
Este artículo se basa en un discurso pronunciado por Shao Wei, ingeniero senior de I+D de Volcano Engine, en la Conferencia Global de Desarrollo de Software QCon. Orador | Discurso de Shao Wei | QCon Guangzhou en mayo de 2023
PPT | Katalyst: Práctica de optimización de costos nativa de ByteDance Cloud
1. Antecedentes
Byte ha comenzado a transformar sus servicios en servicios nativos de la nube desde 2016. A la fecha, el sistema de servicios de Byte incluye principalmente cuatro categorías: los microservicios tradicionales son en su mayoría servicios web RPC basados en Golang; el servicio de búsqueda de promociones es un servicio tradicional de C++ con mayor rendimiento; requisitos además También hay aprendizaje automático, big data y varios servicios de almacenamiento .
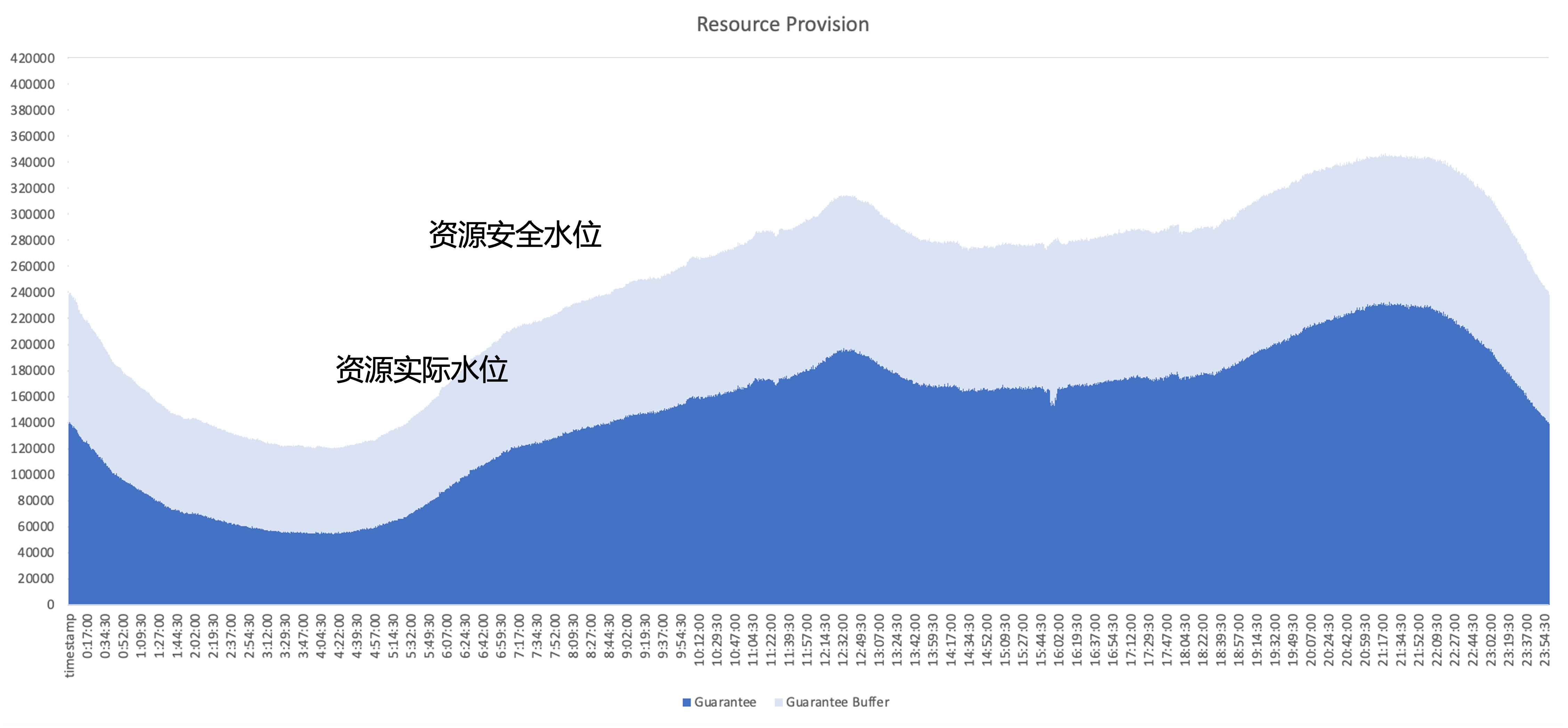
El problema principal que debe resolverse después de la nube nativa es cómo mejorar la eficiencia de utilización de recursos del clúster, tomando como ejemplo el uso de recursos de un servicio en línea típico; la parte azul oscuro es la cantidad de recursos realmente utilizados por la empresa; , Y la parte azul claro es el búfer de seguridad proporcionado por el área comercial. Incluso si se aumenta el área de búfer, todavía hay muchos recursos que la empresa ha solicitado pero no ha utilizado. Por lo tanto, el objetivo de optimización es utilizar estos recursos no utilizados tanto como sea posible desde una perspectiva arquitectónica.
plan de gestión de recursos
Byte ha probado varios tipos diferentes de soluciones de gestión de recursos internamente, incluyendo
- Operación de recursos: ayude periódicamente a la empresa a gestionar el estado de utilización de los recursos y promueva la gestión de aplicaciones de recursos. El problema es que la carga de operación y mantenimiento es pesada y el problema de utilización no se puede resolver.
- Overbooking dinámico: evalúe la cantidad de recursos comerciales en el lado del sistema y reduzca proactivamente la cuota. El problema es que la estrategia de overbooking no es necesariamente precisa y puede generar un riesgo de ejecución.
- Escalado dinámico: el problema es que si solo apunta a los servicios en línea para escalar, dado que los picos y valles del tráfico en los servicios en línea son similares, no podrá mejorar completamente la utilización a lo largo del día.
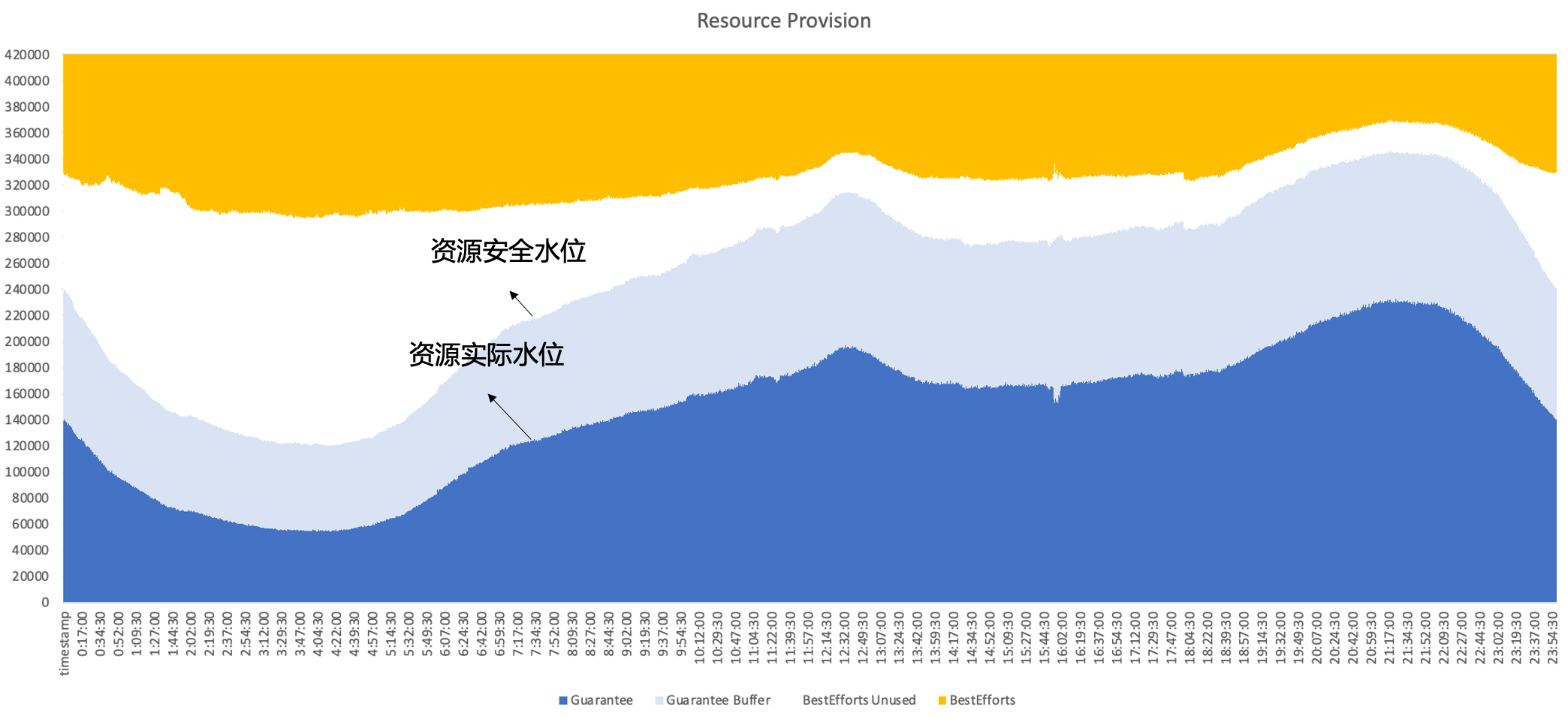
Por lo tanto, al final, Byte adopta una implementación híbrida, ejecutándose en línea y fuera de línea en el mismo nodo al mismo tiempo, aprovechando al máximo las características complementarias entre los recursos en línea y fuera de línea para lograr una mejor utilización de los recursos; en última instancia, esperamos lograr el siguiente efecto; , es decir, las ventas secundarias son en línea. Los recursos no utilizados se pueden llenar con cargas de trabajo fuera de línea para mantener la eficiencia de utilización de los recursos en un alto nivel durante todo el día.
2. Historial de desarrollo de la implementación híbrida de bytes
A medida que Byte Cloud se vuelve nativo, elegimos soluciones de implementación híbrida apropiadas según las necesidades comerciales y las características técnicas en diferentes etapas, y continuamos iterando nuestro sistema híbrido en el proceso.
2.1 Fase 1: Mezcla de tiempo compartido sin conexión
La primera etapa implica principalmente la implementación híbrida de tiempo compartido en línea y fuera de línea.
- En línea: en esta etapa, hemos creado una plataforma de elasticidad del servicio en línea. Los usuarios pueden configurar reglas de escalamiento horizontal basadas en indicadores comerciales, por ejemplo, si el tráfico comercial disminuye temprano en la mañana y el negocio se reduce de manera proactiva en algunas instancias, el sistema utilizará los recursos; embalaje de bing sobre la base de la contracción del caso. Esto libera toda la máquina;
- Para fuera de línea: en esta etapa, los servicios fuera de línea pueden obtener una gran cantidad de recursos de tipo spot y, debido a que su suministro es inestable, pueden disfrutar de un cierto descuento en el costo al mismo tiempo; en línea, vender recursos no utilizados fuera de línea puede; obtener una determinada rebaja del coste.
La ventaja de esta solución es que no requiere un mecanismo complejo de aislamiento del lado de una sola máquina y la implementación técnica es relativamente baja; sin embargo, también presenta algunos problemas, como;
- La eficiencia de conversión no es alta y pueden ocurrir problemas como la fragmentación durante el proceso de empaquetamiento bing;
- Es posible que la experiencia fuera de línea tampoco sea buena. Cuando el tráfico en línea fluctúa ocasionalmente, el usuario fuera de línea puede morir por la fuerza, lo que resulta en fuertes fluctuaciones de recursos.
- Provocará cambios de instancia en el negocio. En las operaciones reales, el negocio generalmente configura una política elástica relativamente conservadora, lo que resulta en un límite superior bajo para la mejora de recursos.
2.2 Fase 2: implementación conjunta de Kubernetes/YARN
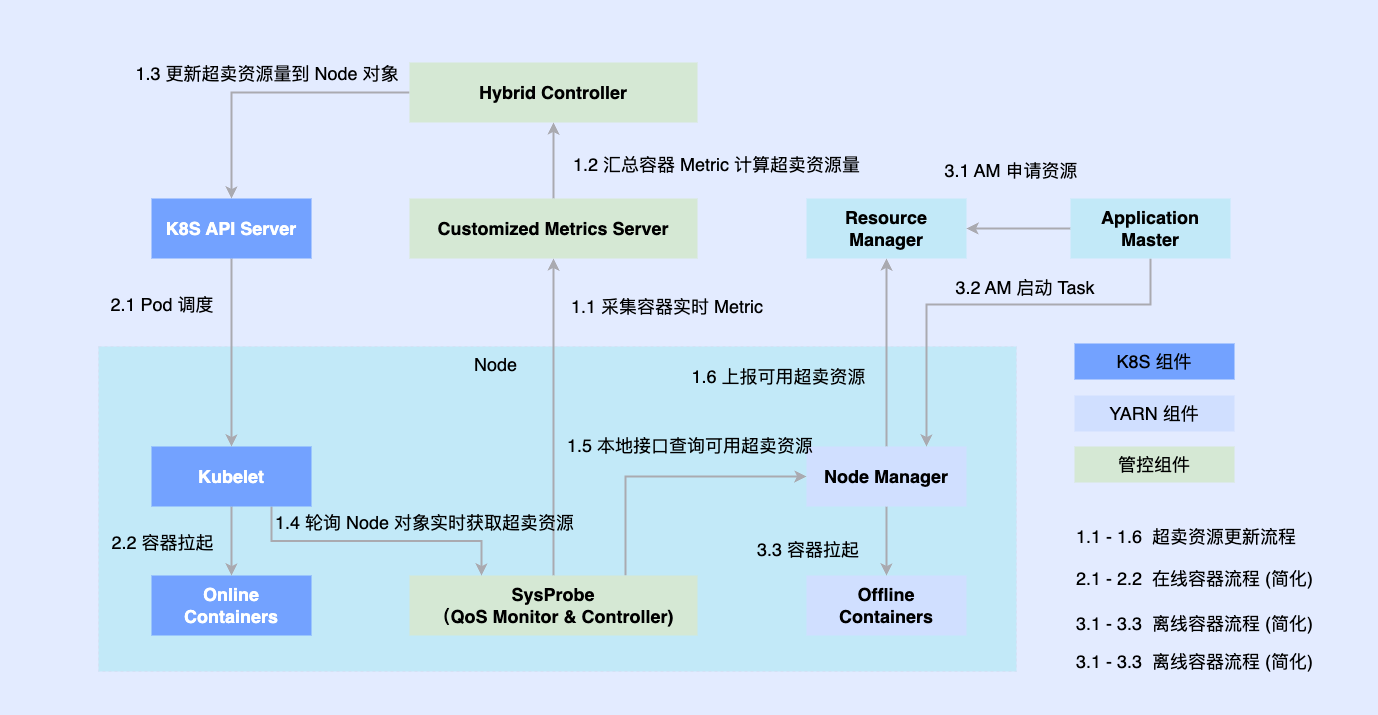
Para resolver los problemas anteriores, ingresamos a la segunda etapa e intentamos ejecutar en línea y sin conexión en un nodo.
Dado que la parte en línea se transformó de forma nativa en función de Kubernetes anteriormente, la mayoría de los trabajos fuera de línea todavía se ejecutan en función de YARN. Para promover la implementación híbrida, introducimos componentes de terceros en una sola máquina para determinar la cantidad de recursos coordinados en línea y fuera de línea, y los conectamos con componentes independientes como Kubelet o Node Manager al mismo tiempo; Las cargas de trabajo en línea y fuera de línea están programadas para los nodos y también están coordinadas por El componente de coordinación actualiza de forma asincrónica las asignaciones de recursos para ambas cargas de trabajo.
Este plan nos permite completar la acumulación de reservas de capacidades de coubicación y verificar la viabilidad, pero todavía hay algunos problemas.
- Los dos sistemas se ejecutan de forma asincrónica, por lo que el contenedor fuera de línea solo puede eludir la gestión y el control, y hay una carrera y una pérdida excesiva de recursos en los enlaces intermedios;
- La simple abstracción de las cargas de trabajo fuera de línea nos impide describir requisitos complejos de QoS.
- La fragmentación de los metadatos fuera de línea dificulta la optimización extrema y no puede lograr una optimización de la programación global.
2.3 Fase 3: programación unificada e implementación mixta fuera de línea
Para resolver los problemas en la segunda etapa, en la tercera etapa realizamos completamente una implementación híbrida unificada fuera de línea.
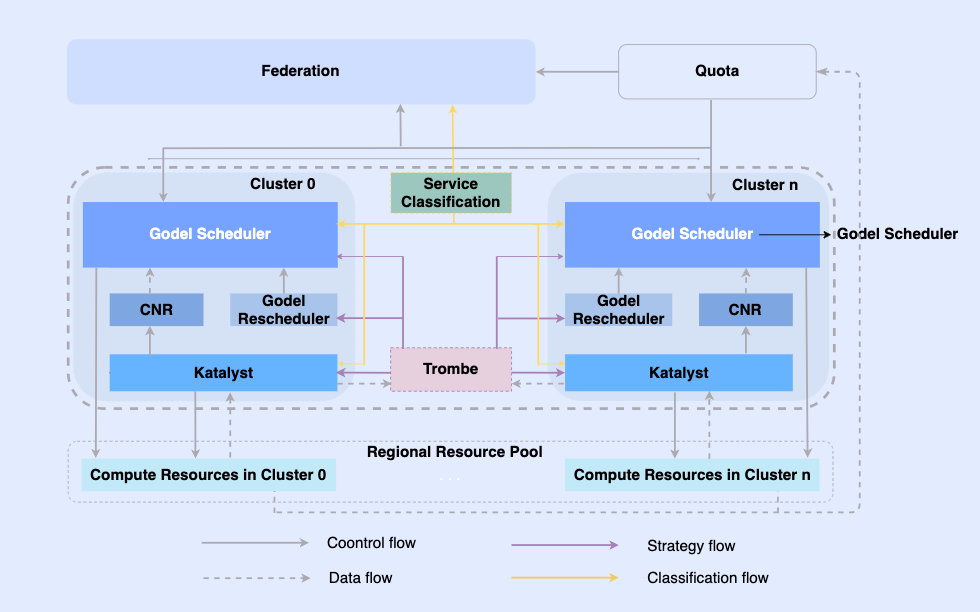
Al hacer que los trabajos fuera de línea sean nativos de la nube, permitimos programarlos y administrar los recursos en la misma infraestructura. En este sistema, la capa superior es una federación de recursos unificada para realizar la gestión de recursos de múltiples clústeres. En un solo clúster, hay un programador unificado central y un administrador de recursos unificado independiente que trabajan juntos para lograr capacidades de gestión de recursos integradas fuera de línea. .
En esta arquitectura, Katalyst actúa como la capa central de control y gestión de recursos y es responsable de realizar la asignación y estimación de recursos en tiempo real en el lado de una sola máquina. Tiene las siguientes características.
- Estandarización de la abstracción: abra metadatos fuera de línea, haga que la abstracción de QoS sea más compleja y rica y cumpla mejor con los requisitos de rendimiento empresarial;
- Sincronización de gestión y control: la política de gestión y control se emite cuando se inicia el contenedor para evitar la corrección asincrónica de los ajustes de recursos después del inicio, al tiempo que admite la expansión gratuita de la política;
- Estrategia inteligente: al crear retratos de servicios, puede detectar las demandas de recursos con anticipación e implementar estrategias de control y gestión de recursos más inteligentes;
- Automatización de operación y mantenimiento: A través de la entrega integrada, se logra la automatización y estandarización de operación y mantenimiento.
3. Introducción al sistema Katalyst
Katalyst se deriva de la palabra inglesa catalizador, que originalmente significa catalizador. La primera letra se cambió a K, lo que significa que el sistema puede proporcionar capacidades de gestión automatizada de recursos más potentes para todas las cargas que se ejecutan en el sistema Kubernetes.
3.1 Descripción general del sistema Katalyst
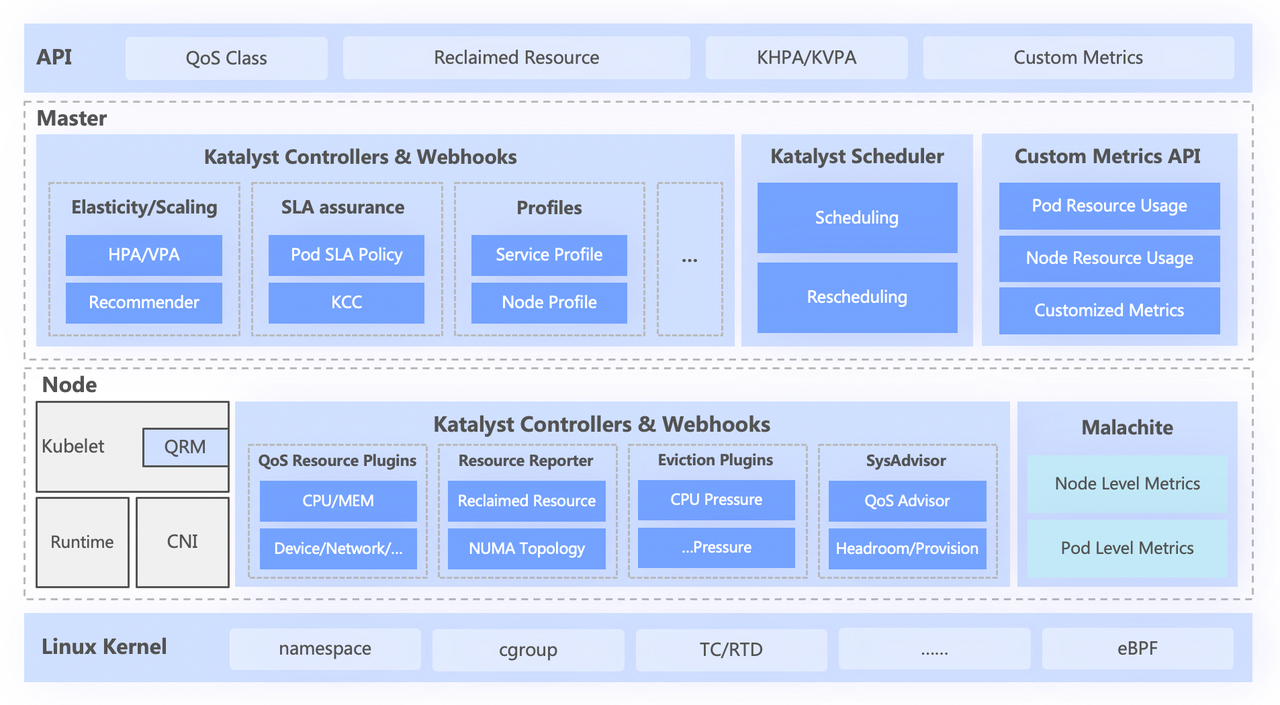
El sistema Katalyst se divide aproximadamente en cuatro capas, que incluyen
- La API estándar de nivel superior abstrae diferentes niveles de QoS para los usuarios y proporciona capacidades ricas de expresión de recursos;
- La capa central es responsable de capacidades básicas como la programación unificada, la recomendación de recursos y la creación de retratos de servicios;
- La capa independiente incluye un sistema de monitoreo de datos de desarrollo propio y un asignador de recursos responsable de la asignación en tiempo real y el ajuste dinámico de los recursos;
- La capa inferior es un kernel personalizado por bytes, que resuelve el problema del rendimiento de una sola máquina cuando se ejecuta sin conexión al mejorar el parche del kernel y el mecanismo de aislamiento subyacente.
3.2 Estandarización abstracta: Clase QoS
Katalyst QoS se puede interpretar desde perspectivas macro y micro
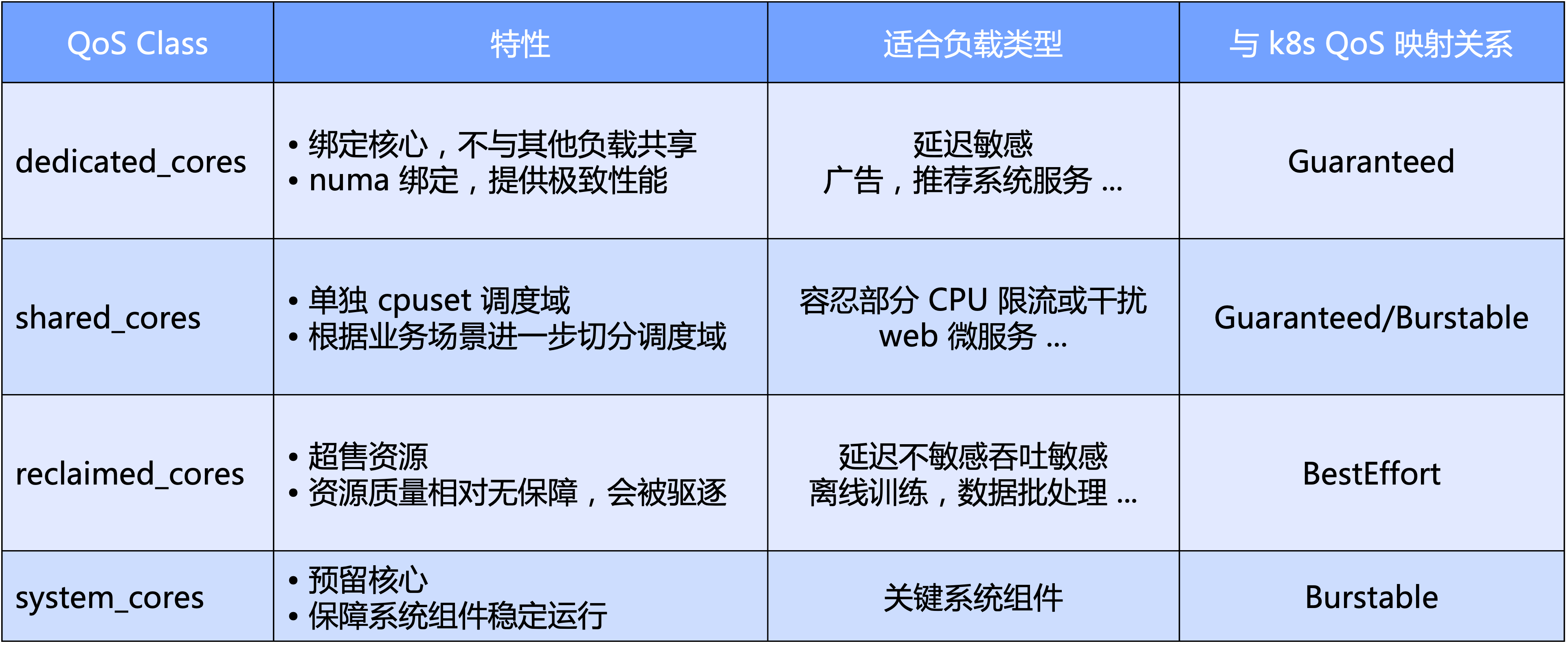
- A nivel macro, Katalyst define niveles de QoS estándar basados en la dimensión principal de la CPU. Específicamente, dividimos la QoS en cuatro categorías: exclusiva, compartida, de reciclaje y tipo de sistema reservado para componentes clave del sistema;
- Desde una perspectiva micro, la expectativa final de Katalyst es que no importa qué tipo de carga de trabajo sea, se puede ejecutar en un grupo en el mismo nodo sin la necesidad de aislar el clúster mediante cortes estrictos, logrando así una mejor eficiencia del tráfico de recursos y utilización de recursos. eficiencia.
Sobre la base de QoS, Katalyst también proporciona una gran cantidad de mejoras de extensión para expresar otros requisitos de recursos además de los núcleos de CPU.
- Mejora de QoS: expresión ampliada de los requisitos comerciales para recursos multidimensionales, como enlace de tarjeta de red/NUMA, asignación de ancho de banda de tarjeta de red, peso de IO, etc.
- Mejora del pod: amplía la expresión de la sensibilidad del negocio a varios indicadores del sistema, como el impacto del retraso en la programación de la CPU en el rendimiento del negocio.
- Mejora del nodo: exprese las demandas combinadas de la microtopología entre múltiples dimensiones de recursos al extender la TopologyPolicy nativa
3.3 Gestión y sincronización de control: QoS Resource Manager
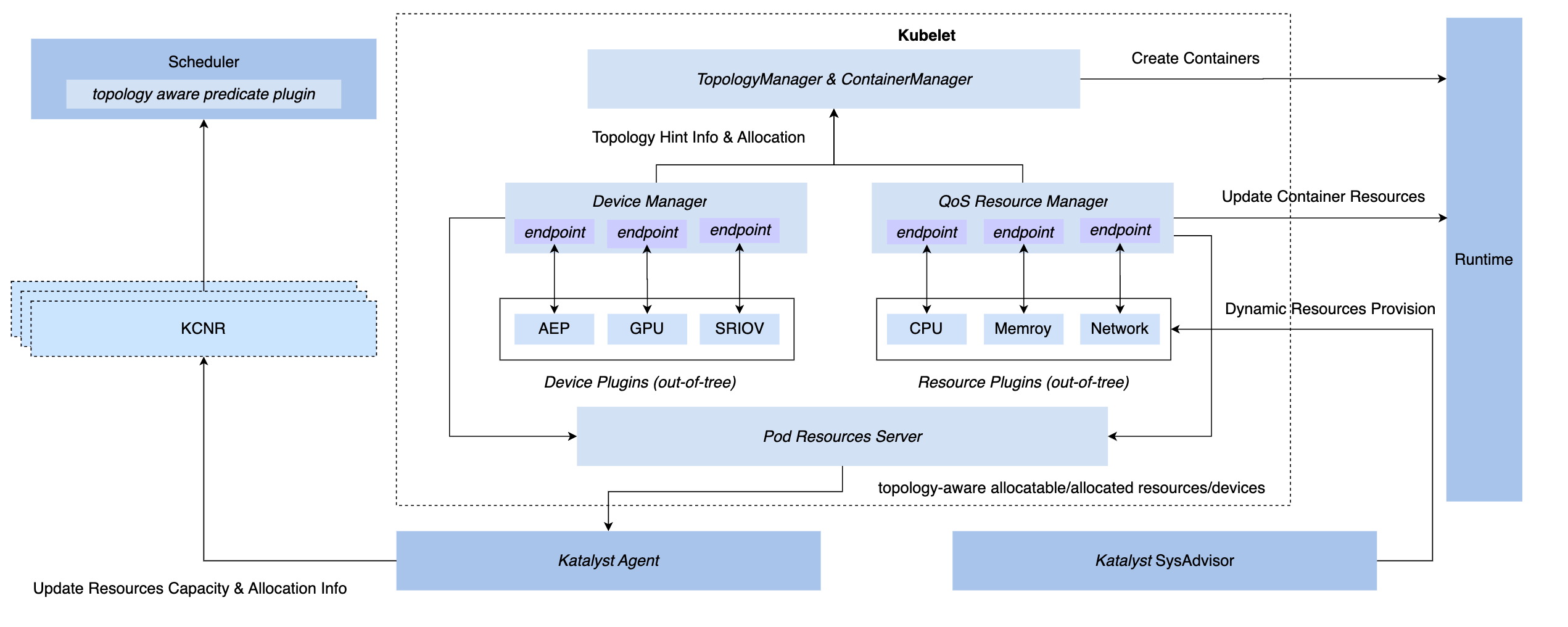
Para lograr capacidades de gestión y control sincrónicas en el sistema K8, tenemos tres métodos de enlace: inserción de capa CRI, capa OCI y capa Kubelet. Al final, Katalyst optó por implementar la gestión y el control en el lado de Kubelet, es decir, implementar un Administrador de recursos QoS al mismo nivel que el Administrador de dispositivos nativo. Las ventajas de este programa incluyen.
- Implemente la interceptación durante la etapa de admisión, eliminando la necesidad de depender de medidas encubiertas para lograr el control en los pasos posteriores.
- Conecte metadatos con Kubelet, informe información de microtopología de una sola máquina al nodo CRD a través de una interfaz estándar y realice el acoplamiento con el programador.
- Sobre la base de este marco, los complementos conectables se pueden implementar de manera flexible para satisfacer las necesidades personalizadas de gestión y control.
3.4 Estrategia inteligente: retrato de servicios y estimación de recursos
Por lo general, es más intuitivo optar por utilizar indicadores comerciales para crear un retrato del servicio, como el retraso del servicio P99 o la tasa de error descendente. Pero también hay algunos problemas. Por ejemplo, en comparación con los indicadores del sistema, generalmente es más difícil obtener indicadores comerciales; las empresas generalmente integran múltiples marcos y los significados de los indicadores comerciales que producen no son exactamente los mismos. Si se depende mucho de estos indicadores, toda la implementación del control se volverá muy complicada.
Por lo tanto, esperamos que el control final de recursos o el retrato del servicio se base en indicadores del sistema en lugar de indicadores comerciales. El más crítico es cómo encontrar los indicadores del sistema que más preocupan al negocio. canales para descubrir indicadores de negocio e indicadores del sistema. Por ejemplo, para el servicio en la figura, el indicador comercial principal es el retraso P99. A través del análisis, se encuentra que el indicador del sistema con la correlación más alta es el retraso en la programación de la CPU. Continuaremos ajustando el suministro de recursos del servicio para acercarnos. su objetivo tanto como sea posible retrasar la programación de la CPU.
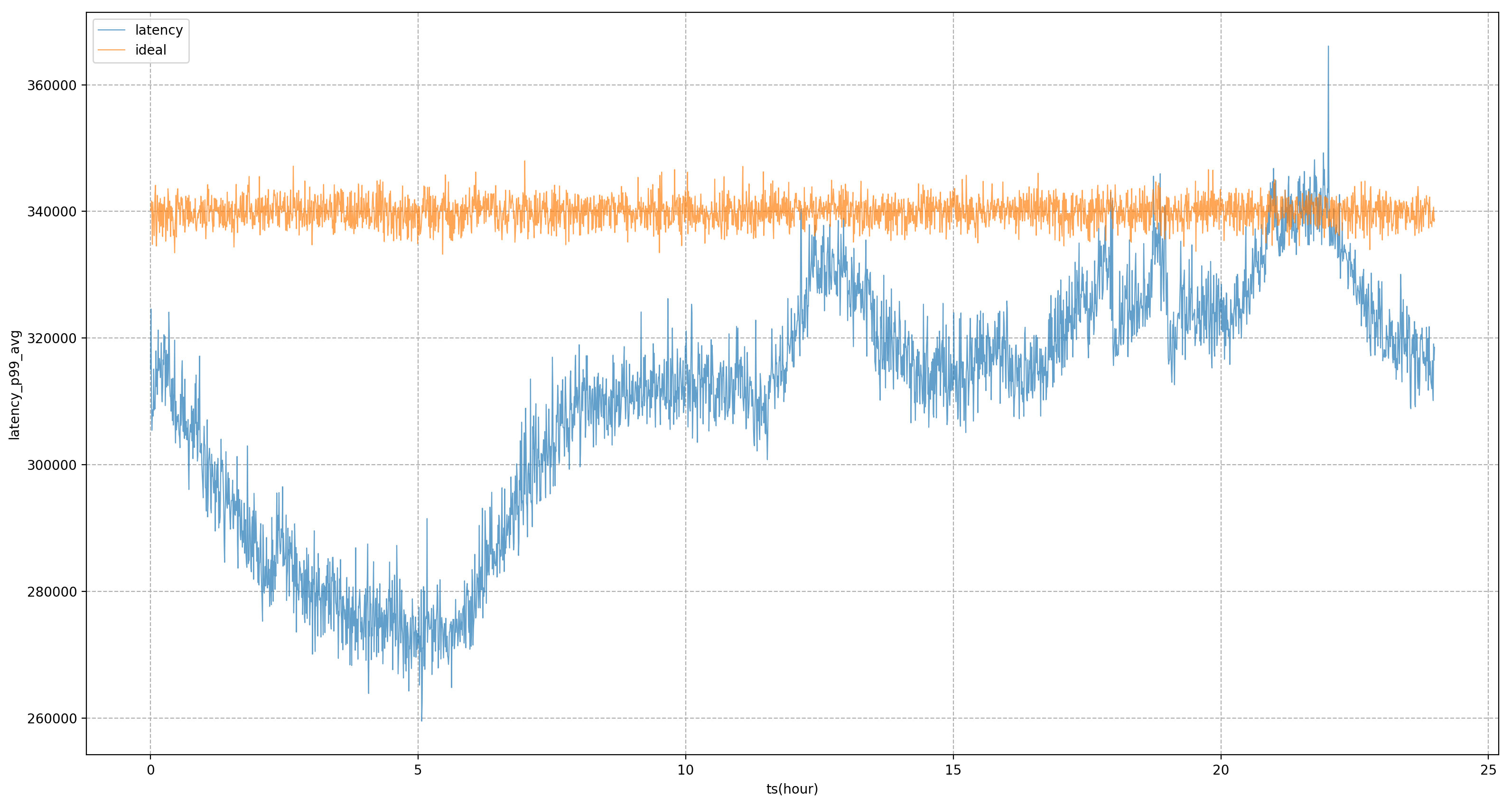
Sobre la base de los retratos de servicios, Katalyst proporciona mecanismos de aislamiento completos para CPU, memoria, disco y red, y personaliza el kernel cuando es necesario para proporcionar requisitos de rendimiento más estrictos. Sin embargo, estos medios no son necesariamente aplicables para diferentes escenarios y tipos de negocios; Es necesario enfatizar que el aislamiento es más un medio que un fin. En el proceso de emprender negocios, debemos elegir diferentes soluciones de aislamiento en función de necesidades y escenarios específicos.
3.5 Automatización de operación y mantenimiento: gestión de configuración dinámica multidimensional
Aunque esperamos que todos los recursos estén bajo un sistema de grupo de recursos, en un entorno de producción a gran escala, es imposible colocar todos los nodos en un clúster. Además, un clúster puede tener máquinas con CPU y GPU, aunque el plano de control puede; se puede compartir, pero se requiere cierto aislamiento en el plano de datos; a nivel de nodo, a menudo necesitamos modificar la configuración de la dimensión del nodo para la verificación en escala de grises, lo que resulta en diferencias en los SLO de diferentes servicios que se ejecutan en el mismo nodo.
Para resolver estos problemas, debemos considerar el impacto de las diferentes configuraciones de nodos en los servicios durante la implementación empresarial. Para ello, Katalyst proporciona capacidades de gestión de configuración dinámica para la entrega estándar, evaluando el rendimiento y la configuración de diferentes nodos a través de métodos automatizados y seleccionando el nodo más adecuado para el servicio en función de estos resultados.
4. Aplicación de coubicación de Katalyst y análisis de casos
En esta sección, compartiremos algunas de las mejores prácticas basadas en casos internos de Byte.
4.1 Efecto de utilización
En términos de los efectos de la implementación de Katalyst, según las prácticas comerciales internas de Byte, nuestros recursos se pueden mantener en un estado relativamente alto durante el ciclo trimestral; en un solo clúster, la utilización de recursos también muestra un nivel relativamente alto en varios períodos de tiempo de cada día. Distribución estable; al mismo tiempo, la utilización de la mayoría de las máquinas en el clúster también está relativamente concentrada y nuestro sistema de implementación híbrida se ejecuta de manera relativamente estable en todos los nodos.
| Algoritmo de previsión de recursos | Proporción de recursos recuperados | Utilización promedio de CPU a nivel diario | Uso máximo de CPU a nivel diario |
|---|---|---|---|
| Buffer fijo de utilización | 0,26 | 0,33 | 0,58 |
| algoritmo de agrupamiento k-medias | 0,35 | 0,48 | 0,6 |
| Algoritmo PID del indicador del sistema | 0,39 | 0,54 | 0,66 |
| Estimación del modelo de indicador del sistema + algoritmo PID | 0,42 | 0,57 | 0,67 |
4.2 Práctica: acceso sin sentido sin conexión
Después de ingresar a la tercera etapa, debemos llevar a cabo la transformación nativa de la nube fuera de línea. Hay dos métodos principales de transformación. Uno es para los servicios que ya están en el sistema K8. Conectaremos directamente el grupo de recursos basado en Virtual Kubelet. El otro es para los servicios bajo la arquitectura YARN si el servicio está conectado directamente al sistema Kubernetes. Una transformación completa del marco será muy costosa para la empresa y, en teoría, conducirá a actualizaciones continuas para todas las empresas. Obviamente, este no es un estado ideal.
Para resolver este problema, Byte se refiere a la capa adhesiva de Yodel, es decir, el acceso empresarial todavía utiliza la API Yarn estándar, pero en esta capa adhesiva, interactuaremos con la semántica subyacente de K8 y abstraeremos la solicitud de recursos del usuario; algo así como Pod o Descripción del contenedor. Este método nos permite utilizar tecnología K8 más madura en el nivel inferior para administrar recursos, lograr una transformación nativa de la nube fuera de línea y, al mismo tiempo, garantizar la estabilidad del negocio.
4.3 Práctica: Gobernanza de la operación de recursos
Durante el proceso de coubicación, debemos adaptar y transformar el marco de capacitación y big data, y realizar varios reintentos, puntos de control y calificaciones para garantizar que después de reducir estos trabajos de capacitación y big data a todo el conjunto de recursos de coubicación, La experiencia de usarlos no es tan mala.
Al mismo tiempo, necesitamos tener capacidades básicas completas en materia de recursos básicos, clasificación de negocios, gobernanza operativa y gestión de cuotas en el sistema. Si la operación no se realiza bien, la tasa de utilización puede ser muy alta durante ciertos períodos pico, pero puede haber una gran brecha de recursos durante otros períodos, lo que hace que la tasa de utilización no cumpla con las expectativas.
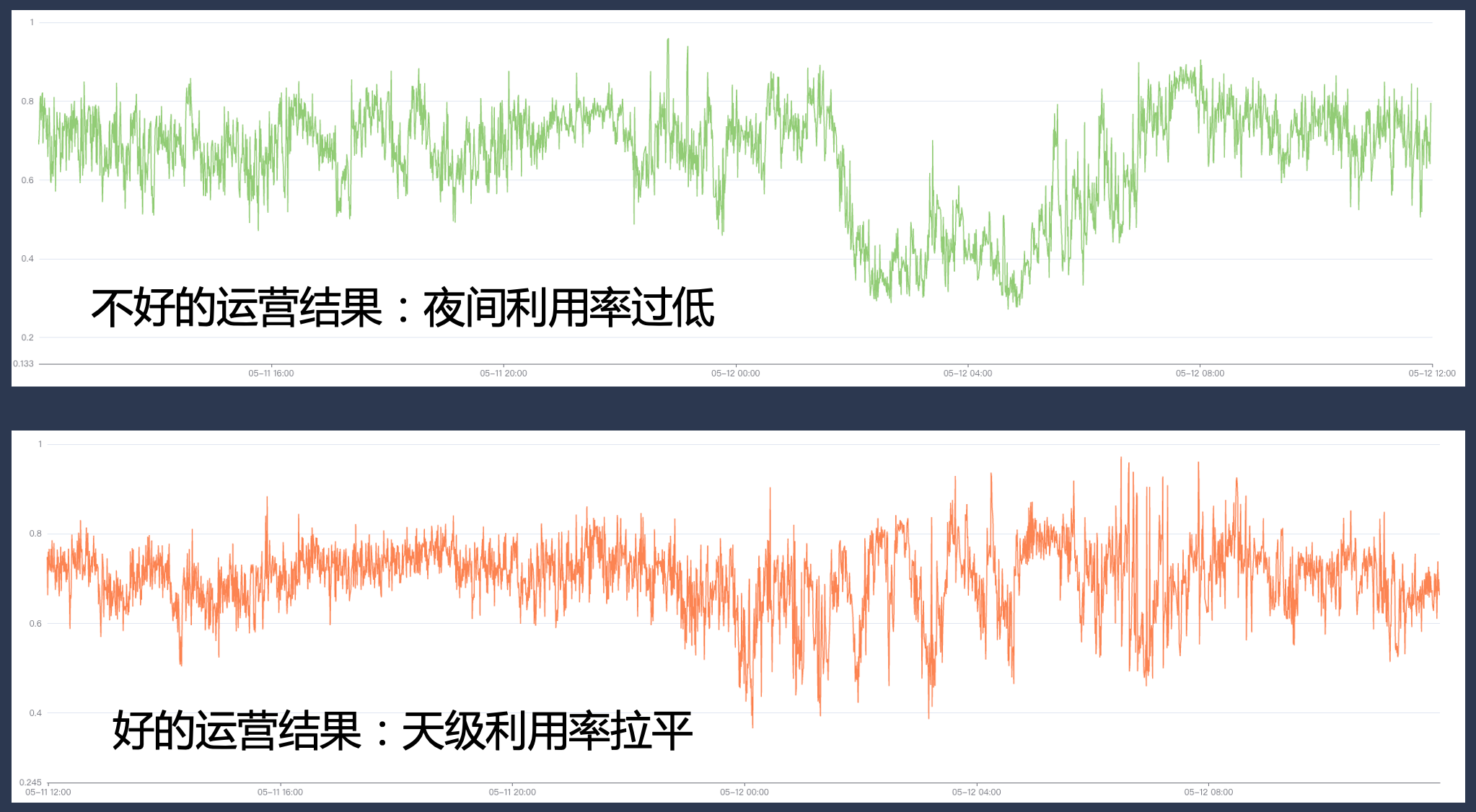
4.4 Práctica: Maximizar la mejora de la eficiencia de los recursos
Al crear retratos de servicios, utilizamos indicadores del sistema para la gestión y el control. Sin embargo, los indicadores estáticos del sistema basados en análisis fuera de línea no pueden mantenerse al día con los cambios en el lado comercial en tiempo real. Es necesario analizar los cambios en el desempeño comercial dentro de un cierto período de tiempo. Es hora de ajustar los valores estáticos.
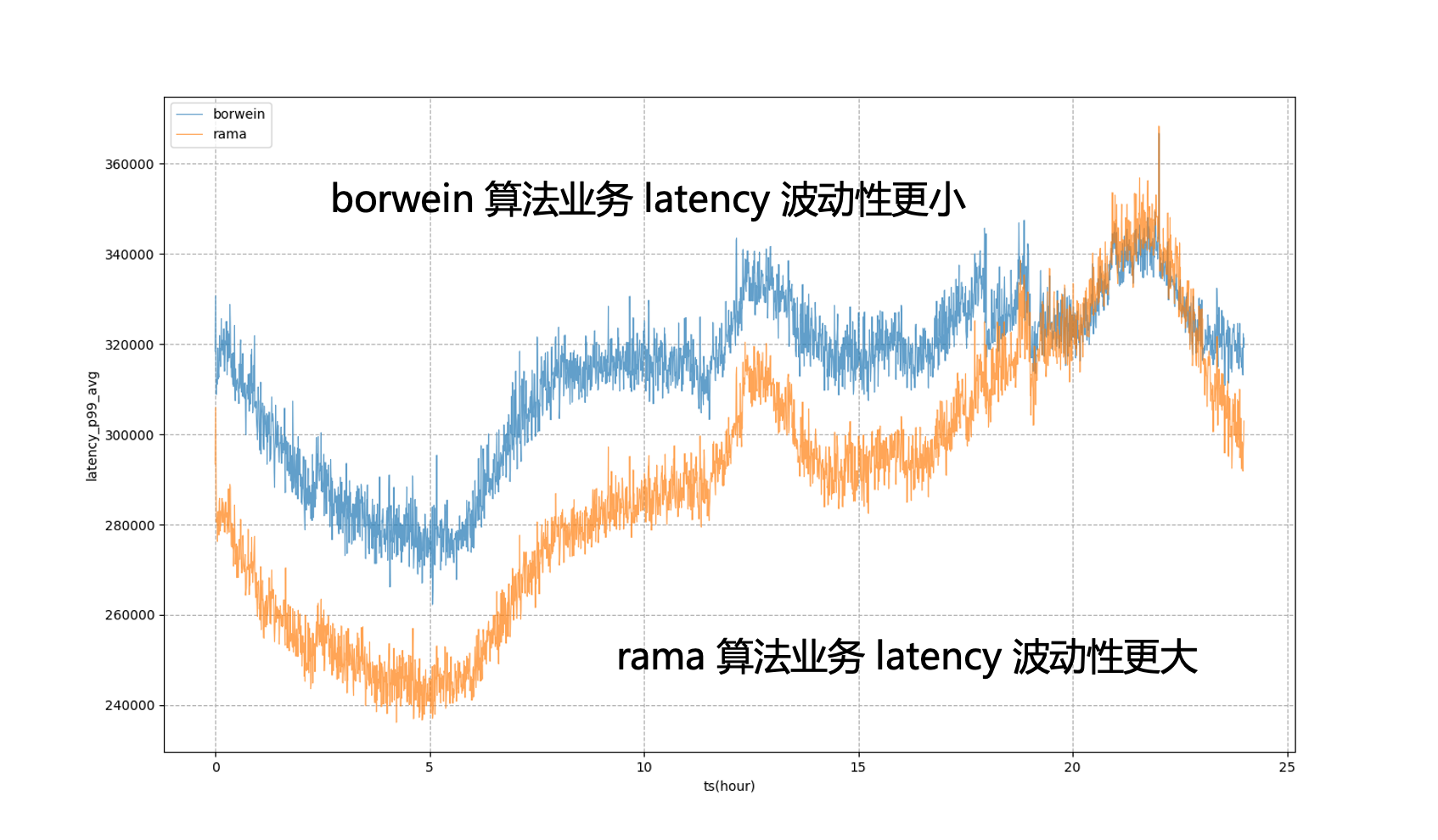
Con este fin, Katalyst introduce modelos para ajustar las métricas del sistema. Por ejemplo, si pensamos que el retraso en la programación de la CPU puede ser de x milisegundos, y después de un período de tiempo, calculamos a través del modelo que el retraso del objetivo comercial puede ser de y milisegundos, podemos ajustar dinámicamente el valor del objetivo para evaluar mejor el rendimiento del negocio.
Por ejemplo, en la figura siguiente, si los objetivos del sistema estático se utilizan completamente para la regulación, el negocio P99 estará en un estado de fluctuación severa, lo que significa que durante las horas pico no vespertinas, no podemos reducir el uso de recursos comerciales a un nivel más alto. estado extremo para acercarlo al negocio La cantidad que se puede tolerar durante las horas pico de la tarde después de introducir el modelo, podemos ver que el retraso del negocio será más estable, lo que nos permitirá nivelar el desempeño del negocio a un nivel relativamente estable; durante todo el día y obtener beneficios de recursos.
4.5 Práctica: Resolver problemas de una sola máquina
En el proceso de promoción de la coubicación, continuaremos encontrando varios problemas de rendimiento en línea y fuera de línea y demandas para la gestión de microtopología. Por ejemplo, inicialmente todas las máquinas se administraban y controlaban en base a cgroup V1. Sin embargo, debido a la estructura de V1, el sistema necesita atravesar un árbol de directorios muy profundo y consumir una gran cantidad de CPU en modo kernel para resolver este problema. , estamos cambiando los nodos de todo el clúster a cgroup V1. La arquitectura de cgroup V2 nos permite aislar y monitorear recursos de manera más eficiente para servicios como la búsqueda de promociones; para lograr un rendimiento más extremo, necesitamos implementar una afinidad más compleja; y estrategias anti-afinidad a nivel de Socket/NUMA, etc. Etc., estos requisitos de gestión de recursos más avanzados se pueden realizar mejor en Katalyst.
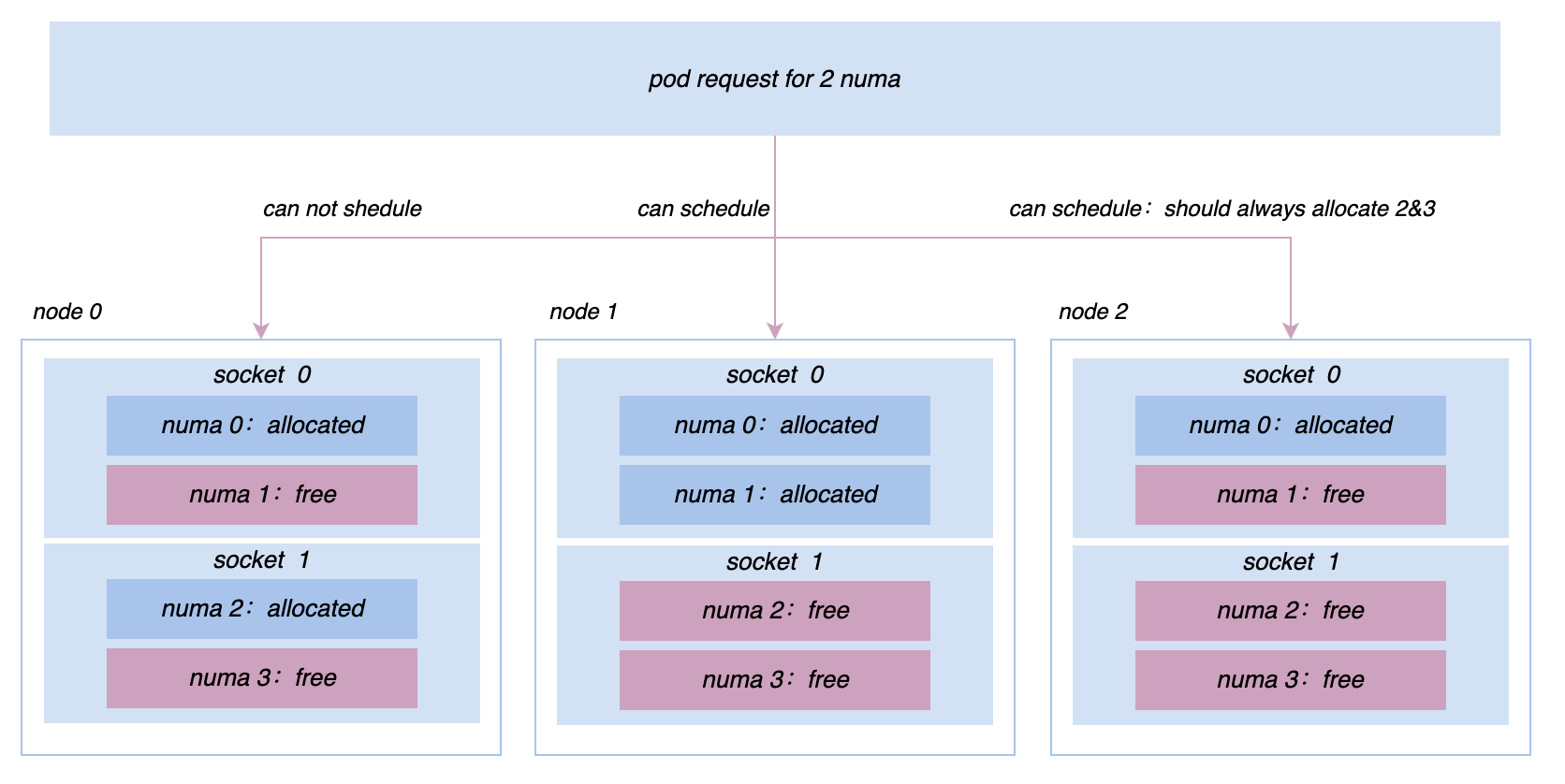
5 Resumen y perspectivas
Katalyst ha sido oficialmente de código abierto y lanzó la versión v0.3.0, y continuará invirtiendo más energía en la iteración; la comunidad desarrollará capacidades y mejoras del sistema en aislamiento de recursos, perfiles de tráfico, estrategias de programación, estrategias elásticas, administración de dispositivos heterogéneos, etc. Todos pueden prestar atención, participar en este proyecto y brindar comentarios.
¡Compañero pollo deepin-IDE de "código abierto" y finalmente logró el arranque! Buen chico, Tencent realmente ha convertido Switch en una "máquina de aprendizaje pensante" Revisión de fallas de Tencent Cloud del 8 de abril y explicación de la situación Reconstrucción de inicio de escritorio remoto de RustDesk Cliente web Base de datos de terminal de código abierto WeChat basada en SQLite WCDB marcó el comienzo de una actualización importante Lista de abril de TIOBE: PHP cayó a un mínimo histórico, Fabrice Bellard, el padre de FFmpeg, lanzó la herramienta de compresión de audio TSAC , Google lanzó un modelo de código grande, CodeGemma , ¿te va a matar? Es tan bueno que es de código abierto: herramienta de edición de carteles e imágenes de código abiertoVideo del discurso de la conferencia: Katalyst: Práctica de optimización de costos nativos de Bytedance Cloud |