目次
❀❀❀継続力のない努力は本質的には無意味です。
1. 引用
1.1 参照概念
型&参照変数名(オブジェクト名) = 参照エンティティ (注:参照型は参照エンティティと同じ型である必要があります)
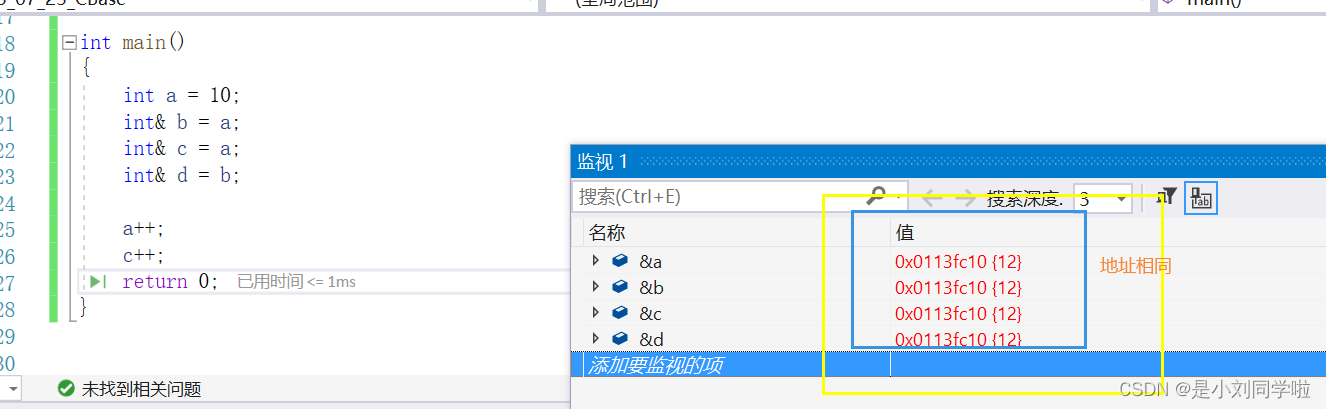
b は参照と呼ばれますが、b はエイリアスとも呼ばれます (ABCD 4、1 つが変更されると残りも変更されます)
アプリケーション 1 :
void Swap(int& a, int& b) { int tmp = a; a = b; b = tmp; }データ交換の場合、ポインタを渡す代わりに参照を使用できます。
アプリケーション 2 :
#include <iostream> typedef struct ListNode { int val; struct ListNode* next; }LTNode; void LTPushBack_C(LTNode** pphead, int x) { //C语言,单链表尾插需要传结构体的二级指针,因为需要改变首部地址 } void LTPushBack_CPP(LTNode*& phead, int x) { //C++中,用引用,仅仅需要传结构体地址 } int main() { LTNode* plist = NULL; //初始化 LTPushBack_C(&plist, 1); LTPushBack_CPP(plist, 1); return 0; }ポインタ型も参照できます
知らせ:
typedef struct ListNode { int val; struct ListNode* next; }LTNode,*PLTNode; void LTPushBack_CPP(LTNode*& phead, int x) { //C++中,用引用,仅仅需要传结构体地址 } //这两个等同 void LTPushBack_CPP(PLTNode& phead, int x) { //C++中,用引用,仅仅需要传结构体地址 }
1.2 引用特性
コード表示:
#include <iostream>
int main()
{
int a = 10;
int& b = a;
int& c = a;
int& d = b;
//一个变量可以多次引用
int& e;//代码运行到这里会报错,因为引用在定义时必须初始化
int m = 2;
b = m;//b在前面已经引用了a,在这里并不是成为m的别名,而是把m的值赋值给b,然后此时abcd的值都是2
return 0;
}1. 参照は 定義時に初期化する必要があります2. 変数は複数の参照を持つことができます3. エンティティへの参照が行われると、他のエンティティは参照できなくなります。
1.3 頻繁に引用されるもの
const によって変更された変数は読み取りのみ可能ですが、書き込みはできません(ここでの許可とは読み取りと書き込みを指します)
#include <iostream> int main() { int a = 0; int& b = a;//权限不变 const int c = 2; int& d = c;//这里是错误的,权限不能被放大 const int x = 3; const int& y = x;//这里是可以的,权限不变 int m = 6; const int& n = m;//这里是可以的,权限缩小 return 0; }エイリアシングの原則: 参照タイプの場合、アクセス許可は縮小のみ可能であり、拡大はできません。
一時変数はconstです
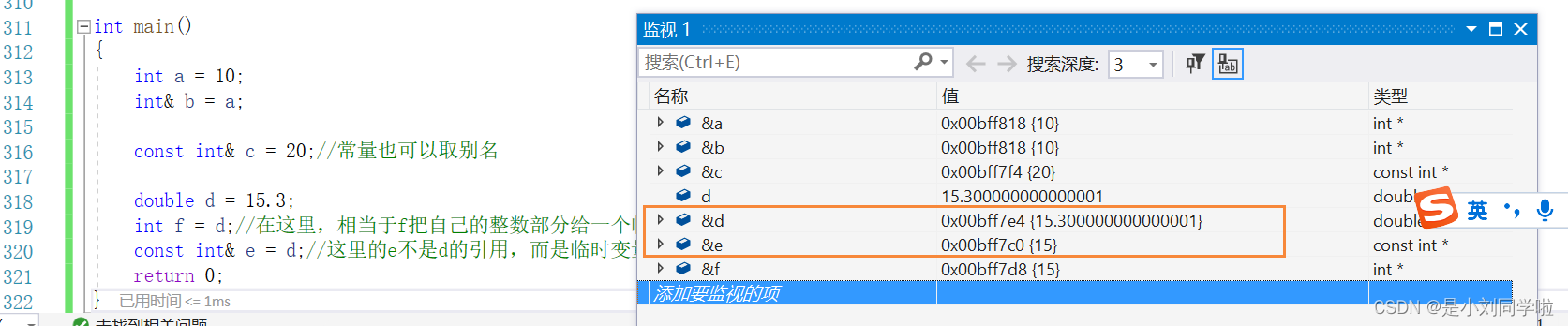
#include <iostream> int main() { int a = 10; int& b = a; const int& c = 20;//常量也可以取别名 double d = 15.3; int f = d;//在这里,相当于f把自己的整数部分给一个临时变量,临时变量把值赋给f(临时变量具有常性) const int& e = d;//这里的e不是d的引用,而是临时变量的引用 return 0; }
1.4 使用シナリオ
(1) パラメータの作成
void Swap(int& a, int& b)
{
int tmp = a;
a = b;
b = tmp;
}ポインタを渡す必要はありません
(2) 戻り値を実行する
コード 1 は次を示します: (値による戻り値)
#include <iostream> int Count() { int n = 0; n++; return n; }//n出了这个函数就被销毁了,所以是赋值给临时变量的 int main() { int ret = Count(); return 0; }関数はプロセスに戻り、戻り値 n は一時変数に渡されます。一時変数の型は関数の型 (上記コードでは int) で、一時変数はメイン関数の ret に値を代入します。関数。(一時変数にはコピーがあります)
コード 2 は次を示します: (参照によりコピー)
#include <iostream> int& Count() { static int n = 0;//static不能去掉,如果去掉,就会涉及出现越界问题(因为空间被系统回收) n++; return n; }//返回int&,说明有一个临时引用是int&类型,临时引用是n的别名 int main() { int& ret = Count();//ret是临时引用的别名, return 0; }コピー不要、高効率
関数が関数のスコープ外に戻った場合、返されたオブジェクトがまだそこにある ( まだシステムに返されていない )場合は 参照で返すことができ、 システムに返されている場合は値で返す必要があります。(そうしないと範囲外の問題が発生します)
知らせ:
#include <iostream>
int Count()
{
int n = 0;
n++;
return n;
}
int main()
{
const int& ret = Count();//因为是临时变量的别名,临时变量具有常性
return 0;
}1.5 値渡しと参照渡しの効率比較
1.6 参照とポインタの違い
文法の観点から見ると、参照はエイリアスであり、開く追加のスペースはなく、ポインタはアドレスを格納するため、4/8 バイトのスペースが必要ですが、最下層の観点からは、これは実装されています。同じように(アセンブリコードは一貫しています)
2. インライン関数
2.1 コンセプト
ナレッジレビュー: ADD マクロを作成する
inline の存在意義: (1) わかりにくいマクロ機能と書き間違いを解決する (2) マクロはデバッグをサポートしていない
メリット: (1) デバッグ機能がデバッグをサポート (2) 通常の関数の書き方なので間違えにくい (3) プログラムの効率が向上
2.2 特徴
知識のポイント :マクロの長所と短所は?アドバンテージ:1. コードの再利用性を強化します。2. パフォーマンスを向上させます。欠点:1. マクロのデバッグが不便です。(プリコンパイル段階での置き換えのため)2. コードの可読性、保守性が低下し、誤用が容易になります。3. タイプセーフティチェックはありません。C++ のマクロに代わる技術的な代替手段は何ですか ?1.定数定義を const に置き換える2. 関数定義をインライン関数に置き換える
3. auto キーワード (C++11)
3.1 型エイリアスの考え方
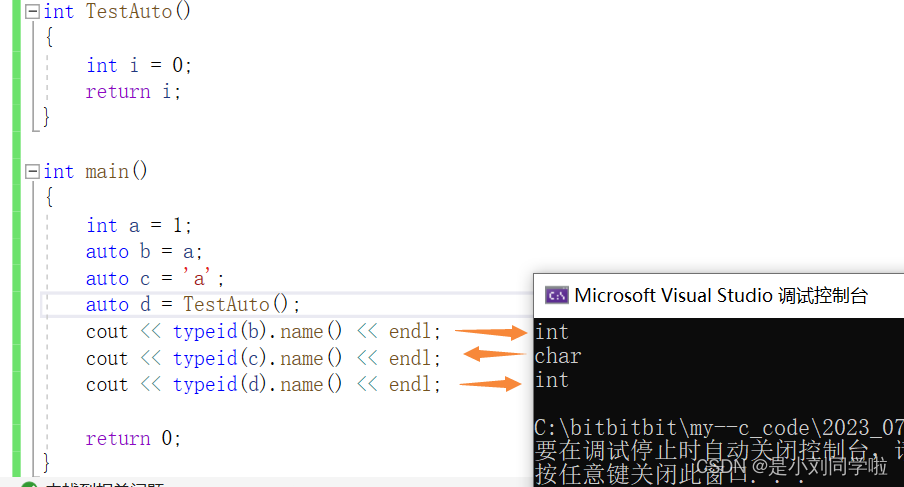
auto は、等号の後の変数に従って型を自動的に定義できます。
C++ では、typeid(A).name() ; A の型を知ることができます。
3.2 自動の概要
autoを 使用して変数を定義する 場合は、 初期化する必要があります 。コンパイル段階で、コンパイラは初期化式に従って auto の実際の 型 推測する必要があります。したがって、 auto は 「型」宣言 ではなく、 型が宣言されたときの「プレースホルダー」です。コンパイラは、コンパイル中にauto を変数の実際の型に置き換えます。
3.3 自動使用のルール
(1) Auto はポインタや参照と組み合わせて使用されます。
( auto* はポインタ型として定義する必要があります)
auto の意味の 1 つは、型が非常に長い場合に、それを書くのが面倒な場合に、自動的に推測させることができます。
3.4 auto を導出できないシナリオ
// 此处代码编译失败,auto不能作为形参类型,因为编译器无法对a的实际类型进行推导
void TestAuto(auto a)
{}void TestAuto()
{
int a[] = {1,2,3};
auto b[] = {4,5,6};
}3. C++98でのautoとの混同を避けるために、 C++11 では型インジケーターとしてのautoの使用のみが維持されます。
4. 範囲ベースの for ループ (C++11)
4.1 範囲の構文
void TestFor()
{
int array[] = { 1, 2, 3, 4, 5 };
//加&的原因是e是array内容的拷贝,所以改变e不是改变array里面的内容
for (auto& e : array)
{
e *= 2;
}
//范围for,依次自动取arrar中的数据,赋值给e,自动判断结束
for (auto e : array)//这里写int也可以
{
cout << e << " ";
}
}4.2 スコープの使用条件
void TestFor(int array[])
{
for(auto& e : array)
cout<< e <<endl;
}ここでの配列は配列の最初の要素のアドレスであるため、範囲は不確かです
5. ポインタ空値 nullptr(C++11)
5.1 C++98 の Null ポインタ
//指针初始化
int* p1 = NULL;
int* p2 = 0;
int* p3 = nullptr;//建议用这一种