
Nota del editor: actualmente, el sistema de recuperación mejorada de generación (RAG) se ha convertido en una de las tecnologías clave para potenciar el conocimiento masivo en modelos grandes. Sin embargo, cómo procesar eficientemente datos semiestructurados y no estructurados, especialmente datos tabulares en documentos, sigue siendo un problema importante al que se enfrentan los sistemas RAG.
El autor de este artículo propone una solución novedosa para procesar datos tabulares para abordar este problema. Primero, el autor clasifica sistemáticamente las tecnologías centrales del procesamiento de tablas en el sistema RAG, incluido el análisis de tablas, el diseño de la estructura del índice, etc., y revisa algunas soluciones de código abierto existentes. Sobre esta base, el autor propuso su propia innovación: usar la herramienta Nougat para analizar de manera precisa y eficiente el contenido de la tabla en el documento, usar el modelo de lenguaje para resumir la tabla y su título y, finalmente, construir una nueva estructura de índice de resumen del documento. proporciona detalles completos de implementación del código.
La ventaja de este método es que puede analizar la tabla de manera efectiva y considerar completamente la relación entre el resumen de la tabla y la tabla. No requiere el uso de LLM multimodal y puede ahorrar costos de análisis. Esperemos y veamos la aplicación y el desarrollo de este esquema en la práctica.
Autor | Florián junio
Compilado |
La implementación de un sistema RAG es una tarea desafiante, especialmente cuando es necesario analizar y comprender tablas en documentos no estructurados. Para documentos que han sido digitalizados mediante operaciones de escaneo (documentos escaneados) o documentos en formato de imagen (documentos en formato de imagen), es aún más difícil implementar estas operaciones. Hay al menos tres desafíos:
- Los documentos digitalizados mediante operaciones de escaneo (documentos escaneados) o documentos en formato de imagen (documentos en formato de imagen) son relativamente complejos , como la diversidad de estructuras del documento, el documento puede contener algunos elementos que no son texto y el documento puede simultáneamente La presencia de El contenido escrito a mano e impreso planteará desafíos para la extracción precisa y automatizada de la información del formulario. El análisis inexacto del documento destruirá la estructura de la tabla. La conversión de información incompleta de la tabla en representación vectorial (incrustación) no solo no puede capturar de manera efectiva la información semántica de la tabla, sino que también puede causar fácilmente problemas en el resultado final de RAG.
- Cómo extraer los títulos de cada tabla y asociarlos con la tabla específica a la que corresponden.
- Cómo organizar y almacenar de manera eficiente información semántica clave en tablas mediante un diseño de estructura de índice razonable.
Este artículo presenta primero cómo administrar y procesar datos tabulares en el modelo de recuperación de generación aumentada (RAG). Luego se revisan algunas soluciones de código abierto existentes y, finalmente, se diseña e implementa un novedoso método de gestión de datos tabulares basado en la tecnología actual.
01 Introducción a las tecnologías centrales relacionadas con los datos de la tabla RAG
1.1 Análisis de tablas Análisis de datos de tablas
La función principal de este módulo es extraer con precisión estructuras de tablas de documentos o imágenes no estructurados.
Requisitos adicionales: es mejor extraer el título de la tabla correspondiente para facilitar a los desarrolladores asociar el título de la tabla con la tabla.
Según mi conocimiento actual, existen varios métodos, como se muestra en la Figura 1:
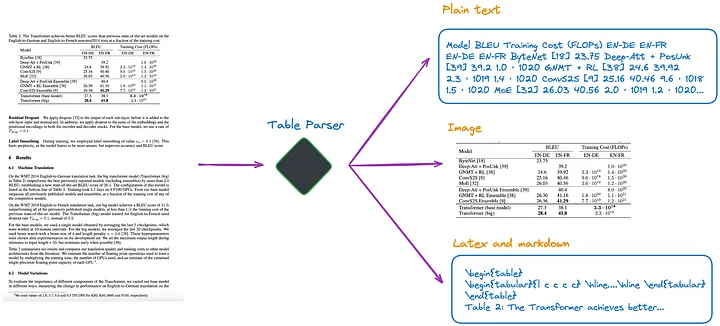
Figura 1: Analizador de tablas. Imagen proporcionada por el autor original.
(a).Utilice LLM multimodal (como GPT-4V[1]) para reconocer tablas y extraer información de cada página PDF.
- Entrada: página PDF en formato de imagen
- Salida: datos tabulares en JSON u otros formatos. Si el LLM multimodal no puede extraer datos tabulares, debe resumir la imagen PDF y devolver un resumen del contenido.
(b). Utilice modelos de detección de tablas profesionales (como Table Transformer[2]) para identificar las estructuras de las tablas.
- Entrada: imagen de página PDF
- Salida: imagen de la tabla
(c). Utilice marcos de código abierto, como no estructurados [3] u otros marcos que también utilicen modelos de detección de objetos (este artículo [4] detalla el proceso de detección de tablas no estructuradas). Estos marcos pueden analizar completamente todo el documento y extraer contenido relacionado con tablas de los resultados analizados.
- Entrada: Documento en formato PDF o imagen
- Salida: tabla en texto sin formato o formato HTML (obtenida al analizar todo el documento)
(d). Utilice modelos de un extremo a otro como Nougat[5] y Donut[6] para analizar todo el documento y extraer contenido relacionado con la tabla. Este enfoque no requiere un modelo OCR.
- Entrada: Documento en formato PDF o imagen
- Salida: Tabla en formato LaTeX o JSON (obtenida al analizar todo el documento)
Cabe señalar que no importa qué método se utilice para extraer la información de la tabla, también se debe extraer el título de la tabla. Porque en la mayoría de los casos, el título de la tabla es una breve descripción de la tabla por parte del autor del documento o del artículo, que puede resumir en gran medida el contenido de toda la tabla.
Entre los cuatro métodos anteriores, el método (d) puede recuperar títulos de tablas de manera más conveniente. Este es un gran beneficio para los desarrolladores, ya que pueden asociar títulos de tablas con tablas. Los siguientes experimentos ilustrarán mejor esto.
1.2 Cómo indexa la estructura del índice los datos tabulares
Existen aproximadamente los siguientes tipos de métodos de indexación:
(e). Sólo tablas de índice en formato de imagen.
(f). Indizar únicamente tablas en texto plano o formato JSON.
(g). Sólo tablas de índice en formato LaTeX.
(h). Sólo se indexa el resumen de la tabla.
(i) De pequeño a grande (Nota del traductor: incluye tanto la indexación detallada, como la indexación de cada fila o el resumen de la tabla, como la indexación gruesa, como la indexación de la tabla completa de imágenes, texto sin formato o LaTeX). escriba datos, forme una estructura de índice jerárquica, de pequeña a grande). O utilice el resumen de la tabla para crear una estructura de índice, como se muestra en la Figura 2.
El contenido del fragmento pequeño (Nota del traductor: bloque de datos correspondiente al nivel de índice detallado), como tratar cada fila de la tabla o información resumida como un pequeño bloque de datos independiente.
El contenido del fragmento grande (Nota del traductor: el bloque de datos correspondiente al nivel de índice de grano grueso) puede ser una tabla completa en formato de imagen, formato de texto sin formato o formato LaTeX.
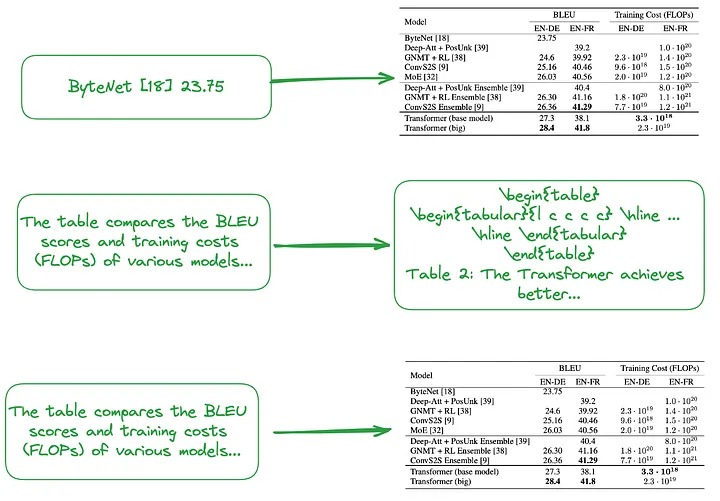
Figura 2: Indexación de pequeño a grande (arriba) y uso de resúmenes de tablas (centro, abajo). Imagen proporcionada por el autor original.
Como se mencionó anteriormente, los resúmenes tabulares generalmente se generan mediante el procesamiento LLM:
- Entrada: formato de imagen, formato de texto o tabla en formato LaTeX
- Salida: resumen de la tabla
1.3 Un enfoque que no requiere analizar tablas, crear índices ni utilizar tecnología RAG
Algunos algoritmos no requieren análisis de datos tabulares.
(j). Envíe la imagen relevante (página del documento PDF) y la consulta del usuario al modelo VQA (como DAN [7], etc.) (Nota del traductor: abreviatura de modelo de respuesta visual a preguntas. Es una combinación de modelos de computadora. de visión y técnicas de procesamiento del lenguaje natural que se pueden utilizar para responder preguntas en lenguaje natural sobre el contenido de la imagen) o LLM multimodal y devolver respuestas.
- Contenido a indexar: Documentos en formato imagen
- Qué enviar al modelo VQA o LLM multimodal: Consulta + página de documentación correspondiente como imagen
(k). Enviar la página PDF en formato de texto relevante y la consulta del usuario a LLM, y luego devolver la respuesta.
- Contenido a indexar: Documentos en formato texto
- Contenido enviado a LLM: Consulta + página de documentación correspondiente en formato texto
(l). Envíe imágenes de documentos relevantes (páginas de documentos PDF), bloques de texto y la consulta del usuario a un LLM multimodal (como GPT-4V, etc.) y luego devuelva directamente la respuesta.
- Contenido a indexar: documentos en formato de imagen y fragmentos de documentos en formato de texto
- Contenido enviado a LLM multimodal: consulta + documento en el formato de imagen correspondiente + fragmentos de texto correspondientes
Además, a continuación se muestran algunos métodos que no requieren indexación, como se muestra en las Figuras 3 y 4:
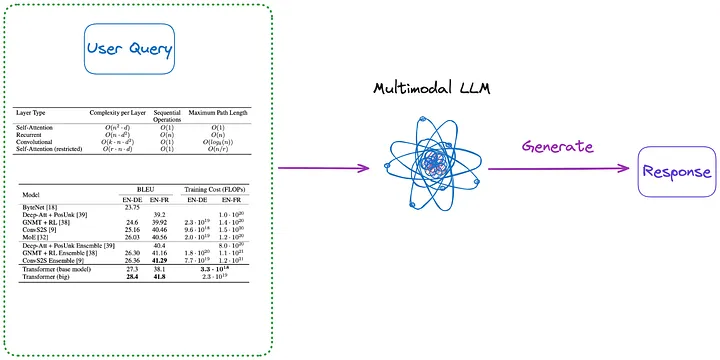
Figura 3: Categoría (m) (Nota del traductor: contenido presentado en el primer párrafo a continuación). Imagen proporcionada por el autor original.
(m). Primero, analice todas las tablas del documento en forma de imagen utilizando cualquiera de los métodos de (a) a (d). Luego, todas las imágenes de la tabla y la consulta del usuario se envían directamente a un LLM multimodal (como GPT-4V, etc.) y se devuelve la respuesta.
- Contenido a indexar: Ninguno
- Contenido enviado a LLM multimodal: consulta + todas las tablas que se han convertido a formato de imagen
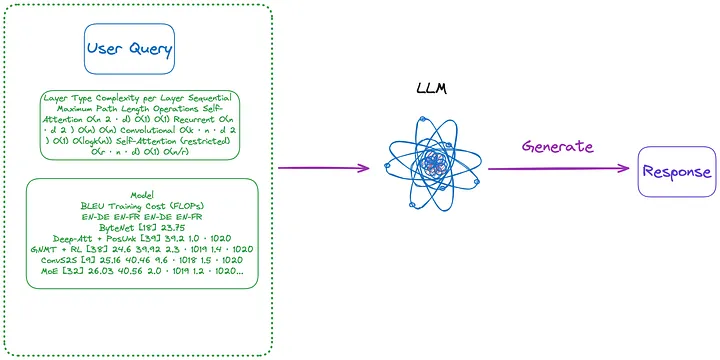
Figura 4: Categoría (n) (Nota del traductor: contenido presentado en el primer párrafo a continuación). Imagen proporcionada por el autor original.
(n) Use la tabla en el formato de imagen extraído por el método (m), y luego use el modelo OCR para identificar todo el texto en la tabla y luego envíe directamente todo el texto en la tabla y la consulta del usuario a LLM. y devolver directamente la respuesta.
- Contenido a indexar: Ninguno
- Contenido enviado a LLM: Consulta del usuario + todo el contenido de la tabla (enviado en formato de texto)
Vale la pena señalar que al procesar tablas en documentos, algunos métodos no utilizan la tecnología RAG (Recuperación-Generación Aumentada):
- El primer tipo de método no utiliza LLM, sino que se entrena en un conjunto de datos específico, de modo que los modelos de IA (como otros modelos de lenguaje basados en la arquitectura Transformer e inspirados en BERT) puedan soportar mejor el procesamiento de tareas de comprensión de tablas, como TAPAS [8 ].
- El segundo tipo de método es utilizar LLM, utilizando métodos de pre-entrenamiento, ajuste fino o ingeniería de palabras rápidas, para que LLM pueda completar tareas de comprensión de tablas, como GPT4Table [9].
02 Soluciones de código abierto existentes para el procesamiento de tablas
La sección anterior resumió y clasificó las tecnologías clave para el procesamiento de datos tabulares en sistemas RAG. Antes de proponer la solución que implementaremos en este artículo, exploremos algunas soluciones de código abierto.
LlamaIndex propone cuatro métodos [10], de los cuales los tres primeros utilizan modelos multimodales.
- Recupere la imagen de la página PDF relevante y envíela a GPT-4V en respuesta a la consulta del usuario.
- Convierta cada página PDF a formato de imagen y deje que GPT-4V realice el razonamiento de imágenes en cada página. Establezca un índice de Text Vector Store para el proceso de razonamiento de la imagen (Nota del traductor: convierta la información de texto inferida de la imagen en forma vectorial y cree un índice) y luego use Image Reasoning Vector Store (Nota del traductor: debe ser el índice anterior , consulte el índice de Text Vector Store creado anteriormente) para encontrar la respuesta.
- Utilice Table Transformer para recortar la información de la tabla de las imágenes recuperadas y luego envíe estas imágenes de tabla recortadas a GPT-4V para obtener respuestas a la consulta (Nota del traductor: envíe la consulta al modelo y obtenga las respuestas devueltas por el modelo).
- Aplique OCR en la imagen de la tabla recortada y envíe los datos a GPT4/GPT-3.5 para responder la consulta del usuario.
Para resumir los cuatro métodos anteriores:
- El primer método es similar al método (j) presentado en este artículo y no requiere análisis de tablas. Pero resulta que, aunque la respuesta está ahí en la imagen, no produce la respuesta correcta.
- El segundo método implica el análisis de tablas y corresponde al método (a). El contenido del índice puede ser contenido tabular o resúmenes de contenido, dependiendo completamente de los resultados arrojados por GPT-4V, que pueden corresponder al método (f) o (h). La desventaja de este enfoque es que la capacidad de GPT-4V para identificar tablas y extraer su contenido de imágenes de documentos es inconsistente, especialmente cuando la imagen del documento contiene tablas, texto y otras imágenes (lo cual es común en documentos PDF).
- El tercer método es similar al método (m) y no requiere indexación.
- El cuarto método es similar al método (n) y tampoco requiere indexación. Los resultados mostraron que la razón de las respuestas incorrectas era la incapacidad de extraer eficazmente información tabular de las imágenes.
A través de las pruebas, se descubrió que el tercer método tiene el mejor efecto general. Sin embargo, según las pruebas que realicé, el tercer método tuvo problemas para detectar la tabla, y mucho menos para extraer y asociar correctamente el título y el contenido de la tabla.
Langchain también propuso algunas soluciones para la tecnología RAG (RAG semiestructurada) de datos semiestructurados [11]. Las tecnologías principales incluyen:
- Utilice no estructurado para el análisis de tablas, que es un método de clase (c).
- El método de índice es el índice de resumen de documentos (Nota del traductor: utilice información de resumen de documentos como contenido del índice), que pertenece al método de clase (i). El bloque de datos correspondiente al nivel de índice detallado: contenido de resumen de la tabla y el bloque de datos correspondiente al nivel de índice detallado: contenido de la tabla original (formato de texto).
Como se muestra en la Figura 5:
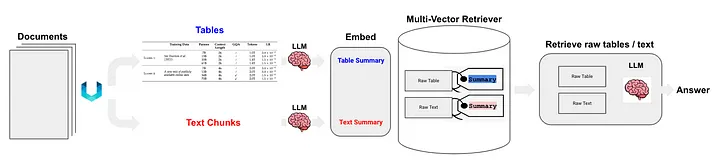
Figura 5: Solución RAG semiestructurada de Langchain. Fuente: RAG semiestructurado[11]
RAG semiestructurado y multimodal [12] propuso tres soluciones, cuya arquitectura se muestra en la Figura 6.
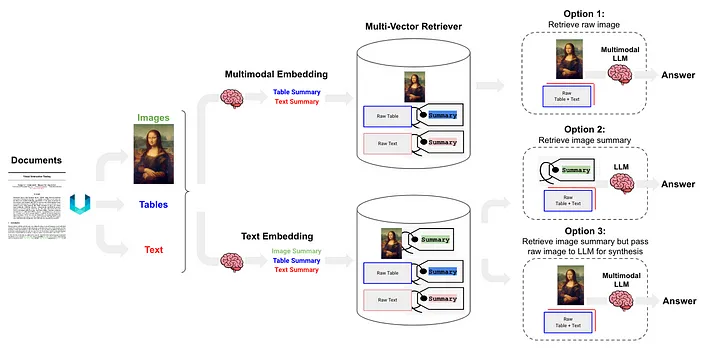
Figura 6: Esquema RAG semiestructurado y multimodal de Langchain. Fuente: RAG Semiestructurado y Multimodal[12].
La opción 1 es similar al método (l) anterior. Este enfoque implica el uso de incrustaciones multimodales (como CLIP [13]) para convertir imágenes y texto en vectores de incrustación, luego usar un algoritmo de búsqueda de similitud para recuperar ambos y convertir los datos de imagen y texto sin procesar que se pasan al LLM multimodal, permitiéndoles para ser procesados en conjunto y generar respuestas a preguntas.
La opción 2 utiliza LLM multimodal (como GPT-4V[14], LLaVA[15] o FUYU-8b[16]) para procesar la imagen y generar resúmenes de texto. Luego, los datos de texto se convierten en vectores de incrustación, y estos vectores se utilizan para buscar o recuperar contenido de texto que coincida con la consulta planteada por el usuario y se pasan al LLM para generar respuestas.
- Los datos de la tabla se analizan utilizando el método no estructurado, que pertenece al método de clase (d).
- El método de indexación es el índice de resumen del documento (Nota del traductor: la información del resumen del documento se utiliza como contenido del índice), que pertenece al método de clase (i) El bloque de datos correspondiente al nivel de índice detallado: el contenido del resumen de la tabla y los datos. bloque correspondiente al nivel de índice de grano grueso: texto Formatear el contenido de la tabla.
La opción 3 utiliza LLM multimodal (como GPT-4V [14], LLaVA [15] o FUYU-8b [16]) para generar resúmenes de texto a partir de datos de imágenes y luego incrustar estos resúmenes de texto en vectores, utilizando estos vectores de incrustación. , Los resúmenes de imágenes se pueden recuperar (recuperar) de manera eficiente. En cada resumen de imagen recuperado, se conserva una referencia correspondiente a la imagen sin procesar (referencia a la imagen sin procesar). y los bloques de texto se pasan al LLM multimodal para generar respuestas.
03 La solución propuesta en este artículo.
Las tecnologías clave y las soluciones existentes se resumen, clasifican y analizan en el artículo anterior. Sobre esta base, proponemos la siguiente solución, como se muestra en la Figura 7. Para simplificar, algunos módulos RAG, como la reclasificación y la reescritura de consultas, se omiten en la figura.
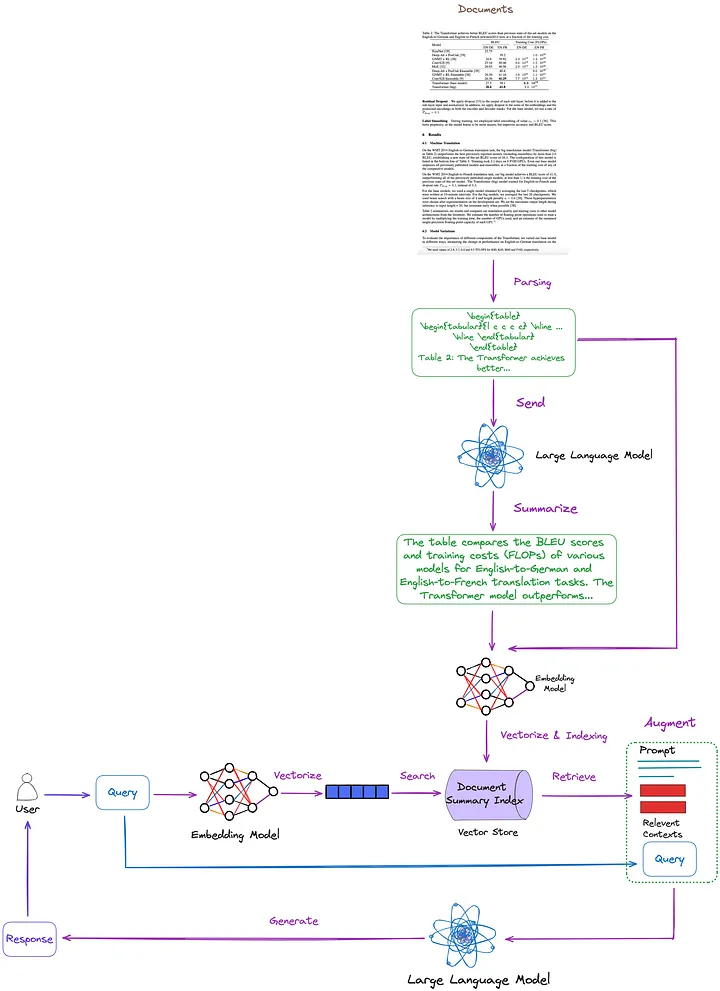
Figura 7: La solución propuesta en este artículo. Imagen proporcionada por el autor original.
- Técnica de análisis de tablas: utilizando Nougat (método de clase (d)). Según mis pruebas, las capacidades de detección de tablas de esta herramienta son más efectivas que las no estructuradas (una técnica de tipo (c)). Además, Nougat también puede extraer muy bien títulos de tablas, lo que hace que sea muy conveniente asociarlos con tablas.
- Estructura de índice para indexar y recuperar resúmenes de documentos (métodos de la clase (i)): el nivel de índice detallado contiene resúmenes de contenido tabular, y el nivel de índice detallado contiene tablas correspondientes en formato LaTeX y títulos de tablas en formato de texto. Usamos un recuperador de múltiples vectores[17] (Nota del traductor: un recuperador para recuperar contenido en un índice de resumen de documentos que puede procesar múltiples vectores al mismo tiempo para recuperar de manera eficiente resúmenes de documentos relacionados con la consulta).
- Cómo obtener un resumen del contenido de una tabla: envíe la tabla y el título de la tabla a LLM para resumir el contenido.
La ventaja de este método es que puede analizar la tabla de manera efectiva y considerar completamente la relación entre el resumen de la tabla y la tabla. Elimina la necesidad de utilizar LLM multimodal, lo que genera ahorros de costos.
3.1 Cómo funciona Turrón
Nougat [18] está desarrollado en base a la arquitectura Donut [19]. Este enfoque utiliza algoritmos que pueden reconocer automáticamente texto de manera implícita sin ninguna entrada o módulo relacionado con OCR.
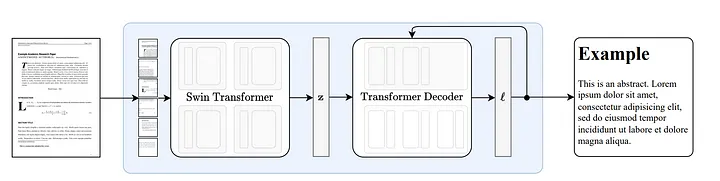
Figura 8: Arquitectura de extremo a extremo siguiendo Donut [19]. El codificador Swin Transformer toma una imagen de documento y la convierte en incrustaciones latentes (Nota del traductor: la información de la imagen está codificada en un espacio latente) y luego la convierte en una secuencia de tokens de manera autorregresiva. Fuente: Nougat: Neural Optical Understanding for Academic Documents.[18]
La capacidad de Nougat para analizar fórmulas es impresionante[20], pero su capacidad para analizar tablas también es excepcional. Como se muestra en la Figura 9, se puede asociar con títulos de tablas, lo cual es muy conveniente:

Figura 9: Resultados de ejecución de Nougat El archivo de resultados está en formato Mathpix Markdown (se puede abrir a través del complemento vscode) y la tabla se presenta en formato LaTeX.
En una prueba que realicé en una docena de artículos, descubrí que los títulos de las tablas siempre estaban fijos en la siguiente fila de la tabla. Esta coherencia sugiere que esto no fue un accidente. Por lo tanto, estamos más interesados en cómo Nougat logra esta funcionalidad.
Dado que se trata de un modelo de extremo a extremo que carece de resultados intermedios, es probable que su rendimiento dependa en gran medida de sus datos de entrenamiento.
Según el análisis del código, la ubicación y la forma en que se almacena la sección del encabezado de la tabla parecen ser consistentes (e inmediatamente \end{table} posteriores caption_parts ) con el formato organizativo de la tabla en los datos de entrenamiento.
def format_element(
element: Element, keep_refs: bool = False, latex_env: bool = False
) -> List[str]:
"""
Formats a given Element into a list of formatted strings.
Args:
element (Element): The element to be formatted.
keep_refs (bool, optional): Whether to keep references in the formatting. Default is False.
latex_env (bool, optional): Whether to use LaTeX environment formatting. Default is False.
Returns:
List[str]: A list of formatted strings representing the formatted element.
"""
...
...
if isinstance(element, Table):
parts = [
"[TABLE%s]\n\begin{table}\n"
% (str(uuid4())[:5] if element.id is None else ":" + str(element.id))
]
parts.extend(format_children(element, keep_refs, latex_env))
caption_parts = format_element(element.caption, keep_refs, latex_env)
remove_trailing_whitespace(caption_parts)
parts.append("\end{table}\n")
if len(caption_parts) > 0:
parts.extend(caption_parts + ["\n"])
parts.append("[ENDTABLE]\n\n")
return parts
...
...
3.2 Ventajas y Desventajas del Turrón
ventaja:
- Nougat puede analizar con precisión secciones que eran difíciles de analizar con herramientas de análisis anteriores, como fórmulas y tablas, en código fuente LaTeX.
- El resultado del análisis de Nougat es un documento semiestructurado similar a Markdown.
- Capacidad para obtener fácilmente títulos de tablas y asociarlos fácilmente con tablas.
defecto:
- La velocidad de análisis de Nougat es lenta, lo que puede causar dificultades en aplicaciones a gran escala.
- Dado que el conjunto de datos de entrenamiento de Nougat son básicamente artículos científicos, esta técnica funciona bien en documentos con estructuras similares. El rendimiento se degrada al procesar documentos de texto no latinos.
- El modelo Nougat solo se entrena en una página de un artículo científico a la vez y carece de conocimiento de otras páginas. Esto puede generar algunas inconsistencias en el contenido analizado. Por lo tanto, si el efecto de reconocimiento no es bueno, puede considerar dividir el PDF en páginas separadas y analizarlas página por página.
- El análisis de tablas en artículos de dos columnas no es tan bueno como en artículos de una sola columna.
3.3 Implementación del código
Primero, instale los paquetes de Python relevantes:
pip install langchain
pip install chromadb
pip install nougat-ocr
Una vez completada la instalación, debe verificar la versión del paquete Python:
langchain 0.1.12
langchain-community 0.0.28
langchain-core 0.1.31
langchain-openai 0.0.8
langchain-text-splitters 0.0.1
chroma-hnswlib 0.7.3
chromadb 0.4.24
nougat-ocr 0.1.17
Configure un entorno de trabajo e importe paquetes:
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
import subprocess
import uuid
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
from langchain_core.runnables import RunnablePassthrough
Descargue el documento "La atención es todo lo que necesita" [21] en la ruta YOUR_PDF_PATH, ejecute turrón para analizar el archivo PDF y obtenga los datos de la tabla en formato látex y el título de la tabla en formato de texto a partir de los resultados del análisis. Al ejecutar el programa por primera vez, se descargarán los archivos de modelo necesarios al entorno local.
def june_run_nougat(file_path, output_dir):
# Run Nougat and store results as Mathpix Markdown
cmd = ["nougat", file_path, "-o", output_dir, "-m", "0.1.0-base", "--no-skipping"]
res = subprocess.run(cmd)
if res.returncode != 0:
print("Error when running nougat.")
return res.returncode
else:
print("Operation Completed!")
return 0
def june_get_tables_from_mmd(mmd_path):
f = open(mmd_path)
lines = f.readlines()
res = []
tmp = []
flag = ""
for line in lines:
if line == "\begin{table}\n":
flag = "BEGINTABLE"
elif line == "\end{table}\n":
flag = "ENDTABLE"
if flag == "BEGINTABLE":
tmp.append(line)
elif flag == "ENDTABLE":
tmp.append(line)
flag = "CAPTION"
elif flag == "CAPTION":
tmp.append(line)
flag = "MARKDOWN"
print('-' * 100)
print(''.join(tmp))
res.append(''.join(tmp))
tmp = []
return res
file_path = "YOUR_PDF_PATH"
output_dir = "YOUR_OUTPUT_DIR_PATH"
if june_run_nougat(file_path, output_dir) == 1:
import sys
sys.exit(1)
mmd_path = output_dir + '/' + os.path.splitext(file_path)[0].split('/')[-1] + ".mmd"
tables = june_get_tables_from_mmd(mmd_path)
La función june_get_tables_from_mmd se utiliza para extraer todo el contenido de un archivo mmd (desde \begin{table} hasta \end{table}, pero también incluye \end{table} la primera línea después), como se muestra en la Figura 10.

Figura 10: Resultados de ejecución de Nougat El archivo de resultados está en formato Mathpix Markdown (se puede abrir a través del complemento vscode) y el contenido de la tabla analizada está en formato látex. La función de la función june_get_tables_from_mmd es extraer la información de la tabla en el cuadro rojo. Imagen proporcionada por el autor original.
Sin embargo, no existe ningún documento oficial que indique que el título de la tabla deba colocarse debajo de la tabla, o que la tabla deba comenzar con \begin{table} y terminar con \end{table}. Por tanto, june_get_tables_from_mmd es un método heurístico.
Los siguientes son los resultados del análisis de la tabla del documento PDF:
Operation Completed!
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{l c c c} \hline \hline Layer Type & Complexity per Layer & Sequential Operations & Maximum Path Length \ \hline Self-Attention & (O(n^{2}\cdot d)) & (O(1)) & (O(1)) \ Recurrent & (O(n\cdot d^{2})) & (O(n)) & (O(n)) \ Convolutional & (O(k\cdot n\cdot d^{2})) & (O(1)) & (O(log_{k}(n))) \ Self-Attention (restricted) & (O(r\cdot n\cdot d)) & (O(1)) & (O(n/r)) \ \hline \hline \end{tabular}
\end{table}
Table 1: Maximum path lengths, per-layer complexity and minimum number of sequential operations for different layer types. (n) is the sequence length, (d) is the representation dimension, (k) is the kernel size of convolutions and (r) the size of the neighborhood in restricted self-attention.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{l c c c c} \hline \hline \multirow{2}{*}{Model} & \multicolumn{2}{c}{BLEU} & \multicolumn{2}{c}{Training Cost (FLOPs)} \ \cline{2-5} & EN-DE & EN-FR & EN-DE & EN-FR \ \hline ByteNet [18] & 23.75 & & & \ Deep-Att + PosUnk [39] & & 39.2 & & (1.0\cdot 10^{20}) \ GNMT + RL [38] & 24.6 & 39.92 & (2.3\cdot 10^{19}) & (1.4\cdot 10^{20}) \ ConvS2S [9] & 25.16 & 40.46 & (9.6\cdot 10^{18}) & (1.5\cdot 10^{20}) \ MoE [32] & 26.03 & 40.56 & (2.0\cdot 10^{19}) & (1.2\cdot 10^{20}) \ \hline Deep-Att + PosUnk Ensemble [39] & & 40.4 & & (8.0\cdot 10^{20}) \ GNMT + RL Ensemble [38] & 26.30 & 41.16 & (1.8\cdot 10^{20}) & (1.1\cdot 10^{21}) \ ConvS2S Ensemble [9] & 26.36 & **41.29** & (7.7\cdot 10^{19}) & (1.2\cdot 10^{21}) \ \hline Transformer (base model) & 27.3 & 38.1 & & (\mathbf{3.3\cdot 10^{18}}) \ Transformer (big) & **28.4** & **41.8** & & (2.3\cdot 10^{19}) \ \hline \hline \end{tabular}
\end{table}
Table 2: The Transformer achieves better BLEU scores than previous state-of-the-art models on the English-to-German and English-to-French newstest2014 tests at a fraction of the training cost.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{c|c c c c c c c c|c c c c} \hline \hline & (N) & (d_{\text{model}}) & (d_{\text{ff}}) & (h) & (d_{k}) & (d_{v}) & (P_{drop}) & (\epsilon_{ls}) & train steps & PPL & BLEU & params \ \hline base & 6 & 512 & 2048 & 8 & 64 & 64 & 0.1 & 0.1 & 100K & 4.92 & 25.8 & 65 \ \hline \multirow{4}{*}{(A)} & \multicolumn{1}{c}{} & & 1 & 512 & 512 & & & & 5.29 & 24.9 & \ & & & & 4 & 128 & 128 & & & & 5.00 & 25.5 & \ & & & & 16 & 32 & 32 & & & & 4.91 & 25.8 & \ & & & & 32 & 16 & 16 & & & & 5.01 & 25.4 & \ \hline (B) & \multicolumn{1}{c}{} & & \multicolumn{1}{c}{} & & 16 & & & & & 5.16 & 25.1 & 58 \ & & & & & 32 & & & & & 5.01 & 25.4 & 60 \ \hline \multirow{4}{*}{(C)} & 2 & \multicolumn{1}{c}{} & & & & & & & & 6.11 & 23.7 & 36 \ & 4 & & & & & & & & 5.19 & 25.3 & 50 \ & 8 & & & & & & & & 4.88 & 25.5 & 80 \ & & 256 & & 32 & 32 & & & & 5.75 & 24.5 & 28 \ & 1024 & & 128 & 128 & & & & 4.66 & 26.0 & 168 \ & & 1024 & & & & & & 5.12 & 25.4 & 53 \ & & 4096 & & & & & & 4.75 & 26.2 & 90 \ \hline \multirow{4}{*}{(D)} & \multicolumn{1}{c}{} & & & & & 0.0 & & 5.77 & 24.6 & \ & & & & & & 0.2 & & 4.95 & 25.5 & \ & & & & & & & 0.0 & 4.67 & 25.3 & \ & & & & & & & 0.2 & 5.47 & 25.7 & \ \hline (E) & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} & & \multicolumn{1}{c}{} & & & & & 4.92 & 25.7 & \ \hline big & 6 & 1024 & 4096 & 16 & & 0.3 & 300K & **4.33** & **26.4** & 213 \ \hline \hline \end{tabular}
\end{table}
Table 3: Variations on the Transformer architecture. Unlisted values are identical to those of the base model. All metrics are on the English-to-German translation development set, newstest2013. Listed perplexities are per-wordpiece, according to our byte-pair encoding, and should not be compared to per-word perplexities.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{c|c|c} \hline
**Parser** & **Training** & **WSJ 23 F1** \ \hline Vinyals & Kaiser et al. (2014) [37] & WSJ only, discriminative & 88.3 \ Petrov et al. (2006) [29] & WSJ only, discriminative & 90.4 \ Zhu et al. (2013) [40] & WSJ only, discriminative & 90.4 \ Dyer et al. (2016) [8] & WSJ only, discriminative & 91.7 \ \hline Transformer (4 layers) & WSJ only, discriminative & 91.3 \ \hline Zhu et al. (2013) [40] & semi-supervised & 91.3 \ Huang & Harper (2009) [14] & semi-supervised & 91.3 \ McClosky et al. (2006) [26] & semi-supervised & 92.1 \ Vinyals & Kaiser el al. (2014) [37] & semi-supervised & 92.1 \ \hline Transformer (4 layers) & semi-supervised & 92.7 \ \hline Luong et al. (2015) [23] & multi-task & 93.0 \ Dyer et al. (2016) [8] & generative & 93.3 \ \hline \end{tabular}
\end{table}
Table 4: The Transformer generalizes well to English constituency parsing (Results are on Section 23 of WSJ)* [5] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. _CoRR_, abs/1406.1078, 2014.
Luego use LLM para resumir los datos tabulares:
# Prompt
prompt_text = """You are an assistant tasked with summarizing tables and text. \
Give a concise summary of the table or text. The table is formatted in LaTeX, and its caption is in plain text format: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
# Summary chain
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
# Get table summaries
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
print(table_summaries)
El siguiente es un resumen del contenido de las cuatro tablas de "La atención es todo lo que necesita" [21], como se muestra en la Figura 11:
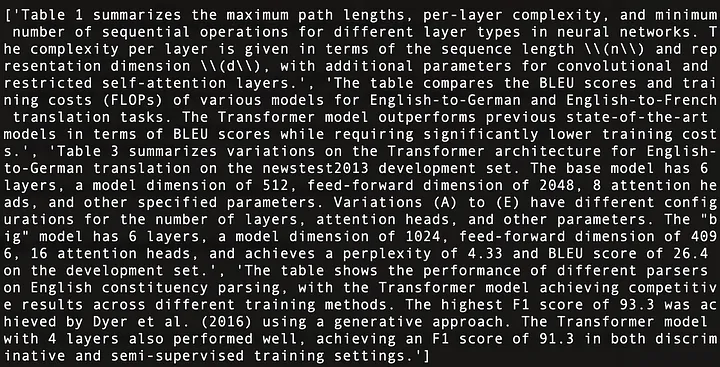
Figura 11: Resumen de contenido de las cuatro tablas de "La atención es todo lo que necesita" [21].
Utilice un recuperador de vectores múltiples (Nota del traductor: un recuperador para recuperar contenido en el índice de resumen de documentos. El recuperador puede procesar múltiples vectores al mismo tiempo para recuperar de manera efectiva resúmenes de documentos relacionados con la consulta). Cree una estructura de índice de resumen de documentos [17] (Nota del traductor: una estructura de índice que se utiliza para almacenar información resumida de documentos, y esta información resumida se puede recuperar o consultar según sea necesario).
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name = "summaries", embedding_function = OpenAIEmbeddings())
# The storage layer for the parent documents
store = InMemoryStore()
id_key = "doc_id"
# The retriever (empty to start)
retriever = MultiVectorRetriever(
vectorstore = vectorstore,
docstore = store,
id_key = id_key,
search_kwargs={"k": 1} # Solving Number of requested results 4 is greater than number of elements in index..., updating n_results = 1
)
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content = s, metadata = {id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
Una vez que todo esté listo, configure una canalización RAG simple y ejecute las consultas del usuario:
# Prompt template
template = """Answer the question based only on the following context, which can include text and tables, there is a table in LaTeX format and a table caption in plain text format:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
# Simple RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
print(chain.invoke("when layer type is Self-Attention, what is the Complexity per Layer?")) # Query about table 1
print(chain.invoke("Which parser performs worst for BLEU EN-DE")) # Query about table 2
print(chain.invoke("Which parser performs best for WSJ 23 F1")) # Query about table 4
Los resultados de ejecución son los siguientes. Estas preguntas se han respondido con precisión, como se muestra en la Figura 12:

Figura 12: Respuestas a tres consultas de usuarios. La primera fila corresponde a la tabla 1, la segunda fila a la tabla 2 y la tercera fila a la tabla 4 en Atención es todo lo que necesita.
El código general es el siguiente:
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
import subprocess
import uuid
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
from langchain_core.runnables import RunnablePassthrough
def june_run_nougat(file_path, output_dir):
# Run Nougat and store results as Mathpix Markdown
cmd = ["nougat", file_path, "-o", output_dir, "-m", "0.1.0-base", "--no-skipping"]
res = subprocess.run(cmd)
if res.returncode != 0:
print("Error when running nougat.")
return res.returncode
else:
print("Operation Completed!")
return 0
def june_get_tables_from_mmd(mmd_path):
f = open(mmd_path)
lines = f.readlines()
res = []
tmp = []
flag = ""
for line in lines:
if line == "\begin{table}\n":
flag = "BEGINTABLE"
elif line == "\end{table}\n":
flag = "ENDTABLE"
if flag == "BEGINTABLE":
tmp.append(line)
elif flag == "ENDTABLE":
tmp.append(line)
flag = "CAPTION"
elif flag == "CAPTION":
tmp.append(line)
flag = "MARKDOWN"
print('-' * 100)
print(''.join(tmp))
res.append(''.join(tmp))
tmp = []
return res
file_path = "YOUR_PDF_PATH"
output_dir = "YOUR_OUTPUT_DIR_PATH"
if june_run_nougat(file_path, output_dir) == 1:
import sys
sys.exit(1)
mmd_path = output_dir + '/' + os.path.splitext(file_path)[0].split('/')[-1] + ".mmd"
tables = june_get_tables_from_mmd(mmd_path)
# Prompt
prompt_text = """You are an assistant tasked with summarizing tables and text. \
Give a concise summary of the table or text. The table is formatted in LaTeX, and its caption is in plain text format: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
# Summary chain
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
# Get table summaries
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
print(table_summaries)
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name = "summaries", embedding_function = OpenAIEmbeddings())
# The storage layer for the parent documents
store = InMemoryStore()
id_key = "doc_id"
# The retriever (empty to start)
retriever = MultiVectorRetriever(
vectorstore = vectorstore,
docstore = store,
id_key = id_key,
search_kwargs={"k": 1} # Solving Number of requested results 4 is greater than number of elements in index..., updating n_results = 1
)
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content = s, metadata = {id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
# Prompt template
template = """Answer the question based only on the following context, which can include text and tables, there is a table in LaTeX format and a table caption in plain text format:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
# Simple RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
print(chain.invoke("when layer type is Self-Attention, what is the Complexity per Layer?")) # Query about table 1
print(chain.invoke("Which parser performs worst for BLEU EN-DE")) # Query about table 2
print(chain.invoke("Which parser performs best for WSJ 23 F1")) # Query about table 4
04 Conclusión
Este documento analiza las tecnologías clave y las soluciones existentes para las operaciones de procesamiento de tablas en sistemas RAG y propone una solución y su implementación.
En este artículo, utilizamos Nougat para analizar tablas. Sin embargo, consideraremos reemplazar Nougat si hay disponible una herramienta de análisis más rápida y eficiente. Nuestra actitud hacia las herramientas es tener primero la idea correcta y luego encontrar herramientas para implementarla, en lugar de depender de una determinada herramienta.
En este artículo, ingresamos todo el contenido de la tabla en LLM. Sin embargo, en escenarios reales, debemos tener en cuenta la situación en la que el tamaño de la tabla excede la longitud del contexto LLM. Podemos resolver este problema utilizando métodos de fragmentación eficientes.
¡Gracias por leer!
——
florián junio
Investigador de inteligencia artificial, escribe principalmente artículos sobre modelos de lenguajes grandes, estructuras y algoritmos de datos y PNL.
FIN
Referencias
[1] https://openai.com/research/gpt-4v-system-card
[2] https://github.com/microsoft/table-transformer
[3] https://unstructured-io.github.io/unstructured/best_practices/table_extraction_pdf.html
[4] https://pub.towardsai.net/advanced-rag-02-unveiling-pdf-parsing-b84ae866344e
[5] https://github.com/facebookresearch/nougat
[6] https://github.com/clovaai/donut/
[7] https://arxiv.org/pdf/1611.00471.pdf
[8] https://aclanthology.org/2020.acl-main.398.pdf
[9] https://arxiv.org/pdf/2305.13062.pdf
[10] https://docs.llamaindex.ai/en/stable/examples/multi_modal/multi_modal_pdf_tables.html
[13] https://openai.com/research/clip
[14] https://openai.com/research/gpt-4v-system-card
[16] https://www.adept.ai/blog/fuyu-8b
[17] https://python.langchain.com/docs/modules/data_connection/retrievers/multi_vector
[18] https://arxiv.org/pdf/2308.13418.pdf
[19] https://arxiv.org/pdf/2111.15664.pdf
[21] https://arxiv.org/pdf/1706.03762.pdf
Este artículo fue compilado por Baihai IDP con la autorización del autor original. Si necesita reimprimir la traducción, comuníquese con nosotros para obtener autorización.
Enlace original:
https://ai.plainenglish.io/advanced-rag-07-exploring-rag-for-tables-5c3fc0de7af6
¿Cuántos ingresos puede generar un proyecto desconocido de código abierto? El equipo chino de inteligencia artificial de Microsoft empacó colectivamente y se fue a los Estados Unidos, involucrando a cientos de personas. Huawei anunció oficialmente que los cambios de trabajo de Yu Chengdong estaban clavados en el "Pilar de la vergüenza de FFmpeg" durante 15 años. Hace, pero hoy tiene que agradecernos—— ¿Tencent QQ Video venga su humillación pasada? El sitio espejo de código abierto de la Universidad de Ciencia y Tecnología de Huazhong está oficialmente abierto para acceso externo : Django sigue siendo la primera opción para el 74% de los desarrolladores. El editor Zed ha logrado avances en el soporte de Linux. Un ex empleado de una conocida empresa de código abierto . dio la noticia: después de ser desafiada por un subordinado, la líder técnica se puso furiosa y grosera, fue despedida y quedó embarazada. La empleada Alibaba Cloud lanza oficialmente Tongyi Qianwen 2.5 Microsoft dona 1 millón de dólares a la Fundación Rust.