2-1モデルの説明
オレゴン州ポートランドの住宅価格を含むデータセットを使用します。ここでは、さまざまな家のサイズで販売された価格に基づいてデータセットを描画します。たとえば、友人の家が1,250平方フィートである場合、家がどれだけ売れるかを伝える必要があります。
このデータモデルから、友人に約220,000(USD)で家を売ることができると友達に伝えることができます。これは教師あり学習アルゴリズムの例です。

コース全体のトレーニングサンプルの数には小文字のmを使用します。
前の住宅取引問題を例にとると、下の表に示すように問題のトレーニングセット(トレーニングセット)に戻ると

この回帰問題の説明に使用するラベルは次のとおりです。
mは、トレーニングセット内のインスタンスの数を表します
xは特徴/入力変数を表します
yはターゲット変数/出力変数を表します
(x、y)はトレーニングセットのインスタンスを表します
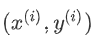 それは表し 観測例
それは表し 観測例
hは、学習アルゴリズムの解または関数を表し、仮説と呼ぶこともできます。
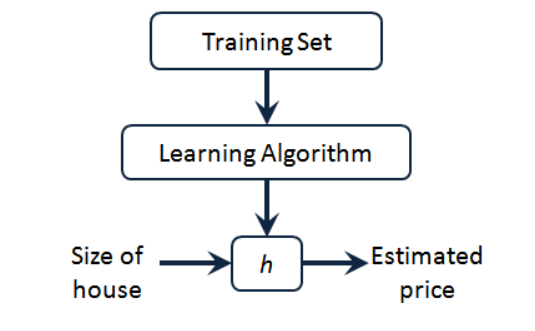
トレーニングセットに住宅価格があることがわかります。これを学習アルゴリズム、学習アルゴリズムの動作に与え、次に小文字の hで表される関数を出力します 。
仮説(仮説)、関数を表します。入力は家のサイズです。友人が売りたい家のように、h は 入力x 値に基づいてy 値を 導き出し、y 値 は家の価格に対応します。したがって、h はx からyへの 関数マッピングです。
それでは、住宅価格予測問題のhをどのように表すの でしょうか。
1つの可能な表現方法は次のとおり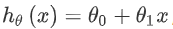 です。1つの特徴/入力変数(家の面積)のみが含まれているため、このような問題は一変量線形回帰問題と呼ばれます。
です。1つの特徴/入力変数(家の面積)のみが含まれているため、このような問題は一変量線形回帰問題と呼ばれます。
2-2コスト関数
コスト関数の概念を定義します。これは、最も可能性の高い直線をデータに適合させる方法を理解するのに役立ちます。

線形回帰では、次のようなトレーニングセットがあります。m はトレーニングサンプルの数を表します(例:m = 47)。そして、私たちの仮想関数は、予測を行うために使用される関数の形式です: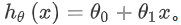
いくつかの用語を紹介します。ここで必要なことは、モデルに適切なパラメーターを選択することです 。住宅価格の問題の場合、それは直線の傾きとy 軸上の切片です。
。住宅価格の問題の場合、それは直線の傾きとy 軸上の切片です。
モデリングエラー選択するパラメーターによって、トレーニングセットに対するモデルの予測値とトレーニングセットの実際の値との間のギャップ(下図の青い線)に対する直線の精度が決まります。

私たちの目標は、二乗モデリング誤差の合計を最小化できるモデルパラメーターを選択することです。
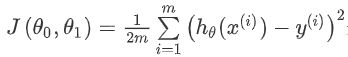
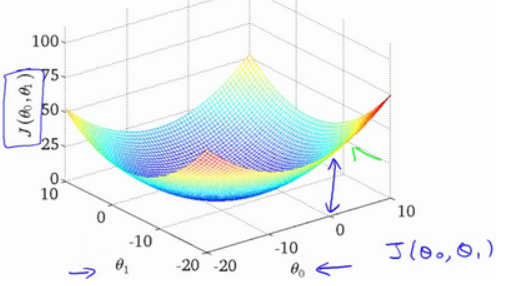
我々は、等高線図を描く、3点の座標であり、θ 0 及び θは1。及びJ(θ 0、角度θ1) :
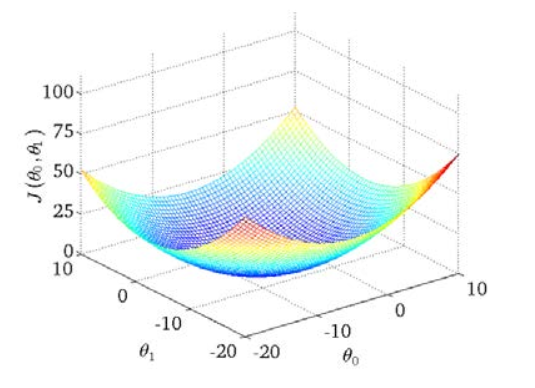
三次元空間に極小点があることがわかります。
コスト関数は二乗誤差関数とも呼ばれ、二乗誤差コスト関数と呼ばれることもあります。二乗誤差の合計が必要なのは、誤差二乗コスト関数がほとんどの問題、特に回帰問題にとって妥当な選択であるためです。
2-3コスト関数を理解する(1)
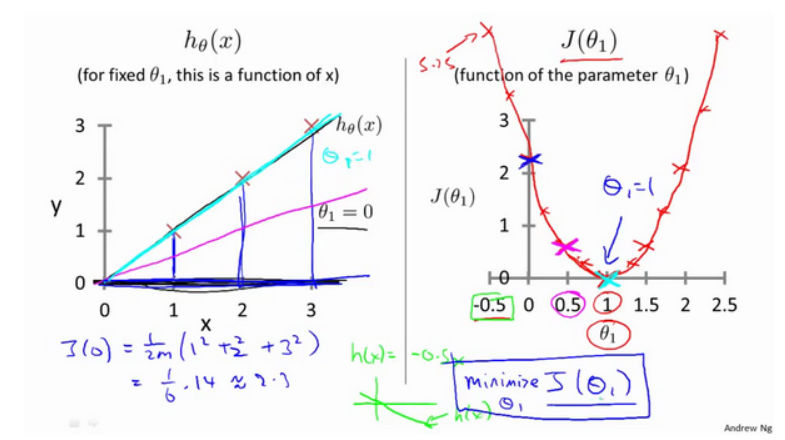
いくつかの例を通して直感的な感覚を得て、コスト関数が何をしているか見てみましょう。

私たちの次の例では、θで0分析0時間
2-4コスト関数を理解する(2)
コスト関数の外観である等高線図は、3次元空間にJ(θ0 、 θ1)を最小化する点があることを示しています。
近似する直線が図のようになっていると仮定すると、2つのパラメーターθ0 、 θ1があり、そのコスト関数は次のようになります。
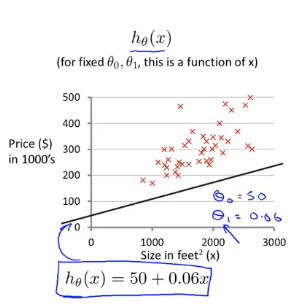
下の図は、等高線図を示しています。等高線図の各ポイントには、対応する勾配と切片があります。中心に近いほど、直線の近似が良くなります。
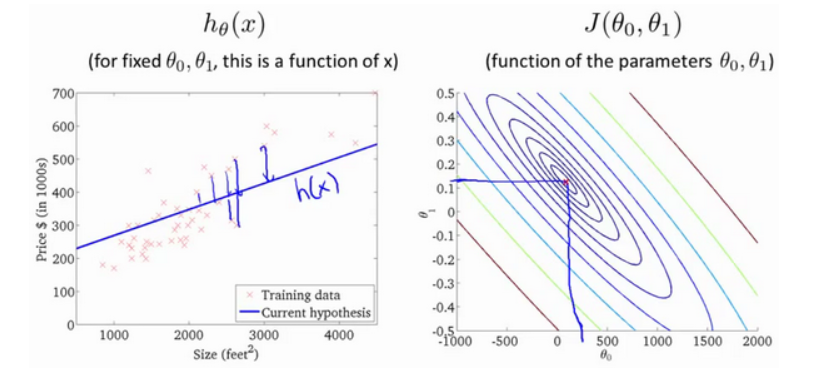
これらのグラフィックスを通じ、私はあなたがより良いコスト関数Jを理解することを願っ 近いJコスト関数に、値が仮定が何を、どのような点に対応する仮定を何であるか、彼らが対応表明 さん最小値。
2-5勾配降下
最低限の機能を見つけるために勾配降下アルゴリズムであり、我々は、コスト関数J(θ見つけるために、勾配降下アルゴリズムを使用します0、 θは。1) 最小値を。
勾配降下法の背後にある考え方は、最初にパラメーターの組み合わせをランダムに選択し、コスト関数を計算してから、コスト関数値が最も低下する次のパラメーターの組み合わせを探します。すべてのパラメーターの組み合わせを試したわけではないため、ローカルの最小値に到達するまでこれを続けます。そのため、取得するローカルの最小値がグローバルの最小値であるかどうかはわかりません。異なる初期パラメーターの組み合わせを選択すると、極小。
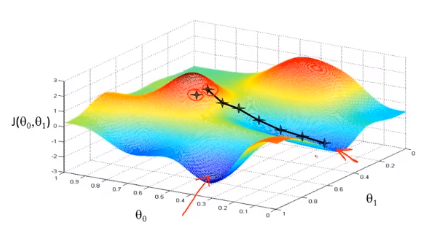
あなたが山のこの地点に立って、想像する公園の赤い山の上に立っていると想像してください。勾配降下アルゴリズムでは、360度回転させ、周りを見回して、特定の場所にいるように頼むだけです。この方向に、小さな階段で山を下ります。現地の最低ポイントに近づくまでのすべてのステップについて考えます
バッチ勾配降下アルゴリズムの式は次のとおりです。

ここで、α は学習率であり、コスト関数が最も減少する方向をいくつ下がるかを決定します。αが大きいほど、学習率が大きくなり、山を下るときの歩数が大きくなります。バッチ勾配降下法では、すべての学習パラメーターを同時に学習するたびに、学習率にコスト関数の導関数を掛けます。

勾配降下アルゴリズムでは、これは同時更新を実現する正しい方法です。
2-6勾配降下法の知識ポイントのまとめ

θ を割り当てると、J(θ) は勾配降下の最も速い方向に進み、最後まで反復して最終的に局所最小値を取得します。その中には、学習率α(学習率)があります。これは、コスト関数を最も減少させることができる方向にどれだけのステップを実行するかを決定します。
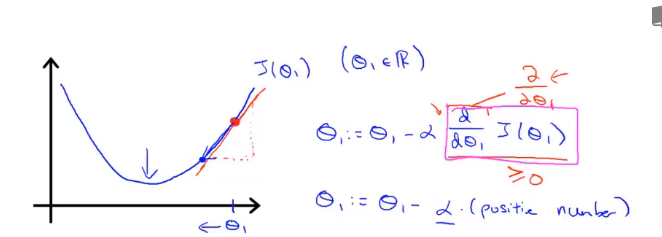
私は、新しいθを得る今、この行は、それが正の誘導体を有することを意味する正の傾きを有する1を、更新に等しいた後、θを乗じマイナス正数1 。
αが小さすぎる、または大きすぎる場合はどうなるか見てみましょう 。
αが 小さすぎる、つまり学習率が小さすぎると、赤ちゃんのように少ししか動かせず、最低点に近づこうとするため、最低点に到達するまでに多くのステップが必要になります。
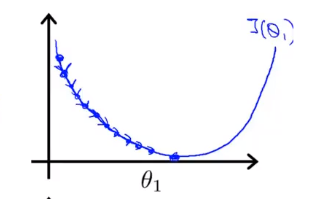
αが大きすぎる場合 、勾配降下法は最低点を横切る可能性があり、収束に失敗する可能性もあります。次の反復により、実際に最低点から離れていることがわかるまで、最低点を何度も何度も繰り返し、大きなステップが移動しました。ポイントはどんどん遠くなっているので、大きすぎると案内します
その結果、収束することも発散することもできません。

パラメーターが既にローカルの最低点にあり、勾配が0の場合、勾配降下法の更新は何も行わず、パラメーターの値は変更されません。これは、学習率α が変更されない場合でも、勾配降下が局所的な最低点に収束できる理由も説明します 。
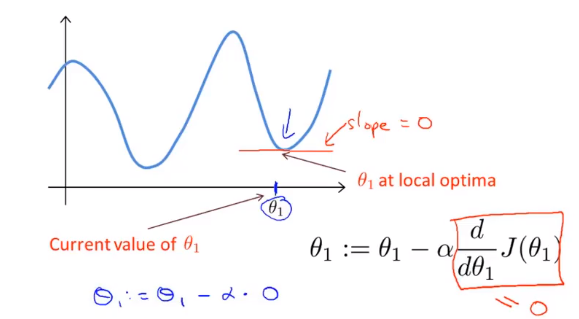
勾配降下法では、極小値に近づくと、勾配降下法は自動的に振幅が小さくなります。これは、極小値に近づくと、導関数が極小値でゼロに等しくなるため、極小値に近づくと明らかになるためです。最低点では、微分値は自動的に小さくなり、勾配降下は自動的により小さい振幅をとります。これは勾配降下の方法です。
2-7線形回帰の勾配降下
勾配降下アルゴリズムと線形回帰アルゴリズムの比較は次のとおりです。

以前の線形回帰問題に勾配降下法を適用する鍵は、コスト関数の導関数を見つけることです。
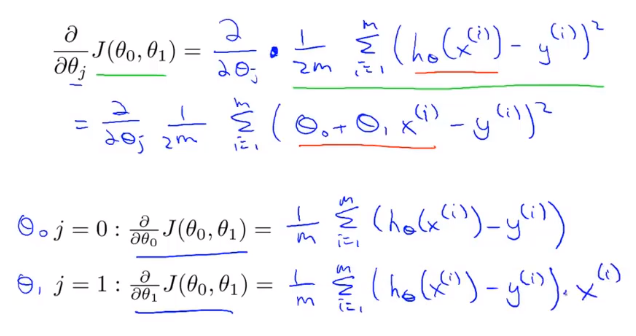
先ほど使用したアルゴリズムは、バッチ勾配降下法と呼ばれることもあります。これは、勾配降下の各ステップで、すべてのトレーニングサンプルmを使用することを意味します。勾配降下では、微分微分を計算するときに、合計演算を実行する必要があります。最後に、このようなことを計算する必要があります。このアイテムは、m個のトレーニングサンプルをすべて合計する必要があり ます。
勾配降下法をマスターしたので、勾配降下法をさまざまな環境で使用できます。また、さまざまな機械学習の問題で広範囲に使用します。