Crear y mantener un motor de búsqueda de mil millones de niveles no es fácil y no existe un método de gestión óptimo de una vez por todas. Este artículo es el resultado del aprendizaje continuo y el resumen en la práctica. Presenta cómo construir un sistema de búsqueda que pueda admitir productos que van desde decenas de millones hasta cientos de millones, y cómo aumentar el QPS total de consultas de cientos a miles, y escribir. el QPS total El proceso de aumento del nivel 100 al nivel 10,000. Entre ellos, la expansión de recursos de ES es esencial, pero además, este artículo también se centrará en algunos problemas de rendimiento de ES que no se pueden resolver mediante la expansión. Espero que a través de este artículo pueda tener más datos y referencias de uso para escenarios de uso de ES. Debido al espacio limitado, la parte sobre la gobernanza de la estabilidad se presentará en el próximo artículo.
Introducción de negocios
El sistema de gestión de inversiones de la plataforma sirve al escenario de inversión de múltiples entidades de las actividades de la plataforma de comercio electrónico Douyin. Recopilará y seleccionará productos a través de la plataforma de inversión y luego distribuirá los productos a varios sistemas de extremo C. Las entidades que atraen inversiones también son muy diversas, incluidas salas de transmisión en vivo, inversiones en productos, inversiones en cupones, etc. Entre ellas, la inversión en productos es nuestra entidad de inversión más grande.
Estructura de servicio de la plataforma de inversión.
centro de datos
El centro de datos es un servicio de búsqueda basado en ES que proporciona servicios de orquestación y adquisición de datos configurables, escalables y universales. Es un servicio universal que admite la consulta de datos en la plataforma de inversión.
Conceptos clave para entender:
-
Indicadores
: Los indicadores son metadatos que utilizamos para describir un atributo de una entidad u objeto, como el nombre del producto, la puntuación de la experiencia en la tienda, el nivel de experto, el ID del registro de registro. Al mismo tiempo, también puede ser la actualización y adquisición mínima de un. Unidad, como información de comparación de precios de productos. Podemos definir todos los campos con una semántica clara como indicadores
.
-
Conjunto
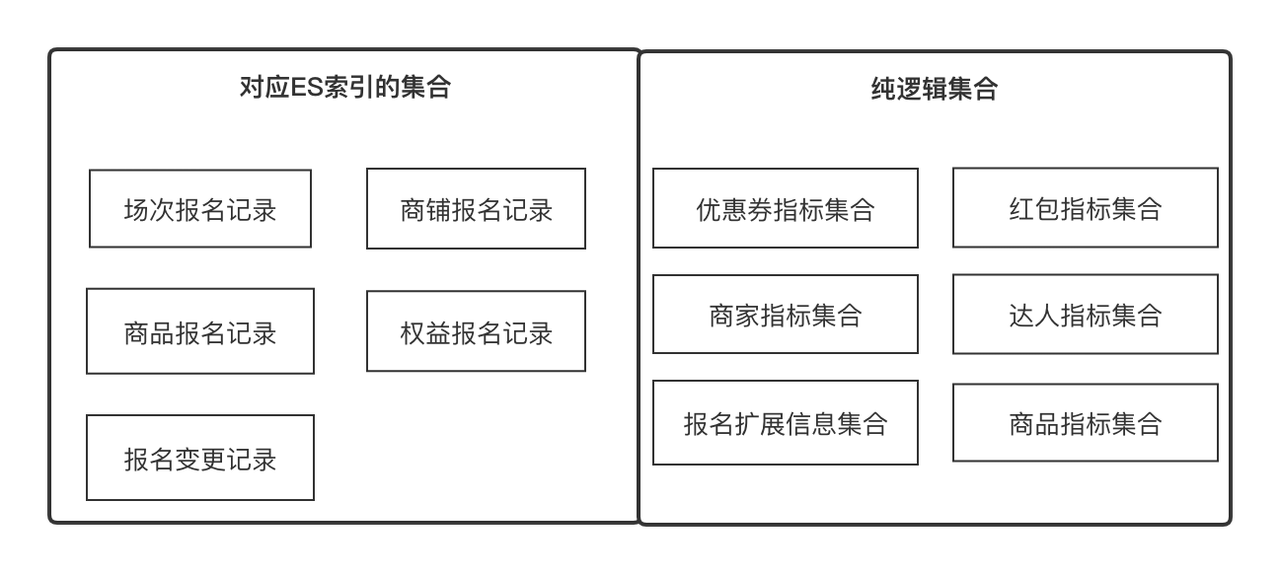
: representa un conjunto que puede converger mediante algunos puntos en común, como el conjunto de atributos del producto y el conjunto de atributos de la tienda, que se pueden obtener por ID de producto e ID de tienda respectivamente. También puede ser una colección de registros de registro de producto, que se puede obtener mediante. ID de registro de registro. En términos comerciales, expresa un conjunto de indicadores relacionados, y los indicadores están en una relación de uno a muchos.
-
Solución
: Solución de adquisición de datos. Abstraemos los dos conceptos de indicadores y colecciones para que los datos se puedan obtener en la unidad más pequeña y se puedan expandir continuamente horizontalmente. La solución nos ayuda a abstraer cómo obtener indicadores en diferentes colecciones.
-
Encabezado personalizado
: el encabezado personalizado se refiere al título que se mostrará en cualquier lista de datos de fila bidimensional. Tiene una relación de uno a muchos con el indicador;
-
Elemento de filtro
: El elemento de filtro se refiere al elemento de filtro que debe usarse en cualquier lista de datos de fila bidimensional. Puede indicar una relación de 1 a 1;
-
Vista de auditoría
: la vista de auditoría se refiere a una página de auditoría que se puede representar dinámicamente a partir de un conjunto de encabezados personalizados y un conjunto de elementos de filtro en un escenario empresarial de auditoría.
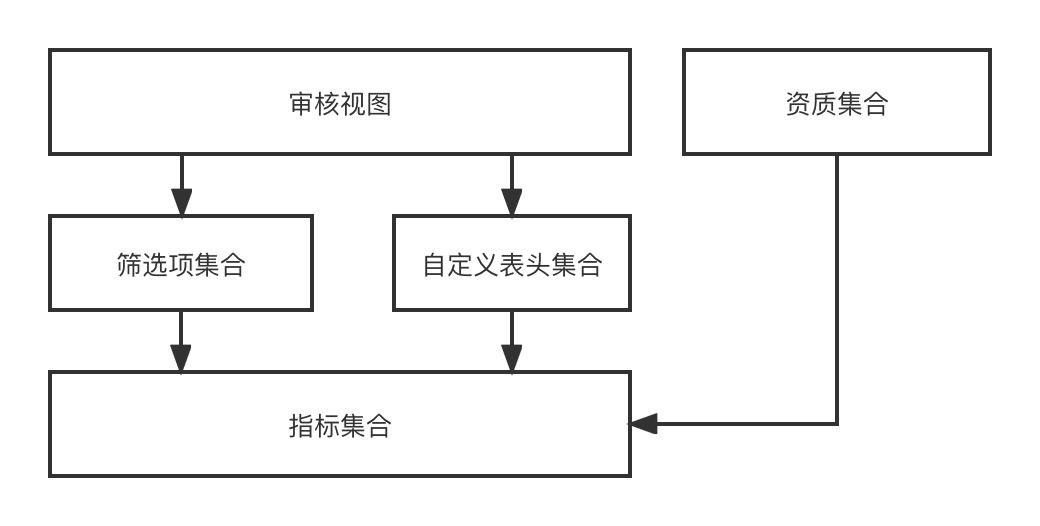
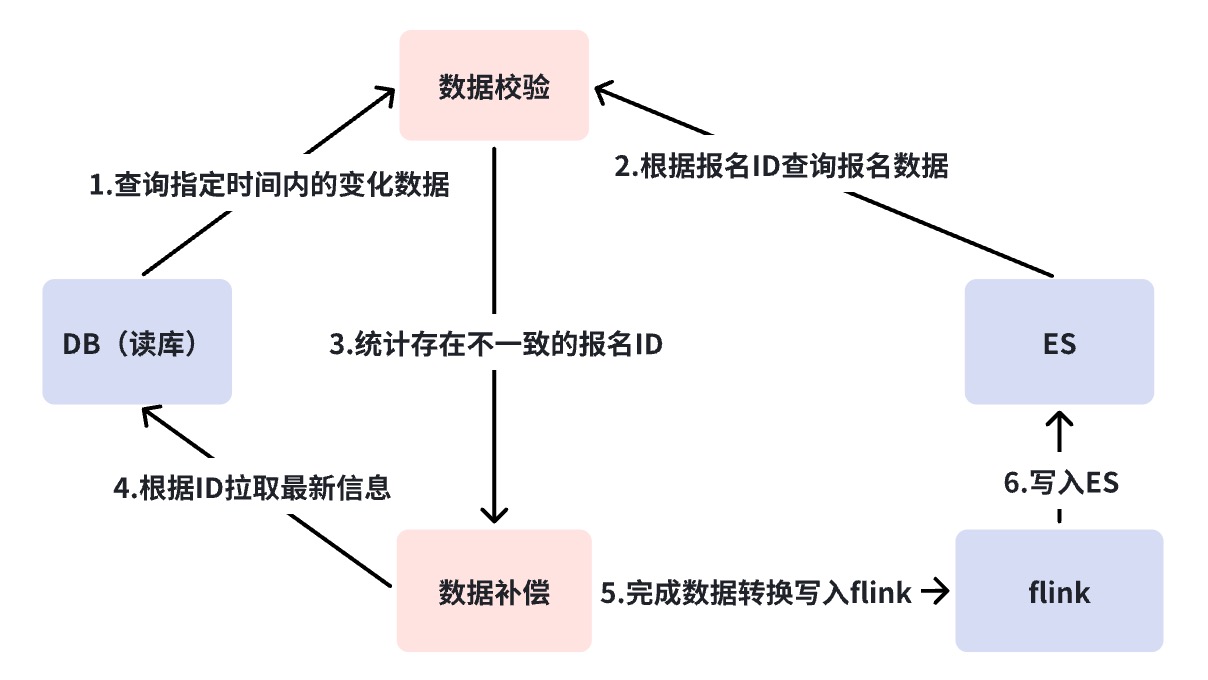
En el diseño funcional, a través del indicador-->[Filtrar elementos, encabezado personalizado]-->Vista de auditoría-->el proceso de finalmente representar dinámicamente una página de auditoría. Dado que estamos reclutando inversiones con múltiples entidades y múltiples escenarios, diferentes entidades. Hay diferentes escenarios y se requieren diferentes vistas de auditoría, por lo que esta serie de capacidades que diseñamos puede combinar dinámicamente cualquier efecto de vista de auditoría requerido.
El centro de datos proporciona capacidades generales de adquisición de datos para empresas de nivel superior, incluida la sincronización y consulta de datos. Actualmente hay dos fuentes de datos, la interfaz RPC externa y el registro de registro ES. El centro de datos integra dos conjuntos de soluciones de adquisición de datos, que desconocen por completo el mundo exterior, es decir, solo necesita obtener qué indicadores de datos bajo qué. recopilación.
El propósito de construir ES es respaldar las capacidades estadísticas y de detección de los registros de registro de inversiones y generar el contenido de datos que desea para el negocio de nivel superior.
Construya un clúster ES de 0 a 1
Para construir un sistema de 0 a 1, sobre la base de satisfacer las necesidades comerciales básicas, la estabilidad debe respaldar los dos puntos siguientes;
-
El mecanismo básico de recuperación ante desastres significa que cuando el rendimiento del sistema se ve afectado debido a cambios en los componentes básicos y al tráfico de lectura y escritura, la empresa puede adaptarse a tiempo.
-
La coherencia final de los datos significa que el registro de registro DB --> ES los datos de la sala de máquinas múltiples están completos.
Investigación del programa
Evaluación de la capacidad del clúster ES
La evaluación de la capacidad del clúster ES es para garantizar que el clúster pueda proporcionar servicios estables durante un período de tiempo después de su construcción. Principalmente debe poder resolver los siguientes problemas:
-
Cuántos fragmentos se deben configurar para cada índice, cuánto incremento de datos posterior se espera y estimaciones de tráfico de lectura y escritura;
-
Cuántas instancias de datos se deben configurar en un solo clúster y qué especificaciones se deben usar para una sola instancia de datos;
-
Comprenda la diferencia entre expansión vertical y expansión horizontal, cuál es nuestra estrategia de respuesta cuando el volumen de datos aumenta inesperadamente o el tráfico aumenta inesperadamente y cómo se debe diseñar la recuperación ante desastres del clúster ES.
Soluciones clave:
-
Una vez que se establece la cantidad de fragmentos de índice ES, no se puede modificar, por lo que es importante determinar la cantidad de fragmentos. Por lo general, la cantidad de fragmentos es un múltiplo entero de la instancia de ES para garantizar el equilibrio de carga;
-
El tamaño de un único fragmento es relativamente razonable, entre 10 y 30 G. Una indexación excesiva afectará el rendimiento de la consulta;
-
El aumento del tráfico se puede resolver mediante la expansión de la capacidad, y el aumento de los datos se puede resolver eliminando datos antiguos o aumentando el número de fragmentos, y se debe implementar con un plan de implementación de recuperación ante desastres de salas de máquinas múltiples, de modo que se puedan implementar entre sí; es una sala de máquinas resistente a desastres.
Selección de enlace de sincronización de datos
Resuelve principalmente cómo sincronizar los registros de registro de base de datos con ES, cómo escribir otros indicadores relacionados en ES y cómo actualizar y garantizar la coherencia de los datos.
-
DB -> ES debe ser un flujo de datos casi en tiempo real, y los cambios en los registros de registro y otra información deben poder buscarse en tiempo casi real;
-
Además de sus propios campos, el registro de registro también necesita complementar sus campos de atributos, como productos registrados, tiendas y expertos. También está escrito en ES y
puede admitir actualizaciones parciales
, por lo que el método de escritura de ES solo puede ser el método Upsert. ;
-
Las actualizaciones de los registros de registro individuales deben estar en orden y no deben entrar en conflicto.
Encuesta de configuración básica del índice ES
Comprender los fundamentos y configuraciones esenciales de ES.
-
{"dynamic": false} evita la expansión automática de asignaciones es o la adición de tipos de índice inesperados;
-
index.translog.durability=async, actualizar translog de forma asincrónica ayudará a mejorar el rendimiento de escritura, pero existe el riesgo de pérdida de datos;
-
El intervalo de actualización predeterminado de ES es 1 segundo, lo que significa que los datos se pueden encontrar tan pronto como un segundo después de una escritura exitosa.
Solución de sincronización de datos
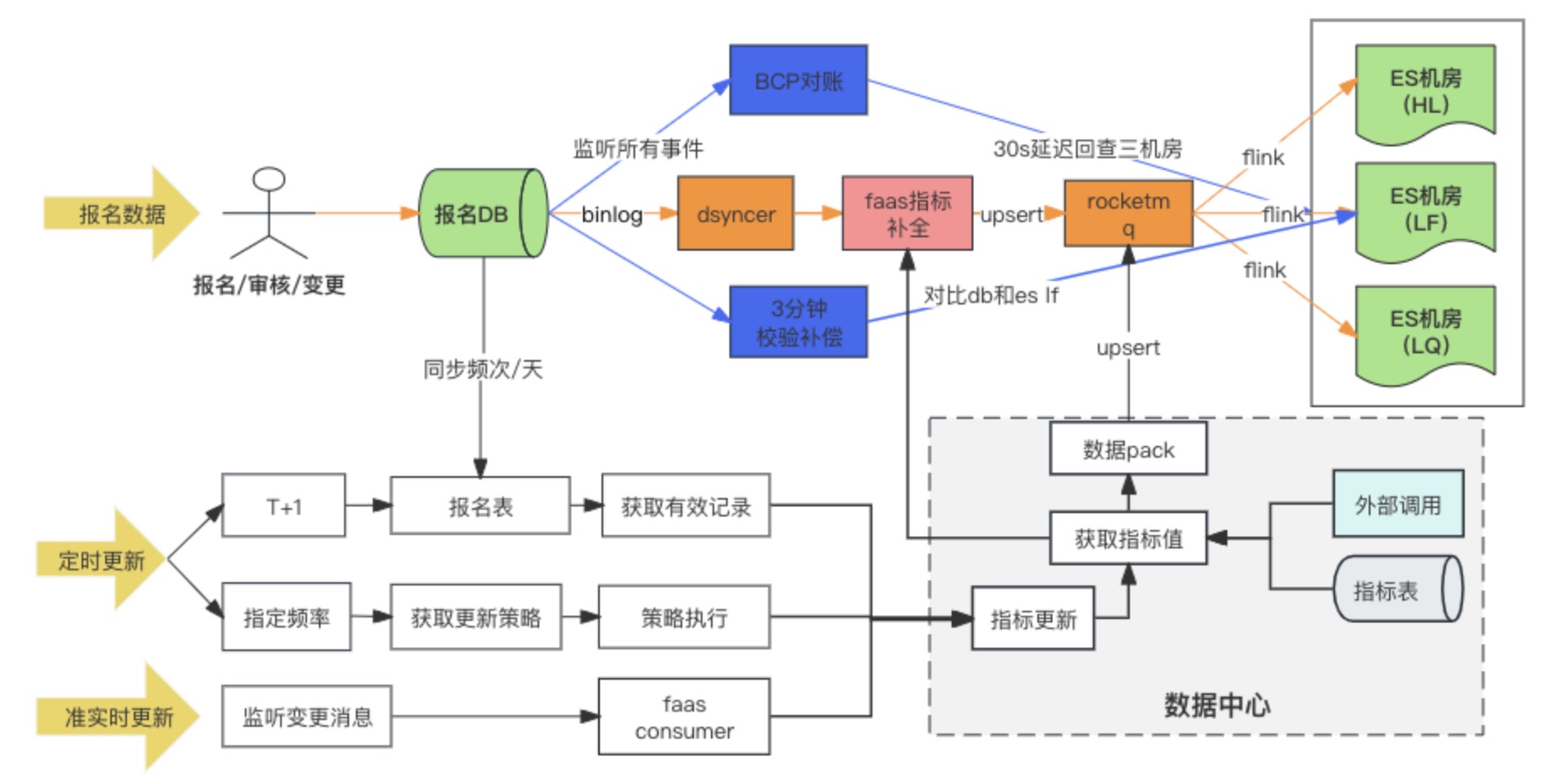
Diagrama de enlace de sincronización de datos
La solución de sincronización de datos DB -> ES finalmente adopta el método de escritura síncrona de datos heterogéneos en RocketMQ + Flink para el consumo de salas de máquinas múltiples. Al mismo tiempo, cuando se escribe el registro de registro por primera vez, se completan los indicadores extendidos. a través del script de conversión personalizado de Faas, y las dependencias de actualización de los indicadores extendidos son Cambie los dos métodos de escucha de mensajes y tareas programadas. Durante la investigación, en realidad había tres opciones para DB -> ES sala de computadoras. Al final, elegimos la tercera opción. Aquí comparamos las diferencias entre las tres opciones.
Solución 1: escriba directamente en la sala de máquinas múltiples de ES mediante sincronización de datos heterogénea (Dsyncer)
defecto:
-
La escritura directa está en desventaja para cumplir con los requisitos de ES para implementar múltiples salas de computadoras al mismo tiempo, porque no puede garantizar una escritura exitosa en varias salas de computadoras al mismo tiempo. ¿Está bien implementar múltiples datos heterogéneos y escribirlos por separado? Sí, es decir, la carga de trabajo se triplica a aproximadamente una docena de índices.
-
La capacidad de escritura masiva de escritura directa es relativamente débil y los picos de escritura serán más obvios a medida que el tráfico fluctúe, lo que no favorece el rendimiento de escritura de ES.
-
La escritura directa no puede garantizar la actualización ordenada de un único registro de registro cuando ES tiene varias entradas de actualización. ¿Puedo aumentar la versión global? Sí, pero demasiado pesado.
Ventajas:
la ruta de dependencia más corta, baja latencia de escritura y riesgo mínimo para el sistema. No es ningún problema para empresas con poco tráfico y empresas con escenarios de sincronización simples.
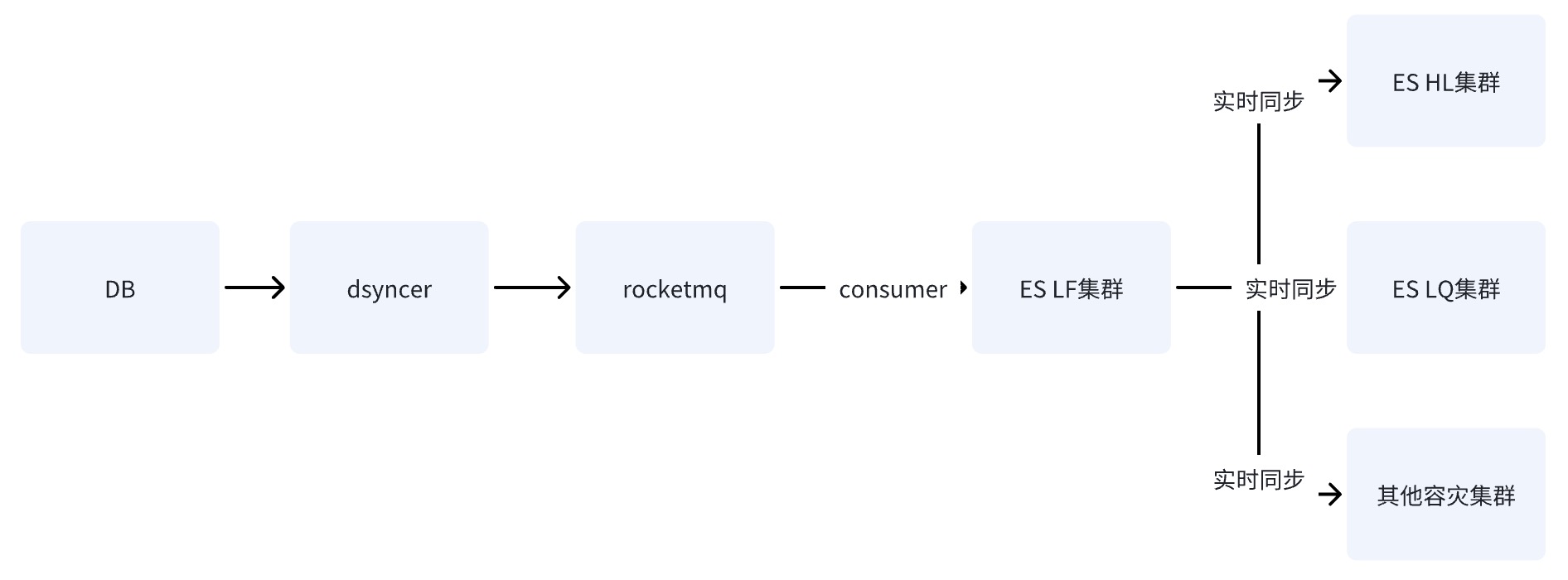
Opción 2: escribir una sala de computadoras única ES a través de RocketMQ
Después de que DB escribe en la sala de computadoras única de ES a través de RocketMQ, los datos se sincronizan con otras salas de computadoras a través de la capacidad de replicación entre clústeres de datos proporcionada por ES.
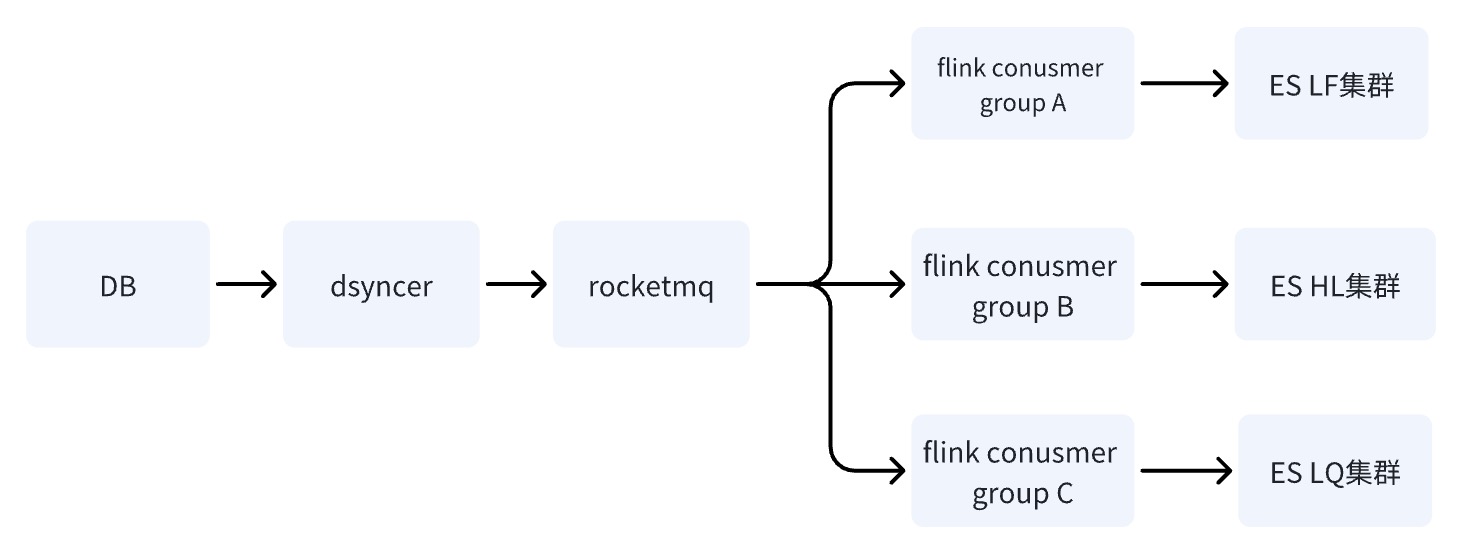
Opción 3: Escriba una sala de máquinas múltiples ES a través de RocketMQ + Flink ✅
Cuando DB escribe en el clúster ES a través de RocketMQ, se inician varias tareas independientes del grupo de consumidores. El sistema puede utilizar el sistema distribuido Flink para escribir datos en varias salas de computadoras.
Solo hay una diferencia entre el esquema dos y el esquema tres: la forma de escribir en varias salas de computadoras es diferente. El esquema dos es escribir en una sala de computadoras y luego sincronizar los datos con otras salas de computadoras en tiempo casi real, mientras que el esquema. El tercero es escribir varios consumidores independientes por separado.
Las desventajas de las opciones dos y tres son las mismas: la ruta de dependencia es la más larga y el retraso de escritura se ve fácilmente afectado por la fluctuación de los componentes básicos. Sin embargo, la desventaja fatal de la opción dos es que existe un
único punto de riesgo. el sistema
Suponiendo que los datos están sincronizados con HL y LQ a través de LF, el sistema quedará inutilizable después de que LF cuelgue.
La ventaja de la opción tres es que los enlaces de escritura de varias salas de computadoras son independientes entre sí. En comparación con la opción dos, si algún enlace tiene problemas, no causará riesgos para el negocio. RocketMQ puede resolver fácilmente el problema de actualización secuencial de una sola clave. ,
lo cual tampoco es deseable por la primera opción
.
¿Por qué escribir a través de RocketMQ puede resolver el problema del desorden y el conflicto?
-
En primer lugar, la escritura ES se controla mediante un bloqueo optimista basado en el número de versión. Si el mismo registro se actualiza al mismo tiempo, entonces la versión que obtenemos al mismo tiempo es la misma, suponiendo que sea 1, entonces todos lo harán. actualice la versión a 2 para escribir, se producirán conflictos y los conflictos siempre causarán el problema de la pérdida de actualizaciones;
-
Los escenarios comerciales generales requieren un consumo ordenado basado en el orden de claves y particiones. El consumo ordenado requiere dos condiciones necesarias: cuando se almacenan los mensajes, deben ser consistentes con el orden en que se envían; cuando se consumen, deben ser consistentes con el orden; en el que se almacenan.
Por lo tanto, si la empresa quiere consumir mensajes de manera ordenada, debe asegurarse de que los mensajes enviados con la misma clave se envíen a la misma partición, y los mensajes consumidos deben garantizar que los mensajes con la misma clave siempre sean consumidos por el mismo Consumidor. Pero, de hecho, las dos condiciones necesarias mencionadas anteriormente son ideales y, en algunos casos, no se pueden garantizar por completo, como el reequilibrio del consumidor, que se analiza a continuación.
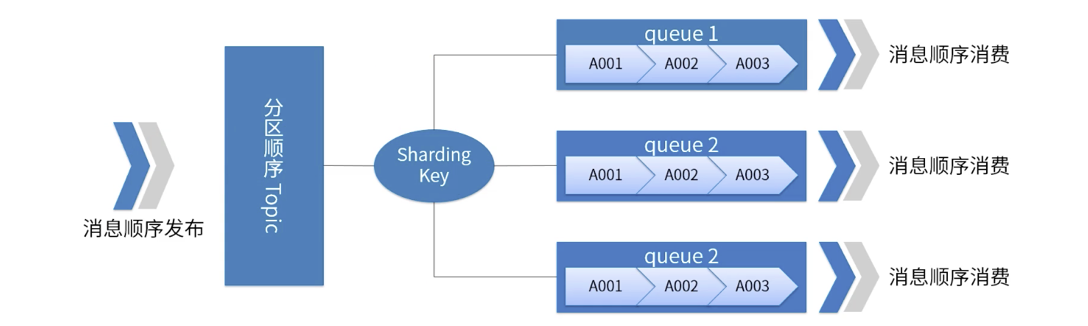
Una imagen ilustra el orden de partición de RocketMQ.
-
Para un tema específico, todos los mensajes se dividen en múltiples (cola) según la clave de fragmentación.
-
Los mensajes de la misma cola se publican y consumen en estricto orden FIFO.
-
Sharding Key es un campo clave que se utiliza para distinguir diferentes particiones en mensajes secuenciales. Es un concepto completamente diferente de la clave de los mensajes ordinarios.
-
Escenarios aplicables: requisitos de alto rendimiento. Determine a qué cola se envía el mensaje en función de la clave de fragmentación del mensaje. Generalmente, la partición ordenada puede cumplir con nuestros requisitos comerciales y tiene un alto rendimiento.
Lo que hay que tener en cuenta aquí es
que
RocketMQ puede haber ayudado a la empresa a resolver el 99% de los problemas de desorden, pero no el 100%. En casos extremos, es posible que los mensajes aún tengan problemas de consumo de desorden, como. Como el fenómeno ABA, como cuando la partición falla, el mensaje se envía repetidamente a otras colas de partición, etc., por lo que la reconciliación de coherencia es esencial.
Mecanismo de reconciliación multicapa
El mecanismo de conciliación resuelve el problema de coherencia de datos de DB->ES. Como se mencionó anteriormente, DB->ES es un flujo de datos casi en tiempo real y el enlace de dependencia es relativamente largo. Necesitamos un monitoreo correspondiente en diferentes estados. estrategias de conciliación y compensación para garantizar la eventual coherencia de los datos.
Aquí hemos realizado una conciliación de tres capas. Utilizamos la plataforma de conciliación para lograr la conciliación a nivel de minutos y la conciliación fuera de línea. Las razones de la necesidad de la conciliación de múltiples capas se explicarán una por una a continuación.
Diagrama de análisis de fallas del enlace ES de sincronización de base de datos
Conciliación de segundo nivel de la Plataforma de Verificación Empresarial ( BCP )
Consultando la figura anterior, encontrará que la sincronización DB -> ES depende de muchos componentes dependientes. En este caso, necesitamos una
conciliación desde una perspectiva global
para descubrir problemas de enlace de sincronización, es decir, la conciliación de BCP en tiempo real.
La conciliación de BCP es una conciliación de flujo único que monitorea Binlog y verifica directamente la conciliación de la sala de máquinas múltiples de ES. Solo depende del flujo de Binlog y los estudiantes cuidadosos pueden descubrir rápidamente retrasos en la sincronización de datos en los enlaces intermedios. Encontrará que si Binlog está cortado y la conciliación de BCP no se puede corregir, se discutirá cómo resolver esta situación más adelante, pero al menos se puede ver que, excepto DB->DBus, la conciliación de BCP es suficiente para encontrar la mayor parte del retraso de sincronización. problemas. ¿Por qué una transmisión única en lugar de múltiples transmisiones?
-
Evite problemas de retrasos incontrolables causados por enlaces de flujo de datos largos para la conciliación de múltiples flujos, lo que resulta en una baja precisión de verificación.
-
El costo de mantenimiento de la conciliación de BCP se reducirá considerablemente, porque si se utiliza flujo múltiple, necesitamos mantener múltiples conciliaciones de BCP para la conciliación de varias salas de computadoras, que dependen de componentes más básicos para el mantenimiento.
La escritura de base de datos de conciliación de BCP siempre activa solicitudes de obtención de ES, lo que consume ciertos recursos de consulta en ES, pero las solicitudes de obtención son métodos de consulta con muy buen rendimiento. Por ejemplo, no tenemos problemas para escribir dentro de 1000 QPS.
Obtener solicitud debe prestar atención a un parámetro en tiempo real, que debe establecerse en Falso al realizar la solicitud; de lo contrario, se activará una operación de actualización cada vez que se solicite, lo que tendrá un impacto en el rendimiento de escritura del sistema.
mgetReq := EsClient.MultiGet().
Tiempo real (falso)
Conciliación a nivel de minutos
Como se mencionó en la sección anterior, la ruta que la conciliación de la Plataforma de verificación empresarial (BCP) no puede cubrir es DB->DBus, que es la situación en la que se corta Binlog. Normalmente la interrupción de Binlog puede haber significado un accidente más grave, pero lo que tenemos que hacer es hacer todo lo posible.
La conciliación a nivel de minuto consulta directamente a DB y ES para la conciliación, sin depender de ningún componente. Cuando ocurren inconsistencias, se realiza una compensación automática. Por un lado, la conciliación a nivel de minutas compensa las deficiencias de la conciliación del BCP, y el segundo punto es agregar un mecanismo de compensación. La razón por la que BCP no compensa es porque BCP se utiliza principalmente para descubrir problemas, por lo que debe seguir siendo liviano y rápido. Además, todavía depende de componentes básicos como RocketMQ y DBus. Este tipo de compensación aún no puede cubrir todos los escenarios anormales.
De forma predeterminada, consideraremos que la función del componente está intacta para la conciliación cada tres minutos, pero un breve retraso en un nodo provoca una compensación. Si las alarmas de compensación ocurren con frecuencia, debemos analizar más a fondo cuál es el problema con el enlace. En este momento, en nuestro escenario, dividiré el enlace en dos y confirmaré si hay un problema con el enlace anterior de RocketMQ o un problema con RocketMQ y los enlaces de consumo posteriores. A través del diagrama de análisis de fallas, si hay un problema con el enlace antes de RocketMQ, como una interrupción de Binlog, un componente de la plataforma de sincronización de datos heterogéneos que se cuelga, etc., los datos de compensación se escribirán directamente en RocketMQ y se consumirán en varias salas de computadoras. Al mismo tiempo, no es necesario cortar el tráfico de lectura y puede garantizar la coherencia de los datos en varias salas de computadoras. Pero si RocketMQ cuelga, escribirá directamente en ES. Debido a que en este momento no podemos garantizar que se puedan escribir varias salas de computadoras al mismo tiempo, nuestra decisión es escribir solo en una única sala de computadoras y cambiar todo el tráfico a ella. la única sala de ordenadores.
RocketMQ colgar es una muy mala señal y la situación aquí es más complicada. Debido a la escritura directa en ES, si el tráfico de escritura es alto, el sistema pierde la protección límite actual en este momento y es posible que ES no pueda soportarlo en una sola sala de computadoras; Al mismo tiempo, si ocurren conflictos de escritura con frecuencia, es necesario degradar el puerto de escritura comercial. Por lo tanto, si RocketMQ cuelga, se puede entender que el sistema central del enlace de escritura está paralizado.
Esto es lo último que desea ver, por lo que el SLA de RocketMQ es la base del negocio.
Conciliación fuera de línea T+1
La conciliación fuera de línea consiste en sincronizar los datos de DB y ES con Hive diariamente. Los datos incrementales verifican la coherencia final. Si son inconsistentes, la reconciliación fuera de línea es el resultado final de la coherencia de los datos. los datos deben ser T a más tardar +1 compensación exitosa.
Resumir
Arriba hemos completado la primera fase de construcción, implementación de recuperación ante desastres, conciliación de coherencia y estrategias básicas de respuesta a excepciones del sistema. En este momento, ES puede admitir solicitudes de lectura y escritura para decenas de millones de índices de productos. El tráfico de una sola sala de computadoras fluctúa entre 500 y 100 QPS, y el tráfico de escritura se mantiene básicamente en alrededor de 500 QPS.
Sin embargo, con el desarrollo de los negocios, el clúster ES ha experimentado aumentos repentinos de la CPU, una o más salas de computadoras están llenas al mismo tiempo y los retrasos en las consultas aumentan repentinamente. Sin embargo, el tráfico de lectura y escritura no fluctúa mucho, o sí. mucho menor que el pico del sistema. Este riesgo se atribuye a los problemas de rendimiento que ocurren en el clúster ES y la postura de uso de la empresa. Continuaremos presentando esta parte del contenido en el próximo artículo sobre la gestión de estabilidad del motor de búsqueda ES.
Fuente del artículo | Plataforma empresarial ByteDance Wang Dan