Este blog trata principalmente sobre el resumen de los errores y soluciones comunes del código CUDA ~
1. RuntimeError error de ejecución
1.1.RuntimeError: error CUDA: sin memoria
Los errores del kernel de CUDA pueden informarse de forma asíncrona en alguna otra llamada de API, por lo que el seguimiento de la pila a continuación puede ser incorrecto.
Para la depuración, considere pasar CUDA_LAUNCH_BLOCKING=1.

Análisis de errores:
El programa funcionaba bien, el código estaba bien, la memoria de video aún era inútil y la memoria de video era suficiente, la GPU puede estar ocupada,
Puede deberse al problema de caché del entrenamiento anterior, porque se está ejecutando en el contenedor de la ventana acoplable, así que primero detenga el contenedor de la ventana acoplable y luego inicie el contenedor ~
1.2.RuntimeError: error cuDNN: CUDNN_STATUS_INTERNAL_ERROR

posibles errores
La versión de pytorch y cuda es incorrecta.
Memoria de vídeo insuficiente
Consulte otro código de prueba del blog
# True:每次返回的卷积算法将是确定的,即默认算法。
torch.backends.cudnn.deterministic = True
# 程序在开始时花额外时间,为整个网络的每个卷积层搜索最适合它的卷积实现算法
# 实现网络的加速。
torch.backends.cudnn.benchmark = Truesolución final
Establecer número a 0
1.3.RuntimeError: CUDA sin memoria
①RuntimeError: CUDA sin memoria. Intenté asignar 152,00 MiB (GPU 0; 23,65 GiB de capacidad total; 13,81 GiB ya asignados; 118,44 MiB libres; 14,43 GiB reservados en total por PyTorch) Si la memoria reservada es >> memoria asignada, intente configurar max_split_size_mb para evitar la fragmentación. Consulte la documentación para la gestión de memoria y PYTORCH_CUDA_ALLOC_CONF

Si se excede la memoria ocupada por la GPU, los recursos de la GPU local deberían ser completamente suficientes. Sin embargo, durante el proceso de entrenamiento de pytorch, debido a los parámetros de propagación hacia atrás y hacia adelante de los parámetros de la red neuronal, como el descenso de gradiente , se ocupará una gran cantidad de memoria de la GPU. , por lo que debe reducirse .
Solución:
Reducir el lote, es decir, reducir el tamaño de la muestra de entrenamiento de palabras
Liberar memoria de video: torch.cuda.empty_cache()
②torch.cuda.OutOfMemoryError : CUDA sin memoria. Intenté asignar 128,00 MiB (GPU 0; 23,65 GiB de capacidad total; 22,73 GiB ya asignados; 116,56 MiB libres; 22,78 GiB reservados en total por PyTorch) Si la memoria reservada es >> memoria asignada, intente configurar max_split_size_mb para evitar la fragmentación. Consulte la documentación para la gestión de memoria y PYTORCH_CUDA_ALLOC_CONF
torch.cuda.OutOfMemoryError: CUDA no tiene memoria. Intentando asignar 128,00 MiB (GPU 0; 23,65 GiB en total; 22,73 GiB asignados; 116,56 MiB libres; 22,78 GiB en total reservados por PyTorch) Si la memoria reservada >> memoria asignada, intente configurar max_split_size_mb para evitar la fragmentación. Consulte la documentación para la gestión de memoria y PYTORCH_CUDA_ALLOC_CONF.
Análisis de la causa del error:
Durante el entrenamiento del modelo de aprendizaje profundo, el código no libera la memoria de video cada vez que se entrena
solución:
ver nvidia-smi
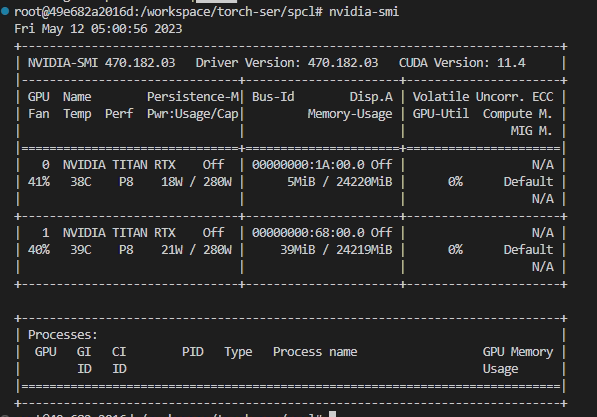
En este momento , la GPU se ejecuta sin programa y la memoria de video aún está ocupada, como se muestra en la figura.
Usar consulta de fusor
fuser -v /dev/nvidia*(Opción) Si ingresa el comando anterior y le indica que no hay fusor, entonces instale
apt-get install psmiscSi aparece No se puede localizar el paquete XXX, entonces
apt-get update
Fuerza (-9) para matar el proceso, ingrese el siguiente comando
kill -9 PIDDiagrama de ejemplo

Solo libera la memoria de video~