

El 14 de noviembre, Ant Group y la Universidad Jiao Tong de Shanghai publicaron una revisión de 55 páginas de modelos de código grande, que cubre más de 50 modelos, 30 tareas posteriores y 500 referencias, que resume de manera integral los últimos avances y desarrollos de modelos de lenguaje grande en código. -aplicaciones relacionadas desafío.

Enlace del artículo: https://arxiv.org/abs/2311.07989
Repositorio: https://github.com/codefuse-ai/Awesome-Code-LLM
Publicado nuevamente por Twitter big V: https://twitter.com/_akhaliq/status/1724630901441585521
El repositorio continuará actualizándose para agregar los artículos más recientes, todos pueden prestar atención.
1. Introducción
Con la aparición de grandes modelos de lenguaje en todas partes, cómo combinarlos eficazmente con aplicaciones prácticas, especialmente aplicaciones relacionadas con la ingeniería de software, se ha convertido en una cuestión de creciente preocupación tanto para el mundo académico como para la industria. Sin embargo, estas aplicaciones todavía son muy limitadas en la actualidad: las tareas de generación de código representadas por HumanEval y MBPP son sobresalientes en la PNL y en las grandes comunidades de modelos, pero el rendimiento en estos conjuntos de datos clásicos está cerca de la saturación, mientras que otras tareas como la traducción de código, la anotación de código y las tareas unitarias, como la generación de pruebas, rara vez se abordan. Por otro lado, en la comunidad de ingeniería de software, la aplicación de modelos de lenguaje todavía está dominada por el modelo de solo codificador representado por CodeBERT y el modelo de codificador-decodificador representado por CodeT5, mientras que las aplicaciones a nivel industrial de la serie GPT de modelos grandes están en ascenso.
A diferencia de muchas revisiones anteriores, este artículo parte de una perspectiva interdisciplinaria e investiga exhaustivamente el trabajo de las dos comunidades disciplinarias de PNL e Ingeniería de Software (SE), cubriendo los grandes modelos generativos representados por la serie OpenAI GPT y la serie Meta LLaMA. Tareas de generación de código, también cubre modelos pequeños de código profesional como CodeBERT y otras tareas posteriores como la traducción de código, y se centra en la tendencia de desarrollo de integración de NLP y SE.
Este artículo se divide en cuatro partes: antecedentes técnicos, modelo de código, tareas posteriores, oportunidades y desafíos. La primera parte presenta los principios básicos y los objetivos de entrenamiento comunes de los modelos de lenguaje, así como las últimas mejoras a la arquitectura básica de Transformer. La segunda parte presenta modelos grandes generales como Codex y PaLM y modelos de código profesionales como CodeGen y StarCoder, e incluye la aplicación de tecnologías de PNL como el ajuste fino de la instrucción y el aprendizaje por refuerzo, así como características del programa como AST, DFG e IR. en modelos de código. La tercera parte presenta brevemente más de 30 tareas posteriores de código y enumera conjuntos de datos comunes. La cuarta parte presenta las oportunidades y desafíos de los modelos de código grande actuales.
2. Antecedentes técnicos
Aunque la mayoría de los grandes modelos generativos actuales se basan en el decodificador Transformer, su arquitectura no ha cambiado desde que se propuso en 2017. Esta sección presenta brevemente la regularización previa a la capa (prenorma), la atención paralela (atención paralela), la codificación de posición de rotación (RoPE), la atención de recuperación múltiple y la atención de recuperación grupal (MQA, GQA) y los métodos basados en atención. Optimización (FlashAttention), amigos familiares pueden omitirlo ~
2.1 La clásica autoatención del toro
En el artículo de 2017, Attention Is All You Need, cada capa de Transformer se define de la siguiente manera:

Entre ellos, LN es la normalización de capas (Normalización de capas), Atención es la subcapa de autoatención de múltiples cabezales (MHA) y FFN es la subcapa completamente conectada (Red de alimentación hacia adelante).
2.2 Regularización previa a la capa
En 2019, GPT-2 trasladó la regularización de capas a la entrada de cada subcapa:

El trabajo posterior solo con decodificador siguió básicamente esta arquitectura para hacer que el entrenamiento sea más estable. En términos del modelo codificador-decodificador, la serie T5 también adoptó esta arquitectura.
2.3 Atención paralela
En 2021, GPT-J cambió el cálculo secuencial de la autoatención y las capas completamente conectadas a paralelo para mejorar la eficiencia del entrenamiento:

En el experimento del artículo de PaLM, se descubrió que el uso de esta arquitectura puede aumentar la velocidad de entrenamiento en un 15%, lo que dañará levemente el rendimiento en el modelo 8B, pero básicamente no tiene ningún impacto en el modelo 62B.
2.4 Codificación de posición
Dado que la atención propia no puede distinguir la relación posicional entre los tokens de entrada, la codificación posicional es una parte importante de la arquitectura Transformer y su capacidad de extrapolación también determina la longitud de la secuencia que el modelo puede procesar.
El Transformer clásico utiliza codificación de coseno que no se puede aprender, que se agrega a la entrada del vector de palabras en la parte inferior del modelo. GPT y BERT lo cambiaron a codificación de posición absoluta que se puede aprender y continuaron usando modelos clásicos como RoBERTa, BART, GPT-2 y GPT-3. Transformer-XL y XLNet usan codificación de posición relativa y agregan el vector aprendible correspondiente a k de acuerdo con la relación de posición relativa entre k y q en auto atención, mientras que T5 simplifica esto y usa la codificación de cada posición relativa como El escalar aprendible es agregado al producto escalar de k y q.
RoPE (Rotary Position Embedding) y ALiBi (Atención con polarizaciones lineales) son las dos últimas tecnologías de codificación de posición. RoPE multiplica q y k por la matriz de rotación diagonal del bloque para inyectar información de posición:
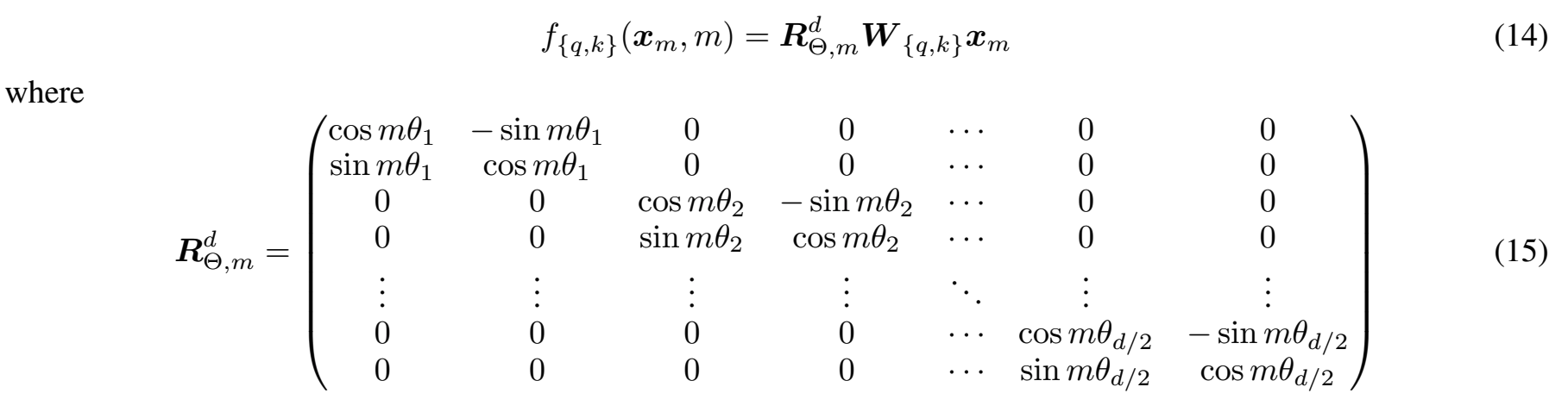
Fuente de la figura en papel RoPE, m en la figura es el subíndice de posición. Los modelos grandes convencionales, como PaLM y LLaMA, utilizan RoPE.
ALiBi atenúa directamente la matriz de atención por adelantado:

Fuente de la imagen en papel ALiBi. BLOOM utiliza ALiBi como codificación de ubicación.
2.5. MQA, GQA, Atención Flash
Un desafío importante de la arquitectura Transformer es la complejidad al cuadrado de la autoatención con respecto a la longitud de la secuencia de entrada. Muchos trabajos simulan la atención personal y simultáneamente reducen la complejidad mediante métodos de aproximación, como Sparse Transformer, Reformer, Longformer, Linformer, Performer, Sinkformer, cosFormer, Sliceformer, etc., pero estos métodos no se han probado en modelos grandes. Además, muchos de estos métodos se basan en la relación entre la longitud de la secuencia y la latitud de la capa oculta n<<d, lo que no es válido en los modelos grandes existentes (por ejemplo, la longitud de la secuencia de GPT-3 175B es 2048 y la longitud de la secuencia de GPT-3 175B es 2048). La latitud de la capa oculta es 12288).
Por lo tanto, el punto de partida para la optimización acelerada de la autoatención en modelos grandes no suele ser el proceso de cálculo de la atención, sino la lectura y escritura del hardware. MQA se basa en esta idea, permitiendo que diferentes cabezas compartan K y V en la autoatención de múltiples cabezas, mientras que cada cabeza conserva su propia Q. Esta optimización casi no tiene impacto en la velocidad de entrenamiento, pero aumenta directamente la velocidad de inferencia h veces (h es el número de cabezas de atención, como BERT-large es 16, GPT-3 175B es 96). La fuente de esta aceleración es que todos los elementos de palabras en la etapa de inferencia deben generarse autorregresivamente, y el cálculo de cada paso en el proceso de generación involucra q y k de todos los elementos de palabras anteriores. El proceso de cargar estos q y k desde la memoria de video al núcleo informático de la GPU constituye un cuello de botella en el rendimiento.
En cuanto a GQA, como su nombre indica, es un producto intermedio entre MHA y MQA:
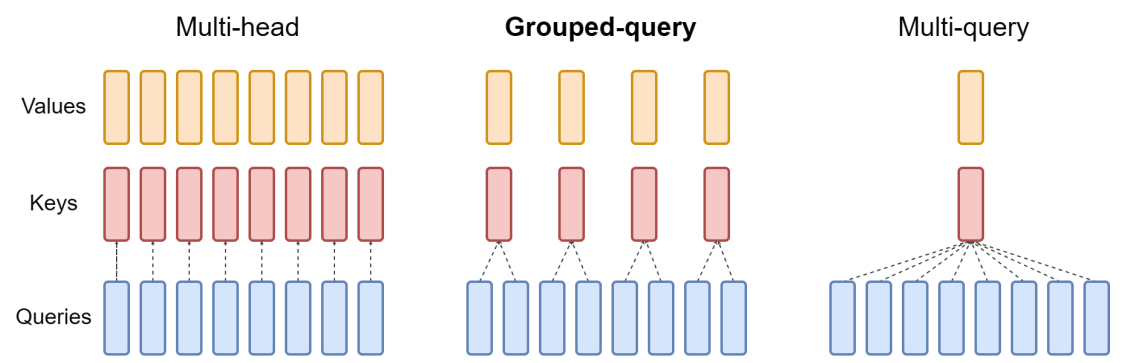
Fuente de la imagen en papel GQA.
Entre los modelos grandes convencionales, PaLM usa MQA, mientras que LLaMA 2 y su variante Code LLaMA usan GQA.
Otra tecnología relacionada es FlashAttention. Esta tecnología optimiza el cálculo de la matriz de atención mediante tecnología de mosaico en informática distribuida. Vale la pena señalar que, a diferencia de otras técnicas de optimización, FlashAttention no es un método de aproximación y no cambia los resultados del cálculo.
3. modelo de código
Dividimos los modelos de código en modelos grandes de uso general, modelos grandes de entrenamiento con código agregado y modelos profesionales previamente entrenados desde cero en función de los campos de entrenamiento previo, y la última categoría se divide en codificador, decodificador y codificador-decodificador Transformer. Además de UniLM, también prestamos especial atención al trabajo que surgió este año sobre el ajuste de instrucciones en el código, el uso de comentarios del compilador para el aprendizaje reforzado y la integración de características específicas del programa, como árboles de sintaxis y flujos de datos. en el modelo:
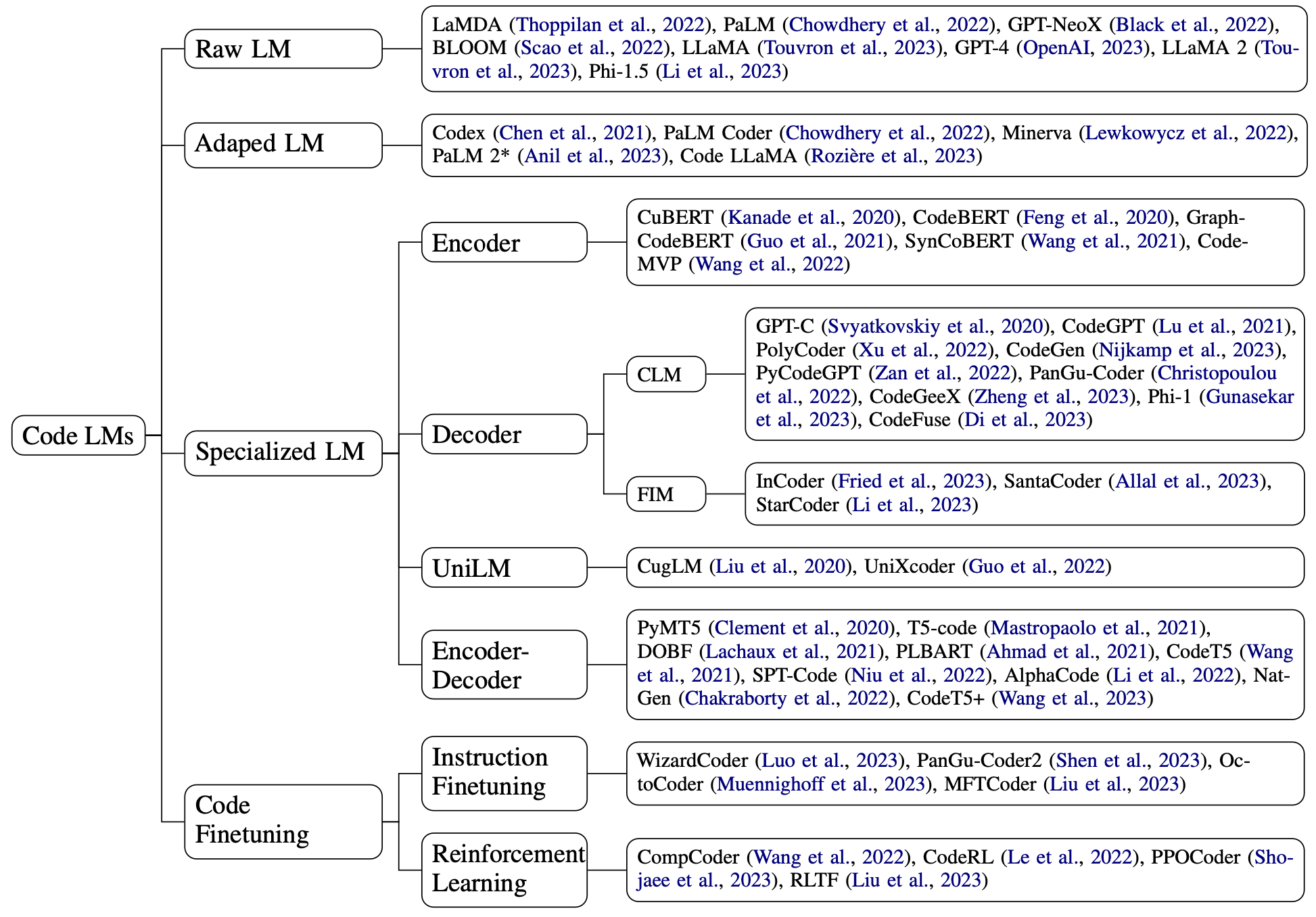
3.1 Modelo grande general y modelo grande de entrenamiento adicional
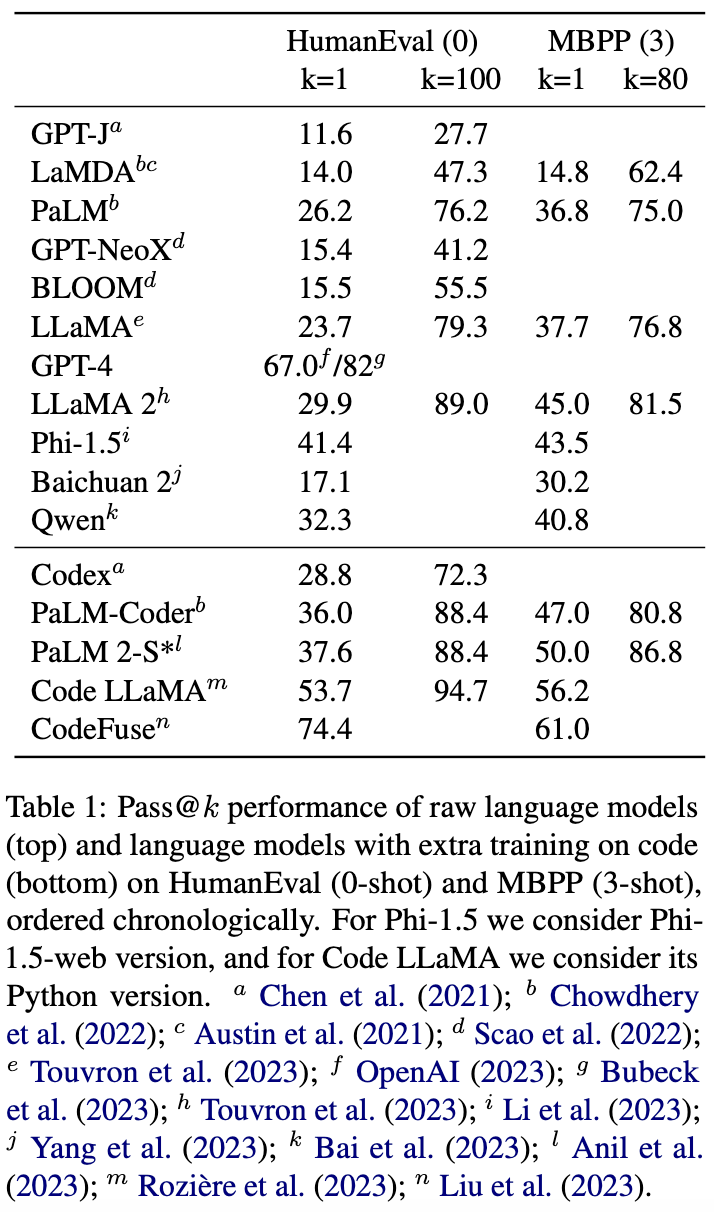
Cuando se trata de modelos de código grandes, el que la mayoría de la gente está más familiarizada es el Codex. Codex es un modelo obtenido mediante entrenamiento autosupervisado de 100 mil millones de palabras en datos de Python basado en GPT-3. Al igual que Codex, están PaLM Coder, que ha agregado 39 mil millones de palabras a PaLM, y Code LLaMA, que ha agregado más de 500 mil millones de palabras a LLaMA 2.
Por supuesto, los modelos grandes no necesariamente requieren capacitación adicional para manejar el código. Los datos de preentrenamiento de modelos grandes actuales a menudo ascienden a billones de palabras, que a menudo incluyen código. Por ejemplo, Pile, uno de los conjuntos de datos públicos de preentrenamiento más utilizados, incluye 95 GB de código, mientras que el conjunto de datos de preentrenamiento ROOTS de BLOOM también incluye 163 GB de código en 13 lenguajes de programación.
Rendimiento del modelo grande general en HumanEval y MBPP:
3.2 Modelo específico del código
Desde que GPT y BERT iniciaron la moda de los modelos de preentrenamiento, se ha trabajado mucho en el campo de la ingeniería de software para reproducir estos modelos en código.
A diferencia de la revisión anterior, no solo nos centramos en el diseño de alto nivel de los objetivos y datos de entrenamiento de cada modelo, sino que también analizamos en detalle los detalles técnicos, incluida la codificación de posición y la implementación de la atención, y los resumimos en una descripción general para su referencia:

3.2.1. Codificador
CodeBERT es uno de los modelos más influyentes en el campo de la ingeniería de software. Se inicializa desde RoBERTa y se entrena en el código con el objetivo de MLM+RTD (RTD es el objetivo de preentrenamiento de ELECTRA Detección de tokens reemplazados). Como se puede ver en la tabla anterior, desde entonces se han desarrollado múltiples modelos de código de codificador, incluidos GraphCodeBERT, SynCoBERT y Code-MVP, basados en CodeBERT.
En PNL, la tarea NSP (predicción de la siguiente oración) también se utiliza en el entrenamiento previo de BERT. Aunque la mayor parte del trabajo posterior representado por RoBERTa creía que esta tarea no era útil, el formato de esta tarea también abrió ideas para el entrenamiento previo del codificador y generó muchas variantes en el modelo de código. Dado que el código es diferente del lenguaje natural, las características que lo acompañan, como los árboles de sintaxis abstracta (AST) y los comentarios, se pueden extraer mediante métodos automatizados. El aprendizaje comparativo en formato NSP se ha convertido en un método común. SynCoBERT lleva a cabo un aprendizaje comparativo entre diferentes características como código-AST, código de anotación-AST, etc. DISCO utiliza inyección de errores y transformación de preservación semántica para construir muestras positivas y negativas respectivamente, mientras que Code-MVP también agrega información de flujo de control (CFG). .
3.2.2. Descifrador
Hablando de decodificador, lo primero que me viene a la mente es, por supuesto, el preentrenamiento autorregresivo en modo GPT. De hecho, desde 2020, han aparecido muchos decodificadores autorregresivos, incluidos GPT-C, CodeGPT, PolyCoder, CodeGen, PyCodeGPT, PanGu-Coder, CodeGeeX, Phi-1, CodeFuse, CodeShell, DeepSeek Coder, con tamaños que varían desde 100M hasta 16B.
Sin embargo, algunos trabajos representados por InCoder, FIM, SantaCoder y StarCoder también exploran la posibilidad de utilizar objetivos autorregresivos no tradicionales para entrenar decodificadores. Estos trabajos primero convierten los datos de entrada en un formulario para completar espacios en blanco: dividen aleatoriamente toda la entrada en tres segmentos: prefijo-medio-sufijo y los reordenan en prefijo-sufijo-medio (formato PSM) o sufijo-prefijo. -middle (formato SPM) y luego envía los datos al modelo para el entrenamiento autorregresivo. Cabe señalar que después de la conversión de datos, las tres etapas participan en un preentrenamiento autorregresivo.
3.2.3. Codificador-Decodificador
En PNL, el modelo codificador-decodificador representado por BART y T5 todavía ocupa un lugar incluso en la era actual de los grandes modelos, y su presencia es naturalmente indispensable en el procesamiento de código.
Dado que la arquitectura codificador-decodificador puede manejar naturalmente problemas de modelado de secuencia a secuencia, en el proceso de entrenamiento del modelo de código, además de las dos tareas estándar de DAE (Denoising Auto-Encoding) de BART y Span Corruption de T5, muchos códigos Tareas específicas Las funciones también se utilizan para el aprendizaje previo al entrenamiento de secuencia a secuencia. Por ejemplo, DOBF utiliza tareas de desofuscación para entrenar el modelo para convertir el código ofuscado en código original. De manera similar, NatGen propone la tarea de “naturalización” de recuperar el código original a partir de código no natural producido por transformación artificial.
La predicción de identificadores también es otra tarea común en el preentrenamiento de código. CodeT5 utiliza anotaciones de secuencia para saber si cada token es un identificador durante el proceso de entrenamiento previo, mientras que SPT-Code predice directamente los nombres de los métodos en forma de generación de secuencia a secuencia.
Además, como UL2 en PNL unifica el preentrenamiento autorregresivo y el preentrenamiento de eliminación de ruido bajo la arquitectura codificador-decodificador, el último modelo de código codificador-decodificador CodeT5+ también adopta un método de preentrenamiento similar.
3.3 Ajuste de la instrucción y aprendizaje por refuerzo
En PNL, el ajuste de la instrucción y el aprendizaje reforzado con retroalimentación humana (RLHF) desempeñan un papel esencial en el proceso de alineación humana de modelos de diálogo como ChatGPT. El ajuste fino de las instrucciones desbloquea la capacidad de generalizar entre tareas entrenando el modelo en un conjunto diverso de instrucciones, mientras que el aprendizaje por refuerzo entrena el modelo hacia las preferencias humanas (como utilidad, seguridad, etc.) recompensando el modelo con retroalimentación automatizada. .
Ambas técnicas también se utilizan en el procesamiento de código. Tanto WizardCoder como PanGu-Coder 2 utilizan el método Evol-Instruct propuesto por el modelo WizardLM en PNL, utilizan modelos como ChatGPT para desarrollar conjuntos de instrucciones más diversos a partir de datos de instrucciones existentes y utilizan las instrucciones generadas para ajustar StarCoder. OctoCoder y OctoGeeX no utilizan instrucciones generadas por modelos grandes, sino que utilizan registros de confirmación y código previo y posterior en GitHub como instrucciones para ajustar StarCoder y CodeGeeX. Recientemente, el marco MFTCoder de código abierto de Ant Group también ha agregado explícitamente una variedad de tareas posteriores a los datos de instrucción para mejorar el rendimiento del modelo de ajuste fino en estas tareas.
En términos de aprendizaje por refuerzo, el procesamiento de código tiene una ventaja natural sobre el procesamiento del lenguaje natural: el compilador puede generar automáticamente comentarios precisos en lugar de los humanos. CompCoder, CodeRL, PPOCoder, RLTF y otros trabajos han aprovechado esta característica para ajustar CodeGPT o CodeT5. PanGu-Coder 2 también aplica el aprendizaje por refuerzo al StarCoder más grande.
4. Tareas posteriores
Con el auge de los modelos de código grande representados por Codex, la tarea de generación de código basada en descripciones de lenguaje natural se ha convertido en el foco de los modelos grandes, y HumanEval también se ha convertido en un punto de referencia imprescindible para los últimos modelos grandes:
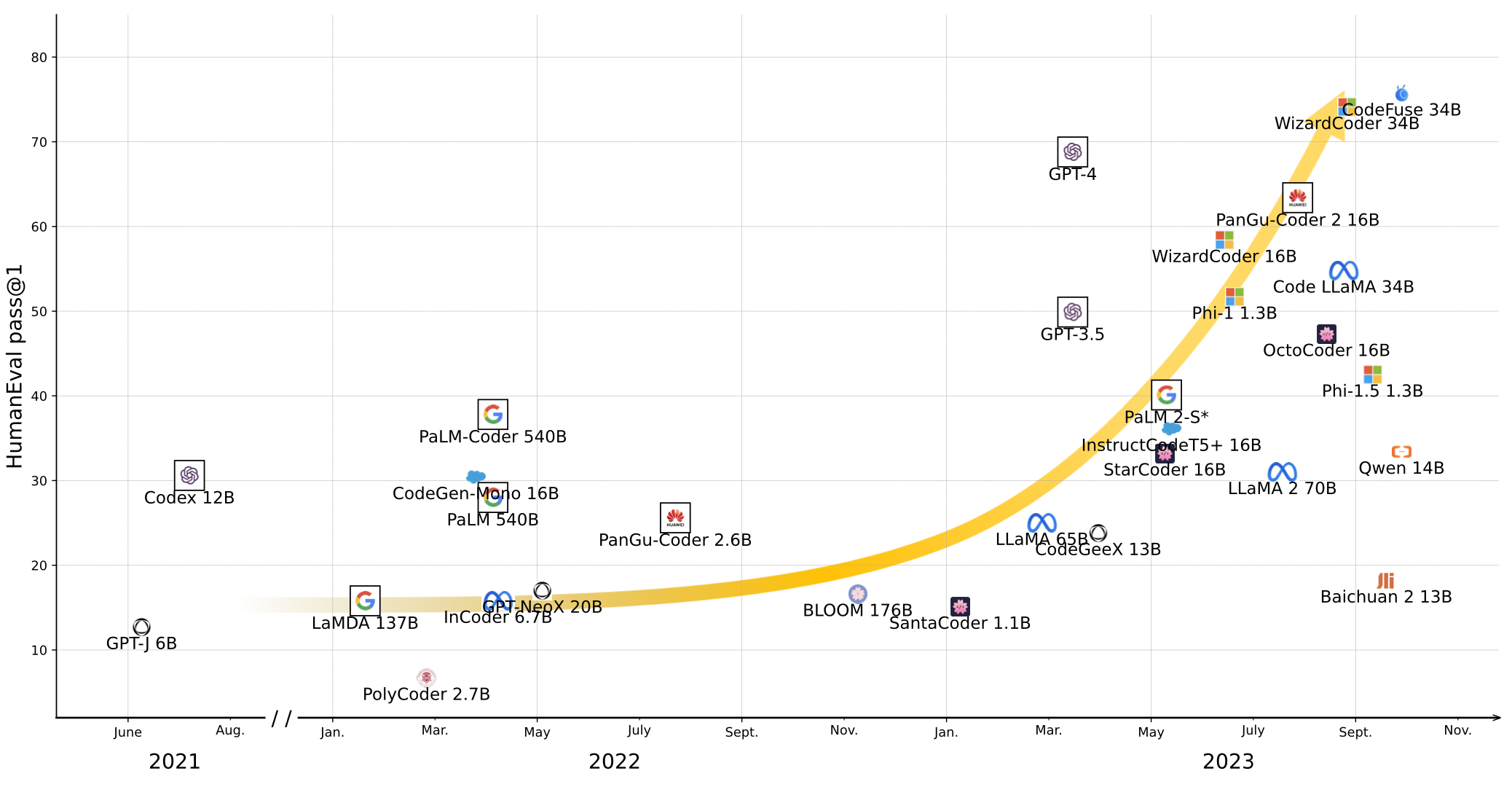
Pero además de la generación de código, también hemos compilado otras 30 tareas posteriores de SE:
- Generación de SQL: genere declaraciones SQL a partir de consultas en lenguaje natural
- Programación matemática: genera código para resolver tareas matemáticas como GSM8K
- Recuperación de código: haga coincidir el código de un grupo de códigos existente que mejor coincida con una consulta en lenguaje natural
- Búsqueda de código: haga coincidir el código de un grupo de códigos existente que tenga la misma funcionalidad o una similar que el código de entrada.
- Finalización de código: complete las partes restantes según el fragmento de código, que a menudo se usa en complementos IDE
- Traducción de código: traducir código de un lenguaje de programación a otro
- Corrección de código: corregir errores en el código
- Relleno de código: similar a completar código, pero puede hacer referencia al contexto de ambos lados en lugar de solo un lado.
- Desofuscación de código: recupere el código original del código ofuscado (es decir, nombres de identificadores modificados)
- Tareas relacionadas con las pruebas de software: generación de pruebas unitarias, generación de afirmaciones, generación de variantes, generación de entradas de prueba, evaluación de código
- Predicción de clases: prediga tipos de variables o parámetros de funciones y tipos de valores de retorno en código de lenguaje de programación dinámico (como Python)
- Resumen de código: genere la explicación o documentación en lenguaje natural correspondiente para el código
- Predicción de identificadores: predice nombres de identificadores significativos (variable, función, clase, etc.) en el código
- Detección de defectos: detecta si el código de entrada contiene defectos o vulnerabilidades
- Detección de clones: detecta si dos fragmentos de código de entrada son semánticamente equivalentes
- Razonamiento del código: evalúe el dominio del modelo grande del conocimiento relacionado con el código (como funciones de código, conceptos, algoritmos, etc.) en forma de preguntas y respuestas.
- Clasificación de código: determine la función del código en categorías predefinidas, o el autor del código.
- Traducción de documentos: traduzca documentación relacionada con el código de un lenguaje natural a otro
- Análisis de registros: analice los registros generados durante la operación del sistema de software, genere tablas formales o detecte problemas automáticamente.
En el documento, también enumeramos conjuntos de datos estándar existentes para algunas tareas:
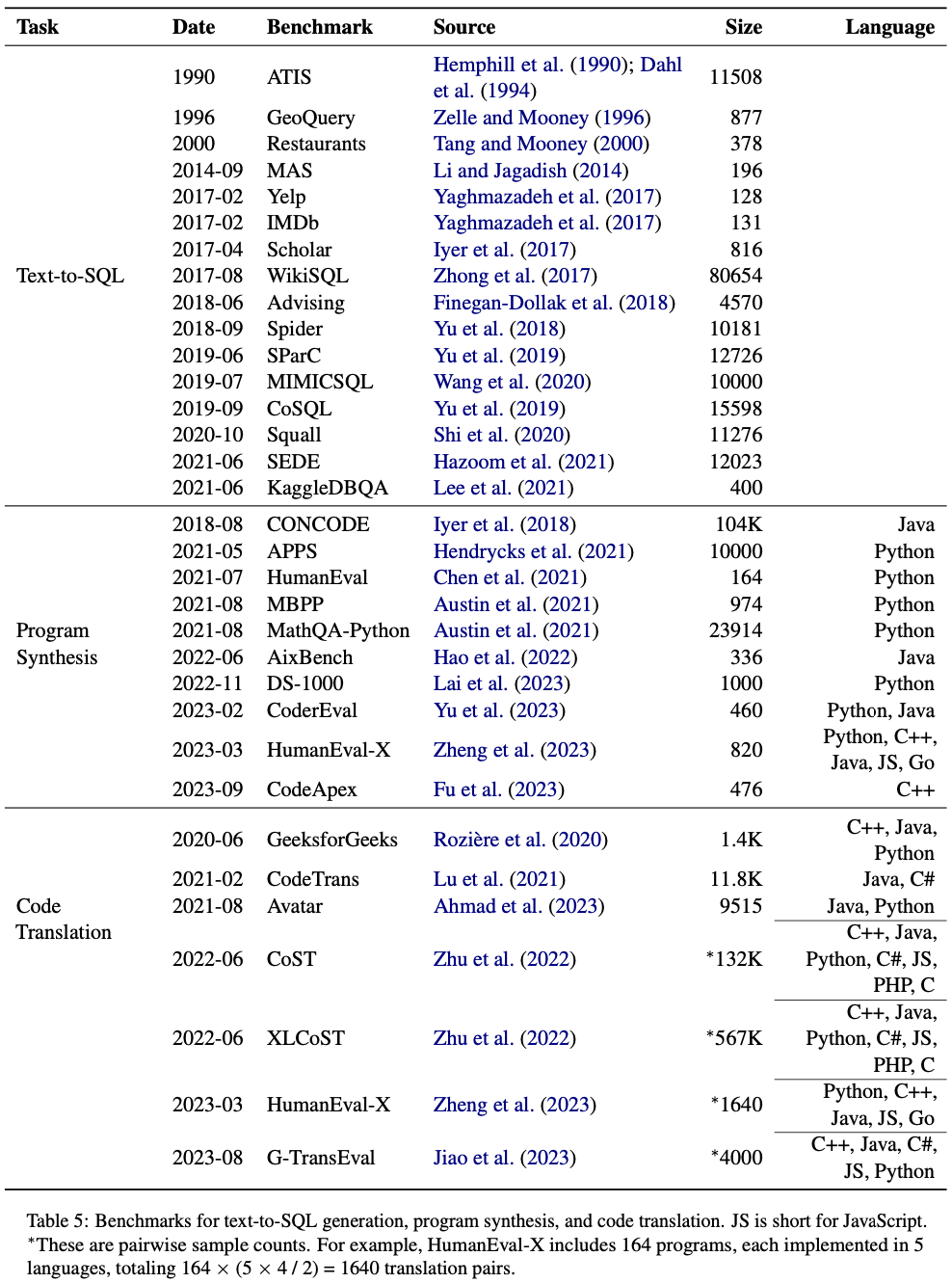
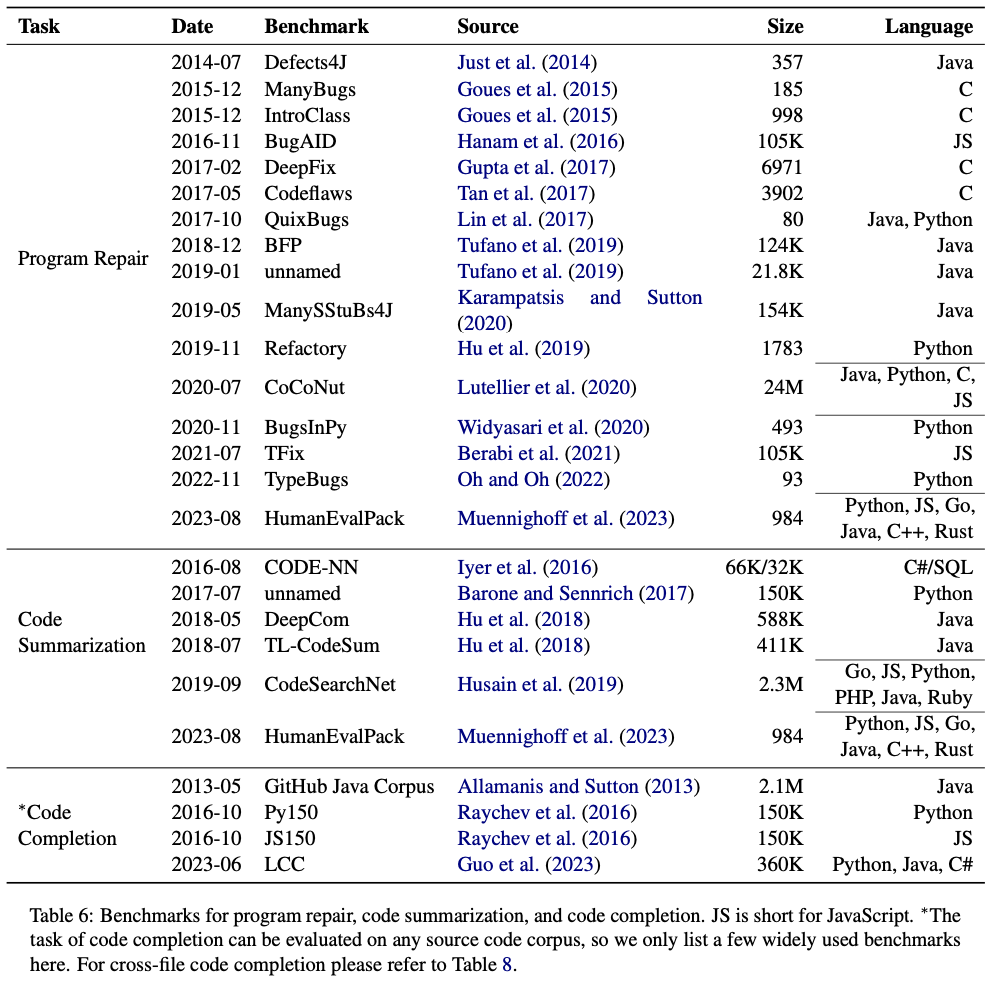
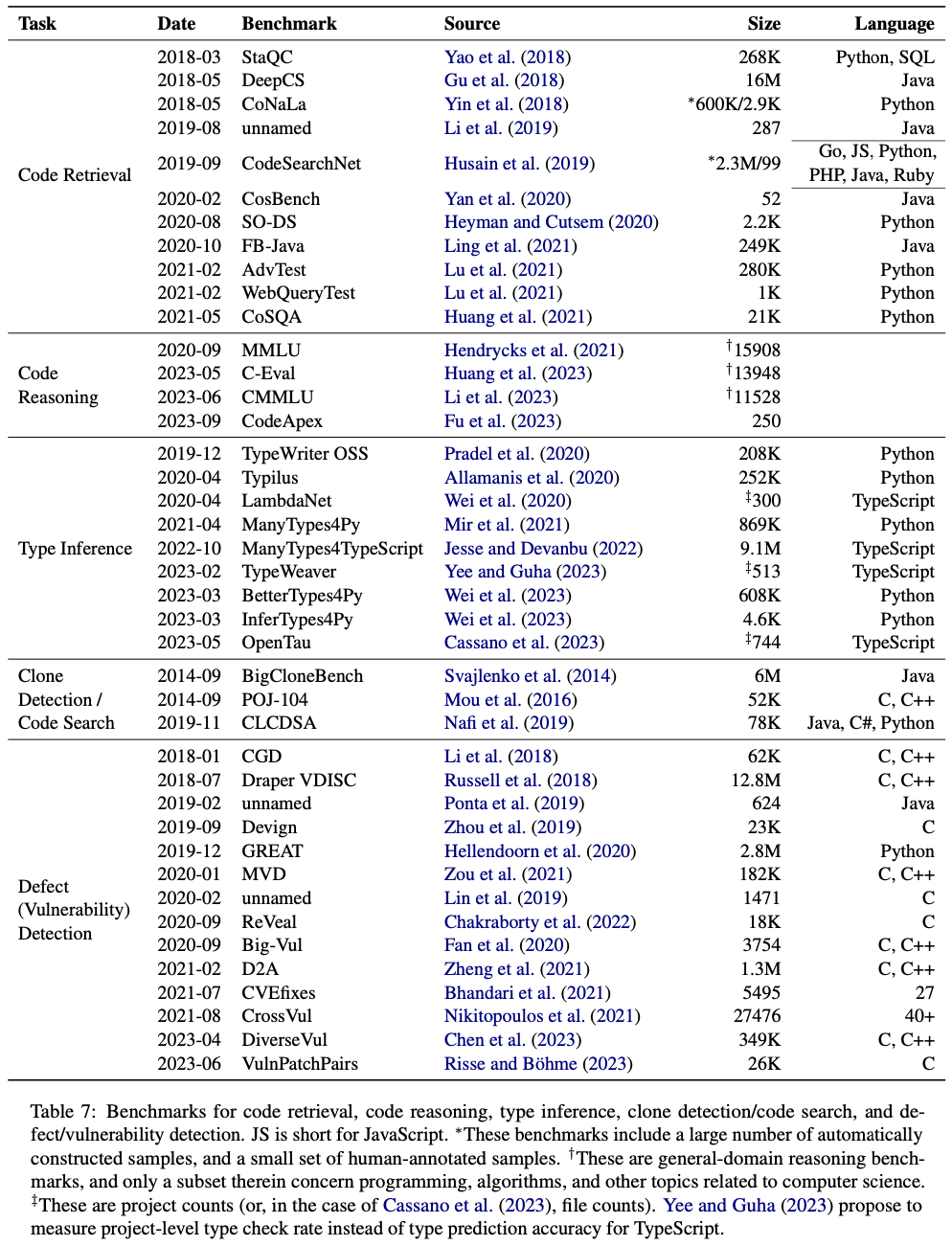
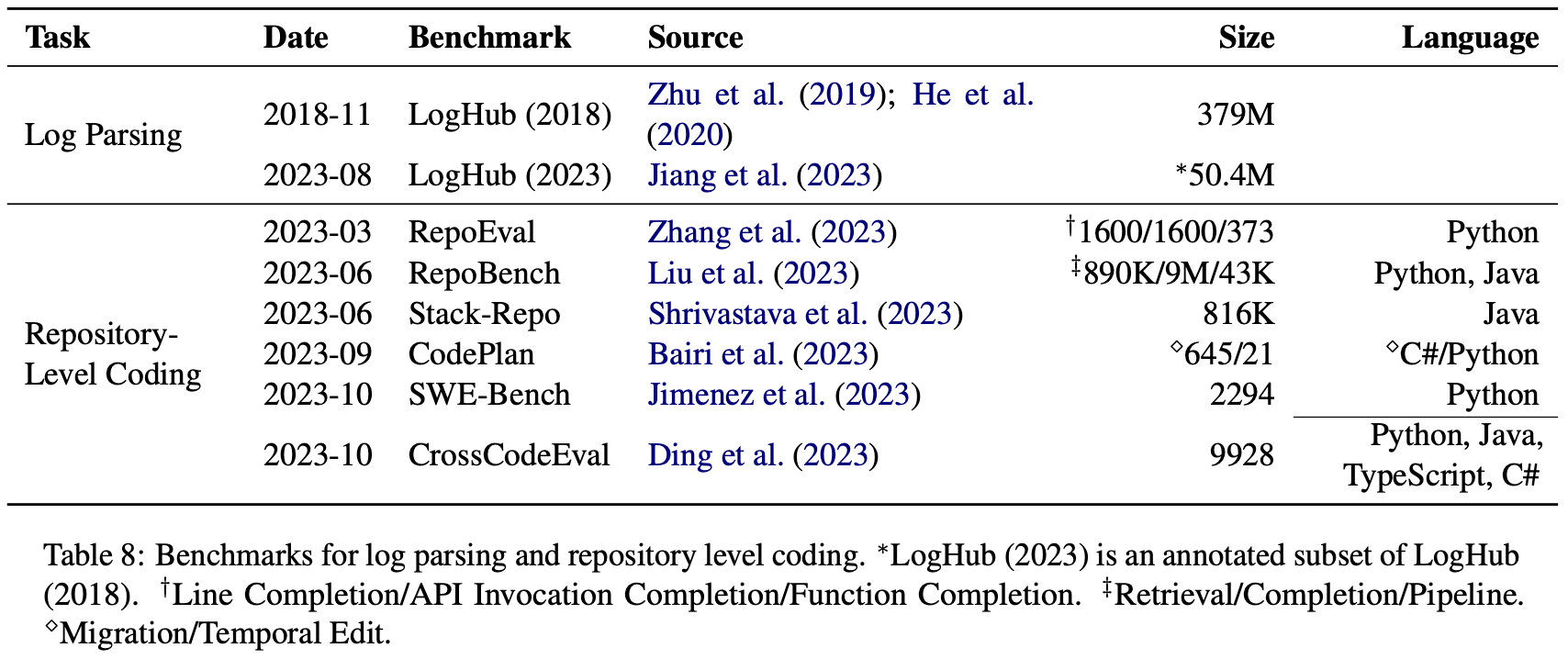
Los enlaces URL de estos conjuntos de datos se proporcionan en el repositorio de GitHub. Para otras tareas, especialmente tareas relacionadas con pruebas de software, como generación de pruebas unitarias, generación de afirmaciones, desofuscación de código, etc., actualmente no existe un conjunto de datos estándar a gran escala, y Los modelos de lenguaje grandes también tienen pocas aplicaciones entre ellos, y es una dirección en la que la PNL y la SE pueden centrarse en trabajos futuros.
5. Oportunidades y desafíos
No hace mucho, en Github Universe 2023, Microsoft lanzó algunas actualizaciones para GitHub Copilot, incluido Copilot Workspace, que lidera la industria: comenzando desde un problema, logrando la implementación de requisitos a nivel de almacén, pruebas, compilación y espera de iteraciones. Esto también nos dio una gran inspiración. Basado en el análisis anterior y la inspiración de exploraciones pioneras relacionadas, este artículo también resume los desafíos actuales en la aplicación de modelos de lenguaje en ingeniería de software:
- Construir un punto de referencia de evaluación más realista para reemplazar el casi agotado HumanEval
- Obtenga datos de mayor calidad y comprenda y reflexione sobre modelos como Phi-1 "usando datos de IA para entrenar IA"
- Conecte sin problemas características que son exclusivas del código y que se pueden obtener automáticamente, como árboles de sintaxis abstracta, flujos de datos y flujos de control, en grandes modelos de lenguaje.
- Aplicar modelos de lenguaje grandes en más tareas posteriores de SE, especialmente tareas relacionadas con pruebas de software.
- Arquitectura de modelos no tradicionales y objetivos de capacitación, como el modelo de difusión representado por Microsoft CodeFusion, etc.
- Cree un ecosistema en torno a modelos de lenguaje grandes para todo el proceso de desarrollo de software, rompiendo la limitación actual de que la mayoría de los modelos grandes se utilizan como complementos IDE.
- Supervise y administre mejor el código generado por modelos grandes para evitar riesgos relacionados
Contáctenos
Además de esta revisión, nuestro resto de trabajos, incluidos modelos y conjuntos de datos, también son de código abierto. Si te gusta nuestro trabajo, puedes probarlo, corregir errores y contribuir con código. Si puedes, agrega estrellas a nuestro proyecto para apoyarnos.
- Sitio web oficial de CodeFuse: https://codefuse.alipay.com
- Página de inicio del proyecto GitHub: https://github.com/codefuse-ai
- Página de inicio de HuggingFace: https://huggingface.co/codefuse-ai
- Página de inicio de la comunidad Codefuse: https://modelscope.cn/organization/codefuse-ai