Tabla de contenido
2. El aprendizaje profundo presenta desafíos de optimización
3. Convexidad y funciones convexas.
3.3 Optimización de la función convexa
3.4 Ejemplos convexos y no convexos
4. Método de descenso de gradiente
4.1 Método de descenso de gradiente unidimensional
4.2 Método de descenso de gradiente multidimensional
1. ¿Qué es un optimizador?
El optimizador (Optimizer) es un componente importante en el aprendizaje automático y el aprendizaje profundo, que se utiliza para ajustar los parámetros del modelo para minimizar (o maximizar) la función de pérdida. El objetivo principal del optimizador es minimizar el valor de la función de pérdida actualizando los parámetros del modelo. Es un componente clave en el entrenamiento del modelo, ya que ayuda al modelo a converger gradualmente a la configuración de parámetros óptima para mejorar el rendimiento del modelo.
2. El aprendizaje profundo presenta desafíos de optimización
Se puede dividir principalmente en los siguientes tres puntos: Mínimo local, punto de silla y desaparición del gradiente. Mediante la optimización continua del algoritmo, se pueden aliviar los problemas anteriores (como optimizador de impulso ( Momentum), optimizador Adam, etc.).
2.1 Mínimo local

Como se muestra en la figura anterior para una función f (x), el mínimo local es el mínimo local, mientras que el mínimo global es el mínimo global. Durante el proceso de optimización, el mínimo local puede confundirse con el mínimo global.
2.2 Punto de silla
Los puntos de silla son otra razón para que los gradientes desaparezcan. Un punto de silla (punto de silla) es cualquier posición donde todos los gradientes de una función desaparecen pero no hay un mínimo global ni un mínimo local. Considere esta función (que se muestra a continuación) f(x) = . La optimización puede detenerse en este punto, aunque no es el valor mínimo. = 0x . Su primera y segunda derivada desaparecen cuando ^3x

Otro tipo defunciónf(x, y ) = x2 - y2. Su punto de silla es (0, 0). Este es el valor máximo con respecto a y y el valor mínimo con respecto a x . Además, parece una silla de montar, de ahí el nombre del punto de silla (como se muestra en la imagen a continuación, el punto de silla está rodeado por un círculo rojo).
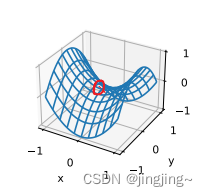
2.3 La elevación desaparece
Desaparición de gradiente, especialmente cuando se entrena con redes neuronales profundas (con múltiples capas ocultas). Este problema suele ocurrir cuando se utiliza el descenso de gradiente o sus variantes para la retropropagación. El gradiente de la red neuronal disminuye gradualmente hasta casi cero, lo que hace que los pesos de las neuronas subyacentes casi ya no se actualicen, lo que hace que las características aprendidas por la capa de red subyacente sean inestables o no válidas.
3. Convexidad y funciones convexas.
3.1 colección convexa
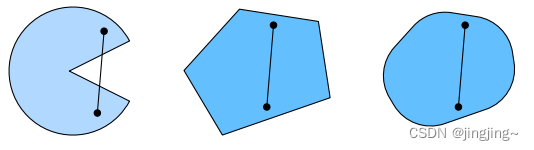
El conjunto convexo (conjunto convexo) es la base de la convexidad. En pocas palabras, si para cualquier a, b ∈ X, el segmento de línea que conecta a y b también se encuentra en X, entonces un conjunto Después de la línea, hay una parte que no está en la tendencia, es decir, no está en la tendencia. convexo, mientras que las dos figuras de la derecha son convexas.
3.2 Función convexa
Si la función f :C→R es convexa si y solo si f(ax +(1 - a)y)≤af(x)+(1 -a)f(y) , todo a ∈[0,1], todos x,y∈c. Si la desigualdad se cumple estrictamente cuando x ≠ y,a ∈ (0,1), entonces se llama función estrictamente convexa, como se muestra en la siguiente figura.

3.3 Optimización de la función convexa
Si la función de costo f es convexa y el conjunto de restricciones C es convexo, entonces se trata de un problema de optimización convexo. Entonces el mínimo local debe ser el mínimo global. Los problemas de optimización estrictamente convexos tienen un mínimo global único.
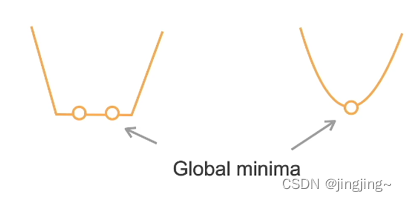
La figura de la izquierda en la figura anterior no es una función estrictamente convexa, por lo que el punto óptimo no es único. La figura de la derecha es una función estrictamente convexa y el punto óptimo es único.
3.4 Ejemplos convexos y no convexos
1. convexo
Regresión lineal f(x)= l|Wx-bl.
Softmax regresa
2. No convexo: otro
MLP, CNN, RNN, atención, ..., entre las cuales CNN es una función de activación lineal.
Los modelos de aprendizaje profundo son en su mayoría no convexos
Puede consultar las Secciones 1-3: el libro "Aprendizaje profundo práctico" y el vídeo:72 Algoritmo de optimización [Aprendizaje profundo práctico v2]_bilibili_bilibili
4. Método de descenso de gradiente
Hay tres formas diferentes de descenso de gradiente:
Descenso de gradiente por lotes BGD,Descenso de gradiente estocásticoSGD, descenso de gradiente mini-batch MBGD
4.1 Método de descenso de gradiente unidimensional
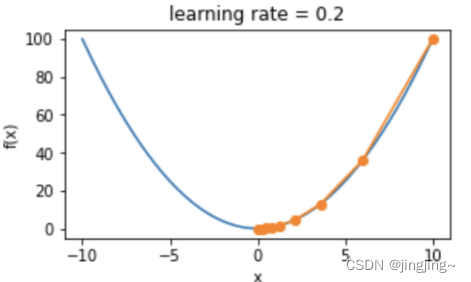
El método de iteración es: , tomando f (x) = x ^ 2 como ejemplo, la tasa de aprendizaje es 0,2 y el descenso del gradiente se muestra en la siguiente figura.
, tomando f (x) = x ^ 2 como ejemplo, la tasa de aprendizaje es 0,2 y el descenso del gradiente se muestra en la siguiente figura.
4.2 Método de descenso de gradiente multidimensional
Cómo transferir: , luegof(X )=x1^2+2x2^2
, luegof(X )=x1^2+2x2^2
Por ejemplo, la tasa de aprendizaje es 0,4, como se muestra en la figura siguiente, donde la línea azul es la línea de contorno de la función objetivo y la línea naranja es el punto óptimo de descenso del gradiente.

5. Impulso
Idea: dejar que la actualización de parámetros tenga inercia. Cada paso de actualización se basa en la acumulación de gradientes anteriores v y el gradiente del actual. se combina el punto v a> . g
Oficial:
Actualización de nivel acumulativo:v←αv+( 1−α)g. Entre ellos, < a i =9>αNivel de acumulación,vNivel de acumulación,v < /span>∗< /span> vη−w←wTasa de avance, nivel actualizado: ηNivel habitual,
ventaja:
1. Acelerar la convergencia puede ayudar a que los parámetros se aceleren en la dirección correcta.
2. Puede ayudar a superar los mínimos locales
6、Adagrado
El algoritmo de optimización de Adagrad se denomina algoritmo de optimización de la tasa de aprendizaje adaptativo. El método de descenso de gradiente estocástico mencionado anteriormente utiliza la misma tasa de aprendizaje fija para optimizar todos los parámetros, pero los gradientes de diferentes parámetros pueden diferir mucho. , utilizando la misma tasa de aprendizaje, el efecto no será muy bueno.
Adagrad Idea: establecer diferentes tasas de aprendizaje para diferentes parámetros.
Método: para cada parámetro, inicialice un gradiente cuadrado acumulativo r=0 y luego agregue la suma de los gradientes cuadrados del parámetro a esta variable cada vez r Arriba:![]()
Luego, al actualizar este parámetro, la tasa de aprendizaje pasa a ser:
Actualización de peso:
Entre ellos, g es el gradiente; r es el gradiente de acumulación al cuadrado (inicialmente 0); η es la tasa de aprendizaje; δ Es un parámetro pequeño, evita que el denominador sea 0, y generalmente toma el valor de 10 menos 10 veces.
De esta manera, diferentes parámetros tienen diferentes gradientes y sus tamaños r correspondientes también son diferentes, por lo que las tasas de aprendizaje también son diferentes. Esto también es Se logra una tasa de aprendizaje adaptativo.
Resumen: la idea central de Adagrad es que si el gradiente de un parámetro es siempre muy grande, entonces su tasa de aprendizaje correspondiente se vuelve un poco más pequeño, evita la oscilación, y el gradiente de un parámetro siempre ha sido muy pequeño , entonces la tasa de aprendizaje de este parámetro aumenta, lo que permite que se actualice más rápido. Así es como el algoritmo de Adagrad acelera el Entrenamiento de redes neuronales profundas.
7、RMSProp
RMSProp: Propagación de raíz cuadrática media
RMSProp se basa en adagrad y se optimiza aún más en la dirección de la tasa de aprendizaje.
gradiente cuadrado acumulado:![]()
Actualización de parámetros:![]()
Entre ellos, g es el gradiente, r es el gradiente cuadrado de acumulación (inicialmente 0), λ es el coeficiente de atenuación, η es la tasa de aprendizaje, δ es un parámetro pequeño (para evitar que el denominador sea 0).
8 、 Adán
Basado en Grandient Descent, se han realizado las siguientes mejoras:
1. Se agrega impulso al gradiente y se utiliza el gradiente acumulativo: ![]()
2. Al igual que el algoritmo de optimización RMSProp, la tasa de aprendizaje se optimiza y se utiliza el gradiente cuadrado acumulativo:![]()
3. Corrección de desviación:![]()
Según las tres mejoras anteriores, el peso se actualiza:![]()
¿Por qué realizar una corrección de sesgo?
Durante la primera actualización, ![]() , ya que el valor inicial de v0 es 0, y α está sesgado hacia 0. v es pequeño, tEl valor generalmente se establece cerca de 1, por lo que cuando
, ya que el valor inicial de v0 es 0, y α está sesgado hacia 0. v es pequeño, tEl valor generalmente se establece cerca de 1, por lo que cuando
9. Resumen
1. La mayoría de los modelos de aprendizaje profundo no son convexos.
2. El descenso de gradiente estocástico de mini lotes es el algoritmo de optimización más utilizado
3. El impulso suaviza el gradiente.
4. Adam suaviza el gradiente y regenera los valores de cada dimensión del gradiente.
10. Referencias
Referencia de la sección 1-3: libro "Aprendizaje profundo práctico" y vídeo: 72 Algoritmo de optimización [Aprendizaje profundo práctico v2]_bilibili_bilibili
4-8 puede consultar el blog:Optimizador (enzo-miman.github.io) y vídeo principal superior: https:/ / www.bilibili.com/video/BV1jh4y1q7ua/