Arquitectura de RegionServer
Arquitectura detallada de RegionServer:
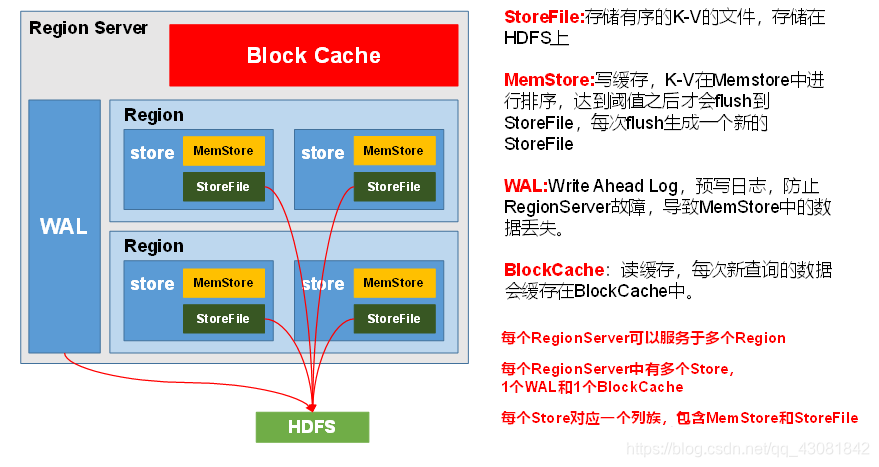
- StoreFile
almacena los archivos físicos de datos reales y StoreFile se almacena en HDFS en forma de Hfile. Cada tienda tiene uno o más StoreFiles (HFile) y los datos se ordenan en cada StoreFile. - MemStore
escribir caché. Dado que los datos en HFile deben ordenarse, los datos se almacenan primero en MemStore. Después de ordenar, se actualizará a HFile cuando se alcance el tiempo de parpadeo. Cada parpadeo formará uno nuevo. HFile. - Los
datos de WAL deben ser ordenados por MemStore antes de ser descargados a HFile, pero almacenar los datos en la memoria tiene una alta probabilidad de causar la pérdida de datos. Para resolver este problema, los datos se escribirán en un archivo llamado Write-Ahead logfile., Y luego escríbalo en MemStore. Entonces, cuando el sistema falla, los datos se pueden reconstruir a través de este archivo de registro.
Cada intervalo hbase.regionserver.optionallogflushinterval (predeterminado 1s), HBase escribirá la operación desde la memoria a WAL.
Todas las regiones de un RegionServer comparten una instancia de WAL.
El intervalo de verificación WAL está definido por hbase.regionserver.logroll.period, y el valor predeterminado es 1 hora. El contenido de la verificación es comparar las operaciones en el WAL actual con las operaciones que realmente persisten en HDFS, para ver qué operaciones se han persistido y las operaciones persistentes se moverán a la carpeta .oldlogs (esta carpeta también está activada). HDFS). Una instancia de WAL contiene varios archivos WAL. El número máximo de archivos WAL se define mediante el parámetro hbase.regionserver.maxlogs (el valor predeterminado es 32). - ) BlockCache
lee el caché y los datos consultados cada vez se almacenarán en caché en BlockCache, lo que es conveniente para la siguiente consulta.
Proceso de escritura de HBase
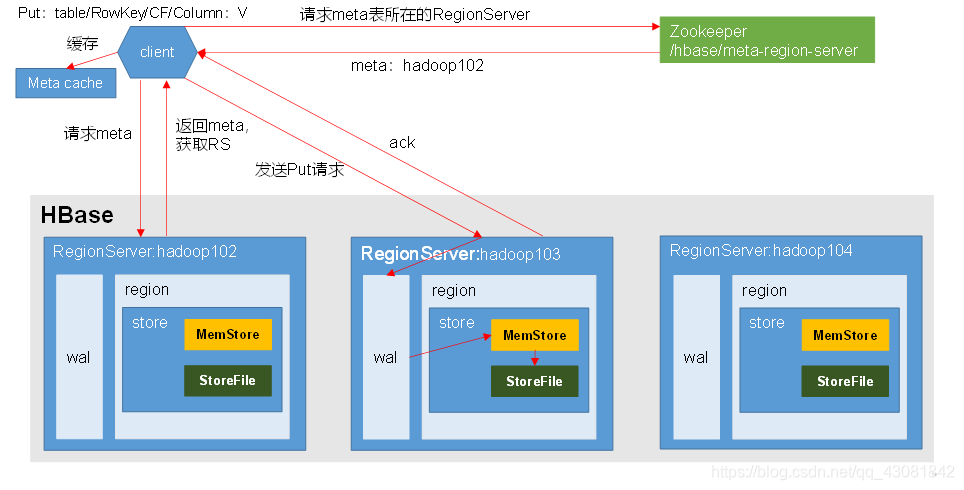
Proceso de escritura:
- El cliente primero accede a zookeeper para obtener en qué servidor de región se encuentra la tabla hbase: meta.
- Acceda al servidor de región correspondiente, obtenga la meta tabla hbase: y consulte en qué región del servidor de región se encuentran los datos de destino de acuerdo con el espacio de nombres: tabla / clave de fila de la solicitud de lectura. La información de la región de la tabla y la información de ubicación de la metatabla se almacenan en la memoria caché del cliente para facilitar el siguiente acceso.
- Comunicarse con el servidor de región de destino;
- Escriba (agregue) datos secuencialmente a WAL;
- Escriba los datos en el MemStore correspondiente y los datos se ordenarán en el MemStore;
- Envíe una respuesta al cliente;
- Después de alcanzar el tiempo de parpadeo de MemStore, actualice los datos a HFile.
Proceso de lectura de HBase
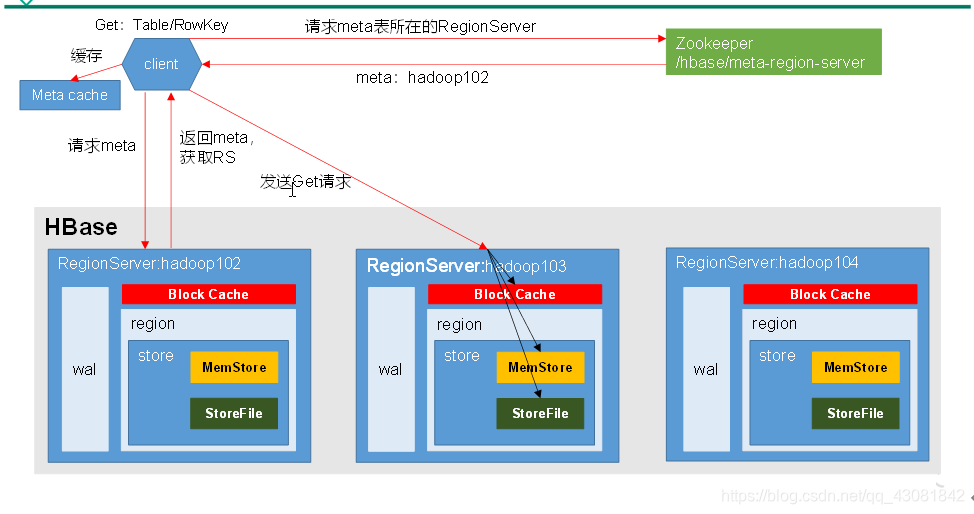
Proceso de lectura
- El cliente primero accede a zookeeper para obtener en qué servidor de región se encuentra la tabla hbase: meta.
- Acceda al servidor de región correspondiente, obtenga la meta tabla hbase: y consulte en qué región del servidor de región se encuentran los datos de destino de acuerdo con el espacio de nombres: tabla / clave de fila de la solicitud de lectura. La información de la región de la tabla y la información de ubicación de la metatabla se almacenan en la memoria caché del cliente para facilitar el siguiente acceso.
- Comunicarse con el servidor de región de destino;
- Consulte los datos de destino en Block Cache (caché de lectura), MemStore y Store File (HFile), y combine todos los datos encontrados. Todos los datos aquí se refieren a diferentes versiones (marca de tiempo) o diferentes tipos (Put / Delete) del mismo dato.
- Almacene en caché el bloque de datos consultado (bloque, unidad de almacenamiento de datos HFile, el tamaño predeterminado es 64 KB) en la caché de bloques.
- El resultado final después de la fusión se devuelve al cliente.
MemStore Flush
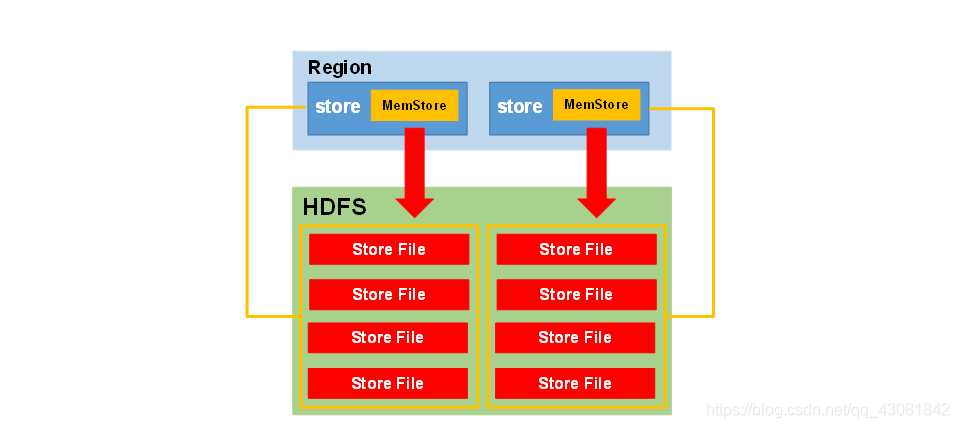
El significado de la existencia de MemStore es organizar los datos de manera ordenada antes de escribir en HDFS.
Tiempo de flash MemStore:
-
Cuando el tamaño de un memstore alcanza hbase.hregion.memstore.flush.size (el valor predeterminado es 128M), todos los memstores de la región se eliminarán. Cuando se alcanza el tamaño de memstore
Cuando hbase.hregion.memstore.flush.size (valor predeterminado 128M) * hbase.hregion.memstore.block.multiplier (valor predeterminado 4)
, evitará continuar escribiendo datos en el memstore. -
Cuando el tamaño total del memstore en el servidor de la región alcanza
java_heapsize * hbase.regionserver.global.memstore.size (valor predeterminado 0.4) * hbase.regionserver.global.memstore.size.lower.limit (valor predeterminado 0.95)
La región se mostrará en orden de tamaño de todas sus memorias (grandes a pequeñas). Hasta que el tamaño total de todos los almacenes de memoria del servidor de la región se reduzca por debajo del valor anterior.
-
Cuando el tamaño total del memstore en el servidor de la región alcanza
java_heapsize * hbase.regionserver.global.memstore.size (valor predeterminado 0.4)
, evitará escribir datos en todos los almacenes de memoria. -
Cuando se alcance el tiempo de descarga automática, también se activará la descarga de memstore. El intervalo de actualización automática se configura mediante esta propiedad hbase.regionserver.optionalcacheflushinterval (el valor predeterminado es 1 hora).
-
Cuando el número de archivos WAL excede hbase.regionserver.max.logs, la región se vaciará en orden cronológico hasta que el número de archivos WAL se reduzca por debajo de hbase.regionserver.max.log (este nombre de atributo es obsoleto y no hay necesita configurarlo manualmente ahora, el valor máximo es 32).
Compactación StoreFile
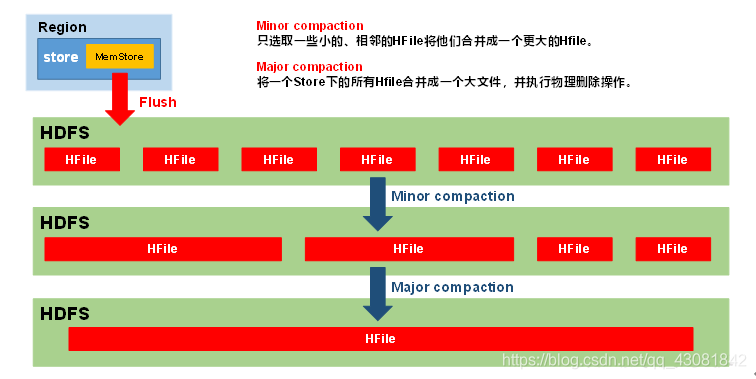
- Dado que Hbase se basa en el almacenamiento HDFS, HDFS solo admite escrituras adicionales. Por lo tanto, cuando se agrega una nueva celda, HBase agrega una nueva pieza de datos en HDFS. Al modificar una celda, HBase agrega otro dato a HDFS, pero el número de versión es mayor que el anterior (o personalizado). ¡Al eliminar una celda, HBase aún agrega una nueva pieza de datos! Es solo que este dato no tiene valor y el tipo es DELETE, también conocido como marca de lápida (Tombstone)
- HBase realizará una compactación (Compactación) cada intervalo de tiempo, y el objeto combinado es el archivo HFile. La fusión se divide en dos tipos de compactación menor y compactación mayor.
- Cuando HBase realiza una compactación importante, fusiona varios archivos H en un archivo H. En este proceso, una vez que se detecta un registro marcado con una lápida, este registro se ignora durante el proceso de combinación. De esta manera, en el archivo HFile recién generado, no existe tal registro, lo que naturalmente equivale a ser realmente eliminado
- Dado que memstore genera un nuevo HFile cada vez que se actualiza, y diferentes versiones (marca de tiempo) y diferentes tipos (Put / Delete) del mismo campo pueden distribuirse en diferentes HFiles, es necesario atravesar todos los HFiles al realizar consultas. Para reducir la cantidad de HFiles y limpiar los datos caducados y eliminados, se realizará la compactación de StoreFile.
- La compactación se divide en dos tipos, a saber, compactación menor y compactación mayor. La compactación menor fusionará varios archivos H más pequeños adyacentes en un archivo H más grande, pero no limpiará los datos caducados y eliminados. Major Compaction fusionará todos los archivos H de una tienda en un archivo H grande y limpiará los datos caducados y eliminados.
División de región
De forma predeterminada, cada tabla tiene solo una región al principio. Como los datos se escriben continuamente, la región se dividirá automáticamente. Al dividir, las dos subregiones se encuentran en el servidor de región actual, pero por consideraciones de equilibrio de carga, HMaster puede transferir una región a otro servidor de región.
Tiempo de división de región:
- Cuando el tamaño total de todos los StoreFiles en una tienda en una región excede hbase.hregion.max.filesize, la región se dividirá (antes de la versión 0.94).
- La estrategia de división después de la versión 0.94
usa la estrategia IncreasingToUpperBoundRegionSplitPolicy para dividir la región de forma predeterminada, getSizeToCheck () comprueba el tamaño de la región para determinar si se cumplen las condiciones de corte y corte.
protected long getSizeToCheck(final int tableRegionsCount) {
// safety check for 100 to avoid numerical overflow in extreme cases
return tableRegionsCount == 0 || tableRegionsCount > 100
? getDesiredMaxFileSize()
: Math.min(getDesiredMaxFileSize(),
initialSize * tableRegionsCount * tableRegionsCount * tableRegionsCount);
}
tableRegionsCount: el número de regiones que pertenecen a la tabla en el servidor de región actual.
getDesiredMaxFileSize () Este valor es el valor del parámetro hbase.hregion.max.filesize y el valor predeterminado es 10 GB.
La inicialización de initialSize es más complicada y está determinada por múltiples parámetros.
@Override
protected void configureForRegion(HRegion region) {
super.configureForRegion(region);
Configuration conf = getConf();
//默认hbase.increasing.policy.initial.size 没有在配置文件中指定
initialSize = conf.getLong("hbase.increasing.policy.initial.size", -1);
if (initialSize > 0) {
return;
}
// 获取用户表中自定义的memstoreFlushSize大小,默认也为128M
HTableDescriptor desc = region.getTableDesc();
if (desc != null) {
initialSize = 2 * desc.getMemStoreFlushSize();
}
// 判断用户指定的memstoreFlushSize是否合法,如果不合法,则为hbase.hregion.memstore.flush.size,默认为128.
if (initialSize <= 0) {
initialSize = 2 * conf.getLong(HConstants.HREGION_MEMSTORE_FLUSH_SIZE,
HTableDescriptor.DEFAULT_MEMSTORE_FLUSH_SIZE);
}
}
La estrategia de segmentación específica es que tableRegionsCount esté entre 0 y 100, luego
initialSize (el predeterminado es 2 * 128) * tableRegionsCount ^ 3, por ejemplo:
la primera división: 1 ^ 3 * 256 = 256 MB la
segunda división: 2 ^ 3 * 256 =
2048 MB La tercera división: 3 ^ 3 * 256 = 6912 MB La
cuarta división: 4 ^ 3 * 256 = 16384 MB> 10 GB, así que tome el valor más pequeño de 10 GB
y el tamaño de cada división es 10 GB.
Si tableRegionsCount supera los 100, la región se dividirá si supera los 10 GB.

hbase.regionserver.region.split.policy :