1 Instalación y despliegue
1.1 Planificación de grupos

1.2 Implementación de clústeres
Dirección de descarga oficial: http://kafka.apache.org/downloads.html
(1) Descomprima el paquete de instalación:
tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/
(2) Modifique el nombre del archivo descomprimido:
mv kafka_2.12-3.0.0/ kafka
(3) Vaya al directorio /opt/module/kafka/config y modifique el archivo de configuración server.properties: modifique
:
valor del parámetro broker.id=0 (el número único global del agente, que no se puede repetir, solo puede ser un número) ;
registro de operación de kafka (datos) ruta de almacenamiento log.dirs=/opt/module/kafka/datas;
conexión de configuración Dirección de clúster de Zookeeper zookeeper.connect=hadoop102:2181, hadoop103:2181, hadoop104:2181/kafka.
#broker 的全局唯一编号,不能重复,只能是数字。
broker.id=0
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘 IO 的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/opt/module/kafka/datas
#topic 在当前 broker 上的分区个数
num.partitions=1
#用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
# 每个 topic 创建时的副本数,默认时1 个副本
offsets.topic.replication.factor=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
#每个 segment 文件的大小,默认最大 1G
log.segment.bytes=1073741824
# 检查过期数据的时间,默认 5 分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
#配置连接Zookeeper 集群地址(在 zk 根目录下创建/kafka,方便管理)
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
(4) Distribución de paquetes de instalación
xsync kafka/
(5) Modifique broker.id=1 y broker.id=2 en el archivo de configuración /opt/module/kafka/config/server.properties en hadoop103 y hadoop104 respectivamente. (broker.id no debe repetirse, es único en todo el clúster).
(6) Agregue la configuración de la variable de entorno kafka en el archivo /etc/profile.d/my_env.sh:
sudo vim /etc/profile.d/my_env.sh
#添加:
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
(7) Actualizar las variables de entorno, distribuir las variables de entorno a otros nodos y obtenerlas.
source /etc/profile
sudo xsync /etc/profile.d/my_env.sh
(8) Al iniciar el clúster, primero debe iniciar el clúster de zookeeper y luego iniciar Kafka. Al cerrar el clúster, primero debe asegurarse de que Kafka esté cerrado antes de cerrar zookeeper.
1.3 Script de inicio y detención del clúster
(1) Cree el archivo de script kf.sh en el directorio /home/username/bin:
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------启动 $i Kafka--------"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh - daemon /opt/module/kafka/config/server.properties"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------停止 $i Kafka--------"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh "
done
};;
esac
(2) Agregar permiso de ejecución:
chmod 777 kf.sh
(3) Inicie el clúster:
zk.sh start
kf.sh start
Nota: Al detener el clúster de Kafka, asegúrese de esperar a que se detengan todos los procesos del nodo de Kafka antes de detener el clúster de Zookeeper. Debido a que el clúster de Zookeeper registra la información relevante del clúster de Kafka, una vez que el clúster de Zookeeper se detiene primero, el clúster de Kafka no tiene forma de obtener la información del proceso detenido y solo puede eliminar manualmente el proceso de Kafka.
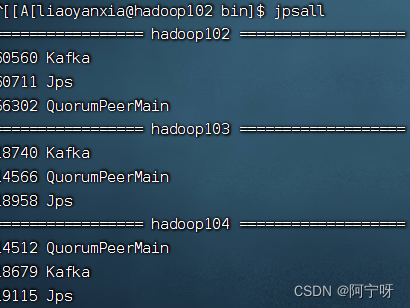
2 Operación de línea de comando de Kafka
2.1 Operaciones de línea de comando de tema
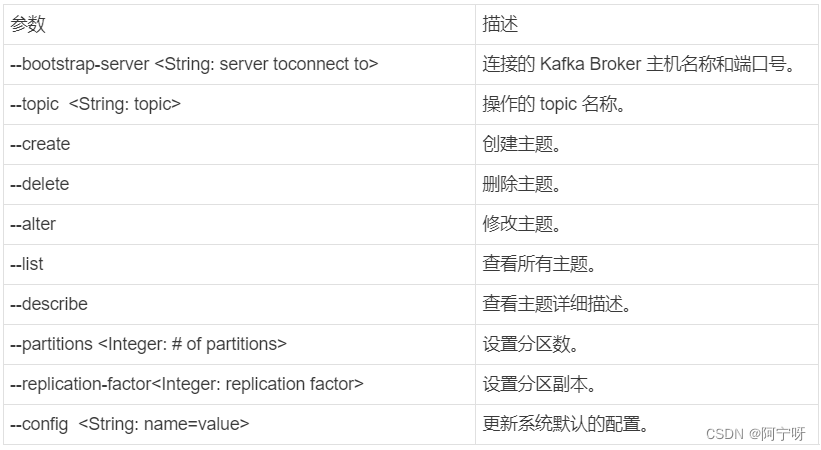
#查看操作主题命令参数
bin/kafka-topics.sh
#查看当前服务器中所有topic
bin/kafka-topics.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --list
#创建first topic
bin/kafka-topics.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --create --partitions 1 --replication-factor 3 --topic first
#选项说明:
#--topic 定义 topic 名
#--replication-factor 定义副本数
#--partitions 定义分区数
#查看first主题详情
bin/kafka-topics.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --describe --topic first
#修改分区数,分区数只能增不能减
bin/kafka-topics.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --alter --topic first --partitions 3
#删除topic
bin/kafka-topics.sh --bootsrtap-server hadoop102:9092,hadoop103:9093 --delete --topic first
2.2 Operación de la línea de comando del productor
#查看操作生产者命令参数
bin/kafka-console-producer.sh

#发送消息
bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --topic first
>hello
2.3 Operación de la línea de comando del consumidor
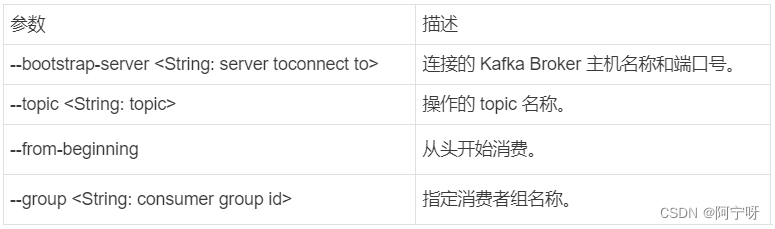
#查看操作消费者命令参数
bin/kafka-console-consumer.sh
#消费first主题中的数据
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --topic first
#把主题中所有的数据读取出来(包括历史数据)
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --from-beginning --topic first