B +ツリー
B +ツリーは、InnoDBストレージエンジンは、B +ツリーインデックスが、その構造を実現使用することで、外部メモリのインデックス構造を実現することがより適切にするためにBツリーに基づいた最適化です。
各ノードは、上で構成図でBツリーからのデータ、およびデータ値を含んで我々だけでなく、キーの値を見ることができます。データは、各ノード(すなわち、ページ)のための大規模なデータをもたらす場合に、メモリ・ページの各々は、記憶された大量のデータはまた、B-につながる場合、キーの小さな数を格納することができ、限定されますより大きな深さの木、Iクエリ/ O回、それによって、クエリの効率に影響を与えるディスクを増やします。B +ツリーでは、すべてのノードが同じレベルのリーフノードの順に格納された鍵データレコードに従っているだけでなく、大幅に各ノードに格納されたキー値の数を増加させることができるリーフノード情報のキー値を格納します減少高さ+ツリーB.
B +ツリーは、Bツリーに対して異なる点を有します。
非リーフノードは、鍵情報のみを保存します。
これは、すべてのリーフノード間のポインタのチェーンを持っています。
データレコードは、リーフノードに格納されています。
Bツリーは、非リーフノードのB +ツリーは、各ディスクは4つの主要ブロックとポインタ情報を格納することができると仮定すると、唯一のキー情報を格納するため、最適化では、次のようにB +ツリー構造でありなります図:
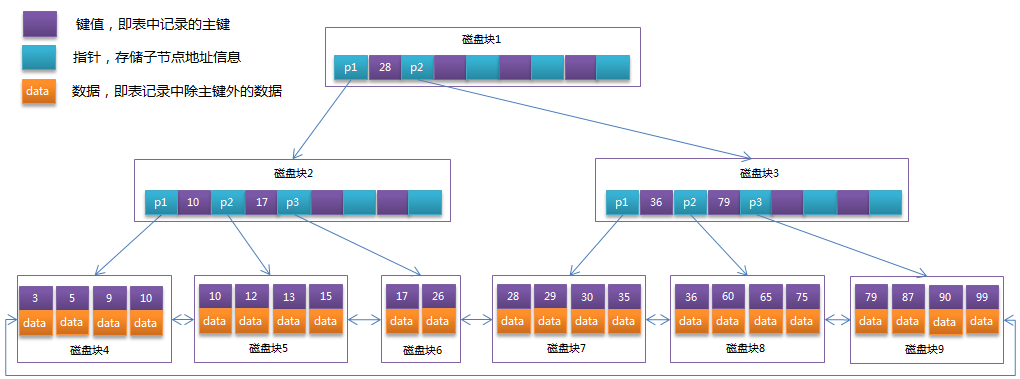
そこB +ツリーは、ルートノードへのポインタに2つのヘッド・ポインタは、別のキーワード最小のリーフノードを指し、通常は、環構造は、すべてのリーフノードのうち鎖(すなわち、ノードデータ)です。したがって、2つの検索操作は、B +ツリー上で実行することができる:一つは、主キーの範囲を検索するためのものであり、タブを見つけ、他のルートノード、ランダムサーチからのものです。
図22は、作られた投影下に、B +ツリーの利点を参照し、上記の例では、データレコードであってもよいです。
InnoDBストレージエンジンのページ・サイズは16キロバイト、主キーテーブルINTの一般的なタイプ(4バイト)、またはBIGINT(8バイト)であり、ポインタ型と言うことであること、また、典型的には4または8バイトでありますページは、(B +ツリーノードである)は、約16キロバイト/((B)+(b))1Kキー値=(計算の便宜のために推定値であるように、K ^ 3 10〗〖の値)に格納されています。それは3 B + Treeインデックスの深さ10 ^ 3 * 3 * 10 ^ 10 ^ 3 = 10億回の記録を維持することが可能です。
実際の状況での各ノードは、2〜4層に一般的にデータベース、B +ツリーの高さ故に充填し、されなくてもよいです。設計のInnoDBストレージエンジンMySQLは、これだけ1〜3回のディスクI / O操作の最大キー値列を探していることを意味する永久メモリのルートです。
B +ツリーインデックスデータベースは、クラスタ化インデックス(クラスタ化インデックス)とセカンダリインデックス(二次索引)に分けることができます。B +ツリーは、リーフノードの集合インデックスB +ツリーは、テーブル全体のデータ行に格納され、図データベースインデックス上記の例では、集約され得ます。補助リーフノードクラスタ化インデックスとの間の屈折率差は、行のすべてのデータが含まれていない二次的指標であるが、すなわち行に対応するインデックスキー、主キーをクラスタ化データが格納されます。二次インデックスを介してデータを照会する場合、InnoDBストレージエンジンは、主キーを見つけるために二次インデックスをトラバースし、次いで主キークラスタ化インデックスによって記録されたデータの完全なラインを見つけます。
HASH
直接データ構造にアクセスするためのキーコード値(キー値)に基づいて(また、ハッシュ・テーブルと呼ばれるハッシュテーブル)ハッシュテーブル。つまり、キー値によってレコードにアクセスするには、テーブルに検索をスピードアップするために位置をマッピングされます。ストレージアレイを記録し、ハッシュ関数と呼ばれるこのマッピング関数は、ハッシュテーブルと呼ばれます。
ハッシュテーブルハッシュテーブルは、実際には非常に単純な、キーを固定アルゴリズム関数によって整数に変換される(キー、値)の両方は、デジタルアレイモジュロ長、ハッシュ関数と呼ばれます私は、配列の添字の結果としてそれを取る、配列は次の年のためにデジタルに格納された値にスペースの対象となります。
ハッシュテーブルを使用するクエリは、ハッシュ関数が再び対応するインデックス配列に変換キー、および目標値取得スペース、この方法を使用するときそして、私たちはデータを検索する機能配列をフルに活用することができますポジショニング。
最大の利点のハッシュテーブルは、大幅にほぼ一定の時間として、見つけるために、消費するデータストレージと時間を削減することである。しかし、コストはちょうどより多くのメモリ消費量です。しかし、利用可能な電流より多くのメモリに、時間的なアプローチのためのスペースを使用することは価値があります。また、コードも簡単に、その機能の一つです。また、ハッシュテーブルハッシュテーブルとして知られている「オープンハッシュ」とに分け「閉ハッシュ。」
ハッシュインデックスB-treeインデックス差
特殊ハッシュインデックス構造は、検索効率が配置されるとインデックスがブランチノード、あまりページにアクセスする最後のノードへのルートからB-Treeインデックスのニーズは異なり、取得することができ、非常に高いですIOアクセス時間、そのクエリ効率のハッシュインデックスはB-Treeインデックスよりもはるかに高いです。
(1)ハッシュインデックスのみが「=」を満たすことができ、「IN」および「<=>」クエリは、クエリの範囲を使用することができません。
ハッシュインデックスハッシュ値の比較は、ハッシュ演算の後に行われるので、それが唯一の理由サイズ関係ハッシュ値対応するハッシュアルゴリズムによって処理した後、使用することができないフィルタの範囲に基づいて、等価をフィルタリングするために使用することができる、ことができず前とハッシュ動作を確実とまったく同じ。
(2)ハッシュインデックスは、操作データ分類を回避するために使用することができません。
インデックスは、次のハッシュ、ハッシュ値との大小関係を介して算出されたハッシュハッシュ値を格納され、データベース操作の任意の並べ替えを避けるために、インデックスデータを使用できないような値は、ハッシュ演算前と必ずしも厳密に同じではないからです。
(3)ハッシュインデックスは、インデックスキーのクエリの一部を使用することはできません。
代わりに、一方の前面または複合インデックスキーのいくつかの、インデックスハッシュを介して、単独でクエリインデックスをハッシュ値を算出する、時間インデックスの組み合わせのために、ハッシュハッシュ値を算出する指標が計算され、次いで、複合インデックスキーのハッシュ値と結合します使用することはできません。
いつでも(4)ハッシュインデックスはテーブルスキャンを回避することはできません。
既に知られているように、ハッシュ演算によってインデックスキー後ハッシュインデックス、ハッシュ値により同一のハッシュ値が異なるインデックスキーの存在のために、ハッシュテーブルに格納された情報に対応するハッシュ計算結果と行ポインタもテイクを満たす特定の場合データのレコード数ハッシュキーを直接クエリハッシュインデックスから行うことができない、またはテーブル内の実際のデータ、および対応する結果にアクセスすることによって適切な比較を行うこと。
性能は必ずしも高い屈折率よりもBツリー(5)ハッシュインデックスは、大きなハッシュ値が等しい遭遇します。
あなたは、インデックスのハッシュを作成した場合、比較的低い選択のインデックスキーについては、その後、ハッシュ値に関連付けられたポインタ情報に格納されているレコードの数が多いでしょう。非常に面倒になりますログのいずれかを突き止めるためにこのように、貧しい全体的なパフォーマンスが得られ、表データに多くの訪問を浪費することになります。
----------------
免責事項:この記事は元の記事CSDNブロガー「ドードー・バロン」で、CC 4.0 BY-SAの著作権契約書に従って、再現し、元のソースとのリンクを添付してくださいこの文。
オリジナルリンクします。https://blog.csdn.net/Baron0071/article/details/86089914