El artículo original número 93 se centra en "el crecimiento personal y la libertad de riqueza, la lógica de la operación mundial, la inversión cuantitativa de IA".
Hoy quiero hablar sobre el aprendizaje por refuerzo.
En mi opinión, el aprendizaje por refuerzo es el paradigma más adecuado para la inversión financiera. En realidad no es un algoritmo específico, sino un paradigma.
A diferencia del aprendizaje supervisado, el aprendizaje supervisado es "único" con etiquetas explícitas. En analogía con el aprendizaje humano, no usaremos 10,000 imágenes de gatos para que los niños aprendan qué es un gato. Es posible que un niño solo haya visto unos pocos gatos, y casi puede reconocer todo tipo de imágenes, abstractas y gatos de dibujos animados. El aprendizaje en el cerebro humano es un mecanismo de incentivo-retroalimentación. Cuando haces una acción y obtienes una retroalimentación positiva, puedes fortalecer la acción, y si obtienes una retroalimentación negativa, puedes debilitar la acción.
Cuando aprendemos a andar en bicicleta, no usamos fórmulas físicas para calcular el ángulo entre el cuerpo humano y el suelo, cómo ejercer fuerza sobre el brazo, sino simplemente montarlo. La bicicleta y el suelo te dan retroalimentación, y te ajustas en consecuencia.
En resumen, el agente ajusta sus acciones al interactuar con el entorno y obtener retroalimentación inmediata hasta que aprende una determinada habilidad. - la adopción de tal paradigma de aprendizaje. Entonces, hay maestros de Go como alpha go, alpha master y alpha zero, y luego sus habilidades se transfieren para jugar juegos estratégicos, y también son jugadores de primera clase, todo gracias al aprendizaje por refuerzo.
En el modelo DNN del que hablamos ayer, dejamos que el modelo aprenda los factores pasados para "predecir" los "altibajos" del precio de cierre del día. Pero en el proceso comercial real, no compraremos solo porque juzguemos que subirá hoy y lo venderemos si bajará mañana.
La inversión es una serie de decisiones que buscan la tasa de rendimiento durante un período de tiempo, no los altibajos de un día determinado o de unos pocos días. Este tipo de juego de rondas múltiples y juego de rondas múltiples con costo es perfecto para usar el aprendizaje por refuerzo.
01 Aprendizaje por refuerzo
Importar configuración general general:
importarnos
importar matemáticas
importar aleatoriamente
importar numpy como np
importar pandas como pd
de pylab importar plt, mpl
plt.style.use('seaborn')
mpl.rcParams['savefig.dpi'] = 300
mpl.rcParams['font.family'] = 'serif'
np.set_printoptions(precisión=4, suprimir=Verdadero)
os.environ['PYTHONHASHSEED'] = '0'
Implemente una clase de espacio de observación, que es un vector N-dimensional, donde la dimensión de n es igual al número de nuestros factores .
clase espacio_observación:
def __init__(self, n):
self.shape = (n,)
Espacio de acción, aquí el espacio de acción es 2 (comprar, vender)
class action_space:
def __init__(self, n):
self.n = n
def seed(self, seed):
pass
def sample(self):
return random.randint(0, self.n - 1)
Entorno comercial simulado:
Además de preparar los datos de transacción en el entorno de transacción, lo más importante es la función de paso. Nuestra recompensa aquí sigue siendo similar al DNN de ayer. Si el agente adivina correctamente una vez, la recompensa agregará 1 punto .
Salga cuando la tasa de precisión sea inferior al 47,5 % o salga al final de un episodio .
Es equivalente a hacer un juego de comercio. Entra un agente y "adivina". Si la suposición es correcta, se agrega 1 punto para calcular la tasa de precisión. Si es inferior al 47,5%, quedará fuera del juego.
clase Finanzas:
url = 'http://hilpisch.com/aiif_eikon_eod_data.csv'
def __init__(self, símbolo, características):
self.symbol = símbolo
self.features = características
self.observation_space = observe_space(4)
self.osn = self.observation_space.shape[0]
self.action_space = action_space(2)
self.min_accuracy = 0.475
self._get_data()
self._prepare_data()
def _get_data(self):
self.raw = pd.read_csv(self.url, index_col =0,
parse_dates=True).dropna()
def _prepare_data(self):
self.data = pd.DataFrame(self.raw[self.symbol])
self.data['r'] = np.log(self.data / self.data.shift(1))
self.data.dropna(inplace=True)
self.data = (self.data - self.data.mean()) / self.data.std()
self.data['d'] = np.where(self. data['r'] > 0, 1, 0)
def _get_state(self):
return self.data[self.features].iloc[
self.bar - self.osn:self.bar].values
def seed(self, seed=Ninguno):
pass
def reset(self):
self.treward = 0
self.accuracy = 0
self.bar = self.osn
state = self.data[self.features].iloc[
self.bar - self.osn: self.bar]
return estado.valores
def paso(self, action):
correcto = action == self.data['d'].iloc[self.bar]
recompensa = 1 si es correcto else 0
self.treward += recompensa
self.bar += 1
self.accuracy = self.treward / (self.bar - self.osn)
if self.bar >= len(self.data):
done = True
elif recompensa == 1:
done = False
elif (self.accuracy < self.min_accuracy and
self.bar > self.osn + 10):
done = True
else:
done = False
state = self._get_state()
info = { }
estado de retorno, recompensa, hecho, información
DRL de implementación del agente:
def set_seeds(seed=100):
random.seed(seed)
np.random.seed(seed)
env.seed(seed)
set_seeds(100)
from collections import deque
from keras.optimizers import Adam, RMSprop
from keras.layers import Dense , Deserción
de keras.models import Sequential
from keras.optimizers import Adam, RMSprop
from sklearn.metrics import precision_score
from tensorflow.python.framework.ops import disabled_eager_execution
disabled_eager_execution()
class DQLAgent:
def __init__(self, gamma=0.95, hu=24 , opt=Adam,
lr=0.001, finish=False):
self.finish = finish
self.epsilon = 1.0
self.epsilon_min = 0.01
modelo.add(Dense(env.action_space.n, activación='lineal'))
self.epsilon_decay = 0.995
self.gamma = gamma
self.batch_size = 32
self.max_treward = 0
self.averages = list()
self.memory = deque(maxlen=2000)
self.osn = env.observation_space.shape[0]
self .model = self._build_model(hu, opt, lr)
def _build_model(self, hu, opt, lr):
model = Sequential()
model.add(Dense(hu, input_dim=self.osn,
activación='relu') )
model.add(Dense(hu, activación='relu'))
model.compile(loss='mse', Optimizer=opt(lr=lr))
return model
def act(self, state):
si random.random() <= self.epsilon:
return env.action_space.sample()
action = self.model.predict(state )[0]
return np.argmax(action)
def replay(self):
lote = random.sample(self.memory, self.batch_size)
for estado, acción, recompensa, siguiente_estado, hecho en lote:
si no está hecho:
recompensa + = self.gamma * np.amax(
self.model.predict(next_state)[0])
target = self.model.predict(state)
target[0, action] = recompensa
self.model.fit(state, target, epochs =1,
verbose=False)
if self.epsilon > self.epsilon_min:
estado = siguiente_estado
self.epsilon *= self.epsilon_decay
def aprender(auto, episodios):
trewards = []
for e in range(1, episodios + 1):
state = env.reset()
state = np.reshape(state, [1, self.osn])
for _ in range(5000):
action = self.act(state)
next_state, recompensa, hecho, info = env.step(action)
next_state = np.reshape(next_state,
[1, self.osn])
self.memory.append([ estado, acción, recompensa,
siguiente_estado, hecho])
treward = _ + 1
trewards.append(treward)
si se hace:
av = sum(trewards[-25:]) / 25
self.averages.append(av)
self.max_treward = max(self.max_treward, treward)
templ = 'episode: {:4d}/{} | treward: {:4d} | '
templ += 'av: {:6.1f} | max: {:4d}'
print(templ.format(e, episodios, treward, av,
self.max_treward), end='\r')
romper
si av > 195 y self.finish:
print()
romper
si len( self.memory) > self.batch_size:
self.replay()
def test(self, episodios):
trewards = []
para e en el rango (1, episodios + 1):
estado = env.reset ()
para _ en el rango (5001):
estado = np.reshape (estado, [1, self.osn])
acción = np .argmax(self.model.predict(estado)[0])
siguiente_estado, recompensa, hecho, información = env.paso(acción)
estado = siguiente_estado
si está hecho:
treward = _ + 1
trewards.append(treward)
print('episode : {:4d}/{} | treward: {:4d}'
.format(e, episodios, treward), end='\r')
romper
return trewards
Centrarse en la función de aprendizaje:
Cada episodio se ejecuta 5000 veces y se cerrará si falla. DRL tiene un mecanismo de reproducción, del que hablaremos cuando hablemos de algoritmos de aprendizaje por refuerzo en el sistema.
Tomó 22 minutos entrenar este modelo.

02 DRL se aplica a la inversión real
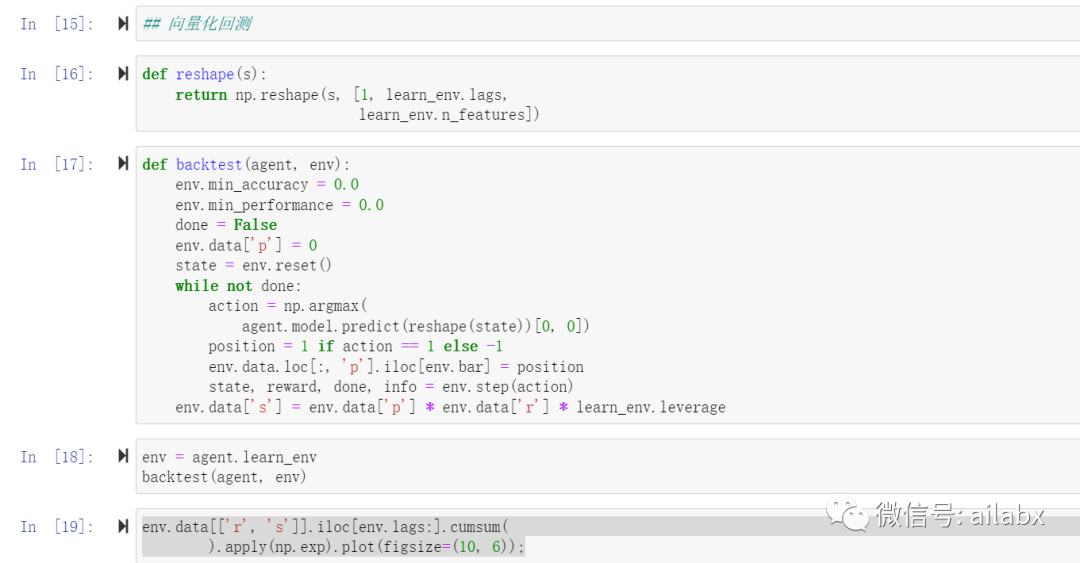
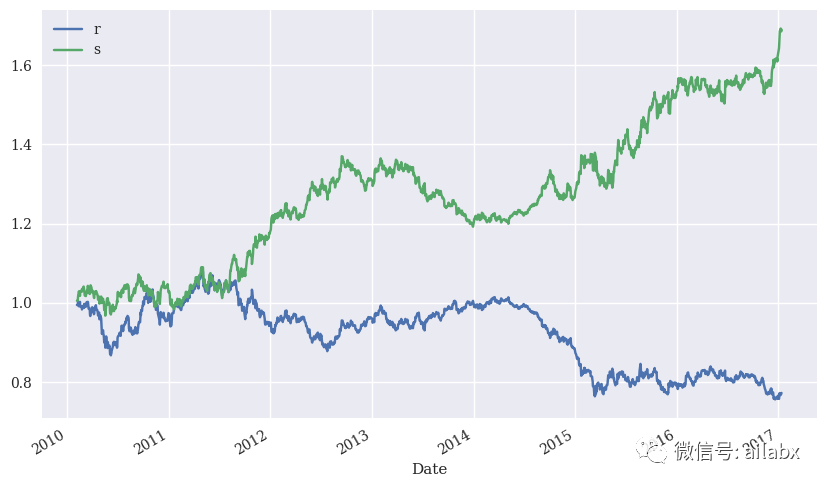
El rendimiento en la muestra sigue siendo bueno, veamos el rendimiento fuera de la muestra:

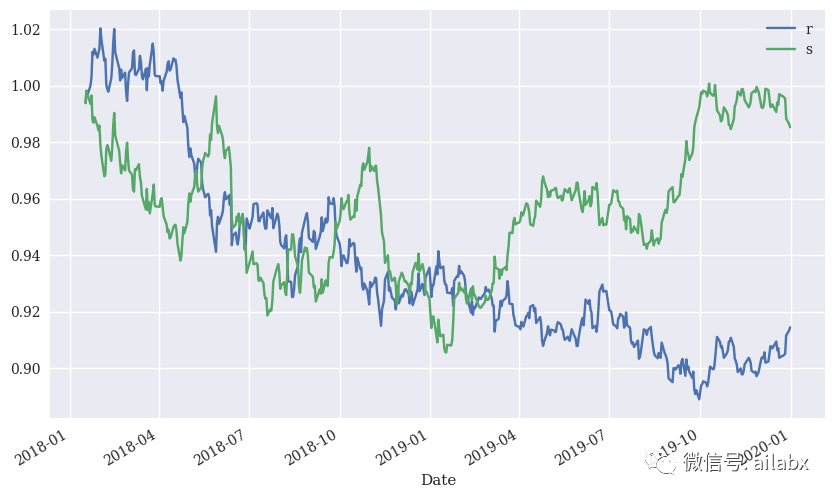
Está bien, pero tenga en cuenta que la tarifa de manejo no se considera aquí.
resumen:
Este artículo se enfoca en demostrar cómo funciona el aprendizaje por refuerzo en datos de series de tiempo financieras, esta dirección debe ser factible y debe explorarse en profundidad.