Inhaltsverzeichnis
MDP (Markov-Entscheidungsprozess) Markov-Entscheidungsprozess
Elemente und Architektur des Reinforcement Learning
Grundwissen
MDP (Markov-Entscheidungsprozess)Markov-Entscheidungsprozess Prozess
MDP (Markov Decision Process) ist ein mathematisches Framework zur Beschreibung von Problemen mit Zufälligkeit und sequenzieller Entscheidungsfindung. Bei MDP ergreift der Agent kontinuierlich Maßnahmen und beobachtet durch Interaktion mit der Umgebung Rückmeldungen aus der Umgebung, wodurch er Strategien erlernt, um in verschiedenen Zuständen optimale Maßnahmen zu ergreifen. MDP wird häufig im Bereich des Reinforcement Learning eingesetzt.
MDP enthält die folgenden Elemente:
Zustand: Der Zustand des Agenten zu einem bestimmten Zeitpunkt.
Aktion: Die Aktion, die der Agent in einem bestimmten Zustand durchführt.
Belohnung: Die Belohnung oder Bestrafung, die ein Agent erhält, nachdem er in einem bestimmten Zustand eine Aktion ausgeführt hat.
Übergangswahrscheinlichkeit: Die Wahrscheinlichkeit, dass ein Agent von einem Zustand in einen anderen übergeht.
Abzinsungsfaktor: Wird verwendet, um den Wert zukünftiger Belohnungen zu messen, normalerweise zwischen 0 und 1.
Richtlinie: Die Regeln, nach denen ein Agent in jedem Status Maßnahmen ergreifen soll.

Beim MDP besteht das Ziel des Agenten darin, eine optimale Strategie zu finden, die seine angesammelten Belohnungen langfristig maximiert. Um dieses Ziel zu erreichen, muss der Agent durch Versuch und Irrtum lernen, wie wichtig es ist, in verschiedenen Zuständen unterschiedliche Maßnahmen zu ergreifen, und auf der Grundlage dieser Werte die beste Maßnahme auswählen. Die Wertfunktion und die Q-Funktion sind in MDP häufig verwendete Funktionen zur Darstellung von Werten.
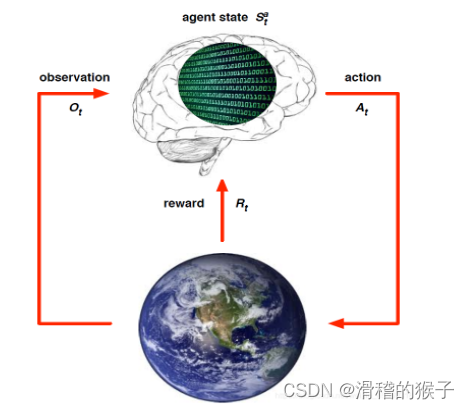
Elemente und Architektur des Reinforcement Learning
Reinforcement-Learning-Systeme umfassen im Allgemeinen vier Elemente: Richtlinie, Belohnung, Wert und Umgebung oder Modell.
Richtlinie: Richtlinie definiert das Verhalten eines Agenten für einen bestimmten Status.
Belohnung: Das Belohnungssignal definiert das Ziel des Reinforcement-Learning-Problems
Wert: Oder Wertfunktion. Im Gegensatz zur Unmittelbarkeit von Belohnungen ist die Wertfunktion ein Maß für den langfristigen Nutzen.
Umgebung (Modell): Die äußere Umgebung, auch Modell (Modell) genannt, ist eine Simulation der Umgebung
Architektur des verstärkenden Lernens

Algorithmisches Denken
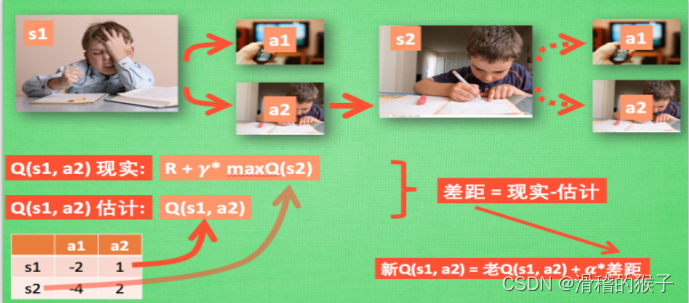
Der Q-Learning-Algorithmus ist ein verstärkender Lernalgorithmus, der auf Werteiteration basiert und zum Erlernen der optimalen Strategie für die Interaktion eines Agenten mit der Umgebung verwendet wird. Die Grundidee dieses Algorithmus besteht darin, die Aktionsauswahl durch das Erlernen einer Q-Wert-Funktion zu steuern. Die Q-Wert-Funktion stellt die erwartete Rendite einer Aktion in einem bestimmten Zustand dar.
Im Q-Learning-Algorithmus aktualisiert der Agent die Q-Wert-Funktion kontinuierlich durch Interaktion mit der Umgebung. Konkret beobachtet der Agent den aktuellen Zustand s_t in jedem Zeitschritt t, wählt eine Aktion a_t basierend auf dem aktuellen Zustand und der Q-Wert-Funktion aus und beobachtet nach der Ausführung den nächsten Zustand s_{t+1} und die entsprechende Belohnung r_{ die Aktion. t+1} und aktualisieren Sie die Q-Wert-Funktion gemäß der Q-Learning-Aktualisierungsregel. Die Aktualisierungsregeln lauten wie folgt:
Q(s,a)←Q(s,a)+α[r+γmaxa′Q(s′,a′)−Q(s,a)]
Unter diesen stellt Q(s,a) den Q-Wert der Aktion a im Zustand s dar und gibt den Wert der aktuellen Aktion an, α ist die Lernrate, γ ist der Abzinsungsfaktor, maxa′Q(s′, a′) stellt den nächsten Zustand dar. s′ ist der maximale Q-Wert, der durch die optimale Aktion erhalten wird.
Die Kernidee des Q-Learning-Algorithmus besteht darin, die Aktionsauswahl durch kontinuierliche Aktualisierung der Q-Wert-Funktion zu steuern und letztendlich eine optimale Strategie zu erlernen. In der praktischen Anwendung erfordert der Algorithmus eine Diskretisierung des Zustandsraums und des Aktionsraums, um diese als Q-Werte-Tabelle darzustellen. Gleichzeitig können Techniken wie Erfahrungswiedergabe und Erkundungsstrategien eingesetzt werden, um die Stabilität und Konvergenzgeschwindigkeit des Algorithmus zu erhöhen.

Code
Regeln aktualisieren
def get_update(row, col, action, reward, next_row, next_col):
#target为下一个格子的最高分数,这里的计算和下一步的动作无关
target = 0.9 * Q[next_row, next_col].max()
#加上本步的分数
target += reward
#value为当前state和action的分数
value = Q[row, col, action]
#根据时序差分算法,当前state,action的分数 = 下一个state,action的分数*gamma + reward
#此处是求两者的差,越接近0越好
update = target - value
#这个0.1相当于lr
update *= 0.1
return update
get_update(0, 0, 3, -1, 0, 1)Zug
def train():
for epoch in range(1500):
#初始化当前位置
row = random.choice(range(4))
col = 0
#初始化第一个动作
action = get_action(row, col)
#计算反馈的和,这个数字应该越来越小
reward_sum = 0
#循环直到到达终点或者掉进陷阱
while get_state(row, col) not in ['terminal', 'trap']:
#执行动作
next_row, next_col, reward = move(row, col, action)
reward_sum += reward
#求新位置的动作
next_action = get_action(next_row, next_col)
#计算分数
update = get_update(row, col, action, reward, next_row, next_col)
#更新分数
Q[row, col, action] += update
#更新当前位置
row = next_row
col = next_col
action = next_action
if epoch % 100 == 0:
print(epoch, reward_sum)
train()Vollständiger Code: im 4-Zeit-Sequenzbewertungsalgorithmushttps://download.csdn.net/download/qq_46684028/88076627