écrire devant
Bonjour à tous, je suis Liu Cong PNL.
À l'ère des grands modèles, non seulement les grands modèles deviennent de plus en plus volumineux, mais les critiques liées aux grands modèles deviennent également de plus en plus volumineuses. Aujourd'hui, je vous présente la dernière revue du réglage des instructions pour les grands modèles de langage. Le nom complet est "Instruction Tuning for Large Language Models: A Survey", qui vient de Zhihu@ Turtle Shell.
Paper: https://arxiv.org/pdf/2308.10792.pdf
知乎:https://zhuanlan.zhihu.com/p/656733177Le réglage des instructions (IT) est une technologie clé pour améliorer la capacité et la contrôlabilité des grands modèles de langage. Cette revue présente principalement la méthodologie générale de l'informatique, la construction d'ensembles de données informatiques, la formation de modèles informatiques, l'application de différents modes, domaines et applications, ainsi que l'analyse des aspects qui affectent les résultats informatiques (par exemple, la génération d'instructions). rendement, taille du jeu d'instructions, etc.), il passe également en revue les lacunes potentielles de l'informatique et ses critiques, pointe les lacunes des stratégies existantes et propose des pistes de recherche fructueuses.
Attention article long ! Il est recommandé de le lire lentement après l'avoir récupéré ! !
1. Introduction
Ces dernières années, la recherche sur les grands modèles de langage (LLM) a fait des progrès significatifs. Un problème majeur des LLM est l'inadéquation entre les objectifs de formation et les objectifs des utilisateurs : les LLM effectuent généralement une prédiction contextuelle de mots sur de grands corpus pour minimiser les erreurs de formation, alors que les utilisateurs attendent le modèle à suivre leurs instructions « utilement et en toute sécurité ». Pour résoudre ce problème, une technologie de réglage des instructions est proposée, qui est une technologie efficace pour améliorer la capacité et la contrôlabilité des grands modèles de langage. Cela implique une formation continue des LLM en utilisant (Instruction, sortie), où Instruction représente l'instruction manuelle pour le modèle et la sortie représente le résultat attendu correspondant à l'instruction. Les avantages de l'informatique sont triples : (1) le réglage fin des LLM sur l'ensemble de données d'instructions comble le fossé entre l'objectif des LLM de prédire le mot suivant et l'objectif de l'utilisateur de suivre les instructions ; (2) Par rapport aux LLM standards, l'informatique permet plus fiable Comportement du modèle contrôlable et prévisible. La fonction des instructions est de contraindre la sortie du modèle afin qu'elle soit conforme aux caractéristiques de réponse attendues ou aux connaissances du domaine, et de fournir un canal permettant aux humains d'intervenir dans le comportement du modèle ; (3) l'informatique est efficace sur le plan informatique et peut aider Les LLM s'adaptent rapidement à des domaines spécifiques sans nécessiter une grande quantité de recyclage ou de changements d'architecture.
Malgré son efficacité, l'informatique pose également un certain nombre de défis : (1) Produire des instructions de haute qualité qui couvrent de manière appropriée le comportement cible visé n'est pas trivial : les ensembles de données d'instructions existants sont souvent inférieurs en nombre, en variété et en créativité limitée ; (2 ) préoccupation croissante selon laquelle l'informatique n'améliorera que les tâches qui sont fortement prises en charge par les ensembles de données de formation informatique ; (3) l'informatique ne peut capturer que des modèles et des styles de surface plutôt que de comprendre et d'apprendre des tâches, ce qui est toujours une critique virulente. L’amélioration du respect des instructions et la gestion des réponses inattendues des modèles restent des questions de recherche ouvertes. Ces défis soulignent l'importance d'investigations, d'analyses et de résumés plus approfondis dans ce domaine pour optimiser le processus de réglage fin et mieux comprendre le comportement des LLM adaptés aux instructions.
2. Méthodes de recherche
2.1 Construction de l'ensemble de données d'instruction
Chaque instance de l'ensemble de données d'instructions se compose de trois éléments : une instruction, qui est une séquence de texte en langage naturel qui spécifie une tâche (par exemple, écrire une lettre de remerciement à XX pour XX, écrire un blog sur un sujet XX, etc.) ; Une entrée facultative qui fournit des informations supplémentaires sur le contexte et le résultat attendu en fonction de la directive et de l'entrée.
Il existe généralement deux manières de construire un ensemble de données d'instruction :
Intégrez des données à partir d’ensembles de données annotés en langage naturel. Dans cette approche, les paires d'étiquettes de texte sont converties en paires (instruction, sortie) à l'aide de modèles.
Utilisez des LLM pour générer une sortie : étant donné les instructions, utilisez des LLM, tels que GPT-3.5-Turbo ou GPT4, pour générer rapidement une sortie. Les instructions proviennent de deux sources : (1) la collecte manuelle ; (2) l'utilisation de LLM pour développer une petite instruction manuscrite sur les semences. Ensuite, envoyez les instructions collectées à llm pour obtenir le résultat.
2.2 Réglage des instructions
Sur la base de l'ensemble de données informatiques collectées, un modèle pré-entraîné peut être directement affiné de manière entièrement supervisée, en entraînant le modèle en prédisant chaque jeton dans la sortie en fonction des instructions et des entrées.
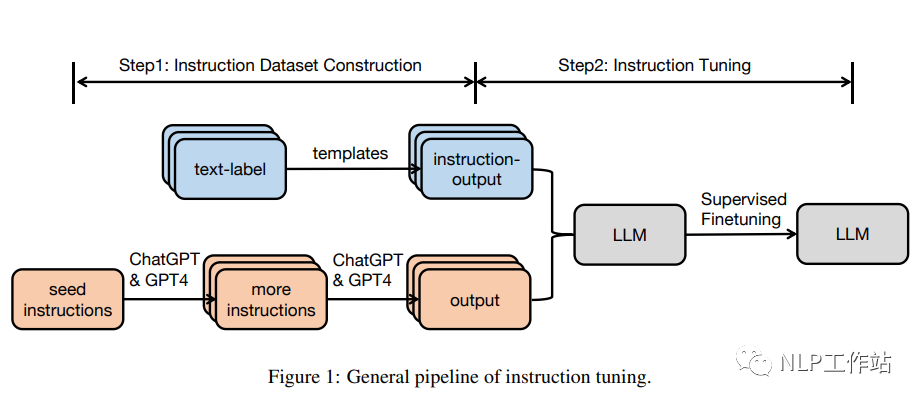
3. Ensemble de données
3.1 Instructions naturelles
Natural Instructions est un ensemble de données d'instructions en anglais conçues à la main contenant 193 000 instances de 61 tâches PNL différentes. Les ensembles de données sont constitués d'« instructions » et d'« instances ». Chaque instance d'une « instruction » est une description de tâche composée de 7 parties : titre, définition, choses à éviter, accentuations/avertissements, conseils, exemples positifs et exemples négatifs. La sous-figure (a) de la figure 2 donne un exemple d'« instruction ». Une « instance » est constituée de paires (« entrée », « sortie »), qui sont des données d'entrée et des résultats textuels qui suivent correctement les instructions données. La sous-figure (b) de la figure 2 en donne un exemple.

3.2P3
P3 (Public Pool of Prompts) est un ensemble de données de réglage fin des commandes construit à partir de 170 ensembles de données PNL en anglais et de 2 052 invites en anglais. Les invites, parfois appelées modèles de tâches, sont des fonctions qui mappent les instances de données dans les tâches PNL traditionnelles (par exemple, réponse aux questions, classification de texte) à des paires d'entrées-sorties en langage naturel.
Chaque instance dans P3 comporte trois composants : "inputs", "answer_choices" et "targets". La « saisie » est une séquence de texte qui décrit la tâche en langage naturel (par exemple, « S'il est vrai qu'il aime Mary, est-il également vrai qu'il aime le chat de Mary ? »). « Choix de réponses » est une liste de chaînes de texte qui constituent des réponses appropriées pour une tâche donnée (par exemple, ["oui", "non", "indéterminé"]). "Cibles" est une chaîne de texte qui constitue la réponse correcte à une "entrée" donnée (par exemple "oui"). L'auteur a créé PromptSource, un outil de création collaborative d'invites de haute qualité et une archive d'invites open source de haute qualité. L'ensemble de données P3 est construit en échantillonnant aléatoirement une invite parmi plusieurs invites dans PromptSource et en mappant chaque instance à un triplet (« entrée », « choix de réponse », « cible »).
3.3xP3
xP3 (Cross-Language Public Prompt Pool) est un ensemble de données d'instructions multilingues composé de 16 tâches différentes en langage naturel dans 46 langues. Chaque instance de l'ensemble de données comporte deux composants : "entrée" et "cible". La « entrée » est une description en langage naturel de la tâche. Les « cibles » sont les résultats textuels du suivi correct de la directive « entrées ».
Les données originales de xP3 proviennent de trois sources : l'ensemble de données d'instructions en anglais P3, 4 tâches implicites en anglais dans P3 (telles que la traduction, la synthèse de programme) et 30 ensembles de données PNL multilingues. Les auteurs ont construit l'ensemble de données xP3 en extrayant des modèles de tâches écrites par des humains à partir de PromptSource, puis en remplissant les modèles pour convertir différentes tâches NLP en une formalisation unifiée. Par exemple, le modèle de tâche de raisonnement en langage naturel est le suivant : "Si la prémisse est vraie, l'hypothèse est-elle également vraie ?" ; "Oui", "Possible", "Non" sont relatifs aux étiquettes de tâche d'origine " Implication (0)", "Neutralité (1)" et "Contradiction (2)".
3.4 Flanc 2021
Flan 2021 est un ensemble de données d'instructions en anglais construit en convertissant 62 benchmarks NLP largement utilisés (tels que SST-2, SNLI, AG News, MultiRC) en paires d'entrées-sorties de langue. Chaque instance de Flan 2021 comporte des composants « d'entrée » et « cible ». Une « entrée » est une séquence de texte décrivant une tâche via des instructions en langage naturel (par exemple, « Déterminez le sentiment de la phrase « Il aime les chats ». Positif ou négatif ?). "Target" est le résultat textuel de l'exécution correcte de l'instruction "input" (par exemple "positive"). Convertissez les ensembles de données de traitement du langage naturel traditionnels en paires entrée-cible : Étape 1 : Écrivez manuellement les instructions et les modèles cibles ; Étape 2 : Remplissez les modèles avec des instances de données de l'ensemble de données.
3.5 Instructions contre nature
Unnatural Instructions est un jeu d'instructions contenant environ 240 000 instances, construit à l'aide d'InstructGPT (text-davinci-002). Chaque instance de l'ensemble de données comporte quatre composants : instructions, entrées, contraintes et sorties. Les « instructions » sont des descriptions de tâches d'enseignement en langage naturel. Une saisie en langage naturel est un paramètre utilisé pour instancier une tâche d'instruction. Les contraintes sont des limites à l'espace de sortie des tâches. La sortie est une séquence de texte qui exécute correctement les instructions compte tenu des paramètres et des contraintes d'entrée. Les auteurs échantillonnent d’abord les instructions de départ à partir d’un ensemble de données d’instructions paranormales construit manuellement. Ensuite, ils ont proposé à InstructGPT d'introduire une nouvelle paire (instruction, entrée, contrainte), qui contient trois instructions de départ à titre de démonstration. Ensuite, les auteurs ont élargi l’ensemble de données en réécrivant de manière aléatoire les instructions ou les entrées. Les connexions d'instructions, d'entrées et de contraintes sont introduites dans InstructGPT pour obtenir une sortie.
3.6 Auto-formation
Self-Instruct (Wang et al., 2022c) est un ensemble de données d'enseignement de l'anglais construit à l'aide d'InstructGPT, contenant 52 000 instructions de formation et 252 instructions d'évaluation. Chaque instance de données se compose d'« instructions », d'« entrées » et de « sorties ». Les « instructions » sont des définitions de tâches en langage naturel (par exemple « Veuillez répondre aux questions suivantes »). "Entrée" est facultative et est utilisée comme contenu supplémentaire à la description (par exemple, "La capitale de quel pays est Pékin ?"), et "sortie" est un résultat textuel qui correspond à la description (par exemple, "Pékin"). Générez l'ensemble de données complet selon les étapes suivantes :
Étape 1 : L'auteur a sélectionné au hasard 8 instructions en langage naturel parmi 175 tâches de départ à titre d'exemples et a invité InstructGPT à générer davantage d'instructions de tâches.
Étape 2 : L'auteur détermine si l'instruction générée à l'étape 1 est une tâche de classification. Si tel est le cas, ils demandent à InstructGPT de générer toutes les options de sortie possibles en fonction des instructions données et de sélectionner au hasard une catégorie de sortie spécifique, invitant InstructGPT à générer le contenu « d'entrée » correspondant. Il devrait y avoir de nombreuses options de « sortie » pour les instructions qui ne sont pas des tâches classifiées. L'auteur a proposé une stratégie « entrée d'abord », qui invite d'abord InstructGPT à générer des « entrées » basées sur les « instructions » données, puis génère des « sorties » basées sur les « instructions » et les « entrées » générées.
Étape 3 : Sur la base des résultats de l'étape 2, l'auteur utilise InstructGPT pour générer « l'entrée » et la « sortie » de la tâche d'instruction correspondante, en utilisant la stratégie « sortie d'abord » ou « entrée en premier ».
Étape 4 : L'auteur a effectué un post-traitement sur les tâches d'instructions générées (par exemple, filtrer les instructions similaires, supprimer les données d'entrée et de sortie en double) et a finalement obtenu 52 000 instructions en anglais.
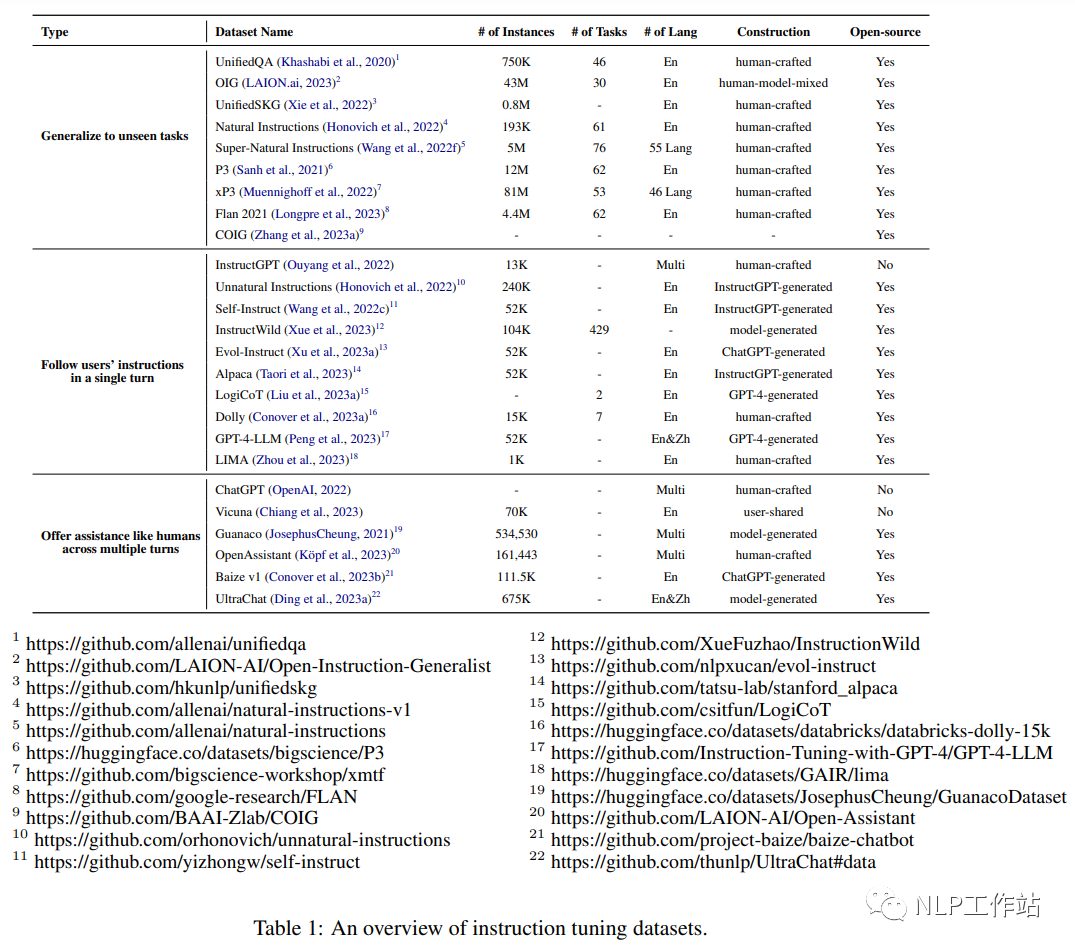
3.7 Evol-Instruire
Evol-Instruct est un ensemble de données d'instructions en anglais composé d'un ensemble de formation de 52 000 instructions et d'un ensemble d'évaluation de 218 instructions. Les auteurs ont incité ChatGPT (OpenAI, 2022) à réécrire les instructions en utilisant des stratégies d'évolution profondes et époustouflantes. La stratégie d'évolution profonde comprend cinq types d'opérations : l'ajout de contraintes, l'ajout d'étapes de raisonnement et l'augmentation de la complexité des entrées. La stratégie d'évolution inspiratoire met à niveau des instructions simples ou les met directement à niveau vers des instructions complexes pour générer une nouvelle instruction pour augmenter la diversité. L'auteur utilise d'abord 52 000 paires (commande, réponse) comme ensemble initial. Ils ont ensuite sélectionné au hasard une stratégie évolutive et ont demandé à ChatGPT de réécrire les instructions originales en fonction de la stratégie évolutive choisie. Utilisez ChatGPT et les règles pour filtrer les paires d'instructions non évoluées et mettre à jour l'ensemble de données avec les paires d'instructions évoluées nouvellement générées. Après avoir répété le processus ci-dessus 4 fois, l'auteur a collecté 250 000 paires d'instructions. En plus de l'ensemble de formation, les auteurs ont également collecté 218 instructions générées par l'homme à partir de scénarios réels (par exemple, des projets, des plateformes et des forums open source), appelés ensemble de test Evol-Instruct.
3.8 LIME
LIMA est un ensemble de données d'instructions en anglais composé d'un ensemble d'entraînement avec 1 000 instances et d'un ensemble de tests avec 300 instances. L'ensemble de formation contient 1 000 paires (« instruction », « réponse »). Pour les données de formation, 75 % des échantillons proviennent de trois sites Web communautaires de questions et réponses (c'est-à-dire les ensembles de données Stack Exchange, wikiHow et PushshiftReddit (Baumgartner et al., 2020)), et 20 % sont codés manuellement par un groupe de auteurs inspirés par leurs intérêts. 5 % des échantillons proviennent de l'ensemble de données d'instructions paranormales (Wang et al., 2022d). Pour l'ensemble de validation, les auteurs ont échantillonné 50 instances de l'ensemble écrit par les auteurs du groupe A. L'ensemble de test contient 300 exemples, dont 76,7 % ont été obtenus par un autre groupe (écrit par les auteurs du groupe B), 23,3 % des échantillons proviennent de l'ensemble de données Pushshift Reddit, qui est une collection de questions et réponses au sein de la communauté Reddit.
3.9 Instructions surnaturelles
Supernatural Instructions (Wang et al., 2022f) est un ensemble d'instructions multilingues composé de 1 616 tâches PNL et de 5 millions d'instances de tâches, couvrant 76 types de tâches différents (par exemple, classification de texte, extraction d'informations, réécriture de texte, création de texte, etc.) et 55 langues. . Chaque tâche de l'ensemble de données se compose d'une « instruction » et d'une « instance de tâche ». Plus précisément, « l'instruction » se compose de trois parties : une « définition » qui décrit la tâche en langage naturel ; un exemple positif, c'est-à-dire un échantillon de sortie correcte, et donner une brève explication de chaque échantillon ; et des "exemples négatifs", c'est-à-dire des échantillons d'entrée et de sortie non souhaitée, et une brève explication de chaque échantillon, comme le montre la figure 3(a). Une « instance de tâche » est une instance de données composée d'une entrée de texte et d'une liste de sorties de texte acceptables, comme le montre la figure 3(b). Les données brutes de Supernatural Directive proviennent de trois sources : (1) des ensembles de données PNL publics existants (tels que CommonsenseQA) ; (2) des annotations intermédiaires applicables générées par un processus de crowdsourcing (par exemple, dans l'ensemble de données QA crowdsourcing) Interprétation d'un problème donné) ; (3) Les tâches synthétiques, qui sont transformées à partir de tâches symboliques et exprimées en quelques phrases (telles que des comparaisons numériques et d'autres opérations algébriques).

3.10 Chariot
Dolly est un ensemble de données d'instructions en anglais contenant 15 000 exemples de données générées par l'homme, conçu pour permettre aux LLM d'interagir avec des utilisateurs similaires à ChatGPT. Cet ensemble de données est conçu pour simuler un large éventail de comportements humains et comprend 7 types spécifiques : questions-réponses ouvertes, questions-réponses fermées, extraction d'informations de Wikipédia, résumé d'informations de Wikipédia, brainstorming, classification et écriture créative. Des exemples de chaque type de tâche dans l'ensemble de données sont présentés dans le tableau 2.

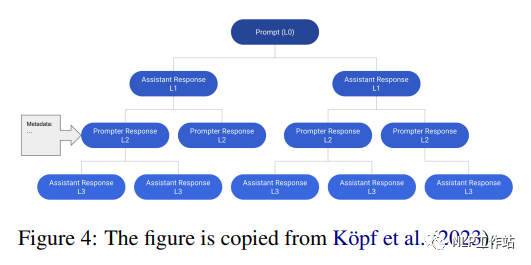
3.11 Conversations OpenAssistant
OpenAssistant Conversations est un corpus conversationnel multilingue de style assistant construit par l'homme, composé de 161 443 messages (c'est-à-dire 91 829 invites utilisateur, 69 614 réponses de l'assistant) provenant de 66 497 arbres de conversation en 35 langues et de 461 292 évaluations de masse annotées par l'homme. Chaque instance de l'ensemble de données est un arbre de conversation (CT). Plus précisément, chaque nœud de l'arborescence de session représente un message généré par un rôle dans la session (c'est-à-dire une invite, un assistant). Le nœud racine du CT représente l'invite initiale du prompteur, tandis que les autres nœuds représentent les réponses du prompteur ou de l'assistant. Le chemin de la racine vers n'importe quel nœud du CT représente une conversation valide entre l'invite et l'assistant dans une séquence, appelée fil d'exécution. La figure 4 montre un exemple d'arborescence de session contenant
12 messages dans 6 fils de discussion. L’auteur a d’abord rassemblé un arbre de dialogue basé sur un processus en cinq étapes :
Étape 1 : Invite : les contributeurs agissent comme des prompteurs, élaborant l'invite initiale ;
Étape 2 : Étiqueter les invites : les participants évaluent les invites initiales de la première étape et les auteurs sélectionnent les invites de haute qualité comme nœuds racines à l'aide d'une stratégie d'échantillonnage équilibrée ;
Étape 3 : Développez le nœud de l'arborescence : le contributeur ajoute un message de réponse sous forme d'invite ou d'assistant ;
Étape 4 : Annotation de réponse : les contributeurs notent les réponses des nœuds existants ;
Étape 5 : Classement : Classez les contributeurs conformément aux directives des contributeurs.
La machine à états arborescente gère et suit l'état (par exemple, l'état initial, l'état de croissance, l'état final) tout au long de la construction de la session. Par la suite, l’ensemble de données OpenAssistantConversations est construit en filtrant les arbres de conversation offensants et inappropriés.
3.12 Oui
Baize (Conover et al., 2023b) est un corpus de chat multi-tours anglais construit avec 111,5K instances utilisant ChatGPT. Chaque tour comprend les invites de l'utilisateur et les réponses de l'assistant. Chaque instance dans Baize v1 contient 3,4 sessions rondes. Pour créer l'ensemble de données Baize, les auteurs ont proposé un auto-chat, où ChatGPT joue à tour de rôle les rôles d'utilisateur et d'assistant IA, et génère des messages sous la forme d'une conversation. Plus précisément, l'auteur a d'abord conçu un modèle de tâches définissant les rôles et les tâches de ChatGPT (comme le montre le tableau 3). Ensuite, ils ont échantillonné des questions (par exemple, « Comment réparer un compte Google Play Store qui ne fonctionne pas ? ») à partir des ensembles de données Quora et Stack Overflow en tant que germes de conversation (par exemple, sujets). Ils ont ensuite demandé à ChatGPT des modèles et des graines échantillonnées. ChatGPT génère en continu des messages pour les deux parties jusqu'à ce qu'il atteigne un point d'arrêt naturel.

4. Instructions pour affiner les LLM

4.1 Instruction sur le GPT
InstructGPT (176B) (Ouyang et al., 2022) est initialisé à l'aide de GPT-3 (176B) (Brown et al., 2020b), puis affiné en fonction des instructions humaines. Le processus de réglage fin comprend les trois étapes suivantes :
(1) Réglage fin supervisé (SFT) des ensembles de données d'instructions de filtrage manuel en fonction de l'historique de l'API Playground ;
(2) En échantillonnant manuellement plusieurs réponses à une instruction et en les classant, un modèle de récompense basé sur des ensembles de données annotées est établi pour prédire les préférences humaines ;
(3) Utilisez de nouvelles instructions pour optimiser davantage le modèle à l'étape 1 et le modèle de récompense de formation à l'étape 2. Les paramètres sont mis à jour à l'aide de la méthode d'optimisation de politique proximale (PPO) (Schulman et al., 2017), qui est une méthode d'apprentissage par renforcement du gradient de politique. Les étapes (2) et (3) sont alternées plusieurs fois jusqu'à ce que les performances du modèle ne s'améliorent pas de manière significative.
Dans l’ensemble, InstructGPT est meilleur que GPT-3. En termes d'évaluation automatique, InstructGPT est 10 % plus véridique que GPT-3 sur l'ensemble de données TruthfulQA (Lin et al., 2021), et plus toxique que GPT sur l'ensemble de données RealToxicityPrompts (Gehman et al., 2020). 3 est 7% plus élevé. Sur l'ensemble de données NLP (c'est-à-dire WSC), InstructGPT atteint des performances comparables à celles de GPT-3. Lors de l'évaluation humaine, InstructGPT a surpassé GPT-3 de +10 %, +20 %, -20 % et +10 % dans quatre aspects : suivre des instructions correctes, suivre des contraintes claires, réduire les hallucinations et générer des réponses appropriées.
4.2 BLOOMZ
BLOOMZ (176B) (muenighoff et al., 2022) a été initialisé avec BLOOM(176B) (Scao et al., 2022), puis affiné sur l'ensemble de données d'instructions xP3 (muenighoff et al., 2022), un modèle humain de 46 langues. Collecte d'ensembles de données d'instructions, à partir de deux sources :
(1) P3, qui est un ensemble de paires (commande en anglais, réponse en anglais) ;
(2) Un ensemble de (instructions en anglais, réponses multilingues), converti à partir d'un ensemble de données PNL multilingue (comme le benchmark chinois) en remplissant le modèle de tâche avec des instructions en anglais prédéfinies.
En termes d'évaluation automatique, avec le paramètre d'échantillon zéro, BLOOMZ s'est amélioré de 10,4 %, 20,5 % et 9,8 % par rapport à BLOOM en termes de résolution de coréférence, de complétion de phrases et d'ensembles de données de raisonnement en langage naturel, respectivement. Dans le benchmark HumanEval (Chen et al., 2021), BLOOMZ a obtenu des résultats 10 % supérieurs à BLOOM en termes de métrique Pass@100. Pour les tâches de génération, BLOOMZ réalise une amélioration BLEU de +9% par rapport à BLOOM sur le benchmark lm-evaluation-harness.
4.3 Flan-T5
FLAN-T5 (11B) est un grand modèle de langage initialisé par T5 (11B) (Raffel et al., 2019) puis affiné sur l'ensemble de données FLAN (Longpre et al., 2023). L'ensemble de données FLAN est un ensemble de paires (instructions, paires) composées de 62 ensembles de données pour 12 tâches PNL (telles que le raisonnement en langage naturel, le raisonnement de bon sens, la génération de paraphrase, etc.) en remplissant divers modèles d'instructions sous la tâche unifiée. formalisation.Construire. Au cours du processus de réglage fin, FLAN-T5 a ajusté le framework T5X basé sur JAX de sorte que toutes les 2 000 étapes, le modèle optimal soit sélectionné en fonction des tâches de rétention évaluées. Par rapport à la phase de pré-formation du T5, le réglage fin nécessite 0,2 % de ressources informatiques en plus (environ 128 puces TPU v4 et 37 heures). En termes d'évaluation, le FLAN-T5 (11B) surpasse le T5 (11B) et obtient des résultats comparables à ceux des modèles plus grands, notamment PaLM (60B) (Chowdhery et al., 2022) dans un contexte de quelques prises de vue. Dans MMLU (Hendrycks et al., 2020), BBH (Suzgun et al., 2022), TyDiQA (Clark et al., 2020), MGSM (Shi et al., 2022), génération ouverte et RealToxicityPrompts (Gehman et al. , 2022) 2020), FLAN-T5 a surperformé T5 de +18,9%, +12,3%, +4,1%, +5,8%, +2,1% et +8%. Dans quelques cas, FLAN-T5 surpasse PaLM de +1,4 % et +1,2 % sur les ensembles de données BBH et TyDiQA.
4.4 Alpaga
Alpaca (7B) (Taori et al., 2023) est construit en affinant LLaMA (7B) (Touvron et al., 2023a) sur l'ensemble de données d'instructions de construction généré par InstructGPT (175B, text-davinci-003) (Ouyang et al., 2022) modèle de langage formé. Le processus de réglage fin a duré environ 3 heures sur un appareil A100 à 8 cartes de 80 Go avec une formation à précision mixte et un parallélisme complet des données partagées. En termes d'évaluation humaine, Alpaca (7B) a obtenu des performances comparables à InstructGPT (175B, text-davinci-003). Plus précisément, Alpaca surpasse InstructGPT sur l'ensemble de données autoguidé, atteignant 90 instances gagnantes au lieu de 89.
4.5 Vicogne
Vicuna (13B) (Chiang et al., 2023) est un modèle de langage entraîné en affinant LLaMA (13B) (Touvron et al., 2023a) sur l'ensemble de données de conversation généré par ChatGPT. L'auteur a collecté les sessions ChatGPT partagées par les utilisateurs sur le site Web http://ShareGPT.com, et après avoir filtré les échantillons de mauvaise qualité, 70 000 enregistrements de sessions ont été obtenus. LLaMA (13B) est affiné sur l'ensemble de données de session construit à l'aide d'une fonction de perte modifiée adaptée aux sessions multi-époques. Pour mieux comprendre les contextes longs dans les conversations à plusieurs tours, les auteurs étendent la longueur maximale du contexte de 512 à 2 048. En termes de formation, l'auteur utilise les technologies de point de contrôle de gradient et d'attention flash (Dao et al., 2022) pour réduire les coûts de mémoire GPU lors du réglage fin. Sur un appareil A100 de 8 × 80 Go avec un parallélisme de données entièrement partagé, le processus de réglage fin a pris 24 heures. Les auteurs ont construit un ensemble de tests spécialement conçu pour mesurer les performances des chatbots. Ils ont collecté un ensemble de tests composé de 8 catégories de problèmes, tels que les problèmes de Fermi, les scénarios de jeu de rôle, les tâches de programmation/mathématiques, etc., puis ont demandé au GP-4 (OpenAI, 2023) de prendre en compte l'utilité, la pertinence, l'exactitude et les détails. pour évaluer les réponses du modèle. Sur l'ensemble de tests construit, Vicuna (13B) surpasse Alpaca (13B) (Taori et al., 2023) et LLaMA (13B) produit autant ou mieux que ChatGPT dans 90 % des problèmes de test dans 45 % des réponses d'évaluation des problèmes. .
4.6 GPT-4-LLM
GPT-4-LLM(7B) (Peng et al., 2023) est un langage entraîné en affinant LLaMA (7B) (Touvron et al., 2023a) sur l'ensemble de données d'instructions généré par GPT-4 (OpenAI, 2023 ) Modèle. GPT-4-LLM est initialisé avec LLaMA puis affiné en deux étapes :
Affinement supervisé sur des jeux de données d'instructions construits. Les auteurs ont utilisé les instructions d'Alpaca (Taori et al., 2023), puis ont utilisé GPT-4 pour recueillir des commentaires. LLaMA est affiné sur l'ensemble de données généré par GPT-4. Le processus de réglage fin a duré environ 3 heures sur une machine 8*80GBA100 avec une précision mixte et un parallélisme de données entièrement partagé.
En utilisant la méthode d'optimisation de la politique proximale (PPO) (Schulman et al., 2017) pour optimiser le modèle de l'étape 1, l'auteur a d'abord collecté GPT-4, InstructGPT (Ouyang et al., 2022) et OPT-IML (Iyer et al. ., 2022) pour créer un ensemble de données de comparaison, puis laisser GPT-4 noter chaque réponse de 1 à 10. Utilisez les évaluations pour former un modèle de récompense basé sur l'OPT (Zhang et al., 2022a). Utilisez le modèle de récompense pour calculer le gradient politique afin d'optimiser le modèle ajusté à l'étape 1.
En termes d'évaluation, GPT-4-LLM (7B) surpasse non seulement le modèle de base Alpaca (7B), mais également les modèles plus grands, notamment Alpaca (13B) et LAMA (13B). En termes d'évaluation automatique, GPT-4-LLM (7B) a les meilleures performances dans les instructions orientées utilisateur-252 (Wang et al., 2022c), les instructions Vicuna (Chiang et al., 2023) et les instructions non naturelles ( Honovich et al., 2022) sont respectivement 0,2, 0,5 et 0,7 fois supérieurs à ceux de l'Alpaga. En termes d'évaluation humaine, les performances du GPT-4-LLM en termes d'utilité, de sincérité et d'innocuité sont respectivement 11,7, 20,9 et 28,6 supérieures à celles de l'Alpaga.
4.7 Claude
Claude est un modèle de langage formé en affinant un modèle de langage pré-entraîné sur un ensemble de données d'instructions, dans le but de générer des réponses utiles et inoffensives. Le processus de réglage fin comprend deux étapes :
(1) Superviser le réglage fin de l’ensemble de données d’instruction. Les auteurs ont créé un ensemble de données d’instructions en collectant 52 000 instructions différentes et en les associant aux réponses générées par GPT-4. Le processus de réglage fin a duré environ 8 heures sur une machine A100 à 8 cartes de 80 Go avec une précision mixte et un parallélisme de données entièrement partagé.
(2) Utilisez la méthode d’optimisation de la stratégie proximale pour optimiser le modèle étape 1. Les auteurs construisent d’abord un ensemble de données de comparaison en collectant les réponses de plusieurs grands modèles de langage (tels que GPT-3) à un ensemble d’instructions donné, puis en laissant GPT-4 noter chaque réponse. À l'aide des évaluations, un modèle de récompense est formé. Ensuite, le modèle de récompense et la méthode d’optimisation de la politique proximale sont utilisés pour optimiser le modèle de réglage fin à l’étape 1. Claude a produit des réponses plus bénéfiques et inoffensives que le modèle de base.
En termes d'évaluation automatique, les performances de toxicité de Claude sur RealToxicityPrompts sont 7 % supérieures à celles de GPT-3. Pour l'évaluation humaine, Claude a surpassé GPT-3 de +10 %, +20 % et -20 %, respectivement, dans quatre aspects différents, notamment suivre des instructions correctes, suivre des contraintes claires, réduire les hallucinations et générer des réponses appropriées. +10 %.
4.8 AssistantLM
WizardLM (7B) (Xu et al., 2023a) est un modèle de langage formé en affinant LLaMA(7B) sur l'ensemble de données d'instructions Evol-Instruct généré par ChatGPT. Il est affiné sur un sous-ensemble (70K) d'Evol-Instruct pour fournir une comparaison équitable avec Vicuna. Basé sur le GPU V100 à 8 cartes basé sur la technologie Deepspeed Zero-3, le réglage fin pour 3 époques prend environ 70 heures. Lors de l'inférence, la longueur maximale générée est de 2 048. Pour évaluer les performances des LLM sur des instructions complexes, les auteurs ont collecté 218 instructions générées par l'homme à partir de scénarios réels (par exemple, des projets, des plateformes et des forums open source), appelés ensemble de tests Evol-Instruct.
Évalué sur l'ensemble de tests Evol-Instruct et l'ensemble de tests Vicuna. En termes d'évaluation humaine, WizardLM a largement surpassé Alpaca (7B) et Vicuna (7B), produisant une réponse identique ou meilleure que ChatGPT dans 67 % des échantillons testés. L'évaluation automatisée est obtenue en demandant à GPT-4 d'évaluer les réponses des LLM. Plus précisément, par rapport à Alpaca, les performances de WizardLM se sont améliorées respectivement de 6,2 % et 5,3 % sur l'ensemble de tests Evol-Instruct et Vicuna. Par rapport à Vicuna, il est 5,8 % plus élevé sur l’ensemble de tests Evol-Instruct et 1,7 % plus élevé sur l’ensemble de tests Vicuna.
4.9 ChatGLM2
ChatGLM2 (6B) (Du et al., 2022) est un modèle linguistique entraîné en affinant GLM (6B) (Du et al., 2022) sur un ensemble de données bilingues contenant des instructions en chinois et en anglais. L'ensemble de données d'instructions bilingues contient 1,4T de jetons avec un rapport anglais-chinois de 1:1. Les instructions de l'ensemble de données sont extraites de tâches de réponse aux questions et de conclusion de conversations. ChatGLM utilise GLM pour l'initialisation, puis s'entraîne à l'aide d'une stratégie de réglage fin en trois étapes similaire à InstructGPT (Ouyanget al., 2022). Pour mieux simuler les informations contextuelles dans les conversations à plusieurs tours, les auteurs étendent la longueur maximale du contexte de 1 024 à 32 Ko. Afin de réduire le coût en mémoire de l’étape de réglage fin du GPU, des stratégies d’attention multi-requêtes et de masque causal sont utilisées. Pendant le processus d'inférence, ChatGLM2 utilisant FP16 nécessite 13 Go de mémoire GPU. Après avoir utilisé la technologie de quantification du modèle INT4, 6 Go de mémoire GPU peuvent être utilisés pour prendre en charge des sessions jusqu'à 8K. Les évaluations sont menées sur quatre critères d'évaluation en anglais et en chinois, notamment MMLU (anglais), C-Eval (chinois), GSM8K (mathématiques) et BBH (anglais). Dans tous les benchmarks, ChatGLM2 (6B) surpasse GLM (6B) et le modèle de base ChatGLM (6B). Plus précisément, ChatGLM2 est +3,1 meilleur que GLM sur MMLU, +5,0 mieux que GLM sur C-Eval, +8,6 mieux que GLM sur GSM8K et +2,2 mieux que GLM sur BBH. Sur MMLU, C-Eval, GSM8K et BBH, les performances de ChatGLM2 sont améliorées respectivement de +2,1, +1,2, +0,4 et +0,8 par rapport à ChatGLM.
4.10 LIME
LIMA (65B) (Zhou et al., 2023) est un grand modèle de langage formé en affinant LLaMA (65B) (Touvron et al., 2023a) sur l'ensemble de données d'instructions, qui est construit sur la base de l'hypothèse d'alignement de surface proposée. L'hypothèse d'alignement de surface signifie que les connaissances et les capacités du modèle sont acquises presque au stade de pré-formation, tandis que la formation alignée (par exemple, le réglage fin des instructions) permettra au modèle de répondre dans un état formalisé préféré par l'utilisateur. Sur la base de l'hypothèse de l'alignement des surfaces, les auteurs affirment que les grands modèles de langage peuvent générer des réponses satisfaisantes pour l'utilisateur en affinant un petit ensemble de données d'instruction. Par conséquent, l’auteur a construit l’ensemble de formation aux instructions/l’ensemble valide/l’ensemble de test pour vérifier cette hypothèse. Évaluez l’ensemble de test construit. En termes d'évaluation humaine, LIMA est respectivement 17 % et 19 % meilleurs qu'InstructGPT et Alpaca. De plus, LIMA a obtenu des résultats comparables à ceux de BARD, Cladue et GP-4. Pour l'évaluation automatisée, qui est effectuée en demandant à GPT-4 de noter les réponses, avec des scores plus élevés indiquant de meilleures performances, LIMA surpasse InstructGPT et Alpaca de 20 % et 36 % respectivement, obtenant des résultats comparables à BARD, tout en étant moins efficace que Claude et GP- 4. Les résultats expérimentaux valident l'hypothèse d'alignement de surface proposée.
4.11 Autres
Il existe également quelques autres modèles. Sans entrer dans les détails, les modèles sont les suivants :
OPT-IML (175B)
Chariot 2.0 (12B)
Faucon-Instruire (40B)
Guanaco (7B)
Minotaure (15B)
Nous-Herme (13B)
TÜLU (6,7B)
YuLan-Chat (13B)
MOUSSE (16B)
Airoboros (13B)
UltraLM (13B)
5. Affinement de l’enseignement multimodal
5.1 Ensembles de données multimodaux

MUL-TIINSTRUCT (Xu et al., 2022) est un ensemble de données de réglage d'instructions multimodales composé de 62 tâches multimodales différentes dans un format séquence à séquence unifié. L'ensemble de données couvre 10 catégories principales et ses tâches sont dérivées de 21 ensembles de données open source existants. Chaque mission est accompagnée de 5 instructions écrites par des experts. Pour les tâches existantes, les auteurs créent des instances en utilisant des paires entrée/sortie à partir des ensembles de données open source dont ils disposent. Pour chaque nouvelle tâche, les auteurs ont créé 5 000 à 5 millions d'instances en extrayant les informations nécessaires des instances de tâches existantes ou en les reconstruisant. L'efficacité de l'ensemble de données MUL-TIINSTRUCT pour améliorer diverses techniques d'apprentissage par transfert est vérifiée. Par exemple, affiner le modèle OFA (930M) à l’aide de plusieurs stratégies d’apprentissage par transfert, telles que l’ajustement des instructions hybrides et l’ajustement des instructions séquentielles sur MUL-TIINSTRUCT (Wang et al., 2022a), peut améliorer zéro sur toutes les tâches invisibles. . Dans la tâche VQA régulière, l'OFA optimisé sur MUL-TIINSTRUCT atteint 50,60 sur RougeL avec une précision de 31,17, tandis que l'OFA RougeL original est de 14,97 avec une précision de 0,40.
PMC-VQA (Zhang et al., 2023c) est un ensemble de données de réponses à des questions visuelles médicales à grande échelle contenant 227 000 paires image-question de 149 000 images, couvrant diverses modalités ou maladies. Cet ensemble de données peut être utilisé pour des tâches ouvertes et à choix multiples. Le processus de génération de l'ensemble de données PMC-VQA comprend la collecte de paires image-légende à partir de l'ensemble de données PMC-OA (Lin et al., 2023), l'utilisation de ChatGPT pour générer des paires question-réponse et la vérification manuelle de la qualité d'un sous-ensemble de l'ensemble de données. . Les auteurs proposent MedVInT, un modèle de compréhension visuelle médicale basé sur la génération qui aligne les informations visuelles avec de grands modèles de langage. MedVInt, pré-entraîné sur PMC-VQA, atteint des performances de pointe et surpasse les modèles existants sur les benchmarks VQA-rad (Lau et al., 2018) et SLAKE (Liu et al., 2021a), surpassant les modèles existants sur VQA -rad La précision sur SLAKE est de 81,6 % et la précision sur SLAKE est de 88,0 %.
LAMM (Yin et al., 2023) est un ensemble de données multimodal complet optimisé pour la compréhension des images 2D et des nuages de points 3D. LAMM contient 186 000 paires commande-réponse d’image de langage et 10 000 paires commande-réponse de nuage de points de langage. Les auteurs collectent des images et des nuages de points à partir d'ensembles de données accessibles au public et utilisent GPT-API et des méthodes d'auto-instruction pour générer des instructions et des réponses basées sur les étiquettes originales de ces ensembles de données. LAMM-Dataset comprend des paires de données pour répondre aux questions de connaissances de bon sens en intégrant le système d'étiquetage des graphiques de connaissances hiérarchiques et les descriptions Wikipédia correspondantes de l'ensemble de données Bamboo (Zhang et al., 2022b). Les auteurs ont également proposé LAMM-Benchmark pour évaluer les performances des modèles de langage multimodaux (MLLM) existants sur diverses tâches de vision par ordinateur. Il comprend 9 tâches d'image publique et 3 tâches de nuage de points publics, ainsi que le cadre LAMM, qui est un cadre de formation MLLM principal permettant de distinguer les blocs de réglage fin de l'encodeur, du projecteur et du LLM afin d'éviter les conflits modaux entre les différents modes.
5.2 Modèle de réglage fin des instructions multimodales
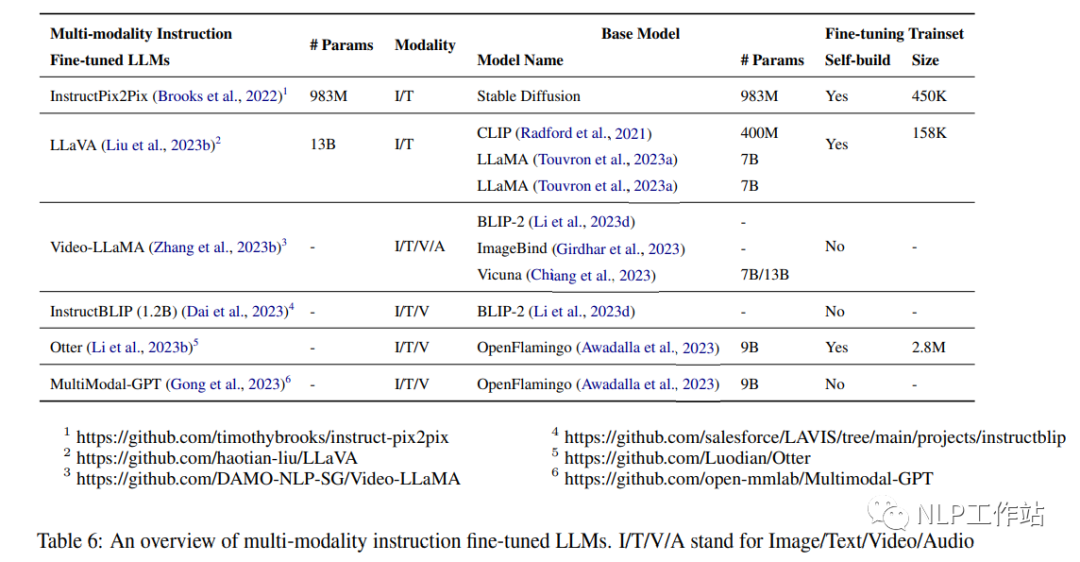
InstructPix2Pix (983M) (Brooks et al., 2022) est un modèle de diffusion conditionnelle affiné avec Stable Diffusion (983M) (Rombach et al., 2022) sur un ensemble de données multimodales construit contenant plus de 450 000 textes. Instructions d'édition et images correspondantes avant et après édition. Les auteurs ont combiné les capacités de deux modèles pré-entraînés à grande échelle, un modèle de langage GPT-3 (Brown et al., 2020b) et un modèle texte-image Stable Diffusion (Rombach et al., 2022), pour générer l’ensemble de données de formation. GPT-3 est optimisé pour générer des modifications de texte basées sur des signaux d'image, et Stable Diffusion est utilisé pour convertir les modifications de texte générées en modifications d'images réelles. InstructPix2Pix est ensuite formé sur cet ensemble de données généré à l'aide de cibles de diffusion latentes. La figure 5 montre le processus de génération d'un ensemble de données d'édition d'image et de formation d'un modèle de diffusion sur cet ensemble de données. Les auteurs ont comparé qualitativement la méthode proposée dans cet article avec des travaux antérieurs tels que SDEdit (Meng et al., 2022) et Text2Live (Bar-Talet et al., 2022), en soulignant que le modèle suit des instructions d'édition d'images plutôt que des descriptions d'images ou capacité d'édition des calques,. Les auteurs ont également effectué une comparaison quantitative avec SDEdit (Meng et al., 2022) en utilisant des métriques qui mesurent la cohérence de l'image et la qualité de l'édition.

LLaVA (13B) (Liu et al., 2023b) est un grand modèle multimodal combinant l'encodeur visuel CLIP (400M) (Radford et al., 2021) avec le décodeur de langage LLaMA(7B) (Touvron et al., 2023a) développé par connexion. LLaVA est affiné à l'aide d'un ensemble de données de langage visuel instruit généré composé de 158 000 instructions d'images verbales uniques suivant des échantillons. Le processus de collecte de données comprenait la création d'un dialogue, de descriptions détaillées et d'invites de raisonnement complexes. GPT-4 est utilisé pour convertir les paires image-texte dans un format de suivi d'instructions approprié pour cet ensemble de données. Les fonctionnalités visuelles telles que les titres et les bordures sont utilisées pour coder les images. Par rapport à GPT-4, LLaVA atteint un score relatif de 85,1 % sur les instructions multimodales synthétiques basées sur l'ensemble de données. Lorsqu'elle a été affinée sur Science QA, la synergie de LLaVA et GPT-4 a atteint une précision de pointe de 92,53 %.
Video-LLaMA (Zhang et al., 2023b) est un cadre multimodal qui améliore la capacité des modèles linguistiques à grande échelle à comprendre le contenu visuel et auditif des vidéos. Il comprend deux encodeurs de branche : la branche du langage visuel (VL) et la branche du langage audiovisuel (AL), ainsi qu'un décodeur de langage (Vicuna (7B/13B), LLaMA (7B). La branche VL comprend un encodeur d'image pré-entraîné gelé. (le composant visuel pré-entraîné de BLIP-2, qui comprend un ViT-G/14 et un Q-former pré-entraîné), une couche d'intégration de position, un Q-former vidéo et une couche linéaire. La branche AL comprend un Encodeur audio pré-entraîné (ImageBind (Girdhar et al., 2023)) et un Q-former audio. La figure 6 montre l'architecture globale de Video-LLaMA, y compris la branche du langage visuel et la branche du langage audiovisuel. La branche VL est implémentée dans Webvid-2M (Bain et al. ., 2021) ensemble de données de sous-titres vidéo et effectuer des tâches de génération vidéo-texte et affiner les données de réglage des instructions de MiniGPT-4, LLaVA et VideoChat. La branche AL est formée sur la vidéo/image données de description, connectez la sortie d'ImageBind à un décodeur de langue. Après un réglage fin, Video-LLaMA peut percevoir et comprendre le contenu vidéo, démontrant sa capacité à intégrer des informations auditives et visuelles, à comprendre des images statiques, à reconnaître les concepts de bon sens et à capturer des informations temporelles. dynamique dans les vidéos.
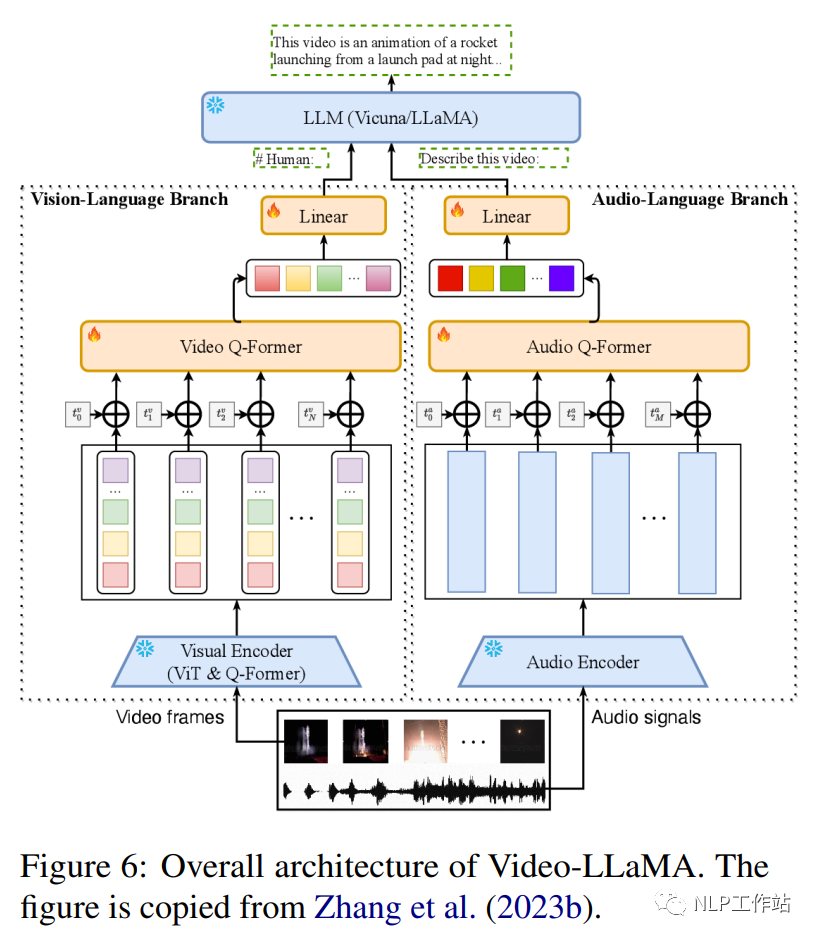
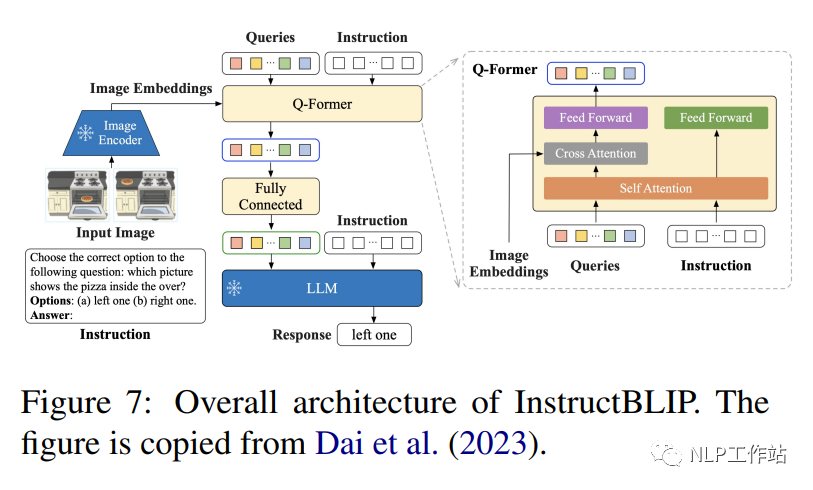
InstructBLIP (1.2B) (Dai et al., 2023) est un cadre de réglage des instructions de langage visuel, initialisé avec BLIP-2 pré-entraîné, et le modèle se compose d'un encodeur d'image, d'un grand modèle de langage (FlanT5 (3B/11B) ou Vicuna (7B/13B) et un transformateur de requête (Q-Former) pour connecter les deux. Comme le montre la figure 7, Q-Former extrait les caractéristiques visuelles sensibles aux instructions de l'intégration de sortie de l'encodeur d'image figée et saisit les caractéristiques visuelles. sous forme d'invites logicielles entrées dans un LLM gelé. Les auteurs ont évalué les performances du modèle InstructBLIP sur une variété de tâches de langage visuel, y compris la classification d'images, le sous-titrage d'images, la réponse à des questions d'images et le raisonnement visuel. Ils ont utilisé 26 ensembles de données accessibles au public, en les divisant en 13 ensembles de données de formation et 13 ensembles de données d'évaluation. Les auteurs démontrent qu'InstructBLIP atteint des performances de pointe sur une variété de tâches de langage visuel. Par rapport à BLIP-2, InstructBLIP atteint une amélioration relative moyenne de 15,0 %, avec le plus petit InstructBLIP (4B) obtient une amélioration relative moyenne de 24,8 % sur les 6 ensembles de données d'évaluation partagés, surpassant Flamingo (80B) (Alayrac et al., 2022).
Otter (Li et al., 2023b) est un modèle multimodal entraîné par le réglage fin d'OpenFlamingo (9B) (Awadalla et al., 2023). Le langage et les encodeurs visuels sont fixes, et seuls le module de rééchantillonnage du perceptron et le cross- l'attention est affinée.Les calques et les intégrations d'entrée/sortie. Les auteurs ont organisé une variété de tâches multimodales couvrant 11 catégories et ont construit un ensemble de données de réglage d'instructions contextuelles multimodales MIMIC-IT contenant 2,8 millions de paires instruction-réponse multimodales, qui consiste en une composition de triplet image-instruction-réponse, où l'instruction-réponse est adaptée. à l'image. Chaque échantillon de données comprend également un contexte, qui contient une séquence de triplets image-instruction-réponse associés contextuellement aux triplets de la requête. Comparé à OpenFlamingo, Otter démontre la capacité de suivre les instructions de l'utilisateur avec plus de précision et de fournir des descriptions d'images plus détaillées.
MultiModal-GPT (Gong et al., 2023) est un modèle de réglage d'instructions multimodal capable d'exécuter différentes instructions, de générer des sous-titres détaillés, de calculer des objets spécifiques et de résoudre des requêtes générales. MultiModal-GPT est formé en affinant l'ensemble de données ouvert OpenFlamingo (9B) sur une variété de données d'instructions visuelles créées, notamment VQA, les sous-titres d'images, le raisonnement visuel, l'OCR de texte et le dialogue visuel. Les expériences démontrent la capacité de MultiModal-GPT à entretenir des conversations continues avec les gens.
6. Affinement des consignes dans des domaines précis
6.1 Dialogues
InstructDial (Gupta et al., 2022) est un cadre de réglage des instructions conçu pour les conversations. Il contient une collection de 48 tâches de dialogue dans un format texte-texte cohérent créé à partir de 59 ensembles de données de dialogue. Chaque instance de tâche comprend une description de tâche, des entrées d'instance, des contraintes, des instructions et des sorties. Pour assurer l'exécution des instructions, le framework introduit deux méta-tâches : (1) la tâche de sélection d'instruction, où le modèle sélectionne l'instruction correspondant à une paire d'entrée-sortie donnée ; (2) la tâche d'instruction binaire, si l'instruction est de l'entrée-sortie au donné En sortie, le modèle prédit « oui » ou « non ». Deux modèles de base T0-3B (version paramétrique 3B de T5) et BART0 (modèle 406M basé sur Bart) ont été affinés sur la tâche d'InstructDial. InstructDial obtient des résultats impressionnants sur des ensembles de données et des tâches de dialogue invisibles, notamment l'évaluation du dialogue et la détection d'intention. De plus, elle donne de meilleurs résultats lorsqu’elle est appliquée à un petit nombre d’échantillons.
6.2 Classification des intentions et marquage des emplacements (Slot Tagging)
LINGUIST, basé sur le réglage fin d'AlexaTM 5B, est un modèle multilingue de 5 milliards de paramètres pour la tâche de classification des intentions et d'étiquetage des emplacements des ensembles de données d'instructions. Chaque instruction se compose de cinq blocs : (i) le langage dans lequel la sortie est générée, (ii) l'intention, (iii) le type de slot et la valeur contenue dans la sortie (par exemple, le chiffre 3 dans [3,snow] correspond au type d'emplacement, snow est la valeur utilisée par cet emplacement), (iv) un mappage des étiquettes de type d'emplacement aux nombres et (v) jusqu'à 10 exemples indiquant le format de la sortie. Dans un nouveau paramètre d'intention utilisant 10 clichés de l'ensemble de données SNIPS, LINGUIST réalise des améliorations significatives par rapport aux méthodes de pointe. Dans le cadre multilingue à probabilité zéro de l'ensemble de données mATIS++, LINGUIST surpasse les bases de référence solides pour la traduction automatique alignée sur les emplacements dans 6 langues tout en conservant les performances de classification d'intention.
6.3 Extraction d'informations
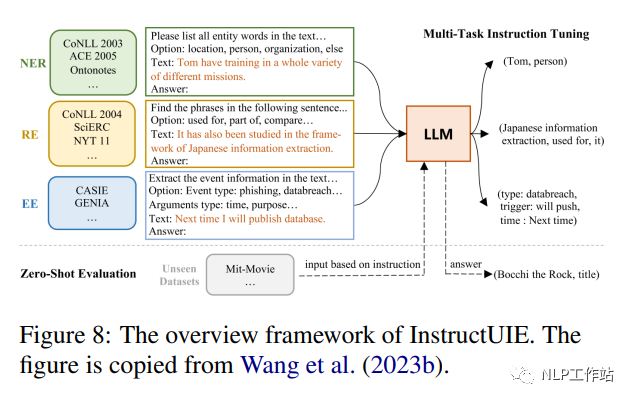
InstructUIE (Wang et al., 2023b) est un cadre d'extraction d'informations (IE) unifié basé sur le réglage des instructions, qui convertit la tâche IE au format seq2seq et la résout en affinant 11B FlanT5 sur l'ensemble de données informatiques construit pour ces questions. La figure 8 montre l'architecture globale d'InstructUIE. Cet article présente la commande IE, une référence basée sur 32 ensembles de données d'extraction d'informations différents dans un format texte-texte unifié, avec des commandes écrites par des experts. Chaque instance de tâche est décrite par quatre attributs : instructions de tâche, options, texte et sortie. Les instructions de tâche contiennent des informations telles que le type d'informations à extraire, le format de la structure de sortie et des contraintes ou règles supplémentaires qui doivent être suivies pendant le processus d'extraction. Les options font référence aux contraintes d'étiquette de sortie de la tâche et le texte fait référence aux phrases d'entrée. Le résultat s'effectue en convertissant l'étiquette originale de l'échantillon (par exemple : "étiquette d'entité : entity span" dans NER). Dans le cadre supervisé, InstructUIE fonctionne à égalité avec BERT (Devlin et al., 2018) et surpasse le GPT3.5 de pointe dans le cadre zéro tir.
6.4 Analyse des sentiments basée sur les aspects
Varia et al. (2022) ont proposé un cadre unifié de réglage des instructions pour résoudre les tâches d'analyse des sentiments basée sur les aspects (ABSA), basé sur le modèle T5 (220M) affiné (Raffel et al., 2019). La sous-tâche multifactorielle gérée par ce cadre implique les quatre éléments de l'ABSA, à savoir les termes d'aspect, les catégories d'aspect, les termes d'opinion et les émotions. Il traite ces sous-tâches comme une combinaison de cinq tâches de questions et réponses, transformant chaque phrase du corpus à l'aide du modèle d'instruction fourni pour chaque tâche. Par exemple, un modèle d'instruction utilisé est « Quel est le terme d'aspect dans texte :$text ? » Le cadre démontre une amélioration substantielle (8,29 F1 en moyenne) par rapport au scénario d'apprentissage en quelques étapes de pointe et le maintient dans le scénario complet de réglage fin diminue la comparabilité.
6.5 Écriture
Zhang et al. (2023d) ont proposé Writing-Alpaca-7B, qui affine LLaMa-7B sur l'ensemble de données d'instructions d'écriture pour fournir une aide à l'écriture. L'ensemble de données d'instructions proposé est une extension du benchmark EITEVAL basé sur les données d'instructions, supprimant la tâche de mise à jour et introduisant une tâche syntaxique. Le schéma d'instruction suit strictement le schéma d'instruction du projet Stanford Alpaca, comprenant une préface générale, un champ d'instruction qui guide l'achèvement des tâches, un champ de saisie qui fournit le texte à modifier et un champ de réponse qui doit être rempli par le modèle. . Writing-Alpaca-7B améliore les performances de LLaMa sur toutes les tâches d'écriture et surpasse les autres LLM disponibles dans le commerce.
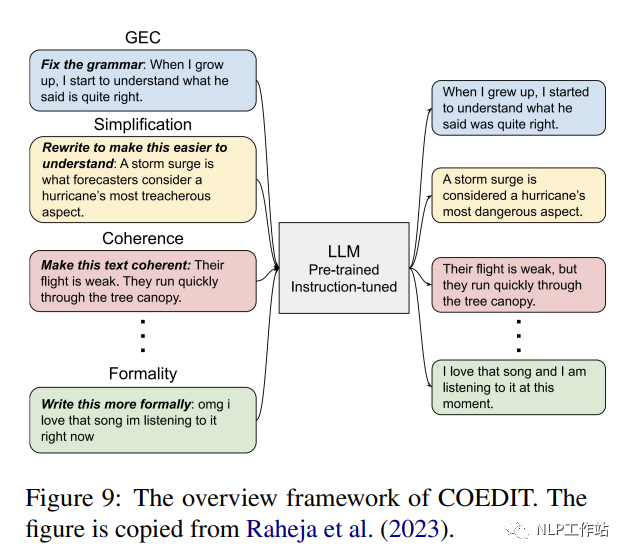
CoEdIT (Raheja et al., 2023) affine FLANT5 (paramètres 770M, paramètres 3B et paramètres 11B) pour l'édition de texte sur l'ensemble de données d'instructions afin de fournir une aide à l'écriture. Le jeu d’instructions se compose d’environ 82 000 paires de <instruction : source, cible>. Comme le montre la figure 9, le modèle accepte les instructions de l'utilisateur pour spécifier les caractéristiques du texte souhaitées, telles que « rendre la phrase plus simple », et génère le texte édité. CoEdIT atteint des performances de pointe dans plusieurs tâches d'édition de texte, notamment la correction des erreurs grammaticales, la simplification du texte, l'édition itérative de texte et trois tâches d'édition stylistique : le transfert de style formel, la neutralisation et la paraphrase. De plus, il se généralise bien à de nouvelles tâches adjacentes non vues lors du réglage fin.
CoPoet (Chakrabarty et al., 2022) est un outil collaboratif d'écriture de poésie qui exploite de grands modèles de langage (tels que les modèles T5-3B, T5-11B et T0-3B) formés sur une collection diversifiée d'instructions d'écriture de poésie. Chaque exemple de l'ensemble de données d'instructions contient une paire <instruction,poe_line>. Il existe trois grands types d'indications : la continuation, la retenue lexicale et la technique rhétorique. CoPoet est déclenché par des instructions utilisateur qui spécifient les attributs souhaités du poème, comme écrire une phrase sur « l'amour » ou terminer une phrase par « voler ». Ce système est non seulement en concurrence avec les LLM accessibles au public formés sur des instructions (tels que InstructGPT), mais est également capable de satisfaire des instructions synthétiques invisibles.
6.6 Médical
Radiology-GPT (Liu et al., 2023c) est un modèle Alpaca-7B affiné pour la radiologie qui utilise une méthode de réglage des instructions sur un large ensemble de données de connaissances dans le domaine de la radiologie. Les rapports de radiologie se composent généralement de deux sections correspondantes : « Résultats » et « Impressions ». La section « Résultats » contient des observations détaillées des images radiologiques, tandis que la section « Impressions » résume les interprétations dérivées de ces observations. Radiology-GPT fournit une brève description du texte des « résultats » : « Impressions dérivées des résultats des rapports de radiologie ». Le texte "Impression" dans le même rapport est affiché comme cible. Comparé aux modèles de langage généraux tels que StableLM, Dolly et LLaMA, Radiology-GPT est nettement plus polyvalent en matière de diagnostic radiologique, de recherche et de communication.
ChatDoctor (Li et al., 2023g) est basé sur le modèle LLaMA-7B affiné, exploitant l'ensemble de données d'instructions d'alpaga et l'ensemble de données de conversation patient-médecin HealthCareMagic100k. Les modèles d'invite sont conçus pour effectuer des recherches dans des bases de connaissances externes telles que des bases de données sur les maladies et des recherches sur Wikipédia lors de conversations médecin-patient afin d'obtenir des résultats plus précis du modèle. ChatDoctor améliore considérablement la capacité du modèle à comprendre les besoins des patients et à fournir des recommandations éclairées, la précision de ses réponses étant grandement améliorée grâce à la récupération autonome d'informations à partir de sources fiables en ligne et hors ligne.
ChatGLM-Med, basé sur le modèle ChatGLM-6B, a affiné l'ensemble de données sur l'enseignement médical chinois (Wang Haochun, 2023). L'ensemble de données d'instructions comprend des paires de questions et réponses liées à la médecine créées à l'aide de l'API GPT3.5 et du graphique de connaissances médicales. Ce modèle améliore les performances de réponse aux questions de ChatGLM dans le domaine médical.
6.7 Arithmétique
Goat (Liu et Low, 2023) est un modèle de LLaMA-7B basé sur des instructions affinées, conçu pour résoudre des problèmes arithmétiques. Il génère des centaines de modèles d'instructions en utilisant ChatGPT pour représenter des questions arithmétiques sous la forme de questions et réponses en langage naturel, telles que « Qu'est-ce que 8914/64 ? » Le modèle utilise diverses techniques pour améliorer son adaptabilité à différents formats de questions, tels que comme randomisation Supprimez les espaces entre les nombres et les symboles dans les expressions arithmétiques et remplacez "*" par "x" ou "times". Le modèle Goat atteint des performances de pointe sur les sous-tâches de l'algorithme BIG-bench. En particulier, le Goat7B à échantillon nul correspond ou dépasse le PaLM-540B à quelques échantillons.
6.8 Codes
WizardCoder (Luo et al., 2023) utilise StarCoder 15B comme base pour effectuer un réglage fin des instructions complexes en adaptant la méthode d'instruction d'évolution (Xu et al., 2023) au domaine du code. L'ensemble de données d'entraînement est obtenu en appliquant itérativement la technique Evol-Instruct sur l'ensemble de données Code Alpaca, qui comprend les propriétés suivantes de chaque échantillon : instructions, entrées et sorties attendues. Par exemple, lorsque l'instruction est « Modifier la requête SQL suivante pour sélectionner différents éléments », l'entrée est la requête SQL et la sortie attendue est la réponse générée. WizardCoder surpasse tous les autres LLM open source, même HumanEval et HumanEval+ surpassent les plus grands LLM comme Claude d'Anthropic et Bard de Google.
7. Techniques de réglage efficaces
Des techniques de réglage fin efficaces visent à optimiser un petit ensemble de paramètres de plusieurs manières, à savoir en fonction des ajouts, des spécifications et du reparamétrage, adaptant ainsi les LLM aux tâches en aval. Les méthodes basées sur les additions introduisent des paramètres ou des modules pouvant être entraînés supplémentaires qui ne sont pas présents dans le modèle d'origine. Les méthodes représentatives incluent le réglage de l'adaptateur (Houlsby et al., 2019) et le réglage basé sur des invites (Schick et Schütze, 2021). Les méthodes basées sur les spécifications spécifient certains paramètres intrinsèques du modèle à ajuster tout en gelant d'autres paramètres. Par exemple, BitFit (Zaken et al., 2022) ajuste le terme de biais du modèle pré-entraîné. La méthode de reparamétrage convertit les poids du modèle en une forme d'ajustement plus efficace en termes de paramètres. La clé est de supposer que l'adaptabilité du modèle est de bas rang, de sorte que les poids puissent être reparamétrés en facteurs de bas rang ou en sous-espaces de faible dimension ( comme LoRA (Hu et al., 2021)). L'invite intrinsèque découvre un sous-espace de faible dimension qui est partagé en ajustant les invites entre différentes tâches.
7.1 LoRA
L'adaptation de bas rang (LoRA) (Hu et al., 2021) peut permettre une adaptation efficace du LLM à l'aide de mises à jour de bas rang. LoRA utilise DeepSpeed (Rasley et al., 2020) comme colonne vertébrale de l'entraînement. L'idée clé de LoRA est que les changements réels dans les poids LLM nécessaires pour s'adapter aux nouvelles tâches existent dans un sous-espace de faible dimension. Plus précisément, pour une matrice de poids pré-entraînée W0, les auteurs modélisent la matrice de poids ajustée comme W0 + ΔW, où ΔW est une mise à jour de bas rang. ΔW est paramétré comme ΔW = BA, où A et B sont des matrices entraînables beaucoup plus petites. Nous choisissons le rang r de ΔW bien plus petit que la dimension de W0. L'intuition de l'auteur n'est pas d'entraîner tous les W0 directement, mais d'entraîner A et B de faible dimension, qui entraînent indirectement W0 dans un sous-espace de bas rang dans la direction pertinente pour la tâche en aval. Cela se traduit par beaucoup moins de paramètres pouvant être entraînés par rapport à un réglage fin complet. Pour GPT-3, LoRA réduit le nombre de paramètres pouvant être entraînés de 10 000 fois et l'utilisation de la mémoire de 3 fois par rapport à un réglage fin complet.
7.2 CONSEIL
HINT (Ivison et al., 2022) combine les avantages généraux du réglage des instructions avec un réglage fin efficace à la demande, évitant ainsi le traitement répété d'instructions longues. L'essence de HINT réside dans un hyperréseau qui génère des modules adaptatifs LLM efficaces en termes de paramètres, basés sur des instructions en langage naturel et un petit nombre d'exemples. L'hyperréseau adopté convertit les instructions et quelques exemples en instructions codées et génère des paramètres d'adaptateur et de préfixe à l'aide d'un encodeur de texte pré-entraîné et d'un générateur de paramètres basé sur l'attention croisée. Les adaptateurs et préfixes générés sont ensuite insérés dans le modèle de base en tant que modules de réglage efficaces. Au moment de l'inférence, l'hyperréseau n'effectue l'inférence qu'une seule fois par tâche pour générer des modules adaptés. L'avantage est que contrairement aux méthodes classiques de réglage fin ou de concaténation d'entrée, HINT peut combiner des instructions plus longues et de petits fragments supplémentaires sans augmenter la charge de calcul.
7.3 Qualité
QLORA (Dettmers et al., 2023) inclut une quantification optimisée et une optimisation de la mémoire, visant à fournir un réglage fin efficace et efficient des LLM. QLORA inclut la quantification NormalFloat (NF4) 4 bits, un schéma de quantification optimisé pour la distribution normale typique des poids LLM. En quantifiant sur la base des quantiles de la distribution normale, NF4 offre de meilleures performances que la quantification standard d'entiers 4 bits ou de virgule flottante. Pour réduire davantage la mémoire, la constante de quantification elle-même est quantifiée sur 8 bits. Ce deuxième niveau de quantification permet d'économiser en moyenne 0,37 bits par paramètre. QLORA profite de la fonction de mémoire unifiée de NVIDIA. Lorsque la mémoire GPU est dépassée, l'état de l'optimiseur de page est transféré à la RAM du CPU, évitant ainsi une mémoire insuffisante pendant le processus d'entraînement. QLORA peut entraîner un LLM de paramètres 65B sur un seul GPU de 48 Go sans dégradation par rapport à un réglage fin complet de 16 bits. QLORA fonctionne en gelant le LLM de base de quantification 4 bits, puis en le rétropropagant.
7.4 LOMO
L'optimisation LOw-Memory (LOMO) (Lv et al., 2023) permet un réglage précis des paramètres complets de LLM avec des ressources informatiques limitées en fusionnant le calcul et la mise à jour du gradient. Son essence est d'intégrer le calcul du gradient et la mise à jour des paramètres en une seule étape de rétropropagation, évitant ainsi le stockage de tenseurs de gradient complets. Tout d'abord, une analyse théorique est fournie dans LOMO expliquant pourquoi SGD fonctionne bien pour affiner les grands modèles pré-entraînés, malgré ses défis pour les modèles plus petits. De plus, LOMO met à jour chaque tenseur de paramètre dès que son gradient est calculé en rétropropagation. Le stockage des dégradés un paramètre à la fois réduit la mémoire des dégradés à O(1). LOMO utilise l'écrêtage de la valeur du gradient, le calcul de la norme du gradient de séparation et la mise à l'échelle dynamique des pertes pour stabiliser l'entraînement. L'intégration des méthodes de points de contrôle activés et d'optimisation zéro permet d'économiser de la mémoire.
7.5 Réglage Delta
Le réglage delta (Ding et al., 2023b) fournit une perspective d'optimisation et de contrôle optimal pour l'analyse théorique. Intuitivement, le réglage delta effectue une optimisation du sous-espace en limitant le réglage aux variétés de faible dimension. Les paramètres ajustés servent de contrôleurs optimaux pour guider le comportement du modèle pour les tâches en aval.
8. Évaluer, analyser et critiquer
8.1 Évaluation HELM
HELM (Liang et al., 2022) est une évaluation holistique des modèles de langage (LM) visant à accroître la transparence des modèles de langage et à fournir une compréhension plus complète des capacités, des risques et des limites des modèles de langage. Plus précisément, contrairement à d'autres méthodes d'évaluation, HELM estime que l'évaluation globale d'un modèle de langage doit se concentrer sur les trois facteurs suivants :
(1) Large couverture. Pendant le développement, les modèles de langage peuvent être adaptés à diverses tâches NLP (telles que l'annotation de séquences et la réponse aux questions), de sorte que l'évaluation des modèles de langage doit être effectuée dans un large éventail de scénarios. En considérant tous les scénarios possibles, HELM propose une taxonomie descendante qui compile d'abord toutes les tâches existantes dans une grande conférence PNL (ACL2022) dans un espace de tâches et divise chaque tâche en scénarios (forme telle que le langage) et mesure (par exemple précision). Ensuite, face à une tâche spécifique, la taxonomie sélectionnera un ou plusieurs scénarios et indicateurs dans l’espace des tâches pour la couvrir. HELM clarifie le contenu de l'évaluation (scénarios de tâches et indicateurs) en analysant la structure de chaque tâche, augmentant ainsi le taux de couverture des scènes du modèle de langage de 17,9 % à 96,0 %.
(2) Mesure multimétrique. Afin de permettre aux humains de mesurer les modèles de langage sous différentes perspectives, HELM propose des métriques multi-métriques. HELM couvre 16 scénarios différents et 7 indicateurs. Pour garantir les résultats de mesures multimétriques intensives, HELM a mesuré 98 des 112 scénarios de base possibles (87,5 %).
(3) Normalisation. L'augmentation de la taille et de la complexité de formation des modèles de langage a sérieusement entravé la compréhension de la structure de chaque modèle de langage. Afin d'établir une compréhension unifiée des modèles de langage existants, HELM a comparé 30 modèles de langage bien connus, dont Google (UL2 (Tay et al., 2022)), OpenAI (GPT-3 (Brown et al., 2020b)) et EleutherAI (GPT-NeoX (Black et al., 2022)) et d'autres institutions. Il est intéressant de noter que HELM a souligné que les LLM tels que T5 (Raffel et al., 2019) et Anthropic-LMv4-s3 (Bai et al., 2022a) n'étaient pas directement comparés dans le travail original, tandis que les LLM tels que GPT-3 et YaLM Après plusieurs évaluations, des divergences subsistent avec les rapports correspondants.
8.2 Réglage des instructions à faibles ressources
Gupta et al. (2023) ont tenté d'estimer les données minimales de formation en aval requises pour que les modèles informatiques répondent aux exigences des modèles supervisés SOTA pour diverses tâches. Gupta et ses collègues (2023) ont mené des expériences sur 119 tâches issues des instructions super naturelles (SuperNI) dans des contextes d'apprentissage monotâche (STL) et d'apprentissage multitâche (MTL). Les résultats montrent que dans le contexte STL, seulement 25 % des données de formation en aval pour le modèle informatique surpassent le modèle SOTA sur ces tâches, tandis que dans le contexte MTL, seulement 6 % des données de formation en aval peuvent guider le modèle informatique pour atteindre Performances SOTA. Ces résultats suggèrent que le réglage des instructions peut aider efficacement les modèles à apprendre rapidement des tâches avec des données limitées.
8.3 Ensemble de données d'instruction plus petit
L'informatique nécessite de grandes quantités de données d'instructions spécialisées pour la formation. Zhou et al. (2023) ont émis l'hypothèse que le LLM pré-entraîné n'a besoin que d'apprendre des styles ou des formats pour interagir avec les utilisateurs, et ont proposé à LIMA d'atteindre de solides performances en affinant le LLM sur seulement 1 000 exemples de formation soigneusement sélectionnés. Plus précisément, LIMA organise d'abord manuellement 1 000 exemples avec des invites et des réponses de haute qualité. Ensuite, 1000 exemples ont été utilisés pour affiner le LLaMa-65B pré-entraîné (Touvron et al., 2023b). En comparaison, LIMA surpasse GPT-davinci003 (Brown et al., 2020b), qui a été affiné sur 5 200 exemples avec des ajustements de rétroaction humaine, sur plus de 300 tâches difficiles. De plus, avec seulement la moitié des exemples, LIMA obtient des résultats comparables à GPT-4 (OpenAI, 2023), Claude (Bai et al., 2022b) et Bard. Plus important encore, LIMA démontre que les puissantes connaissances et capacités des LLM peuvent être démontrées aux utilisateurs avec seulement quelques instructions de réglage minutieusement planifiées.
8.4 Ensemble de données d'évaluation du réglage des instructions
Les performances des modèles informatiques dépendent fortement des ensembles de données informatiques. Cependant, il y a un manque d’évaluation ouverte et subjective de ces ensembles de données informatiques. Pour résoudre ce problème, Wang et al. (2023c) ont effectué une évaluation des ensembles de données en affinant le modèle LLaMa (Touvron et al., 2023b) sur divers ensembles de données informatiques ouverts et ont mesuré différents modèles affinés grâce à une évaluation automatique et manuelle. Entraînez un modèle supplémentaire sur la combinaison d’ensembles de données informatiques. En ce qui concerne les résultats, Wang et al. (2023c) ont montré qu’il n’existe pas de meilleur ensemble de données informatiques pour toutes les tâches, et que les meilleures performances globales peuvent être obtenues en combinant manuellement les ensembles de données. En outre, Wang et al. (2023c) ont souligné que même si l’informatique peut apporter de grands avantages aux LLM de toutes tailles, les modèles plus petits et les qualités de modèle de base de haute qualité sont les plus grands bénéficiaires de l’informatique. Pour l’évaluation humaine, plus le modèle est grand, plus le score d’acceptabilité est élevé.
8.5 L'informatique est-elle simplement une réplication du modèle d'apprentissage ?
Pour remédier au manque de clarté des connaissances spécifiques que les modèles acquièrent grâce au réglage des instructions, Kung et Peng (2023) ont mené une analyse approfondie de la manière dont les modèles utilisent les instructions dans les processus informatiques en comparant le réglage lors de la fourniture d'instructions modifiées et d'instructions originales.
En particulier, Kung et Peng (2023) ont créé des définitions de tâches simplifiées qui supprimaient tous les composants sémantiques et ne laissaient que les informations de sortie. De plus, Kung et Peng (2023) ont introduit des exemples fantômes contenant des mappages entrée-sortie incorrects. Étonnamment, les expériences montrent que les modèles formés sur ces définitions de tâches simplifiées ou sur des exemples erronés peuvent atteindre des performances comparables à celles des modèles formés sur les instructions et exemples originaux. En outre, ce document présente également une base de référence pour les tâches de classification zéro-shot, permettant d'obtenir des performances similaires à celles de l'informatique dans des environnements à faibles ressources.
En résumé, selon Kung et Peng (2023), les améliorations significatives des performances observées dans les modèles informatiques actuels peuvent être attribuées à leur capacité à capturer des modèles au niveau de la surface, tels que l'apprentissage des formats de sortie et à deviner, plutôt qu'à comprendre et à apprendre une tâche spécifique.
8.6 Imitation de LLM propriétaires
Le clonage LLM est une méthode permettant de collecter les résultats de modèles plus puissants (systèmes propriétaires tels que ChatGPT) et d'utiliser ces résultats pour affiner le LLM open source. De cette manière, le LLM open source acquiert la capacité de rivaliser avec n’importe quel modèle propriétaire.
Gudibande et ses collègues (2023) ont mené plusieurs expériences pour analyser de manière critique l'efficacité de l'imitation du modèle. Plus précisément, Gudibande et ses collègues (2023) ont d’abord collecté un ensemble de données issues des nombreuses tâches de ChatGPT. Ces ensembles de données ont ensuite été utilisés pour affiner une gamme de modèles, y compris les modèles de base GPT-2 et LLaMA, dont la taille varie de 1,5 B à 13 B, avec des tailles de données allant de 0,3 Mtoken à 1,5 Mtoken.
Pour l'évaluation, Gudibande et al. (2023) ont démontré que le modèle d'imitation est bien meilleur qu'auparavant pour prendre en charge l'ensemble de données, avec un résultat similaire à ChatGPT. Dans les tâches sans ensembles de données simulées, la précision du modèle de simulation ne s'est pas améliorée, voire a diminué.
Par conséquent, Gudibande et al. (2023) ont souligné que c'est le phénomène selon lequel le modèle d'imitation est efficace pour imiter le style de ChatGPT (par exemple fluide, confiant et bien structuré) qui donne aux chercheurs une illusion sur la capacité générale de ChatGPT. le modèle d'imitation. Par conséquent, Gudibande et al. (2023) suggèrent que les chercheurs feraient mieux de se concentrer sur l’amélioration de la qualité des modèles de base et des exemples d’instructions plutôt que d’imiter des modèles propriétaires.
Résumer
A l'ère des grands modèles, si on n'avance pas, on recule, j'espère que tout le monde en tirera des leçons.
Veuillez prêter plus d'attention à "Liu Cong NLP" sur Zhihu. Les amis qui ont des questions sont également invités à m'ajouter à WeChat "logCong" pour un chat privé. Faisons-nous des amis, apprenons ensemble et progressons ensemble. Notre slogan est "La vie est sans fin, l'apprentissage est sans fin".
PS : Le nouveau livre « Principes de ChatGPT et combat pratique » est sorti, bienvenue à acheter~~.
Recommandé dans le passé :
Le rapport technique BaiChuan2 détaille le partage et les réflexions personnelles
Résumé de l'expérience de mise au point LLM sur grand modèle et mise à jour du projet
Sommes-nous en train de former le grand modèle, ou est-ce que les grands modèles nous forment ?
L'ère des grands modèles - Repenser la mise en œuvre de l'industrie
Recherche sur le problème des hallucinations des grands modèles