En primer lugar, se divide el conjunto de entrenamiento y de prueba
- conjunto de entrenamiento: un conjunto de modelo de formación
- Las unidades de prueba: un conjunto de entrenamiento del modelo de prueba.
Los métodos comunes de resolución conjunto de datos:
1. método de destilación
Aparte método (retención de salida) el conjunto de datos D directamente dividido en dos conjuntos mutuamente exclusivos, donde un conjunto de entrenamiento como S, y el otro como el T. conjunto de prueba Es decir, D = S∪T, S∩T = ∅. Después de que el modelo está entrenado en el S, T con la prueba para evaluar el error, ya que la generalización de error estimado.
Nota: (1) la formación brecha / equipo de prueba para mantener la consistencia de la distribución de datos tanto como sea posible, para evitar un impacto en el resultado final debido a los datos en el proceso de introducción de sesgo adicional.
(2) la división diferente dará lugar a la formación diferente / equipo de prueba, resultados de la evaluación de modelo son también diferencias.
(3) una práctica común para muestrear aproximadamente 2 / 3-4 / 5 para la formación y las muestras restantes para la prueba.
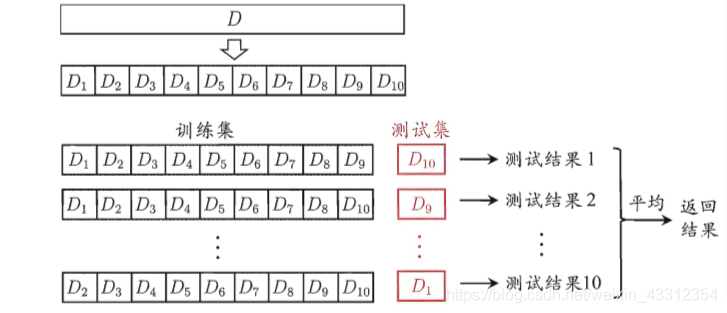
2. La validación cruzada
La validación cruzada (validación cruzada) primer conjunto de datos D en k conjuntos disjuntos de tamaño similar, cada subconjunto como sea posible para asegurar la consistencia de la distribución de datos, es decir, de la muestra obtenida por capas en D. A continuación, cada subconjunto con k-1 y se definen como un conjunto de entrenamiento, como el resto del equipo de prueba, por lo que puede obtener los conjuntos de k de conjunto de entrenamiento / prueba, que puede ser la formación y tiempos de prueba k, k que devuelve los resultados de las pruebas finales promedio. valor de K de 10 comúnmente, referido como caso 10 veces la validación cruzada. Otros valores de k común son 5, 20 y similares.
3. Bootstrap
Auto-muestreo método con el régimen de autoservicio. Puede reducir mejor el impacto de diferente tamaño de la muestra de entrenamiento, sino también más eficiente para llevar a cabo experimentos para estimar. conjunto de datos D contiene un conjunto de M muestras, generamos un conjunto de datos que se muestrea D ': una muestra seleccionada al azar de cada uno de D, copiarlo en D', y luego de nuevo en el conjunto de datos inicial de muestras D de modo que la siguiente muestra cuando la muestra es todavía probable que se toma; cuando este proceso se realiza repetidamente m veces, para obtener un conjunto de muestras de datos D comprende m', que es el resultado de la auto-muestreo. parte D de la muestra tendrá D 'aparecerá muchas veces, y no parece que otra parte de la muestra. muestra de probabilidad en m muestras no se toman para ser aproximadamente 0.368.
método de autoayuda es útil cuando conjunto de datos pequeño, es difícil divide efectivamente en la formación del sistema / de prueba; método de autoayuda generar una pluralidad de diferentes enfoques de formación del conjunto de datos inicial, una gran ventaja de aprendizaje heredado.
En segundo lugar, los resultados de la evaluación: La precisión, la matriz de confusión, precisión, recordar, F1 Score, curva ROC
1. La relación precisa (precisión):
Valor predictivo de 1, y la relación de la previsión, es decir: Estamos preocupados acerca del evento, predijeron cómo es exacto.
2. recuerdo (recuerdo):
Todos los datos real es 1, la predicción del número, a saber: un caso real de la ocurrencia del evento que nos ocupa, que predijo correctamente la proporción de la cantidad.
En general, la precisión y la recuperación es una medida de una contradicción. Cuando la alta precisión, recordar a menudo baja, mientras que el índice de repetición, la precisión suele ser baja.
En la elección de métricas-offs, a menudo tienen que basarse en la escena. En la tendencia futura de las acciones de dicha problema de clasificación binaria, llame a la preocupación general es que la gente, en el aumento de las existencias, bienes aumento de la proporción de grande es mejor, esta es la esperanza tasa de precisión . Incluso omitido algún ciclo ascendente, no tenemos mucho que perder. Para el diagnóstico de la enfermedad en el campo de la medicina, si el índice de repetición es bajo, significa que el paciente hubiera enfermado, solo no predice, por lo que queremos tanto como sea posible a todos los pacientes previstos, por lo que es la necesidad de mejorar la memoria .
matriz 3. confusión:
Para preguntas dicotómicas, y el aprendizaje de su categoría predicción verdadera clase puede dividirse en una combinación de casos reales (TP), los casos de falsos positivos (FP), verdaderos negativos (VN), falsa contraejemplo (FN) cuatro casos. TP + FP + TN + FN = el número total de muestras, la matriz se forma como sigue:
| Las predicciones | Las predicciones | |
|---|---|---|
| verdad | ejemplo positivo | contraejemplo |
| ejemplo positivo | TP | FN |
| contraejemplo | FP | Tennesse |
En la que:
(1) la precisión Precision = TP / (TP + FP )
(2) índice de repetición, la sensibilidad, memoria, verdadera tasa positiva la Recall = TPR = TP / (TP + FN)
(. 3) verdadera tasa negativa la TNR, especificidad del TNR = la TN / (la FP + TN)
(. 4) falso negativo tasa de FNR, la tasa de diagnóstico erróneo (1-sensibilidad) el FNR = FN / (TP + FN)
(. 5) false FPR tasa positiva, la tasa de diagnóstico erróneo (1-especificidad) FPR = FP / (FP + TN)
4.F1 Puntuación:
Si nos ocupamos tanto de la tasa de precisión (P) y la recuperación (R) estos dos indicadores, F1 puntuación es la media armónica de precisión y la recuperación.
2 = Fl P R ^ / (P + I + LT)
es decir, 1 / F1 = (1 / P + 1 / R) / 2
El umbral de la clasificación:
Es decir, para ajustar el valor umbral de la muestra umbral de determinación ejemplos positivos.
Si la probabilidad de que el retorno de un modelo de regresión logística para predecir un email 0,9995, entonces el modelo predice que este mensaje es muy probable que sea correo no deseado. Por el contrario, se predijo en un modelo de regresión logística con una puntuación de 0,0003 en otro e-mail no es probablemente spam. Si se puede predecir el resultado de un correo electrónico a 0,6? Con el fin de asignar el valor en una categoría de regresión logística binaria, debe especificar el umbral de clasificación (también conocido como umbral de discriminación). Si el valor es superior al umbral, entonces el "spam"; si el valor está por debajo del umbral, se indica "no spam". La gente tiende a pensar que el umbral siempre debe ser clasificado como 0.5, pero el umbral depende del problema específico, así que hay que ajustarlo.
la precisión disminuye al aumentar el umbral, el recuerdo disminuye a medida que aumenta el umbral . Si algunos escenarios requieren precisión, cobertura se mantiene a se puede obtener de esta manera umbral del 80%.
curva 6.ROC:
curva ROC (Receiver Característica de operación Cureve), describe la relación entre la TPR y FPR. El eje x es FPR, eje y es la TPR.
TPR es un ejemplo positivo, cuántos fueron determinó correctamente que ser positivo; FPR es negativo en todos los casos, el número se determinó incorrectamente a ser positivo. umbral de clasificación de valores diferentes, el resultado del cálculo de TPR y FPR también son diferentes, la situación más ideal, esperamos que todos los casos positivos y negativos ejemplos se predijo con éxito TPR = 1, FPR = 0, es decir, todos los valores ejemplos positivos predichos> todos valor predictivo Ejemplo negativo, entonces el valor de umbral puede tomar un valor entre el mínimo y el valor positivo máximo del valor predictivo negativo Ejemplo Ejemplo predicho.
TPR más grande mejor, FPR pequeño es el mejor, pero los dos indicadores a menudo contradictorias. Para aumentar la TPR, se puede predecir muestras ejemplo más positivas, al mismo tiempo aumenta más como el caso de casos falsos negativos fueron ejemplos positivos.
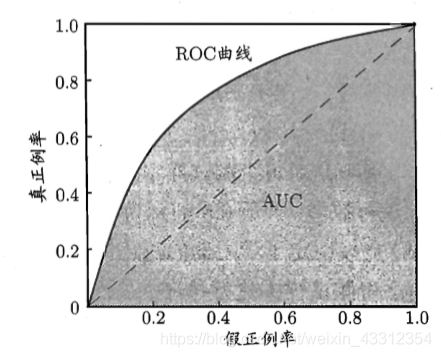
Cuanto más cerca de la esquina superior izquierda de la curva ROC, mejor será el efecto clasificador prueba. El punto de esquina superior izquierda de la perfecta clasificación, (TPR = 1, FPR = 0), expresado como los médicos están altamente cualificados,-diagnóstico completo derecha.
7.AUC:
En general, la curva ROC, nos preocupa es el área bajo la curva, conocida como AUC (área bajo la curva). El AUC es el rango del eje horizontal (0,1), el eje vertical (0,1) de manera que la superficie total es de menos de 1.
Bajo la curva ROC de trapezoide, un rectángulo puede ser considerada como la forma trapezoidal característica. Por lo tanto, esta área puede ser considerado como el AUC de * H / 2, el área bajo la curva se puede obtener por la superposición de una pluralidad de áreas trapezoidales la parte inferior :( base inferior +). AUC, mejores serán los resultados de clasificación clasificador.
Cuando • AUC = 1, es el clasificador perfecto, utilizando el modelo predictivo, no importa lo que el valor umbral se puede configurar para llegar a una predicción perfecta. La gran mayoría predecir ocasiones, no hay una clasificación perfecta.
• 0.5 <AUC <1, mejor que adivinar al azar. El clasificador (modelo) para configurar correctamente el umbral, entonces, tener valor predictivo.
• AUC = 0,5, como adivinar al azar, modelo n ° valor predictivo.
• AUC <0,5, peor que adivinar al azar; pero siempre y cuando la línea está siempre predicen contra, es mejor que adivinar al azar.
En tercer lugar, la evaluación de los resultados de la regresión: MSE, RMSE, MAE, R Squared
1. La media MSE error cuadrático
Different conjunto de prueba de cantidad de datos m, porque la operación de acumulación, los datos aumenta, el error se acumulará gradualmente; m y por lo tanto una medida de la correlación. Para compensar la cantidad de datos de imagen, la cantidad de datos se puede quitar, error de desplazamiento. Los resultados obtenidos por este método se llama el error cuadrático medio. Los parámetros estadísticos son los datos en bruto y los puntos de datos de predicción correspondientes y el error cuadrático medio
MSE (Mean Squared Error):
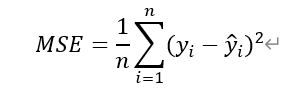
2. La raíz cuadrada media de error RMSE
Pero usando el error cuadrático medio MSE recibir el impacto sin dimensiones. Por ejemplo, cuando una medida de la propiedad inmobiliaria, la unidad de y es (millones), el resultado obtenido es una medida (millones de pies cuadrados). Para resolver el problema de las dimensiones, es posible que se recetando (dimensión con el fin de resolver el problema de la varianza, que es la raíz cuadrada de la diferencia al cuadrado obtenido) para dar la media RMSE de error de raíz cuadrada (Root Mean Squarde error):
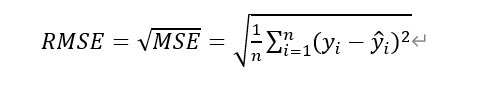
3. La media absoluta error MAE
Para algoritmo de regresión lineal, hay otro muy simples criterios de evaluación. distancia requerida entre el valor real y el resultado de predicción mínimo, un valor de la resta absoluta se puede hacer directamente, a continuación, dividido por M Plus m veces, para obtener la distancia media que se conoce como el error absoluto medio (MAE Mean Absolute Error):
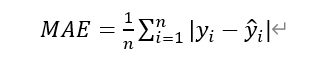
Antes la determinación de la función de pérdida, hemos mencionado, no es la función de valor absoluto en todas partes, así que no use valores absolutos. Pero no afecta al modelo de evaluación. Por lo tanto la función de pérdida modelo de evaluación puede ser diferente.
4.R-Square (coeficiente de determinación)
El principal factor determinante, SST estos dos parámetros determinada por la SSR.
(1) SSR: diferencias al cuadrado suma de cuadrados de la regresión, es decir, los datos de predicción y los datos originales significan la suma, la siguiente ecuación
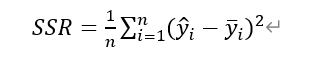
(2) SST: suma total de cuadrados, es decir, el cuadrado de la diferencia entre los datos originales y la suma media, la siguiente ecuación
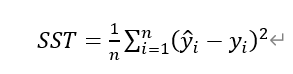
Se encontró: SST = SSE + SSR
y nuestro "coeficiente de determinación" se define como la relación de SSR y SST, por lo
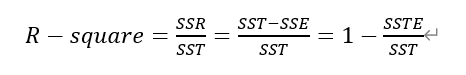
"Coeficiente de determinación" se caracteriza por un cambio en el ajuste de datos es bueno o malo. La expresión anterior puede conocer el "coeficiente de determinación" gama valor normal de [0 1], el más cercano a 1, indica que poder explicativo la ecuación variable y más fuerte de este modelo son mejor ajuste a los datos.
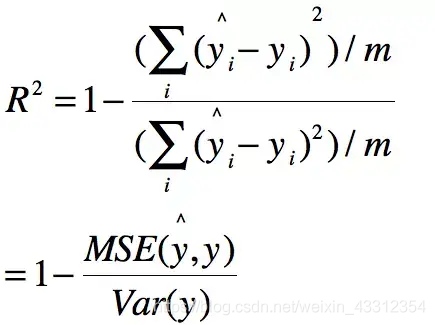
R & lt ¿Por qué lado bueno este indicador?
Para las moléculas, el cuadrado de la diferencia entre el valor predicho y el valor verdadero y que el uso de la Nuestro modelo predice que produce mal.
Para el denominador, que es el cuadrado de la diferencia entre la media y el valor verdadero y que mal pensamiento, "valor predictivo = media de la muestra" este modelo (Modelo de base) producida.
Utilizamos el modelo de referencia más errores producidos, utilizamos sus propios modelos con menos errores. Así, con el menor número de errores erróneos dividido por uno menos el más, de hecho, es una medida de nuestro lugar el ajuste del modelo a datos en tiempo real, que no se corresponde error de índice.
Nos lo anterior, las siguientes conclusiones pueden ser:
R & lt ^ 2 <= 1
R2 de Ye mayor, mayor es la sustracción de una molécula pequeña, una baja tasa de error; modelo de predicción cuando hacemos errores, R2 valor máximo de 1
cuando cuando el modelo es igual al modelo de referencia, R ^ 2 = 0
si R ^ 2 <0, que aprendimos modelo no como modelo de referencia. En este punto, es probable que los datos no existe ninguna relación lineal.
