
Autor: Huan Xiang
Manbang Group, como empresa de plataforma "Internet + Logística", cubre las necesidades de envío de los transportistas por un lado y se conecta con los camioneros por el otro para mejorar la eficiencia de la logística de carga. Cotizará en la bolsa de valores de EE. UU. en 2021, convirtiéndose en la primera plataforma de carga digital en cotizar. Según el informe anual de la compañía, en 2021, más de 3,5 millones de camioneros completaron más de 128,3 millones de pedidos en la plataforma, logrando un valor de transacción total de GTV 262,3 mil millones de yuanes, lo que representa más del 60% de la participación de la plataforma de carga digital de China. En octubre de 2022, el MAU de la versión de conductor de Yunmanman alcanzó los 9,4921 millones, el MAU de la versión de conductor de Wagonmanman fue de 3,9991 millones, el MAU de la versión de propietario de Yunmanman fue de 2,1868 millones y el MAU de la versión de propietario de carga de Wagonbang; fue 637.800. (El siguiente contenido es compilado y publicado por Zikui y Congyan)
El crecimiento empresarial desafía la estabilidad del servicio
Manbang Group construyó su propia puerta de enlace de microservicios en el entorno de producción empresarial, que es responsable de la programación del tráfico norte-sur, la protección de la seguridad y la gobernanza de microservicios. Al mismo tiempo, teniendo en cuenta la capacidad de recuperación ante desastres multiactiva, también proporciona servicios como este. como llamadas prioritarias en la misma sala de computadoras, llamadas de recuperación de desastres entre salas de computadoras, etc. Como componente frontal de la arquitectura de microservicios, la puerta de enlace de microservicios sirve como entrada de tráfico para todos los microservicios. Cuando llega una solicitud de un cliente, primero llegará al ALB (equilibrio de carga), luego irá a la puerta de enlace interna y luego será enrutada al módulo de servicio empresarial específico a través de la puerta de enlace.
Por lo tanto, la puerta de enlace necesita utilizar un centro de registro de servicios para descubrir dinámicamente todas las instancias de microservicios implementadas en el entorno de producción actual. Cuando algunas instancias de servicio no pueden proporcionar servicios debido a fallas, la puerta de enlace también puede trabajar con el centro de registro de servicios para reenviar automáticamente. solicitudes a instancias sanas, se logra la conmutación por error y la elasticidad, y se utiliza un marco de desarrollo propio para cooperar con el centro de registro de servicios para realizar llamadas entre servicios. Para implementar la gestión de configuración y el impulso de cambios, Manbang Group fue el primero en adoptar Eureka y ZooKeeper de código abierto para construir un centro de implementación de clústeres y un centro de configuración. Esta estructura también emprendió el rápido crecimiento comercial de Manbang Group en la etapa inicial.
Sin embargo, a medida que el volumen de negocios aumenta gradualmente, hay cada vez más módulos comerciales y el número de instancias de registro de servicios crece explosivamente . Los problemas de estabilidad del clúster del centro de registro de servicios Eureka y del clúster ZooKeeper de construcción propia en esta arquitectura se han vuelto cada vez más obvios. .
Durante la operación y el mantenimiento, los estudiantes del Grupo Manbang descubrieron que cuando el número de instancias de registro de servicios en el clúster Eureka construido por ellos mismos alcanzó más de 2000, debido a la sincronización de la información de registro de instancias entre los nodos del clúster Eureka, algunos nodos no pudieron manejarlo, lo que Los problemas surgen cuando los nodos no brindan servicios y eventualmente causan fallas en el GC frecuente en el clúster de ZooKeeper, lo que provoca inquietudes en las llamadas entre servicios y las versiones de configuración, lo que afecta la estabilidad general. Además, ZooKeeper no tiene ninguna autenticación ni autenticación de identidad. Las capacidades habilitadas de forma predeterminada y el almacenamiento de configuración enfrentan riesgos de seguridad. Estos problemas también traen grandes desafíos para el desarrollo estable y duradero del negocio.
Migración fluida de la arquitectura empresarial
Con la experiencia empresarial anterior, los estudiantes de Manbang optaron por migrar a la nube con urgencia y utilizaron los productos Alibaba Cloud MSE Nacos y MSE ZooKeeper para reemplazar los clústeres originales de Eureka y Zookeeper. Sin embargo, ¿cómo podemos lograr también actualizaciones de arquitectura rápidas y de bajo costo? ¿Qué pasa con la migración del tráfico sin pérdidas y sin problemas?
En este sentido, MSE Nacos ha logrado compatibilidad total con el protocolo nativo de código abierto de Eureka. El kernel todavía está impulsado por Nacos. La capa de adaptación empresarial asigna el modelo de datos Eureka InstanceInfo y el modelo de datos de Nacos (servicio e instancia) uno por uno. Todo esto es completamente transparente para las partes comerciales de que Manbang Group se ha hecho cargo del clúster Eureka de construcción propia.
Esto significa que no es necesario cambiar el lado comercial original a nivel de código. Solo necesita modificar la configuración del punto final de la instancia del servidor conectada por el cliente Eureka al punto final de MSE Nacos. También es muy flexible en uso. Puede continuar usando el protocolo nativo de Eureka para usar la instancia de MSE Nacos como un clúster de Eureka, o puede usar los protocolos duales del cliente Nacos y Eureka para coexistir. La información de registro de servicio de diferentes protocolos se admite mutuamente. conversión, asegurando así la conectividad de las llamadas de microservicios empresariales.
Además, durante el proceso de migración a la nube, MSE proporcionó oficialmente la solución MSE-Sync, que es una herramienta de sincronización de datos compatible con la migración optimizada basada en Nacos-Sync de código abierto. Admite sincronización bidireccional, servicios de extracción automática y un solo clic. Funciones de sincronización. A través de MSE-Sync, los estudiantes de Manbang pueden migrar fácilmente los datos de existencias de registro de servicios en línea existentes en el clúster Eureka original de construcción propia al nuevo clúster MSE Nacos con un solo clic. Al mismo tiempo, los datos incrementales recién registrados en el clúster anterior pueden. También se migrará con un solo clic y se sincronizará de forma continua y automática con el nuevo clúster, lo que garantizará que la información de la instancia de registro del servicio del clúster en ambos lados sea siempre completamente coherente antes de la migración del flujo de negocios real. Una vez superada la verificación de sincronización de datos, reemplace la configuración original del Eureka Client Endpoint, vuelva a publicarla, actualice y migre exitosamente al nuevo clúster MSE Nacos.
Superar el cuello de botella de rendimiento de la arquitectura de clúster nativa de Eureka
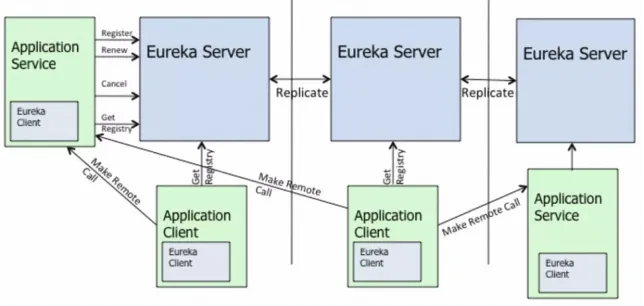
Cuando Manbang Group encontró la actualización de la arquitectura técnica de cooperación del equipo de MSE, la solicitud más importante fue resolver el problema original de la alta presión para sincronizar la información de registro de servicios entre los clústeres de Eureka . Esto se debe a que Eureka Server es una estrella tradicional de igual a igual. Según el modelo AP de sincronización, las funciones de cada nodo del servidor son iguales y completamente equivalentes. Para cada cambio (registro/baja del registro/renovación de latido/cambio de estado del servicio, etc.), se generará una tarea de sincronización correspondiente para la sincronización de todos los datos de la instancia. De esta manera, la cantidad de trabajos de sincronización aumenta en correlación directa con el tamaño del clúster y el número de instancias.
A través de la práctica, los estudiantes de Manbang Group descubrieron que cuando la escala de registro de servicios de clúster alcanzaba más de 2000, descubrieron que la tasa de ocupación de la CPU y la carga de algunos nodos eran muy altas y, a veces, fingían la muerte de vez en cuando, lo que provocaba nerviosismo en los negocios. Esto también se menciona en la documentación oficial de Eureka. El modelo de replicación de transmisión de código abierto de Eureka no solo causa su propia vulnerabilidad arquitectónica, sino que también afecta la escalabilidad horizontal general del clúster.
El algoritmo de replicación limita la escalabilidad: Eureka sigue un modelo de replicación de transmisión, es decir, todos los servidores replican datos y latidos a todos los pares. Esto es simple y efectivo para el conjunto de datos que contiene eureka; sin embargo, la replicación se implementa transmitiendo todas las llamadas HTTP que recibe un servidor tal cual a todos los pares. Esto limita la escalabilidad ya que cada nodo tiene que soportar toda la carga de escritura en eureka.
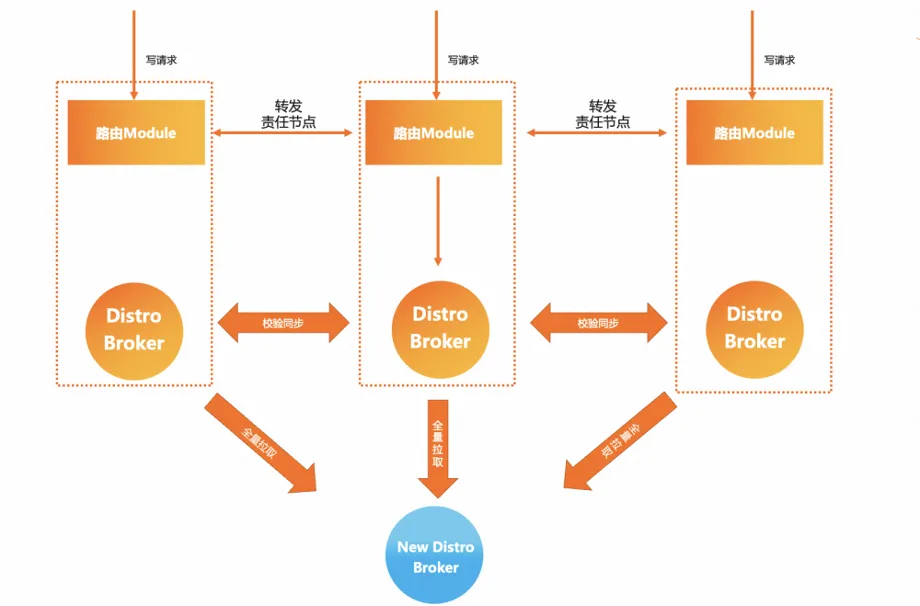
MSE Nacos tuvo en cuenta este problema en la selección de la arquitectura y brindó una mejor solución, que es el protocolo Distro del modelo AP de desarrollo propio. Sobre la base de conservar el modelo de sincronización en estrella, Nacos registra datos de instancia para todos los servicios. Se realiza la fragmentación y se asigna un nodo de responsabilidad del clúster a cada dato de instancia de servicio. Cada nodo del servidor solo es responsable de la sincronización y la lógica de renovación de su propia parte de los datos. relativamente El Eureka también es más pequeño. La ventaja de esto es que incluso en implementaciones a gran escala y grandes datos de instancias de servicio, la cantidad de tareas de sincronización entre clústeres puede ser relativamente controlable , y cuanto mayor sea el tamaño del clúster, mayor será la mejora obvia en el rendimiento que aporta este modelo.
La optimización iterativa continua busca el máximo rendimiento
Después de que MSE Nacos y MSE ZooKeeper completaron el negocio completo del centro de registro de microservicios de Manbang Group, continuaron optimizando iterativamente en versiones actualizadas posteriores y continuaron optimizando el rendimiento del servidor en cada detalle a través de una gran cantidad de pruebas de comparación de pruebas de estrés de rendimiento. Experiencia empresarial, los puntos de optimización de la versión actualizada se analizarán e introducirán uno por uno.
Protección de recuperación ante desastres de alta disponibilidad de registro de servicios
Native Nacos proporciona funciones de alto nivel: protección push . Cuando el centro de registro cambia o encuentra una emergencia, o el proveedor de servicios y el proveedor de servicios se suscriben. centro de registro Cuando el enlace entre centros falla debido a la red, la CPU y otros factores, puede causar excepciones en la suscripción, lo que hace que los consumidores de servicios obtengan una lista de instancias de proveedores de servicios vacía.
Para resolver este problema, puede habilitar la función de protección push en el cliente Nacos o en el servidor MSE Nacos para mejorar la disponibilidad de todo el sistema. También hemos introducido esta función de estabilidad en el soporte del protocolo para Eureka. Cuando los datos del servidor MSE Nacos son anormales, cuando el cliente Eureka extrae datos del servidor, recibirá soporte de protección de recuperación ante desastres de forma predeterminada para garantizar el uso comercial. De esta manera, no obtendrá una lista de instancias de proveedores de servicios que no cumplan con las expectativas, lo que provocará fallas comerciales.
Además, MSE Nacos y MSE ZooKeeper también proporcionan múltiples mecanismos de garantía de alta disponibilidad . Si el lado comercial tiene requisitos de seguridad de datos y confiabilidad más altos, puede optar por implementar con no menos de 3 nodos al crear una instancia. Cuando una de las instancias falla, el cambio entre nodos se completa en segundos y el nodo fallido abandona automáticamente el clúster. Al mismo tiempo, cada región MSE contiene múltiples zonas de disponibilidad. El retraso de la red entre diferentes zonas en la misma región es muy pequeño (dentro de 3 ms, las instancias de zonas de disponibilidad múltiple pueden implementar nodos de servicio en diferentes zonas de disponibilidad). , , el tráfico se cambiará a otra zona de disponibilidad B en un corto período de tiempo. El lado comercial no tiene conocimiento de todo el proceso, y el nivel del código de la aplicación no tiene conocimiento y no se requieren cambios. Este mecanismo solo requiere configurar la implementación de múltiples nodos, y MSE lo ayudará automáticamente a implementar en múltiples zonas de disponibilidad para una recuperación ante desastres dispersa.
Admite al cliente Eureka para extraer datos de forma incremental
Después de que los estudiantes de Manbang migraron a MSE Nacos, el problema original de que la instancia del servidor estaba suspendida y no podía proporcionar servicios se resolvió bien. Sin embargo, se descubrió que el ancho de banda de la red de la sala de computadoras era demasiado alto y, ocasionalmente, el ancho de banda estaba lleno. durante los períodos pico de servicio. Más tarde, se descubrió que la razón era que cada vez que el cliente Eureka extraía la información de registro del servicio de MSE Nacos, solo admitía la extracción completa y se extraían miles de niveles de datos con regularidad, lo que resultó en un aumento en la cantidad de FGC en el nivel de entrada mucho.
Para resolver este problema, MSE Nacos ha lanzado un mecanismo de extracción incremental para la información de registro del servicio Eureka. Junto con el ajuste del uso del cliente, el cliente solo necesita extraer la cantidad total de datos una vez después del primer inicio, y posteriormente solo. necesita extraer la cantidad total de datos en función del incremento. Los datos se utilizan para mantener la coherencia de los datos locales y los datos del servidor, y ya no se requieren extracciones periódicas a gran escala. La cantidad de datos incrementales modificados en un entorno de producción normal es muy grande. pequeño, lo que puede reducir significativamente la presión sobre el ancho de banda de exportación. Después de actualizar a esta versión optimizada, los estudiantes de Manbang descubrieron que el ancho de banda cayó repentinamente de 40 MB/s antes de la actualización a 200 KB/s, y el problema del ancho de banda completo se resolvió.

Prueba de estrés completa para optimizar el rendimiento del servidor
Posteriormente, el equipo de MSE realizó una prueba de estrés de rendimiento a mayor escala en el clúster MSE Nacos para el escenario Eureka, utilizó varias herramientas de análisis de rendimiento para identificar cuellos de botella de rendimiento en los enlaces comerciales y realizó más optimización del rendimiento y optimización de las funciones originales. ajuste de parámetros de rendimiento de nivel.
- El almacenamiento en caché se introduce para la información de registro de datos completa e incremental en el lado del servidor, y si se han producido cambios se determina en función del hash de datos del lado del servidor. En escenarios donde el servidor Eureka lee más y escribe menos, puede reducir significativamente la sobrecarga de rendimiento de los cálculos de la CPU para generar resultados devueltos.
- Se descubrió que el StringHttpMessageConverter nativo de SpringBoot tenía un cuello de botella en el rendimiento al procesar devoluciones de datos a gran escala, y se proporcionó EnhancedStringHttpMessageConverter para optimizar el rendimiento de la transmisión de E/S de datos de cadena.
- La devolución de datos del lado del servidor admite fragmentos.
- El número de grupos de subprocesos de Tomcat se ajusta de forma adaptativa según la configuración del contenedor.
Después de que Manbang Group completó la actualización iterativa de la versión anterior, varios parámetros en el lado del servidor también lograron excelentes resultados de optimización:
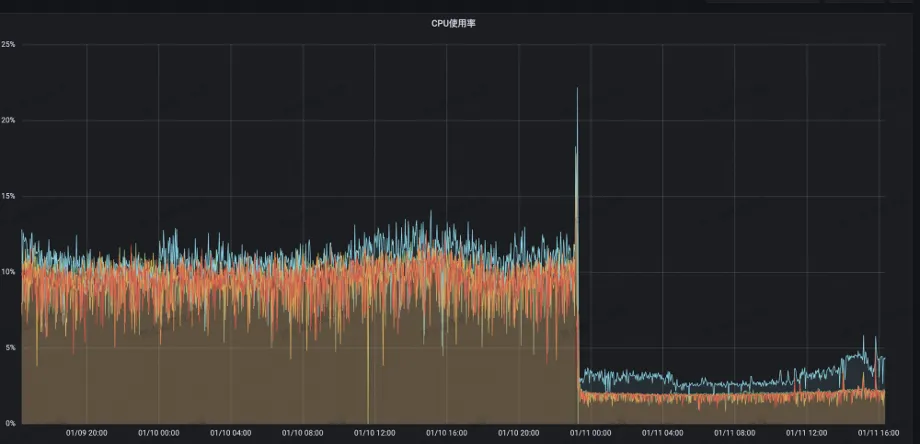
La utilización de la CPU del servidor cayó del 13% al 2%
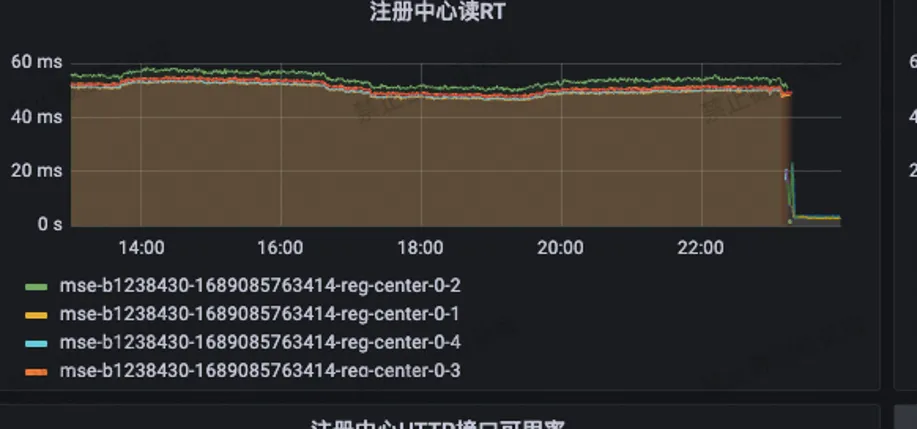
La lectura RT del centro de registro se ha reducido de los 55 ms originales a menos de 3 ms.

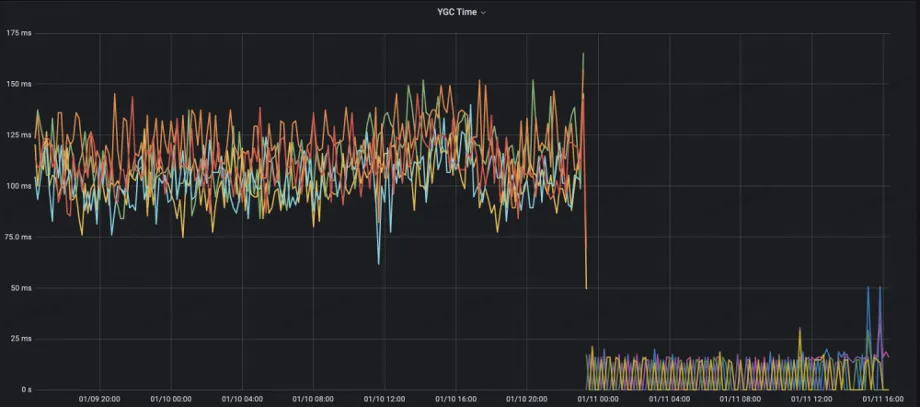
El recuento de YGC del lado del servidor se ha reducido del 10+ original a 1
Tiempo de YGC reducido de los 125 ms originales a menos de 10 ms
La optimización de derivación garantiza la estabilidad del clúster bajo alta presión.
Después de que los estudiantes de Manbang migraron a MSE ZooKeeper por un período de tiempo, se produjo nuevamente GC completo en el clúster, lo que provocó que el clúster se volviera inestable. Después de la investigación de emergencia de MSE, se descubrió que la razón se debía a un indicador estadístico de métricas relacionado con la vigilancia. ZooKeeper se guardó en el nodo actual durante el cálculo. Los datos de observación se copian por completo y la escala de observación es muy grande en un escenario de grupo completo. La observación de copia de cálculo de métricas genera una gran cantidad de fragmentos de memoria en tal escenario. el clúster final no puede asignar recursos de memoria calificados y, en última instancia, GC completo.
Para resolver este problema, MSE ZooKeeper toma medidas de degradación para métricas no importantes para garantizar que estas métricas no afecten la estabilidad del clúster. Para las métricas de copia de vigilancia, adopta una estrategia de adquisición dinámica para evitar problemas de fragmentación de memoria causados por los cálculos de copia de datos. Después de aplicar esta optimización, el tiempo y el número de Young GC del clúster se reducen significativamente.
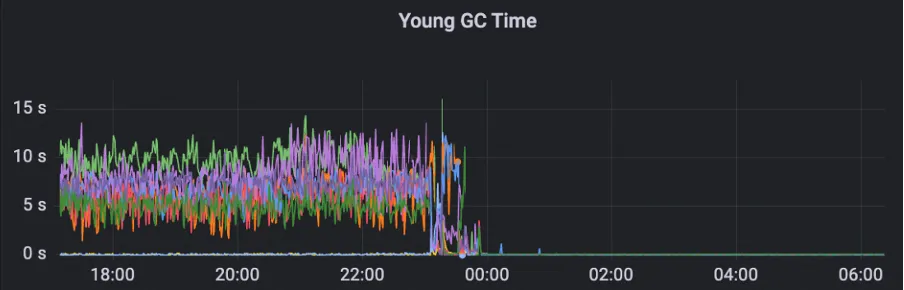

Después de la optimización, el clúster puede manejar sin problemas QPS de 200 W y GC es estable.
Optimización continua de parámetros para encontrar el mejor punto de equilibrio entre latencia y rendimiento
Después de que los estudiantes de Manbang migraron su ZooKeeper de construcción propia a MSE ZooKeeper, descubrieron que cuando se lanzó la aplicación, el retraso del cliente en la lectura de los datos en ZooKeeper era demasiado grande y el tiempo de espera de la configuración de lectura de inicio de la aplicación, lo que resultó en un tiempo de espera de inicio de la aplicación. Para resolver este problema, el análisis de pruebas de estrés dirigidas de MSE ZooKeeper muestra que en un escenario de servicio completo, ZooKeeper necesita manejar una gran cantidad de solicitudes cuando se lanza la aplicación, y los objetos generados por las solicitudes causan Young GC frecuentes en el existente. configuración.
En respuesta a este escenario, el equipo de MSE ajustó la configuración del clúster a través de múltiples rondas de pruebas de estrés para encontrar el punto de intersección óptimo entre el retraso de la solicitud y el TPS. Con la premisa de cumplir con los requisitos de retraso, el equipo de MSE exploró el rendimiento óptimo del clúster. y garantizó un retraso de solicitud de 20 ms. Bajo el nivel diario de QPS de 10 w del clúster, la CPU se reduce del 20% al 5% y la carga del clúster se reduce significativamente.
posdata
En un contexto de feroz competencia en la industria del transporte de carga digital y rápido desarrollo tecnológico, Manbang Group ha mejorado con éxito su propia arquitectura técnica, migrando sin problemas del centro de registro Eureka de construcción propia a la plataforma MSE Nacos, más eficiente y estable. Esto no solo representa la firme determinación del Grupo Manbang en la innovación tecnológica y la expansión comercial, sino que también demuestra sus planes de largo alcance para el desarrollo futuro. Manbang Group considera la estabilidad y el alto rendimiento de la arquitectura de microservicios como el núcleo de su transformación digital. La importante mejora del rendimiento y la estabilidad aportadas por la nueva arquitectura del centro de registro brindan un fuerte soporte a Manbang, lo que permite que la plataforma esté más preparada para manejar negocios en crecimiento. demandas y tener el poder para hacer frente a cualquier desafío que pueda surgir en el futuro.
Vale la pena mencionar que la ágil respuesta de Manbang Group durante todo el proceso de migración y la ejecución profesional de su equipo técnico también aceleraron el ritmo de la actualización de la arquitectura. La transformación exitosa de la plataforma empresarial no sólo mejora la confianza de los usuarios en los servicios de Manbang, sino que también proporciona una experiencia valiosa a otras empresas. En el futuro, Manbang seguirá trabajando estrechamente con MSE para mejorar aún más la estabilidad, la escalabilidad y el rendimiento de la arquitectura técnica, seguir estableciendo puntos de referencia para la industria y promover la transformación digital de toda la industria logística.
Durante este proceso de migración, el negocio pudo migrarse sin problemas y sin pérdidas y el rendimiento mejoró significativamente, lo que demostró el excelente rendimiento y confiabilidad de MSE en el campo de los centros de registro de servicios. Creo que con la continua evolución de las MPE, su búsqueda continua de facilidad de uso y estabilidad sin duda aportará un enorme valor comercial a más empresas y desempeñará un papel cada vez más importante en el proceso de digitalización de las empresas.
Además, MSE también es totalmente compatible con las funciones de gobernanza de microservicios, incluida la protección del tráfico, la liberación de escala de grises de enlace completo, etc. Al aplicar reglas de limitación actuales completamente configuradas desde la puerta de entrada hasta el backend, los riesgos de estabilidad del sistema causados por el tráfico repentino se resuelven de manera efectiva, lo que garantiza el funcionamiento continuo y estable del sistema, y las empresas pueden centrarse más en el desarrollo del negocio principal. El caso exitoso de Manbang Group ha establecido un nuevo hito para la industria. Esperamos ver más empresas logrando logros más brillantes en su viaje digital.
Mensaje del CTO de Manbang, Wang Dong (Dongtian): Comprender y utilizar plenamente las capacidades de la nube puede liberar al equipo técnico de Manbang de una inversión continua en el nivel inferior, centrarse en la estabilidad del sistema de nivel superior y la eficiencia de la ingeniería, y lograr mejores resultados desde el Nivel arquitectónico. Alto retorno de la inversión.
Actividades recomendadas:

Haga clic aquí para registrarse en la primera sesión de arquitectura de aplicaciones nativas de IA del Feitian Technology Salon.
El equipo de inteligencia artificial de China de Microsoft empacó colectivamente y se fue a los Estados Unidos, involucrando a cientos de personas. ¿Cuántos ingresos puede generar un proyecto desconocido de código abierto? Huawei anunció oficialmente que la posición de Yu Chengdong se ajustó en la estación espejo de código abierto de la Universidad de Ciencia y Tecnología de Huazhong. ¡Los estafadores abrieron oficialmente el acceso a la red externa y utilizaron TeamViewer para transferir 3,98 millones! ¿Qué deberían hacer los proveedores de escritorio remoto? La primera biblioteca de visualización front-end y fundador del conocido proyecto de código abierto de Baidu, ECharts, un ex empleado de una conocida empresa de código abierto que "se fue al mar" dio la noticia: después de ser desafiado por sus subordinados, el técnico El líder se puso furioso y grosero y despidió a la empleada embarazada. OpenAI consideró permitir que la IA genere contenido pornográfico. Microsoft informó a The Rust Foundation que donó 1 millón de dólares estadounidenses. Por favor, dígame cuál es el papel de time.sleep(6) aquí. ?