1.概要
前回の記事では、コンパイル時のマウントプロセス中に、テンプレートがレンダー式にコンパイルされ、後でvnodeの形成に備えることを説明しました。
コンパイルプロセスの概要を見てみましょう。

プロセス全体は3つの段階に分かれています。
1. templatを解析してASTモデルツリーに変換します。
2.最適化し、静的ノードをマークします。
3.レンダリング式を生成、生成します。
また、3つの章で紹介します。この章では、最初の段階に焦点を当てています。
第二に、入り口
前回の記事では、src / platform / web / entry-runtime-with-compiler.jsのコードについて説明しました
//2、编译,生成render
...
const { render, staticRenderFns } = compileToFunctions(template, {
shouldDecodeNewlines,
shouldDecodeNewlinesForHref,
delimiters: options.delimiters,
comments: options.comments
}, this)
options.render = render
options.staticRenderFns = staticRenderFns
...
}compileToFunctionsの入力パラメーターは、テンプレート、オプション配列、およびvmオブジェクトであり、最後にrenderおよびstaticRenderFnsオブジェクトを返します。compileToFunctionsはsrc / platform / compiler / index.jsで定義され、createCompilerによって返されます。
import { baseOptions } from './options'
import { createCompiler } from 'compiler/index'
const { compile, compileToFunctions } = createCompiler(baseOptions)入力がbaseOptionsオブジェクトであるcreateCompilerは、compileおよびcompileToFunctionsという2つのメソッドを返します。
createCompiler(src / compiler / index.js)を引き続き表示します
export const createCompiler = createCompilerCreator(function baseCompile (
template: string,
options: CompilerOptions
): CompiledResult {
const ast = parse(template.trim(), options)
if (options.optimize !== false) {
optimize(ast, options)
}
const code = generate(ast, options)
return {
ast,
render: code.render,
staticRenderFns: code.staticRenderFns
}
})createCompilerは、src / compiler / create-compiler.jsで定義されているcreateCompilerCreatorメソッドによって返されます。
export function createCompilerCreator (baseCompile: Function): Function {
return function createCompiler (baseOptions: CompilerOptions) {
function compile (
template: string,
options?: CompilerOptions
): CompiledResult {
...
//真正实现编译的核心代码
const compiled = baseCompile(template, finalOptions)
...
compiled.errors = errors
compiled.tips = tips
return compiled
}
return {
compile,
compileToFunctions: createCompileToFunctionFn(compile)
}
}
}createCompilerCreatorの入力パラメーターはbaseCompileメソッドです。createCompilerメソッドは関数本体で定義され、compileメソッドはcreateCompilerで定義されます。このメソッドでは、baseCompileを呼び出して実際のコンパイルを実現します。createCompilerは、createCompileToFunctionFnに実装されているcompileToFunctionsメソッドを返します。
export function createCompileToFunctionFn (compile: Function): Function {
const cache = Object.create(null)
return function compileToFunctions (
template: string,
options?: CompilerOptions,
vm?: Component
): CompiledFunctionResult {
....
const compiled = compile(template, options)
....
return (cache[key] = res)
}
}
createCompileToFunctionFnの入力パラメーターは、compileToFunctionsを返すcompileメソッドです。これは、最初に呼び出し、最後にソースを見つけたメソッドです。
入り口全体を定義するプロセスは非常に丸いため、次の図を使用して、レイヤーごとに肌を引き抜きます。
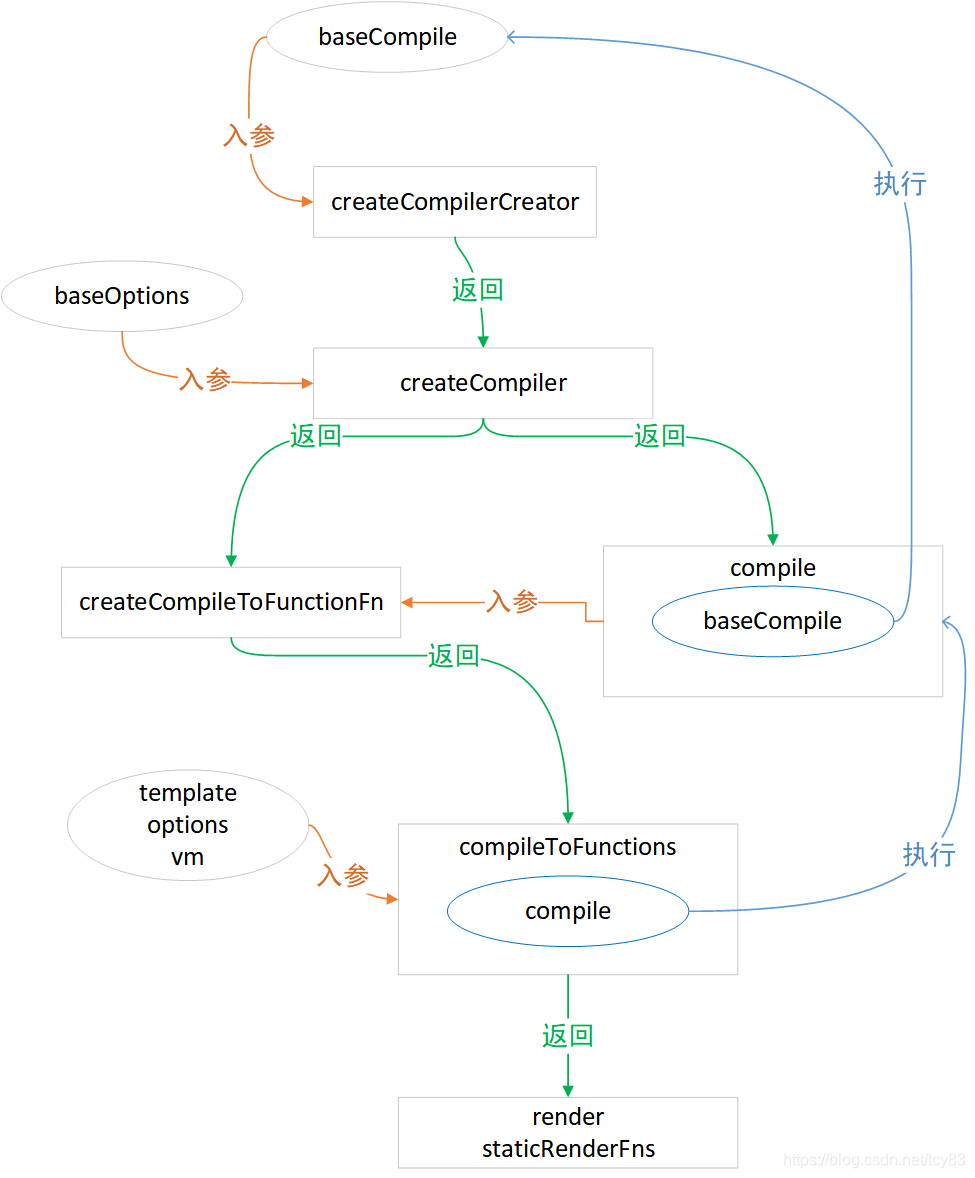
なぜこれを行うのですか?これは派手な手法ではありません。vue.jsが異なるプラットフォームでコンパイルするbaseoptionsは異なりますが、コアコンパイルプロセスbaseComplieは同じであるため、関数カリー化の巧妙な使用が実装されています。このプロセスのカリー化された疑似関数を書きます
createCompilerCreator(baseCompile)(baseOptions)(compile)(template,options,vm)3. AST
上記の分析によれば、最終的な方法はbaseCompileを実行するコンパイル。
export const createCompiler = createCompilerCreator(function baseCompile (
template: string,
options: CompilerOptions
): CompiledResult {
//1、parse,将templat转成AST模型
const ast = parse(template.trim(), options)
//2、optimize,标注静态节点
if (options.optimize !== false) {
optimize(ast, options)
}
//3、generate,生成render表达式
const code = generate(ast, options)
return {
ast,
render: code.render,
staticRenderFns: code.staticRenderFns
}
})このメソッドは、コンパイルプロセスの3つの段階を定義します。解析はテンプレートをASTモデルに変換することであり、ASTは抽象構文ツリーです。例として次のテンプレートを取り上げます。
<div id="app">
<ul>
<li v-for="item in items">
itemid:{{item.id}}
</li>
</ul>
</div>AST抽象ツリーモデルに変換すると、次のようになります。
{
"type": 1,
"tag": "div",
"attrsList": [
{
"name": "id",
"value": "app"
}
],
"attrsMap": {
"id": "app"
},
"children": [
{
"type": 1,
"tag": "ul",
"attrsList": [],
"attrsMap": {},
"parent": {
"$ref": "$"
},
"children": [
{
"type": 1,
"tag": "li",
"attrsList": [],
"attrsMap": {
"v-for": "item in items"
},
"parent": {
"$ref": "$[\"children\"][0]"
},
"children": [
{
"type": 2,
"expression": "\"\\n itemid:\"+_s(item.id)+\"\\n \"",
"tokens": [
"\n itemid:",
{
"@binding": "item.id"
},
"\n "
],
"text": "\n itemid:{{item.id}}\n "
}
],
"for": "items",
"alias": "item",
"plain": true
}
],
"plain": true
}
],
"plain": false,
"attrs": [
{
"name": "id",
"value": "\"app\""
}
]
}ASTの各要素には、それ自体のノード(タグ、attrなど)に関する情報が含まれ、同時に、親と子はそれぞれ親要素と子要素をポイントし、レイヤーごとにネストされ、ツリーを形成します。とりあえず、各属性の説明は省きますが、まず直感的に理解します。このツリーがどのように形成されるか見てみましょう。
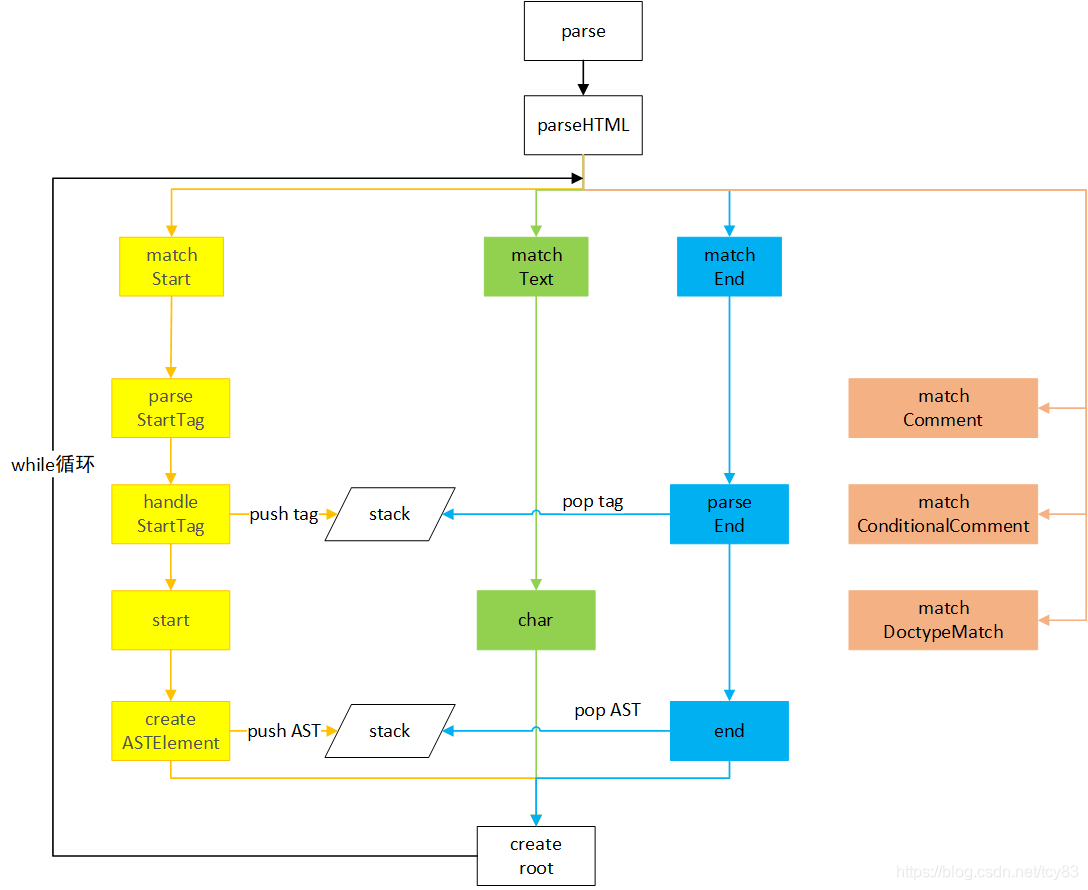
4、解析
parseメソッドはsrc / parser / index.jsで定義されています。このメソッドにはより多くのコンテンツがあります。構造は次のように記述します:
export function parse (
template: string,
options: CompilerOptions
): ASTElement | void {
....
//定义AST模型对象
let root
...
//主要的解析方法
parseHTML(template, {
...
})
//返回AST
return root
}
入力パラメーターはテンプレートとオプションであり、出力は生成されたASTモデルルートです。これは主にparseHTMLメソッドを呼び出すことで行われますが、これにもコンテンツが含まれており、構造のみを記述します
export function parseHTML (html, options) {
const stack = []
const expectHTML = options.expectHTML
const isUnaryTag = options.isUnaryTag || no
const canBeLeftOpenTag = options.canBeLeftOpenTag || no
let index = 0
let last, lastTag
//循环处理html
while (html) {
last = html
// Make sure we're not in a plaintext content element like script/style
//处理非script,style,textarea
if (!lastTag || !isPlainTextElement(lastTag)) {
let textEnd = html.indexOf('<')
//1."<"字符打头
if (textEnd === 0) {
// Comment:
//1.1、处理标准注释,<!--
if (comment.test(html)) {
...
}
// http://en.wikipedia.org/wiki/Conditional_comment#Downlevel-revealed_conditional_comment
//1.2、处理条件注释,<![
if (conditionalComment.test(html)) {
...
}
// Doctype:
//1.3、处理申明,DOCTYPE
const doctypeMatch = html.match(doctype)
if (doctypeMatch) {
...
}
// End tag:
//1.4、处理结束标签
const endTagMatch = html.match(endTag)
if (endTagMatch) {
...
}
// Start tag:
//1.5、处理开始标签
const startTagMatch = parseStartTag()
if (startTagMatch) {
...
}
}
//2、非"<"打头,作为text内容处理
let text, rest, next
if (textEnd >= 0) {
....
}
...
}else{
....
}
}
...
}whileループを介して、着信HTML文字は行ごとに解析されます。メソッド全体は2つの部分に分けることができます。
1. "<"で始まる文字は、さらにタイプに分類され、標準ノート、条件付きノート、アプリケーション、終了タグ、開始タグ、およびさまざまな処理に分類されます。
2.「<」で始まらない文字はテキストとして扱われます。
前のテンプレートを例として、開始、終了、およびテキストモジュールの解析プロセスの分析に焦点を当てましょう。
5、startTag
HTMLテンプレートの分析は、最初の文から始まります。
<div id="app">
<ul>
...由于是"<"字符开头,进入循环,由开始标签的代码段进行处理:
const startTagMatch = parseStartTag()
if (startTagMatch) {
handleStartTag(startTagMatch)
if (shouldIgnoreFirstNewline(lastTag, html)) {
advance(1)
}
continue
}1、parseStartTag
通过各类正则表达式对模板进行解析,并将相关的信息保存到match对象中。
function parseStartTag () {
//1、匹配<${qnameCapture}字符,如:<div
const start = html.match(startTagOpen)
//start=[<div,div,index=0]
if (start) {
//定义match对象保存相关属性
const match = {
tagName: start[1],
attrs: [],
start: index
}
//2、步进tag的长度
advance(start[0].length)
//3、循环查找该标签的attr,直到结束符>
let end, attr
while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) {
//步进该attr的长度
advance(attr[0].length)
match.attrs.push(attr)
}
//4、tag结束,记录全局的位置
if (end) {
match.unarySlash = end[1]
advance(end[0].length)
match.end = index
return match
}
}
}(1)通过RegExp(`^<${qnameCapture}`)匹配出开始的标签,本例中匹配的字符为"<div",并初始化match对象。
(2)步进tag的长度,
function advance (n) {
//index为全局位置
index += n
//从n位置开始截取,后面的字符作为新的html
html = html.substring(n)
}截取标签后的字符作为新的html,完成后如下:
id="app">
<ul>
...(3)循环处理该标签的属性,直到遇到结束符>
第一次判断循环条件,html.match(attribute)匹配出属性字符id="app",进入循环,步进属性的字符数,并将属性保存到match对象中。步进后新的html如下:
>
<ul>
...第二次判断循环条件,html.match(startTagClose)匹配出结束符>,直接跳出。
(4)tag结束,步进结束符长度,并记录保存全局的位置,本例中就是<div id="app">的长度14。新的html字符为:
<ul>
...至此,div的开始标签解析完毕,返回match对象,继续下面的处理流程。
2、handleStartTag
handleStartTag的入参就是match对象,主要实现对属性对象进行规整,并调用start方法,创建该标签的AST模型。
//处理开始标签
function handleStartTag (match) {
const tagName = match.tagName
const unarySlash = match.unarySlash
//有些tag可以作结束处理
if (expectHTML) {
if (lastTag === 'p' && isNonPhrasingTag(tagName)) {
parseEndTag(lastTag)
}
if (canBeLeftOpenTag(tagName) && lastTag === tagName) {
parseEndTag(tagName)
}
}
//是否为单元素,如<img />
const unary = isUnaryTag(tagName) || !!unarySlash
//1、整理attr为字面量对象
const l = match.attrs.length
const attrs = new Array(l)
for (let i = 0; i < l; i++) {
const args = match.attrs[i]
// hackish work around FF bug https://bugzilla.mozilla.org/show_bug.cgi?id=369778
if (IS_REGEX_CAPTURING_BROKEN && args[0].indexOf('""') === -1) {
if (args[3] === '') { delete args[3] }
if (args[4] === '') { delete args[4] }
if (args[5] === '') { delete args[5] }
}
const value = args[3] || args[4] || args[5] || ''
const shouldDecodeNewlines = tagName === 'a' && args[1] === 'href'
? options.shouldDecodeNewlinesForHref
: options.shouldDecodeNewlines
attrs[i] = {
name: args[1],
value: decodeAttr(value, shouldDecodeNewlines)
}
}
//2、非单元素,压入到stack,并在lastTag中缓存
if (!unary) {
stack.push({ tag: tagName, lowerCasedTag: tagName.toLowerCase(), attrs: attrs })
lastTag = tagName
}
//3、创建该标签的AST模型,并建立关联关系
if (options.start) {
options.start(tagName, attrs, unary, match.start, match.end)
}
}主要的流程有以下三部分:
1、循环规整attrs为字面量对象,规整完毕后,对象如下:
attrs=[{name=id,value=app}]
2、对于非单元素,压入到stack栈中,通过缓存当前的tagname为lastTag。该stack在后面的结束tag中进行闭环处理。
3、继续调用start方法,创建该标签元素的AST模型,建立模型树。
3、start
options.start是核心方法,在该方法中实现了AST模型的创建,以及关联关系的建立。
start (tag, attrs, unary) {
// check namespace.
// inherit parent ns if there is one
const ns = (currentParent && currentParent.ns) || platformGetTagNamespace(tag)
// handle IE svg bug
/* istanbul ignore if */
if (isIE && ns === 'svg') {
attrs = guardIESVGBug(attrs)
}
//1、创建ASTelement
let element: ASTElement = createASTElement(tag, attrs, currentParent)
if (ns) {
element.ns = ns
}
if (isForbiddenTag(element) && !isServerRendering()) {
element.forbidden = true
process.env.NODE_ENV !== 'production' && warn(
'Templates should only be responsible for mapping the state to the ' +
'UI. Avoid placing tags with side-effects in your templates, such as ' +
`<${tag}>` + ', as they will not be parsed.'
)
}
//2、以下是处理属性中各类指令,从attrsList中删除相关的属性,
// apply pre-transforms
for (let i = 0; i < preTransforms.length; i++) {
element = preTransforms[i](element, options) || element
}
if (!inVPre) {
processPre(element)
if (element.pre) {
inVPre = true
}
}
if (platformIsPreTag(element.tag)) {
inPre = true
}
if (inVPre) {
processRawAttrs(element)
} else if (!element.processed) {
// structural directives
processFor(element)
processIf(element)
processOnce(element)
// element-scope stuff
processElement(element, options)
}
function checkRootConstraints (el) {
if (process.env.NODE_ENV !== 'production') {
if (el.tag === 'slot' || el.tag === 'template') {
warnOnce(
`Cannot use <${el.tag}> as component root element because it may ` +
'contain multiple nodes.'
)
}
if (el.attrsMap.hasOwnProperty('v-for')) {
warnOnce(
'Cannot use v-for on stateful component root element because ' +
'it renders multiple elements.'
)
}
}
}
// tree management
//3、构建AST模型树
if (!root) {
//如第一个元素,设置根元素
root = element
checkRootConstraints(root)
} else if (!stack.length) {
//其他元素,构建关联关系
// allow root elements with v-if, v-else-if and v-else
if (root.if && (element.elseif || element.else)) {
checkRootConstraints(element)
addIfCondition(root, {
exp: element.elseif,
block: element
})
} else if (process.env.NODE_ENV !== 'production') {
warnOnce(
`Component template should contain exactly one root element. ` +
`If you are using v-if on multiple elements, ` +
`use v-else-if to chain them instead.`
)
}
}
if (currentParent && !element.forbidden) {
if (element.elseif || element.else) {
processIfConditions(element, currentParent)
} else if (element.slotScope) { // scoped slot
currentParent.plain = false
const name = element.slotTarget || '"default"'
;(currentParent.scopedSlots || (currentParent.scopedSlots = {}))[name] = element
} else {
//建立父子element关系
currentParent.children.push(element)
element.parent = currentParent
}
}
//4、非单元素,将元素push到stack数组,
if (!unary) {
currentParent = element
stack.push(element)
} else {
closeElement(element)
}
}忽略掉其中的细节处理,主要有四部分:
1. createASTElementを呼び出して、ラベル要素のASTモデルオブジェクトを作成します。」
export function createASTElement (
tag: string,
attrs: Array<Attr>,
parent: ASTElement | void
): ASTElement {
return {
type: 1,//1-标签,2-表达式text,3-普通内容
tag,//标签
attrsList: attrs,//标签属性数组
attrsMap: makeAttrsMap(attrs),//标签属性map
parent,//父元素
children: []//子元素
}
}3番目の部分では、ここで定義されている最終的なASTモデルについて説明しました。ASTモデルは、タグ、属性、関連する親子要素など、タグ要素の関連情報を定義するリテラルオブジェクトです。
2.属性内のさまざまな命令を処理し、関連する属性をattrsListから削除して、後続の処理の準備をします。
3. ASTモデルツリーを作成します。最初のタグ要素は、この例のdivなどのルート要素として機能し、次のタグ要素は、親と子を設定することで関連付けを確立します。最終的にはツリーを形成します。
4.非単一要素の場合は、現在のAST要素をスタック配列にプッシュします(上記のスタックとの違いに注意してください。2つによって保存されるオブジェクトは異なり、また、後者の終了のための閉ループの準備です)。単一要素の場合、closeElementを呼び出して処理を終了します。
そんなに多くを言って、私は実際に<div id = "app">行を処理しました。次に、whileループは次の2行を処理し続け、プロセスは同じです。
<ul>
<li v-for="item in items">6、テキスト
開始タグの処理が完了した後、次の行が解析されると、「<」で始まらないため、テキストとして処理されます。
itemid:{{item.id}}
</li>
</ul>
</div>次のコードブロックを入力してください
let text, rest, next
if (textEnd >= 0) {
rest = html.slice(textEnd)
while (
!endTag.test(rest) &&
!startTagOpen.test(rest) &&
!comment.test(rest) &&
!conditionalComment.test(rest)
) {
// < in plain text, be forgiving and treat it as wen
//普通文本中包含的<字符,作为普通字符处理
next = rest.indexOf('<', 1)
if (next < 0) break
textEnd += next
rest = html.slice(textEnd)
}
//1、获取text内容,并步进到新的位置
text = html.substring(0, textEnd)
advance(textEnd)
}
//html的<字符匹配结束,将剩余字符都作为text处理
if (textEnd < 0) {
text = html
html = ''
}
//2、创建text的AST模型
if (options.chars && text) {
options.chars(text)
}1. textendによると、テキストコンテンツの前の文字(つまり</ li>)を取得します。itemid:{{item.id}}。
2. charsを呼び出して文字を処理します。ASTモデルを作成します。
その主なロジックを見てみましょう:
chars (text: string) {
...
//创建AST模型
if (text) {
let res
//包含表达式的text
if (!inVPre && text !== ' ' && (res = parseText(text, delimiters))) {
children.push({
type: 2,
expression: res.expression,
tokens: res.tokens,
text
})
}
//纯文本的text
else if (text !== ' ' || !children.length || children[children.length - 1].text !== ' ') {
children.push({
type: 3,
text
})
}
}
}テキストを独自の要素の子としてASTモデルツリーに組み込みます。この場合は、<li>のタグ要素です。式がテキストに含まれているかどうか(つまり、「{{}}」)に応じて、2つのケースがあります。
1.式テキスト、タイプ3、および式とトークン属性を使用して式を保存します。
2.プレーンテキスト、タイプ2。
この例は最初のケースに属します。分析が完了すると、次のようになります。
{
"type": 2,
"expression": "\"\\n itemid:\"+_s(item.id)+\"\\n \"",
"tokens": [
itemid:",
{"@binding": "item.id"},
"\n "
],
"text": "\n itemid:{{item.id}}\n "
}式とトークンの内容を見ることができます。これらについては後で詳しく分析します。
テキストテキスト分析が完了し、タグで処理が終了します。
七、終わり
終了タグまで解析した後、タグの要素オブジェクトに対して閉ループ処理が実行されます。HTMLの残りの部分を読み続ける
</li>
</ul>
</div>処理されたコードスニペット:
const endTagMatch = html.match(endTag)
if (endTagMatch) {
const curIndex = index
//步进结束tag的长度
advance(endTagMatch[0].length)
parseEndTag(endTagMatch[1], curIndex, index)
continue
}html.match(endTag)は、タグの終了文字であると判断された</ xx>などの通常の文字と一致し、現在の終了文字の位置をcurIndexに記録し、終了タグの長さをステップし、parseEndTagを呼び出して処理します。
function parseEndTag (tagName, start, end) {
...
// Find the closest opened tag of the same type
//1、从stack数组中查找结束的tag标签,并记录位置pos
if (tagName) {
for (pos = stack.length - 1; pos >= 0; pos--) {
if (stack[pos].lowerCasedTag === lowerCasedTagName) {
break
}
}
} else {
// If no tag name is provided, clean shop
pos = 0
}
//2、当pos>0,关闭从pos到最后的所有元素,理论上只会有一个,但也要防止不规范多写了结束标签
if (pos >= 0) {
// Close all the open elements, up the stack
for (let i = stack.length - 1; i >= pos; i--) {
if (process.env.NODE_ENV !== 'production' &&
(i > pos || !tagName) &&
options.warn
) {
options.warn(
`tag <${stack[i].tag}> has no matching end tag.`
)
}
//处理end
if (options.end) {
options.end(stack[i].tag, start, end)
}
}
// Remove the open elements from the stack
//从stack中删除元素
stack.length = pos
lastTag = pos && stack[pos - 1].tag
} else if (lowerCasedTagName === 'br') {
...
}
}1.スタックでタグを見つけます。プロセスの最初に、各タグの一致オブジェクトをスタックにプッシュします。この例では、スタックに3つのオブジェクトがあります
[{タグ:div、...}、{タグ:ul、...}、{タグ:li、...}]
後ろから前に、3番目のオブジェクトliに一致させます。posを2として記録します。
2. pos> 0がラベルが一致することを示す場合、処理のためにendメソッドが呼び出され、オブジェクトがスタックから削除されます。
end () {
// remove trailing whitespace
//从AST中查找该标签的模型对象
const element = stack[stack.length - 1]
//删除text为空格的child
const lastNode = element.children[element.children.length - 1]
if (lastNode && lastNode.type === 3 && lastNode.text === ' ' && !inPre) {
element.children.pop()
}
// pop stack
//stack中删除该模型模型对象,并变更当前的currentParent
stack.length -= 1
currentParent = stack[stack.length - 1]
//关闭
closeElement(element)
}endメソッドは、タグ要素オブジェクトの閉ループ処理を行い、ASTモデルオブジェクトをスタックから削除し、現在の親オブジェクトを更新します。
処理が完了したら、</ li>、</ ul>、</ div>などのタグの処理を続行します。
parseHTMLがすべてのhtml文字の処理を完了すると、parseメソッドまでさかのぼって、最後にASTモデルツリーのルートオブジェクトを返します。
八、総
この章では、解析プロセスの分析に焦点を当てます。以下では、フローチャートを使用してプロセス全体を分類します