Leer este artículo ya no será un problema para el "algoritmo de clasificación de matrices" (algoritmo de clasificación de burbujas, algoritmo de clasificación directa, algoritmo de clasificación inversa)
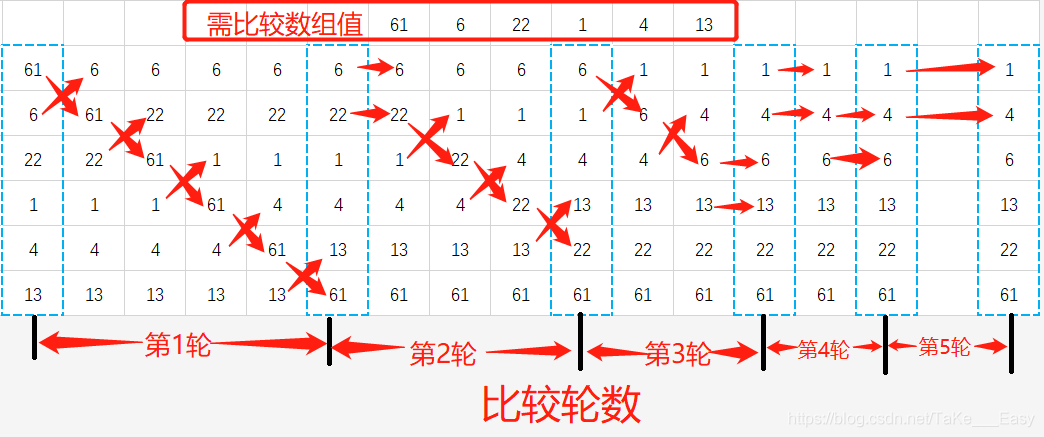
Algoritmo de clasificación de burbujas (clasificación de burbujas)
Descripción general e idea básica del algoritmo
El origen del nombre de este algoritmo se debe a que cuanto más pequeño sea el elemento, "flotará" lentamente hacia la parte superior de la secuencia (en orden ascendente o descendente) a través del intercambio, al igual que las burbujas de dióxido de carbono en las bebidas carbonatadas eventualmente subirán a la parte superior. , de ahí el nombre "burbuja" Ordenar "
La idea básica: la clasificación de burbujas es comparar los valores de dos elementos adyacentes, si se cumplen las condiciones correspondientes, intercambiar los valores de los elementos entre sí, mover el elemento más pequeño al frente de la matriz y mover el más grande elemento a la parte posterior de la matriz (es decir, intercambiar la posición de los dos elementos), de modo que el elemento más pequeño se eleve de abajo hacia arriba como una burbuja
Idea del algoritmo: el algoritmo de burbujeo se realiza mediante un bucle doble. El bucle exterior se utiliza para controlar el número de rondas de clasificación (es decir, varias rondas de operaciones de clasificación). Generalmente, la longitud de la matriz a ordenar es "menos 1 "veces, porque sólo queda el último ciclo. No es necesario comparar el siguiente elemento de la matriz y la matriz ya se ha ordenado. El bucle interno se utiliza para comparar el tamaño de cada elemento adyacente en la matriz para determinar si se intercambian posiciones. El número de comparaciones e intercambios disminuye con el número de rondas de clasificación
Diagrama esquemático del proceso de clasificación.
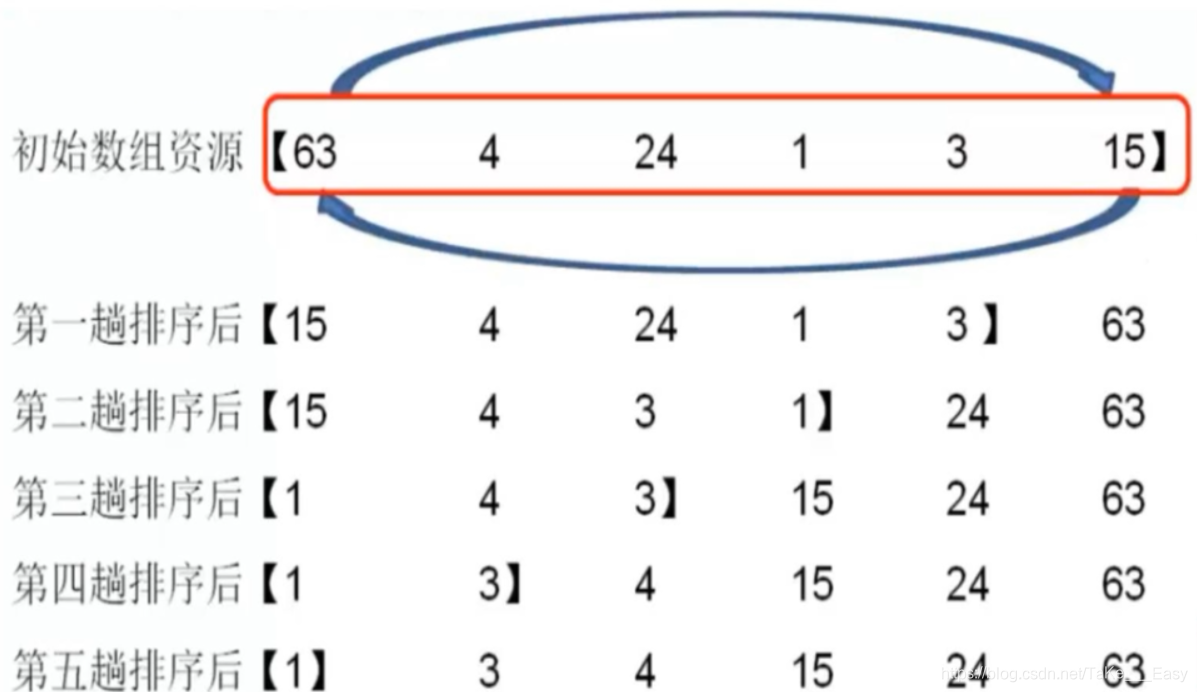
Clasificación de selección recta (clasificación de selección recta)
Descripción general e idea básica del algoritmo
En comparación con la clasificación de burbujas, el número de intercambios para la clasificación de selección directa es menor, por lo que la velocidad de cálculo será más rápida
Idea básica: compare la posición de clasificación especificada con otros elementos de la matriz por separado e intercambie los valores de los elementos si se cumplen las condiciones
La diferencia con la clasificación de burbujas: en lugar de intercambiar elementos adyacentes, los elementos que cumplen las condiciones se intercambian directamente con la posición de clasificación especificada (por ejemplo, clasificando desde el último elemento). De esta manera, la posición ordenada se expande gradualmente y, finalmente, toda la matriz se genera en un formato ordenado.
Diagrama esquemático del proceso de clasificación.
Algoritmo de clasificación inversa (clasificación inversa)
Descripción general e idea básica del algoritmo
Reordenar el contenido de la matriz original en orden inverso
Idea básica: reemplace el último elemento de la matriz con el primer elemento, reemplace el penúltimo elemento con el segundo elemento, y así sucesivamente, hasta que todos los elementos de la matriz se inviertan y reemplacen