Hay algo mal, por favor, corríjanme
Ordenar burbuja
La idea central
Si el número n dispuestas en orden ascendente, de atrás hacia delante ascendente tamaño comparación del par adyacente (creo que se entiende mejor), si el primero que lo segundo en un gran inmediatamente transposición Talia poner, posición directa de cambio, la primera pasada por el más grande en el último, después de la última sin comparación, la segunda vez, la segunda más grande en segundo lugar. . . . . . La comparación de la primera pasada de las n-1 veces, intercambió tiempos de incertidumbre, compara la segunda vez n-2 veces. . . . .
void bubble_sort(int a[],int n)
{
int tem=0;
for(int i=n-1;i>0;--i)
{
for(int j=0;j<i;++j)
{
if(a[j]>a[j+1])
{
tem=a[j];
a[j]=a[j+1];
a[j+1]=tem;
}
}
}
}
selección Ordenar
La idea central
Los métodos específicos son:
Atravesando una grabación de la localización de los elementos más valiosos, el final de la travesía, el valor de este elemento se ajusta a la posición más adecuada de
la primera pasada, comparar los tiempos de n-1, sólo un cambio, será la colocación adecuada del valor de la mayoría
void sort(int a[],int n){
for(int i=0;i<n;i++)//外层循环
{
int min=a[i];//每次循环把a[i]假设当前最小的数
int index=i;//相当一个索引,始终指向最小的
for(int j=i+1;j<n;j++)//内层循环,从剩下的数中找有没有更小的
{
if(a[j]<min)
{
min=a[j];
index=j;//跟新索引
}
}
int temp=a[index];//交换
a[index]=a[i];
a[i]=temp;
}
}
改进
void select_sort(int a[],int n)
{
int k,temp;
for(int i=0;i<n-1;i++)
{
k=i;//假设最小为a[i],用k标记
for(int j=i+1;j<n;j++)//内层循环,从剩下的数中找有没有更小的
{
if(a[j]<a[k])
{
k=j;//找到新的最小的,跟新k的值
}
}
if(i!=k)//比较i和k的值,判断是否交换
{
temp=a[i];
a[i]=a[k];
a[k]=temp;
}
}
}
La diferencia en el
caso en el que los mismos datos, el número de ciclos de los dos algoritmos es el mismo, el mismo número de comparaciones, pero la selección ordenar sólo 0-1 veces el cambio y cambio de tipo burbuja sólo 0 a n veces.
La parte principal del algoritmo afecta nuestro rendimiento es la circulación y el intercambio, obviamente, cuanto más el número, peor será el rendimiento. Es complejidad de O (n * n). Pero la eficiencia de diferentes
burbuja para ordenar:
cuando los datos en el caso inverso, el mismo número de ciclos como el intercambio (el intercambio será determinado en cada ciclo),
una complejidad de O (n * n). Cuando los datos son positivos, no habrá ningún cambio. La complejidad es O (0). Trastorno en un estado intermedio. Es por esta razón, por lo general estamos algoritmo para comparar el número de ciclos.
Selección para ordenar:
Debido a que cada bucle externo genera sólo un cambio (sólo un mínimo). Por lo tanto, f (n) <= n
tenemos f (n) = O (n ). Por lo tanto, más caos en los datos, se puede reducir el número de veces que un cierto cambio.
Ordenación rápida
La idea central:
Ordenar la inserción
El núcleo idea:
la ordenación por inserción que cada paso será una fila de datos a insertar en el tamaño adecuado de acuerdo con su posición ya ordenadas de datos hasta que todos cued.
1, empezando desde el primer elemento que a [0] puede considerarse que han sido ordenados.
2, ir a buscar el siguiente elemento de la secuencia de elementos ha sido ordenada en el escaneado de la parte posterior
3, si el elemento a [0] (ordenados), un nuevo elemento es mayor que una y, a continuación los elementos de un cambio [1] [0] a la siguiente posición
4, 3 repiten hasta que encuentre la ubicación es menor o igual elementos ordenados del nuevo elemento
5, el nuevo elemento se inserta en la posición
6 se repitió 2
método de ordenación por inserción para ordenar y dividir directamente en la inserción binaria tipo son dos, aquí solamente la inserción directa especie, la inserción binaria tipo Ver otro artículo http://blog.csdn.net/qq_29232943/article/details/52939374
1 cartas de presentación los cuatro elementos del proceso directamente en el tipo, un total de (a), (b), (c) la interpolación cúbica.
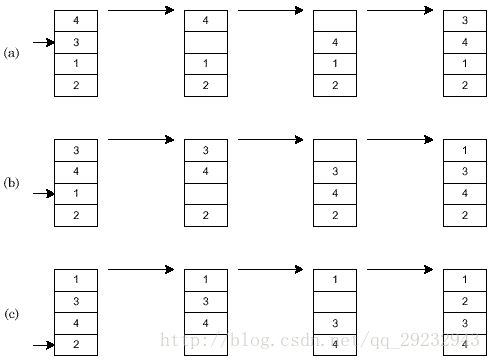
#include <iostream>
using namespace std;
void insert_sort(int a[],int n);
int main()
{
int a[]={3,41,369,1,2,4,5,9};
int n=8;
insert_sort(a,n);
for(int i=0;i<n;i++)
{
cout<<a[i]<<" ";
}
return 0;
}
void insert_sort(int a[],int n)
{
for (int i=1;i<n;i++)
{
for(int j=i;(j>0)&&(a[j]<a[j-1]);j--)
{
int tem=a[j];
a[j]=a[j-1];
a[j-1]=tem;
}
}
}
El mejor de los casos, los ya ascendente, sólo n-1 comparaciones, el peor de los casos, es descendente, a n (n-1) / comparaciones
complejidad media de O (n2)
