

Si eres un usuario con dos aplicaciones RAG diferentes, ¿cómo decides cuál es mejor? Para los desarrolladores, ¿cómo mejorar cuantitativa e iterativamente el rendimiento de su aplicación RAG?
Claramente, es importante tanto para los usuarios como para los desarrolladores evaluar con precisión el rendimiento de las aplicaciones RAG. Sin embargo, una simple comparación de unos pocos ejemplos no puede medir completamente la calidad de las respuestas de las aplicaciones RAG. Es necesario utilizar indicadores creíbles y reproducibles para evaluar cuantitativamente las aplicaciones RAG.
Este artículo discutirá cómo evaluar cuantitativamente una aplicación RAG desde la perspectiva de la caja negra y la caja blanca.
01. Método de caja negra VS método de caja blanca
Comparamos la evaluación de aplicaciones RAG con la prueba de un sistema de software. Hay dos formas de evaluar la calidad del sistema RAG, una es el método de caja negra y la otra es el método de caja blanca.
Al evaluar una aplicación RAG en forma de caja negra, no podemos ver el interior de la aplicación RAG y solo podemos evaluar el efecto de RAG desde la información ingresada a la aplicación RAG y la información que devuelve. Para un sistema RAG general, solo podemos acceder a estas tres piezas de información: consulta del usuario, contextos recuperados recuperados por el sistema RAG y respuesta de RAG. Utilizamos estos tres datos para evaluar el efecto de las aplicaciones RAG. El método de caja negra es un método de evaluación de un extremo a otro y también es más adecuado para evaluar aplicaciones RAG de código cerrado.
Al evaluar una aplicación RAG en forma de caja blanca, podemos ver todos los procesos internos de la aplicación RAG. Por lo tanto, algunos componentes internos clave pueden determinar el rendimiento de esta aplicación RAG. Tomando como ejemplo el proceso de solicitud común de RAG, algunos componentes clave incluyen el modelo de integración, el modelo de reclasificación y el LLM. Algunos RAG tienen capacidades de recuperación multicanal y también pueden tener algoritmos de búsqueda de frecuencia de términos. Reemplazar y actualizar estos componentes clave también puede brindar mejores resultados a las aplicaciones RAG. El enfoque de caja blanca se puede utilizar para evaluar aplicaciones RAG de código abierto o mejorar aplicaciones RAG de desarrollo propio.
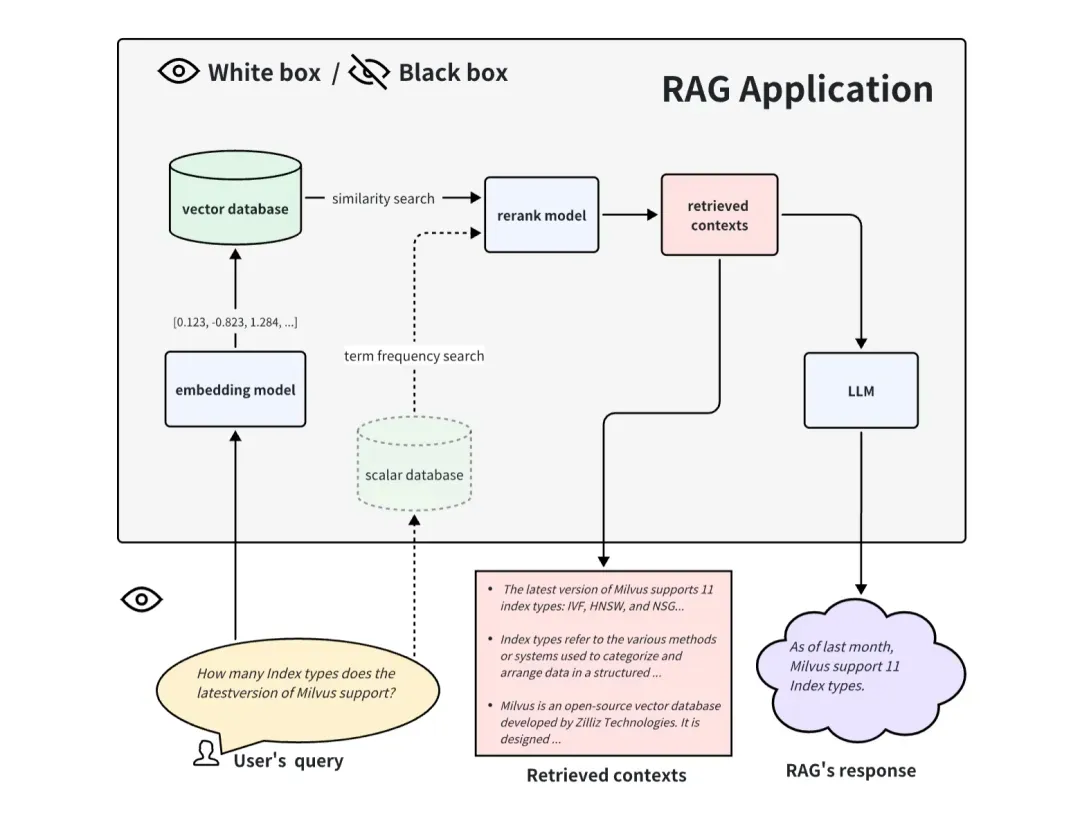
02.Método de evaluación de un extremo a otro de la caja negra
Indicadores de evaluación en condiciones de caja negra.
En el caso de que la aplicación RAG sea una caja negra, solo podemos acceder a estos tres datos: consulta del usuario, contextos recuperados recuperados por el sistema RAG y respuesta de RAG. Son el triplete más importante en todo el proceso de RAG, y dos de ellos se frenan entre sí. Podemos evaluar el efecto de una aplicación RAG detectando la correlación entre dos elementos del triplete.
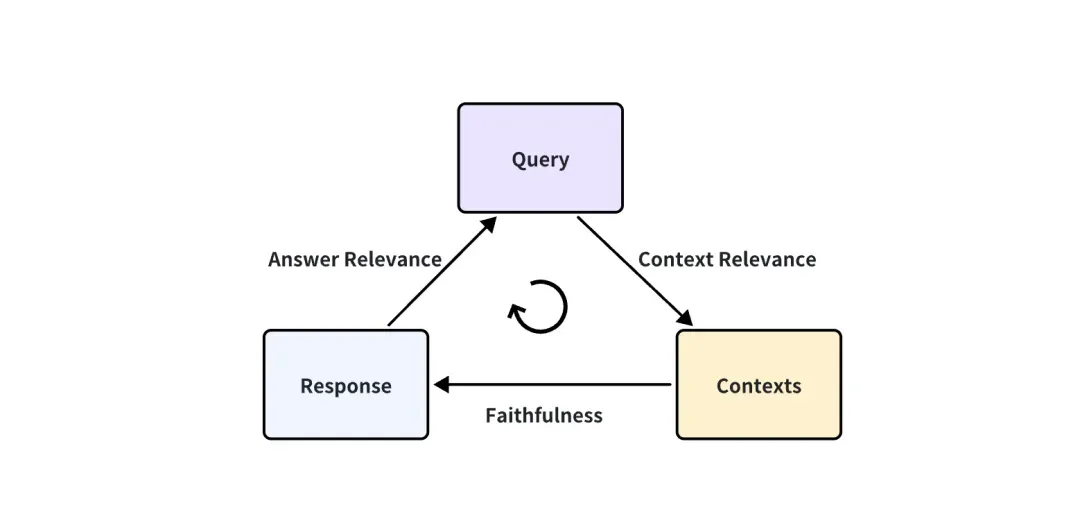
Se proponen las siguientes tres puntuaciones de indicadores correspondientes:
-
Relevancia del contexto: mide hasta qué punto el contexto recuperado puede admitir la consulta. Si la puntuación es baja, refleja que se ha recordado demasiado contenido irrelevante para la pregunta de la consulta, y estos conocimientos recordados erróneos tendrán un cierto impacto en la respuesta final de LLM.
-
Fidelidad: esta métrica mide la coherencia fáctica de las respuestas generadas en un contexto determinado. Se calcula en función de la respuesta y el contexto recuperado. Si esta puntuación es baja, lo que refleja el hecho de que la respuesta del LLM no se ajusta al conocimiento recordado, entonces es más probable que la respuesta sea ilusoria.
-
Relevancia de la respuesta: se centra en evaluar la relevancia de la respuesta generada para una consulta determinada. Se asignan puntuaciones más bajas a las respuestas que están incompletas o contienen información redundante.
Tome la relevancia de la respuesta como ejemplo:
Question: Where is France and what is it’s capital?
Low relevance answer: France is in western Europe.
High relevance answer: France is in western Europe and Paris is its capital.
¿Cómo calcular cuantitativamente estos indicadores?
Para la pregunta "¿Dónde está Francia y cuál es su capital?", una respuesta de baja relevancia es "Francia está en Europa occidental". Esta es una conclusión extraída del análisis del conocimiento humano previo. Puntuación, ¿esta respuesta es 0,2 puntos y la otra respuesta es 0,4 puntos? Y objetivamente, debemos asegurarnos de que el efecto de 0,4 puntos sea mejor que el de 0,2 puntos.
Además, si cada respuesta requiere que los humanos califiquen, entonces se debe organizar una gran cantidad de trabajo y formular ciertos estándares rectores para que puedan aprender esta pauta y cumplirla para calificar. Este método lleva mucho tiempo y obviamente no es realista.
Afortunadamente, los LLM avanzados como GPT-4 ahora pueden alcanzar un nivel similar al de los anotadores humanos. Puede satisfacer las dos necesidades que mencionamos anteriormente al mismo tiempo. Una es que puede puntuar de forma cuantitativa, objetiva y justa, y la otra es que puede automatizarse.
En este artículo LLM-as-a-Judge ( https://arxiv.org/abs/2306.05685), el autor propuso la posibilidad de LLM como juez y realizó una gran cantidad de experimentos sobre esta base. Los resultados muestran que los jueces LLM poderosos (como GPT-4) pueden igualar bien el control y las preferencias humanas de crowdsourcing, logrando más del 80% de consistencia, que es el mismo nivel de consistencia entre humanos. Por lo tanto, el LLM como juez es un método escalable e interpretable para aproximarse a las preferencias humanas, cuya puntuación sería muy costosa de otro modo.
Se puede pensar que el acuerdo del 80% entre LLM y evaluadores humanos no significa que LLM y los humanos sean muy consistentes. Pero debe saber que es posible que dos personas diferentes que hayan recibido orientación no puedan lograr un 100% de acuerdo al calificar preguntas tan subjetivas. Por lo tanto, el hecho de que GPT-4 sea 80% consistente con los humanos muestra que GPT-4 puede convertirse completamente en un juez calificado.
Con respecto a cómo se califica GPT-4, todavía tomamos la relevancia de la respuesta como ejemplo. Usamos el siguiente mensaje para hacer preguntas de GPT-4:
There is an existing knowledge base chatbot application. I asked it a question and got a reply. Do you think this reply is a good answer to the question? Please rate this reply. The score is an integer between 0 and 10. 0 means that the reply cannot answer the question at all, and 10 means that the reply can answer the question perfectly.
Question: Where is France and what is it’s capital?
Reply: France is in western Europe and Paris is its capital.
La respuesta de GPT-4:
10
Se puede ver que siempre que se diseñe de antemano un mensaje adecuado, como el mensaje del ejemplo anterior, y se reemplacen la pregunta y la respuesta, todos los pares de control de calidad se pueden evaluar automáticamente. Por lo tanto, cómo diseñar el mensaje también es muy importante. El mensaje del ejemplo anterior es solo un ejemplo. El mensaje real suele ser muy largo para que la puntuación GPT sea más justa y sólida. Esto requiere el uso de algunas técnicas avanzadas de ingeniería de indicaciones, como las técnicas de cadena de pensamiento de disparo múltiple o CoT (cadena de pensamiento). Al diseñar estas indicaciones, a veces es necesario considerar algunos sesgos de LLM, como el sesgo de posición común de LLM: cuando la indicación es relativamente larga, LLM tiende a notar parte del contenido al frente de la indicación e ignorar parte del contenido en la mitad.
Afortunadamente, no tenemos que preocuparnos demasiado por el diseño rápido. Las herramientas de evaluación para estas aplicaciones RAG ya se han diseñado e integrado. La comunidad y el tiempo pueden ayudar a probar qué tan bien diseñan las indicaciones. Lo que debería preocuparnos más es que acceder a LLM como GPT-4 en grandes cantidades requiera consumir demasiadas claves API. En el futuro, espero que haya un LLM más barato o un LLM local que pueda alcanzar el nivel de ser un buen juez.
¿Necesito marcar la verdad sobre el terreno?
Es posible que haya notado que la verdad fundamental no se utiliza en el ejemplo anterior. Es una respuesta estándar escrita por humanos para responder las preguntas correspondientes. Por ejemplo, se puede definir un indicador entre Verdad fundamental y Respuesta, llamado Corrección de la respuesta, que se utiliza para medir la exactitud de las respuestas de RAG. El principio de puntuación es el mismo que la forma en que Answer Relevance utiliza la puntuación LLM mencionada anteriormente.
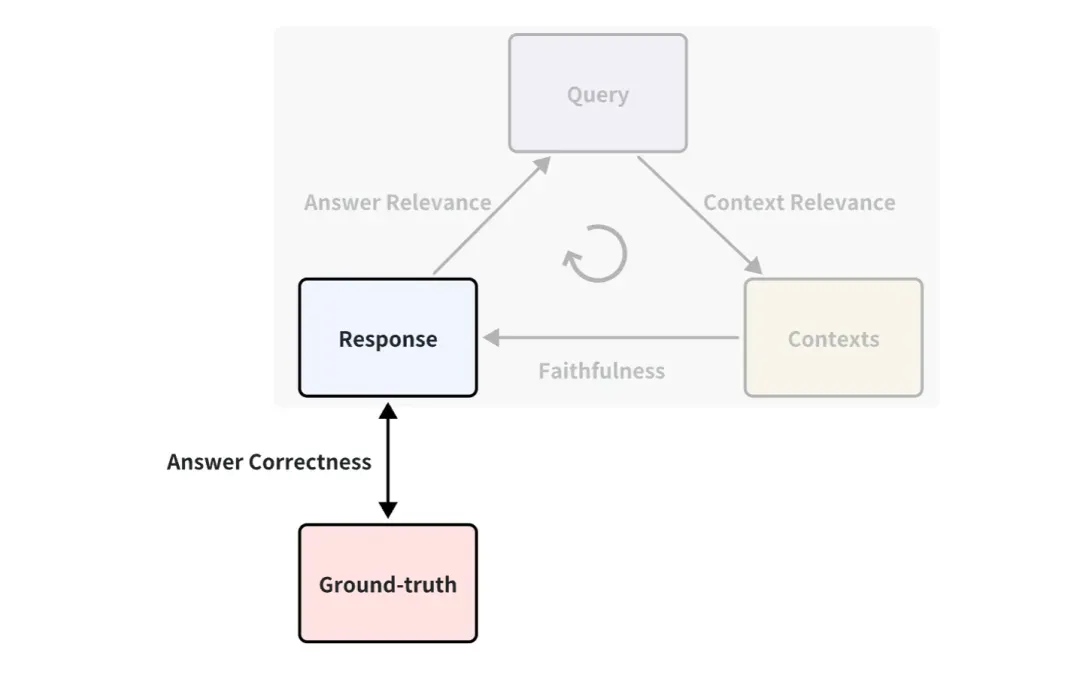
Por lo tanto, si existe verdad sobre el terreno, los indicadores de evaluación serán más ricos, es decir, el efecto de la aplicación de RAG se puede medir desde más ángulos. Pero en la mayoría de los casos, obtener un buen conjunto de datos estándar de verdad sobre el terreno es costoso y puede requerir mucha mano de obra y tiempo para realizar anotaciones. ¿Hay alguna manera de lograr una anotación rápida?
Dado que LLM puede generar todo, es factible permitir que LLM genere consultas y verdad sobre el terreno basada en documentos de conocimiento. Por ejemplo, existen algunos métodos integrados en la generación de datos de prueba sintéticos de ragas y en QuestionGeneration de llama-index, que se pueden usar directa y convenientemente.
Echemos un vistazo al efecto generado en base a documentos de conocimiento en ragas:

Preguntas y respuestas generadas a partir de documentos de conocimiento ( https://docs.ragas.io/en/latest/concepts/testset_generación.html)
Como puede ver, la figura anterior genera muchas preguntas de consulta y sus respuestas correspondientes, incluidas las fuentes de contexto correspondientes. Para garantizar la diversidad de preguntas generadas, también puede elegir la proporción de varios tipos de preguntas generadas, como la proporción de preguntas simples y preguntas de razonamiento.
De esta manera, podemos utilizar fácil y directamente estas preguntas generadas y la verdad sobre el terreno para evaluar cuantitativamente una aplicación RAG. Ya no necesitamos conectarnos a Internet para encontrar varios conjuntos de datos de referencia. De esta manera, también podemos evaluar datos privados o internos. dentro de la empresa.
03. Método de evaluación de caja blanca
Tubería RAG en condiciones de caja blanca
Al observar las aplicaciones RAG desde una perspectiva de caja blanca, podemos ver el proceso de implementación interna de RAG. Tomando como ejemplo el proceso de solicitud común de RAG, algunos componentes clave incluyen el modelo de integración, el modelo de reclasificación y el LLM. Algunos RAG tienen capacidades de recuperación multicanal y también pueden tener algoritmos de búsqueda de frecuencia de términos. Obviamente, probar estos componentes clave también puede reflejar la efectividad de la canalización RAG en un determinado paso. Reemplazar y actualizar estos componentes clave también puede brindar un mejor rendimiento a las aplicaciones RAG.
A continuación presentamos cómo evaluar estos 3 componentes clave típicos:
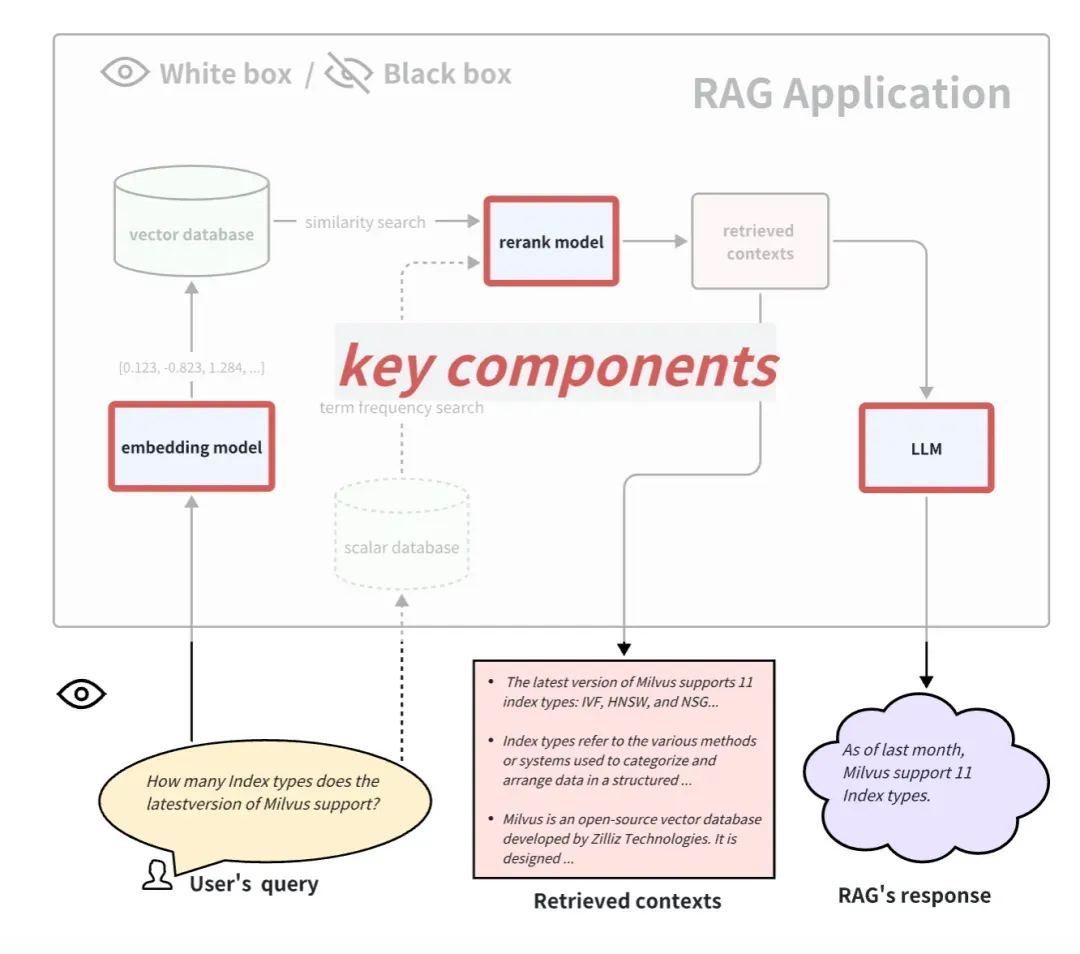
Cómo evaluar el modelo de incrustación y reclasificar el modelo
El modelo de incrustación y el modelo de reclasificación trabajan juntos para completar la función de recuperación de documentos relacionados. Arriba, presentamos el indicador de relevancia del contexto, que se puede utilizar para evaluar la relevancia de los documentos retirados. Pero, en general, para conjuntos de datos con Ground-truth, la gente suele utilizar algunos indicadores deterministas en el campo de la recuperación y el recuerdo de información para medir el efecto del recuerdo. En comparación con los indicadores de relevancia del contexto basados en LLM, estos indicadores son más rápidos, más baratos y más deterministas de calcular (pero deben proporcionar contextos reales).
Indicadores comúnmente utilizados para la recuperación de información.
En el campo de la recuperación y recuperación de información, los indicadores comúnmente utilizados incluyen indicadores que consideran la clasificación e indicadores que no consideran la clasificación.
El índice que considera la clasificación es sensible a la clasificación de los documentos de verdad sobre el terreno recuperados entre todos los documentos retirados. Es decir, cambiar el orden de correlación entre todos los documentos retirados hará que la puntuación de este índice cambie independientemente de los indicadores de clasificación. son todo lo contrario.
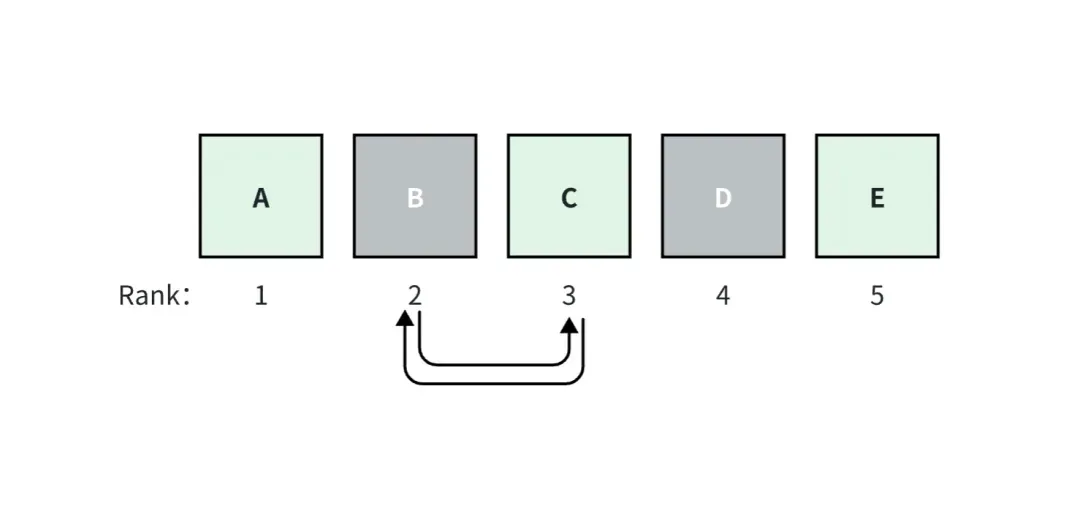
Por ejemplo, en la figura anterior, asumimos que la aplicación RAG recupera top_k=5 documentos, entre los cuales los documentos A, C y E son verdaderos sobre el terreno. El documento A ocupa el puesto 1, tiene la puntuación de relevancia más alta y las puntuaciones disminuyen hacia la derecha.
Si se intercambian los documentos B y C, las puntuaciones de las métricas que se consideran para la clasificación cambiarán, pero las puntuaciones de las métricas que no se consideran para la clasificación no cambiarán.
A continuación se muestran algunos indicadores específicos comunes:
Indicadores que no tienen en cuenta los rankings
-
Recuperación de contexto: la medida en que el sistema ha recuperado por completo todos los documentos necesarios.
-
Precisión del contexto: qué tan bien el sistema recupera la señal (en comparación con el ruido).
Métricas consideradas para la clasificación
-
La precisión promedio (AP) mide todos los bloques relevantes recuperados y calcula una puntuación ponderada. El promedio de AP sobre un conjunto de datos a menudo se denomina MAP.
-
El rango recíproco (RR) mide dónde aparece el primer bloque relevante en su búsqueda. El promedio de RR sobre un conjunto de datos a menudo se denomina MRR.
-
La ganancia acumulativa descontada normalizada (NDCG) tiene en cuenta el caso en el que su clasificación de correlación no es binaria.
El punto de referencia de evaluación más convencional: MTEB
Massive Text Embedding Benchmark (MTEB) es un punto de referencia integral diseñado para evaluar el rendimiento de los modelos de incrustación de texto en una variedad de tareas y conjuntos de datos. MTEB cubre 8 tareas de incrustación, incluida la minería bilingüe (Bitext Mining), clasificación, agrupación, clasificación por pares, reordenación, recuperación, similitud de texto semántico (STS) y resumen. Cubre un total de 58 conjuntos de datos en 112 idiomas, lo que lo convierte en uno de los puntos de referencia de incorporación de texto más completos hasta la fecha.
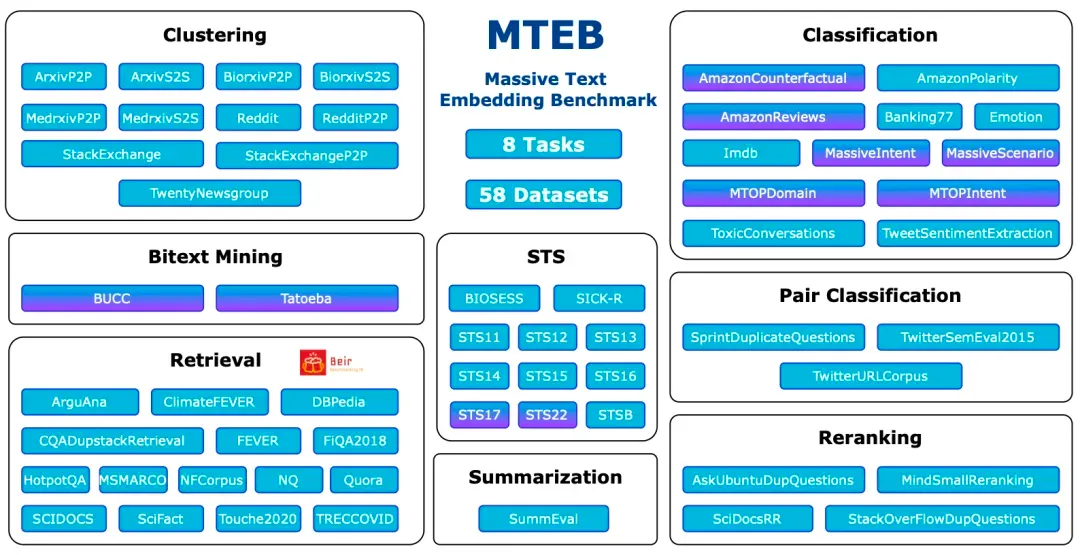
MTEB: Punto de referencia de incrustación de texto masivo
https://arxiv.org/abs/2210.07316
Se puede ver que MTEB contiene tareas de recuperación y tareas de reclasificación. Al evaluar modelos de incrustación y reclasificación en aplicaciones RAG, concéntrese en los modelos con puntuaciones más altas en estas dos tareas. En las recomendaciones del documento MTEB ( https://arxiv.org/abs/2210.07316), para el modelo Embedding, NDCG es el indicador más importante y para el modelo Rerank, MAP es el indicador más importante.
En HuggingFace, MTEB es la tabla de clasificación a la que todos prestan gran atención. Sin embargo, dado que el conjunto de datos es público, es posible que algunos modelos lo hayan sobreajustado hasta cierto punto, lo que degradará el rendimiento del conjunto de datos real. Por lo tanto, al evaluar el efecto de recuperación, también es necesario prestar más atención al desempeño de la evaluación en conjuntos de datos personalizados con sesgo empresarial.
¿Cómo evaluar el LLM?
En general, el proceso de generación se puede evaluar directamente utilizando el indicador basado en LLM del paso del Contexto a la Respuesta presentado anteriormente, a saber, Fidelidad.
Pero para algunas pruebas de consulta relativamente simples, como aquellas en las que las respuestas estándar solo tienen algunas frases simples, también se pueden utilizar algunos indicadores clásicos. Por ejemplo, ROUGE-L Precision, Token Overlap Precision. Esta evaluación determinista también requiere un contexto de verdad sobre el terreno anotado.
ROUGE-L Precision mide la subsecuencia común más larga entre la respuesta generada y el contexto recuperado.
Precisión de superposición de tokens Calcula la precisión de la superposición de tokens entre la respuesta generada y el contexto recuperado.
Por ejemplo, los siguientes problemas relativamente simples aún se pueden evaluar utilizando indicadores como ROUGE-L Precision y Token Overlap Precision.
Question: How many Index types does the latest version of Milvus support?
Reply: As of last month, Milvus support 11 Index types.
Ground-truth Context: In this version, Milvus support 11 Index types.
Sin embargo, cabe señalar que estos indicadores no son adecuados en escenarios RAG con preguntas complejas. En este caso, es necesario utilizar indicadores basados en LLM para la evaluación. Por ejemplo, preguntas abiertas como las siguientes:
Question: Please design a text search application based on the features of the latest version of Milvus and list the application usage scenarios.
04. Introducción a las herramientas de evaluación de uso común.
En la actualidad, han surgido herramientas profesionales en la comunidad de código abierto y los usuarios pueden utilizarlas para facilitar y realizar rápidamente evaluaciones cuantitativas. A continuación presentamos las herramientas de evaluación RAG actualmente comunes y fáciles de usar y algunas de sus características.
Ragas ( https://docs.ragas.io/en/latest/getstarted/index.html ): Ragas es una herramienta enfocada en evaluar aplicaciones RAG. La evaluación se puede lograr a través de una interfaz simple. Los indicadores de Ragas son ricos en variedad y no tienen requisitos en el marco de aplicación de RAG. También puede monitorear el proceso de cada evaluación a través de langsmith ( https://www.langchain.com/langsmith) para ayudar a analizar los motivos de cada evaluación y observar el consumo de claves API.
Evaluación continua ( https://docs.relari.ai/v0.3) : Continuous-eval es un paquete de software de código abierto para evaluar las canalizaciones de aplicaciones LLM, con un enfoque en las canalizaciones de recuperación de generación aumentada (RAG). Proporciona una opción de evaluación más económica y rápida. Además, permite la creación de canales de evaluación de conjuntos confiables y con garantías matemáticas.
TruLens-Eval: Trulens-Eval es una herramienta que se utiliza específicamente para evaluar indicadores RAG. Tiene una integración relativamente buena con LangChain y Llama-Index y se puede utilizar fácilmente para evaluar aplicaciones RAG creadas por estos dos marcos. Además, Trulens-Eval también puede iniciar una página en el navegador para monitoreo visual, ayudando a analizar los motivos de cada evaluación y observar el consumo de claves API.
Llama-Index: Llama-Index es muy adecuado para crear aplicaciones RAG, su ecología actual es relativamente rica y actualmente se encuentra en un rápido desarrollo iterativo. También incluye la función de evaluar RAG y generar conjuntos de datos sintéticos. Los usuarios pueden evaluar fácilmente las aplicaciones RAG creadas por el propio Llama-Index.
Además, existen algunas herramientas de evaluación cuyas funciones son similares a las mencionadas anteriormente. Por ejemplo, Phoenix ( https://docs.arize.com/phoenix ), DeepEval (https://github.com/confident-ai/deepeval), LangSmith, OpenAI Evals ( https://github.com/openai/ evaluaciones). El desarrollo iterativo de estas herramientas de evaluación también es muy rápido. Para funciones y métodos de uso específicos, puede consultar los documentos oficiales correspondientes.
05. Resumen
Para los usuarios y desarrolladores de aplicaciones RAG, en la práctica es crucial evaluar el rendimiento de las aplicaciones RAG. Este artículo presentará el método de evaluación cuantitativa de aplicaciones RAG desde la perspectiva de la caja negra y la caja blanca, y presentará algunas herramientas de evaluación prácticas, con el objetivo de ayudar a los lectores a comprender rápidamente la tecnología de evaluación y comenzar rápidamente. Para obtener más información sobre RAG, consulte otros artículos de esta serie "Manual de cultivo de RAG | Un artículo que explica la tecnología detrás de RAG" "Manual de cultivo de RAG | ¿Es RAG la sentencia de muerte? ¿El contexto largo del modelo grande significa que la recuperación de vectores ya no es importante?
Linus tomó el asunto en sus propias manos para evitar que los desarrolladores del kernel reemplacen las pestañas con espacios. Su padre es uno de los pocos líderes que puede escribir código, su segundo hijo es el director del departamento de tecnología de código abierto y su hijo menor es un núcleo. Colaborador de código abierto Huawei: tomó 1 año convertir 5000 aplicaciones móviles de uso común Migración completa a Hongmeng Java es el lenguaje más propenso a vulnerabilidades de terceros Wang Chenglu, el padre de Hongmeng: el código abierto Hongmeng es la única innovación arquitectónica. En el campo del software básico en China, Ma Huateng y Zhou Hongyi se dan la mano para "eliminar rencores". Ex desarrollador de Microsoft: el rendimiento de Windows 11 es "ridículamente malo " " Aunque lo que Laoxiangji es de código abierto no es el código, las razones detrás de él. Son muy conmovedores. Meta Llama 3 se lanza oficialmente. Google anuncia una reestructuración a gran escala.