1. Обзор HBase
- HBase — распределенная система хранения столбцов, построенная на HDFS;
- HBase является важным членом экосистемы Apache Hadoop и в основном используется для хранения больших объемов структурированных данных;
- Логически HBase хранит данные в таблицах, строках и столбцах.
HDFS подходит для сценариев пакетной обработки:
Не поддерживает произвольный поиск данных
Не подходит для инкрементальной обработки данных
Не поддерживает обновление данных
Особенности таблиц HBase:
大:Таблица может иметь миллиарды строк и миллионы столбцов
无模式: каждая строка имеет сортируемый первичный ключ и любое количество столбцов.Столбцы можно добавлять динамически по мере необходимости, а разные строки в одной таблице могут иметь совершенно разные столбцы; :Column
面向列( хранение и управление разрешениями, ориентированное на семейство, независимый поиск по столбцам (семейству);
稀疏: пустые (нулевые) столбцы не занимают места для хранения, и таблица может быть очень разреженной; :
数据多版本данные в каждом блоке могут быть Несколько версий, по умолчанию автоматически назначается номер версии, который является меткой времени при вставке ячейки;
数据类型单一: Все данные в Hbase представляют собой строки и не имеют типа.
Сравнение хранения строк и хранения столбцов:
Традиционная база данных строк:
- Данные хранятся построчно
- Запросы без индексов используют много операций ввода-вывода.
- Создание индексов и материализованных представлений требует много времени и ресурсов.
- Для выполнения запросов база данных должна быть значительно расширена, чтобы соответствовать требованиям к производительности.
База данных столбцов:
- Данные хранятся в столбцах – каждый столбец хранится отдельно.
- Данные — это индекс
- Получите доступ только к столбцам, участвующим в запросе, — значительно сократите системный ввод-вывод.
- Каждый столбец обрабатывается потоком — параллельная обработка запросов.
- Согласованные типы данных и схожие характеристики данных — эффективное сжатие
2. Модель данных HBase
HBase是基于Google BigTable模型开发的,典型的key/value系统.
- Схема HBase может иметь несколько таблиц, и каждая таблица может состоять из нескольких семейств столбцов.
- HBase может иметь динамический столбец: имя столбца закодировано в ячейке; разные ячейки могут иметь разные столбцы.
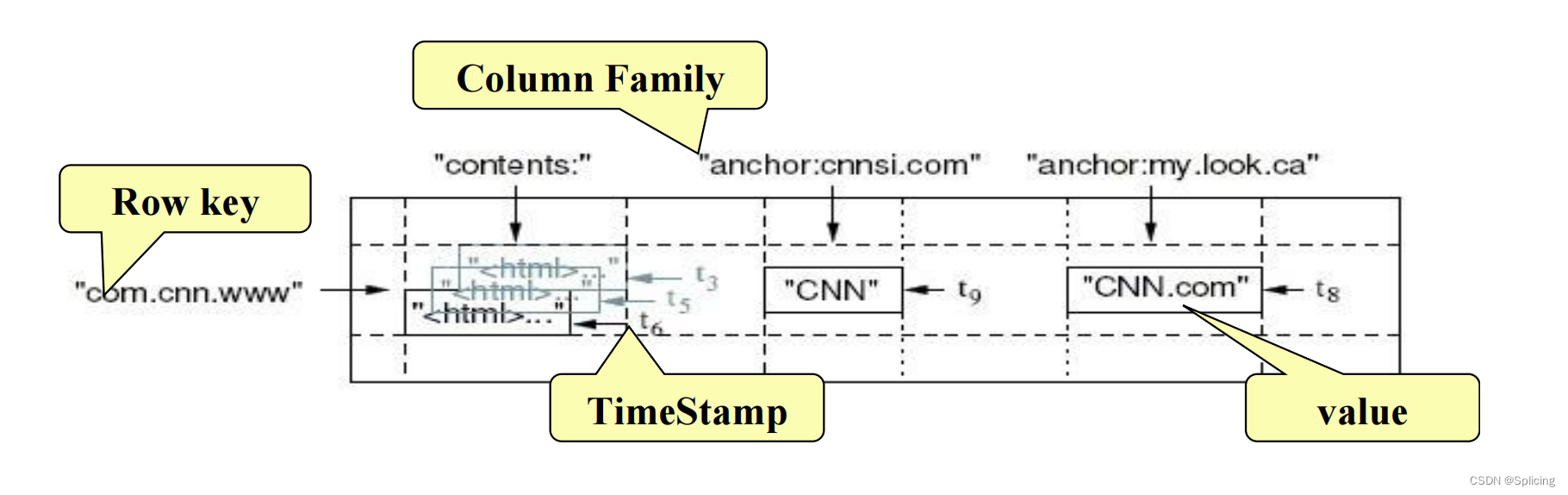
Семейство колонн Rowkey与
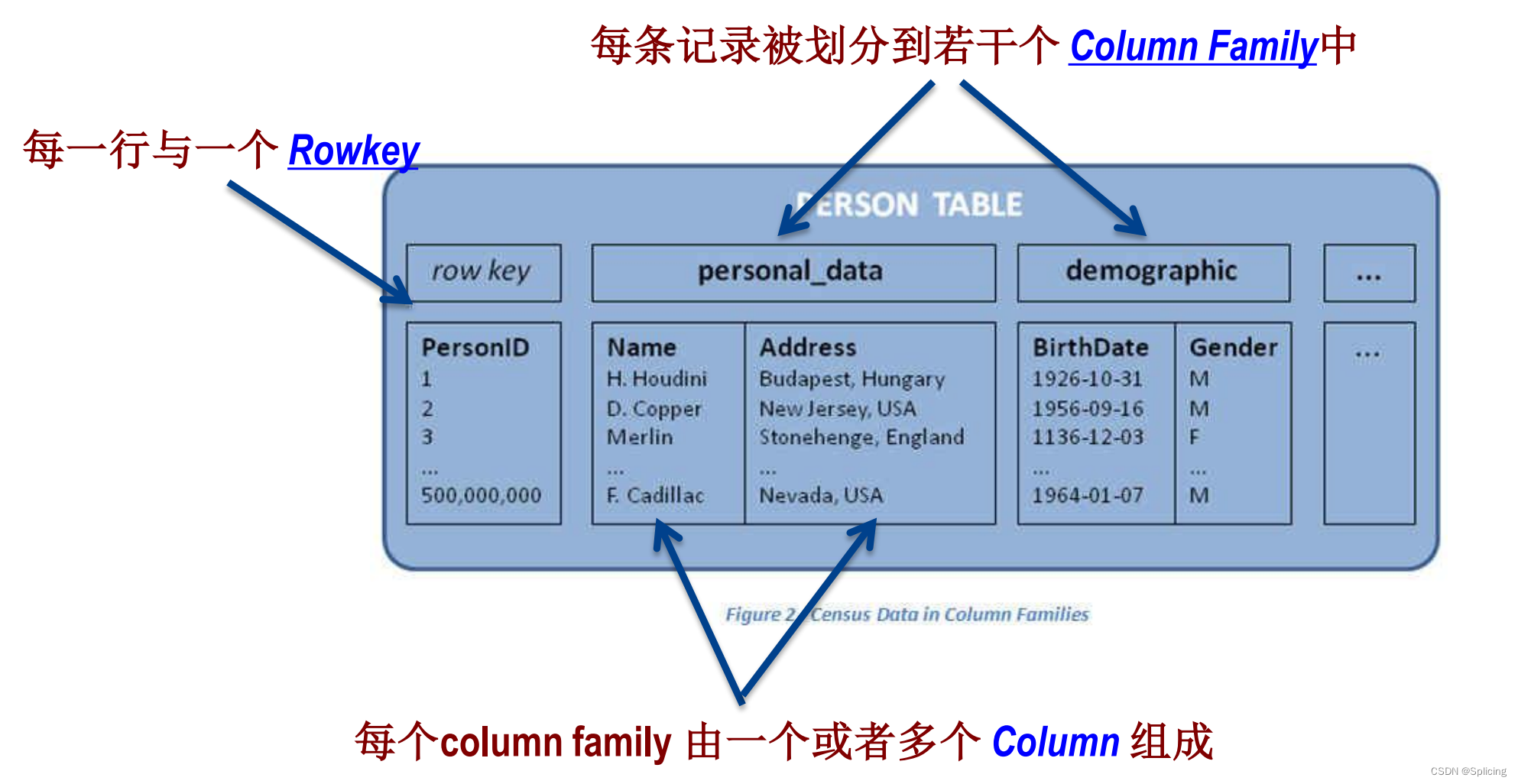
Row Key: "первичный ключ" каждой записи в таблице, который облегчает быстрый поиск. Ключ строки каждой строки должен быть уникальным и не требует вставки в порядке возрастания. : имеет имя и содержит один или несколько связанных столбцов
Column Family.
Column: Принадлежит к определенному семейству столбцов, содержащемуся в столбце FamilyName:columnName
Version Number: уникально для каждого ключа строки, значение по умолчанию -> системная метка времени, тип Long
Value (Cell): массив байтов
Операции, поддерживаемые Hbase
- Все операции основаны на ключе строки;
- Поддержка CRUD (создание, чтение, обновление и удаление) и сканирование;
- Однострочные операции: «Положить», «Получить», «Сканировать».
- Многострочные операции: Scan, MultiPut
- Встроенной операции соединения нет, и ее можно решить с помощью MapReduce.
3. Физическая модель HBase
- Каждое семейство столбцов хранится в отдельном файле в HDFS;
- Ключ и номер версии имеют одну копию в каждом семействе столбцов;
- Нулевые значения не сохранятся.
- HBase поддерживает многоуровневый индекс для каждого значения, а именно: <ключ, семейство столбцов, имя столбца, метка времени>
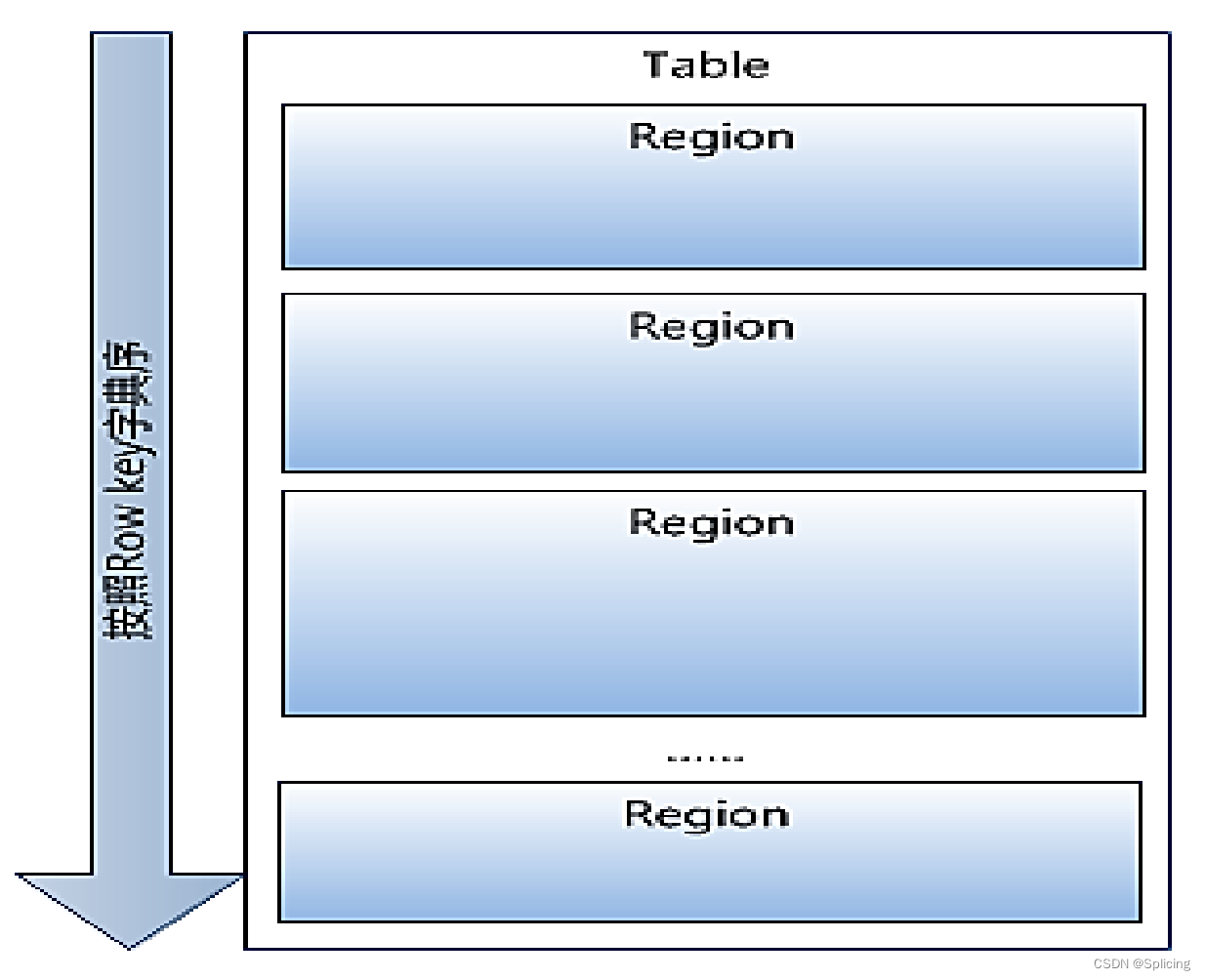
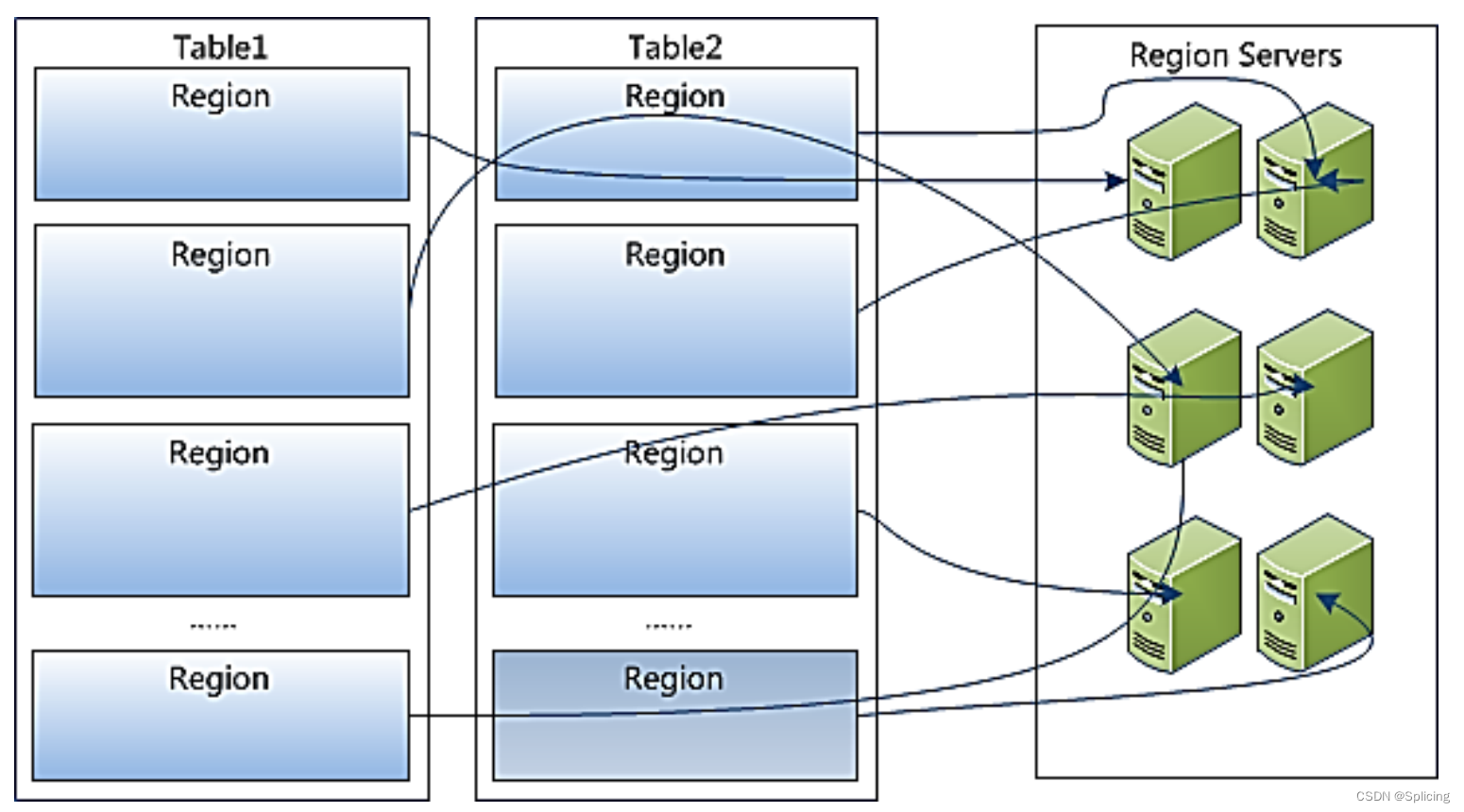
- 1. Все строки таблицы располагаются в словарном порядке по ключу строки;
- 2. Таблица разделена на несколько регионов в направлении строк;
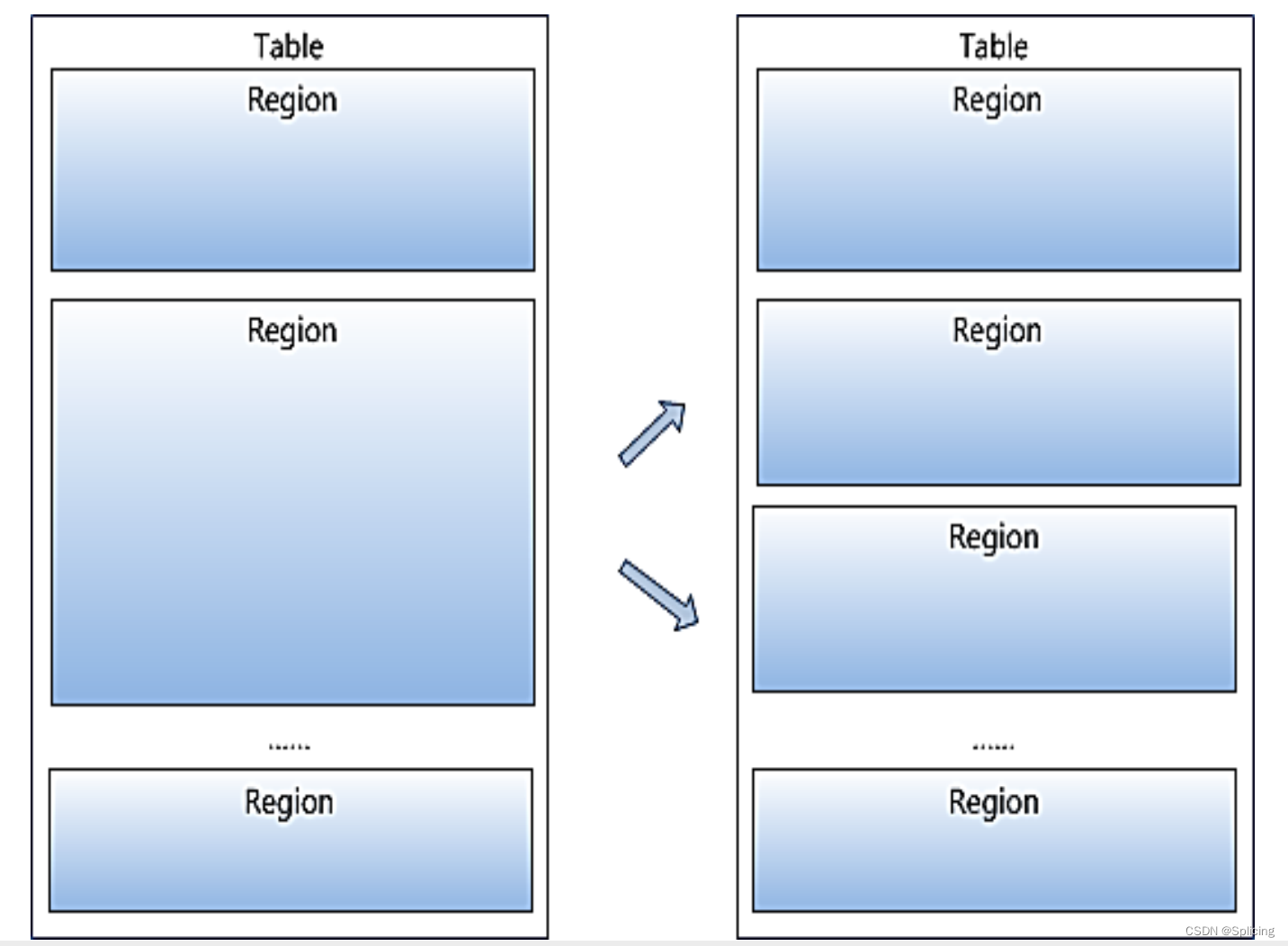
- 3.Регионы разделены по размеру.Каждая таблица начинается только с одного региона.По мере увеличения данных регион продолжает увеличиваться.Когда он увеличится до порогового значения, регион будет разделен на два новых региона, а затем появятся Все больше и больше регионов;
- 4. Регион — это наименьшая единица распределенного хранилища и балансировки нагрузки в HBase. Разные регионы распределяются по разным серверам региона;
- 5,
Region虽然是分布式存储的最小单元, но это не самая маленькая единица хранения (数据存储的最小单元是cell).
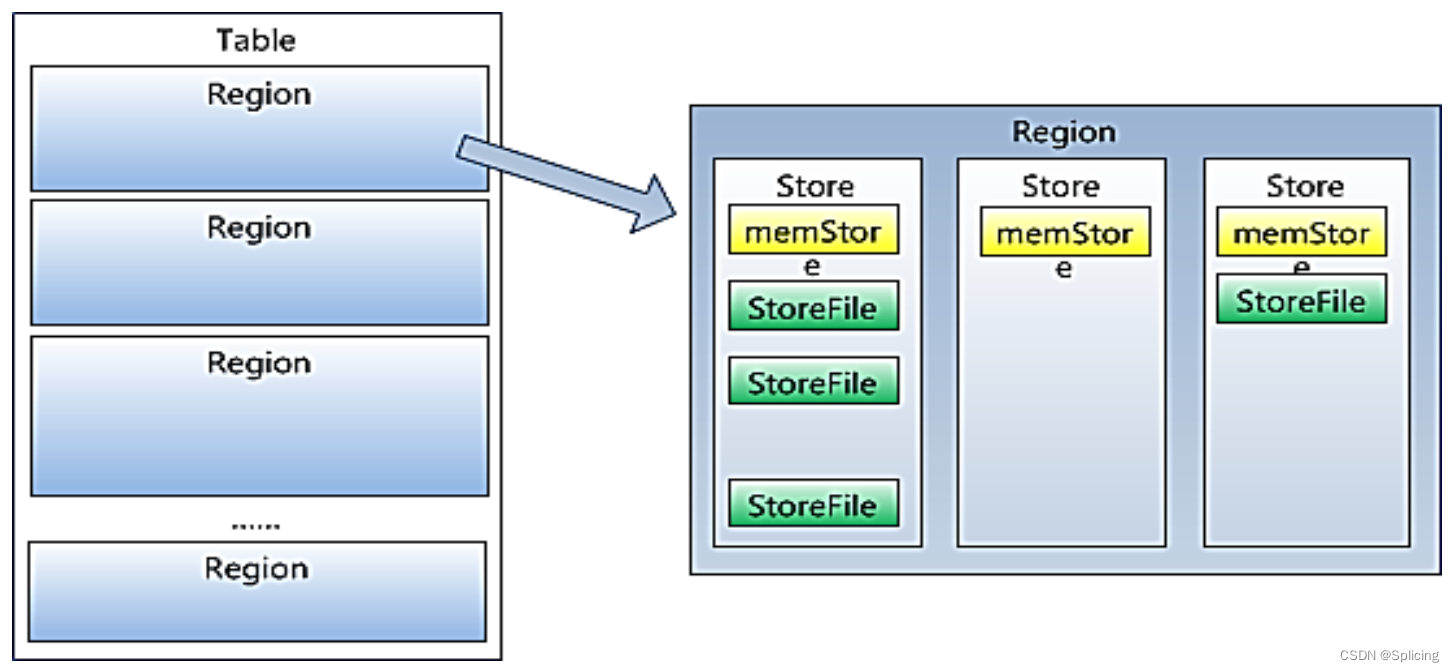
- Регион состоит из одного или нескольких магазинов, в каждом магазине хранится семейство столбцов;
- Каждое хранилище состоит из memStore и от 0 до нескольких StoreFiles;
- memStore хранится в памяти, а StoreFile хранится в HDFS.
4. Базовая структура HBase
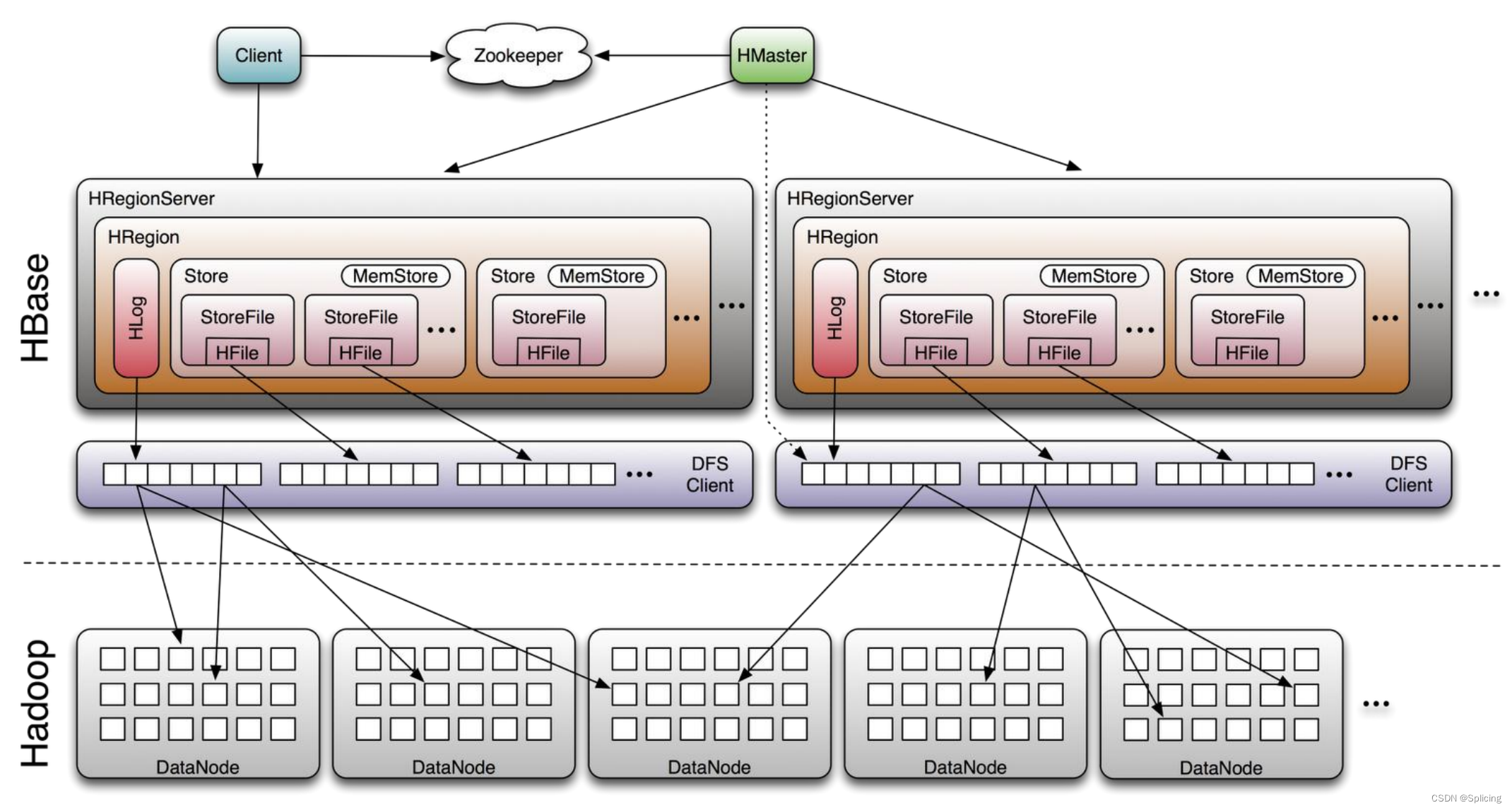
Базовые компоненты HBase
Клиент:
- Содержит интерфейсы для доступа к HBase и поддерживает кеш для ускорения доступа к HBase.
Работник зоопарка:
- Убедитесь, что в кластере всегда есть только один мастер.
- Сохраните записи адресации всех регионов.
- Отслеживайте онлайн- и офлайн-информацию сервера региона в режиме реального времени. И уведомить Мастера в режиме реального времени
- Храните схему HBase и метаданные таблицы.
Владелец:
- Назначить регион серверу региона
- Отвечает за балансировку нагрузки сервера региона.
- Обнаружьте неисправный региональный сервер и перераспределите на нем регионы.
- Управляйте операциями пользователей по добавлению, удалению, изменению и проверке таблиц.
Сервер региона:
- Сервер региона поддерживает регионы и обрабатывает запросы ввода-вывода в эти регионы.
- Сервер регионов отвечает за разделение регионов, которые в процессе работы становятся слишком большими.
Роль смотрителя зоопарка
HBase использует ZooKeeper.
По умолчанию HBase управляет экземплярами ZooKeeper. Например, запуск или остановка ZooKeeper
Master и RegionServers будут регистрироваться в ZooKeeper при запуске.Внедрение
Zookeeper делает Master больше не единственной точкой отказа.
Журнал упреждающей записи (WAL)
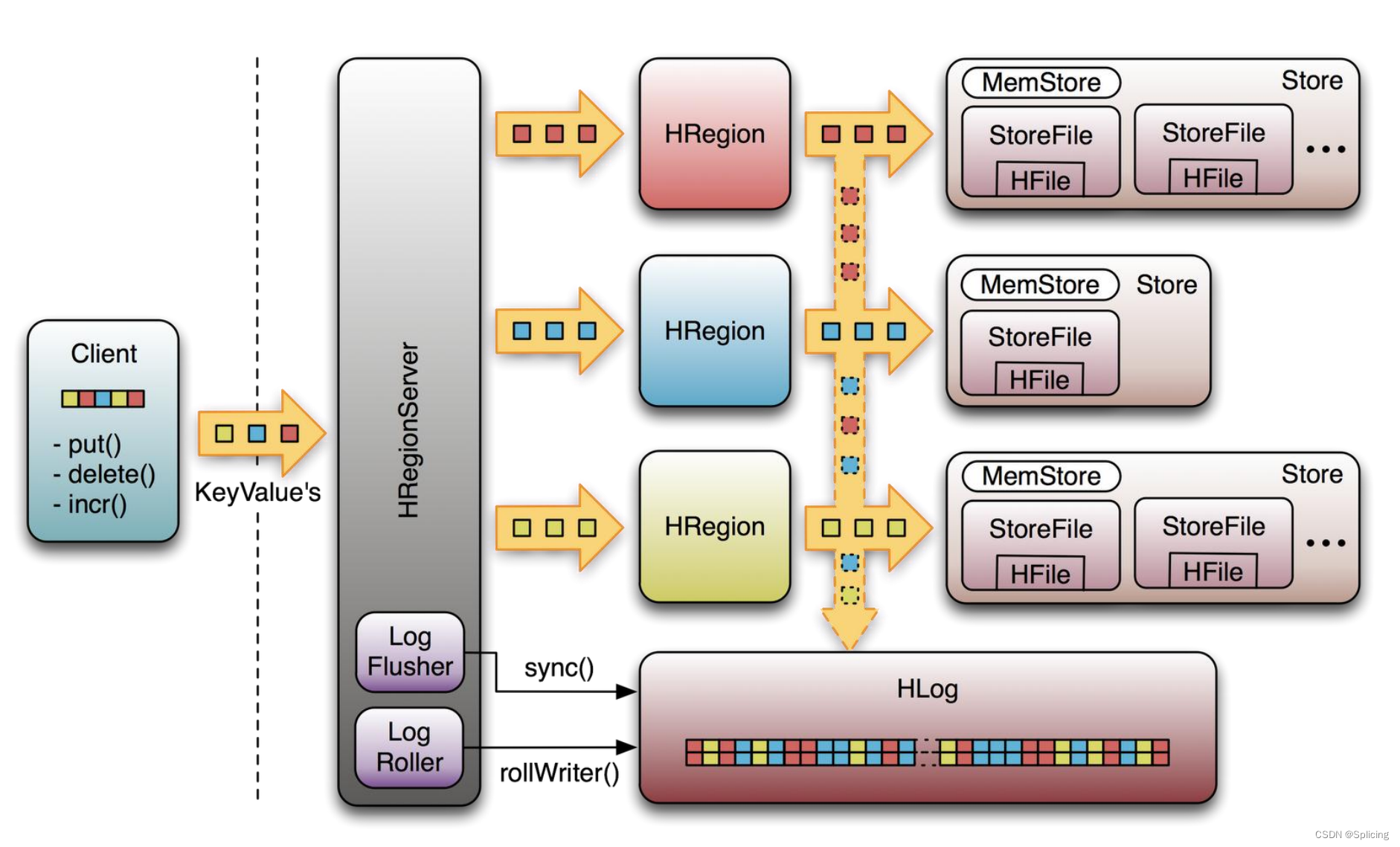
Отказоустойчивость HBase
Отказоустойчивость мастера: Zookeeper повторно выбирает нового мастера
- В процессе без Мастера чтение данных продолжается как обычно;
- В процессе без мастера не может быть выполнена сегментация регионов, балансировка нагрузки и т.п.;
Отказоустойчивость RegionServer: регулярно сообщает о тактовых сигналах в Zookeeper, если в течение определенного времени тактовых импульсов не происходит.
- Мастер перераспределяет регион на сервере региона между другими серверами региона;
- Журнал «упреждающей записи» на вышедшем из строя сервере разделяется основным сервером и отправляется на новый сервер региона.
Отказоустойчивость Zookeeper: Zookeeper — надежный сервис
- Обычно настраиваются 3 или 5 экземпляров Zookeeper.
Region定位: Ищем RegionServer -> (ZooKeeper, -ROOT-(один регион), .META., таблица пользователя)
-КОРЕНЬ-
- Таблица содержит список регионов, в которых находится таблица .META.. В таблице будет только один регион;
- Местоположение таблицы -ROOT- записывается в Zookeeper.
.МЕТА.
- Таблица содержит список всех регионов пользовательского пространства и адрес сервера RegionServer.