En las primeras semanas de lecciones que hemos aprendido de aprendizaje supervisado de regresión lineal, regresión logística, redes neuronales. Recordando la labor supuesto, todos los datos de la muestra se utilizan para entrenar el modelo. Validar el modelo, sólo los resultados del modelo con los datos se comparan los resultados parecen exactitud derecha. Este método de entrenamiento es correcta? velocidad correcta puede ser utilizado como criterios para evaluar el modelo? Usted aprenderá cómo evaluar nuestro modelo, así como la forma de llevar las estrategias de mejora correctos y eficaces.
Haga clic en el vídeo cursos usted será capaz de aprender continuamente Ng, por supuesto, el código Python está en el trabajo del curso se ha puesto en Github, puede hacer clic en el código del curso a Github Ver (Github puede acceder, a continuación, puede hacer clic en Codificación de vista), y los errores en el código Bienvenido a la mejora observada.
mejores estrategias
para la predicción de la función, que a menudo utilizan varios medios para mejorar:
Los datos recogidos más muestras
para reducir el número de características, vaya a menos que las principales características de
la introducción de las características más relevantes
características polinómicas
reducen los regularización parámetro λλ
parámetros de regularización aumentar λλ
Andrew Ng le dijo que había visto una gran cantidad de desarrolladores ciegamente mejora el uso estrategia, para lo cual pasó mucho tiempo y esfuerzo, sin mucho efecto. Por lo que necesitamos una cierta base para ayudarnos a elegir la estrategia correcta.
Dividir el conjunto de datos
utilizado para evaluar el modelo, el conjunto de datos que generalmente se divide en tres partes, del 60% al 60% del conjunto de entrenamiento, el 20% del conjunto de validación cruzada del 20% y del 20% al 20% del equipo de prueba, y utilizando el error como el Modelo evaluación de la forma de estos conjuntos, una función de coste error el mismo que el anterior (función lineal error de regresión más adelante).
Js ([theta]) = = 1 ms 12msΣi (H?. (X (I) S) -Y (I) S) 2 (S = Tren, CV, Test)
Js ([theta]) = = 1 ms 12msΣi (XS H?. ( (i)) - ys (i )) 2 (s = tren, cv, prueba)
en el conjunto dividido, se utiliza un conjunto de entrenamiento para entrenar a los parámetros θθ, conjuntos de validación cruzada para seleccionar el modelo (tales como el uso de cuántas veces polinomio característico), utilizando el equipo de ensayo para evaluar la capacidad de predicción del modelo.
Varianza y la desviación
cuando los malos resultados de nuestro modelo, por lo general hay dos problemas, uno de ellos es un problema de alto sesgo, el otro es un problema de alta varianza. Ellos ayudan a identificar maneras de elegir la optimización de la derecha, por lo que vamos a ver la importancia de la desviación y la varianza.
- Desviación: brecha entre las expectativas y los resultados reales de los resultados del modelo de muestra descrito.
- Varianza: Modelo Descripción estabilidad de salida para un valor dado.
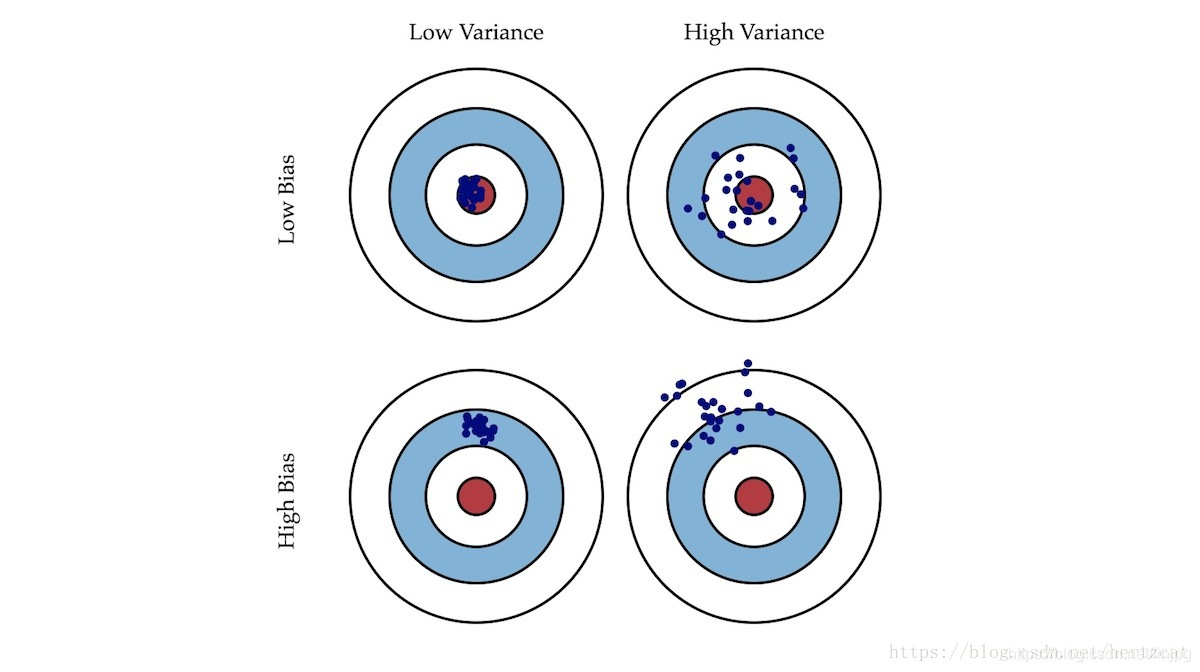
Como disparar, disparar desviación describir nuestra global se ha desviado de nuestro objetivo, y si la varianza derecho describe el tiroteo. conjunto Vamos a través de la formación y la curva de error de validación cruzada en cada set caso a intuitivamente entender la importancia de la desviación y alta varianza es alta.
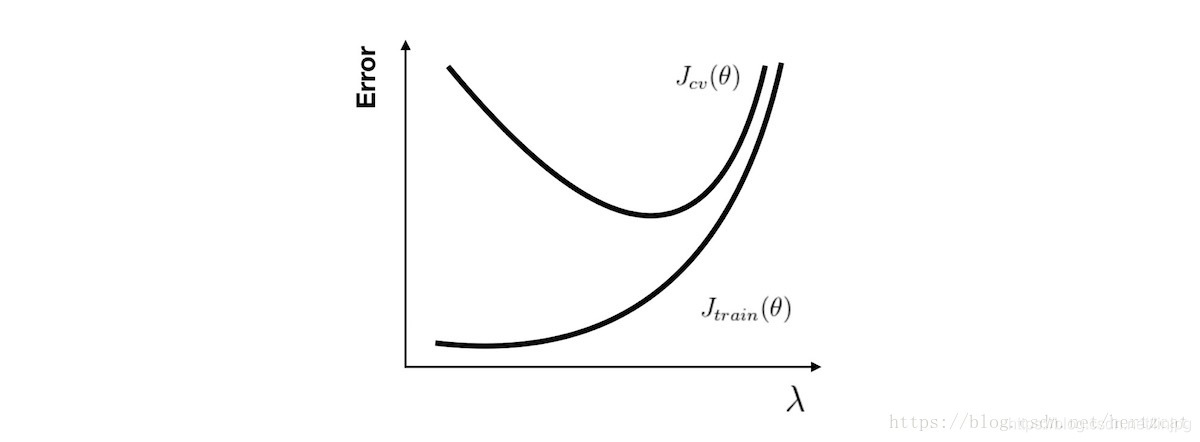
Para la regresión polinómica, cuando el número de bajas seleccionado, nuestro conjunto de entrenamiento y el error de validación cruzada de error conjunto haría en gran manera, cuando el número acaba de seleccionar, del conjunto de entrenamiento y el error de error conjunto de validación cruzada es muy pequeña; cuando el número es demasiado grande el Produce exceso de ajuste, aunque el error es pequeño conjunto de entrenamiento, pero el error conjunto de validación cruzada sería grande (diagrama de abajo).

Así podemos calcular Jtrain (θ) Jtrain (θ) y Jcv (θ) Jcv (θ), si también muy grande, está experimentando un problema de sesgo alto, y Jcv (θ) Jcv (θ) que Jtrain (θ) Jtrain (θ) es mucho más grande, que está experimentando un problema de alta varianza.
Para el parámetro de regularización problema alta varianza, utilizando los mismos métodos de análisis, cuando el parámetro es pequeño propensos a fenómeno exceso de ajuste, que es. Y propenso al fenómeno de la mala parámetro de ajuste es relativamente grande, es decir, alta problema del sesgo.
La curva de aprendizaje
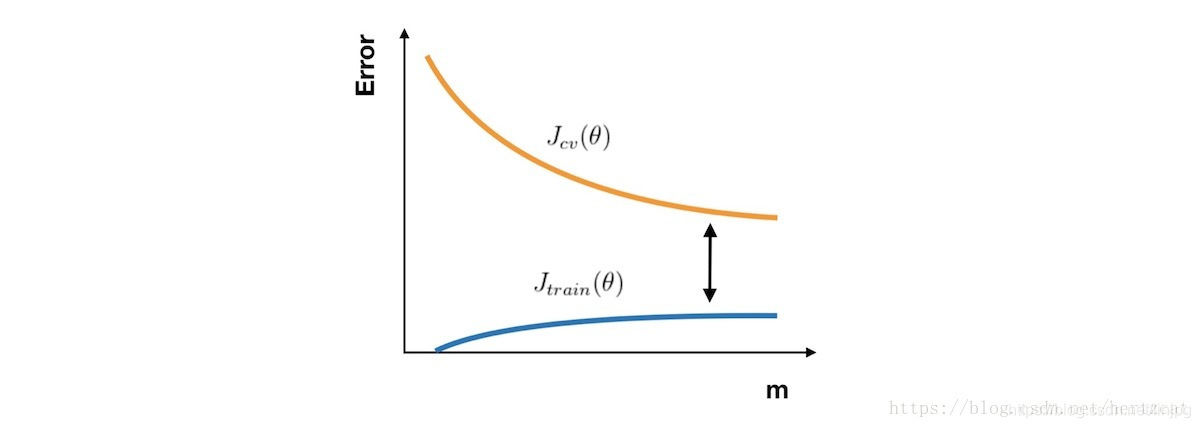
si desea comprobar si su trabajo o algoritmo de aprendizaje para mejorar el rendimiento del algoritmo, la curva de aprendizaje es una herramienta muy intuitiva y eficaz. El eje horizontal es el número de muestras de la curva de aprendizaje, el eje vertical representa el conjunto de entrenamiento y error conjunto de validación cruzada. Así pues, en un principio, debido al pequeño número de muestras, Jtrain (θ) Jtrain (θ ) casi nada, pero Jcv (θ) Jcv (θ) es muy grande. A medida que el número de muestras, Jtrain (θ) Jtrain (θ ) está aumentando, mientras que JCV (theta) Jcv (θ) aumenta a medida que el mejor ajuste a los datos de entrenamiento y por lo tanto disminuir. Por lo tanto, el aspecto curva de aprendizaje, como se muestra a continuación:
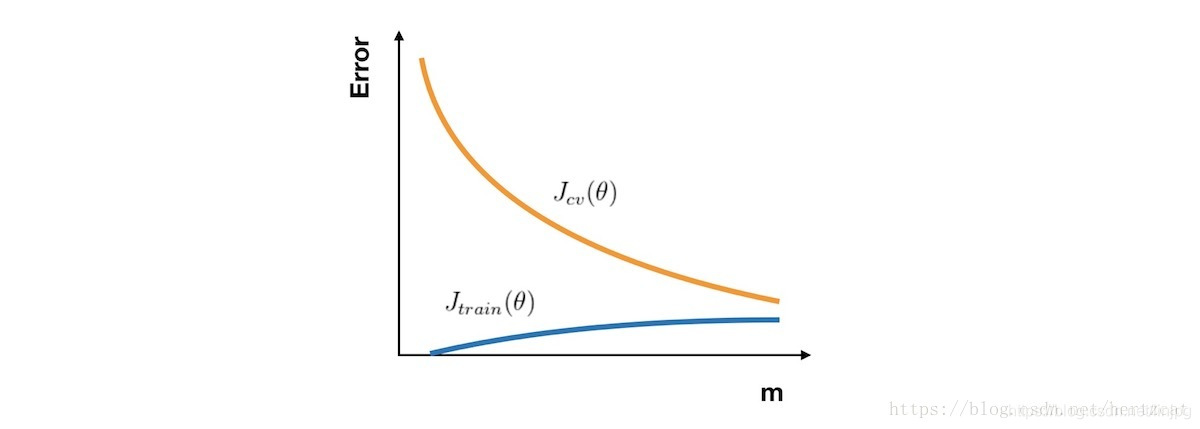
En el caso de la alta desviación, Jtrain (θ) Jtrain (θ ) con Jcv (θ) Jcv (θ) ha estado muy cerca, pero un gran error. Esta vez ciegamente a aumentar el número de muestras no reconocen el rendimiento del algoritmo trae mejorado.
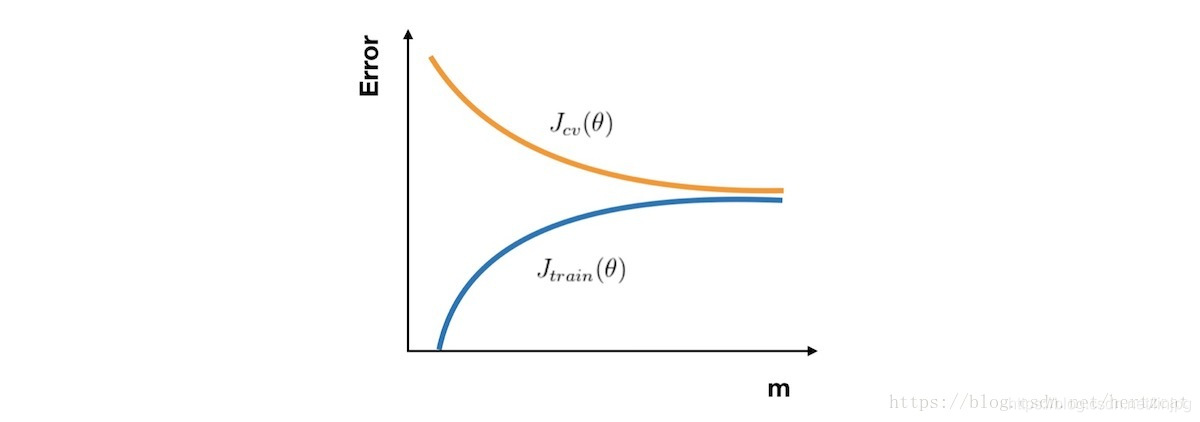
En el caso de una alta varianza, Jtrain (θ) Jtrain (θ ) de error es pequeño, Jcv (θ) Jcv (θ ) es probablemente relativamente grandes, recoger más muestras para llevar ayuda.
Resumen
Con estas herramientas de análisis, será capaz de llegar a nuestras estrategias de mejora en qué escenario:
[High varianza] para recoger más muestras de datos
[alta varianza] reduciendo el número de características, para eliminar características no esenciales
[alta desviación] introducción de características más relevantes
[desviación alta] polinomio característico
[alta desviación] reducida parámetro de regularización λλ
[alta varianza] aumentar la λ parámetro de regularización
Referencias Andrew Ng Machine Learning: varianza y desviación de
09 aprendizaje automático (Andrew Ng): diagnóstico de la máquina de aprendizaje
