関数のオーバーロード
C ++には、新しい機能である関数のオーバーロードが導入されました。
同じスコープの下で、同じ関数名の場合、関数のパラメーターは異なり、異なるタイプのパラメーターの順序は異なり、パラメーターの数も異なります。すべて関数オーバーロードを形成できます(異なるパラメーター名、異なる戻り値はオーバーロードを形成しません) )
関数のオーバーロードは主に、同じ関数でデータ型が異なるデータを処理するために使用されます。
たとえば
int test(int i, int j)
{
cout << "test" << endl;
}
int test(double i, int j)
{
cout << "test" << endl;
}
int test(double i, int j, int k)
{
cout << "test" << endl;
}
C ++がオーバーロードをサポートし、C言語がサポートしないのはなぜですか?
ウィンドウの処理はより複雑なので、Linuxでgccとg ++を使用する方が直感的です。
まず、リンカは関数が呼び出されたことを検出すると、シンボルテーブルに移動して対応する関数名を検索し、関数のアドレスを取得して、リンクします。
まず、C言語の処理方法を確認します。
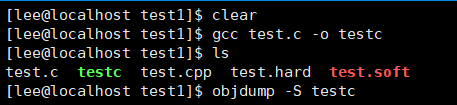

逆アセンブリにより、C言語は関数名を処理しないことがわかります。つまり、パラメーターの数、パラメーターの種類、パラメーターの順序に関係なく、関数のみを認識します。名前。同じ関数名を持つ2番目の名前がある場合、再定義と見なされます。
もう一度C ++を見てみましょう

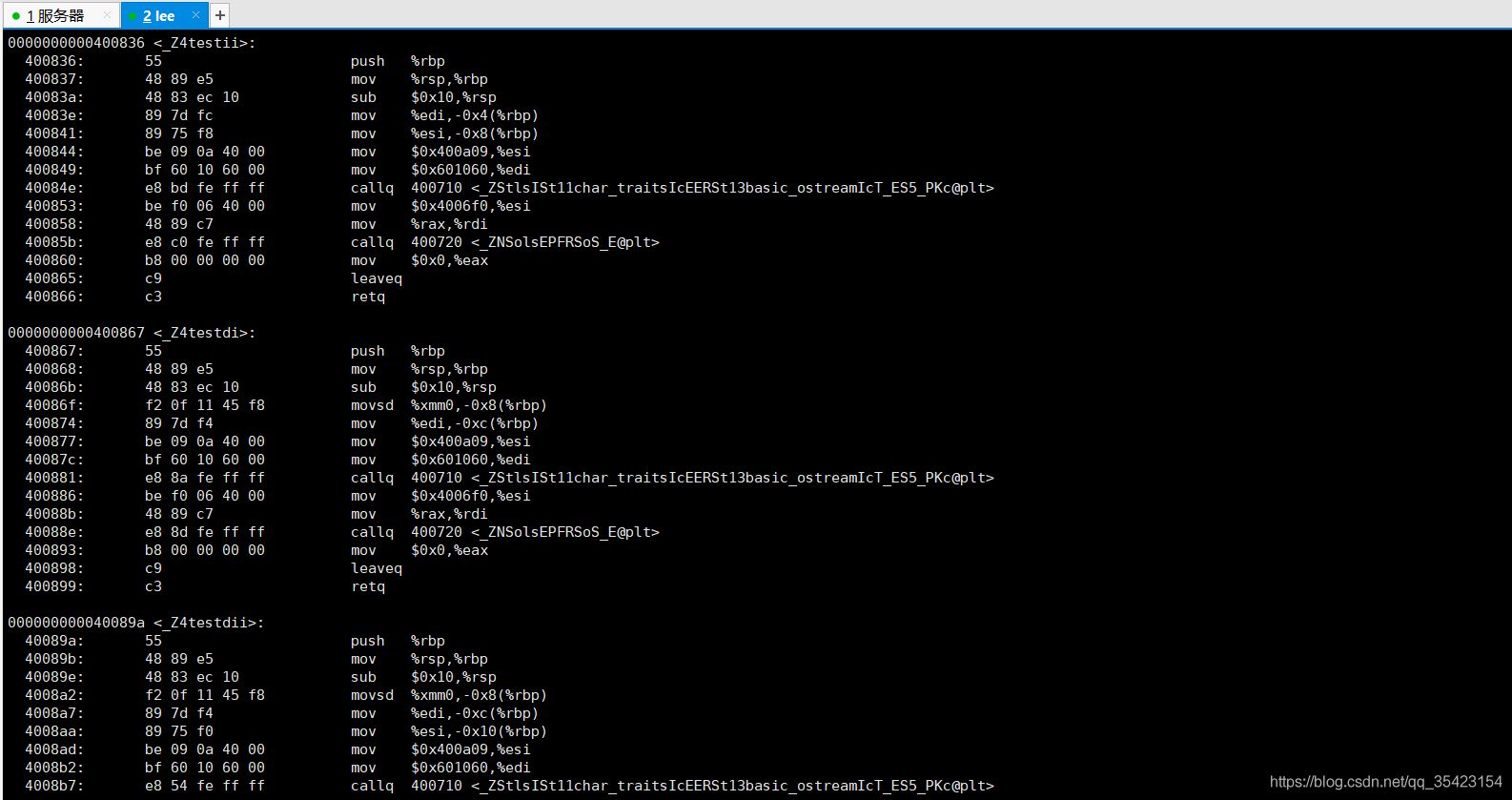
。C++が関数名を処理したことがわかります。関数は_Z4で始まり、次に関数名、最後にすべてのパラメーターの省略形です。
_Zはすべての関数のプレフィックス、4は関数名の文字数です。たとえば、最初の_Z4testiiは関数名テストを表し、4文字で、パラメーターはiiです。
これが、戻り値が異なり、パラメーター名がオーバーロードを構成しない理由です。C++は、この関数名の変更規則を使用して、関数のオーバーロードを実装します。
外部「C」
C ++を使用している場合があります。Cスタイルでコンパイルする必要がある一部の関数では、関数の前にextern“ C”を追加するだけで、C言語の規則に従って関数をコンパイルするようコンパイラーに指示できます。

見積もり
引用された概念
参照は、オブジェクトに別の名前を付けることです。このエイリアスを使用して、元のオブジェクトを操作できます。同時に、コンパイラーは参照変数用のスペースを開きません。参照するオブジェクトとスペースを共有します。
使用法:タイプと参照オブジェクト名=参照エンティティ
int main()
{
int i = 5;
int& j = i;
cout << i << ' ' << j << endl;
j = 8;
cout << i << ' ' << j << endl;
return 0;
}
参照機能
- 参照は定義時に初期化する必要があります(参照はオブジェクトのエイリアスであるため、初期化する必要があります)
- オブジェクトは複数の参照を持つことができます
- エンティティを参照すると、他のエンティティを参照できなくなります(ポインタのトップレベルのconstと少し似ています)
よく引用される
int main()
{
const int i = 5;
int& j = i;
//错误的
const int & k = i;
正确的
}
ここでは定数iが参照されます。これは、iが定数であるため、その値を変更できないため、通常の参照を使用する場合、その権限を拡大して、jを介してiを変更できるようにします。これは、不合理なので、コンパイラはエラーを報告します。定数参照のみを使用
int main()
{
int x = 6;
const int & y = x;
}
同時に、定数参照を使用してこのxを参照します。xは変更できますが、yは変更できません。これにより、権限が縮小され、読み取り専用になるため、これが可能になります。
相互参照
int main()
{
double x = 3.14;
int& y = x;
//错误的
const int& z = x;
//正确的
return 0;
}
ここでは、xを参照するためにyとzを使用しますが、コンパイラーはyがエラーを報告し、zは正当であり、クロスタイプでもあるというプロンプトを出します。
タイプが異なる場合、一時的な数量がxを参照するために使用され、その後、一時的な数量が参照されます。
int main()
{
double x = 3.14;
int& y = x;
/*
等价于
const int &temp = x;
int &y = temp;
*/
const int& y = x;
/*
等价于
const int &temp = x;
const int &z = temp;
*/
return 0;
}
通常の参照の場合、実際にはtempを参照していますが、xを変更したいのですが、これは不可能です。一時的な量が一定であるため、この動作は不正です。
定数参照の場合、xを変更しないことを意味するため、参照が実際には一時的な量tempであっても、この動作は正当です
引用された使用シナリオ
- パラメータとして
struct A
{
int arr[1000000];
};
void test(A& s1)
{
}
非常に大きな構造があるとします。構造を直接渡すと、一時変数が生成され、構造が仮パラメーターにコピーされます。これは大きなオーバーヘッドですが、参照を使用すると、渡されるのはエイリアスのみですが、上記と同じことが必要ですが、一時的な量は一定であるため、定数を渡す場合は、参照の前にconstを追加する必要があります。
- 戻り値として
> int& Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int& ret = Add(1, 2);
Add(3, 4);
cout << ret << endl;
return 0;
}
このようなコードの場合、最初はretが3になると思うかもしれません
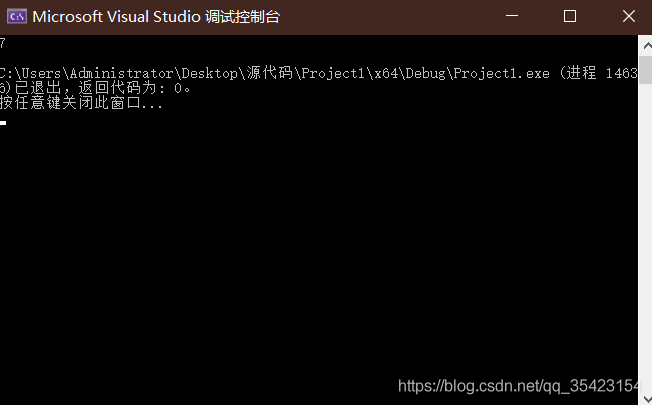
が、実際には7です。
cへの参照を返しますが、cは呼び出し時にスタックフレームにのみ存在します。呼び出しが完了すると、スタックフレームは破棄されます。破棄後にデータは消去されませんが、領域へのアクセスはアクセス許可が解放され、次の呼び出し関数で使用されたり、操作で使用されたりする可能性があるため、これは非常に危険な動作です。参照を返す場合は、オブジェクトが関数のスコープ内にまだ存在することを確認してください。
上記の7は、2回目の呼び出し後に変更されたcの値です。
したがって、戻り値として引用する必要がある場合は、関数のスコープが外にあり、返されたオブジェクトがシステムに返されず、まだ存在していることを確認する必要があります。
値がパラメーターまたは戻り値として使用される場合、パラメーターを渡して返すときに、元の変数の一時コピーが渡されるか、返されます。この効率は、特にデータが特に大きい場合は非常に低くなりますが、参照をパラメータがあれば、そのような問題はありません。
参照とポインタ
先ほど、参照はオブジェクトのエイリアスであると説明しました。別個のスペースはなく、参照するエンティティとスペースを共有しますが、これは文法上の概念にすぎません。同時に、参照が実際にはポインターに類似していることがわかりました。これは、トップレベルのconstポインターに似ているため、逆アセンブリを入力して、それらの間に関係があるかどうかを確認できます。
int main()
{
int x = 5;
int& y = x;
int* z = &x;
return 0;
}
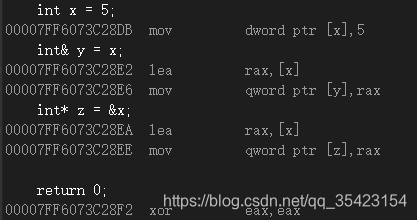
逆アセンブリでは、アセンブリでのポインタと参照の実装はまったく同じであることがわかります。
したがって、参照はポインタに従って実装され、新しい関数はポインタに基づいてカプセル化されるという結論を導き出すことができます
参照とポインターの違い:
- 参照は定義時に初期化する必要があり、ポインターは必要ありません
- 参照は初期化中にエンティティを参照した後、他のエンティティを参照できなくなり、ポインタはいつでも同じタイプの任意のエンティティを指すことができます
- NULL参照はありませんが、NULLポインター
- sizeofでは意味が異なります。参照結果は参照タイプのサイズですが、ポインタは常にアドレス空間が占めるバイト数です(32ビットプラットフォームでは4バイト)。
- 参照される自己追加は、1ずつ増加する参照されるエンティティを参照し、ポインターの自己追加は、型サイズによってオフセットされるポインターを参照します。
- マルチレベルポインターはありますが、マルチレベル参照はありません
- エンティティにアクセスする方法は異なり、ポインタを明示的に逆参照する必要があり、参照コンパイラがそれを処理します
- 参照はポインタよりも使用するのが比較的安全です
インライン関数
inlineキーワードで変更された関数は、インライン関数です。コンパイラーは、コンパイル時に、インライン関数が呼び出された関数のコードを拡張し、関数のスタックのオーバーヘッドを差し引いて、プログラムの効率を向上させます。

たとえば、このような単純なコードアセンブリ
で直接呼び出すと
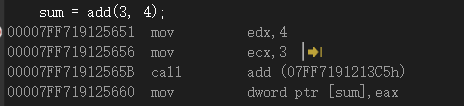
、新しいスタックフレームが作成され、パラメーター3と4がスタックにプッシュされ、結果が計算されて返され
ます。関数の前にインラインを追加してインラインにした場合

この時点で関数を見ると、呼び出し時に関数のコードが直接展開されており、新しいスタックフレームを作成していないことがわかります。
インライン関数の特徴
- インライン関数は、時間のスペースをスワップする方法であり、スタックフレームの作成とスタックのプッシュのオーバーヘッドを節約します。ただし、コードは非常に複雑であり、ループまたは再帰を含む関数は、次のように宣言されていても、インライン関数としては適していません。インライン関数コンパイラも自動的に無視します。
- インライン関数は、インライン関数として宣言すると、呼び出されたときに直接展開されるため、個別に宣言して定義することはできません。関数のアドレスがないと、定義された部分にリンクできません。
インライン関数はCのマクロ関数にいくぶん似ていることは言及に値します。マクロはタイプセーフチェックがなくデバッグできないため(マクロ置換は前処理段階で実行されました)、マクロのパフォーマンスは良好ですが、C ++中程度のマクロ関数はインライン関数に置き換えられ、マクロ定数の定義はconstに置き換えられます。
オート
プログラミング時には、式の値を変数に割り当てる必要があることがよくありますが、式のタイプがわからない場合もあります。この問題を解決するために、C ++ 11では、コンパイラーを作成するために使用できる自動タイプ指定子が導入されました式のタイプを分析する代わりに。
autoはコンパイラに初期値を通じて変数の型を推測させる必要があるため、autoには初期値が必要です。
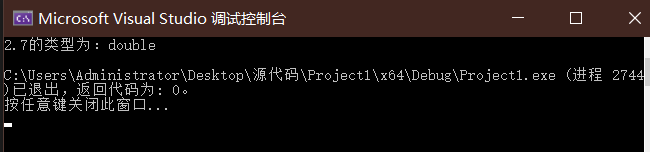
int main()
{
auto i = 2.7;
cout << i <<"的类型为:" << typeid(i).name() << endl;
}
自動ルール
- autoはポインターおよび参照と組み合わせることができます
int main()
{
int i = 4;
auto a1 = &i;
auto *a2 = &i;
auto& a3 = i;
cout <<"a1的类型为:" << typeid(a1).name() << endl;
cout << "a2的类型为:" << typeid(a2).name() << endl;
cout << "a3的类型为:" << typeid(a3).name() << endl;
}
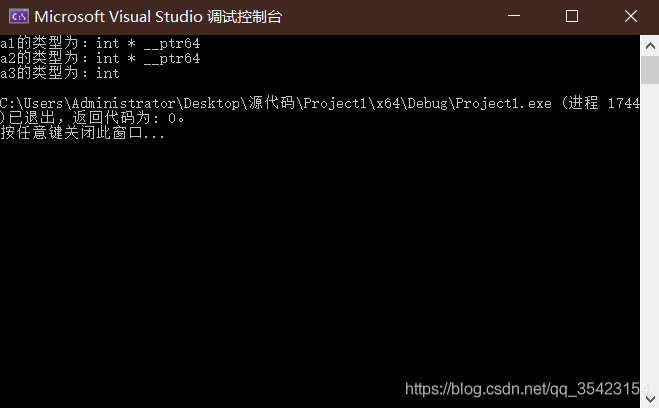
autoはポインター型を認識できるため、*なしで追加できますが、参照は&を付けて追加する必要があります。C++はこの型を参照しないため、参照は変更されたエイリアスにすぎないため、本質はそのままです。
- 同じ行に複数の変数を定義する
int main()
{
auto i = 1, j = 2; //正确,同一行都是相同类型
auto x = 3, y = 4.8;//错误,同一行类型不同
}
-
Autoを関数のパラメーターとして使用することはできません。Autoを

仮パラメーターの型として使用することはできません。コンパイラーはiとjの型を推定できません。 -
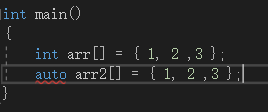
autoを直接使用して配列を宣言することはできません
-
autoは通常、最上位のconstを無視します
int main()
{
const int i = 5;
//i : const int
auto a1 = i;
//忽略了顶层const ,al : int
const auto a2 = i;
//加上const, a2 : const int
}
ループの範囲
範囲のある一部のコレクションでは、ループを使用するときに長さがわからなかったり、誤って境界を越えたりすることがあります。この問題を解決するために、c ++ 11ではループの範囲が導入されました。
ループは2つの部分に分かれています。最初の部分は変数のタイプ、2番目の部分は反復のスコープで、次のように区切られています。
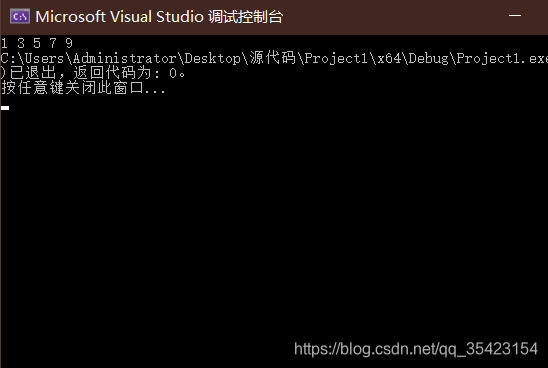
int main()
{
vector<int> vec{ 1, 3, 5, 7, 9 };
for (auto i : vec)
{
cout << i << ends;
}
}
iは元のデータをコピーするための一時変数であることに注意してください。元のデータを変更する場合は、&i(両方とも元のデータへの参照)に変更する必要があります。
