El llamado mecanismo de atención es un mecanismo que se enfoca en información local, como un área de imagen determinada en una imagen. Las regiones atencionales tienden a cambiar a medida que cambian las tareas. El mecanismo de atención es una técnica comúnmente utilizada en el aprendizaje profundo. Cuando usamos una red neuronal convolucional para procesar imágenes, esperamos que la red neuronal convolucional pueda prestar atención a lugares relativamente importantes. El mecanismo de atención es una forma de realizar la atención adaptativa de la red.
Los mecanismos de atención generalmente se pueden dividir en atención de canal y atención espacial, o una combinación de las dos.
1. Canal de Atención (SENet)
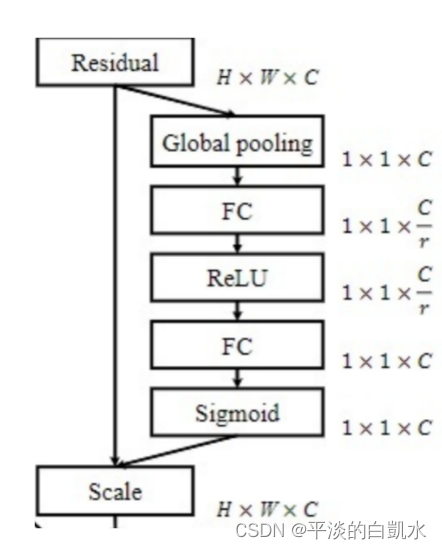
La atención del canal se preocupa por el peso de cada canal destacado, lo que permite que la cadena se centre en el canal al que debe prestar más atención. La figura anterior muestra sus pasos de implementación específicos, y hay 6 pasos de la siguiente manera:
1) Realice una agrupación global (máximo/promedio) en el mapa de características de entrada de HxWxC, y se puede obtener una franja de características de 1x1xC, y la longitud es el número de canales C del mapa de características de entrada;
2) Luego realice una conexión completa, reduzca la dimensión a la dimensión C/r con menos neuronas y obtenga un vector 1x1XC/r;
3) función de activación ReLu;
4) La segunda conexión completa restaura la longitud del vector a la misma que antes, es decir, el vector de 1x1xC;
5) La función Sigmoid normaliza cada peso entre 0-1;
6) Cada canal del mapa de características de entrada se multiplica por el peso de cada canal para obtener un nuevo mapa de características.
El código de implementación es el siguiente (la agrupación máxima y promedio se usan en el código y finalmente se agregan):
import torch
import torch.nn as nn
import torch.utils.data as Data
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x): # x 的输入格式是:[B, C, H, W]
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
2. Atención espacial
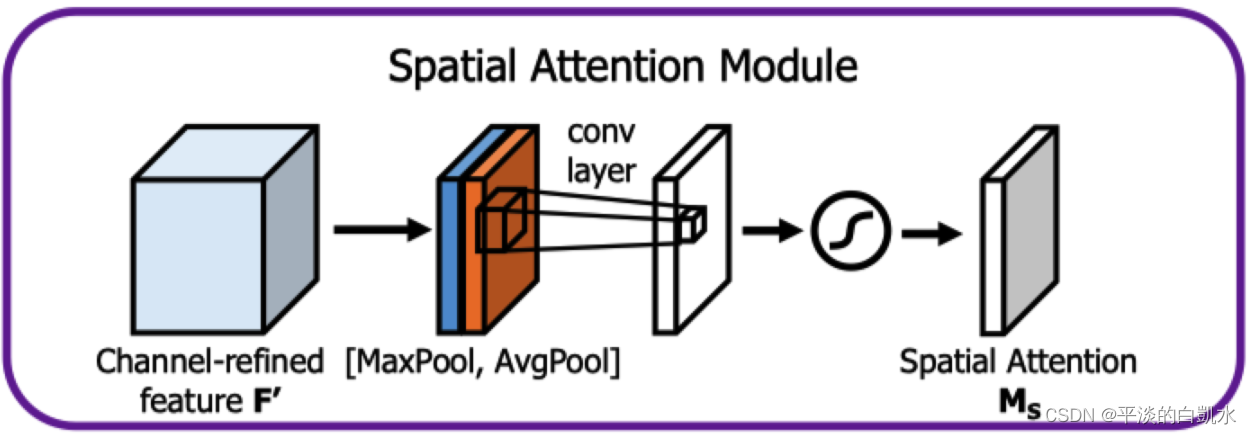
La atención espacial se preocupa por el peso de cada parte en la superficie.Los pasos específicos de implementación son los siguientes:
1) Para cada posición del mapa de características de entrada HxWxC, tome el valor máximo de todos los canales y se puede obtener un mapa de características HxWx1;
2) Para cada posición del mapa de características de entrada de HxWxC, tome el valor promedio de todos los canales y también obtenga un mapa de características de HxWx1;
3) Apilar (concatenar) los dos mapas de funciones para obtener el mapa de funciones de HxWx2, realizar una convolución para ajustar el número de canales a 1 y obtener el mapa de funciones de HxWx1;
4) La función Sigmoid normaliza el peso de cada posición entre 0-1;
5) Cada posición del mapa de características de entrada se multiplica por el peso de cada posición para obtener un nuevo mapa de características.
El código de implementación es el siguiente:
import torch
import torch.nn as nn
import torch.utils.data as Data
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x): # x 的输入格式是:[B, C, H, W]
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
3. Realización de CBAM
CBAM combina el mecanismo de atención de canales y el mecanismo de atención espacial, que puede lograr mejores resultados que el mecanismo de atención de SENet que solo se enfoca en canales. El diagrama esquemático de su implementación se muestra a continuación. CBAM procesará el mecanismo de atención del canal y el mecanismo de atención espacial para la capa de características de entrada.
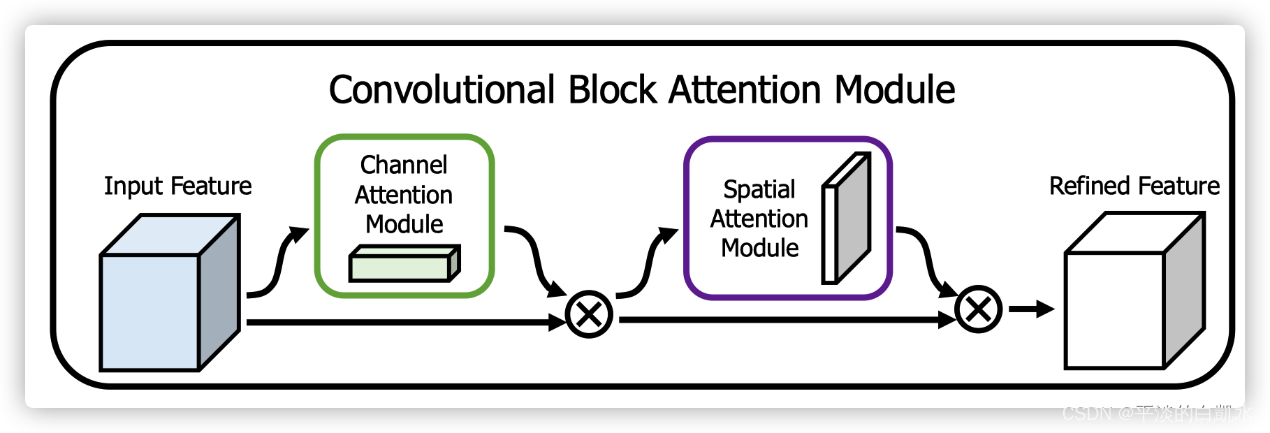
Diseño de módulos de atención: Dada una imagen de entrada, dos módulos de atención, canal y espacio, calculan la atención complementaria, enfocándose en "qué" y "dónde", respectivamente. Teniendo esto en cuenta, ambos módulos se pueden colocar de forma paralela o secuencial. Los autores del artículo original encontraron que las permutaciones secuenciales dieron mejores resultados que las permutaciones paralelas.
El código de implementación es el siguiente:
class cbam_block(nn.Module):
def __init__(self, channel, ratio=8, kernel_size=7):
super(cbam_block, self).__init__()
self.channelattention = ChannelAttention(channel, ratio=ratio)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
x = x * self.channelattention(x)
x = x * self.spatialattention(x)
return x