HBase ist eine verteilte, skalierbare, spaltenorientierte Datenspeicherung (Millionen Spalten), skalierbare, hochzuverlässige NoSQL-Datenbank zum Lesen und Schreiben in Echtzeit.
HBase verwendet HDFS von Hadoop als Dateispeichersystem, MapReduce zur Verarbeitung großer Datenmengen in HBase und Zookeeper als verteilten kollaborativen Dienst.
HBase-Grundbetriebsbefehle:
# 进入HBase 客户端
[zsm@hadoop102 hbase-1.3.1]$ bin/hbase shell
# 查看所有的表
hbase(main):002:0> list
TABLE
stu
stu2
stu3
stu4 Tabelle erstellen:
create 'tableName', 'cf1', 'cf2'Erstellen Sie eine Tabelle mit zwei Spaltenfamilien cf1 und cf2
Daten einfügen:
put 'tableName', 'row1', 'cf1:column1', 'value1'Fügen Sie in der Zeile [row1] der Tabelle den Wert [value1] in die Spalte [column1] unter der Spaltenfamilie [cf1] ein
Daten aktualisieren:
put 'tableName', 'row1', 'cf1:column1', 'value2'Ändern Sie die Zeile [row1] der Tabelle, den Spaltenwert [column1] unter der Spaltenfamilie [cf1] in [value2]
Daten anzeigen:
# 查看指定行
get 'tableName', 'row1'
# 查看指定行的指定列族的指定列
get 'tableName', 'row1', 'cf1:column1'Vollständige Tabellenscandaten:
# 全表扫描
scan 'tableName'
# 分段扫描 ,从row1行开始 【, 到row2行结束】
scan 'tableName', {STARTROW => 'row1' [, STOPROW => 'row2']}Bedingter Filter:
# 单列值过滤器(SingleColumnValueFilter)
scan 'mytable', {FILTER => "SingleColumnValueFilter('cf1', 'column1', '=', 'value1')"}
# 组合过滤
scan 'mytable', {FILTER => "FilterList(AND, SingleColumnValueFilter('cf1', 'column1', '=', 'value1'), SingleColumnValueFilter('cf2', 'column2', '>=', '100'))"}
# 页码过滤
scan 'mytable', {FILTER => "PageFilter(10)"}
# 行键范围过滤器(RowFilter)
scan 'mytable', {FILTER => "RowFilter(>=, 'binary:row1')"}Tabelle, Daten löschen
# 删除表
disable 'tableName'
drop 'tableName'
# 清空表
truncate 'tableName'
# 删除某一行
delete 'tableName', 'row1'
# 删除某一列
delete 'tableName', 'row1', 'cf1:column1'HBase-Datenmodell
Das Datenmodell von HBase ist dem einer relationalen Datenbank sehr ähnlich. Daten werden in einer Tabelle mit Zeilen und Spalten gespeichert. Aus der Perspektive der zugrunde liegenden physischen Speicherstruktur (KV) von HBase ähnelt HBase jedoch eher einer multi-dimensional map(多维度 K-V). Es handelt sich um einen spaltenorientierten Datenspeicher, der Millionen von Spalten aufnehmen kann.
Physische HBase-Speicherstruktur:
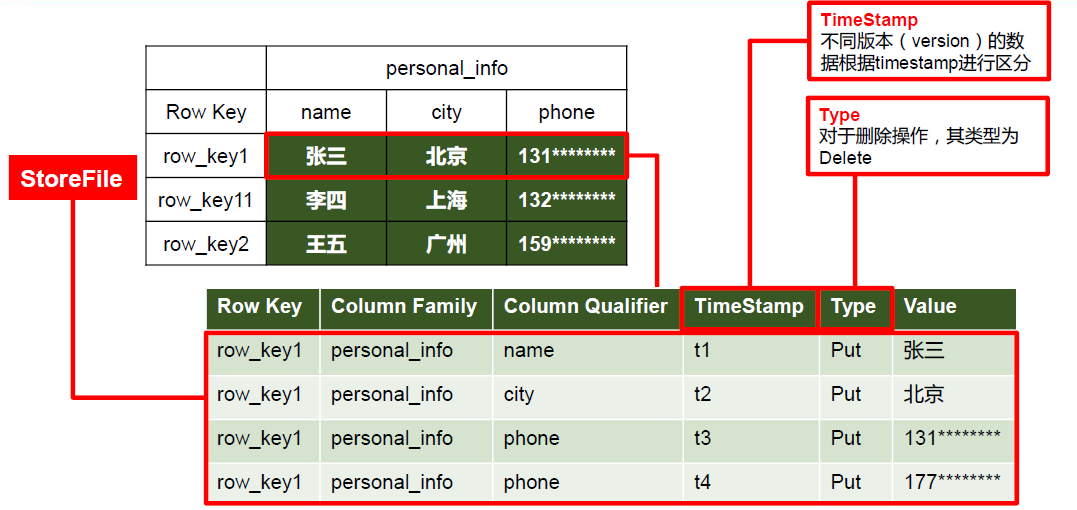
Die Hauptkomponenten des HBase-Datenmodells:
-
Tabelle: Daten in HBase werden in Tabellen gespeichert und jede Tabelle hat einen eindeutigen Namen. Eine Tabelle besteht aus Zeilen und Spalten und speichert Daten in Form von Schlüssel-Wert-Paaren.
-
Zeile: In HBase wird jede Zeile durch einen eindeutigen Zeilenschlüssel identifiziert. Der Zeilenschlüssel ist ein Byte-Array variabler Länge, lexikografisch sortiert. Zeilenschlüssel sind die Hauptmethode für den Datenzugriff und die Datenabfrage in HBase.
-
Spaltenfamilie: Die Spalten in einer Tabelle sind nach der Spaltenfamilie organisiert, die eine Gruppe von Spalten mit ähnlichen Attributen definiert. Jede Spaltenfamilie hat einen eindeutigen Namen. Spalten verschiedener Spaltenfamilien werden separat im physischen Speicher gespeichert, sodass für Daten verschiedener Spaltenfamilien unterschiedliche Speicher- und Komprimierungsstrategien festgelegt werden können.
-
Spaltenqualifizierer (Column Qualifier): Der Spaltenqualifizierer wird verwendet, um jede Spalte in der Spaltenfamilie zu identifizieren, die innerhalb der Spaltenfamilie eindeutig ist. Wenn die Spaltenfamilie beispielsweise „Benutzer“ lautet, könnte der Spaltenqualifizierer „Alter“, „Name“ usw. lauten.
-
Zelle: Eine Zelle besteht aus Zeilenschlüssel, Spaltenfamilie, Spaltenqualifizierer und Zeitstempel. Daten in einer Tabelle bestehen aus mehreren Zellen.
-
Versionsnummer (Version): HBase unterstützt das Speichern mehrerer Datenversionen. Jede Zelle kann mehrere Versionen eines Werts speichern, jede mit einem entsprechenden Zeitstempel. Die historische Abfrage und Versionskontrolle von Daten kann über die Versionsnummer realisiert werden.
-
Namespace (Namespace): Ein Namespace ist eine logische Gruppierung von Tabellen, die einem Namespace-Container entspricht. Es bietet eine Möglichkeit, Tabellen logisch zu isolieren und zu verwalten.
Prinzip der HBase-Architektur:
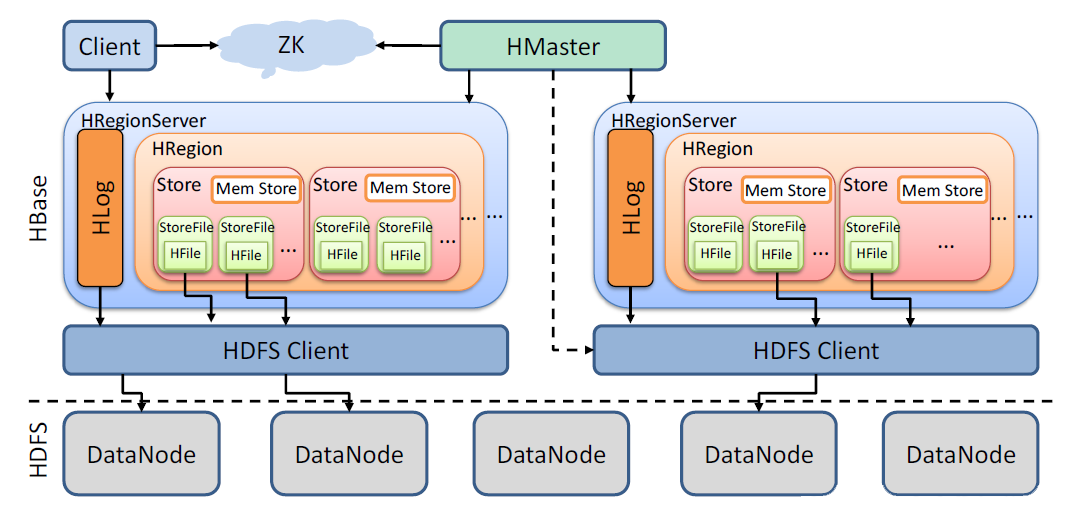
- Client: Enthält die Schnittstelle für den Zugriff auf HBase und verwaltet den Cache, um den Zugriff auf HBase zu beschleunigen
- Tierpfleger:
- Stellen Sie sicher, dass es immer nur einen aktiven Master im Cluster gibt
- Speichern Sie die Adressierungseinträge aller Regionen
- Überwachen Sie die Online- und Offline-Informationen des Regionsservers in Echtzeit und benachrichtigen Sie den Master in Echtzeit
- Speichern Sie Metadaten des Schemas und der Tabelle von HBase
- Meister
- Weisen Sie RegionServer Region zu
- Verantwortlich für den Lastausgleich des Regionsservers
- Entdecken Sie ungültige Regionsserver und weisen Sie ihnen Regionen neu zu
- Verwalten Sie Benutzerhinzufügungen, -löschungen und -änderungen an Tabellen
- RegionServer
- Speichern Sie die tatsächlichen Daten von HBase
- Leeren Sie den Cache in HDFS
- Pflegen Sie Regionen und bearbeiten Sie E/A-Anfragen für diese Regionen
- Segmentieren Sie einen Bereich, der sich während des Betriebs zu stark ändert
- Region: Die kleinste Einheit des verteilten HBase-Speichers und Lastausgleichs, einschließlich eines oder mehrerer Stores, und jeder Store speichert eine Spaltenfamilie.
- Store: Beinhaltet Memstore im Speicher und Storefile auf der Festplatte. Wenn der Client Daten abruft, sucht er zunächst im Memstore danach. Wenn er sie nicht finden kann, sucht er nach der Storedatei.
- MemStore: Es wird im Speicher abgelegt und die geänderten Daten werden als Schlüsselwerte gespeichert. Wenn die Größe des MemStores einen Schwellenwert erreicht (standardmäßig 64 MB), wird der MemStore in die Datei geleert.
- StoreFile: Nachdem die Daten im MemStore-Speicher in die Datei geschrieben wurden, wird sie zur StoreFile. Die unterste Ebene der StoreFile wird im HFile-Format gespeichert.
- Wenn die Anzahl der Storefile-Dateien einen bestimmten Schwellenwert erreicht, führt das System eine Zusammenführung durch (kleinere, größere Komprimierung) und während des Zusammenführungsvorgangs wird eine Versionszusammenführung und -löschung (Majar) durchgeführt, um eine größere Storefile zu bilden
- Wenn die Größe aller Storefiles in einer Region einen bestimmten Schwellenwert überschreitet, wird die aktuelle Region in zwei Teile geteilt und der Hmaster wird dem entsprechenden Regionserver-Server zugewiesen, um einen Lastausgleich zu erreichen
- HFile: Das Speicherformat von KeyValue-Daten in HBase, der Binärformatdatei von Hadoop.
- HLog: WAL-Protokoll --- WAL steht für Write-Ahead-Protokoll, das für die Notfallwiederherstellung verwendet wird. HLog zeichnet alle Datenänderungen auf. Sobald der Regionsserver ausfällt, kann er aus dem Protokoll wiederhergestellt werden.