目次
共通機能
機能の概念と特徴:
Java および js の関数の概念と一致
機能: データベース関数には戻り値が必要です (1 つの行と 1 つの列)
いくつかの機能タイプ
1.日付機能
now() は現在の日付を取得します。
例: select now();
day() は、指定された日付の日の部分を取得します。
例: select day(now());
month() 指定された日付の月の部分を取得します。
例: select month(now());
year() は、指定された日付の月の部分を取得します。
例: select year(now());
date_format() 日付を指定された形式の文字列に変換します;
例: select date_format(now(), '%Y-%m-%d %H:%i:%s ');
str_to_date(): 特定の形式の日付を日付に変換します;
例: select str_to_date('2017-01-06 10:20:30','%Y-%m-%d %H:%i :%s');
包括的な例:
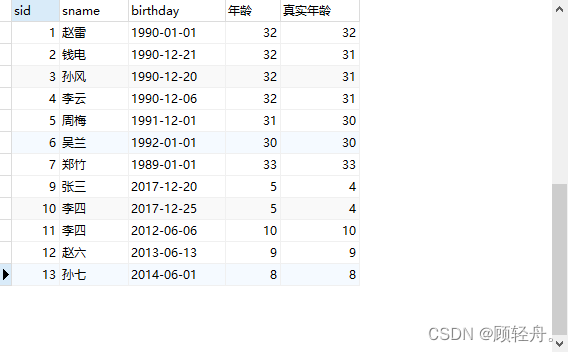
1)直接按年份计算学生年龄
SELECT t.sname, YEAR(NOW()) - YEAR(t.birthday) FROM t_student t
2)按照出生日期来算,当前月日 < 出生年月的月日则(说明月份还没到),年龄减一
SELECT sid,sname,birthday,YEAR(NOW())-YEAR(birthday) '年龄',
YEAR(NOW())-YEAR(birthday) + IF(CONVERT(DATE_FORMAT(NOW(),'%m%d'),SIGNED)-CONVERT(DATE_FORMAT(birthday,'%m%d'),SIGNED)<0,-1,0) '真实年龄'
FROM t_student;
3)查询本月过生日的学生信息
SELECT * FROM t_student t WHERE MONTH(NOW()) - MONTH(t.birthday) = 0;2) 実行結果の例は次のとおりです。
2. 文字列関数
upper() 大文字に変換します
例: select upper('faafafa')
lower() 小文字に変換します
例: Sselect lower('FEFEFF')
replace() 文字列内の部分文字列を検索して置換します
例: select replace( 'www. google.net','w','n')
substring() 特定の長さの位置から始まる最後の部分文字列
例:
select substring('abcdefghijk', 1, 3)
select substring((' abcdefghijk', 4);
select substring(('abcdefghijk', -3);
trim() 前後のスペースを削除
例: select trim(' fdfdfdfd ');
length()
文字列の長さを取得する例: select length('abcdef') ;
3. デジタル機能
floor() 切り捨て
例: select floor(123.8934);
ceil(
) 切り上げ例: select ceil(123.8934)
round()
切り捨て 例: select round(123.8934, 2);
4.集計機能
特徴: group by と組み合わせて使用するのが一般的ですが、単独で使用することもできます.たとえば、フィルター処理が必要な場合は、having 句
SUM を使用して合計
COUNT を使用してレコード数をカウントし、
AVG を使用して平均値を見つけることができます。
MAX は最大値を検索し、
MIN は最小値を検索します。
マージ
キーワード:
union すべてのクエリ結果をまとめて同じレコードを削除します。
union all 同じレコード を削除せずにすべてのクエリ結果を結合します。マージの前提: 結果セットに同じ数の列がある
使用シナリオ: プロジェクトの統計レポート モジュールで、データをマージするために使用されます
select 'abc', 123
union
selet 'def',456
select 'abc', 123
union
select 'abc', 123
select sid fromt_score where cid = 1
union
select sid from t_score where cid = 2
# 注意此处去掉了重复的值,可以与下面的语句执行结果比较
select sid fromt_score where cid = 1
union all
select sid from t_score where cid = 2
select 'abc', 123
union all
select 'def', 456
select 'abc', 123
union all
select 'abc', 123インデックスを見る
見る
コンセプトと機能:
ビューは一種の仮想テーブルで、データベース内の 1 つ以上のテーブルから派生したテーブルです。
データベースにはビューの定義が格納されますが、ビューのデータは格納されず、データは引き続きオリジナルテーブル。
ビューを使用してデータをクエリする場合、データベースは元のテーブルからデータを取得します
(注: マテリアライズド ビューはここには含まれません。現在、mysql はデフォルトでマテリアライズド ビューをサポートしていません)。
ビューの役割:1) 操作の簡素化
2) データ セキュリティ
の向上 3) テーブルの論理的独立性の向上
基本的な構文:
selectステートメントの例としてビュービュー名を作成します:create view stu_score_statistics as select t1.sid, t1.sname, t1.ssex, t2.courses, t3.total total_score from t_student t1 left join (select sid, count(*) courses from t_score group by sid) t2 on t1.sid=t2.sid left join (select sid, sum(score) total from t_score group by sid) t3 on t1.sid=t3.sid
索引
概念:
インデックスは、データベース テーブル内の 1 つまたは複数の列で構成され、その役割は、テーブル内のデータのクエリ速度を向上させる
ことであり、本のディレクトリの役割として理解できます。
長所と短所長所: 中規模または大規模なテーブルの場合、インデックスを適切に使用すると、クエリのパフォーマンスが大幅に向上します
短所: インデックスのメンテナンスの作業が増え、挿入、変更、および削除操作が遅くなります
分類:通常のインデックス(クエリのパフォーマンスを向上させることが目的の基本的なインデックス)一意
のインデックス(クエリのパフォーマンスを向上させるだけでなく、列の値の重複を回避することもできます) Null 値なし)結合インデックス(複数の列を結合して生成されるインデックス。インデックスの順序に注意する必要があります)全文インデックス(全文検索 (FULLTEXT) をサポートするために使用されます)
インデックスのメンテナンス:作成
構文
CREATE [UNIQUE|FULLTEXT] INDEX インデックス名 ON テーブル名 (フィールド名 [(長さ)][ASC|DESC])
例
CREATE INDEX sname_inx ON t_student(sname);
変更
構文
ALTER TABLE テーブル名 ADD [UNIQUE|FULLTEXT] INDEX インデックス名 (フィールド名[(長さ)][ASC|DESC])
例
ALTER TABLE t_student ADD INDEX birthday_inx(birthday);
削除
構文
DROP INDEX インデックス名 ON テーブル名
例
DROP INDEX birthday_inx ON t_student;
一般的なエラー コード
1075
には自動インクリメント キーがありますが、主キーとして設定されていないわけではありません.
1142一般
に権限がないため、操作は拒否されます.
1064
一般に、キーワード エラー、欠落などの構文エラーがあります。
1048
列を null にすることはできません
1055
GROUP BY に含まれていません
1265
保存されたデータの形式が定義と異なります1366
データ
エンコーディング
1451
外部キー制約違反