1. Definiciones
Cada partición consiste Kafka ordenó serie, inmutable mensaje composición, estos mensajes se añaden continuamente a la partición. Cada partición tiene un número de mensaje serial continuo para identificar de forma única una partición mensaje.
número de desplazamiento de mensaje grabado para ser transmitido al lado del Consumidor.
Transmitir sistema de procesamiento de tres semántica común:
| Como máximo una vez | Cada registro se procesa ya sea una vez, o no del todo trato con |
| Al menos una vez | Esta vez, mejor que la mayoría, ya que asegura que no se pierden datos. Pero puede haber duplicado |
| Y sólo una vez | Cada registro será tratado exactamente una vez, no hay datos se perderán, y no hay datos será procesado varias veces |
La semántica de los sistemas de transmisión son a menudo capturados en términos de la cantidad de veces cada registro puede ser procesado por el sistema. Hay tres tipos de garantías que un sistema puede proporcionar en todas las condiciones de funcionamiento (a pesar de los fracasos, etc.)
- Como máximo una vez : Cada registro será procesado una vez, ya sea o no procesado en absoluto.
- Al menos una vez : Cada registro se procesará una o más veces. Esto es más fuerte que en situación de máximo una vez , ya que asegurarse de que no se perderán los datos. Pero puede haber duplicados.
- Exactamente una vez : Cada registro será procesada exactamente una vez - se perderá ningún dato y no hay datos será procesado varias veces. Esto es obviamente la mejor garantía de los tres.
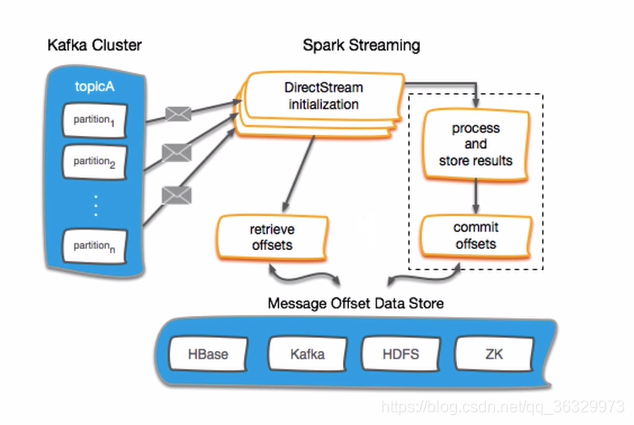
2.Kafka compensado con Gestión de Transmisión de chispa
Offset En primer lugar, propongo que se tienda en Zookeeper, Zookeeper comparación con hbase etc. para más ligeras, y HA (clúster de alta disponibilidad, alta disponible) es, compensado más seguro.
Para la gestión común de compensación de dos pasos:
- Guardar las compensaciones
- Get compensaciones
3. listos Ambiental
Iniciar un productor de Kafka, pruebas utilizando tema: tp_kafka:
./kafka-console-producer.sh --broker-list hadoop000:9092 --topic tp_kafkaKafka comenzó un consumidor:
./kafka-console-consumer.sh --zookeeper hadoop000:2181 --topic tp_kafkaLos datos de producción de IDEA:
package com.taipark.spark;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import java.util.Properties;
import java.util.UUID;
public class KafkaApp {
public static void main(String[] args) {
String topic = "tp_kafka";
Properties props = new Properties();
props.put("serializer.class","kafka.serializer.StringEncoder");
props.put("metadata.broker.list","hadoop000:9092");
props.put("request.required.acks","1");
props.put("partitioner.class","kafka.producer.DefaultPartitioner");
Producer<String,String> producer = new Producer<>(new ProducerConfig(props));
for(int index = 0;index <100; index++){
KeyedMessage<String, String> message = new KeyedMessage<>(topic, index + "", "taipark" + UUID.randomUUID());
producer.send(message);
}
System.out.println("数据生产完毕");
}
}
4. La gestión del primer desplazamiento: más pequeña
Spark enlaces de secuencias cuentan el número de Kafka:
package com.taipark.spark.offset
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object Offset01App {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("Offset01App")
val ssc = new StreamingContext(sparkConf,Seconds(10))
val kafkaParams = Map[String, String](
"metadata.broker.list" -> "hadoop000:9092",
"auto.offset.reset" -> "smallest"
)
val topics = "tp_kafka".split(",").toSet
val messages = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,topics)
messages.foreachRDD(rdd=>{
if(!rdd.isEmpty()){
println("Taipark" + rdd.count())
}
})
ssc.start()
ssc.awaitTermination()
}
}
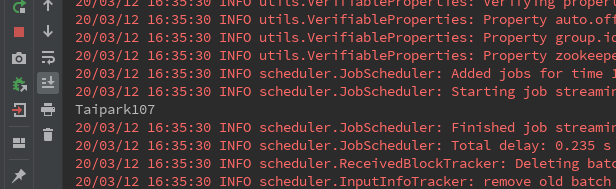
Kafka datos de reproducción 100 -> Spark Streaming aceptado:

Pero entonces, si reinicio Spark Transmisión de parada:
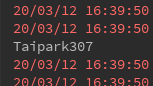
Aquí encontrará un conteo de volver a empezar, porque el código con el fin de establecer el valor de auto.offset.reset más pequeño. (Antes de la versión kafka-0.10.1.X)
5. La gestión de segunda offset: puesto de control
Crear una carpeta / desplazamiento en HDFS:
hadoop fs -mkdir /offset
Uso Punto de control:
package com.taipark.spark.offset
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Duration, Seconds, StreamingContext}
object Offset01App {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("Offset01App")
val kafkaParams = Map[String, String](
"metadata.broker.list" -> "hadoop000:9092",
"auto.offset.reset" -> "smallest"
)
val topics = "tp_kafka".split(",").toSet
val checkpointDirectory = "hdfs://hadoop000:8020/offset/"
def functionToCreateContext():StreamingContext = {
val ssc = new StreamingContext(sparkConf,Seconds(10))
val messages = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,topics)
//设置checkpoint
ssc.checkpoint(checkpointDirectory)
messages.checkpoint(Duration(10*1000))
messages.foreachRDD(rdd=>{
if(!rdd.isEmpty()){
println("Taipark" + rdd.count())
}
})
ssc
}
val ssc = StreamingContext.getOrCreate(checkpointDirectory,functionToCreateContext _)
ssc.start()
ssc.awaitTermination()
}
}
Nota: IDEA modificar HDFS usuario, opciones de VM en la configuración de:
-DHADOOP_USER_NAME=hadoopPrimera apertura:
Se encontró que el consumo de 100 antes. Esto es después de la parada, la producción de 100, y luego empezar:
Encontrado aquí sólo para leer el último 100 entre el final de la salida, en lugar del menor número de piezas antes de leer todo lo mismo.
Pero hay un problema checkpiont, si esta gestión de manera compensada, siempre y cuando los cambios de la lógica de negocio, no habrá efecto del punto de control. Debido a que invoca es getOrCreate ().
6. La tercera gestión offset: desplazamiento manejar manualmente
ideas:
- La creación de StreamingContext
- Obtener datos de Kafka <== quedar compensado
- El procesamiento de la lógica de servicio
- El resultado del procesamiento se escribe en el almacenamiento externo ==> Guardar compensado
- Iniciar las esperas del programa para el hilo para terminar
package com.taipark.spark.offset
import kafka.common.TopicAndPartition
import kafka.message.MessageAndMetadata
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtils}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object Offset01App {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("Offset01App")
val ssc = new StreamingContext(sparkConf,Seconds(10))
val kafkaParams = Map[String, String](
"metadata.broker.list" -> "hadoop000:9092",
"auto.offset.reset" -> "smallest"
)
val topics = "tp_kafka".split(",").toSet
//从某地获取偏移量
val fromOffsets = Map[TopicAndPartition,Long]()
val messages = if(fromOffsets.size == 0){ //从头消费
KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,topics)
}else{ //从指定偏移量消费
val messageHandler = (mm:MessageAndMetadata[String,String]) => (mm.key,mm.message())
KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder,(String,String)](ssc,kafkaParams,fromOffsets,messageHandler)
)
}
messages.foreachRDD(rdd=>{
if(!rdd.isEmpty()){
//业务逻辑
println("Taipark" + rdd.count())
//将offset提交保存到某地
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
offsetRanges.foreach(x =>{
//提交如下信息提交到外部存储
println(s"${x.topic} ${x.partition} ${x.fromOffset} ${x.untilOffset}")
})
}
})
ssc.start()
ssc.awaitTermination()
}
}
- En primer lugar guardar después de guardar los datos de desplazamiento puede provocar la pérdida de datos
- Después de que el primer salvamento de datos datos de corrección almacenados pueden conducir a la repetición
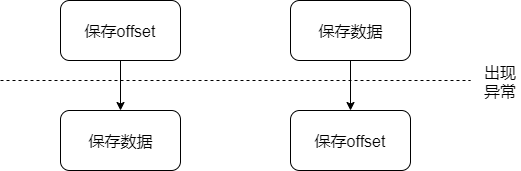
Solución 1: Lograr idempotente (idempotente)
En una operación de programación es idempotente características se lleva a cabo cualquier número de veces que son el impacto y la influencia de la primera representación de la misma.
Solución 2: Transacción (transacción)
1. La base de datos de transacción puede contener una o más operaciones de base de datos, estas operaciones constituyen un todo lógico.
2. Estas operaciones de bases de datos constituyen un todo lógico, ya sea ejecutado todo éxito o no realizarse.
3. Todas las operaciones compensar la transacción, o bien todos tienen un impacto en la base de datos, o todos no tienen un impacto, es decir, independientemente de si la operación tiene éxito, la base de datos es siempre estado consistente.
4. Lo anterior es aún válida en la presencia de un fallo y, incluso si hay transacciones simultáneas en la base de datos.
La lógica de negocio y de offset almacenado en una transacción, sólo una vez.
7.Kafka-0.10.1.X versión posterior auto.kafka.reset:
| más temprano | Cuando desplazamiento se ha presentado en relación con el distrito, el gasto de desplazamiento inicial presentado; sin desplazamiento presentado por el consumo cero |
| último | Bajo ninguna datos de corrección cuando se presentó, un nuevo consumidor crea la partición, cuando no se compensa presentado en relación con el distrito, el gasto de desplazamiento inicial presentado |
| ninguna | tema cuando están presentes en offset presentaron las particiones, tras el desplazamiento desde el comienzo del consumidor, siempre y cuando hay un desfase partición presentado no existe, se produce una excepción |
