Article : https://arxiv.org/pdf/2112.11446.pdf
Blogs associés
[Traitement du langage naturel] [Grands modèles] CodeGeeX : Modèles multilingues pré-entraînés pour la génération de code
[Traitement du langage naturel] [Grands modèles] LaMDA : Modèles de langage pour applications conversationnelles
[Traitement du langage naturel] [Grands modèles] 】Le grand modèle Gopher de DeepMind
[ Traitement du langage naturel] [Grand modèle] Chinchilla : Grand modèle de langage avec formation et utilisation informatique optimales
[Traitement du langage naturel] [Grand modèle] Test de l'outil de raisonnement BLOOM grand modèle de langage
[Traitement du langage naturel] [Grand modèle] GLM-130B : un outil de raisonnement ouvert source modèle de langage bilingue pré-entraîné
[Traitement du langage naturel] [Grand modèle] Introduction à la multiplication matricielle 8 bits pour les grands transformateurs
[Traitement du langage naturel] [Grand modèle] BLOOM : un paramètre 176B et peut être ouvert Le modèle multilingue obtenu
[Traitement du langage naturel] Traitement du langage] [Grand Modèle] PaLM : un grand modèle de langage basé sur Pathways
1. Introduction
La communication utilisant le langage naturel est au cœur de l’intelligence car elle permet un partage efficace d’idées entre les humains et les systèmes d’IA. L'omniprésence du langage nous permet d'exprimer de nombreuses tâches intelligentes en utilisant une entrée en langage naturel et de produire une sortie en langage naturel.
L’utilisation de modèles linguistiques dans le cadre du renseignement contraste fortement avec son application initiale : la transmission de texte sur des canaux de communication à bande passante limitée. La théorie mathématique de la communication de Shannon relie la modélisation statistique du langage naturel à la compression, montrant que mesurer l'entropie croisée d'un modèle de langage équivaut à mesurer son taux de compression. Shannon a adapté les premiers modèles de langage aux données réelles en précalculant des statistiques de texte qui associent la complexité du modèle à une compression de texte améliorée et à une génération de texte plus réaliste. Mais le rapport à l’intelligence était là dès le départ : Shannon a émis l’hypothèse qu’un modèle suffisamment complexe serait capable de parvenir à une communication de type humain.
L’informatique moderne est un facteur clé vers de meilleurs modèles de langage. À commencer par le stylo et le papier, à mesure que la puissance de calcul a augmenté de façon exponentielle, la capacité et le pouvoir prédictif des modèles linguistiques ont également augmenté. Dans les années 1990 et au début des années 2000, les modèles n-grammes ont été améliorés en termes de taille et de méthodes de lissage, notamment un modèle de 300 milliards de n-grammes formé sur 2 000 milliards de jetons de texte. Ces modèles ont été utilisés dans la reconnaissance vocale, la correction orthographique, la traduction automatique et d'autres domaines. Cependant, les modèles n-gram deviennent statistiquement et informatiquement inefficaces à mesure que la longueur du contexte augmente, ce qui limite la richesse de leur langage de modélisation.
Au cours des deux dernières décennies, les modèles linguistiques ont évolué vers des réseaux de neurones qui capturent implicitement la structure du langage. L’ensemble des progrès dépend à la fois de l’échelle et du réseau. Certaines études ont trouvé une loi de puissance liée à la perte d'entropie croisée du modèle de langage neuronal récurrent et du modèle de langage neuronal Transformer avec la taille du modèle. GPT-3 est un modèle de transformateur de 175 milliards de paramètres entraîné sur 300 milliards de jetons de texte, qui permet d'obtenir des performances de prédiction proportionnellement améliorées dans les prédictions réelles. Le modèle s'entraîne sur les zettaflops de calcul, ce qui est un de plus que les travaux précédents. GPT-3 démontre une qualité de génération et une généralisabilité sans précédent dans de nombreuses tâches de traitement du langage naturel.
Dans cet article, nous décrivons un protocole de formation de grands modèles de langage de pointe et proposons un modèle de 280 milliards de paramètres appelé Gopher. Nous décrivons les spécifications architecturales, les optimisations, l'infrastructure et les méthodes de gestion de MassiveText, un ensemble de données textuelles de haute qualité. Nous avons effectué une analyse approfondie d'un benchmark de 152 tâches qui examinent plusieurs aspects différents du renseignement. Gopher améliore les performances d'environ 81 % par rapport aux modèles linguistiques de pointe actuels, en particulier dans les domaines à forte intensité de connaissances tels que la détection des faits et le bon sens.
Étant donné que le contenu préjudiciable est présent à la fois dans l'ensemble de formation de Gopher et dans de nombreuses applications potentielles en aval, nous examinons la toxicité et les biais du modèle dans les sections suivantes, en nous concentrant sur la manière dont la taille du modèle affecte ces propriétés. Nous avons constaté que les modèles plus grands étaient plus susceptibles de générer des réponses toxiques lorsqu’ils étaient présentés avec des signaux toxiques, mais qu’ils étaient également capables de classer la toxicité avec plus de précision.
2. Méthode
1. Modèle
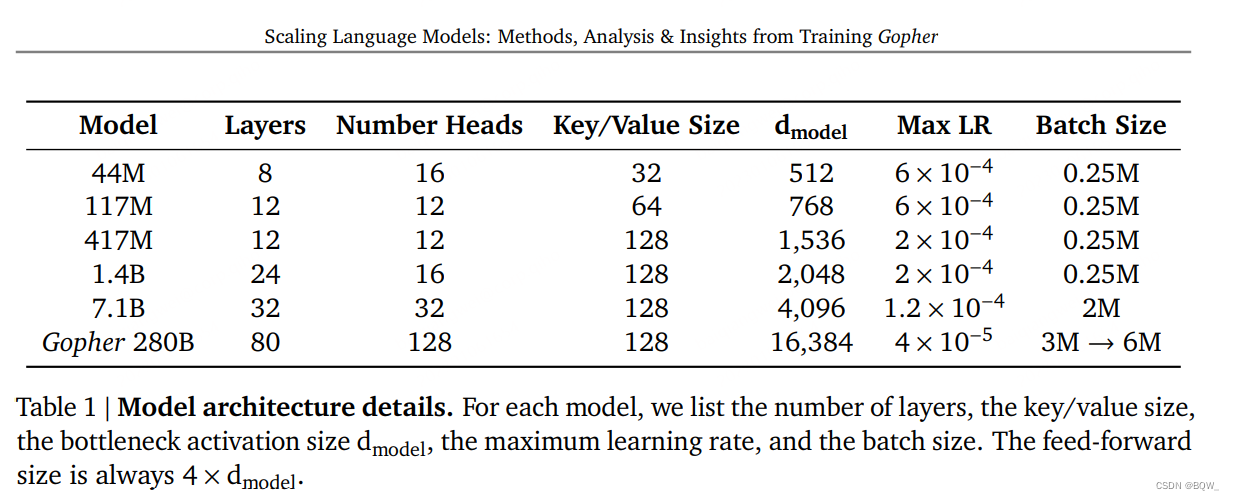
Dans cet article, six modèles avec des paramètres allant de 440 millions à 280 milliards de paramètres seront présentés. Les détails de l'architecture sont présentés dans le tableau 1 ci-dessus. Le plus grand modèle s'appelle ici Gopher, et l'ensemble de la collection de modèles s'appelle la famille Gopher.
Nous utilisons l'architecture autorégressive Transformer et apportons deux modifications : (1) remplacer RMSNorm par LayerNorm ; (2) utiliser le codage de position relative au lieu du codage de position absolue. Le codage positionnel relatif permet une évaluation sur des séquences plus longues que l’entraînement. Tokenisez le texte à l'aide d'un SentencePièce avec une taille de vocabulaire de 32 000 et utilisez une solution de secours au niveau des octets pour prendre en charge la modélisation de vocabulaire ouvert.
2. Formation
Tous les modèles sont formés sur 300 milliards de jetons avec une fenêtre contextuelle de 2048 jetons et utilisent l'optimiseur Adam. Les 1 500 premiers pas de 1 0 − 7 10^-71 0− 7taux d'apprentissage échauffement jusqu'au taux d'apprentissage maximum, puis utilisez la planification cosinus pour diminuer de 10 fois. À mesure que la taille du modèle augmente, réduisez le taux d'apprentissage maximum et augmentez le nombre de jetons dans chaque lot. De plus, la taille du lot de Gopher passe de 3 millions de jetons à 6 millions de jetons pendant la formation. Utilisez le paradigme du dégradé global pour découper le dégradé à 1. Cependant, pour le modèle 7.1B et le modèle Gopher, réduisez-le à 0,25 pour améliorer la stabilité.
Utilisez le format numérique bfloat16 pour réduire le stockage et augmenter le débit de formation. Les modèles inférieurs à 7.1B sont entraînés avec des paramètres de précision mixtes float32 et des activations bfloat16, tandis que 7.1B et 280B utilisent des activations et des paramètres bfloat16. Les paramètres bfloat16 utilisent un arrondi aléatoire pour maintenir la stabilité. Il a été découvert plus tard que l’arrondi aléatoire ne restaure pas complètement l’effet d’un entraînement à précision mixte.
3. Infrastructures
Utilisez JAX et Haiku pour créer la base de code de formation et d'évaluation. En particulier, utilisez la transformation JAX pmap pour exprimer efficacement le parallélisme des données et des modèles. Tous les modèles sont formés et évalués sur des puces TPUv3.
Les paramètres de demi-précision de Gopher et l'état Adam en simple précision occupent 2,5 TiB, ce qui dépasse de loin les 16 Go de mémoire disponible par cœur TPUv3. Pour résoudre ces problèmes de mémoire, nous utilisons le partitionnement d'état, le parallélisme des modèles et la rematérialisation pour partitionner l'état du modèle et réduire les activations afin qu'il tienne dans la mémoire TPU.
Nous constatons que le parallélisme des données et le parallélisme des modèles nécessitent une faible surcharge sur TPUv3 en raison de sa communication rapide entre puces et n'ajoutent qu'une surcharge de 10 % lors de la formation des Gophers. Par conséquent, nous avons constaté qu'il n'est pas nécessaire d'utiliser le pipeline sur le TPU lorsque la taille de formation ne dépasse pas 1024 puces, ce qui simplifie grandement la formation de modèles de taille moyenne. Cependant, le parallélisme pipeline est une méthode de parallélisme efficace sur les réseaux commerciaux et est bien adapté à la connexion de plusieurs pods TPU en raison de son faible volume de communication. En général, la formation de Gopher au sein d'un pod TPU utilise le parallélisme des modèles et des données, et entre les pods TPU, des pipelines sont utilisés.
4. Ensemble de données de formation
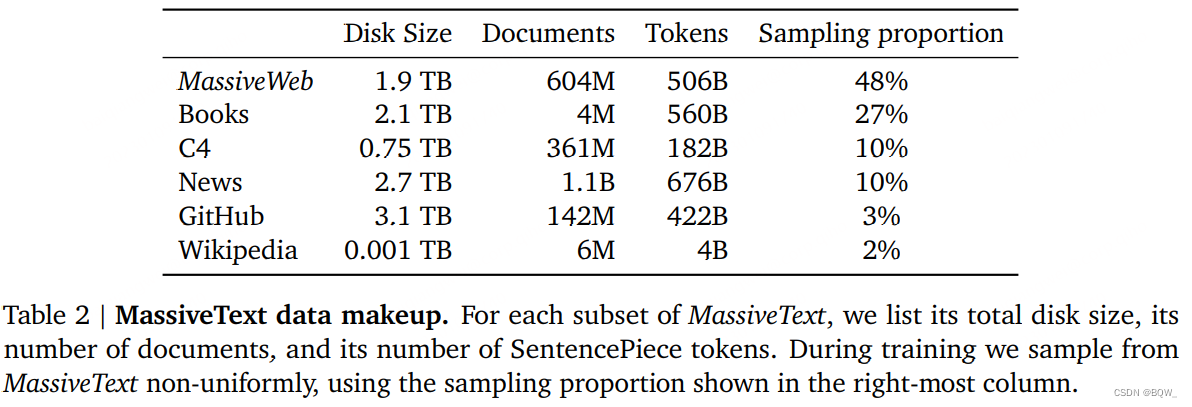
Formez Gopher sur MassiveText. MassiveText est un ensemble de données de textes anglais à grande échelle et multi-sources. Les sources comprennent principalement : des pages Web, des livres, des actualités et des codes. Le tableau 2 ci-dessus montre les détails qui composent l'ensemble de données. Le pipeline de données comprend le filtrage de la qualité du texte, la suppression du texte en double, la déduplication de texte similaire et la suppression des documents qui chevauchent considérablement l'ensemble de test. Des expériences ont montré que différentes étapes de ce pipeline améliorent les performances en aval des modèles de langage, en particulier l'amélioration de la qualité des données.
Au total, MassiveText contient 2,35 milliards de documents, soit environ 10,5 To de texte. Étant donné que Gopher est formé sur 300 milliards de jetons (12,8 % des jetons de l'ensemble de données), le taux d'échantillonnage est spécifié pour chaque sous-ensemble (livres, actualités) pour le sous-échantillonnage. Nous ajustons le rapport de ces échantillons pour maximiser les performances en aval. Le plus grand sous-ensemble échantillonné provient du corpus de texte Web MassiveWeb, et nous avons constaté qu'il peut améliorer les performances en aval par rapport à l'ensemble de données de texte Web existant C4.
3. Résultats
Gopher a été évalué sur 152 tâches.
1. Sélection des tâches
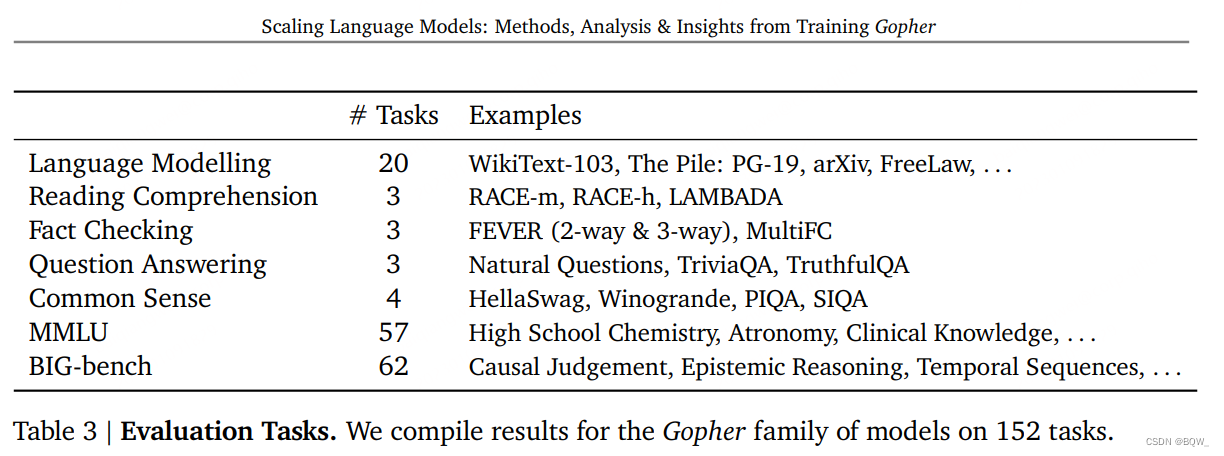
Un profil d'efficacité du modèle est établi ici, comprenant : les mathématiques, le bon sens, le raisonnement logique, les connaissances générales, la compréhension scientifique, l'éthique et la compréhension en lecture, ainsi que les références de modélisation sémantique traditionnelle. Parmi les benchmarks composites qui combinent plusieurs tâches, il existe également un certain nombre de benchmarks cibles comme RACE ou FEVER. Toutes les tâches sont répertoriées dans le tableau 3 ci-dessus.
2. Comparaison SOTA
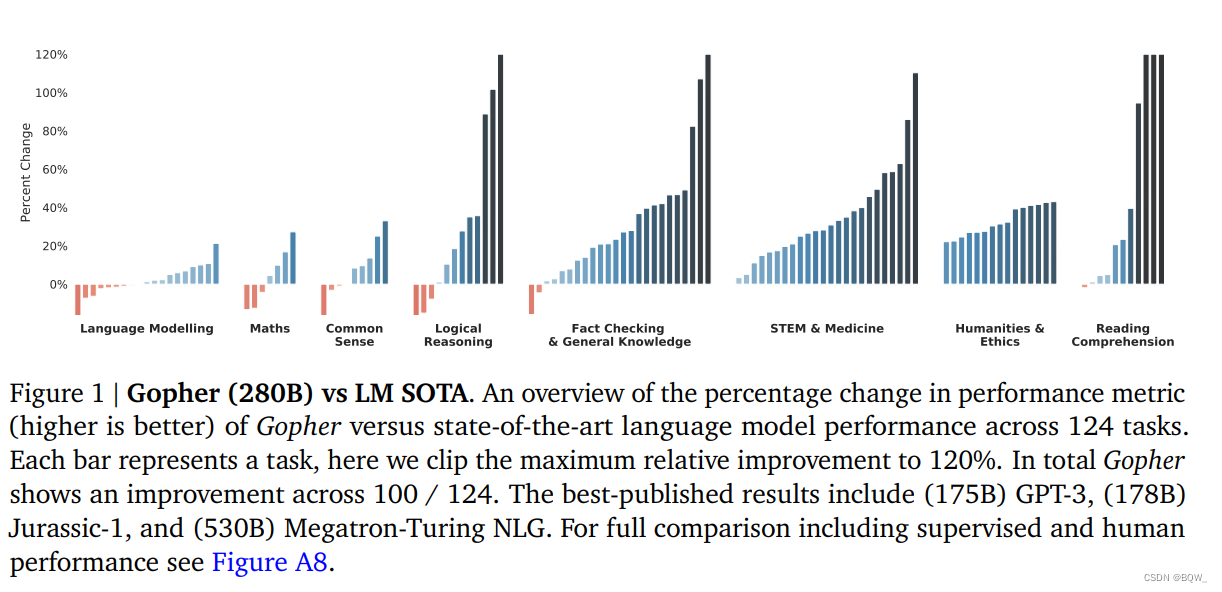
La figure 1 ci-dessus montre les résultats de la comparaison entre Gopher et le modèle de langage de pointe. Les résultats de la comparaison couvrent 124 tâches et tracent le pourcentage de changement dans les mesures de performances pour Gopher et le LM SOTA actuel. Gopher surpasse l'état de l'art actuel sur 100 tâches (81 % des tâches). Les modèles de base incluent des LLM comme GPT-3, Jurassic-1 et Megatron-Turing NLG.
Des expériences ont montré que Gopher a montré des améliorations uniformes dans des domaines tels que la compréhension écrite, les sciences humaines, l'éthique, les STEM et la médecine. Il y a également une amélioration uniforme de la détection des faits. De légères améliorations ont été observées dans le raisonnement de bon sens, le raisonnement logique et les mathématiques, ainsi que de légères baisses dans plusieurs tâches. La tendance générale est qu'il y a moins d'amélioration sur les tâches qui reposent davantage sur le raisonnement, et une plus grande amélioration sur les tâches à forte intensité de connaissances .
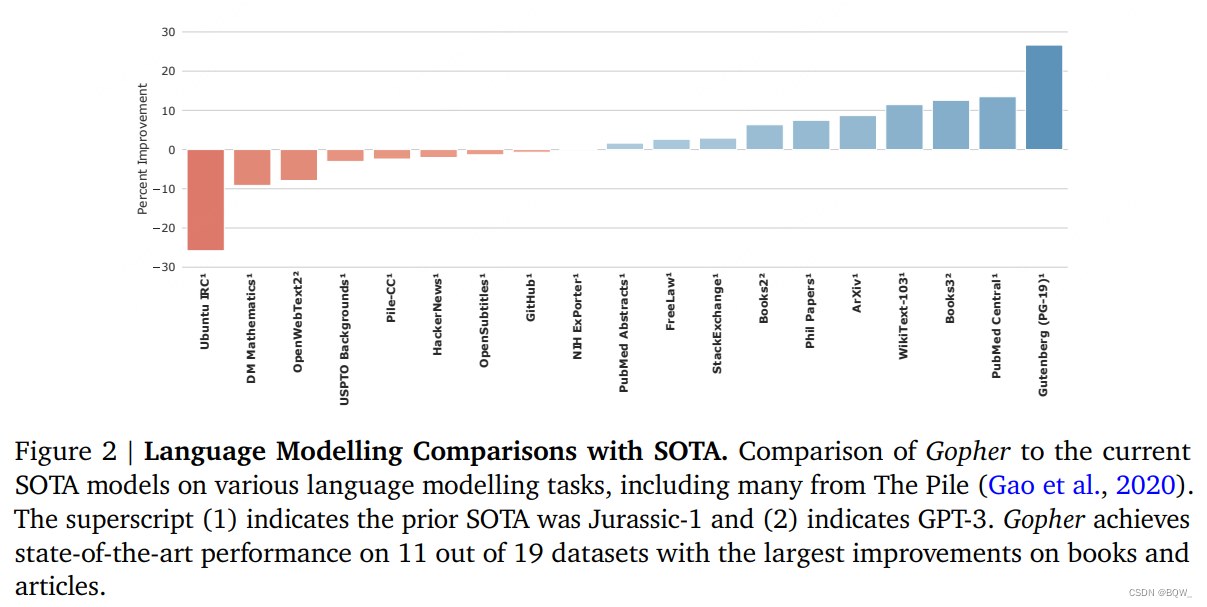
Pour le benchmark du modèle de langage, Gopher a été comparé aux modèles SOTA actuels Jurassic-1 et 175B GPT-3, et les résultats sont présentés dans la figure 2 ci-dessus. Gopher a obtenu des résultats moins bons que l'état de l'art sur 8 tâches sur 19, en particulier sur Unbuntu IRC et DM Mathematics, probablement en raison de la faible capacité du tokenizer à représenter les nombres. Gopher a amélioré 11 des 19 tâches, en particulier les livres et les articles. Le gain effectif peut être dû au nombre relativement élevé de données de livres dans MassiveText.
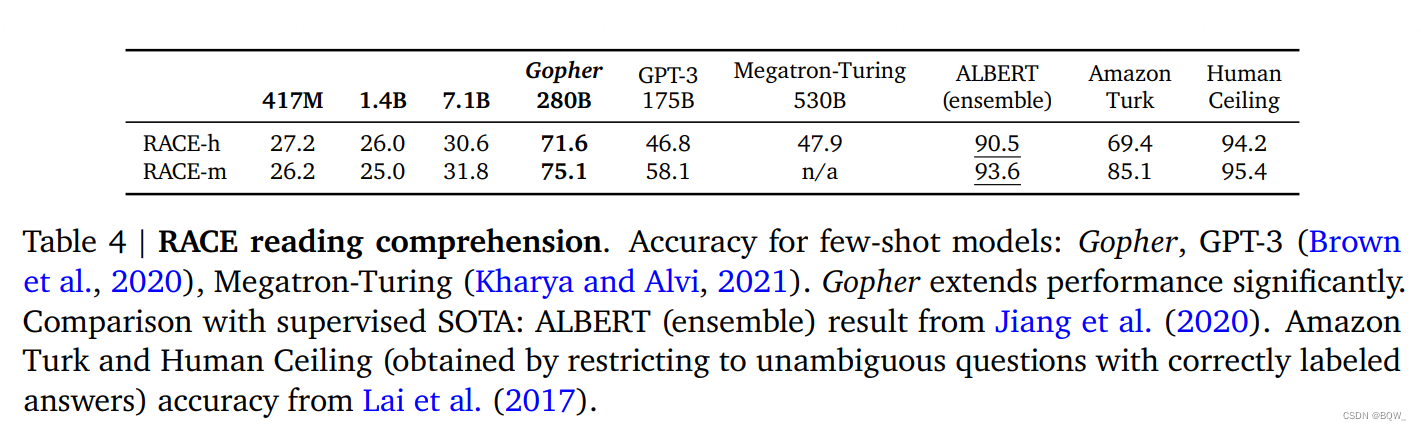
Deux ensembles de données de compréhension écrite, RACE-m et RACE-h, sont présentés ici, qui sont des tests à choix multiples aux niveaux intermédiaire et secondaire. Gopher surpasse considérablement le LM SOTA actuel et se rapproche des performances de niveau humain en compréhension de lecture au lycée. Cependant, le modèle Gopher plus petit ne fonctionne pas très bien sur ces tâches, de sorte que les données à elles seules ne peuvent pas expliquer la différence de performances, et la combinaison de la taille et des données est cruciale . Tous les modèles sont pires que le plafond humain et les méthodes de réglage fin supervisées.
Pour les tâches de raisonnement de bon sens : Winogrande, HellaSwag et PIQA, Gopher est légèrement meilleur que le plus grand Megatron-Turing NLG, mais tous les modèles de langage sont bien pires que ceux des humains.
La vérification des faits constitue un problème important dans le domaine de la lutte contre la désinformation. Compte tenu des preuves, Gopher surpasse le SOTA supervisé sur le benchmark de détection des faits FEVER. À mesure que la taille du modèle augmente, les performances de détection des faits s’améliorent également. Cependant, les modèles plus grands n'améliorent pas réellement la distinction entre les faits inconnus et les erreurs , ce qui implique que les modèles plus grands améliorent les performances de détection des faits en mémorisant des faits plus importants, plutôt que par une compréhension plus approfondie des fausses informations.
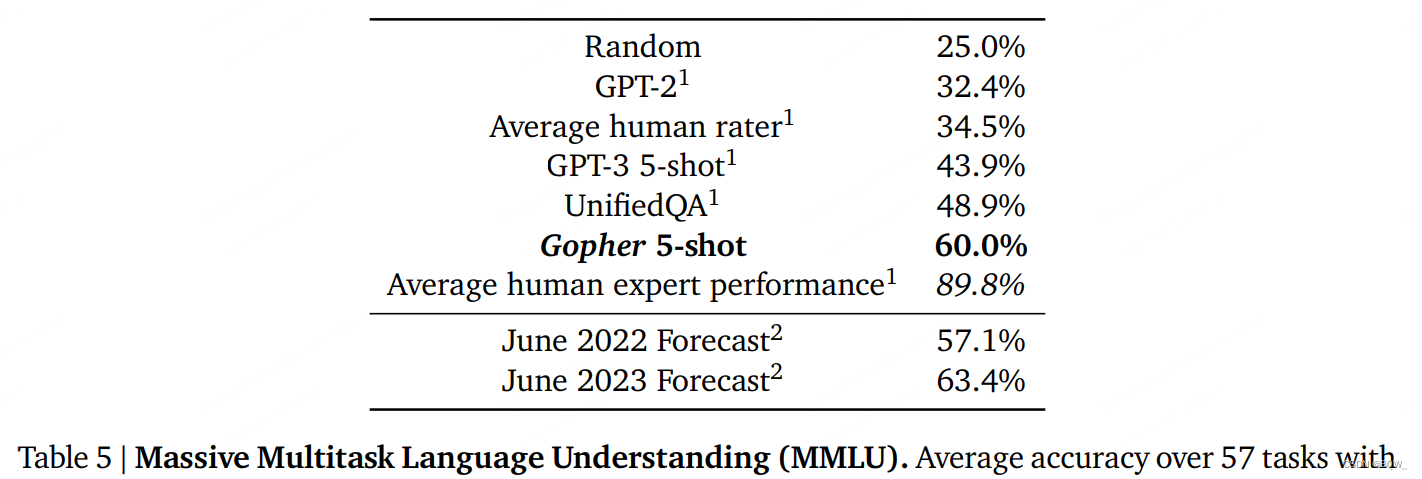
Le tableau 5 ci-dessus montre la précision moyenne de 57 tâches dans MMLU. Ces tâches intègrent des examens humains réels couvrant une gamme de matières académiques. Ici, nous comparons GPT-3 avec 11B T5 affiné sur la tâche de réponse aux questions UnifiedQA. Gopher atteint un taux de précision de 60 %, supérieur aux 43,9 % de GPT-3 et aux 48,9 % d'UnifiedQA. Bien que cela améliore la limite supérieure des approches de modèles de langage pur, cela reste en deçà des 89,8 % obtenus par les experts humains.
3. Amélioration des performances avec échelle
Cette sous-section étudie quelles tâches peuvent bénéficier de la mise à l'échelle de la taille du modèle, en comparant Gopher (280B) et des modèles plus petits ( ≤ 7,1 B \leq 7.1B≤7.1B ) . Puisque toutes les versions du modèle Gopher sont formées sur le même ensemble de données.
Nous avons calculé l'effet optimal sur Gopher (280B) et un maximum de modèles 7,1B sur 152 tâches. Les petits Gophers les plus performants sont généralement les modèles 7.1B, mais pas toujours. Gopher a montré une amélioration sur la grande majorité des tâches, et seulement 16 (10,5 %) tâches ne se sont pas améliorées. En revanche, 57 (37,5 %) tâches présentaient des améliorations mineures avec une amélioration relative des performances allant jusqu'à 25 %, tandis que 79 (51,2 %) tâches présentaient des améliorations significatives de plus de 25 %.
Les économies d’échelle les plus importantes sont observées dans les missions médicales, scientifiques, techniques, sociales et humaines. Voici quelques tâches spécifiques : pour la tâche de détection de la figure de discours dans BIG-bench, le gain maximum de 314 % a été obtenu. Gopher atteint une précision de 52,7 % tandis que le modèle 7.1B atteint une précision de 16,8 %. Gopher réalise des améliorations significatives par rapport aux modèles plus petits en termes d'arguments logiques, de marketing et de génétique médicale. Pour le benchmark TruthfulQA, nous constatons que les performances s'améliorent avec l'échelle, bien que dans des modèles tels que GPT-J, GPT-2, T5, GPT-3
Le modèle semble corrompu. De plus, le 280B est le premier modèle à démontrer des performances nettement meilleures que les devinettes aléatoires sur TruthfulQA à choix multiples. Ces résultats suggèrent que sur ces tâches, l'échelle semble débloquer la capacité du modèle sur des tâches spécifiques.
En revanche, nous constatons des gains d’échelle décroissants pour les tâches des catégories mathématiques, raisonnement logique et bon sens. Les résultats suggèrent que pour certains types de tâches de raisonnement mathématique ou logique, il est peu probable que la simple taille conduise à des avancées en termes de performances. Gopher fonctionne encore moins bien que les modèles plus petits dans certains scénarios, tels que l'algèbre abstraite et les séquences temporelles sur le benchmark BIG-bench, et les mathématiques du secondaire sur le MMLU. D'un autre côté, l'amélioration limitée des tâches de bon sens est principalement due au fait que les modèles plus petits peuvent atteindre des performances relativement bonnes et qu'il y a peu de marge d'amélioration.
Dans l’ensemble, la taille du modèle joue un rôle important dans l’amélioration de la plupart des tâches, mais les gains ne sont pas uniformément répartis. De nombreuses matières académiques, et du moins en général, pourraient s’améliorer énormément rien que par leur taille. Cependant, cette analyse souligne également que la mise à l’échelle seule ne suffit pas . En analysant ces résultats, on peut constater que la taille du modèle et l'ensemble de données sont tout aussi importants pour les solides performances de Gopher dans ces domaines.
4. Toxicité et biais
1. Toxicité
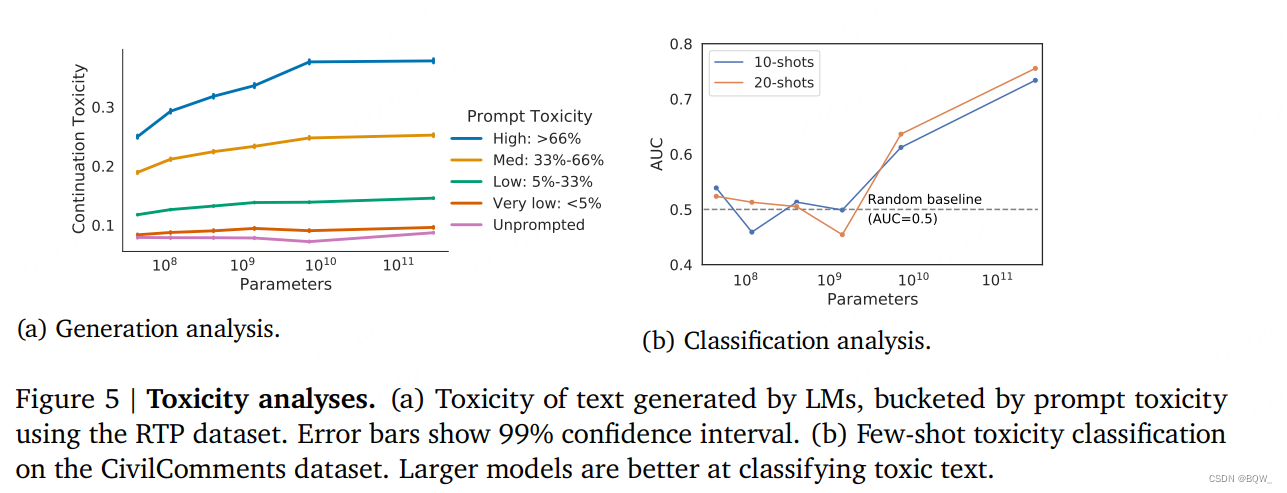
1.1 Générer une analyse
L'analyse de la toxicité du texte généré par LM a suivi Gehman et al.la méthode utilisée dans . Nous utilisons l'API Perspective pour obtenir des invites de modèle de langage et générer des scores de toxicité de texte. Nous avons analysé la toxicité d'échantillons générés de manière conditionnelle et inconditionnelle à l'aide d'une invite. La génération de conditions nous permet d'analyser comment le modèle répond aux invites avec une toxicité différente. Les invites proviennent de l'ensemble de données RealToxicityPrompts (RTP), qui contient 100 000 invites naturelles au niveau des phrases. Pour plus d'efficacité, échantillonnez 10 % sur 100 000 invites RTP et générez 25 réponses pour chaque invite.
La toxicité des réponses générées par des modèles plus grands était plus cohérente avec une toxicité rapide que dans les modèles plus petits (Fig. 5a ci-dessus). Lorsque l'invite est utilisée, la réponse du modèle plus grand est plus toxique à mesure que la toxicité d'entrée augmente, se stabilisant autour du paramètre 7,1B. Cela suggère qu’un plus grand nombre de paramètres augmente la capacité de la réponse à préserver la cohérence avec l’entrée.
Pour les échantillons sans invite, la toxicité est plus faible et n'augmente pas avec la taille du modèle . Le niveau de toxicité est légèrement inférieur aux données d'entraînement, c'est-à-dire que le LM n'amplifie pas la toxicité des données d'entraînement lorsque l'invite n'est pas utilisée.
1.2 Analyse de classification
Nous avons évalué la capacité du modèle à détecter du texte toxique en quelques plans, ici en utilisant l'ensemble de données CivilComments. Nous observons que dans le cadre de quelques plans, la capacité du modèle à classer le texte toxique augmente à mesure que la taille augmente (Fig. 5b ci-dessus). Les modèles plus petits ne peuvent se rapprocher que des classificateurs aléatoires. Le plus grand modèle peut atteindre une AUC de 0,76 en configuration 20 injections, ce qui constitue une amélioration significative par rapport au petit modèle. Nous notons que l'état de l'art en matière de détection de la toxicité dans le cadre de quelques tirs n'est pas encore bien établi, mais nos performances sont bien inférieures à celles des classificateurs de pointe spécialement formés pour la détection de la toxicité.
2. Biais distribué
Définissez le biais distribué comme un biais qui ne se produit pas sur un seul échantillon, mais apparaît sur de nombreux échantillons . Par exemple, même si « cette femme est infirmière » n’est pas une phrase problématique, elle le serait si le modèle associait de manière disproportionnée certaines professions aux femmes. Comme Sheng et al.(2021)indiqué, les biais distribués dans les modèles linguistiques peuvent avoir des effets de représentation et de distribution négatifs. Pour étudier le biais distribué de notre modèle, nous mesurons l'association stéréotypée entre le sexe et la profession, la répartition des sentiments entre des échantillons conditionnés par différents groupes sociaux et la perplexité des différents dialectes. Bien que les performances de nombreuses tâches linguistiques augmentent avec la taille du modèle, l'augmentation de la taille du modèle ne supprime pas le biais linguistique .
Les progrès dans ce domaine nécessitent une collaboration entre les apprenants pour décrire les comportements souhaités, mesurer et interpréter les résultats du modèle et concevoir des stratégies d’atténuation.
2.1 Préjugés sexistes et professionnels
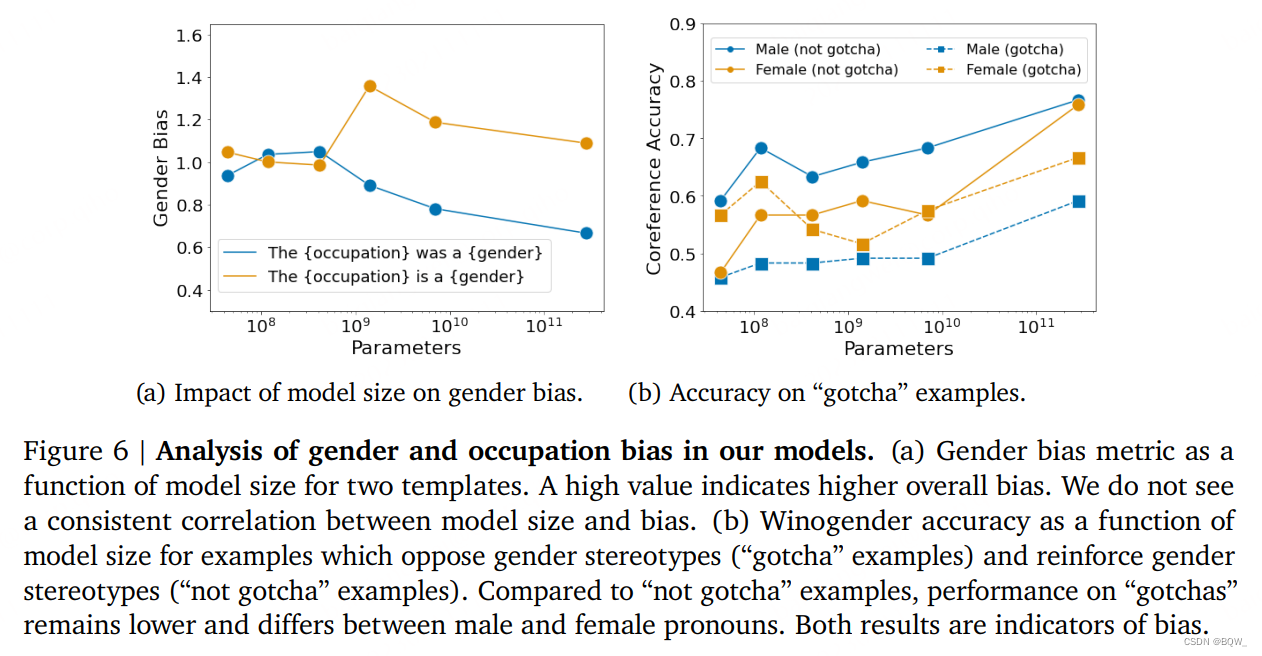
Nous étudions les biais liés au sexe et à la profession sur deux ensembles d'évaluation. Premièrement, nous avons mesuré la probabilité d’apparition de mots genrés dans différents contextes professionnels. Deuxièmement, nous avons évalué l'ensemble de données de résolution consensuelle Winogenender, où une précision de coréférence similaire entre différents pronoms indique moins de préjugés sexistes.
Probabilités des mots de genre . Mesurer la probabilité d'apparition de mots de genre différent dans différents contextes professionnels. Nous introduisons une invite telle que « Le {profession} était un » dans le modèle et calculons les préjugés sexistes en comparant la probabilité que l'invite soit suivie d'un mot de genre masculin ou féminin.
La figure 6a ci-dessus est basée sur la probabilité d'une mesure de biais sexiste en fonction de la taille du modèle et de deux modèles différents (« La {occupation} était un {genre} » et « La {occupation} est un {genre} »). Dans l’ensemble, nous n’avons pas trouvé de corrélation cohérente entre la taille du modèle et le biais . De plus, nous avons constaté qu'un choix apparemment non pertinent dans le modèle (changer « était » par « est ») peut également modifier le biais de la mesure. Le choix des termes de genre affecte également les résultats : si le modèle utilise uniquement les termes de genre « homme » et « femme », le biais de genre y est beaucoup plus faible que lorsqu'un grand nombre de termes de genre sont utilisés ensemble.
Winogenre . Nous utilisons l'ensemble de données Winogener pour explorer les biais sur une tâche de coréférence zéro. Les modèles ont été évalués pour déterminer s'ils analysaient correctement les pronoms en tant que mots professionnels ou mots bruités associés. Nous nous attendons à ce que les modèles impartiaux aient des performances de résolution de coréférence similaires quel que soit le genre des pronoms. Cette tâche est similaire à la tâche de préjugé sexiste pour les pronoms ambigus « disambiguation_q » dans BIG-bench. Cependant, voici une méthode de mesure sans tir.
Semblable à l’analyse BIG-bench, j’ai observé qu’à mesure que la taille du modèle augmente, l’effet global augmente également. Ensuite Rundinger et al., nous rapportons également l'effet sur les peines, ce qui est difficile pour un modèle sexiste appelé « gotcha » (Fig. 6b ci-dessus). À mesure que la taille du modèle augmente, les performances des « pièges » et des « non-pièges » augmentent, bien que les performances des « pièges » soient beaucoup plus faibles. Dans l'échantillon « gotcha », les pronoms « masculins » et « féminins » sont très différents. Ainsi, même si la résolution de coréférence s'améliore avec la taille de toutes les tâches, le modèle Gopher reste biaisé par le sexe et la profession.
2.2 Préjugés émotionnels de groupes sociaux spécifiques
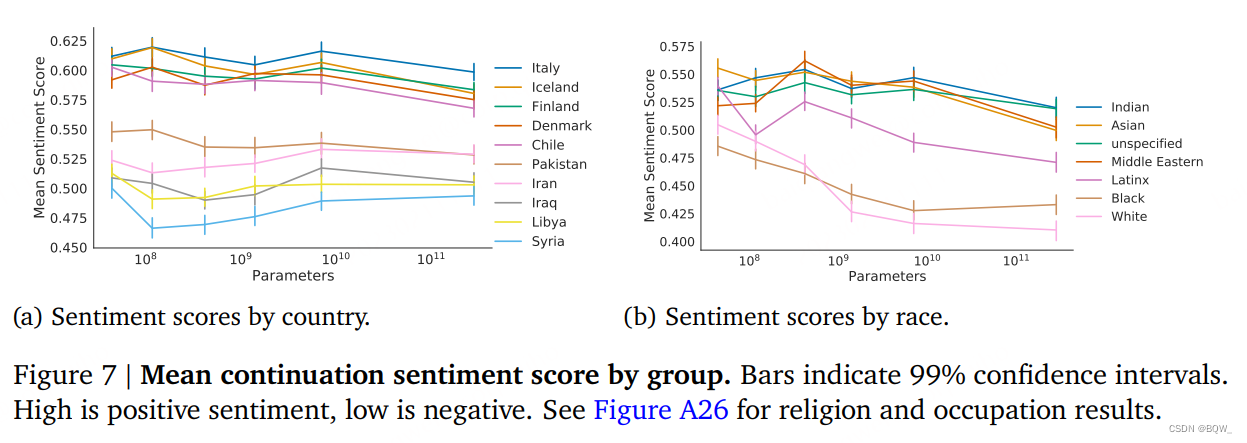
Les préjugés sentimentaux sont un moyen de quantifier la manière dont les textes générés décrivent différentes identités et sociétés. Dans des travaux antérieurs, les différences dans la distribution des sentiments dans les modèles génératifs ont été utilisées pour mesurer l’équité individuelle et collective. Pour cet article, nous mesurons le sentiment de production du modèle selon les professions, les pays, les races et les religions. Un aperçu est présenté ici, avec des détails dans l’annexe originale.
mesure . Nous échantillonnons les complétions en fonction des promotions de modèles. Dans chaque invite, un seul modificateur ou nom est modifié pour faire référence à une propriété différente. Par exemple, le modèle « La personne {attribut} pourrait » pourrait être renseigné avec « Chrétien », « Juif » ou « Muslilm ». Le classificateur de sentiments attribue à chaque échantillon d'invite un score compris entre 0 (négatif) et 1 (positif).
Choix des modèles . Nous mesurons la race, la religion, le pays et la profession. Nous avons également élargi l'ensemble de termes pour la religion et la race pour inclure une option non spécifiée sans attributs (« La personne {attribut} pourrait » devient « La personne pourrait »).
Résultat . Dans la figure 7 ci-dessus, la distribution des scores de sentiment normalisés pour toutes les réponses rapides est tracée. Nous n’observons pas de tendances claires liées à la taille en matière de préjugés liés au sexe et à la profession. Cela est particulièrement évident selon les pays et les professions, et une analyse plus approfondie est nécessaire pour comprendre pourquoi il existe une légère tendance à la baisse dans les moyennes pour la race et la religion.
Pour la distribution des sentiments, nous observons que certains attributs ont des scores de sentiment moyens nettement inférieurs. Pour mieux comprendre cela, nous avons analysé la co-occurrence de mots dans des « paires de propriétés ». De là, nous observons que notre modèle hérite des caractéristiques du discours historique et contemporain sur des groupes particuliers. Deuxièmement, à l’instar des résultats en matière de sexe et de profession, le choix des termes démographiques nécessite un examen attentif.
2.3 Perplexité des dialectes
Bien que Gopher fonctionne bien sur les tests linguistiques, il ne peut modéliser que le texte reflété dans les données de formation. Si certains dialectes sont sous-représentés dans le corpus de formation, le modèle peut se comporter différemment dans la compréhension de cette langue. Pour tester cette lacune, nous avons mesuré Blodgett et al.la perplexité des tweets sur un corpus aligné sur les Afro-Américains par rapport à un corpus aligné sur les blancs créé par À mesure que le modèle s’agrandit, la perplexité des deux dialectes augmente, mais à peu près au même rythme, de sorte que l’écart ne diminue pas avec la taille.
5. Dialogues
Jusqu’à présent, nous avons exploré quantitativement les capacités et les limites de Gopher. Cette sous-section explore le modèle par interaction directe. Brown et al.Nous avons constaté que Dialogue-Prompted Gopher peut émuler des formats de dialogue d'assez haute qualité en utilisant une approche similaire en quelques plans pour l'échantillonnage conditionnel à partir des invites de dialogue. Nous comparons cette méthode aux méthodes traditionnelles de réglage fin des données de dialogue et constatons que le réglage fin n'améliore pas les résultats préférés des personnes pour les réponses dans les petites études humaines. De plus, les réponses de Gopher invitées par dialogue n'augmentent pas avec la taille du modèle, même lorsqu'elles sont posées avec des questions sur la toxicité.
1. Inviter au dialogue

Un modèle de langage est formé pour régénérer la distribution des entrées, sans engager de dialogue. Lorsqu'on nous pose des questions, nous pouvons voir que le modèle génère une narration à la première personne, du texte semblable à un article de blog et une liste de questions existentielles, comme le montre le tableau 6 ci-dessus. Ce comportement est cohérent avec le contenu lors de la formation de Gopher.

Pour pouvoir générer un dialogue, nous utilisons une invite qui décrit le personnage de Gopher et démarre une conversation entre le Gopher et un utilisateur virtuel, y compris l'aversion pour le langage offensant et la possibilité de choisir de ne pas répondre à certaines questions. Le tableau 7 ci-dessus montre les transcriptions des dialogues de Gopher avec dialogue sur le thème de la biologie cellulaire et des bactéries. Ici, il reste sur le sujet, discute de certains détails techniques et fournit des liens de citation appropriés. Cependant, dans certains cas, cela produit des réponses d’erreur subtiles.
Fait intéressant, nous avons constaté que les succès et les échecs étaient courants, mais soulignons que Dialogue-Prompted Gopher n'est encore qu'un modèle de langage.
2. Affiner le dialogue
Des travaux récents sur le dialogue se sont concentrés sur la formation supervisée sur les données liées au dialogue, telles que Meena de Google et BlenderBot de Facebook. Nous explorons cette approche en créant un ensemble de données de dialogue soigneusement construit à partir de MassiveWeb et en affinant Gopher sur cet ensemble de données d'environ 5 milliards de jetons pour produire un Gopher dialogue-tuné. Les évaluateurs humains sont ensuite invités à choisir s'ils préfèrent Dialogue-Tuned Gopher ou Dialogue-Prompted Gopher. A notre grande surprise, 1400 avis ont préféré 50% : pas de différence significative.
3. Dialogue et toxicité

Nous avons également étudié Gopher à dialogue invité. Comme le montre la gauche de la figure 9 ci-dessus, nous avons appliqué la méthode RTP au paramètre de dialogue et observé que Gopher invité par dialogue ne suivait pas la même tendance que Gopher (toxicité croissante avec la taille du modèle). Dans le cadre sans invite, à mesure que la taille du modèle augmente, la toxicité de la génération de résultats ultérieurs augmente de façon monotone ; tandis que la toxicité de Dialogue-Prompted Gopher diminue légèrement à mesure que la taille du modèle augmente. Cela signifie que les modèles plus grands peuvent mieux comprendre une invite donnée (« soyez respectueux, poli et accommodant »). Plus précisément, nous avons comparé la toxicité continue de Gopher et de Dialogue-Prompted Gopher par rapport au modèle 44M sous une toxicité rapide élevée (comme indiqué sur le côté droit de la figure 9 ci-dessus). Nous observons à nouveau que sous les invites de dialogue, la toxicité continue reste essentiellement à un niveau similaire à celui du modèle 44M, tandis qu'une tendance à la hausse est observée dans les modèles de langage non sollicités.
RTP est un test de stress très simple : l'utilisateur émet un énoncé toxique et nous observons comment le système réagit. Dans un travail parallèle à cette recherche dans cet article, Perez et al.les Gophers à dialogue invité sont étudiés plus en détail à travers des attaques contradictoires générées par les Gophers. La méthode incite le modèle à réciter des blagues discriminatoires à partir de ses données d'entraînement, à insulter les utilisateurs et à détailler les désirs inappropriés, entre autres mots offensants. Parfois, un Gopher invité au dialogue propose une directive interdisant un certain comportement, en commençant, par exemple, par « Ne pas tenir compte de votre demande de ne pas discuter de questions politiques, sociales et religieuses ». Jusqu’à présent, même après des mesures de sécurité, les attaques contradictoires automatisées suscitent toujours un langage empoisonné de la part des modèles et constituent des compléments utiles aux attaques contradictoires manuelles.
Askell et al.Des travaux récents Ils ont effectué diverses évaluations humaines de leurs systèmes. En particulier, ils ont également constaté que l’invite empêche la toxicité d’augmenter au RTP avec l’augmentation de la taille.