-
Kafka es una plataforma de transmisión distribuida (sistema de mensajes).
-
Kafka se utiliza para el procesamiento de flujo, el seguimiento de la actividad del sitio web, la recopilación y el monitoreo de índices, la agregación de registros, el análisis en tiempo real, el CEP, la importación de datos en Spark, la importación de datos en Hadoop, CQRS, la reproducción de mensajes, la recuperación de errores y la garantía de envíos distribuidos para el cálculo de la memoria Microservicios).
-
Kafka se utiliza para flujos de datos en tiempo real, para recopilar grandes datos o para realizar análisis en tiempo real (o ambos) .
-
Kafka es una plataforma de transmisión distribuida que se utiliza para publicar y suscribirse a transmisiones de registros .
-
Kafka es una plataforma de transmisión distribuida para publicar y suscribirse a transmisiones de registros --- podemos publicar u obtener registros de mensajes a través de Kafka.
-
Mecanismo de respaldo para garantizar la seguridad de los datos:
-
Kafka de alto rendimiento y baja latencia está diseñado para permitir que sus aplicaciones procesen registros a medida que ocurren (para que pueda operar registros en tiempo real)
-
La persistencia eficiente proporciona estabilidad y velocidad: Kafka es rápido y usa IO de manera eficiente al agrupar y comprimir registros. Al agrupar y comprimir registros para usar IO de manera efectiva.
-
Kafka se usa para desacoplar flujos de datos (Kafka se usa para desacoplar flujos de datos)
-
-
Kafka se usa para transmitir datos a lagos de datos, aplicaciones y sistemas de análisis de flujo en tiempo real (puede enviar flujos de datos a grupos de datos, aplicaciones o sistemas de análisis de datos en tiempo real, como Hadoop)
-
Alta concurrencia
-
-
Para los datos de registro y los sistemas de análisis fuera de línea como Hadoop, pero que requieren limitaciones de procesamiento en tiempo real, Kafka es una solución viable. El propósito de Kafka es unificar el procesamiento de mensajes en línea y fuera de línea a través de un mecanismo de carga en paralelo, y también proporcionar un consumo en tiempo real a través de máquinas de clúster.
Red del Gobierno de Kafka: http://kafka.apache.org/
Página de documentación de ayuda: http://kafka.apache.org/documentation.html
página wiki: https://cwiki.apache.org/confluence/display/KAFKA/Index
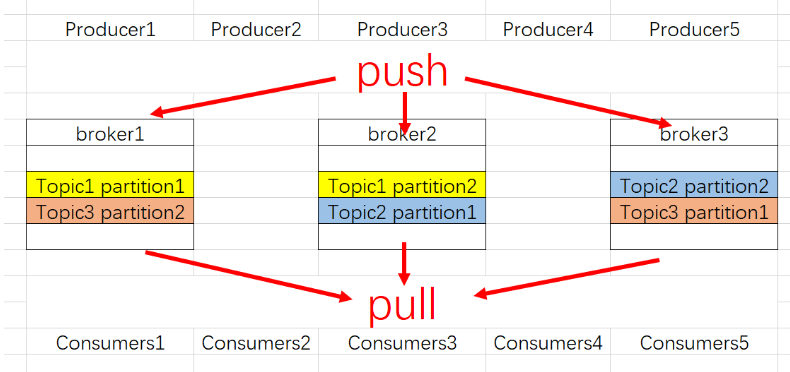
Estructura Kafka
-
Broker: un clúster de Kafka contiene uno o más servidores, estos servidores se denominan brokers.
-
Tema: cada mensaje publicado en el clúster Kafka tiene una categoría, y esta categoría se llama Tema. (Físicamente, los mensajes de diferentes temas se almacenan por separado; lógicamente, los mensajes de un tema se almacenan en uno o más intermediarios, pero los usuarios solo necesitan especificar el tema del mensaje para producir o consumir datos sin tener que preocuparse de dónde se almacenan los datos)
-
Partición: el tema es una partición (partición), la partición es un concepto físico, cada tema contiene una o más particiones.
-
Productor: Productor de mensajes, responsable de publicar mensajes al agente Kafka.
-
Consumidor: un consumidor de mensajes, un cliente que lee mensajes del agente Kafka.
-
Grupo de consumidores: cada consumidor pertenece a un grupo de consumidores específico (puede especificar el nombre del grupo para cada consumidor, si no especifica el nombre del grupo, pertenece al grupo predeterminado).
Tema
-
Cada tema es un resumen de un grupo de mensajes. Kafka divide cada tema.
-
Cada partición se compone de una serie de mensajes ordenados e inmutables , que se agregan continuamente a la partición.
-
Cada mensaje en la partición tiene un número de secuencia continua llamado desplazamiento, que se utiliza para identificar de forma única el mensaje en la partición.
-
Dentro de un período de tiempo configurable, el clúster Kafka retiene todos los mensajes publicados, se consuman o no.
-
Por ejemplo, si la política de retención de mensajes se establece en 2 días, se puede consumir un mensaje dentro de los dos días posteriores a su publicación. Luego se descartará para liberar espacio. El rendimiento de Kafka es un nivel constante independiente de la cantidad de datos, por lo que mantener demasiados datos no es un problema (siempre que haya suficientes discos).
-
-
Los únicos datos que cada consumidor necesita mantener es la posición del mensaje en el registro , que es el desplazamiento. Al restablecer este valor, se pueden leer los datos del mensaje anterior.
Dividir
-
Cada partición tiene copias en varios servicios en el clúster de Kafka, de modo que estos servicios que contienen copias pueden procesar datos y solicitudes conjuntamente, y se puede configurar el número de copias. La copia hace que Kafka sea tolerante a fallas.
-
Cada partición tiene un servidor como "líder" y cero o varios servidores como "seguidores"
-
El líder es responsable de manejar la lectura y escritura de mensajes.
-
los seguidores copian al líder
-
Si el líder cae, uno de los seguidores se convertirá automáticamente en el líder.
-
Cada servicio en el clúster desempeñará dos funciones al mismo tiempo: como líder de una parte de la partición que posee y como seguidor de otras particiones, para que el clúster tenga un mejor equilibrio de carga.
-
-
La gestión de líderes y seguidores se gestiona a través de clústeres zk.
Productor
-
Productor se refiere al productor de mensajes del grupo Kafka. El productor envía el mensaje al tema que especifica y es responsable de decidir en qué partición publicar.
-
Por lo general, la partición se selecciona aleatoriamente mediante el mecanismo de equilibrio de carga, pero la partición también se puede seleccionar mediante una función de partición específica. En términos generales, el segundo método se usa más comúnmente ahora.
-
Consumidor
-
Por lo general, hay dos modos de extraer (extraer) mensajes: poner en cola (poner en cola) y publicar-suscribir (publicar-suscribir).
-
En el modo de cola, los consumidores pueden leer mensajes del servidor al mismo tiempo, y cada mensaje solo lo lee uno de los consumidores;
-
En el modelo de publicación-suscripción, los mensajes se transmiten a todos los consumidores.
-
Los consumidores pueden unirse a un grupo de consumidores, cada grupo tiene y solo un servidor puede capturar mensajes.
-
Si todos los consumidores no están en grupos diferentes, esto se convierte en un modelo de publicación y suscripción, y todos los mensajes se distribuyen a todos los consumidores.
-
Si todos los consumidores están en el mismo grupo, es el modo de cola.
Diferencia de Flume