Artículos de la serie de diseño arquitectónico
- Serie de diseño arquitectónico 1: ¿Qué es el diseño arquitectónico?
- Serie de diseño arquitectónico 2: varios principios comunes de diseño arquitectónico
- Serie de diseño de arquitectura 3: Cómo diseñar una arquitectura escalable
En Architecture Design Series 1: Qué es el Diseño de Arquitectura , hablamos sobre el propósito principal del diseño de arquitectura, que es resolver los problemas causados por la complejidad de los sistemas de software, hoy hablaremos sobre el alto rendimiento, una de las fuentes del sistema de software. complejidad.
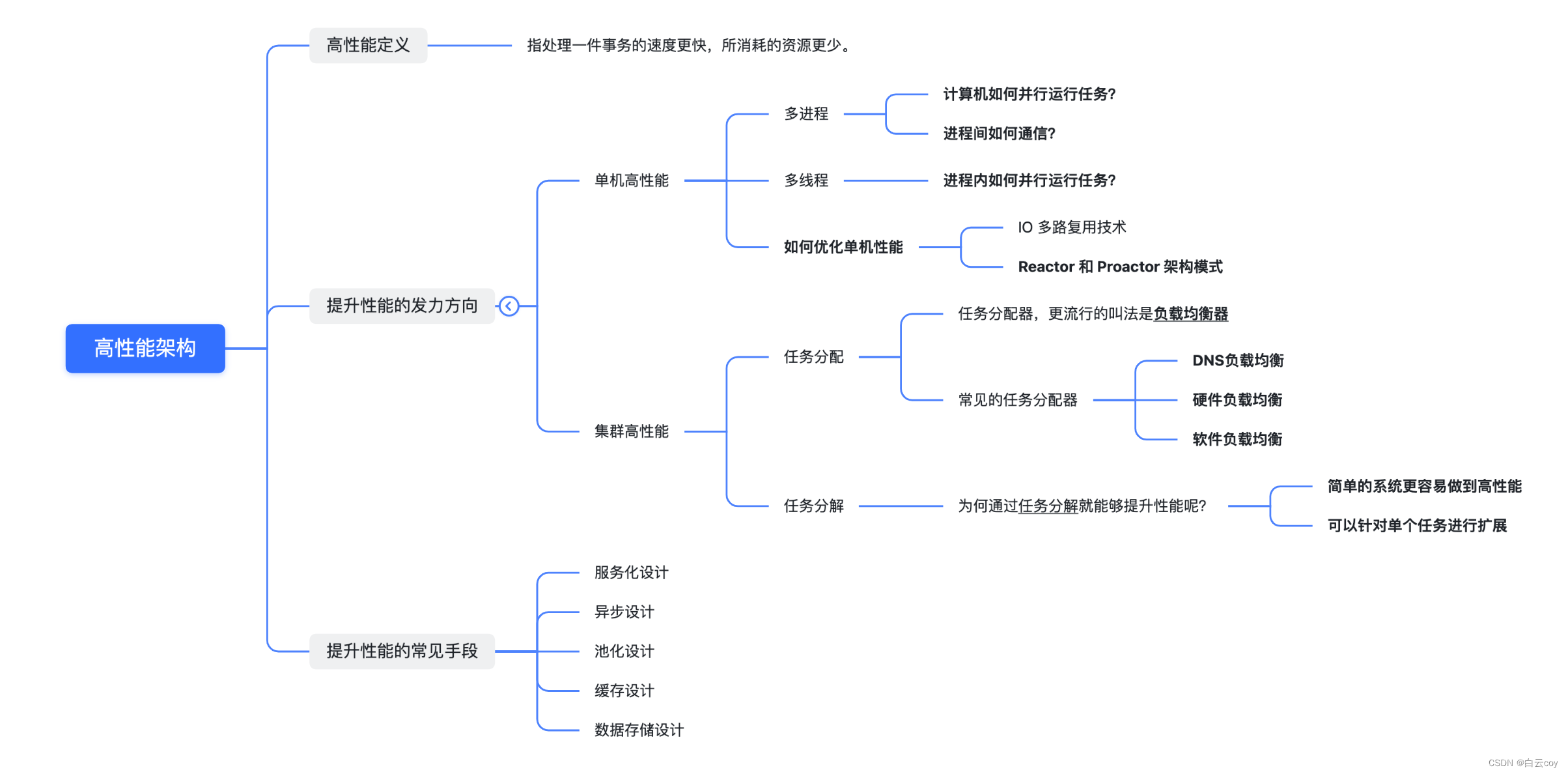
1. ¿Qué es la arquitectura de alto rendimiento?
Para comprender qué es la arquitectura de alto rendimiento , primero debemos comprender qué es el alto rendimiento .
Definición de alto rendimiento
Primero, ¿qué es el rendimiento y cómo entenderlo?
En pocas palabras, el rendimiento se refiere a la capacidad de procesamiento de una transacción.
Entonces, ¿qué es el alto rendimiento?
El alto rendimiento se refiere a procesar una transacción más rápido y consumir menos recursos.
Arquitectura de alto rendimiento
Entonces, ¿qué es una arquitectura de alto rendimiento?
La arquitectura de alto rendimiento se refiere al uso de tecnologías y estrategias apropiadas para lograr un rendimiento excelente del sistema con una inversión de recursos limitada.
Para los técnicos, cómo mejorar el rendimiento del sistema con una inversión de recursos limitada es tanto un desafío como una oportunidad.
Te imaginas que si ambos eres arquitecto y la arquitectura que construyes tiene las mismas prestaciones el coste es menor ¿Es esa tu ventaja?
2. Por qué es importante la arquitectura de alto rendimiento
Después de ingresar a la era de Internet, la velocidad de desarrollo de los negocios está mucho más allá de su imaginación. Por ejemplo:
- En 2016, el número máximo de pagos por segundo de Alipay alcanzó los 120.000 durante el Doble 11 .
- En 2017, la cantidad de sobres rojos enviados y recibidos en WeChat durante el Festival de Primavera alcanzó los 760.000 por segundo .
Hemos extraído la información clave: se realizan 120.000 pagos por segundo y se envían y reciben 760.000 sobres rojos por segundo . Estas dos cifras significan que hay decenas de miles, o incluso cientos de millones, de usuarios que utilizan el sistema al mismo tiempo.
Con un número tan grande de usuarios, se puede imaginar la presión que soporta el sistema, especialmente para servicios complejos como pagos y sobres rojos, que requieren un alto rendimiento en todo el enlace. Los enlaces de un sistema complejo suelen ser muy largos y es una tarea compleja y desafiante garantizar que todos los enlaces del enlace cooperen para lograr un alto rendimiento.
De esta forma, la arquitectura de alto rendimiento resulta útil.
Podemos maximizar la velocidad de procesamiento, el rendimiento y la eficiencia del sistema a través del diseño de arquitectura de alto rendimiento, proporcionando así servicios de sistema estables y confiables para satisfacer necesidades comerciales complejas, de alta concurrencia y a gran escala.
Los sistemas de alto rendimiento generalmente tienen las siguientes características:
- Respuesta rápida
- Alto rendimiento
- baja latencia
- Alta concurrencia
- Escalabilidad
3. Cómo diseñar una arquitectura de alto rendimiento
La complejidad que aporta el alto rendimiento en los sistemas de software se refleja principalmente en dos aspectos: por un lado, es la complejidad que aporta una sola computadora para un alto rendimiento ; por otro lado, es la complejidad que aportan múltiples grupos de computadoras para un alto rendimiento. rendimiento .
Por lo tanto, podemos entender el alto rendimiento de los sistemas de software desde dos aspectos: alto rendimiento independiente y alto rendimiento en clúster .
A continuación, analicemos qué tecnologías comunes pueden mejorar el rendimiento independiente y el rendimiento del clúster.
1. Dirección de los esfuerzos para mejorar el desempeño
1.1 Alto rendimiento de una sola máquina
El aspecto más crítico del alto rendimiento independiente es el sistema operativo .
El desarrollo del rendimiento de las computadoras está impulsado esencialmente por el desarrollo del hardware, especialmente el desarrollo del rendimiento de las CPU. La famosa "Ley de Moore" muestra que la potencia de procesamiento de la CPU se duplica cada 18 meses y la clave para aprovechar al máximo el rendimiento del hardware es el sistema operativo.
Por lo tanto, el sistema operativo en sí se desarrolla con el desarrollo del hardware. El sistema operativo es el entorno de ejecución del sistema de software. La complejidad del sistema operativo determina directamente la complejidad del sistema de software.
Lo más relevante entre los sistemas operativos y el rendimiento son los procesos y los hilos .
1. Multiproceso
¿Cómo ejecuta una computadora tareas en paralelo?
Al principio, las computadoras solo podían realizar una tarea a la vez. Si una tarea requería leer una gran cantidad de datos de un dispositivo de E/S (como una cinta), la CPU estaba realmente inactiva durante la operación de E/S, y este tiempo de inactividad habría sido posible. Otros cálculos son posibles.
Para mejorar el rendimiento se utiliza un proceso que corresponde a una tarea, cada tarea tiene su propio espacio de memoria independiente, los procesos no están relacionados entre sí y son programados por el sistema operativo. Para lograr el propósito de la operación paralela de múltiples procesos, se adopta un método de tiempo compartido, es decir, el tiempo de la CPU se divide en muchos segmentos y cada segmento solo puede ejecutar instrucciones en un determinado proceso.
Aunque todavía se procesa en serie desde la perspectiva del sistema operativo y la CPU, debido a la rápida velocidad de procesamiento de la CPU, desde la perspectiva del usuario, parece que se están procesando múltiples procesos en paralelo.
¿Cómo comunicarse entre procesos?
Aunque el multiproceso requiere que cada tarea tenga un espacio de memoria independiente y los procesos no estén relacionados entre sí, desde el punto de vista del usuario, si dos tareas pueden comunicarse durante el proceso en ejecución, el diseño de la tarea será más flexible y eficiente.
De lo contrario, si las dos tareas no pueden comunicarse durante la operación, la tarea A solo puede escribir los resultados en el almacenamiento y la tarea B luego puede leerlos del almacenamiento para procesarlos, lo que no solo es ineficiente, sino que también hace que el diseño de la tarea sea más complejo.
Para solucionar este problema, se han diseñado varios métodos de comunicación entre procesos, incluidos canalizaciones, colas de mensajes, semáforos, almacenamiento compartido, etc.
2. Subprocesos múltiples
¿Cómo ejecutar tareas en paralelo dentro de un proceso?
El multiproceso permite procesar múltiples tareas en paralelo, pero tiene sus propias desventajas. Un solo proceso solo se puede procesar en serie. De hecho, muchas subtareas dentro de un proceso no necesitan ejecutarse estrictamente en orden cronológico y También deben procesarse en paralelo.
Para resolver este problema, la gente inventó los subprocesos. Los subprocesos son subtareas dentro del proceso, pero todas estas subtareas comparten los mismos datos del proceso. Para garantizar la exactitud de los datos, se inventó un mecanismo de bloqueo mutex.
Con subprocesos múltiples, la unidad más pequeña de programación del sistema operativo se convierte en un subproceso y un proceso se convierte en la unidad más pequeña de asignación de recursos del sistema operativo.
3. ¿Cómo optimizar el rendimiento independiente durante la codificación?
Para mejorar el rendimiento de una sola máquina, uno de los puntos clave es el modelo de concurrencia adoptado por el servidor, que involucra modelos de IO multiproceso, multiproceso y asíncronos sin bloqueo y síncronos sin bloqueo.
Multiplexación IO Hay
dos puntos clave en la tecnología de multiplexación IO:
- Cuando varias conexiones comparten un objeto de bloqueo, el proceso solo necesita esperar a un objeto de bloqueo sin sondear todas las conexiones. Los métodos de implementación comunes incluyen select, epoll, kqueue, etc.
- Cuando una determinada conexión tiene nuevos datos que pueden procesarse, el sistema operativo notificará al proceso, y el proceso regresa del estado de bloqueo y comienza el procesamiento comercial.
Patrones de arquitectura Reactor y Proactor
En el diseño de sistemas back-end, si queremos lograr un alto rendimiento en una sola máquina, basado en la multiplexación IO, todo nuestro marco de red también debe cooperar con la tecnología de agrupación para mejorar nuestro rendimiento.
Por lo tanto, la industria generalmente utiliza multiplexación de E/S + grupo de subprocesos para mejorar el rendimiento. En consecuencia, los dos patrones de arquitectura de alto rendimiento de una sola máquina comúnmente utilizados en la industria son los patrones Reactor y Proactor. El modo Reactor es un modelo de red síncrono sin bloqueo y el modo Proactor es un modelo de red asíncrono sin bloqueo .
Entre el software de código abierto de la industria, Redis adopta un enfoque de un solo reactor y un solo proceso, Memcache adopta un enfoque de múltiples reactores y múltiples subprocesos, y Nginx adopta un enfoque de múltiples reactores y múltiples procesos.
4. Resumen
Si queremos completar un sistema de software de alto rendimiento, debemos considerar puntos técnicos como multiproceso, múltiples subprocesos, comunicación entre procesos y concurrencia de múltiples subprocesos.
Aunque el multiproceso y el multiproceso mejoran en gran medida el rendimiento del procesamiento paralelo de múltiples tareas, siguen siendo esencialmente sistemas de tiempo compartido y no pueden lograr un verdadero paralelismo al mismo tiempo. La forma de resolver este problema es permitir que varias CPU realicen tareas informáticas al mismo tiempo, logrando así un verdadero paralelismo multitarea.
Actualmente, el procesador multinúcleo más común es la solución SMP. SMP, nombre completo Symmetric Multi-Processor, estructura multiprocesador simétrica.
1.2 Clúster de alto rendimiento
Aunque el rendimiento del hardware informático se ha desarrollado rápidamente, todavía palidece en comparación con la velocidad de desarrollo de las empresas, especialmente después de entrar en la era de Internet, la velocidad de desarrollo de las empresas supera con creces la velocidad de desarrollo del hardware.
Como se mencionó anteriormente, para dos negocios complejos, pagos y sobres rojos, el rendimiento de una sola máquina no puede ser compatible de todos modos y se debe utilizar un enfoque de clúster para lograr un alto rendimiento. Por ejemplo, para sistemas comerciales de la escala de Alipay y WeChat, la cantidad de máquinas con sistemas backend es de decenas de miles.
Mejorar el rendimiento a través de una gran cantidad de máquinas no es tan simple como sumar máquinas, sino que es una tarea compleja cooperar con varias máquinas para lograr un alto rendimiento. Las formas comunes son:
1. Asignación de tareas
La distribución de tareas significa que cada máquina puede manejar tareas comerciales completas y se asignan diferentes tareas a diferentes máquinas para su ejecución.
La complejidad del diseño de clústeres de alto rendimiento se refleja principalmente en la necesidad de agregar un asignador de tareas y seleccionar un algoritmo de asignación de tareas apropiado.
Para los asignadores de tareas, el nombre más popular es balanceador de carga . Pero este nombre hace que la gente piense inconscientemente que el propósito de la asignación de tareas es mantener la carga de cada unidad informática en un estado equilibrado. De hecho, la asignación de tareas no se limita a considerar el equilibrio de carga de las unidades informáticas. Los diferentes algoritmos de asignación de tareas tienen diferentes objetivos: algunos se basan en consideraciones de carga, otros en consideraciones de rendimiento (rendimiento, tiempo de respuesta) y otros en Consideraciones comerciales. .
Elegir un asignador de tareas adecuado también es una cuestión compleja y requiere una consideración exhaustiva de varios factores como el rendimiento, el costo, la mantenibilidad y la disponibilidad.
Las clasificaciones comunes de asignadores de tareas son:
Equilibrio de carga de DNS
Este es el método de equilibrio de carga más simple y común y, a menudo, se utiliza para lograr el equilibrio a nivel geográfico.
La esencia del equilibrio de carga de DNS es que cuando usuarios de diferentes ubicaciones geográficas acceden al mismo nombre de dominio, DNS puede devolver diferentes direcciones IP. Por ejemplo, los usuarios del norte visitan la sala de ordenadores de Beijing, mientras que los usuarios del sur visitan la sala de ordenadores de Shenzhen. Tomando www.baidu.com como ejemplo, la dirección obtenida por los usuarios del norte es 61.135.165.224 y la dirección obtenida por los usuarios del sur es 14.215.177.38.
- Ventajas: implementación simple, bajo costo, no es necesario desarrollarlo ni mantenerlo usted mismo, acceso cercano, velocidad de acceso rápida
- Desventajas: actualizaciones inoportunas, escalabilidad deficiente, estrategia de asignación simple
El equilibrio de carga de hardware
implementa la función de equilibrio de carga a través de un dispositivo de hardware independiente. Este tipo de dispositivo es similar a un enrutador y conmutador y puede entenderse como un dispositivo de red básico para el equilibrio de carga. Actualmente existen dos modelos típicos: F5 y A10.
- Ventajas: rendimiento sólido (admite más de 1 millón de concurrencias), funciones potentes (admite el equilibrio de carga en todos los niveles, admite algoritmos de equilibrio integrales)
- Desventajas: caro y poca escalabilidad
El equilibrio de carga de software
implementa la función de equilibrio de carga proporcionando software de equilibrio de carga. Los más comunes son LVS y Nginx. LVS es el equilibrio de carga de 4 capas del kernel de Linux y Nginx es el equilibrio de carga de 7 capas del software.
Además de utilizar sistemas de código abierto para el equilibrio de carga, si el negocio es relativamente especial, también es posible personalizarlo en función de sistemas de código abierto (por ejemplo, complementos de Nginx) o incluso realizar una autoinvestigación.
- Ventajas: simple, económico y flexible, el equilibrio de carga de capa 4 y 7 se puede seleccionar y ampliar según las necesidades comerciales
- Desventajas: en comparación con el equilibrio de carga de hardware, el rendimiento es medio y la función no es tan potente.
La principal diferencia entre el equilibrio de carga de software y el equilibrio de carga de hardware radica en el rendimiento, que es mucho mayor que el del software. Por ejemplo, el rendimiento de Nginx es de nivel 10,000, y después de instalar Nginx en un servidor Linux general, puede alcanzar alrededor de 50,000/segundo; el rendimiento de LVS es de nivel 100,000, y se dice que puede alcanzar 800,000/segundo. ; y el rendimiento de F5 es de nivel millón, comenzando desde 200 Disponible desde 10,000/segundo hasta 8 millones/segundo.
Arquitectura típica de equilibrio de carga
Generalmente, utilizamos una combinación de tres métodos de equilibrio de carga en función de sus respectivas ventajas y desventajas. Los principios básicos de la combinación son: el equilibrio de carga de DNS logra el equilibrio de carga a nivel geográfico; el equilibrio de carga de hardware logra el equilibrio de carga a nivel de clúster; el equilibrio de carga de software logra el equilibrio de carga a nivel de máquina.
2. Desglose de tareas
A través de la asignación de tareas , podemos superar el cuello de botella del rendimiento de procesamiento de una sola máquina y agregar más máquinas para satisfacer las necesidades de rendimiento del negocio, pero si el negocio en sí se vuelve cada vez más complejo, el rendimiento solo se puede expandir mediante la asignación de tareas . , los ingresos serán cada vez más bajos.
Por ejemplo, cuando el negocio es simple, si una máquina se expande a 10 máquinas, el rendimiento se puede aumentar 8 veces (es necesario deducir parte de la pérdida de rendimiento causada por el grupo de máquinas, por lo que no puede alcanzar las 10 veces teóricas). ), pero si el negocio se vuelve cada vez más complejo, si una máquina se expande a 10, el rendimiento solo puede mejorar 5 veces.
La razón principal de este fenómeno es que el negocio se vuelve cada vez más complejo y el rendimiento de procesamiento de una sola máquina será cada vez menor. Para seguir mejorando el rendimiento, debemos adoptar un nuevo enfoque: la descomposición de tareas .
La arquitectura de microservicios adopta esta idea: a través de este método de descomposición de tareas , el sistema empresarial unificado pero complejo original se puede dividir en sistemas empresariales pequeños y simples que requieren la cooperación de múltiples sistemas.
Desde un punto de vista empresarial, la descomposición de tareas no reducirá la funcionalidad ni reducirá la cantidad de código (de hecho, la cantidad de código puede aumentar porque las llamadas se cambian desde dentro del código a llamadas a través de la interfaz entre servidores), entonces, ¿por qué pasar? ¿ La descomposición de tareas mejora el rendimiento? Existen principalmente los siguientes factores:
-
Es más fácil para un sistema simple lograr un alto rendimiento:
cuanto más simple sea la función del sistema, menos puntos afectarán el rendimiento y será más fácil realizar una optimización específica. -
Se puede expandir para una sola tarea.
Cuando cada tarea lógica se descompone en subsistemas independientes, el cuello de botella en el rendimiento de todo el sistema es más fácil de encontrar. Después del descubrimiento, solo es necesario optimizar o mejorar el rendimiento del subsistema con el cuello de botella. sin cambiar todo el sistema, el riesgo será mucho menor.
Dado que descomponer un sistema unificado en múltiples subsistemas puede mejorar el rendimiento, ¿es mejor dividirlo en partes más finas?
De hecho, de lo contrario, no solo no mejorará el rendimiento, sino que también se reducirá. La razón principal es que si el sistema se divide demasiado finamente, para completar un determinado negocio, el número de llamadas entre sistemas aumentará. exponencialmente, y el número de llamadas entre sistemas aumentará exponencialmente. Los canales de llamadas actualmente se transmiten a través de la red y el rendimiento es mucho menor que el de las llamadas a funciones dentro del sistema.
Por lo tanto, los beneficios de rendimiento que aporta la descomposición de tareas tienen un cierto grado. No es que cuanto más detallada sea la descomposición de tareas, mejor. Para el diseño de arquitectura, cómo captar esta granularidad es muy crítico.
Para obtener instrucciones específicas sobre cómo descomponer tareas, puede consultar el capítulo sobre división en Architecture Design Series 3: Cómo diseñar una arquitectura escalable .
2. Métodos comunes para mejorar el rendimiento.
A continuación, analicemos brevemente varios métodos comunes para mejorar el rendimiento.
2.1 Diseño orientado a servicios
1. Qué: ¿Qué es la servitización?
La servitización se refiere a dividir un sistema empresarial complejo en múltiples sistemas empresariales pequeños y simples que necesitan cooperar entre sí mediante la descomposición de tareas .
El resultado inevitable de la servitización de sistemas grandes y complejos es la centralización de los negocios. Además, una arquitectura monolítica no es necesariamente una mala arquitectura, dependiendo de la complejidad de la aplicación. Por ejemplo, si una empresa nueva quiere hacer negocios en Internet, dado que la escala del negocio es pequeña, la complejidad del negocio es limitada y la cantidad de investigación y desarrollo no es grande, una arquitectura monolítica es la más adecuada en este momento. .
2. Por qué: ¿Por qué la servitización?
El propósito de la servitización es combinar de manera flexible servicios reutilizables para responder rápidamente a las necesidades comerciales cambiantes y respaldar pruebas y errores comerciales rápidos.
¿Cómo juzgar si un sistema necesita servitización? Por lo general, debemos considerar principalmente los siguientes factores:
- ¿Es un sistema grande y complejo?
- ¿Existe duplicación de construcción?
- ¿El negocio es incierto?
- ¿La tecnología restringe el desarrollo empresarial?
- ¿Existen cuellos de botella en el rendimiento del sistema?
Si un sistema tiene los problemas anteriores, entonces es una mejor manera de llevar a cabo la actualización técnica general y la reconstrucción comercial del sistema mediante la servitización.
3. Cómo: ¿Cómo implementar la servitización?
La estructura organizativa se ajusta en el lugar
. Para implementar mejor la servitización del sistema, el ajuste de la estructura organizativa es un paso muy crítico.
Porque una vez que el sistema esté orientado al servicio, algunos problemas del equipo se extenderán, como la división del trabajo en equipo, la colaboración, etc. Por lo tanto, sólo ajustando la estructura organizativa existente se pueden maximizar los beneficios de la servitización.
Una vez que la infraestructura orientada a servicios
está orientada a servicios, su énfasis principal está en la comunicación entre diferentes servicios , lo que dará lugar a una serie de problemas complejos que deben resolverse, como el registro de servicios, la publicación de servicios, la invocación de servicios y el equilibrio de carga. Espera, esto requiere una solución completa de gobernanza de servicios.
Por lo tanto, la condición necesaria para la servitización es tener un marco orientado a servicios, que debe poder resolver estos problemas complejos, y el rendimiento del marco orientado a servicios es particularmente importante.
Actualmente existen dos marcos principales orientados a servicios: SpringCloud y Dubbo .
Medios importantes de servitización.
- Diseño sin estado: La condición de estado sin estado facilita que los servicios se amplíen y reduzcan rápidamente.
- Diseño dividido: simplifica lo complejo, reduce la dificultad, divide y conquistarás.
4. Resumen
En una frase: desacoplamiento empresarial, reutilización de capacidades y entrega eficiente .
2.2 Diseño asincrónico
1. Qué: ¿Qué es asincrónico?
Asincrónico es un concepto de diseño relativo a la sincronización.
La sincronización significa que cuando se emite una llamada, la persona que llama tiene que esperar a que la llamada devuelva el resultado antes de continuar con la ejecución.
Asincrónico significa que cuando se emite una llamada, la persona que llama no obtendrá el resultado de inmediato, pero puede continuar realizando operaciones posteriores hasta que la persona que llama complete el procesamiento, y la persona que llama será notificada mediante estado, notificación o devolución de llamada.
2. Por qué: ¿Por qué asincrónico?
A través de la asincronía, se puede reducir la latencia, mejorar el rendimiento general del sistema y mejorar la experiencia del usuario.
3. Cómo: ¿Cómo implementar de forma asincrónica?
1) Asíncrono a nivel de IO
Las llamadas asincrónicas a nivel de IO son lo que a menudo llamamos modelo de E / S, que incluye bloqueo, no bloqueo, síncrono y asíncrono.
En el kernel del sistema operativo Linux, hay cinco modos de interacción IO diferentes integrados: IO de bloqueo, IO sin bloqueo, IO multiplexado, IO controlado por señal y IO asíncrono . Con respecto al modelo de IO de red, en Linux, el modelo más utilizado con mejor rendimiento es el modelo síncrono sin bloqueo.
Técnicas comunes para llamadas asincrónicas
- Comunicación asincrónica: NIO, Netty
2) Proceso asincrónico a nivel de lógica empresarial
El proceso asincrónico a nivel de lógica empresarial significa que nuestra aplicación se puede ejecutar de forma asincrónica en la lógica empresarial.
Por lo general, las empresas más complejas tendrán muchos procesos de pasos. Si todos los pasos están sincronizados, cuando uno de estos pasos se atasque, todo el proceso se atascará. Obviamente, el rendimiento de dicho proceso no será muy alto.
Por este motivo, en la industria, si queremos mejorar el rendimiento y la concurrencia, básicamente utilizaremos procesos asincrónicos.
Técnicas comunes para procesos asincrónicos.
- Cola de mensajes: desacoplamiento asincrónico, reducción de picos de tráfico
- Programación asincrónica: subprocesos múltiples, grupo de subprocesos
- Basado en eventos: patrón de publicación-suscripción (patrón de observador)
- Controlador de trabajo: tareas programadas, XXL-JOB
4. Resumen
Resumen de una frase: aunque la eficiencia de la ejecución asincrónica es alta, la complejidad y la dificultad de programación también lo son, así que no abuse de ella .
2.3 Diseño de agrupación
1. Qué: ¿Qué es la tecnología de agrupación?
La tecnología de agrupación es una tecnología común para mejorar el rendimiento. Mantiene recursos "costosos" y "que consumen mucho tiempo" en un "grupo" específico para reducir la creación y destrucción repetidas de recursos y facilitar la gestión y reutilización unificadas, mejorando así el rendimiento del sistema.
2. Por qué: ¿Por qué se necesita la tecnología de agrupación?
La tecnología de agrupación se utiliza para reducir la sobrecarga del sistema causada por la creación y destrucción repetidas y mejorar el rendimiento del sistema.
3. Cómo: ¿Cómo implementar la tecnología de agrupación?
Grupo de subprocesos
- TenedorJoinPool
- Los parámetros principales del grupo de subprocesos ThreadPoolExecutor
deben configurarse en función del escenario empresarial. Por ejemplo, la cantidad de subprocesos se puede establecer en función de si la tarea requiere uso intensivo de IO o CPU.
grupo de conexiones
- Grupo de conexiones de base de datos
- Grupo de conexiones de Redis
- Grupo de conexiones HttpClient
4. Resumen
En una frase: gestión unificada y reutilización de recursos para mejorar el rendimiento y la utilización de recursos .
2.4 Diseño de caché
1. Qué: ¿Qué es el caché?
El almacenamiento en caché es una tecnología que mejora la velocidad de acceso a los recursos . Sus características son: escribe una vez, lee innumerables veces.
La esencia del almacenamiento en caché es intercambiar espacio por tiempo. Sacrifica la naturaleza en tiempo real de los datos y utiliza datos almacenados en caché en la memoria en lugar de leer los datos más recientes del servidor de destino (como la base de datos), lo que puede reducir la presión del servidor y la latencia de la red.
2. Por qué: ¿Por qué utilizar el almacenamiento en caché?
El propósito de usar caché es obviamente mejorar el rendimiento del sistema (alto rendimiento, alta concurrencia).
¿Cuáles son las ventajas y desventajas de usar caché?
ventaja
- Optimice el rendimiento y acorte el tiempo de respuesta
- Reduzca el estrés y evite la sobrecarga del servidor
- Ahorre ancho de banda y alivie los cuellos de botella de la red
defecto
- consume espacio extra
- Puede haber problemas de coherencia de los datos
3. Cómo: ¿Cómo utilizar el caché?
1) ¿Cómo mejorar la velocidad de acceso a los recursos?
Coloque los recursos más cerca de los usuarios o en sistemas a los que se pueda acceder más rápidamente .
2) ¿Dónde se puede utilizar el caché?
| Clasificación de caché | dimensiones de caché | describir |
|---|---|---|
| caché del cliente | caché de navegador | 1. El punto de caché más cercano al usuario utiliza el dispositivo terminal del usuario para almacenar recursos de red, que es el más rentable. 2. Generalmente se usa para almacenar en caché imágenes, JS, CSS, etc., que se pueden controlar mediante los atributos Expires y Cache-Control en el encabezado del mensaje. |
| caché del servidor | caché CDN | 1. Almacene recursos estáticos como HTML, CSS, JS, etc. 2. Actuar como desvío para reducir la carga en el servidor de origen. |
| caché del servidor | caché de proxy inverso | 1. Separación de recursos dinámicos y estáticos: generalmente, los recursos estáticos se almacenan en caché y los recursos dinámicos se reenvían al servidor de aplicaciones para su procesamiento. |
| caché del servidor | caché local | 1. Memoria caché, velocidad de acceso rápida, adecuada para escenarios donde se almacenan en caché pequeñas cantidades de datos. 2. Almacenamiento en caché del disco duro, almacenamiento en caché de datos en archivos, la velocidad de acceso es más rápida que la obtención de datos a través de la red, adecuado para escenarios donde se almacenan en caché grandes cantidades de datos. |
| caché del servidor | Caché distribuido | 1. Elementos arquitectónicos necesarios en la arquitectura de sitios web a gran escala. 2. Almacenar en caché los datos del punto de acceso para reducir la presión de la base de datos. |
3) ¿Qué tipo de caché es más caro de introducir? ¿Por qué es más caro introducirlo?
El costo de introducción del caché local y el caché distribuido será mayor. Debido a que los recursos de estos dos tipos de cachés están relacionados con el negocio y deben calcularse mediante la lógica empresarial, los requisitos de coherencia de los datos entre el caché y los datos originales son mayores.
4) 1 indicador principal: tasa de aciertos de caché.
Cuanto mayor sea la tasa de aciertos de caché, mejor será el rendimiento. La fórmula de cálculo es: tasa de aciertos de caché = número de aciertos/(número de aciertos + número de errores).
¿Cómo mejorar la tasa de aciertos de la caché? Las estrategias comunes son las siguientes:
- Duración de la caché: en las mismas condiciones, cuanto mayor sea la duración de la caché, mayor será la tasa de aciertos de la caché.
- Actualización de caché: cuando los datos cambian, actualizar directamente el valor de la caché tiene una tasa de aciertos más alta que eliminar la caché.
- Capacidad de caché: cuanto mayor sea la capacidad de caché, más datos se almacenarán en caché y mayor será la tasa de aciertos de caché.
- Granularidad de la caché: cuanto menor es la granularidad de la caché, menores son los cambios de datos y mayor es la tasa de aciertos de la caché (reduce el riesgo de claves grandes)
- Precalentamiento de caché: los datos del punto de acceso se almacenan en caché de antemano para mejorar la tasa de aciertos de caché
Resumen en una frase: ¿Cómo mejorar la tasa de aciertos de caché? Esto es para permitir que los datos residan en la caché durante un período de tiempo más largo .
5) 1 problema central: la coherencia de la caché.
La coherencia de la caché se refiere a la coherencia entre la caché y los datos de origen. Para garantizar la coherencia de la caché, las cosas se volverán complicadas.
¿Cómo lograr la coherencia del caché? Las estrategias de almacenamiento en caché más utilizadas son las siguientes:
En la arquitectura Cache/DB, la estrategia de almacenamiento en caché es cómo leer y escribir datos desde Cache y DB.
1. Modo de caducidad de caché: patrón de caducidad de caché
- Características: la forma más sencilla de lograr la coherencia de la caché es establecer el tiempo de caducidad de la caché para lograr una coherencia final.
- Desventajas: necesidad de tolerar inconsistencias de datos en el tiempo de vencimiento establecido
2. Patrón de caché aparte: Patrón de caché aparte
- Leer: Cache Hit, devuelve directamente datos almacenados en caché, Cache Miss, carga datos de la base de datos al caché y devuelve
- Escribir: escriba primero en la base de datos y luego elimine los datos correspondientes en la caché
- Desventajas: este modo puede provocar inconsistencias de doble escritura entre el caché y la base de datos. Puede utilizar el modo de doble eliminación retrasada para minimizar esta inconsistencia.
3. Modo de escritura asincrónica: patrón de escritura detrás
- Leer: Cache Hit, devuelve directamente datos almacenados en caché, Cache Miss, devuelve directamente vacío
- Escritura: primero escriba en la base de datos, entregue los nuevos datos escritos a MQ a través de la base de datos, luego consuma MQ mediante el proceso asincrónico y finalmente escriba los datos en la caché.
Resumen en una frase: ¿Cómo lograr la coherencia del caché? Esto es para permitir que cada operación de lectura obtenga los datos de la operación de escritura más recientes .
4. Resumen
Resumen de una frase: el almacenamiento en caché es el rey cuando se trata de alta concurrencia (el almacenamiento en caché es el rey) .
2.5 Diseño de almacenamiento de datos
1. Qué: ¿Qué es el almacenamiento de datos?
El almacenamiento de datos generalmente se refiere a datos que se registran en algún formato en un medio de almacenamiento interno o externo de una computadora.
Los medios de almacenamiento comunes incluyen: cintas, discos, etc. La forma en que se almacenan los datos varía según el medio de almacenamiento. Solo se accede a los datos de la cinta en modo de archivo secuencial; en el disco, se puede utilizar el acceso secuencial o el acceso directo según los requisitos de uso. El método de almacenamiento de datos está estrechamente relacionado con la organización del archivo de datos, la clave es establecer la correspondencia entre el orden lógico y físico de los registros y determinar la dirección de almacenamiento para mejorar la velocidad de acceso a los datos.
Los sistemas de gestión de almacenamiento de datos comunes incluyen: base de datos (MySQL), motor de búsqueda (Elasticserach), sistema de caché (Redis), cola de mensajes (Kafka), etc. Este es también el foco de nuestra próxima discusión.
2. Por qué: ¿Por qué es importante el diseño del almacenamiento de datos?
En la era de Internet, cuando la concurrencia del sistema alcanza un cierto nivel, el almacenamiento de datos a menudo se convierte en un cuello de botella en el rendimiento. Si no realiza un buen diseño al principio, encontrará dificultades en la expansión horizontal posterior y en las subbases de datos y subtablas.
¿Por qué el cuello de botella en el rendimiento suele ser el almacenamiento de datos y no el servicio de la aplicación?
Debido a que los servicios de aplicaciones son básicamente sin estado y se pueden expandir fácilmente horizontalmente, el alto rendimiento de los servicios de aplicaciones será relativamente simple. Pero para un alto rendimiento del almacenamiento de datos, es relativamente más complicado porque los datos tienen estado.
3. Cómo: ¿Cómo diseñar el almacenamiento de datos?
Las soluciones comunes para resolver el almacenamiento de alto rendimiento incluyen las siguientes: la mayor parte de la industria se basa en ellas o fabrica derivados y extensiones relacionados.
1) Separación de lectura y escritura
Los sistemas de Internet tienden a leer más y escribir menos, por lo que el primer paso para optimizar el rendimiento es separar la lectura y la escritura.
La separación de lectura y escritura es un método de optimización que separa las operaciones de lectura de las operaciones de escritura. Podemos utilizar esta tecnología para resolver el problema del cuello de botella en el rendimiento del almacenamiento de datos.
Actualmente, las soluciones de separación de lectura y escritura populares en la industria generalmente se basan en la arquitectura del modelo maestro-esclavo , que implementa la separación de lectura y escritura de las acciones de acceso mediante la introducción de una capa de proxy de acceso a datos. En concreto, hay dos formas:
Implementación de la separación de lectura y escritura a través de un proxy independiente
La ventaja de introducir un proxy de acceso a datos es que el programa fuente puede lograr la separación de lectura y escritura sin ningún cambio. La desventaja es que debido a la adición de una capa adicional de middleware como proxy de transferencia, el rendimiento se reducirá y los agentes de acceso a los datos también pueden convertirse fácilmente en cuellos de botella en el rendimiento y existen ciertos costos de mantenimiento. Los productos típicos incluyen MyCAT, agente de base de datos Alibaba Cloud-RDS, etc.
Otra forma de lograr la separación de lectura y escritura a través del SDK integrado es cargar la capa de proxy de acceso a datos en el lado de la aplicación e integrarla con la aplicación a través del SDK, lo que puede evitar la pérdida de rendimiento y los costos de mantenimiento causados por una capa independiente . problema alto. Sin embargo, este método tiene ciertos requisitos para el lenguaje de desarrollo y problemas de aplicabilidad. Los productos típicos incluyen ShardingSphere, etc.
2) partición de datos
"Partición" se refiere al proceso de dividir físicamente los datos en partes separadas para su almacenamiento. Divida los datos en particiones que se puedan administrar y acceder a ellas de forma independiente. La partición puede mejorar la escalabilidad, reducir la contención y optimizar el rendimiento. Además, proporciona un mecanismo para segmentar datos por patrones de uso.
¿Por qué particionar los datos?
- Mejorar la escalabilidad . La ampliación de un sistema de base de datos único eventualmente alcanzará los límites del hardware físico. Si los datos se dividen en varias particiones, cada partición se aloja en un servidor independiente, lo que permite que el sistema se amplíe casi infinitamente.
- Mejorar el rendimiento . Las operaciones de acceso a datos en cada partición se realizan a través de volúmenes de datos más pequeños. Cuando se hace correctamente, la partición puede mejorar la eficiencia de su sistema.
- Proporcionar flexibilidad operativa . El uso de particiones puede optimizar las operaciones, maximizar la eficiencia de la gestión y reducir los costos de muchas maneras.
- Mejorar la usabilidad . Aislar datos en varios servidores evita puntos únicos de falla. Si una instancia falla, solo los datos de esa partición no estarán disponibles. Las operaciones en otras particiones pueden continuar.
¿Cómo diseñar particiones?
Tres estrategias típicas para la partición de datos:
- Partición horizontal (es decir, fragmentación) . En esta estrategia, cada partición es un almacén de datos independiente, pero todas las particiones tienen el mismo esquema. Cada partición, denominada fragmento, contiene un subconjunto específico de datos, como todos los pedidos de un conjunto específico de clientes. El factor más importante es la elección de la clave de fragmento. La fragmentación distribuye la carga entre varias máquinas, lo que reduce la contención y mejora el rendimiento.
- Partición vertical . En esta estrategia, cada partición contiene un subconjunto de los campos del elemento en el almacén de datos. Los campos se han segmentado según sus patrones de uso. Por ejemplo, coloque los campos a los que se accede con frecuencia en una partición vertical y los campos a los que se accede con menos frecuencia en otra partición vertical. El uso más común de la partición vertical es reducir los costos de E/S y de rendimiento asociados con la recuperación de elementos a los que se accede con frecuencia.
- Partición funcional . En esta estrategia, los datos se han agregado en función de cómo los utiliza cada contexto delimitado en el sistema. Por ejemplo, un sistema de comercio electrónico podría almacenar datos de facturas en una partición y datos de inventario de productos en otra partición. Mejore el rendimiento del aislamiento y el acceso a datos mediante particiones funcionales.
3) Subbase de datos y subtabla
Todos deberían estar familiarizados con el concepto de subbase de datos y subtabla, que se pueden dividir en dos métodos: subbase de datos y subtabla:
- División de tablas: se refiere a dividir los datos de una tabla en varias tablas de acuerdo con ciertas reglas para reducir el tamaño de los datos de la tabla y mejorar la eficiencia de las consultas.
- División de la base de datos: se refiere a dividir los datos de una base de datos en varias bases de datos de acuerdo con ciertas reglas para reducir la presión sobre un solo servidor y mejorar el rendimiento de lectura y escritura (como: CPU, memoria, disco, IO).
Dos soluciones típicas para fragmentar bases de datos y tablas:
dividir verticalmente
- División vertical de tablas : es decir, una tabla grande se divide en tablas pequeñas y los diferentes "campos" de una tabla se dividen en varias tablas. Por ejemplo, una biblioteca de productos divide la información básica del producto, el inventario de productos, la información del vendedor, etc. diferentes tablas de bases de datos.
- Descomposición vertical : divide diferentes áreas comerciales de un sistema en múltiples bibliotecas comerciales. Por ejemplo: biblioteca de productos, biblioteca de pedidos, biblioteca de usuarios, etc.
dividir horizontalmente
- División horizontal de tablas : divida los datos en varias tablas de acuerdo con ciertas dimensiones, pero dado que varias tablas todavía pertenecen a una base de datos, la granularidad del bloqueo se reduce, lo que mejora en cierta medida el rendimiento de las consultas, pero todavía existe un cuello de botella en el rendimiento de IO.
- División horizontal de la base de datos : divida los datos en múltiples bases de datos de acuerdo con ciertas dimensiones, lo que reduce la presión sobre una sola máquina y base de datos y mejora el rendimiento de lectura y escritura.
Métodos comunes de división horizontal
- Subbase de datos y tabla de rango : utilice el método de rango para dividir la clave de fragmentación según el rango. Por ejemplo: dividir la base de datos en tablas según el rango de tiempo.
- Fragmentación de bases de datos hash y fragmentación de tablas : utilice el módulo hash para fragmentar claves mediante hash. Por ejemplo: subbase de datos y tabla basada en el ID de usuario.
Para obtener más información sobre subbases de datos y subtablas, consulte el artículo: Práctica de desarrollo y diseño: plan de implementación de subbases de datos y subtablas , que no se describirá aquí.
4) Separación de frío y calor.
La separación en frío y en caliente se refiere al almacenamiento de datos fríos históricos y datos calientes actuales por separado. El almacenamiento en frío solo almacena los datos que alcanzan el estado final. El almacenamiento en caliente también almacena datos que necesitan modificar los campos. Esto puede reducir el volumen de almacenamiento del datos calientes actuales Mejorar el rendimiento.
¿Cómo determinar si los datos son datos fríos o datos calientes? En otras palabras, ¿bajo qué circunstancias se puede utilizar la separación de frío y calor?
- Dimensión de tiempo : los usuarios pueden aceptar que los datos nuevos y antiguos se consulten por separado. Por ejemplo, para los datos de pedidos, podemos usar los datos de hace tres meses como datos fríos y los datos de tres meses como datos activos.
- Dimensión de estado : una vez que los datos alcanzan el estado final, solo hay requisitos de lectura y no de escritura. Por ejemplo, para los datos de pedidos, podemos utilizar pedidos completados como datos fríos y otros como datos activos.
4. Resumen
En una frase: a través de la división, la presión de lectura y escritura se dispersa y la presión de almacenamiento se dispersa, mejorando así el rendimiento .
4. Finalmente
Mientras busca un alto rendimiento del sistema, no ignore el factor costo. Porque un alto rendimiento a menudo significa un alto coste.
Por tanto, a la hora de diseñar sistemas de alto rendimiento se debe prestar especial atención a minimizar costes y maximizar beneficios.
Finalmente, como técnico, debemos tener una búsqueda técnica: aprender a hacer más trabajo con los mismos recursos.