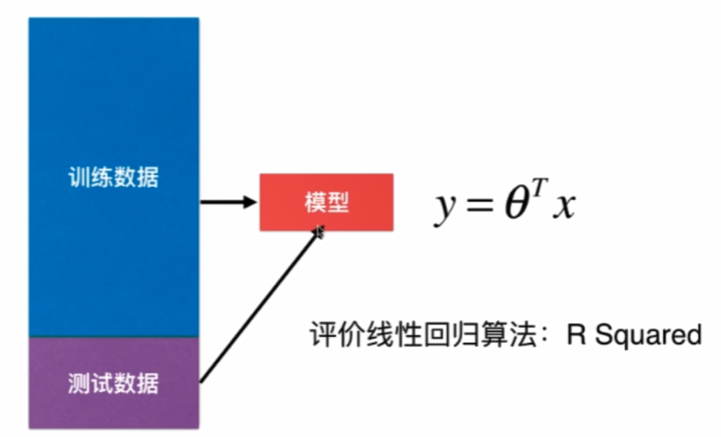
序文
実装するシンプルで簡単な思考、問題を解決するために戻り、良い結果を解釈可能で多くの強力な非線形モデルの基礎は、機械学習の多くの重要な思想が含まれています。
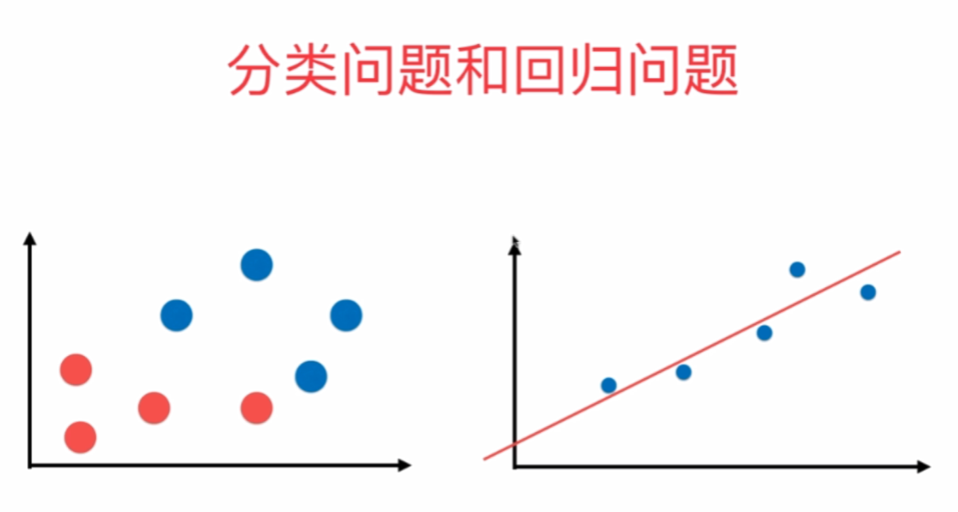
横軸は、縦軸は出力ラベル、水平分類機能は、長手方向軸、出力色フラグであるを示し、回帰問題を特徴としています。
一つだけのサンプル機能は、単純な線形回帰と呼ばれます。

X | | Y =のでどこにでもありませんので、我々は絶対的にギャップを取ることを選択し、その差を二乗しないでください。
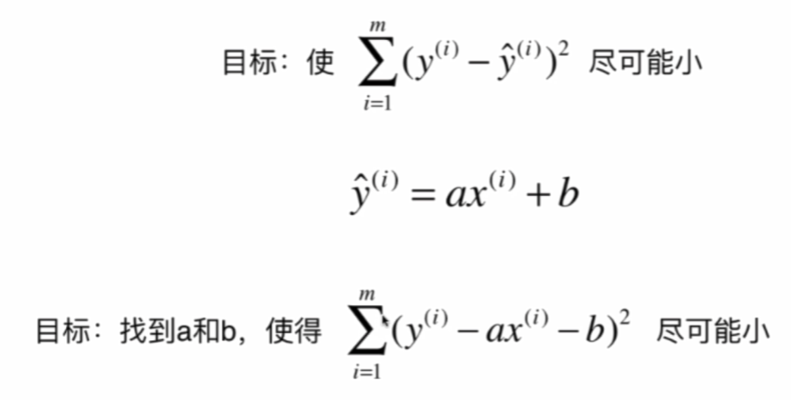
機械学習アルゴリズムのクラスの基本的な考え方:

ほとんどすべてのパラメータなどの学習アルゴリズムは、線形回帰、多項式回帰、ロジスティック回帰、SVM、ニューラルネットワークとして、ルーチンです......
ここでは代表的な最小二乗問題は、次のとおりです。二乗誤差を最小化します
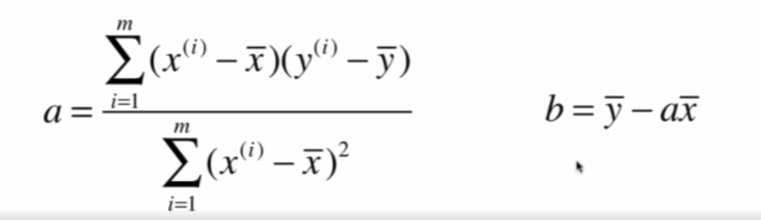
導出:
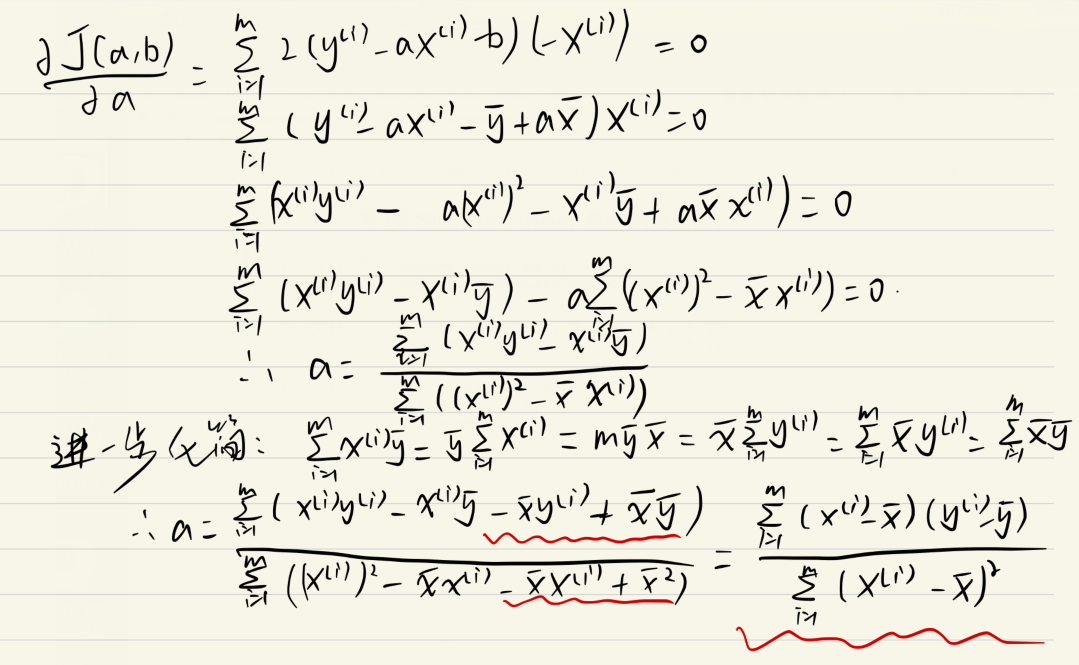
単純な線形回帰クラスの書き込み
import numpy as np
class SimpleLinearRegression1:
def __init__(self):
"""初始化Simple Linear Regression 模型"""
self.a_ = None
self.b_ = None
def fit(self, x_train, y_train):
"""根据训练数据集x_train,y_train训练Simple Linear Regression模型"""
assert x_train.ndim == 1, \
"Simple Linear Regressor can only solve single feature training data."
assert len(x_train) == len(y_train), \
"the size of x_train must be equal to the size of y_train"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = 0.0
d = 0.0
for x, y in zip(x_train, y_train):
num += (x - x_mean) * (y - y_mean)
d += (x - x_mean) ** 2
self.a_ = num / d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self, x_predict):
"""给定待预测数据集x_predict,返回表示x_predict的结果向量"""
assert x_predict.ndim == 1, \
"Simple Linear Regressor can only solve single feature training data."
assert self.a_ is not None and self.b_ is not None, \
"must fit before predict!"
return np.array([self._predict(x) for x in x_predict])
def _predict(self, x_single):
"""给定单个待预测数据x,返回x的预测结果值"""
return self.a_ * x_single + self.b_
def __repr__(self):
return "SimpleLinearRegression1()"ベクトル化
ベクトル演算でnumpyのは、VI *及びbの上記簡略化が式Σwiのように表すことができることを見やすいサイクル効率のために使用されるものよりもはるかに高いが、これは実際には2つのベクトルの最適化のドット積でありますライティングクラスの後に:
class SimpleLinearRegression2:
def __init__(self):
"""初始化Simple Linear Regression模型"""
self.a_ = None
self.b_ = None
def fit(self, x_train, y_train):
"""根据训练数据集x_train,y_train训练Simple Linear Regression模型"""
assert x_train.ndim == 1, \
"Simple Linear Regressor can only solve single feature training data."
assert len(x_train) == len(y_train), \
"the size of x_train must be equal to the size of y_train"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
self.a_ = (x_train - x_mean).dot(y_train - y_mean) / (x_train - x_mean).dot(x_train - x_mean)
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self, x_predict):
"""给定待预测数据集x_predict,返回表示x_predict的结果向量"""
assert x_predict.ndim == 1, \
"Simple Linear Regressor can only solve single feature training data."
assert self.a_ is not None and self.b_ is not None, \
"must fit before predict!"
return np.array([self._predict(x) for x in x_predict])
def _predict(self, x_single):
"""给定单个待预测数据x_single,返回x_single的预测结果值"""
return self.a_ * x_single + self.b_
def __repr__(self):
return "SimpleLinearRegression2()"
線形回帰の尺度
平均二乗誤差MSE(平均二乗誤差)

ルートは(ルートは平均二乗誤差)二乗誤差RMSEの平均します
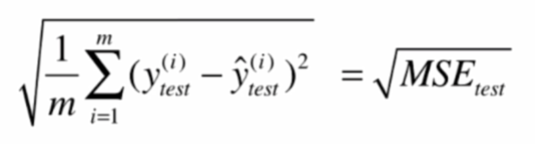
平均絶対誤差MAE(絶対平均誤差)
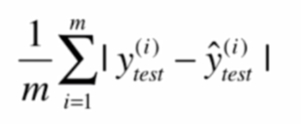
コード
以下のコードはjupyterノートPCで実行されています
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
boston=datasets.load_boston()
x=boston.data[:,5] #只使用房间数量RM这个特征
y=boston.target
plt.scatter(x,y)
plt.show()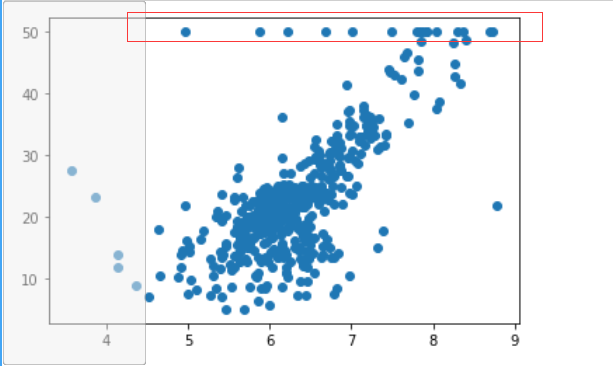
トップは最大値を有することができる測定器、すべての50を超えるが書き込まれている可能性があり、いくつかの点で非常に奇妙な見つけることができますので、我々は、Y> 50個のポイントを削除したい(よりか、アンケートは50を完了したときに50年代に書かれている以上) 。
x=x[y<50]
y=y[y<50]
plt.scatter(x,y)
plt.show()
このような正しいです。
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=666)
%run F:\python3玩转机器学习\线性回归\SimpleLinearRegression.py
reg = SimpleLinearRegression2()
reg.fit(x_train,y_train)
reg.a_
reg.b_
plt.scatter(x_train,y_train)
plt.plot(x_train,reg.predict(x_train),color="r")
plt.show()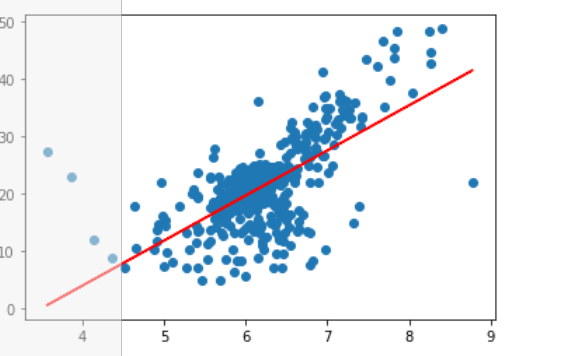
y_predict=reg.predict(x_test)
mse_test=np.sum((y_predict-y_test)**2)/len(y_test)
mse_test
from math import sqrt
rmse_test=sqrt(mse_test)
rmse_test
mae_test=np.sum(np.absolute(y_predict-y_test))/len(y_test)
mae_testMSEとメイのsklearn:
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
#没有rmse,需要自己手动开根
mean_squared_error(y_test,y_predict)
mean_absolute_error(y_test,y_predict)正方形に大きな誤差増幅器をRMSEであろうからである、とメイはなく、メイはRMSEより少し小さく見出すことができるが、その大きさは同じ(同じyの単位)です。だから我々はできるだけRMSE小さなが理にかなっているようにしよう。
R乗
最高分類精度は最悪は0で、RMSEメイと会うことができない、1です。

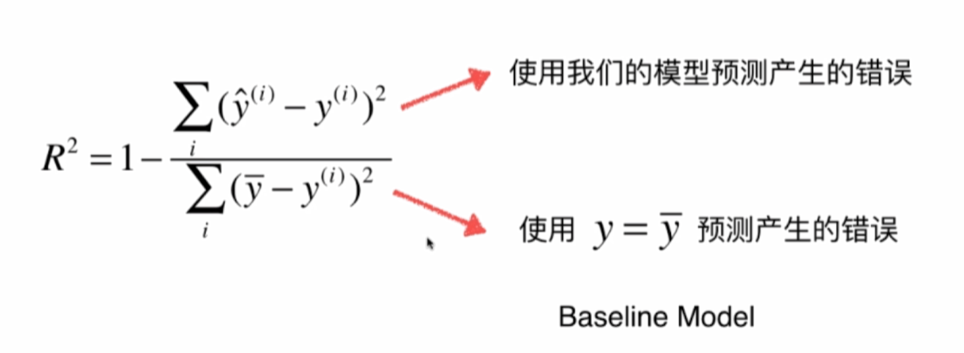

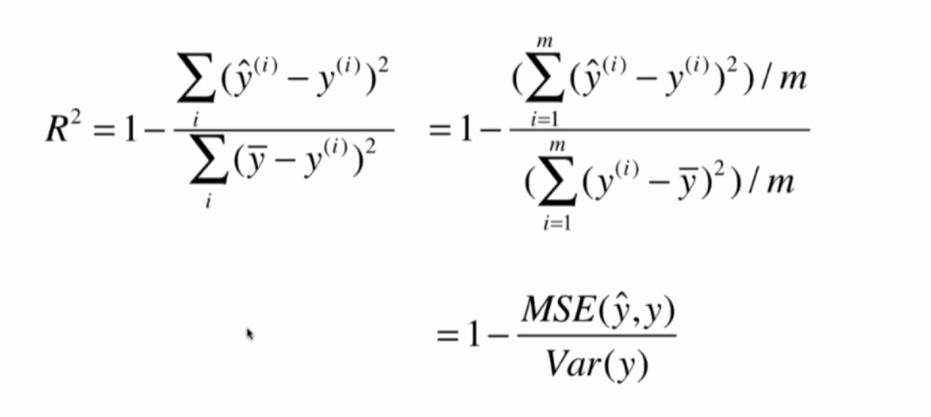
コード:
1-mean_squared_error(y_test,y_predict)/np.var(y_test)機能にカプセル化
def mean_squared_error(y_true, y_predict):
"""计算y_true和y_predict之间的MSE"""
assert len(y_true) == len(y_predict), \
"the size of y_true must be equal to the size of y_predict"
return np.sum((y_true - y_predict)**2) / len(y_true)
def root_mean_squared_error(y_true, y_predict):
"""计算y_true和y_predict之间的RMSE"""
return sqrt(mean_squared_error(y_true, y_predict))
def mean_absolute_error(y_true, y_predict):
"""计算y_true和y_predict之间的MAE"""
assert len(y_true) == len(y_predict), \
"the size of y_true must be equal to the size of y_predict"
return np.sum(np.absolute(y_true - y_predict)) / len(y_true)
def r2_score(y_true, y_predict):
"""计算y_true和y_predict之间的R Square"""
return 1 - mean_squared_error(y_true, y_predict)/np.var(y_true)複数の線形回帰式と正式
複数の線形回帰:
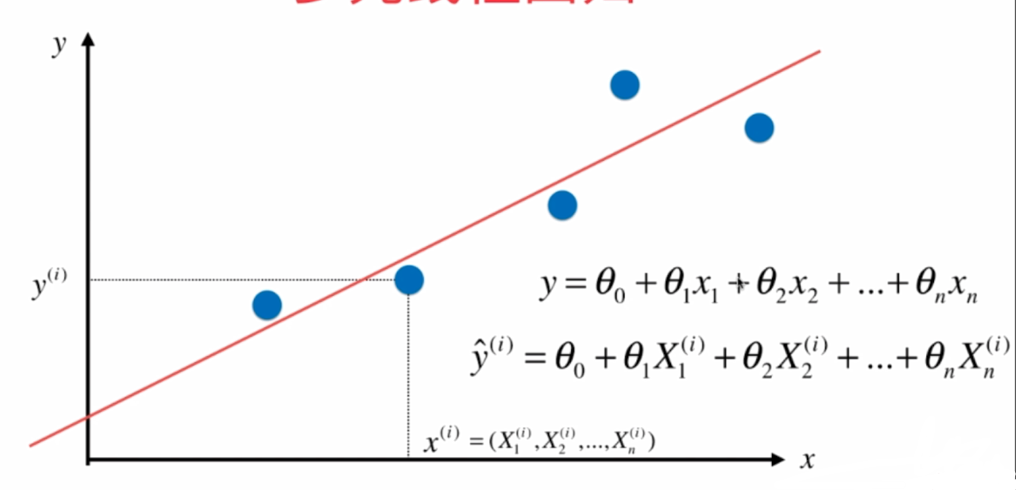
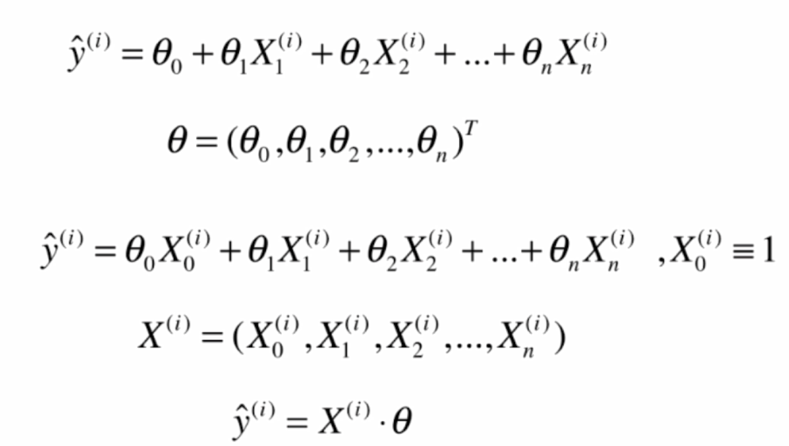

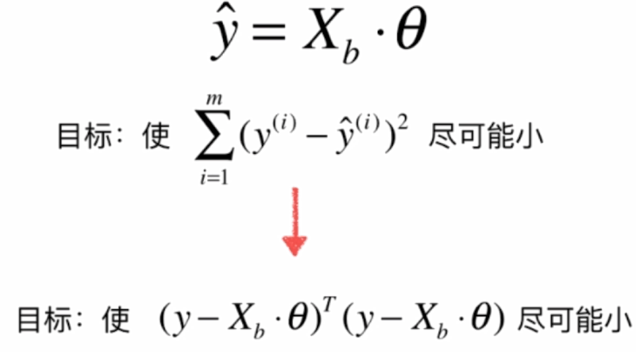


線形回帰カテゴリ:
import numpy as np
from sklearn.metrics import r2_score
class LinearRegression:
def __init__(self):
"""初始化Linear Regression模型"""
self.coef_ = None #系数
self.intercept_ = None #截距
self._theta = None
def fit_normal(self, X_train, y_train):
"""根据训练数据集X_train, y_train训练Linear Regression模型"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
self._theta = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y_train)
self.intercept_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def predict(self, X_predict):
"""给定待预测数据集X_predict,返回表示X_predict的结果向量"""
assert self.intercept_ is not None and self.coef_ is not None, \
"must fit before predict!"
assert X_predict.shape[1] == len(self.coef_), \
"the feature number of X_predict must be equal to X_train"
X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict])
return X_b.dot(self._theta)
def score(self, X_test, y_test):
"""根据测试数据集 X_test 和 y_test 确定当前模型的准确度"""
y_predict = self.predict(X_test)
return r2_score(y_test, y_predict)
def __repr__(self):
return "LinearRegression()"
%run f:\python3玩转机器学习\线性回归\LinearRegression.py
boston=datasets.load_boston()
X=boston.data #全部特征
y=boston.target
X=X[y<50]
y=y[y<50]
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=666)
reg=LinearRegression()
reg.fit_normal(X_train,y_train)
reg.coef_
reg.intercept_
reg.score(X_test,y_test)線形回帰をscikit-学びます
from sklearn.linear_model import LinearRegression
lin_reg=LinearRegression()
lin_reg.fit(X_train,y_train)
lin_reg.intercept_
lin_reg.coef_
lin_reg.score(X_test,y_test)
KNN回帰
from sklearn.neighbors import KNeighborsRegressor
knn_reg=KNeighborsRegressor()
knn_reg.fit(X_train,y_train)
knn_reg.score(X_test,y_test)
#网格搜索最优参数
param_grid =[
{
'weights':['uniform'],
'n_neighbors':[i for i in range(1,11)],
},
{
'weights':['distance'],
'n_neighbors':[i for i in range(1,11)],
'p':[i for i in range(1,6)]
}]
knn_reg=KNeighborsRegressor()
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(knn_reg,param_grid)
grid_search.fit(X_train,y_train)
grid_search.best_params_
grid_search.best_score_ #此方法不能用,因为评价标准和前面不同,采用了CV
grid_search.best_estimator_.score(X_test,y_test) #这样才是真正的和前面相同的评价标准線形回帰解釈可能
boston=datasets.load_boston()
X=boston.data #全部特征
y=boston.target
X=X[y<50]
y=y[y<50]
from sklearn.linear_model import LinearRegression
lin_reg=LinearRegression()
lin_reg.fit(X,y)
lin_reg.coef_
np.argsort(lin_reg.coef_)
boston.feature_names[np.argsort(lin_reg.coef_)]係数は、子供の頃をソートした後、大規模なインデックスで見つけることができます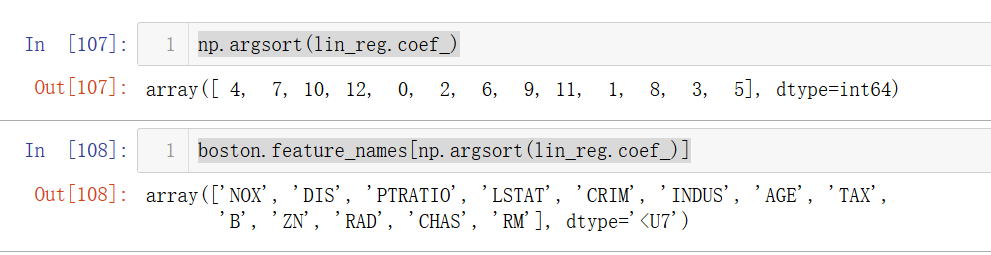
住宅価格とRM(部屋数)、CHAS(川かどうか)、およびその正の相関、およびNOX(一酸化炭素)と他の負の相関で見つけることができる機能の表示DESCの説明。
線形回帰の概要