
Nous constatons que le mappage d'un domaine (édition) à un autre (le langage SQL spécifique au domaine) correspond bien aux atouts de LLM.
Traduit de Génération de schéma SQL avec de grands modèles de langage , auteur David Eastman.
J'ai examiné la persistance des expressions régulières et JSON générées à l'aide de LLM , mais beaucoup pensent que l'IA gère bien le langage de requête structuré (SQL) . Pour célébrer le 50e anniversaire de SQL , discutons des tables, en introduisant la terminologie technique si nécessaire. Cependant, je ne veux pas simplement tester la requête sur une table existante . Le monde des bases de données relationnelles commence avec Schema .
Un schéma décrit un ensemble de tables qui interagissent pour permettre aux requêtes SQL de répondre à des questions sur un modèle d'un système réel. Nous utilisons diverses contraintes pour contrôler la manière dont les tables sont liées les unes aux autres. Dans cet exemple, je développerai un schéma pour les livres, les auteurs et les éditeurs. Nous verrons ensuite si LLM peut reproduire ce travail.
Nous commençons par les relations entre nos choses . Un livre est écrit par un auteur et publié par un éditeur. En fait, la publication d'un livre définit la relation entre l'auteur et l'éditeur.
Ainsi, plus précisément, nous souhaitons produire les résultats suivants :
| Livre | Auteur | Éditeur | Date de sortie |
|---|---|---|---|
| La fabrique de guêpes | Iain Banks | Abaque | 16 février 1984 |
| Considérez Phlébas | Iain M. Banks | Orbite | 14 avril 1988 |
C'est agréable à lire (nous y reviendrons plus tard), mais le tableau lui-même n'est pas un bon moyen de conserver plus d'informations.
Si le nom de l'éditeur n'est qu'une chaîne, vous devrez peut-être le saisir plusieurs fois, ce qui est à la fois inefficace et sujet aux erreurs. L’auteur aussi. Ceux d'entre vous qui ont un penchant littéraire sauront que l'auteur des deux livres (Iain Banks) est la même personne, mais il a utilisé des pseudonymes légèrement différents pour écrire de la science-fiction.
Que se passe-t-il si le livre est réédité ultérieurement par un autre éditeur ? Pour garantir que ces deux événements de publication sont distingués, nous devons fournir à la fois le titre du livre et la date de sortie. Notre clé primaire ou notre identifiant unique doit donc inclure les deux. Nous voulons que le système rejette deux livres portant le même titre et la même date de publication.
Au lieu d'utiliser une grande table, nous utilisons trois tables et les référençons si nécessaire. Un pour l'auteur, un pour l'éditeur et un pour le livre. Nous écrivons les détails des auteurs dans la table Authors, puis nous les référençons dans la table Books à l'aide de clés étrangères .
Ainsi, ce qui suit est une table de schéma écrite en utilisant le langage de définition de données ( DDL ). J'utilise une variante de MySQL. Malheureusement, tous les fournisseurs conservent des dialectes légèrement différents.
Tout d’abord, il y a la table des auteurs. Nous ajoutons un index de colonne d'ID automatique comme clé primaire. Nous n'avons pas réellement résolu le problème du pseudonyme (je laisse cela au lecteur) :
CREATE TABLE Authors (
ID int NOT NULL AUTO_INCREMENT,
Name varchar(255) not null,
Birthday date not null,
PRIMARY KEY (ID)
);
La table des éditeurs suit le même modèle. "NOT NULL" est une autre contrainte qui empêche l'ajout de données sans contenu.
CREATE TABLE Publishers (
ID int NOT NULL AUTO_INCREMENT,
Name varchar(255) not null,
Address varchar(255) not null,
PRIMARY KEY (ID)
);
La table books fera référence à une clé étrangère, ce qui la rend logique mais un peu difficile à comprendre. Notez que nous respectons que le titre du livre et sa date de publication forment ensemble la clé primaire.
CREATE TABLE Books (
Name varchar(255) NOT NULL,
AuthorID int, PublisherID int,
PublishedDate date NOT NULL,
PRIMARY KEY (Name, PublishedDate),
FOREIGN KEY (AuthorID) REFERENCES Authors(ID),
FOREIGN KEY (PublisherID) REFERENCES Publishers(ID)
);
Pour voir une table soignée en haut, nous avons besoin d'une vue . Il s'agit simplement d'une façon d'assembler les tableaux afin que nous puissions sélectionner les informations que nous devons afficher tout en gardant le schéma intact. Maintenant que nous avons le schéma écrit, nous pouvons construire notre vue :
CREATE VIEW ViewableBooks AS
SELECT Books.Name 'Book', Authors.Name 'Author', Publishers.Name 'Publisher', Books.PublishedDate 'Date'
FROM Books, Publishers, Authors
WHERE Books.AuthorID = Authors.ID
AND Books.PublisherID = Publishers.ID;
Voyons si nous pouvons générer notre schéma dans un terrain de jeu en ligne afin de ne pas avoir à installer de base de données.
DB Fiddle devrait faire le travail.
Si vous entrez DDL puis ajoutez les données réelles :
INSERT INTO Authors (Name, Birthday)
VALUES ('Iain Banks', '1954-02-16');
INSERT INTO Authors (Name, Birthday)
VALUES ('Iain M Banks', '1954-02-16');
INSERT INTO Publishers (Name, Address)
VALUES ('Abacus', 'London');
INSERT INTO Publishers (Name, Address)
VALUES ('Orbit', 'New York');
Le résultat de l'affichage de la vue s'affiche sous la forme « Requête 3 » dans DB Fiddle, qui correspond exactement aux données que nous voulions voir :
LLM peut-il également créer des modèles ?
D'accord, nous voulons maintenant demander à LLM de créer le schéma. Pour résumer la façon dont nous espérons guider le LLM :
- Lorsque nous demandons le schéma en anglais, nous voulons qu'il génère du DDL pour les trois tables, y compris les index et les contraintes.
- Nous pouvons également impliquer la nécessité de contraintes (clés primaires, clés étrangères, etc.) si nécessaire.
- Nous pouvons demander à le voir.
- Nous pouvons lui demander d'utiliser la syntaxe MySQL si nécessaire.
J'utiliserai Llama 3 , mais j'ai également regardé le LLM d'OpenAI et j'ai obtenu à peu près les mêmes résultats.
Notre première requête : « Créer un schéma de base de données relationnelle pour décrire les livres, les éditeurs et les auteurs. »
résultat:
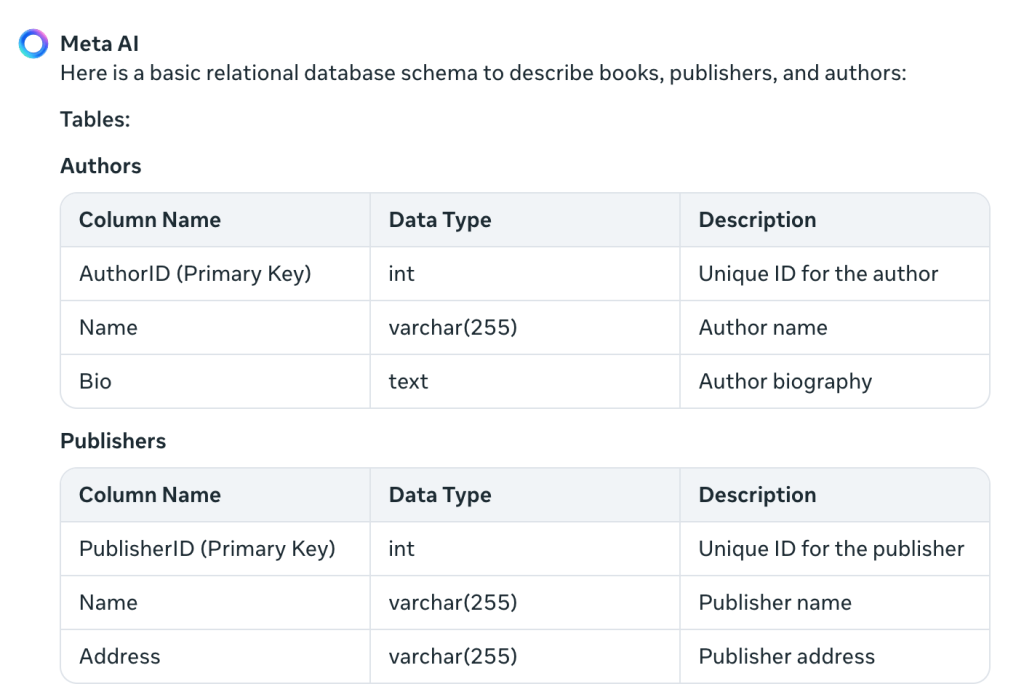
Jusqu'ici, tout va bien. Il n'a pas encore créé le DDL, mais nous pouvons le demander séparément. D'une manière ou d'une autre, il décrit mieux le modèle en anglais. Regardons le reste de la réponse :
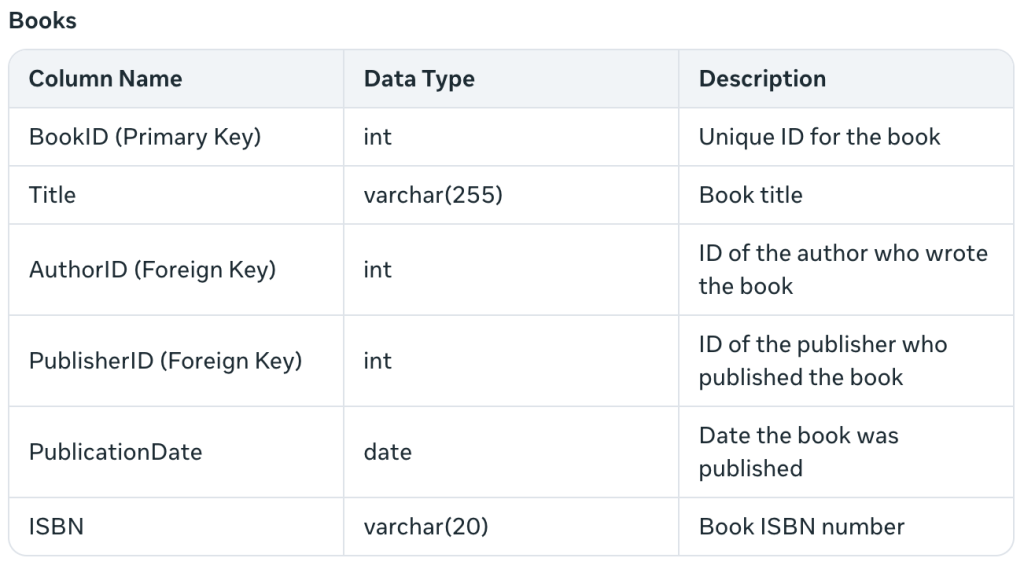
Il décrit les contraintes des clés étrangères et ajoute l'ISBN, ce à quoi je ne m'attendais pas. De plus, "PublicationDate" est plus idiomatique que mon "PublishedDate". Il crée également un tableau :
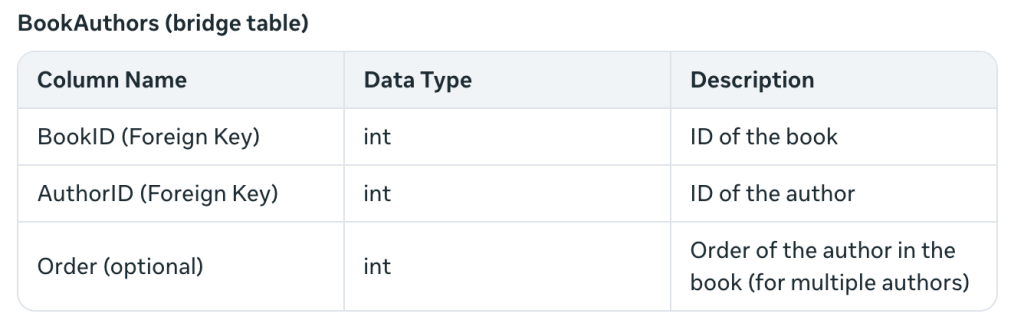
Cela résout le problème de la création de plusieurs auteurs pour un livre – ce que je n’avais pas envisagé auparavant. Le terme table pont indique que deux tables (livres et auteurs) sont reliées par une clé étrangère.
Demandons à DDL : "Montrez-moi le langage de définition de données pour ce schéma."
Ceux-ci sont renvoyés correctement, y compris les NOT NULL, pour garantir qu'il n'y a pas d'entrées vides. Il indique également que le DDL est « universel » à certains égards en raison des différences réelles entre les SQL des fournisseurs.
Enfin, demandons une vue :

C'est plus compliqué que ma version ; cependant, cela fonctionne bien dans DB Fiddle lorsque je m'adapte au nom de mon schéma. Le nom des alias de table vu ici n’est pas utile à la compréhension.
Conclusion : le LLM peut effectivement créer des modèles
Je pense que c'est une énorme victoire pour LLM car ils ont transformé ma description anglaise en un modèle bien contraint, puis en DDL exécutable, tout en fournissant également des explications (bien que ces explications soient devenues des détails de relation plus techniques). Je n'ai même pas utilisé de LLM ou de service dédié, donc cela a très bien fonctionné.
D'une certaine manière, il s'agit d'un mappage d'un domaine (le monde de l'édition) à un autre (le langage SQL spécifique au domaine), et c'est tout à fait à l'avantage de LLM. Chaque zone est bien définie et riche en détails.
Alors joyeux anniversaire à SQL et j'espère que LLM le gardera pertinent pendant encore quelques décennies !
Un programmeur né dans les années 1990 a développé un logiciel de portage vidéo et en a réalisé plus de 7 millions en moins d'un an. La fin a été très éprouvante ! Des lycéens créent leur propre langage de programmation open source en guise de cérémonie de passage à l'âge adulte - commentaires acerbes des internautes : s'appuyant sur RustDesk en raison d'une fraude généralisée, le service domestique Taobao (taobao.com) a suspendu ses services domestiques et repris le travail d'optimisation de la version Web Java 17 est la version Java LTS la plus utilisée Part de marché de Windows 10 Atteignant 70 %, Windows 11 continue de décliner Open Source Daily | Google soutient Hongmeng pour prendre le relais des téléphones Android open source pris en charge par Docker ; Electric ferme la plate-forme ouverte Apple lance la puce M4 Google supprime le noyau universel Android (ACK) Prise en charge de l'architecture RISC-V Yunfeng a démissionné d'Alibaba et prévoit de produire des jeux indépendants pour les plates-formes Windows à l'avenirCet article a été publié pour la première fois sur Yunyunzhongsheng ( https://yylives.cc/ ), tout le monde est invité à le visiter.