実際には、このブログを書くのアイデアは、主にtf2.0共通APIの使い方をいくつか説明されており、どのように迅速かつ容易にtf.kerasを用いたニューラルネットワークを構築します
積み木のように戦う、我々は簡単にビルドネットワークモデルは、彼らが構築することが可能なtf.kerasについて1.最初の話は、レイヤネットワークによって層が積み重なります。しかし、深い勾配ネットワークが消えるというように、これだけにも最適化するために、他の方法のいくつかの知識を必要とするモデルの結果にネットワークモデルを構築することができるようになります。
下のリンクを見てみることができますファッションmnistデータセットを導入するため
のGithub上のファッション・mnistを説明
一般的に、画像の最適化のために使用される一般的な分類について2.その後の話
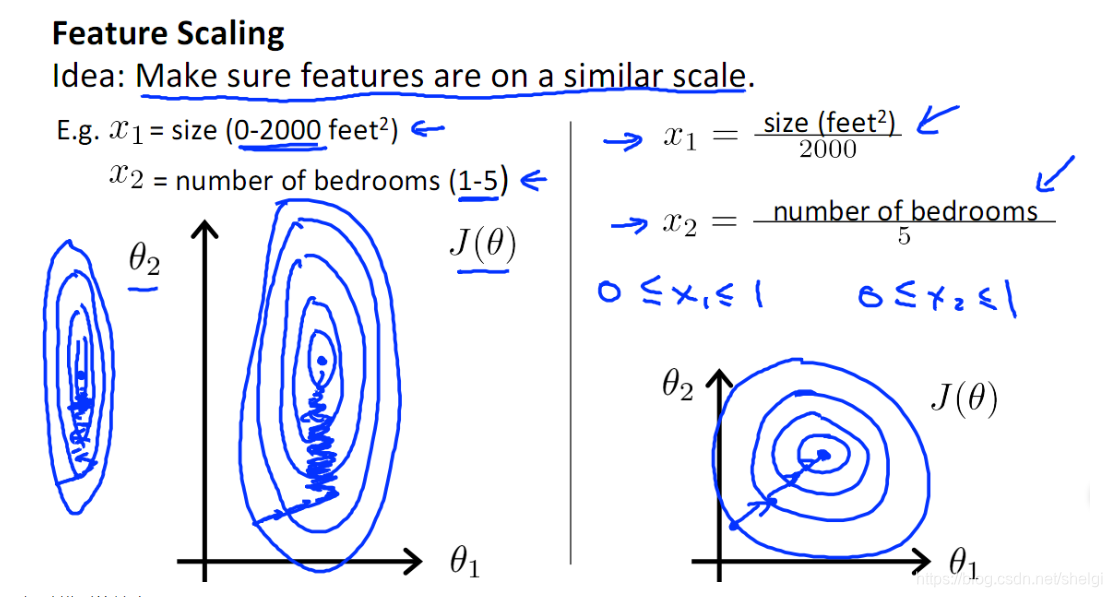
- 1.画像データの正規化(標準化):特定の原則は、センターが勾配に沿って紆余曲折なり、正式なグラフィカル到達せずに中心部に到達するための最速に沿って同心円状のグラデーションに想像することができ、ネットワークのコンバージェンスを加速
- 2.データの機能拡張:リンク
- 3.ネットワークのスーパー検索パラメータ:最高のモデルパラメータ、主にグリッドサーチ、ランダム探索、遺伝的アルゴリズム、ヒューリスティック検索を取得します
- アプリケーション4.dropout、earlystopping、正則化および他の方法:忘却、正則化と早期停止の層を追加することにより、オーバーフィットモデルを防ぐために
3.実装コードと結果セクション
#先导入一些常用库,后续用到再增加
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
import sklearn
import os
import sys
#看一下版本,确认是2.0
print(tf.__version__)
#使用keras自带的模块导入数据,并且切分训练集、验证集、测试集,对训练数据进行标准化处理
fashion_mnist=keras.datasets.fashion_mnist
(x_train_all,y_train_all),(x_test,y_test)=fashion_mnist.load_data()
print(x_train_all.shape)
print(y_train_all.shape)
print(x_test.shape)
print(y_test.shape)
#切分训练集和验证集
x_train,x_valid=x_train_all[5000:],x_train_all[:5000]
y_train,y_valid=y_train_all[5000:],y_train_all[:5000]
print(x_train.shape)
print(y_train.shape)
print(x_valid.shape)
print(y_valid.shape)
#标准化
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
x_train_scaled=scaler.fit_transform(x_train.astype(np.float32).reshape(-1,1)).reshape(-1,28,28)
x_valid_scaled=scaler.fit_transform(x_valid.astype(np.float32).reshape(-1,1)).reshape(-1,28,28)
x_test_scaled=scaler.fit_transform(x_test.astype(np.float32).reshape(-1,1)).reshape(-1,28,28)
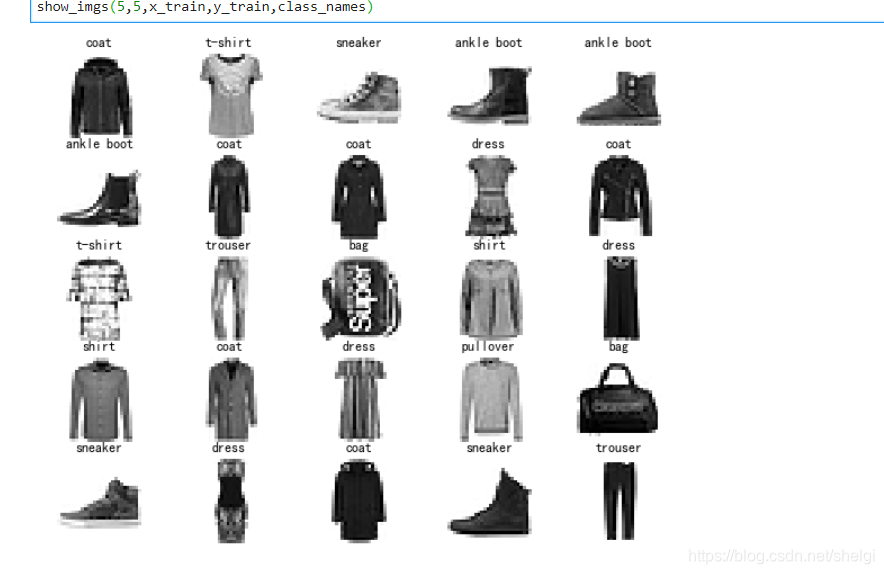
#可视化一下图片以及对应的标签
#展示多张图片
def show_imgs(n_rows,n_cols,x_data,y_data,class_names):
assert len(x_data)==len(y_data)#判断输入数据的信息是否对应一致
assert n_rows*n_cols<=len(x_data)#保证不会出现数据量不够
plt.figure(figsize=(n_cols*2,n_rows*1.6))
for row in range(n_rows):
for col in range(n_cols):
index=n_cols*row+col #得到当前展示图片的下标
plt.subplot(n_rows,n_cols,index+1)
plt.imshow(x_data[index],cmap="binary",interpolation="nearest")
plt.axis("off")
plt.title(class_names[y_data[index]])
plt.show()
class_names=['t-shirt', 'trouser', 'pullover', 'dress', 'coat', 'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
show_imgs(5,5,x_train,y_train,class_names)
#搭建网络模型
model=keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28,28]))
model.add(keras.layers.Dense(300,activation="relu"))
model.add(keras.layers.Dense(100,activation="relu"))
model.add(keras.layers.Dense(10,activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy",optimizer="adam",metrics=["acc"])
model.summary()
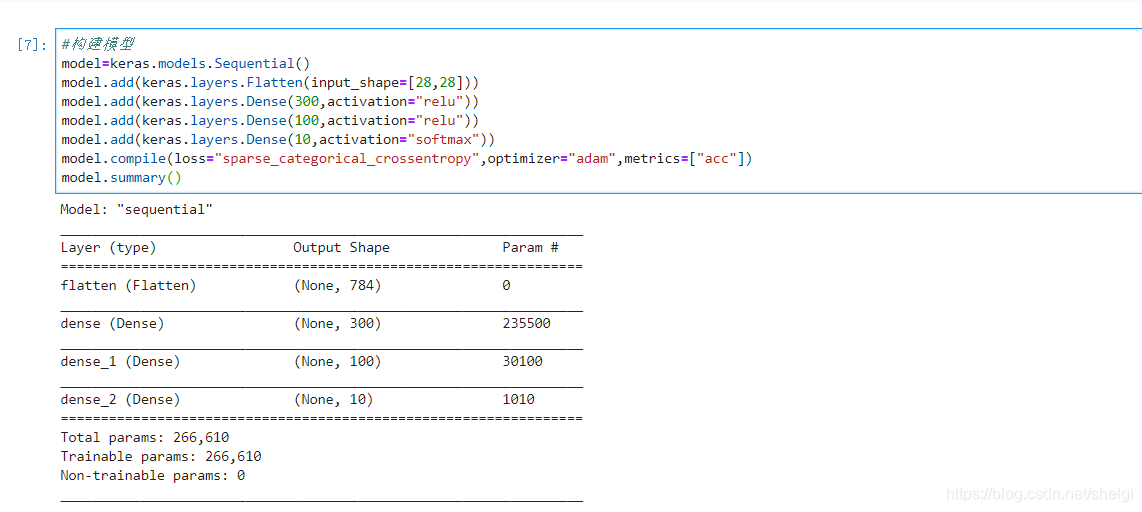
ここで行う方法でデジタルネットワーク情報をparamsは?
W = Y X + b及び(なし、300)の行列乗算(なし、784)からの規則に従って中間行列(784300)であり、バイアス項bの大きさは300であり、784そう 300 + 300 = 235500、これは小さなディテールだけの言及です。
#训练,并且保存最好的模型、训练的记录以及使用早停防止过拟合
import datetime
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
logdir = os.path.join('logs', current_time)
output_model=os.path.join(logdir,"fashionmnist_model.h5")
callbacks=[
keras.callbacks.TensorBoard(log_dir=logdir),
keras.callbacks.ModelCheckpoint(output_model,save_best_only=True),
keras.callbacks.EarlyStopping(patience=5,min_delta=1e-3)
]
history=model.fit(x_train_scaled,y_train,epochs=30,validation_data=(x_valid_scaled,y_valid),callbacks=callbacks)

私が間違っていることをTensorBoardとModelCheckpointランを使用して、指定されたフォルダを所有するために使用する前に、私は解決策、そしてオープンtensorboardルックである上に、Windows上のバグのようなビットを発見しました。
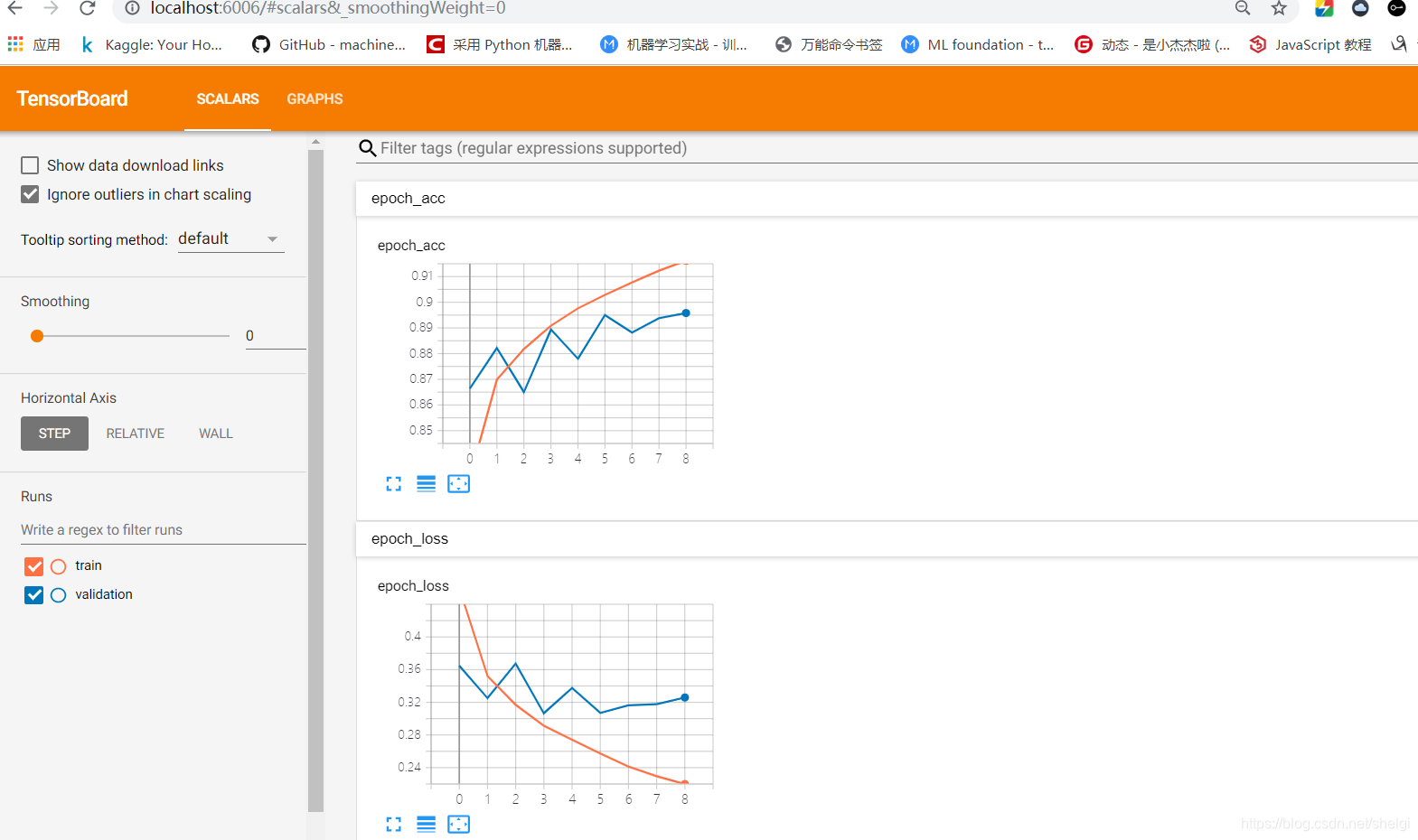

最良のモデルは、ファイルH5として保存され、簡単に呼び出し
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8,5))
plt.grid()
plt.gca().set_ylim(0,1)
plt.show()
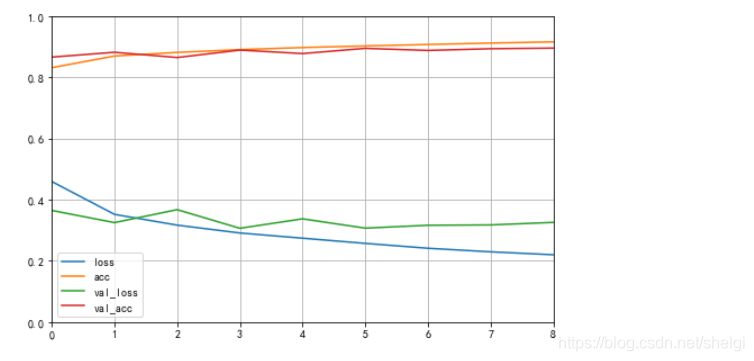
plot_learning_curves(history)
これは、ほぼ上記のトレーニングで自分の変化を描画するための時間であり、
#最后在测试集上的准确率
loss,acc=model.evaluate(x_test_scaled,y_test,verbose=0)
print("在测试集上的损失为:",loss)
print("在测试集上的准确率为:",acc)

#得到测试集上的预测标签,可视化和真实标签的区别
y_pred=model.predict(x_test_scaled)
predict = np.argmax(y_pred,axis=1)
show_imgs(3,5,x_test,predict,class_names)
show_imgs(3,5,x_test,y_test,class_names)
結果は予測

本当の結果を

4.まとめ:
上記の例を読んで、tf.keras建設モデルを使用することが書かれています
model=keras.models.Sequential()
model.add(...)
model.add(...)
...
model.compile(...)
model.fit(...)
#当然也可以写成
model=keras.models.Sequential([
...
...
...
])
#这两者差别不大
#还有函数式的写法
inputs=...
hidden1=...(inputs)
....
#子类的写法
class ...:
...
しかし、そのような選択のようなモデルパラメータ、(「sparse_categorical_crossentropy」と「categorical_crossentropy」または「binary_crossentropy」)あなたが最も適切な関数を使用する必要がある場合の損失のどのような種類の損失関数、ネットワークの各レイヤの活性化機能を選択し、オプティマイザのために私はここでの例では、スーパー検索パラメータに最適なモデルパラメータを使用して与えていない選択は......適切な状況で使用することができたの意味を理解する必要があり、次は検索のパラメータのスーパー例について書く必要があります。
