
Esta cita de Charity Majors probablemente resume mejor el estado actual de observabilidad en la industria tecnológica: un caos total y masivo. Todo el mundo está confundido. ¿Qué es el rastro? ¿Qué es lapso? ¿Es una línea de registro un tramo? Si tengo registros, ¿todavía necesito realizar un seguimiento? Si tengo buenas métricas, ¿por qué necesito seguimiento? La lista sigue y sigue. Charity, junto con otras grandes mentes de los sistemas observables Honeycomb , ha estado trabajando arduamente para resolver estos problemas. Sin embargo, según mi propia experiencia, todavía es difícil explicar qué quiere decir Charity cuando dice que "los registros son basura", y mucho menos que el registro y el rastreo son esencialmente lo mismo. ¿Por qué todos están tan confundidos?
Con un ligero riesgo, voy a culpar a Open Telemetry. Sí, es el centro neurálgico de la observabilidad moderna, pero lo culpo por el desorden. Eso no es porque sea una mala solución: ¡es brillante! Sin embargo, su introducción y explicación de los conceptos y funciones de Open Telemetry hacen que la observabilidad parezca engañosa y complicada.
Primero, Open Telemetry distingue claramente entre seguimientos, métricas y registros desde el principio:
OpenTelemetry es una colección de API, SDK y herramientas. Úselo para instrumentar, generar, recopilar y exportar datos de telemetría (métricas, registros y seguimientos) para ayudarlo a analizar el rendimiento y el comportamiento de su software.
Luego explique cada una de estas 3 preguntas con más profundidad.
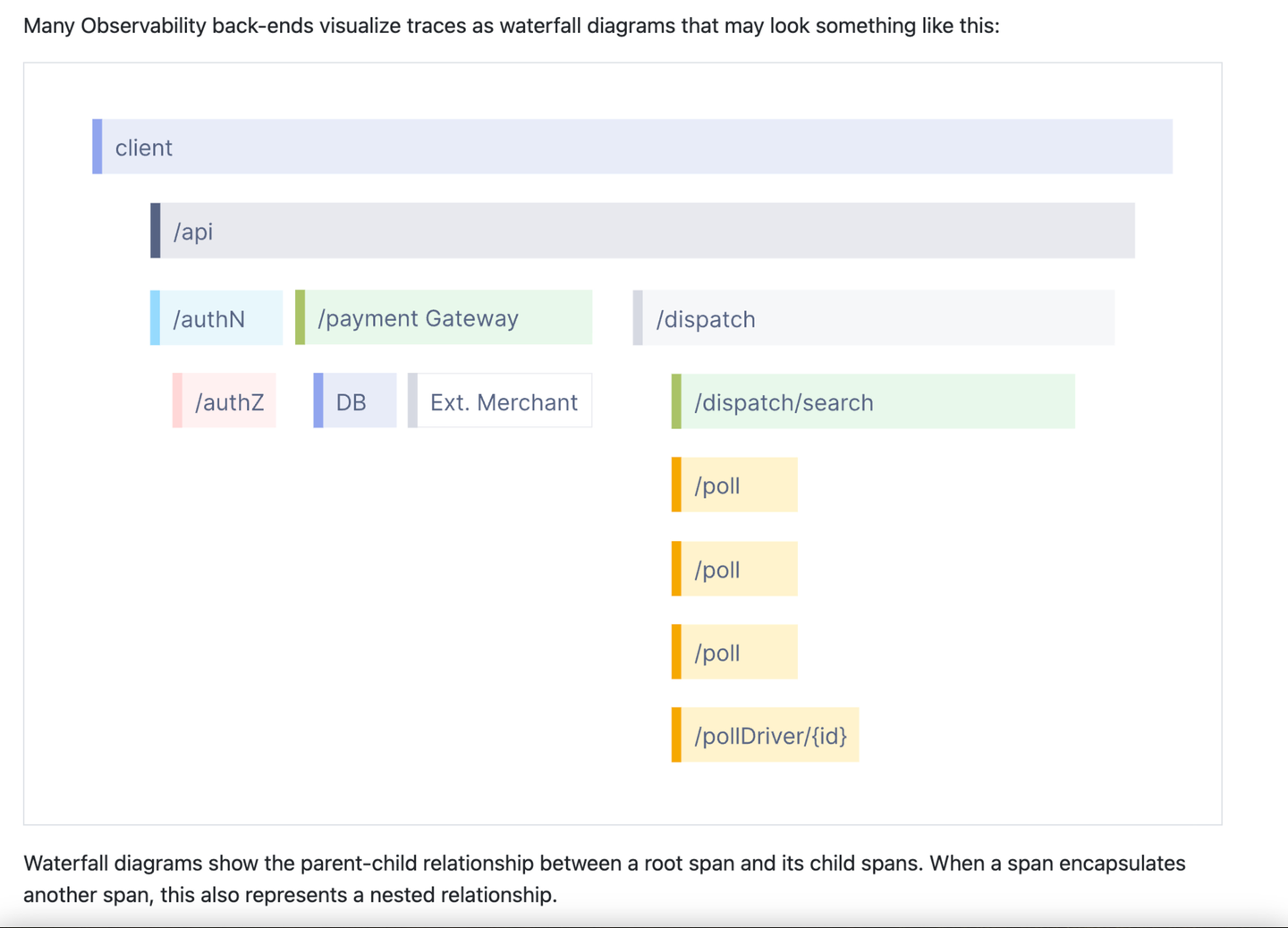
Esta es una captura de pantalla parcial de la introducción del seguimiento en el sitio web de OpenTelemetry. En mi experiencia hablando con el personal de OpenTelemetry, esta presentación realmente se ha convertido en una de las imágenes principales relacionadas con la observabilidad. Para algunos, esto es observabilidad. También distingue el rastro de cualquier otra cosa. Obviamente esto no es un registro, ¿verdad? Esto tampoco parece un indicador, ¿verdad? Esto es algo especial, tal vez un poco asombroso, y requiere dedicación para aprender. En mi experiencia, una vez que las personas entienden los rastros, solo piensan en ellos en el contexto de esta imagen y en términos relacionados como intervalo, intervalo raíz, intervalo anidado, etc. ¡El sitio web OpenTelemetry tiene una página de glosario con más de 60 términos ! ¡Es todo extremadamente complicado!
Pero lo más importante es que este enfoque en “registros, métricas y seguimientos de enlaces” ¿representa el verdadero poder de la observabilidad? Claro, cubre algunos escenarios, pero cuando se trata de sistemas distribuidos a gran escala, es más importante poder profundizar en los datos: "cortarlos en pedazos", construir y analizar varias vistas, hacer correlaciones. Análisis sexual, buscando anomalías... y existen sistemas que proporcionan todas estas capacidades.
Buceo: paraíso de la observabilidad
Cuando trabajé en Meta, no me di cuenta de que tenía la suerte de trabajar con el mejor sistema de observabilidad jamás creado. Este sistema se llama Scuba y es lo que más extraña la gente después de dejar Meta Corporation.
La idea básica de Scuba es lo suficientemente simple como para que no sea necesario leer páginas de terminología para comprenderla. Utiliza eventos amplios. Un evento generalizado es simplemente una colección de campos con nombres y valores, como un documento JSON. Si necesita registrar alguna información, ya sea el estado actual del sistema o causado por una llamada API, un trabajo en segundo plano u otro evento, simplemente escriba algunos eventos generalizados en Scuba. Por ejemplo, si un sistema ofrece publicidad, naturalmente querrá registrar las impresiones de los anuncios, es decir, el hecho de que un usuario vio un anuncio. El evento generalizado correspondiente podría verse así:
{
"Timestamp": "1707951423",
"AdId": "542508c92f6f47c2916691d6e8551279”,
"UserCountry": "US",
"Placement": "mobile_feed",
"CampaingType": "direct_ads",
"UserOS": "Android",
"OSVersion": "14",
"AppVersion": "798de3c28b074df9a24a479ce98302b6",
"...": ""
}Estos eventos se denominan eventos generalizados porque se fomenta que en ellos se almacene toda la información imaginable. Cualquier cosa que pueda ser relevante en el contexto de esos datos en particular, simplemente publíquela y podría ser útil más adelante. Este enfoque sienta las bases para abordar lo desconocido: cosas en las que no se puede pensar ahora y que podrían revelarse durante la investigación de un accidente.
Lidiar con situaciones desconocidas se puede ilustrar mejor con un ejemplo. Scuba tiene una interfaz intuitiva y fácil de usar que facilita su exploración y operación. Tiene una sección para seleccionar qué métricas ver y secciones para filtrar y agrupar: Scuba trazará un bonito gráfico de series temporales. Un primer vistazo al conjunto de datos de impresiones de anuncios simplemente trazará un gráfico que contiene el número de impresiones:
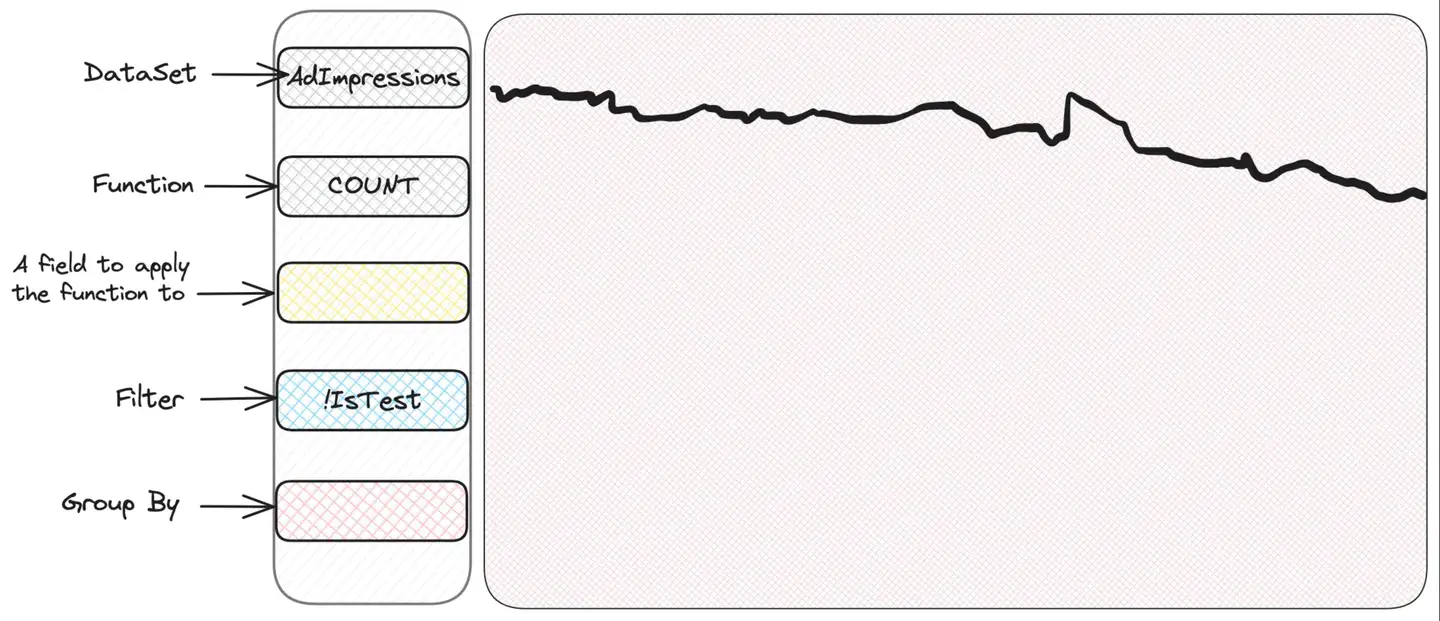
Si expresáramos en SQL qué se selecciona exactamente aquí, entonces esto sería así:
SELECT COUNT(*) FROM AdImpressions
WHERE IsTest = FalseEste no es del todo el caso. El buceo también presenta el concepto de muestreo nativo. Cuando se escribe un evento en Scuba, también se debe escribir un campo llamado , que representa la frecuencia de muestreo de este evento en particular. Scuba utiliza esta información para "acercar" correctamente los resultados mostrados en el gráfico, por lo que no es necesario hacer esta ampliación mentalmente. Este es un gran concepto porque permite el muestreo dinámico; por ejemplo, un determinado tipo de presentación puede muestrearse con más frecuencia que otro tipo de presentación, preservando al mismo tiempo los valores "reales" en la interfaz de usuario. Entonces la consulta real a continuación es: samplingRate
SELECT SUM(samplingRate) FROM AdImpressions
WHERE IsTest = False Tenga en cuenta que la interfaz de usuario realiza todo el "acercamiento" de forma transparente y el usuario no necesita pensar en ello durante la consulta. Entonces, digamos que ocurre alguna alerta y nuestro valioso gráfico de impresiones de anuncios se ve extraño:
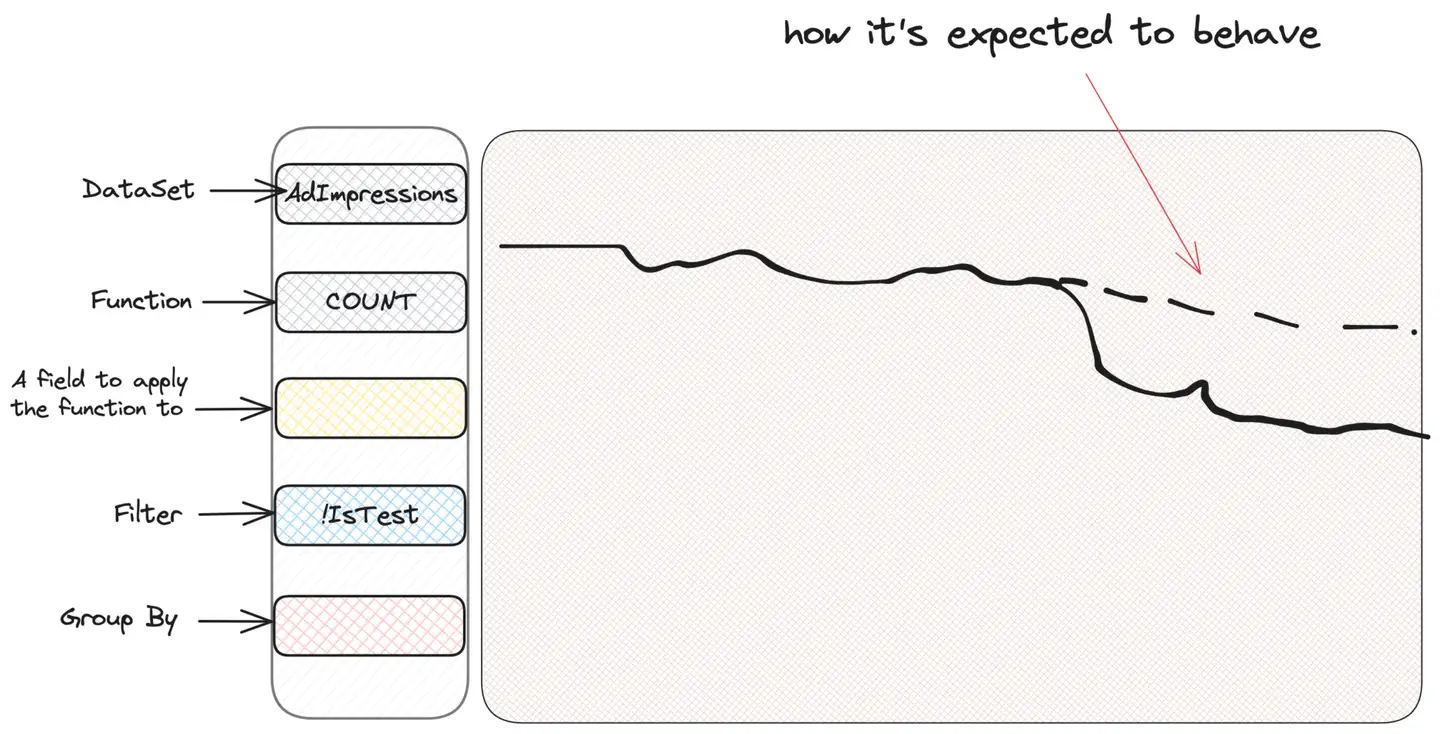
El primer instinto de cualquiera que utiliza Scuba para investigar es "cortar y cortar", es decir, filtrar o agrupar según criterios, para ver si pueden obtener alguna información. No sabemos lo que buscamos, pero creemos que lo encontraremos. Por lo tanto, agrupamos por tipo de impresión, país del usuario o ubicación del anuncio hasta que encontramos algo sospechoso. Supongamos agrupación por tipo de campaña (CampaignType):
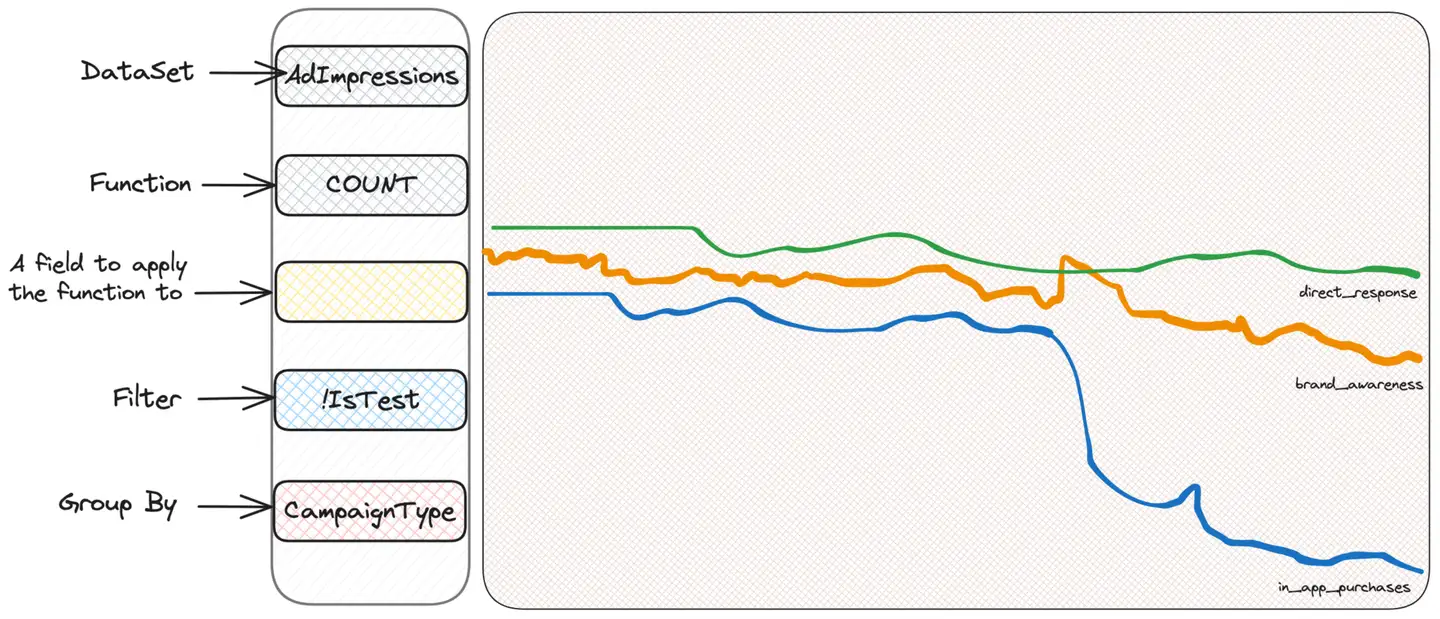
Descubrimos que un tipo de campaña llamada in_app_purchases (tenga en cuenta que esto lo inventé yo) parece ser diferente de los otros tipos. Realmente no sabemos lo que significa, ¡y no necesitamos saberlo! - Sólo tenemos que seguir investigando. Bien, ahora podemos filtrar solo estas campañas y continuar agrupándolas según otros criterios que se nos ocurran. Por ejemplo, el sistema operativo del usuario tiene sentido.
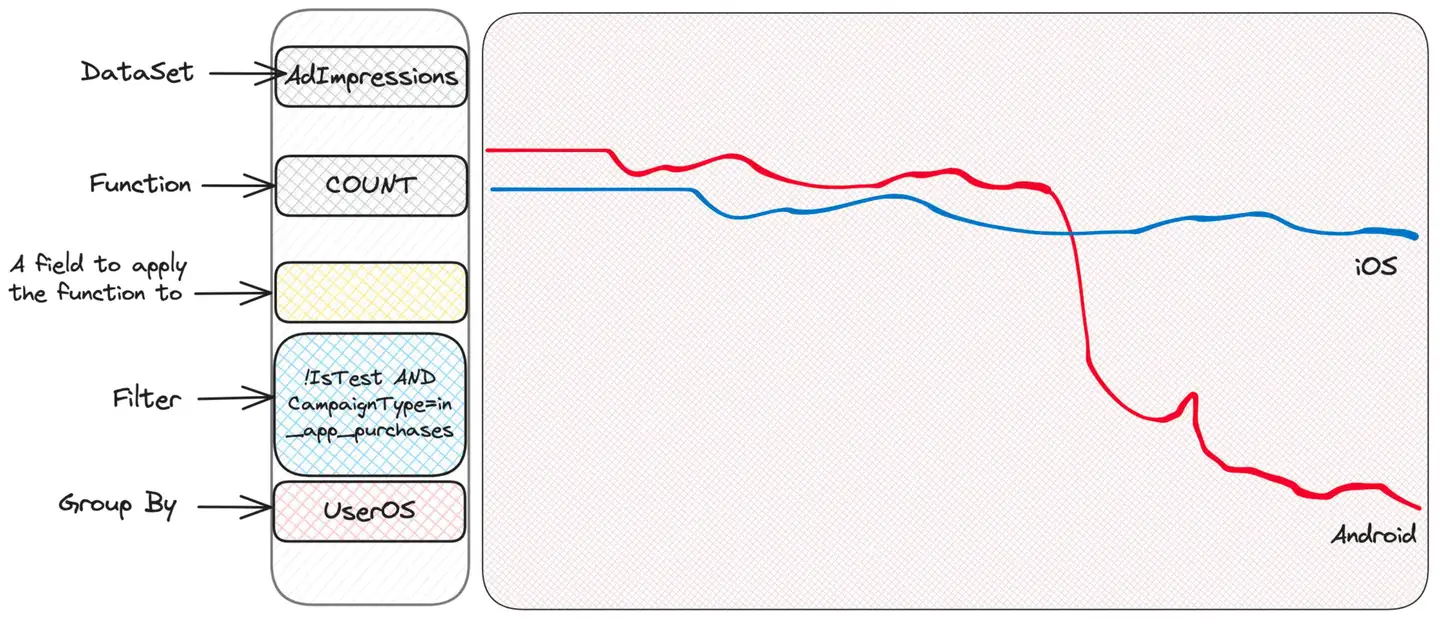
Bueno, parece que hay un problema con Android. iOS está bien, lo que sugiere que el problema puede estar en el lado del cliente, ¿tal vez una versión defectuosa de la aplicación?
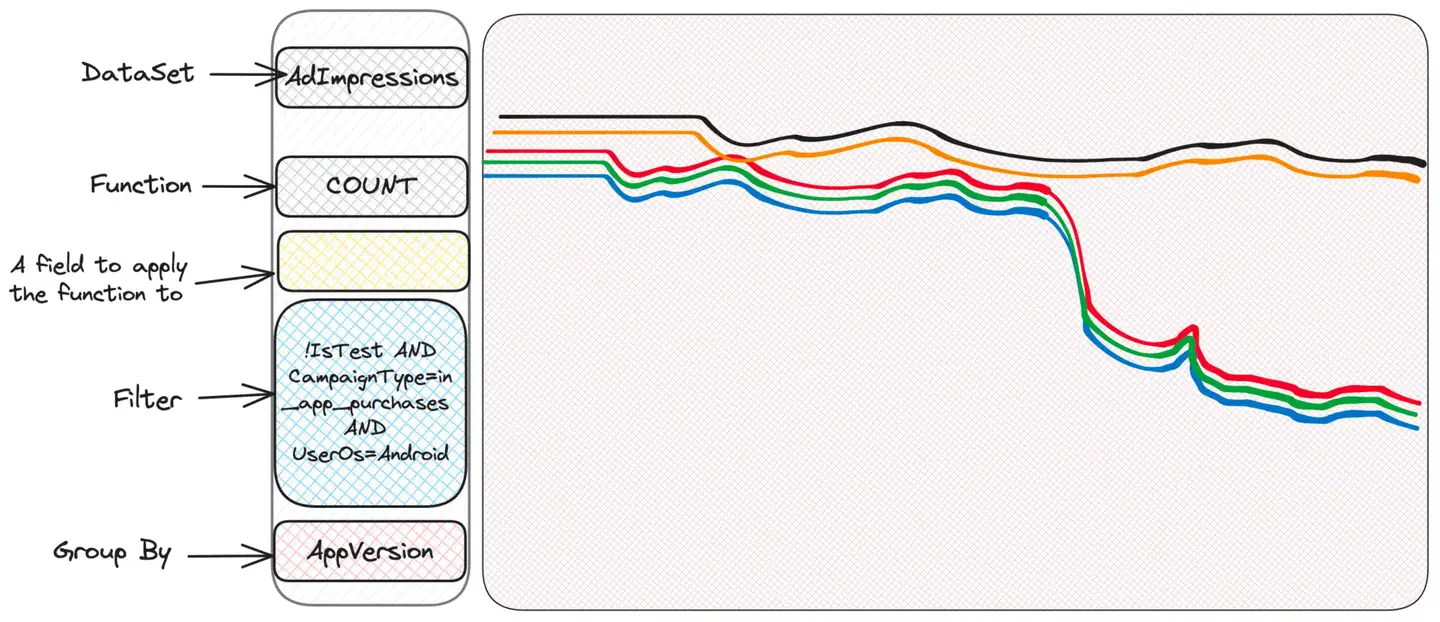
extrañeza. Algunas personas tienen problemas, otras no. ¿Quizás comprobar la versión del sistema operativo?
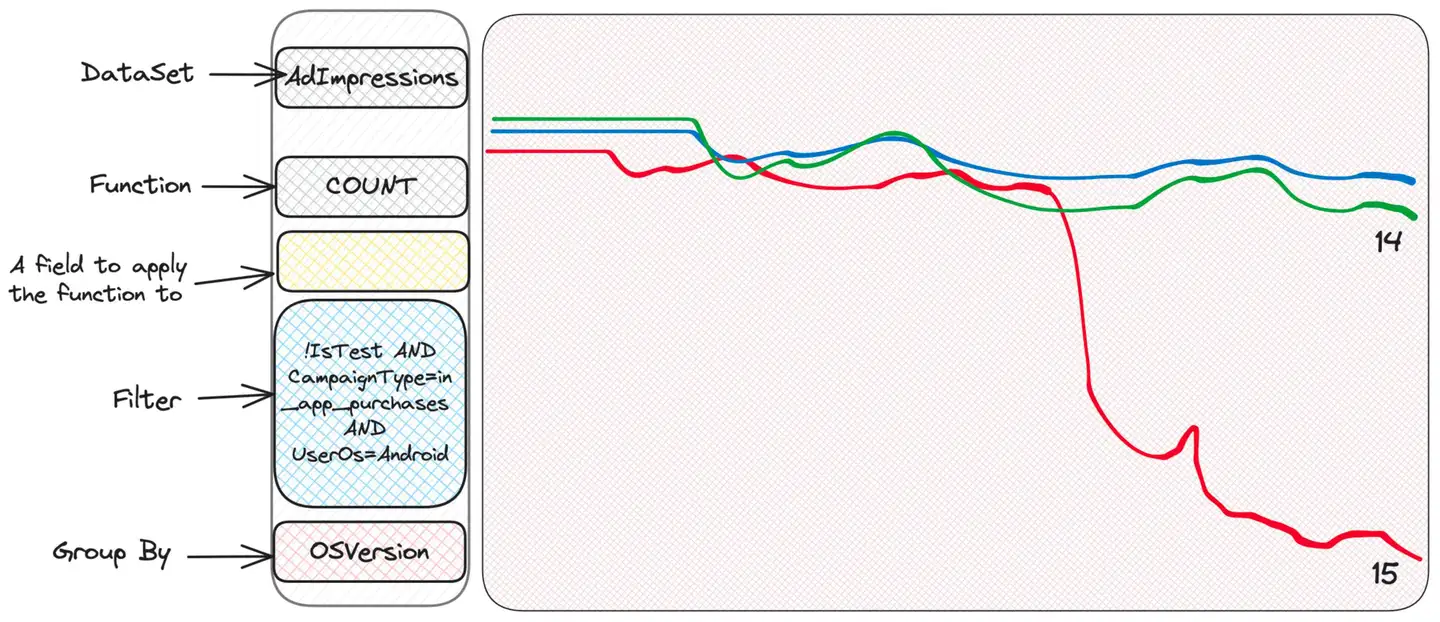
¡Ja! Esta es la última versión del sistema operativo y parece que algunas versiones de la aplicación no funcionan bien para este tipo de campaña en esta versión del sistema operativo. Dada esta información, el equipo dedicado ahora puede profundizar más.
¿qué pasó? Sin ningún conocimiento del sistema, hemos acotado el problema e identificado al equipo responsable de una mayor investigación. ¿Podríamos haber sabido de antemano que esta extraña combinación de sistema operativo, versión de sistema operativo, tipo de campaña y versión de aplicación podría causar algunos problemas y tener las métricas listas? Por supuesto que es imposible. Este es un ejemplo de cómo lidiar con incógnitas desconocidas. Simplemente almacenamos toda la información contextual relevante en eventos generalizados y los usamos cuando es necesario. Scuba facilita la exploración porque es rápido y tiene una interfaz de usuario muy bonita y fácil de usar. También tenga en cuenta que nunca mencionamos nada sobre la cardinalidad. Porque no importa: cualquier campo puede tener cualquier cardinalidad. Scuba opera con eventos sin procesar y no realiza agregación previa, por lo que la cardinalidad no es un problema.
A veces, el aspecto de la interfaz/visualización no recibe suficiente atención y el sistema de monitoreo proporciona algún lenguaje de consulta, tal vez propietario (una experiencia particularmente mala) o SQL (un poco mejor, pero aún no bueno). Una interfaz de este tipo haría casi imposible realizar una encuesta similar. Un aspecto importante de Scuba es que todos los campos (funciones, filtros, agrupaciones, etc.) son explorables. Dicho esto, existe una forma sencilla de ver los tipos de valores que podemos seleccionar. Cuando la persona a cargo de un determinado campo de datos hace un esfuerzo adicional para mejorar los datos de los que es responsable, va más allá de simplemente recopilar los datos: incluso proporciona una descripción detallada del campo determinado, incluidos enlaces relacionados. Esto es muy importante. Llevé a cabo con éxito la solución de problemas muchas veces sin comprender completamente el sistema en su totalidad o los datos disponibles en ese conjunto de datos. Y durante estos procesos de solución de problemas, aprendí mucho sobre el sistema simplemente interactuando con Scuba. Esto es increíble. Este es el paraíso de la observabilidad.
El dolor después de dejar Meta
Ahora imagine mi confusión e incredulidad cuando dejé Meta y me enteré del estado del sistema de observabilidad externo.

¿registro? ¿pista? ¿índice? ¿Qué es esto exactamente? ¿Alguien sabe sobre eventos generalizados? ¿No puedo aprender el glosario de 60 términos y simplemente... explorar cosas?
Pasé bastante tiempo mapeando el modelo mental basado en Scuba con el modelo mental de Telemetría Abierta. Me di cuenta de que el Span de Open Telemetry es en realidad un evento generalizado. En realidad, todavía no estoy muy seguro de haberlo entendido correctamente:

Si tomamos el ejemplo de una visualización publicitaria, esta visualización no es en realidad una operación, son sólo algunos hechos que queremos registrar... Para ser justos, el concepto de eventos sí existe en Open Telemetry:

Pero si seguimos el enlace y profundizamos más, encontramos nuevamente que el evento es en realidad uno de los seguimientos, métricas o registros.

Pero en cualquier caso, Span es el concepto más cercano a un evento generalizado. El problema es que es difícil defender el modelo mental propuesto por Open Telemetry cuando estás acostumbrado. Esto es realmente frustrante porque los seguimientos, las métricas y los registros son en realidad solo casos especiales de eventos generalizados:
- Traces y spans (Spans): Son simplemente eventos generalizados con los campos SpanId, TraceId y ParentSpanId. Por lo tanto, podemos filtrar todos los tramos con un TraceId determinado, ordenarlos topológicamente según la relación SpanId → ParentSpanId y dibujar la vista de seguimiento distribuida favorita de todos.
- Registros: Para ser honesto, estoy realmente confundido por lo que Open Telemetry llama registros. Parece que contiene muchas cosas, una de las cuales es el registro estructurado, que son básicamente eventos amplios. ¡Muy bien! El problema, sin embargo, es que "registro" es un concepto bastante bien definido y, por lo general, la gente se refiere a lo que producen esas llamadas. De todos modos, sea lo que sea que eso signifique, los registros pueden asignarse fácilmente a eventos amplios. En el caso más simple, simplemente tomamos el mensaje de registro, lo colocamos en el campo "log_message", agregamos un montón de metadatos y estamos satisfechos. En un caso más complejo, podríamos intentar extraer automáticamente una plantilla del mensaje de registro eliminando el token que parece una identificación y obtener el hash de esta plantilla. Esto nos permite obtener rápidamente los errores más frecuentes, por ejemplo, agrupando por este hash. Meta tiene un sistema como este y es genial.
logger.info(…) - Métricas: las métricas también se pueden asignar fácilmente. Solo necesitamos emitir un evento amplio que contenga el estado del sistema (como indicadores del sistema de CPU, varios contadores, etc.) dentro de un intervalo determinado. Por cierto, Prometheus hace exactamente esto mediante el método de raspado: tomando una instantánea ocasional del sistema. Sin embargo, a diferencia de Prometheus, al utilizar el enfoque de eventos amplios no necesitamos preocuparnos por cuestiones de cardinalidad.
Pero Wide Events puede proporcionar mucho más que estos "tres pilares" (Seguimientos, Registros, Métricas). La sesión de depuración antes mencionada ya es (al menos no de forma natural) un caso cubierto por Seguimientos, Registros y Métricas. Puede haber otros casos de uso; por ejemplo, los datos de creación de perfiles continuos se pueden representar fácilmente como un evento amplio y consultarse para crear un gráfico de llama. No es necesario tener un sistema independiente para esto: un único sistema que maneje eventos amplios puede hacerlo todo. Imagine las posibilidades de correlación cruzada y análisis de causa raíz cuando todo se almacena junto, en un solo lugar. Especialmente en la era del auge de las herramientas de inteligencia artificial, que son excelentes para descubrir relaciones en los datos.
¿Por lo que entonces?
No lo sé... Sólo quería expresar mi decepción y frustración porque la observabilidad es tan confusa y confusa y se centra en cuáles son los "tres pilares"...
Sólo espero que los proveedores de observabilidad se enfrenten al caos y proporcionen una forma sencilla y natural de interactuar con el sistema. Honeycomb parece estar haciendo esto y algunos otros sistemas como Axiom también lo están haciendo. ¡es genial! Esperemos que otros proveedores sigan su ejemplo.
adjunto
Este artículo es una traducción, texto original: https://isburmistrov.substack.com /p/ all -you-need-is-wide-events-not-metrics
Permítanme insertar un pequeño anuncio al final del artículo. He estado iniciando un negocio durante dos años y nuestra empresa también se dedica a la observabilidad, que es algo similar a la idea de este artículo. Si tiene necesidades en esta área, no dude en contactarnos para intercambios técnicos y de productos.
Acerca de la Nebulosa de Kuaimao
Kuaimao Nebula es una empresa de tecnología de operación y mantenimiento inteligente nativa de la nube. Está compuesta por el equipo de desarrollo central del conocido proyecto de código abierto "Nightingale". El equipo fundador proviene de empresas de Internet como Alibaba, Baidu y Didi. Nightingale es una herramienta de monitoreo nativa de la nube de código abierto. Es el primer proyecto de código abierto donado y alojado por la Sociedad de Computación de China. Tiene más de 8000 estrellas en GitHub, ha lanzado más de 100 versiones iterativas y tiene cientos de comunidades. contribuyentes. Es la solución de observabilidad de código abierto líder en China.
La "Plataforma Flashcat" construida por Kuaimao Nebula con el código abierto Nightingale como núcleo es la implementación del producto de las prácticas de observabilidad de las principales empresas nacionales de Internet y se compromete a hacer que la tecnología de observabilidad sirva mejor a las empresas y garantice la estabilidad del servicio. La plataforma Flashcat tiene las siguientes características:
- Colección unificada: al adoptar el concepto de complemento, se pueden integrar cientos de complementos de colección integrados. Servidores, equipos de red, middleware, bases de datos, aplicaciones y empresas se pueden monitorear y utilizar de forma inmediata.
- Alarma unificada: admite el acoplamiento de docenas de fuentes de datos, recopila eventos de alarma de varios sistemas de monitoreo y realiza convergencia de alarmas unificadas, reducción de ruido, programación, reclamo, actualización y colaboración, lo que mejora en gran medida la eficiencia del procesamiento de alarmas.
- Observación unificada: integre varios datos de observabilidad, como métricas, registros, seguimientos, eventos y perfiles, y las mejores prácticas preestablecidas de la industria. No solo proporciona una cabina desde una perspectiva comercial global y una perspectiva técnica, sino que también proporciona un análisis detallado de fallas. Capacidad de posicionamiento, acortando efectivamente el tiempo de descubrimiento y posicionamiento de fallas.
¡La nebulosa Kuaimao hace que los datos de observabilidad sean más valiosos! https://flashcat.cloud/