーバーフィットしやすくなります。Cが小さいほど、許容誤差が大きくなり、適合しやすくなります。
ガンマは、カーネルとしてRBF関数に付属するパラメーターです。新しい特徴空間にマッピングした後、データの分布を暗黙的に決定します。ガンマが大きいほど、サポートベクトルは少なくなり、ガンマ値が小さいほど、サポートベクトルは多くなります。サポートベクターの数は、トレーニングと予測の速度に影響します。
1.1線形SVM分類
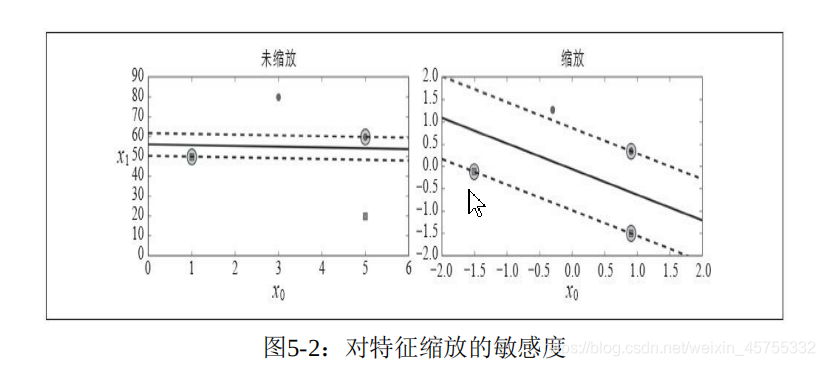
SVMは、機能のスケーリングに非常に敏感です。ロジスティック回帰分類器とは異なり、SVM分類器は各カテゴリの確率を出力しません。図5-2に示すように、左の図では、垂直方向のスケールが水平方向のスケールよりもはるかに大きいため、できるだけ広い通りが水平に近くなっています。機能のスケーリング後(たとえば、Scikit-LearnのStandardScalerを使用)、決定境界ははるかに良く見えます(右を参照)。
ソフトインターバル分類:
すべてのインスタンスが路上および右側に配置されないようにする場合、これはハードパーティション分類です。ハード間隔分類には、主に2つの問題があります。1つ目は、データが線形分離可能である場合にのみ有効です。2つ目は、外れ値に非常に敏感です。
これらの問題を回避するには、より柔軟なモデルを使用することをお勧めします。目標は、通りを広く保つことと間隔違反(つまり、通りにある、または間違った側にあるインスタンス)をできるだけ制限することの間の適切なバランスを見つけることです。これはソフト間隔分類です。
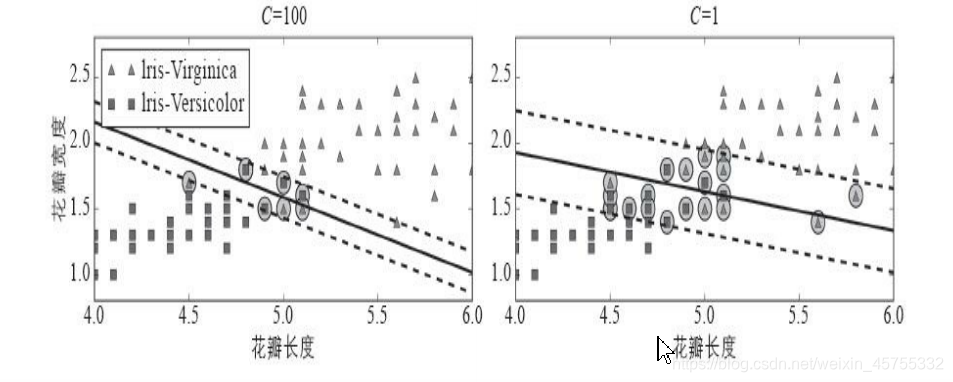
ハイパーパラメータCはこのバランスを制御できます。Cの値が小さいほど、通りは広くなりますが、間隔違反は多くなります。過剰適合の場合、cの値を減らして正則化できます。
1.2非線形SVM分類
非線形データセットを処理する1つの方法は、多項式機能などの機能を追加することです。これにより、データセットが線形的に分離可能になる場合があります。process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NTc1NTMzMg==,size_16,color_FFFFFF,t_70)
多項式カーネル
多項式機能の追加は実装が非常に簡単で、すべての機械学習アルゴリズムに非常に効果的です。ただし、多項式が低次である場合、非常に複雑なデータセットを処理できず、高次では多数のフィーチャが作成され、モデルの速度が低下します。
カーネル技法の結果は、非常に高次の多項式の特徴でさえ、多くの多項式の特徴を追加することと同じですが、実際に追加する必要はありません。実際に追加される機能はないため、大量に爆発する組み合わせ機能はありません。この手法は、SVCクラスによって実装されます。
同様の機能を追加する
非線形問題を解決するもう1つの方法は、同様の機能を追加することです。これらの特徴は、各インスタンスと特定のランドマーク間の類似性を測定できる類似性関数によって計算されます。
ガウスRBFカーネル関数
カーネル関数の機能:完全に分離不可能な問題を分離可能またはほぼ分離可能な状態に変換します。
(ガウス)放射基底関数カーネル(英語:放射基底関数カーネル)、またはRBFカーネルは、一般的に使用されるカーネル関数です。これは、サポートベクターマシン分類で最も一般的に使用されるカーネル関数です。

ランドマークは2つあります。最初は0、0です。
つの座標からの距離が1と2であるため、その新しい機能は次のとおりです。
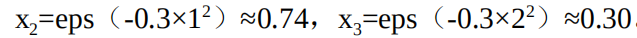
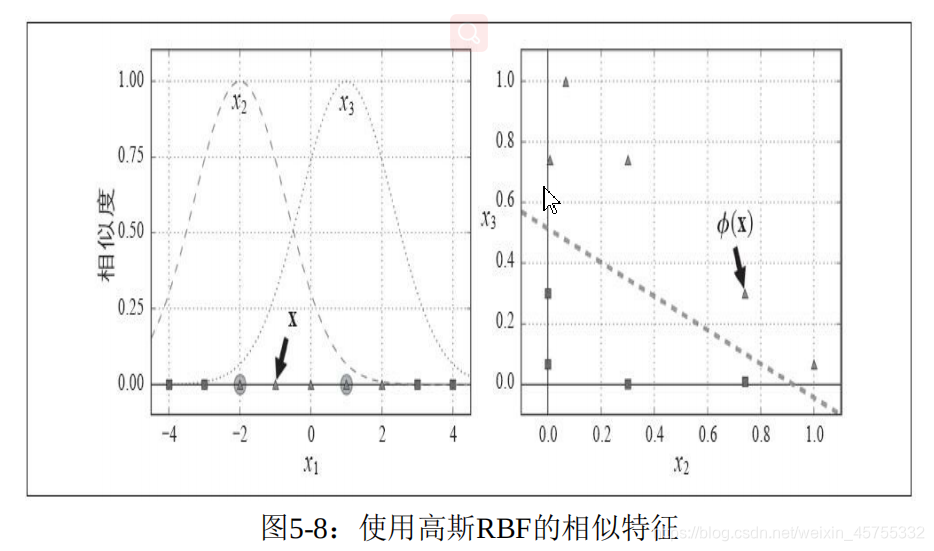
ランドマークを選択する最も簡単な方法は、各インスタンスの場所にランドマークを作成することですが、トレーニングセットが非常に大きい場合、非常に大きくなります。多数の機能。
計算の複雑さ
カーネル関数が非常に多いため、どの関数を使用するかをどのように決定しますか?経験持って
、常に線形カーネルで起動されたルールは(覚えているために、よりLinearSVCしようとし始めた
トレーニングセットが非常に大きいまたは非常に多くの機能で、特に、SVCは、(カーネル=「線形」)はるかに高速です)
の時間。トレーニングセットが大きすぎない場合は、Gaussian RBFカーネルを試すことができます。
これは、ほとんどの場合に非常に役立ちます。まだ時間と計算能力がある場合は、
相互検証とグリッド検索を使用して、他のいくつかのカーネル関数、特に
データセットデータ構造に固有の関数を試すことができます。


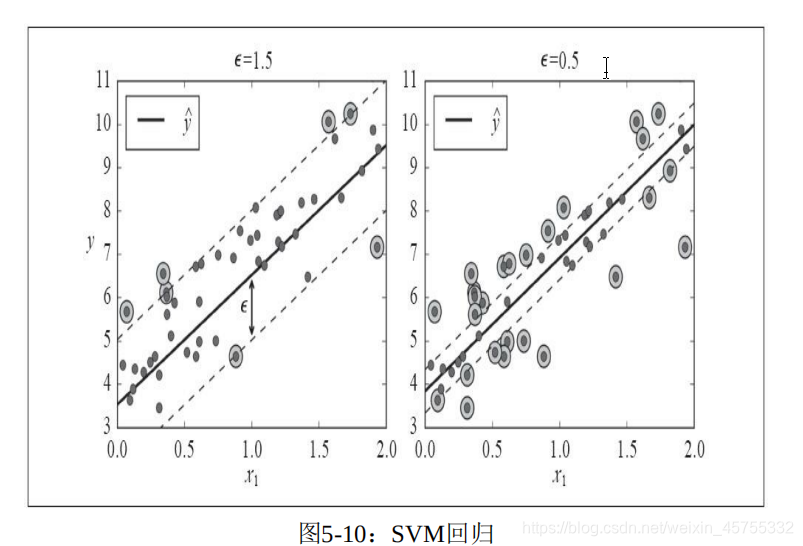
SVM回帰
SVMは、線形および非線形の分類をサポートするだけでなく、線形および非線形の回帰もサポートします。
回帰は、間隔違反を制限しながら、2つのカテゴリ間で可能な限り広い道路に適合しようとする試みではなくなりました。SVM回帰は、道路にできるだけ多くのインスタンスを配置し、間隔違反を制限する(つまり、道路ではない)ことです。例)。
間隔にインスタンスを追加してもモデルの予測には影響しないため、このモデルはε非依存と呼ばれます。
問題
1.サポートベクターマシンの基本的な考え方は何ですか?
回答:サポートベクターマシンの基本的な考え方は、カテゴリ間の可能な限り広い「ストリート」に適合させることです。言い換えると、その目的は、決定境界間の間隔を最大化して、2つのカテゴリーのトレーニング例を分離することです(逆回帰)。SVMがソフト間隔分類を実行するとき、実際には、完全な分類と最も広いストリートフィットとの間で妥協します(つまり、いくつかのインスタンスがストリートで終わることを可能にします)。非線形データセットの訓練の重要なポイントがあり、使用することを覚えてカーネル関数を。
2.サポートベクターとは何ですか?
回答:サポートベクターマシンのトレーニングが完了した後、「ストリート」上のインスタンス(前の回答を参照)はサポートベクターと呼ばれます(つまり、2行の外側にあり、戻るときに2行以内にあります)。境界上のインスタンス。決定境界は、サポートベクトルによって完全に決定されます。サポートされていないベクターインスタンス(つまり、道路の外側のインスタンス)はまったく効果がありません。常に道路の外側にある限り、それらを削除してインスタンスを追加するか、インスタンスを移動するかを選択できます。決定境界は影響しません。予測結果の計算には、トレーニングセット全体ではなく、サポートベクトルのみが含まれます。
3. SVMを使用するときに入力値をスケーリングすることが重要なのはなぜですか?
回答:サポートベクターマシンは、カテゴリ間の可能な限り広い「ストリート」に適合するため、トレーニングセットがスケーリングされていない場合、SVMは値が小さいフィーチャを無視する傾向があります(図5-2を参照)。
4.トレーニングセットに数千万のインスタンスと数百の機能がある場合、元のSVM問題または二重問題を使用してモデルをトレーニングする必要がありますか?
回答:カーネルSVMは二重問題しか使用できないため、この問題は線形サポートベクターマシンにのみ適用されます。SVM問題の場合、元の形式の計算の複雑さはトレーニング例の数に比例しますが、その二重形式の計算の複雑さはm2とm3の間の数に比例します。したがって、インスタンスの数が数百万の場合は、元の問題を使用してください。二重の問題は非常に遅くなるためです。
5. RBFカーネルを使用してSVM分類器をトレーニングするとします。γ(ガンマ)を増減する必要がありますが、トレーニングセットに十分に適合していないようです。Cはどうですか?
回答:RBFカーネルトレーニングを使用するサポートベクターマシンのトレーニングセットへの適合が不十分な場合、過度の正則化が原因である可能性があります。正規化を減らすには、ガンマまたはC(あるいはその両方)を増やす必要があります。(上部の詳細な説明を参照してください)
注
私は初心者なので、アルゴリズムのパラメーターについてはまだよくわかりません。そのため、抜粋から多くを借りてマージしているので、ここには有名なソースはありません。理解したいと思います。私は多くのコードを記述しませんでした。主に記述するとスペースが大きくなりすぎると感じたためです。また、数式に理由をあまり記述しなかったためです(重要なのは私は新入生であり、ほとんどの人が理解できないことです)。基本的な知識を簡潔に記述しました。内部アルゴリズムに従事したい場合は、この記事を元のテキストにリンクできると思います:https
://blog.csdn.net/v_JULY_v/article/details/7624837さらに、この記事は主に「機械学習の戦闘:Scikit-LearnとTensorFlowに基づく」に言及していますこの本の要望があれば(Pythonと機械学習についての情報はまだたくさんあります)、私をフォローして個人的にメールを送っていただければ、1つずつ配信されます。
結局のところ、初心者は、間違いがあった場合でも、啓発とサポートを行い、スプレーをしたくないし、志を同じくし、一緒に学ぶ友達を見つけたいと思っています。
