
Compartidor: Zeng Qingguo |Escuela: Universidad de Ciencia y Tecnología del Sur
breve introducción
La desaceleración de la Ley de Moore ha promovido el desarrollo de paradigmas informáticos no tradicionales, como máquinas Ising personalizadas diseñadas específicamente para resolver problemas de optimización combinatoria. Esta sesión presentará nuevas aplicaciones de máquinas Ising basadas en bits P para entrenar redes neuronales generativas profundas, utilizando máquinas Ising dispersas, asíncronas y altamente paralelas para entrenar redes Boltzmann profundas en un entorno de computación mixta probabilística y clásica.
Artículos relacionados
标题:Entrenamiento de redes Boltzmann profundas con máquinas Ising dispersas
作宇:**Shaila Niazi, Navid Anjum Aadit, Masoud Mohseni, Shuvro Chowdhury, Yao Qin, Kerem Y. Camsari
01
Propósito del artículo
Objetivo: demostrar cómo entrenar de manera eficiente versiones dispersas de redes Boltzmann profundas utilizando sistemas de hardware especializados (por ejemplo, P-bit) que brindan una aceleración de órdenes de magnitud sobre implementaciones de software comúnmente utilizadas en tareas de muestreo de probabilidad computacional estricta;
Objetivo a largo plazo: ayudar a facilitar el desarrollo de hardware probabilístico inspirado en la física para reducir el costo en rápido crecimiento del aprendizaje profundo tradicional basado en gráficos y unidades de procesamiento tensorial (GPU/TPU);
Dificultades en la implementación del hardware:
1. Los p-bits conectados deben actualizarse en serie y las actualizaciones están prohibidas en sistemas densos.
2. Asegúrese de que el p-bit reciba toda la información más reciente de sus nodos vecinos antes de actualizar; de lo contrario, la red no lo hará; Muestreo a partir de una verdadera distribución de Boltzmann.
02
contenido principal
El contenido del entrenamiento de redes profundas de Boltzmann utilizando máquinas Ising dispersas se divide principalmente en cuatro partes:
1. Estructura de la red
2. Función objetivo
3. Optimización de parámetros
4. Inferencia (clasificación y generación de imágenes)
1. Estructura de red
Las topologías de Pegasus y Zepyhr desarrolladas por D-Wave se utilizan para entrenar redes profundas dispersas con reconocimiento de hardware. Esta operación está inspirada en redes extendidas pero con conexiones limitadas, como el cerebro humano y los microprocesadores avanzados. A pesar del uso ubicuo de la conectividad total en los modelos de aprendizaje automático, tanto los microprocesadores avanzados como los cerebros humanos con miles de millones de redes de transistores exhiben un alto grado de escasez. De hecho, la mayoría de las implementaciones de hardware de RBM enfrentan problemas de escalamiento debido a la alta responsabilidad computacional requerida por cada nodo, mientras que las conexiones escasas en las redes neuronales de hardware a menudo muestran ventajas. Además, la escasa estructura de la red resuelve bien las dificultades de implementación de hardware mencionadas anteriormente.
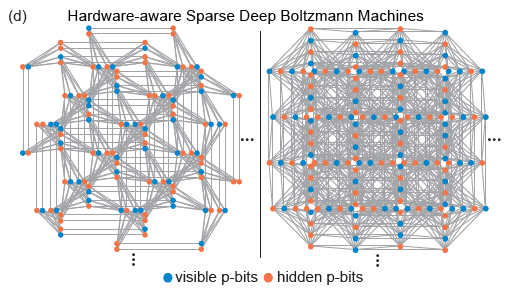
(Fuente de la imagen: arXiv:2303.10728)
2. Función objetivo
Maximizar la función de verosimilitud equivale a minimizar la divergencia KL entre la distribución de datos y la distribución del modelo:
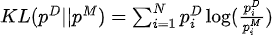
Entre ellos, 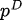 está la distribución de datos y
está la distribución de datos y 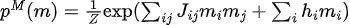 la distribución del modelo.
la distribución del modelo.
El gradiente de divergencia de KL con respecto a los parámetros del modelo ( 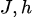 ) es:
) es:
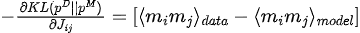
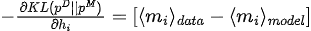
3. Optimización de parámetros

(Fuente de la imagen: arXiv:2303.10728)
Parámetros de la red de trenes según el algoritmo 1, incluidos
-
Inicialización de parámetros de inicialización (
 , );
, );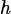
-
Utilice los datos de entrenamiento para asignar valores a los bits p de la capa de entrada y luego realice un muestreo MC para obtener muestras de muestreo de la distribución de datos;
-
Realice directamente un muestreo de MC para obtener muestras de muestreo de la distribución del modelo;
-
El gradiente (llamado divergencia contrastiva persistente) se estima utilizando muestras muestreadas en dos etapas y los parámetros se actualizan utilizando el método de descenso de gradiente.
Entre ellos, el muestreo MC utiliza evolución iterativa de p-bits:

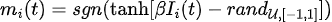
En el proceso de entrenamiento de redes dispersas de Boltzmann, hay dos puntos a tener en cuenta:
-
1) Índice de p-bits aleatorio
Al entrenar un modelo de red de Boltzmann en una red dispersa determinada, la distancia del gráfico entre los nodos visibles, ocultos y de etiquetas es un concepto muy importante. Normalmente, si la capa está completamente conectada, la distancia del gráfico entre dos nodos dados es constante, pero este no es el caso para los gráficos dispersos, por lo que las posiciones de los bits p visibles, ocultos y de etiqueta parecen extraordinariamente importantes. Si los bits p visibles, ocultos y de etiqueta están agrupados y demasiado cerca, la precisión de la clasificación se verá muy afectada. Lo más probable es que esto se deba a que si la distancia gráfica entre los bits de etiqueta y los bits visibles es demasiado grande, la correlación entre ellos se vuelve más débil. La aleatorización del índice de p-bits puede aliviar este problema. -
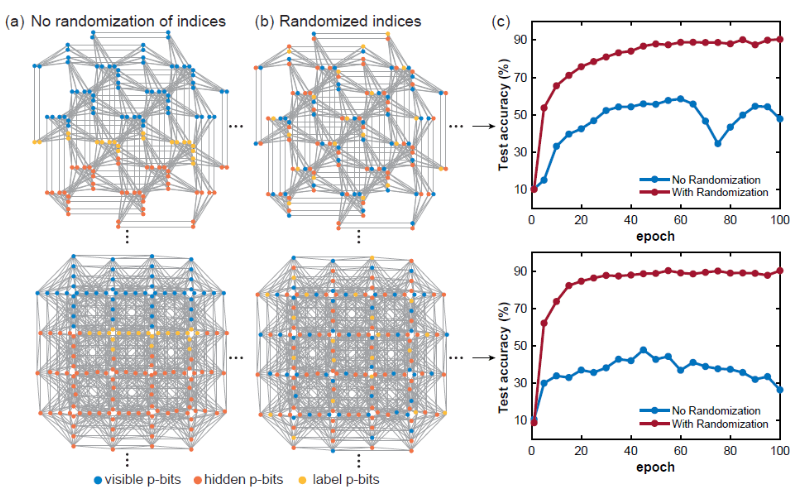
-
(Fuente de la imagen: arXiv:2303.10728)
**2)大规模并行**
在稀疏深度玻尔兹曼网络上,我们使用启发式图着色算法DSatur对图着色,对于未连接p-bits进行并行更新。
-
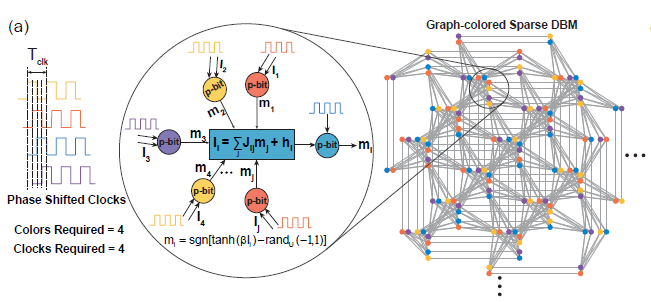
-
(Fuente de la imagen: arXiv:2303.10728)
4. Inferencia
Clasificación: utilice datos de prueba para corregir los p-bits visibles, luego realice un muestreo de MC y luego obtenga las expectativas para los pbits de etiqueta obtenidos y tome la etiqueta con el valor esperado más grande como etiqueta predicha.
-
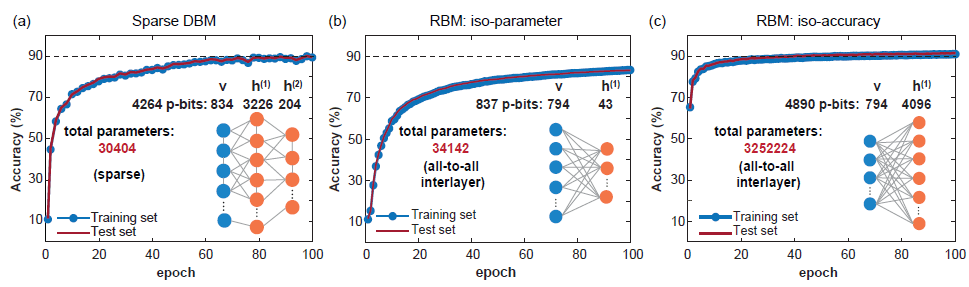
-
(Fuente de la imagen: arXiv:2303.10728)
Generación de imágenes: fije los bits p de la etiqueta a la codificación correspondiente a la etiqueta que desea generar, luego realice el muestreo MC y recoja la red durante el proceso de muestreo (aumentando gradualmente de 0 a 5 en pasos de 0,125), y el resultado las muestras corresponden a Los p-bits visibles son las imágenes generadas.
-

-
(Fuente de la imagen: arXiv:2303.10728)
03
Resumir
El artículo utiliza una máquina Ising dispersa con una arquitectura masivamente paralela, que alcanza velocidades de muestreo órdenes de magnitud más rápidas que las CPU tradicionales. El artículo estudia sistemáticamente el tiempo de mezcla de topologías de red con reconocimiento de hardware y muestra que la precisión de clasificación del modelo no está limitada por la operabilidad computacional del algoritmo, sino por la FPGA de tamaño moderado que se pudo utilizar en este trabajo. Otras mejoras pueden implicar el uso de arquitecturas de red más profundas, más amplias y posiblemente "más difíciles de mezclar" que aprovechen al máximo los muestreadores probabilísticos ultrarrápidos. Además, combinar la tecnología de entrenamiento capa por capa del DBM tradicional con el método del artículo puede aportar posibles mejoras adicionales. La implementación de máquinas Ising dispersas que utilizan dispositivos a nanoescala, como uniones de túneles magnéticos aleatorios, puede cambiar el estado actual de las aplicaciones prácticas de las redes profundas de Boltzmann.
Un programador nacido en los años 90 desarrolló un software de portabilidad de vídeo y ganó más de 7 millones en menos de un año. ¡El final fue muy duro! Google confirmó despidos, relacionados con la "maldición de 35 años" de los codificadores chinos en los equipos Python Flutter Arc Browser para Windows 1.0 en 3 meses oficialmente GA La participación de mercado de Windows 10 alcanza el 70%, Windows 11 GitHub continúa disminuyendo. GitHub lanza la herramienta de desarrollo nativo de IA GitHub Copilot Workspace JAVA. es la única consulta de tipo fuerte que puede manejar OLTP + OLAP. Este es el mejor ORM. Nos encontramos demasiado tarde.