Documento de defensa y ataque adversario de NeurIPS
NeurIPS2022|Recopilación de artículos de defensa y ataque adversario-Zhihu
BIRD: Detección y eliminación de puertas traseras generalizables para el aprendizaje por refuerzo profundo
https://neurips.cc/virtual/2023/poster/70618
Resumen:
Los ataques de puerta trasera representan una seria amenaza para la gestión de la cadena de suministro de las políticas de aprendizaje por refuerzo profundo (DRL). Aunque en estudios recientes se han propuesto defensas iniciales, la generalización y escalabilidad de estos métodos son muy limitadas. Para abordar este problema, proponemos BIRD, una técnica para detectar y eliminar puertas traseras de políticas DRL previamente entrenadas en un entorno limpio sin requerir ningún conocimiento sobre la especificación del ataque y acceso a su proceso de capacitación. Al analizar la naturaleza y el comportamiento únicos de los ataques de puerta trasera, formulamos la recuperación de desencadenadores como un problema de optimización y diseñamos una nueva métrica de detección de estrategia de puerta trasera. También diseñamos un enfoque de ajuste para eliminar las puertas traseras y al mismo tiempo mantener el rendimiento del agente en un entorno limpio. Evaluamos la capacidad de BIRD para resistir tres ataques de puerta trasera en diez entornos diferentes de un solo agente o de múltiples agentes. Nuestros resultados verifican la efectividad, eficiencia y generalización de BIRD, así como su solidez ante diferentes variaciones y adaptaciones de ataques.
Los ataques de puerta trasera representan una grave amenaza para la gestión de la cadena de suministro de las políticas de aprendizaje por refuerzo profundo (DRL). A pesar de las defensas iniciales propuestas en estudios recientes, estos métodos tienen una generalización y escalabilidad muy limitadas. Para abordar este problema, proponemos BIRD, una técnica para detectar y eliminar puertas traseras de una política DRL previamente entrenada en un entorno limpio sin requerir ningún conocimiento sobre las especificaciones del ataque ni acceder a su proceso de capacitación. Al analizar las propiedades y comportamientos únicos de los ataques de puerta trasera, formulamos la restauración de desencadenadores como un problema de optimización y diseñamos una métrica novedosa para detectar políticas de puerta trasera. También diseñamos un método de ajuste para eliminar la puerta trasera, manteniendo al mismo tiempo el rendimiento del agente en un entorno limpio. Evaluamos BIRD contra tres ataques de puerta trasera en diez entornos diferentes de agente único o multiagente. Nuestros resultados verifican la efectividad, eficiencia y generalización de BIRD, así como su solidez ante diferentes variaciones y adaptaciones de ataques.
Desaprendizaje de adversarios compartidos: mitigación de puerta trasera desaprendiendo ejemplos de adversarios compartidos
https://neurips.cc/virtual/2023/poster/69874
Documento: https://arxiv.org/abs/2307.10562
Resumen:
Los ataques de puerta trasera son una grave amenaza de seguridad para los modelos de aprendizaje automático, donde un adversario puede inyectar muestras envenenadas en el conjunto de entrenamiento, lo que hace que el modelo de puerta trasera prediga muestras envenenadas con desencadenantes específicos para una clase objetivo específica mientras funciona bien en muestras benignas normales. En este artículo, exploramos la tarea de desinfectar modelos de puerta trasera utilizando pequeños conjuntos de datos limpios. Al establecer la conexión entre el riesgo de puerta trasera y el riesgo de confrontación, obtenemos un nuevo límite superior de riesgo de puerta trasera que captura principalmente el riesgo de instancias de confrontación compartidas (SAE) entre los modelos de puerta trasera y saneados. Este límite superior propone además un nuevo problema de optimización de dos capas para mitigar las puertas traseras utilizando técnicas de entrenamiento adversarias. Para resolver este problema, proponemos la Liberación Adversaria Compartida (SAU). Específicamente, SAU primero genera SAE y luego ignora los SAE generados para que sean clasificados correctamente por el modelo purificado y/o clasificados de manera diferente por los dos modelos, de modo que el efecto de puerta trasera en el modelo de puerta trasera se mitigará en el modelo purificado. Los experimentos con varios conjuntos de datos de referencia y arquitecturas de red muestran que nuestro enfoque propuesto logra un rendimiento de vanguardia en defensa de puerta trasera.
Los ataques de puerta trasera son amenazas de seguridad graves para los modelos de aprendizaje automático en los que un adversario puede inyectar muestras envenenadas en el conjunto de entrenamiento, lo que genera un modelo de puerta trasera que predice muestras envenenadas con desencadenantes particulares para clases de objetivos particulares, mientras se comporta normalmente en muestras benignas. En este artículo, exploramos la tarea de purificar un modelo con puerta trasera utilizando un pequeño conjunto de datos limpio. Al establecer la conexión entre el riesgo de puerta trasera y el riesgo de adversario, obtenemos un nuevo límite superior para el riesgo de puerta trasera, que captura principalmente el riesgo en los ejemplos adversarios compartidos (SAE) entre el modelo de puerta trasera y el modelo purificado. Este límite superior sugiere además un nuevo problema de optimización de dos niveles para mitigar la puerta trasera mediante técnicas de entrenamiento adversarias. Para solucionarlo, proponemos el desaprendizaje adversario compartido (SAU). Específicamente, SAU primero genera SAE y luego desaprende los SAE generados de modo que sean clasificados correctamente por el modelo purificado y/o clasificados de manera diferente por los dos modelos, de modo que el efecto de puerta trasera en el modelo de puerta trasera se mitigue en el modelo purificado. Los experimentos con varios conjuntos de datos de referencia y arquitecturas de red muestran que nuestro método propuesto logra un rendimiento de última generación para la defensa de puerta trasera.

VillanDiffusion: un marco de ataque de puerta trasera unificado para modelos de difusión
https://neurips.cc/virtual/2023/poster/70045
Documento: https://arxiv.org/abs/2306.06874
Resumen:
El modelo de difusión (DM) es un modelo generativo de última generación que aprende un proceso de destrucción reversible a partir de la adición y eliminación iterativa de ruido. Son la columna vertebral de muchas aplicaciones de inteligencia artificial generativa, como la generación condicional de texto a imágenes. Sin embargo, investigaciones recientes han demostrado que los DM incondicionales básicos (como DDPM y DDIM) son vulnerables a la inyección de puerta trasera, un ataque de manipulación de salida desencadenado por patrones incrustados maliciosamente en la entrada del modelo. Este artículo propone un marco de ataque de puerta trasera unificado (VillanDiffusion) para ampliar el alcance del análisis de puerta trasera de DM actual. Nuestro marco cubre DM condicional e incondicional convencional (basado en eliminación de ruido y basado en puntuación), así como varios muestreadores sin capacitación para una evaluación general. Los experimentos muestran que nuestro marco unificado facilita el análisis de puerta trasera en diferentes configuraciones de DM y proporciona nuevos conocimientos sobre los ataques de puerta trasera basados en subtítulos en DM.
Los modelos de difusión (DM) son modelos generativos de última generación que aprenden un proceso de corrupción reversible a partir de la adición y eliminación iterativa de ruido. Son la columna vertebral de muchas aplicaciones de IA generativa, como la generación condicional de texto a imagen. Sin embargo, estudios recientes han demostrado que los DM incondicionales básicos (por ejemplo, DDPM y DDIM) son vulnerables a la inyección de puerta trasera, un tipo de ataque de manipulación de salida desencadenado por un patrón incrustado maliciosamente en la entrada del modelo. Este artículo presenta un marco unificado de ataque de puerta trasera (VillanDiffusion) para ampliar el alcance actual del análisis de puerta trasera para DM. Nuestro marco cubre los principales DM condicionales e incondicionales (basados en eliminación de ruido y basados en puntajes) y varios muestreadores sin capacitación para evaluaciones holísticas.



Modelado teórico de la divergencia de datos del cliente para la defensa de puerta trasera del lenguaje natural federado
https://neurips.cc/virtual/2023/poster/70177
Resumen:
Los algoritmos de aprendizaje federado permiten entrenar modelos de redes neuronales en múltiples dispositivos periféricos distribuidos sin exponer datos privados. Sin embargo, son vulnerables a ataques de puerta trasera lanzados por clientes maliciosos. Los robustos algoritmos de agregación federados existentes detectan y excluyen heurísticamente a los clientes sospechosos en función de su distancia paramétrica, pero son ineficaces en las tareas de procesamiento del lenguaje natural (NLP). La razón principal es que, aunque los patrones de puertas traseras textuales son evidentes en el nivel del conjunto de datos subyacente, a menudo están ocultos en el nivel de parámetros porque inyectar puertas traseras en texto con un espacio de características discreto tiene menos impacto estadístico en los parámetros del modelo. Para abordar este problema, proponemos identificar clientes de puerta trasera modelando explícitamente las diferencias de datos entre clientes en sistemas federados de PNL. A través del análisis teórico, derivamos la métrica de divergencia f para estimar la divergencia de los datos del cliente con actualizaciones agregadas y hessianos. Además, guiados por la teoría de la difusión, diseñamos un método de síntesis de conjuntos de datos con un mecanismo de redistribución de Hesse para abordar el desafío clave de los conjuntos de datos inaccesibles al calcular los datos de los clientes en Hesse. Luego, proponemos un nuevo algoritmo de agregación basada en divergencia F federada (Fed-FA), que aprovecha las métricas de divergencia F para detectar y descartar clientes sospechosos. Una gran cantidad de resultados empíricos muestran que Fed-FA supera a todos los métodos paramétricos basados en distancia al resistir ataques de puerta trasera en varios escenarios de ataque de puerta trasera en lenguaje natural.
Los algoritmos de aprendizaje federado permiten entrenar modelos de redes neuronales en múltiples dispositivos perimetrales descentralizados sin exposición de datos privados. Sin embargo, son susceptibles a ataques de puerta trasera lanzados por clientes maliciosos. Los robustos algoritmos de agregación federados existentes detectan y excluyen heurísticamente clientes sospechosos en función de las distancias de sus parámetros, pero son ineficaces en las tareas de procesamiento del lenguaje natural (NLP). La razón principal es que, aunque los patrones de puertas traseras de texto son obvios en el nivel del conjunto de datos subyacente, generalmente están ocultos en el nivel de parámetros, ya que inyectar puertas traseras en textos con espacio de características discretas tiene menos impacto en las estadísticas de los parámetros del modelo. Para resolver este problema, proponemos identificar clientes de puerta trasera modelando explícitamente la divergencia de datos entre clientes en sistemas federados de PNL. A través del análisis teórico, derivamos el indicador de divergencia f para estimar la divergencia de los datos del cliente con actualizaciones de agregación y hessianos. Además, diseñamos un método de síntesis de conjuntos de datos con un mecanismo de reasignación de Hesse guiado por la teoría de la difusión para abordar el desafío clave de los conjuntos de datos inaccesibles al calcular los datos de Hesse de los clientes. Luego presentamos el novedoso algoritmo de agregación basada en divergencia F federada (Fed-FA), que aprovecha el indicador de divergencia f para detectar y descartar clientes sospechosos. Amplios resultados empíricos muestran que Fed-FA supera a todos los métodos basados en la distancia de parámetros en la defensa contra ataques de puerta trasera entre varios escenarios de ataques de puerta trasera en lenguaje natural. derivamos el indicador de divergencia f para estimar la divergencia de los datos del cliente con actualizaciones de agregación y hessianos. Además, diseñamos un método de síntesis de conjuntos de datos con un mecanismo de reasignación de Hesse guiado por la teoría de la difusión para abordar el desafío clave de los conjuntos de datos inaccesibles al calcular los datos de Hesse de los clientes. Luego presentamos el novedoso algoritmo de agregación basada en divergencia F federada (Fed-FA), que aprovecha el indicador de divergencia f para detectar y descartar clientes sospechosos. Amplios resultados empíricos muestran que Fed-FA supera a todos los métodos basados en la distancia de parámetros en la defensa contra ataques de puerta trasera entre varios escenarios de ataques de puerta trasera en lenguaje natural. derivamos el indicador de divergencia f para estimar la divergencia de los datos del cliente con actualizaciones de agregación y hessianos. Además, diseñamos un método de síntesis de conjuntos de datos con un mecanismo de reasignación de Hesse guiado por la teoría de la difusión para abordar el desafío clave de los conjuntos de datos inaccesibles al calcular los datos de Hesse de los clientes. Luego presentamos el novedoso algoritmo de agregación basada en divergencia F federada (Fed-FA), que aprovecha el indicador de divergencia f para detectar y descartar clientes sospechosos. Amplios resultados empíricos muestran que Fed-FA supera a todos los métodos basados en la distancia de parámetros en la defensa contra ataques de puerta trasera entre varios escenarios de ataques de puerta trasera en lenguaje natural. Diseñamos un método de síntesis de conjuntos de datos con un mecanismo de reasignación de Hesse guiado por la teoría de la difusión para abordar el desafío clave de los conjuntos de datos inaccesibles al calcular los datos de Hesse de los clientes. Luego presentamos el novedoso algoritmo de agregación basada en divergencia F federada (Fed-FA), que aprovecha el indicador de divergencia f para detectar y descartar clientes sospechosos. Amplios resultados empíricos muestran que Fed-FA supera a todos los métodos basados en la distancia de parámetros en la defensa contra ataques de puerta trasera entre varios escenarios de ataques de puerta trasera en lenguaje natural. Diseñamos un método de síntesis de conjuntos de datos con un mecanismo de reasignación de Hesse guiado por la teoría de la difusión para abordar el desafío clave de los conjuntos de datos inaccesibles al calcular los datos de Hesse de los clientes. Luego presentamos el novedoso algoritmo de agregación basada en divergencia F federada (Fed-FA), que aprovecha el indicador de divergencia f para detectar y descartar clientes sospechosos. Amplios resultados empíricos muestran que Fed-FA supera a todos los métodos basados en la distancia de parámetros en la defensa contra ataques de puerta trasera entre varios escenarios de ataques de puerta trasera en lenguaje natural.
BadTrack: un ataque de puerta trasera solo con veneno para el seguimiento de objetos visuales
https://neurips.cc/virtual/2023/poster/71420
Resumen:
El seguimiento de objetos visuales (VOT) es una de las tareas más fundamentales en la visión por computadora. Los rastreadores VOT de la técnica anterior extraen ejemplos positivos y negativos que se utilizan para guiar al rastreador a distinguir objetos del fondo. En este artículo, demostramos que esta característica se puede aprovechar para introducir nuevas amenazas y, por lo tanto, proponemos un ataque de puerta trasera simple pero efectivo solo con veneno. Específicamente, envenenamos una pequeña porción de los datos de entrenamiento agregando un patrón de activación predefinido a la región de fondo de cada cuadro de video, de modo que los activadores aparecen casi exclusivamente en ejemplos negativos extraídos. Hasta donde sabemos, este es el primer trabajo que revela que los rastreadores VOT están amenazados por ataques de puerta trasera que solo contienen veneno. Nuestros experimentos muestran que nuestro ataque de puerta trasera puede reducir significativamente el rendimiento de los rastreadores Transformer de flujo único y siameses de doble flujo en datos envenenados, al tiempo que logra un rendimiento comparable al de los rastreadores benignos.
El seguimiento de objetos visuales (VOT) es una de las tareas más fundamentales en la comunidad de visión por computadora. Los rastreadores VOT de última generación extraen ejemplos positivos y negativos que se utilizan para guiar al rastreador a distinguir el objeto del fondo. En este artículo, mostramos que esta característica se puede aprovechar para introducir nuevas amenazas y, por lo tanto, proponer un ataque de puerta trasera simple pero efectivo solo con veneno. Para ser específicos, envenenamos una pequeña parte de los datos de entrenamiento adjuntando un patrón de activación predefinido a la región de fondo de cada cuadro de video, de modo que el activador aparezca casi exclusivamente en los ejemplos negativos extraídos. Hasta donde sabemos, este es el primer trabajo que revela la amenaza de un ataque de puerta trasera con veneno en los rastreadores VOT.
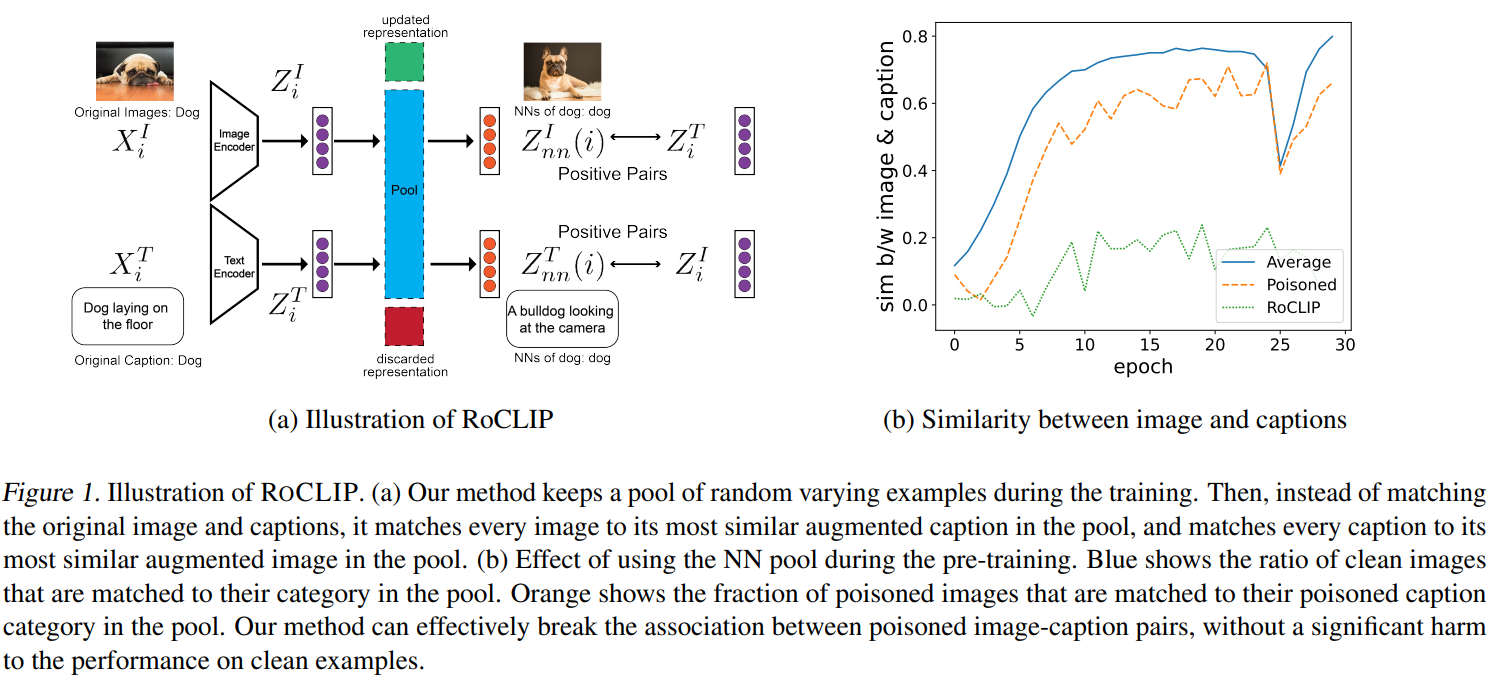
Robusto entrenamiento previo de imágenes y lenguaje contrastivo contra el envenenamiento de datos y los ataques de puerta trasera
https://neurips.cc/virtual/2023/poster/71818
Documento: https://arxiv.org/abs/2303.06854
Resumen:
El aprendizaje de representación visual-verbal contrastante logra un rendimiento de vanguardia en la clasificación de disparo cero al aprender de millones de pares de imágenes cognitivas extraídos de Internet. Sin embargo, las grandes cantidades de datos que impulsan los grandes modelos multimodales como CLIP los hacen altamente vulnerables a ataques de envenenamiento de datos dirigidos y de puerta trasera. A pesar de esta vulnerabilidad, el preentrenamiento robusto del lenguaje visual contrastivo contra estos ataques sigue sin resolverse. En este trabajo, proponemos ROCLIP, el primer método eficaz para un entrenamiento previo sólido de modelos de lenguaje visual multimodal contra el envenenamiento de datos de destino y los ataques de puerta trasera. ROCLIP rompe efectivamente la correlación entre pares de subtítulos de imágenes envenenadas al considerar un grupo relativamente grande y variable de subtítulos aleatorios y hacer coincidir cada imagen con el texto más similar del grupo (en lugar de su propio subtítulo). Nuestros extensos experimentos muestran que nuestro enfoque hace que el envenenamiento de datos dirigido y los ataques de puerta trasera de última generación sean ineficaces durante el CLIP previo al entrenamiento. En particular, RoCLIP reduce la tasa de éxito del ataque envenenado del 93,75% al 12,5% y la tasa de éxito del ataque de puerta trasera al 0%, y mejora efectivamente el rendimiento de detección lineal del modelo en un 10% mientras mantiene un rendimiento de cero emisiones similar a CLIP.
El aprendizaje contrastante de representación de visión y lenguaje ha logrado un rendimiento de vanguardia para la clasificación de disparo cero, al aprender de millones de pares de imágenes y títulos rastreados desde Internet. Sin embargo, los datos masivos que impulsan los grandes modelos multimodales como CLIP los hacen extremadamente vulnerables a ataques de envenenamiento de datos dirigidos y de puerta trasera. A pesar de esta vulnerabilidad, no se ha abordado un sólido entrenamiento previo contrastante de visión y lenguaje contra esos ataques. En este trabajo, proponemos ROCLIP, el primer método eficaz para el preentrenamiento robusto de modelos multimodales de visión y lenguaje contra el envenenamiento de datos dirigidos y los ataques de puerta trasera. ROCLIP rompe efectivamente la asociación entre pares de imágenes y subtítulos envenenados al considerar un conjunto relativamente grande y variable de subtítulos aleatorios. y hacer coincidir cada imagen con el texto más similar en el grupo, en lugar de su propio título. Nuestros extensos experimentos muestran que nuestro método hace que el envenenamiento de datos dirigido y los ataques de puerta trasera de última generación sean ineficaces durante el CLIP previo al entrenamiento. En particular, RoCLIP reduce la tasa de éxito de los ataques envenenados del 93,75 % al 12,5 % y las tasas de éxito de los ataques de puerta trasera hasta el 0 %, y mejora efectivamente el rendimiento de la sonda lineal del modelo en un 10 % y mantiene un rendimiento de disparo cero similar en comparación con CLIP.

Purificación de puerta trasera estable con ajuste de cambio de funciones
https://neurips.cc/virtual/2023/poster/72630
Documento: https://arxiv.org/abs/2310.01875v1
Código: https://github.com/AISafety-HKUST/stable_backdoor_purification
Resumen:
Se ha observado ampliamente que las redes neuronales profundas (DNN) son vulnerables a ataques de puerta trasera, mediante los cuales los atacantes pueden manipular maliciosamente el comportamiento del modelo alterando un pequeño conjunto de muestras de entrenamiento. Aunque se ha propuesto una línea de métodos de defensa para mitigar esta amenaza, requieren modificaciones complejas en el proceso de capacitación o dependen en gran medida de arquitecturas de modelos específicos, lo que dificulta su implementación en aplicaciones del mundo real. Por lo tanto, en este artículo comenzamos con el ajuste fino, una de las defensas de puerta trasera más comunes y más fáciles de implementar, mediante una evaluación exhaustiva de diferentes escenarios de ataque. Las observaciones realizadas a través de experimentos preliminares indican que, contrariamente a los resultados defensivos prometedores con tasas de envenenamiento altas, el enfoque de ajuste básico falla completamente con tasas de envenenamiento bajas. Nuestra hipótesis es que, en el caso de tasas bajas de intoxicación, el entrelazamiento entre las características de puerta trasera y limpias destruye la efectividad de las defensas basadas en ajustes y, por lo tanto, es necesario separar las características limpias y de puerta trasera para mejorar la desinfección de la puerta trasera. Proponemos un método de desinfección de puerta trasera basado en ajustes llamado Feature Shift Tuning (FST), que es simple y estable y puede resistir varios ataques de puerta trasera. Específicamente, nuestro enfoque fomenta la transferencia de características al alejar activamente el cabezal clasificador de los pesos inicialmente comprometidos, desenredando entre características limpias y características de puerta trasera. Amplios experimentos muestran que nuestro FST proporciona un rendimiento consistente y estable bajo diferentes configuraciones de ataque. Además, se puede implementar fácilmente en escenarios del mundo real, lo que reduce en gran medida los costos computacionales.
Se ha observado ampliamente que las redes neuronales profundas (DNN) son vulnerables a ataques de puerta trasera en los que los atacantes podrían manipular maliciosamente el comportamiento del modelo alterando un pequeño conjunto de muestras de entrenamiento. Aunque se propone una línea de métodos de defensa para mitigar esta amenaza, requieren modificaciones complicadas en el proceso de capacitación o dependen en gran medida de la arquitectura del modelo específico, lo que dificulta su implementación en aplicaciones del mundo real. Por lo tanto, en este documento, comenzamos con el ajuste fino, una de las defensas de puerta trasera más comunes y fáciles de implementar, a través de evaluaciones integrales contra diversos escenarios de ataque. Las observaciones realizadas a través de experimentos iniciales muestran que, en contraste con los prometedores resultados defensivos en altas tasas de envenenamiento, los métodos de ajuste estándar fallan por completo en escenarios de bajas tasas de envenenamiento. Postulamos que con la baja tasa de envenenamiento, el entrelazamiento entre las características de puerta trasera y limpias socava el efecto de las defensas basadas en ajustes y, por lo tanto, es necesario desenredar entre las características de puerta trasera y limpias para mejorar la purificación de la puerta trasera. Proponemos un método de purificación de puerta trasera basado en ajustes llamado ajuste de cambio de características (FST), que es simple y estable frente a una amplia gama de ataques de puerta trasera. Específicamente, nuestro método fomenta los cambios de características al desviar activamente el cabezal clasificador de los pesos originalmente comprometidos, desenredando entre las características limpias y de puerta trasera. Amplios experimentos demuestran que nuestro FST proporciona un rendimiento consistentemente estable bajo diferentes configuraciones de ataque y, además, también es conveniente implementarlo en escenarios del mundo real con costos computacionales significativamente reducidos.


Defensa de puerta trasera de caja negra mediante purificación de imágenes de disparo cero
https://neurips.cc/virtual/2023/poster/71421
Documento: https://arxiv.org/abs/2303.12175
Resumen:
El ataque de puerta trasera inyecta muestras envenenadas en los datos de entrenamiento, lo que provoca que la entrada envenenada se clasifique erróneamente durante la implementación del modelo. Protegerse contra este tipo de ataques es un desafío, especialmente para los modelos de caja negra del mundo real que solo permiten el acceso a consultas. En este artículo, proponemos un nuevo marco de defensa de puerta trasera para defenderse de ataques de puerta trasera mediante la purificación de imágenes de muestra cero (ZIP). Nuestro marco se puede aplicar a modelos de caja negra sin requerir información interna sobre el modelo envenenado ni ningún conocimiento previo de muestras limpias/envenenadas. Nuestro marco de defensa consta de dos pasos. Primero, aplicamos una transformación lineal a la imagen envenenada, con el objetivo de destruir el patrón de puerta trasera. Luego utilizamos un modelo de difusión previamente entrenado para recuperar la información semántica faltante eliminada mediante la transformación. En particular, diseñamos un nuevo procedimiento inverso que utiliza imágenes transformadas para guiar la generación de imágenes purificadas de alta fidelidad que funcionan en una configuración de muestra cero. Evaluamos nuestro marco ZIP en múltiples conjuntos de datos con diferentes tipos de ataques. Los resultados experimentales demuestran las ventajas de nuestro marco ZIP en comparación con las líneas base de defensa de puerta trasera de última generación. Creemos que nuestros hallazgos proporcionarán información valiosa sobre futuros métodos de defensa para modelos de caja negra.
Los ataques de puerta trasera inyectan muestras envenenadas en los datos de entrenamiento, lo que da como resultado una clasificación errónea de la entrada envenenada durante la implementación de un modelo. Defenderse contra este tipo de ataques es un desafío, especialmente para los modelos de caja negra del mundo real donde solo se permite el acceso a consultas. En este artículo, proponemos un novedoso marco de defensa de puerta trasera para defenderse de ataques de puerta trasera mediante la purificación de imágenes de disparo cero (ZIP). Nuestro marco se puede aplicar a modelos de caja negra sin requerir información interna sobre el modelo envenenado ni ningún conocimiento previo de las muestras limpias/envenenadas. Nuestro marco de defensa implica dos pasos. Primero, aplicamos una transformación lineal a la imagen envenenada con el objetivo de destruir el patrón de puerta trasera. Luego, utilizamos un modelo de difusión previamente entrenado para recuperar la información semántica faltante eliminada por la transformación. En particular, diseñamos un nuevo proceso inverso mediante el uso de la imagen transformada para guiar la generación de imágenes purificadas de alta fidelidad, que funciona en configuraciones de disparo cero. Evaluamos nuestro marco ZIP en múltiples conjuntos de datos con diferentes tipos de ataques. Los resultados experimentales demuestran la superioridad de nuestro marco ZIP en comparación con las líneas base de defensa de puerta trasera de última generación. Creemos que nuestros resultados proporcionarán información valiosa para futuros métodos de defensa para modelos de caja negra. Los resultados experimentales demuestran la superioridad de nuestro marco ZIP en comparación con las líneas base de defensa de puerta trasera de última generación. Creemos que nuestros resultados proporcionarán información valiosa para futuros métodos de defensa para modelos de caja negra. Los resultados experimentales demuestran la superioridad de nuestro marco ZIP en comparación con las líneas base de defensa de puerta trasera de última generación. Creemos que nuestros resultados proporcionarán información valiosa para futuros métodos de defensa para modelos de caja negra.



A3FL: Ataques de puerta trasera adaptativos adversarios al aprendizaje federado
https://neurips.cc/virtual/2023/poster/71628
Resumen:
El aprendizaje federado (FL) es un paradigma de aprendizaje automático distribuido que permite a varios clientes entrenar de forma colaborativa un modelo global sin compartir datos de entrenamiento locales. Debido a su naturaleza distribuida, muchos estudios han demostrado que es vulnerable a ataques de puerta trasera. Sin embargo, los estudios existentes a menudo utilizan activadores de puerta trasera fijos y predeterminados u los optimizan basándose únicamente en datos y modelos locales sin considerar la dinámica de entrenamiento global. Esto da como resultado una efectividad de ataque subóptima y menos persistente, es decir, tienen tasas de éxito de ataque más bajas cuando los presupuestos de ataque son limitados, y las tasas de éxito de ataque disminuyen rápidamente si el atacante ya no puede realizar el ataque. Para abordar estas limitaciones, proponemos A3FL, un nuevo ataque de puerta trasera que adapta adversamente el disparador de puerta trasera para que sea menos probable que sea eliminado dinámicamente mediante entrenamiento global. Nuestra intuición clave es que la diferencia entre los modelos global y local en FL hace que los desencadenantes de optimización local sean significativamente menos efectivos cuando se transfieren al modelo global. Resolvemos este problema optimizando los desencadenantes; incluso en el peor de los casos, el modelo global está entrenado para ignorar directamente los desencadenantes. Se llevan a cabo extensos experimentos en 12 defensas existentes en conjuntos de datos de referencia para evaluar de manera integral la efectividad de nuestro A3FL.
Federated Learning (FL) es un paradigma de aprendizaje automático distribuido que permite a varios clientes entrenar un modelo global de forma colaborativa sin compartir sus datos de entrenamiento locales. Debido a su naturaleza distribuida, muchos estudios han demostrado que es vulnerable a ataques de puerta trasera. Sin embargo, los estudios existentes generalmente utilizaron un disparador de puerta trasera fijo y predeterminado o lo optimizaron basándose únicamente en los datos y modelos locales sin considerar la dinámica de entrenamiento global. Esto conduce a una efectividad del ataque subóptima y menos duradera, es decir, su tasa de éxito del ataque es baja cuando el presupuesto del ataque es limitado y disminuye rápidamente si el atacante ya no puede realizar ataques. Para abordar estas limitaciones, proponemos A3FL, un nuevo ataque de puerta trasera que adapta adversamente el disparador de la puerta trasera para que sea menos probable que sea eliminado por la dinámica de entrenamiento global. Nuestra intuición clave es que la diferencia entre el modelo global y el modelo local en FL hace que el disparador optimizado localmente sea mucho menos efectivo cuando se transfiere al modelo global. Resolvemos esto optimizando el disparador para sobrevivir incluso al peor de los casos, donde el modelo global fue entrenado para desaprender directamente el disparador. Se llevan a cabo extensos experimentos con conjuntos de datos de referencia para doce defensas existentes para evaluar de manera integral la efectividad de nuestro A3FL. Resolvemos esto optimizando el disparador para sobrevivir incluso al peor de los casos, donde el modelo global fue entrenado para desaprender directamente el disparador. Se llevan a cabo extensos experimentos con conjuntos de datos de referencia para doce defensas existentes para evaluar de manera integral la efectividad de nuestro A3FL. Resolvemos esto optimizando el disparador para sobrevivir incluso al peor de los casos, donde el modelo global fue entrenado para desaprender directamente el disparador. Se llevan a cabo extensos experimentos con conjuntos de datos de referencia para doce defensas existentes para evaluar de manera integral la efectividad de nuestro A3FL.
Colocando la trampa: capturando y derrotando amenazas de puerta trasera en PLM a través de Honeypots
https://neurips.cc/virtual/2023/poster/72945
Resumen:
En el campo del procesamiento del lenguaje natural, los métodos populares incluyen el ajuste de modelos de lenguaje previamente entrenados (PLM) utilizando muestras locales. Investigaciones recientes han expuesto la susceptibilidad del PLM a ataques de puerta trasera, donde un adversario puede incorporar un comportamiento predictivo malicioso manipulando algunas muestras de entrenamiento. En este estudio, nuestro objetivo es desarrollar un procedimiento de ajuste resistente a puertas traseras que produzca modelos sin puertas traseras independientemente de si el conjunto de datos de ajuste contiene muestras envenenadas o no. Con este fin, proponemos e integramos un módulo honeypot en el PLM original, que está diseñado específicamente para absorber información de puerta trasera. Nuestro diseño se basa en la observación de que las representaciones de capas inferiores en PLM tienen suficientes características de puerta trasera y al mismo tiempo contienen información mínima sobre la tarea original. Por lo tanto, podemos penalizar la información obtenida por el módulo honeypot para suprimir la creación de puertas traseras durante el ajuste de la red madre. Experimentos exhaustivos con conjuntos de datos de referencia confirman la eficacia y solidez de nuestra estrategia de defensa. En particular, estos resultados muestran tasas de éxito de ataques significativamente reducidas en comparación con los métodos de última generación anteriores, que oscilan entre el 10% y el 40%.
En el campo del procesamiento del lenguaje natural, el enfoque predominante implica ajustar los modelos de lenguaje previamente entrenados (PLM) utilizando muestras locales. Investigaciones recientes han expuesto la susceptibilidad de los PLM a ataques de puerta trasera, en los que los adversarios pueden incorporar comportamientos de predicción maliciosos manipulando algunas muestras de entrenamiento. En este estudio, nuestro objetivo es desarrollar un procedimiento de ajuste resistente a la puerta trasera que produzca un modelo sin puerta trasera, sin importar si el conjunto de datos de ajuste contiene muestras envenenadas. Para ello, proponemos e integramos un \emph{módulo Honeypot} en el PLM original, diseñado específicamente para absorber información de puerta trasera exclusivamente. Nuestro diseño está motivado por la observación de que las representaciones de capa inferior en PLM tienen suficientes características de puerta trasera y al mismo tiempo contienen información mínima sobre las tareas originales. Como consecuencia, Podemos imponer sanciones a la información adquirida por el módulo Honeypot para inhibir la creación de puertas traseras durante el proceso de ajuste de la red madre. Experimentos exhaustivos realizados con conjuntos de datos de referencia corroboran la eficacia y solidez de nuestra estrategia defensiva. En particular, estos resultados indican una reducción sustancial en la tasa de éxito de los ataques, que oscila entre el 10\% y el 40\% en comparación con métodos de última generación anteriores.
IBA: Hacia ataques de puerta trasera irreversibles en el aprendizaje federado
https://neurips.cc/virtual/2023/poster/71079
Documento: https://arxiv.org/abs/2303.02213
Resumen:
El aprendizaje federado (FL) es un método de aprendizaje distribuido que permite entrenar modelos de aprendizaje automático con datos descentralizados sin comprometer los datos personales y potencialmente confidenciales de los dispositivos finales. Sin embargo, la naturaleza distribuida y los datos no investigados introducen intuitivamente nuevas vulnerabilidades de seguridad, incluidos los ataques de puerta trasera. En este caso, el adversario implanta una función de puerta trasera en el modelo global durante el entrenamiento, que puede activarse para provocar el mal comportamiento deseado en cualquier entrada con un patrón adversario específico. A pesar de su notable éxito en desencadenar y distorsionar el comportamiento del modelo, los ataques de puerta trasera anteriores en FL a menudo tenían suposiciones poco realistas, imperceptibilidad limitada y persistencia. Específicamente, el adversario necesita controlar una porción suficientemente grande de clientes o comprender la distribución de datos de otros clientes honestos. En muchos casos, los disparadores insertados suelen ser visualmente obvios y el efecto de puerta trasera se diluye rápidamente si se retira al oponente del proceso de entrenamiento. Para abordar estas limitaciones, proponemos un nuevo marco de ataque de puerta trasera en FL que aprende conjuntamente los activadores de sigilo visual óptimos y luego incorpora gradualmente la puerta trasera en el modelo global. Este enfoque permite a los adversarios realizar ataques de puerta trasera que pueden evadir la inspección humana y mecánica. Además, mejoramos la eficiencia y persistencia del ataque propuesto envenenando selectivamente los parámetros del modelo que tienen menos probabilidades de ser actualizados por el proceso de aprendizaje de la tarea principal y limitando las actualizaciones del modelo envenenado a la vecindad del modelo global. Finalmente, evaluamos el marco de ataque propuesto en varios conjuntos de datos de referencia, incluidos MNIST, CIFAR10 y Tiny ImageNet, y logramos una alta tasa de éxito al mismo tiempo que evitamos las defensas de puerta trasera existentes, en comparación con otros ataques de puerta trasera. Se logra un efecto de puerta trasera más duradero. En general, nuestro marco proporciona un método más eficaz, encubierto y persistente para ataques de puerta trasera en FL.
El aprendizaje federado (FL) es un enfoque de aprendizaje distribuido que permite entrenar modelos de aprendizaje automático con datos descentralizados sin comprometer los datos personales y potencialmente confidenciales de los dispositivos finales. Sin embargo, la naturaleza distribuida y los datos no investigados introducen intuitivamente nuevas vulnerabilidades de seguridad, incluidos los ataques de puerta trasera. En este escenario, un adversario implanta una funcionalidad de puerta trasera en el modelo global durante el entrenamiento, que puede activarse para provocar los malos comportamientos deseados para cualquier entrada con un patrón adversario específico. A pesar de haber tenido un éxito notable en desencadenar y distorsionar el comportamiento del modelo, ataques de puerta trasera anteriores en FL a menudo contienen suposiciones poco prácticas, imperceptibilidad limitada y durabilidad. Específicamente, el adversario necesita controlar una fracción suficientemente grande de clientes o conocer la distribución de datos de otros clientes honestos. En muchos casos, el disparador insertado suele ser visualmente evidente y el efecto de puerta trasera se diluye rápidamente si se retira al adversario del proceso de entrenamiento. Para abordar estas limitaciones, proponemos un nuevo marco de ataque de puerta trasera en FL que aprende conjuntamente el disparador óptimo y visualmente sigiloso y luego implanta gradualmente la puerta trasera en un modelo global. Este enfoque permite al adversario ejecutar un ataque de puerta trasera que puede evadir las inspecciones tanto humanas como mecánicas. Además, Mejoramos la eficiencia y durabilidad del ataque propuesto envenenando selectivamente los parámetros del modelo que tienen menos probabilidades de actualizarse mediante el proceso de aprendizaje de la tarea principal y restringiendo la actualización del modelo envenenado a la vecindad del modelo global. Finalmente, evaluamos el marco de ataque propuesto en varios conjuntos de datos de referencia, incluidos MNIST, CIFAR10 y Tiny-ImageNet, y logró altas tasas de éxito al mismo tiempo que evitó las defensas de puerta trasera existentes y logró un efecto de puerta trasera más duradero en comparación con otros ataques de puerta trasera. En general, nuestro marco ofrece un enfoque más eficaz, sigiloso y duradero para los ataques de puerta trasera en FL. y logró altas tasas de éxito al mismo tiempo que evitó las defensas de puerta trasera existentes y logró un efecto de puerta trasera más duradero en comparación con otros ataques de puerta trasera. En general, nuestro marco ofrece un enfoque más eficaz, sigiloso y duradero para los ataques de puerta trasera en Florida. y logró altas tasas de éxito al mismo tiempo que evitó las defensas de puerta trasera existentes y logró un efecto de puerta trasera más duradero en comparación con otros ataques de puerta trasera. En general, nuestro marco ofrece un enfoque más eficaz, sigiloso y duradero para los ataques de puerta trasera en Florida.




CBD: un detector de puerta trasera certificado basado en la probabilidad dominante local
https://neurips.cc/virtual/2023/poster/72180
Resumen:
Los ataques de puerta trasera son una amenaza común para las redes neuronales profundas y, durante las pruebas, el modelo de puerta trasera clasificará erróneamente las muestras integradas con activadores de puerta trasera en clases de objetivos adversarios. En este artículo, presentamos el primer detector de puerta trasera (CBD) certificado basado en un nuevo esquema de predicción conforme ajustable que utiliza una estadística llamada "probabilidad de dominancia local". Para examinar cualquier clasificador, no solo proporcionamos inferencias de detección, sino que también derivamos (para el mismo dominio de clasificación) las condiciones bajo las cuales se garantiza que un ataque sea detectable, así como un límite superior probabilístico en la tasa de falsos positivos. Nuestros resultados teóricos muestran que los flip-flops son más resistentes al ruido en el momento de la prueba y que es más probable que los ataques con amplitudes de perturbación más pequeñas se detecten con seguridad. Además, llevamos a cabo experimentos extensos en cuatro conjuntos de datos de referencia con diferentes tipos de puertas traseras, como BadNet, CB y Blend. Empíricamente, la precisión de la detección de CBD es comparable o incluso superior a la de los detectores de última generación que no pueden proporcionar certificación de detección. Vale la pena señalar que para los ataques de puerta trasera con desencadenadores de perturbaciones aleatorias delimitados por $\ell_2\leq0.75$, la tasa de éxito del ataque supera el 90% y CBD logra mejores resultados en cuatro conjuntos de datos de referencia: GTSRB, SVHN, CIFAR-10 y Las tasas de verdaderos positivos de autenticación en TinyImageNet son del 98%, 84%, 98% y 40% respectivamente, y la tasa de falsos positivos es baja.
El ataque de puerta trasera es una amenaza común para las redes neuronales profundas, donde las muestras integradas con un disparador de puerta trasera serán clasificadas erróneamente en una clase objetivo adversaria por un modelo con puerta trasera durante las pruebas. En este documento, presentamos el primer detector de puerta trasera certificado (CBD), que es basado en un esquema de predicción conforme novedoso y ajustable que utiliza una estadística propuesta denominada *probabilidad dominante local*. Para inspeccionar cualquier clasificador, no solo proporcionamos una inferencia de detección, sino que también derivamos (para el mismo dominio de clasificación) la condición bajo la cual el Se garantiza que los ataques serán detectables, así como un límite superior probabilístico para la tasa de falsos positivos. Nuestros resultados teóricos muestran que los ataques con desencadenantes más resistentes a los ruidos en el momento de la prueba y de menor magnitud de perturbación tienen más probabilidades de ser detectados con garantías. ,Llevamos a cabo experimentos extensos en cuatro conjuntos de datos de referencia para varios tipos de puertas traseras, como BadNet, CB y Blend. Empíricamente, CBD logra una precisión de detección comparable o incluso mayor que los detectores de última generación, que no pueden proporcionar certificación de detección. En particular, para ataques de puerta trasera con desencadenadores de perturbaciones aleatorias delimitados por $\ell_2\leq0.75$ que logran una tasa de éxito de ataque superior al 90\%, CBD alcanza tasas de verdadero positivo certificado del 98\%, 84\%, 98\% y 40\%. en los cuatro conjuntos de datos de referencia GTSRB, SVHN, CIFAR-10 y TinyImageNet, respectivamente, con bajas tasas de falsos positivos.En particular, para los ataques de puerta trasera con activadores de perturbaciones aleatorias delimitados por $\ell_2\leq0.75$ que logran una tasa de éxito de ataque superior al 90\%, CBD logra un 98\%, 84\%, 98\% y 40\% certificado como verdadero. tasas positivas en los cuatro conjuntos de datos de referencia GTSRB, SVHN, CIFAR-10 y TinyImageNet, respectivamente, con bajas tasas de falsos positivos.En particular, para los ataques de puerta trasera con activadores de perturbaciones aleatorias delimitados por $\ell_2\leq0.75$ que logran una tasa de éxito de ataque superior al 90\%, CBD logra un 98\%, 84\%, 98\% y 40\% certificado como verdadero. tasas positivas en los cuatro conjuntos de datos de referencia GTSRB, SVHN, CIFAR-10 y TinyImageNet, respectivamente, con bajas tasas de falsos positivos.
Defensa de modelos de lenguaje previamente entrenados como aprendices con pocas posibilidades contra ataques de puerta trasera
https://neurips.cc/virtual/2023/poster/72193
Documento: https://arxiv.org/abs/2309.13256
Código: https://github.com/zhaohan-xi/PLM-prompt-defense
Resumen:
Los modelos de lenguaje previamente entrenados (PLM) muestran un rendimiento notable como aprendices de minorías. Sin embargo, en este caso, sus riesgos de seguridad siguen en gran medida inexplorados. En este trabajo, llevamos a cabo un estudio piloto que muestra que PLM, como aprendiz de pocos disparos, es altamente vulnerable a ataques de puerta trasera y que las capacidades de defensa existentes son insuficientes debido a los desafíos únicos de los escenarios de pocos disparos. Para abordar estos desafíos, defendemos el MDP, un nuevo método de defensa ligero, conectable y eficaz para los PLM que son estudiantes de tiradores pertenecientes a minorías. Específicamente, MDP explota la brecha entre las sensibilidades de enmascaramiento de muestras limpias y envenenadas: refiriéndose a un número limitado de datos de disparo como anclajes de distribución, compara la representación de una muestra dada bajo diferentes enmascaramientos e identifica la muestra envenenada como si tuviera muestras que cambian significativamente. Nuestro análisis muestra que MDP crea un dilema interesante para que los atacantes elijan entre efectividad del ataque y evasión de detección. La evaluación empírica utilizando conjuntos de datos de referencia y ataques representativos valida la eficacia de MDP.
Los modelos de lenguaje previamente entrenados (PLM) han demostrado un rendimiento notable como aprendices de pocas oportunidades. Sin embargo, sus riesgos de seguridad en tales entornos están en gran medida inexplorados. En este trabajo, llevamos a cabo un estudio piloto que muestra que los PLM, como aprendices de pocas oportunidades, son altamente vulnerables a ataques de puerta trasera, mientras que las defensas existentes son inadecuadas debido a los desafíos únicos de los escenarios de pocas oportunidades. Para abordar estos desafíos, defendemos el MDP, una novedosa defensa ligera, conectable y eficaz para los PLM, que son aprendices de pocas oportunidades. Específicamente, MDP aprovecha la brecha entre la sensibilidad al enmascaramiento de muestras limpias y envenenadas: con referencia a los datos limitados de unos pocos disparos como anclas de distribución, compara las representaciones de muestras dadas bajo enmascaramiento variable e identifica muestras envenenadas como aquellas con variaciones significativas. Mostramos analíticamente que MDP crea un dilema interesante para que el atacante elija entre efectividad del ataque y evasión de detección. La evaluación empírica utilizando conjuntos de datos de referencia y ataques representativos valida la eficacia de MDP.

Bloqueo: defensa de puerta trasera para el aprendizaje federado con entrenamiento subespacial aislado
https://neurips.cc/virtual/2023/poster/71476
Código: https://github.com/LockdownAuthor/Lockdown
Resumen:
El aprendizaje federado (FL) es vulnerable a ataques de puerta trasera debido a su naturaleza informática distribuida. Las soluciones de defensa existentes a menudo requieren una computación exhaustiva durante la fase de entrenamiento o prueba, lo que limita su utilidad en escenarios con recursos limitados. En un entorno de puerta trasera centralizada, se propone un método de defensa más práctico, es decir, una defensa basada en la poda de redes neuronales. Sin embargo, nuestro estudio empírico muestra que las soluciones tradicionales basadas en poda sufren el efecto \textit{acoplamiento tóxico} en FL, lo que degrada significativamente el rendimiento de la defensa. Este artículo propone un método de entrenamiento subespacial aislado Lockdown para aliviar el efecto de acoplamiento tóxico. El bloqueo sigue tres procedimientos clave. Primero, modifica el protocolo de entrenamiento aislando subespacios de entrenamiento para diferentes clientes. En segundo lugar, utiliza la aleatoriedad para inicializar subespacios aislados y realiza poda y recuperación de subespacios para aislar subespacios entre clientes maliciosos y benignos. En tercer lugar, introduce un consenso de quórum para reparar el modelo global eliminando parámetros maliciosos/falsos. Los resultados empíricos muestran que, en comparación con los métodos representativos existentes contra ataques de puerta trasera, Lockdown logra un rendimiento de defensa \textit{superior} y \textit{consistente}. Otra característica de valor agregado de Lockdown es la eficiencia de la comunicación y la reducción de la complejidad del modelo, las cuales son cruciales para escenarios de FL con recursos limitados.
El aprendizaje federado (FL) es vulnerable a ataques de puerta trasera debido a su naturaleza informática distribuida. Las soluciones de defensa existentes generalmente requieren una mayor cantidad de cálculos en la fase de entrenamiento o de prueba, lo que limita su viabilidad en escenarios con recursos limitados. Se ha propuesto una defensa más práctica, basada en la poda de redes neuronales (NN), en un entorno de puerta trasera centralizada. Sin embargo, nuestro estudio empírico muestra que la solución tradicional basada en poda sufre el efecto \textit{acoplamiento de veneno} en FL, lo que degrada significativamente el rendimiento de la defensa. Este artículo presenta Lockdown, un método de entrenamiento subespacial aislado para mitigar el efecto de acoplamiento de veneno. El bloqueo sigue tres procedimientos clave. Primero, modifica el protocolo de entrenamiento aislando los subespacios de entrenamiento para diferentes clientes. Segundo, utiliza la aleatoriedad para inicializar subespacios aislados y realiza poda y recuperación de subespacios para segregar los subespacios entre clientes maliciosos y benignos. En tercer lugar, introduce un consenso de quórum para curar el modelo global mediante la eliminación de parámetros maliciosos/ficticios. Los resultados empíricos muestran que Lockdown logra un rendimiento de defensa \textit{superior} y \textit{consistente} en comparación con los enfoques representativos existentes contra ataques de puerta trasera. Otra propiedad de valor agregado de Lockdown es la eficiencia de la comunicación y la reducción de la complejidad del modelo, que son críticas para escenarios de FL con recursos limitados. introduce un consenso de quórum para corregir el modelo global mediante la eliminación de parámetros maliciosos/ficticios. Los resultados empíricos muestran que Lockdown logra un rendimiento de defensa \textit{superior} y \textit{consistente} en comparación con los enfoques representativos existentes contra ataques de puerta trasera. Otra propiedad de valor agregado de Lockdown es la eficiencia de la comunicación y la reducción de la complejidad del modelo, que son críticas para escenarios de FL con recursos limitados. introduce un consenso de quórum para corregir el modelo global mediante la eliminación de parámetros maliciosos/ficticios. Los resultados empíricos muestran que Lockdown logra un rendimiento de defensa \textit{superior} y \textit{consistente} en comparación con los enfoques representativos existentes contra ataques de puerta trasera. Otra propiedad de valor agregado de Lockdown es la eficiencia de la comunicación y la reducción de la complejidad del modelo, que son críticas para escenarios de FL con recursos limitados.
FedGame: una defensa de la teoría de juegos contra ataques de puerta trasera en el aprendizaje federado
https://neurips.cc/virtual/2023/poster/70499
Resumen:
Federated Learning (FL) implementa un modo de capacitación distribuida donde varios clientes pueden entrenar conjuntamente un modelo global sin compartir sus datos locales. Sin embargo, investigaciones recientes muestran que el aprendizaje federado proporciona una superficie adicional para ataques de puerta trasera. Por ejemplo, un atacante puede comprometer un subconjunto de clientes, corrompiendo así el modelo global y prediciendo erróneamente los activadores de puertas traseras como entradas para los objetivos adversarios. Las defensas de aprendizaje federado existentes contra ataques de puerta trasera generalmente se basan en modelos de atacantes $\textit{static}$ para detectar y excluir información corrupta en clientes comprometidos. Sin embargo, tales defensas son insuficientes contra los atacantes $\textit{dynamic}$ que ajustan estratégicamente sus tácticas de ataque. Para cerrar esta brecha en la defensa, modelamos la interacción estratégica de una o varias etapas entre defensores y atacantes dinámicos en FL como un juego maximin. Basado en el modelo de análisis, diseñamos un mecanismo de defensa interactivo FedGame. También mostramos que, bajo supuestos leves, el modelo FL global entrenado con FedGame bajo ataques de puerta trasera está cerca del modelo FL entrenado sin ataques. Empíricamente, llevamos a cabo una evaluación exhaustiva de conjuntos de datos de referencia y comparamos FedGame con múltiples líneas de base de última generación. Nuestros resultados experimentales muestran que FedGame puede defenderse eficazmente contra atacantes estratégicos y lograr una solidez significativamente mayor que las líneas de base. Por ejemplo, en comparación con seis líneas de base de defensa de última generación bajo ataques de escala, la tasa de éxito del ataque de FedGame en CIFAR10 se reduce en un 82%.
El aprendizaje federado (FL) permite un paradigma de capacitación distribuida, donde varios clientes pueden entrenar conjuntamente un modelo global sin necesidad de compartir sus datos locales. Sin embargo, estudios recientes han demostrado que el aprendizaje federado proporciona una superficie adicional para ataques de puerta trasera. Por ejemplo, un atacante puede comprometer un subconjunto de clientes y, por lo tanto, corromper el modelo global para predecir erróneamente una entrada con un disparador de puerta trasera como objetivo del adversario. Las defensas existentes para el aprendizaje federado contra ataques de puerta trasera generalmente detectan y excluyen la información corrupta de los clientes comprometidos basándose en un modelo de atacante $\textit{static}$. Sin embargo, estas defensas no son adecuadas contra atacantes $\textit{dynamic}$ que adaptan estratégicamente sus estrategias de ataque. Para cerrar esta brecha en defensa, Modelamos interacciones estratégicas de una o varias etapas entre el defensor en FL y los atacantes dinámicos como un juego minimax. Con base en el análisis de nuestro modelo, diseñamos un mecanismo de defensa interactivo FedGame. También demostramos que, bajo supuestos leves, el modelo FL global entrenado con FedGame bajo ataques de puerta trasera es cercano al entrenado sin ataques. Empíricamente, realizamos evaluaciones exhaustivas de conjuntos de datos de referencia y comparamos FedGame con múltiples líneas de base de última generación. Nuestros resultados experimentales muestran que FedGame puede defenderse eficazmente contra atacantes estratégicos y logra una solidez significativamente mayor que las líneas de base. Por ejemplo, FedGame reduce la tasa de éxito de los ataques en un 82\% en CIFAR10 en comparación con seis líneas base de defensa de última generación bajo el ataque Scaling. Con base en el análisis de nuestro modelo, diseñamos un mecanismo de defensa interactivo FedGame. También demostramos que, bajo supuestos leves, el modelo FL global entrenado con FedGame bajo ataques de puerta trasera es cercano al entrenado sin ataques. Empíricamente, realizamos evaluaciones exhaustivas de conjuntos de datos de referencia y comparamos FedGame con múltiples líneas de base de última generación. Nuestros resultados experimentales muestran que FedGame puede defenderse eficazmente contra atacantes estratégicos y logra una solidez significativamente mayor que las líneas de base. Por ejemplo, FedGame reduce la tasa de éxito de los ataques en un 82\% en CIFAR10 en comparación con seis líneas base de defensa de última generación bajo el ataque Scaling. Con base en el análisis de nuestro modelo, diseñamos un mecanismo de defensa interactivo FedGame. También demostramos que, bajo supuestos leves, el modelo FL global entrenado con FedGame bajo ataques de puerta trasera es cercano al entrenado sin ataques. Empíricamente, realizamos evaluaciones exhaustivas de conjuntos de datos de referencia y comparamos FedGame con múltiples líneas de base de última generación. Nuestros resultados experimentales muestran que FedGame puede defenderse eficazmente contra atacantes estratégicos y logra una solidez significativamente mayor que las líneas de base. Por ejemplo, FedGame reduce la tasa de éxito de los ataques en un 82\% en CIFAR10 en comparación con seis líneas base de defensa de última generación bajo el ataque Scaling. El modelo FL global entrenado con FedGame bajo ataques de puerta trasera es similar al entrenado sin ataques. Empíricamente, realizamos evaluaciones exhaustivas de conjuntos de datos de referencia y comparamos FedGame con múltiples líneas de base de última generación. Nuestros resultados experimentales muestran que FedGame puede defenderse eficazmente contra atacantes estratégicos y logra una solidez significativamente mayor que las líneas de base. Por ejemplo, FedGame reduce la tasa de éxito de los ataques en un 82\% en CIFAR10 en comparación con seis líneas base de defensa de última generación bajo el ataque Scaling. El modelo FL global entrenado con FedGame bajo ataques de puerta trasera es similar al entrenado sin ataques. Empíricamente, realizamos evaluaciones exhaustivas de conjuntos de datos de referencia y comparamos FedGame con múltiples líneas de base de última generación. Nuestros resultados experimentales muestran que FedGame puede defenderse eficazmente contra atacantes estratégicos y logra una solidez significativamente mayor que las líneas de base. Por ejemplo, FedGame reduce la tasa de éxito de los ataques en un 82\% en CIFAR10 en comparación con seis líneas base de defensa de última generación bajo el ataque Scaling.
Polarizador neuronal: una defensa de puerta trasera ligera y eficaz mediante funciones purificadoras y envenenadas
https://neurips.cc/virtual/2023/poster/71467
Documento: https://arxiv.org/abs/2306.16697
Resumen:
Investigaciones recientes han demostrado la susceptibilidad de las redes neuronales profundas a ataques de puerta trasera. Dado un modelo de puerta trasera, aunque coexisten información desencadenante e información benigna, sus predicciones para muestras envenenadas con desencadenantes estarán dominadas por la información desencadenante. Inspirado en el mecanismo de los polarizadores de luz que pueden pasar ondas de luz con una polarización específica mientras filtran ondas de luz con otras polarizaciones. Proponemos un nuevo método de defensa de puerta trasera mediante la inserción de un polarizador neuronal que se puede aprender como capa intermedia en el modelo de puerta trasera para purificar muestras envenenadas filtrando la información desencadenante mientras se mantiene información benigna. El polarizador neuronal se instancia como una capa de transformación lineal liviana que se aprende resolviendo un problema de optimización de dos capas cuidadosamente diseñado basado en un conjunto de datos limpios limitado. En comparación con otros métodos de defensa basados en ajustes que a menudo ajustan todos los parámetros del modelo de puerta trasera, el método propuesto solo necesita aprender una capa adicional, por lo que es más eficiente y requiere datos menos limpios. Amplios experimentos demuestran la eficacia y eficiencia de nuestro enfoque para eliminar puertas traseras en diversas arquitecturas de redes neuronales y conjuntos de datos, especialmente cuando los datos limpios son muy limitados.
Estudios recientes han demostrado la susceptibilidad de las redes neuronales profundas a ataques de puerta trasera. Dado un modelo con puerta trasera, su predicción de una muestra envenenada con desencadenante estará dominada por la información desencadenante, aunque la información desencadenante y la información benigna coexisten. Inspirándonos en el mecanismo del polarizador óptico según el cual un polarizador podría transmitir ondas de luz con polarizaciones particulares mientras filtra ondas de luz con otras polarizaciones, proponemos un nuevo método de defensa de puerta trasera insertando un polarizador neuronal que se puede aprender en el modelo de puerta trasera como capa intermedia, para para purificar la muestra envenenada mediante el filtrado de la información de activación mientras se mantiene la información benigna. El polarizador neuronal se instancia como una capa de transformación lineal ligera, que se aprende resolviendo un problema de optimización de dos niveles bien diseñado, basado en un conjunto de datos limpio limitado. En comparación con otros métodos de defensa basados en ajustes que a menudo ajustan todos los parámetros del modelo con puerta trasera, el método propuesto solo necesita aprender una capa adicional, por lo que es más eficiente y requiere datos menos limpios. Amplios experimentos demuestran la efectividad y eficiencia de nuestro método para eliminar puertas traseras en varias arquitecturas de redes neuronales y conjuntos de datos, especialmente en el caso de datos limpios muy limitados.

Un marco unificado para defensas de puerta trasera en la etapa de inferencia
https://neurips.cc/virtual/2023/poster/72827
Un marco unificado para defensas de puerta trasera en etapa de inferencia (jding.org)
Resumen:
Los ataques de puerta trasera implican insertar muestras envenenadas durante el entrenamiento, lo que hace que el modelo contenga una puerta trasera oculta que puede desencadenar comportamientos específicos sin afectar el rendimiento de las muestras normales. Estos ataques son difíciles de detectar porque el modelo de puerta trasera parece normal hasta que se activa con el disparador de la puerta trasera, lo que los hace particularmente sigilosos. En este estudio, diseñamos un marco de detección de etapa de inferencia unificada para defendernos contra ataques de puerta trasera. Primero formulamos rigurosamente el problema de detección de puerta trasera en la etapa de inferencia, incluidos varios métodos existentes, y analizamos algunos desafíos y limitaciones. Luego proponemos un marco con garantías demostrables sobre la tasa de falsos positivos o la probabilidad de clasificar erróneamente una muestra limpia. Además, derivamos las reglas de detección más poderosas para maximizar el poder de detección, es decir, la tasa de identificación precisa de muestras de puerta trasera dada la tasa de falsos positivos en escenarios de aprendizaje clásicos. Basado en reglas teóricas de detección óptima, proponemos un enfoque práctico y eficiente para aplicaciones del mundo real de representaciones latentes basadas en redes profundas de puerta trasera. Evaluamos exhaustivamente nuestro método en 12 ataques de puerta trasera diferentes utilizando conjuntos de datos de referencia de visión por computadora (CV) y procesamiento de lenguaje natural (NLP). Los resultados experimentales son consistentes con nuestros resultados teóricos. Superamos significativamente los métodos de última generación; por ejemplo, AUROC evalúa una mejora del 300 % en las capacidades de detección en comparación con las defensas de última generación contra ataques de puerta trasera adaptativos avanzados.
Los ataques de puerta trasera implican la inserción de muestras envenenadas durante el entrenamiento, lo que da como resultado un modelo que contiene una puerta trasera oculta que puede desencadenar comportamientos específicos sin afectar el rendimiento de las muestras normales. Estos ataques son difíciles de detectar, ya que el modelo con puerta trasera parece normal hasta que se activa con el disparador de la puerta trasera, lo que los vuelve particularmente sigilosos. En este estudio, diseñamos un marco unificado de detección de etapa de inferencia para defendernos contra ataques de puerta trasera. Primero formulamos rigurosamente el problema de detección de puerta trasera en la etapa de inferencia, que abarca varios métodos existentes, y analizamos varios desafíos y limitaciones. Luego proponemos un marco con garantías demostrables sobre la tasa de falsos positivos o la probabilidad de clasificar erróneamente una muestra limpia. Además, derivamos la regla de detección más poderosa para maximizar el poder de detección, es decir, la tasa de identificación precisa de una muestra de puerta trasera, dada una tasa de falsos positivos en escenarios de aprendizaje clásicos. Con base en la regla de detección teóricamente óptima, sugerimos un enfoque práctico y efectivo para aplicaciones del mundo real basado en las representaciones latentes de redes profundas con puerta trasera. Evaluamos exhaustivamente nuestro método en 12 ataques de puerta trasera diferentes utilizando conjuntos de datos de referencia de visión por computadora (CV) y procesamiento de lenguaje natural (NLP). Los hallazgos experimentales se alinean con nuestros resultados teóricos. Superamos significativamente los métodos de última generación, por ejemplo, hasta un 300\% de mejora en el poder de detección según lo evaluado por AUCROC, sobre la defensa de última generación contra ataques avanzados de puerta trasera adaptativa. Con base en la regla de detección teóricamente óptima, sugerimos un enfoque práctico y efectivo para aplicaciones del mundo real basado en las representaciones latentes de redes profundas con puerta trasera. Evaluamos exhaustivamente nuestro método en 12 ataques de puerta trasera diferentes utilizando conjuntos de datos de referencia de visión por computadora (CV) y procesamiento de lenguaje natural (NLP). Los hallazgos experimentales se alinean con nuestros resultados teóricos. Superamos significativamente los métodos de última generación, por ejemplo, hasta un 300\% de mejora en el poder de detección según lo evaluado por AUCROC, sobre la defensa de última generación contra ataques avanzados de puerta trasera adaptativa. Con base en la regla de detección teóricamente óptima, sugerimos un enfoque práctico y efectivo para aplicaciones del mundo real basado en las representaciones latentes de redes profundas con puerta trasera. Evaluamos exhaustivamente nuestro método en 12 ataques de puerta trasera diferentes utilizando conjuntos de datos de referencia de visión por computadora (CV) y procesamiento de lenguaje natural (NLP). Los hallazgos experimentales se alinean con nuestros resultados teóricos. Superamos significativamente los métodos de última generación, por ejemplo, hasta un 300\% de mejora en el poder de detección según lo evaluado por AUCROC, sobre la defensa de última generación contra ataques avanzados de puerta trasera adaptativa. Evaluamos exhaustivamente nuestro método en 12 ataques de puerta trasera diferentes utilizando conjuntos de datos de referencia de visión por computadora (CV) y procesamiento de lenguaje natural (NLP). Los hallazgos experimentales se alinean con nuestros resultados teóricos. Superamos significativamente los métodos de última generación, por ejemplo, hasta un 300\% de mejora en el poder de detección según lo evaluado por AUCROC, sobre la defensa de última generación contra ataques avanzados de puerta trasera adaptativa. Evaluamos exhaustivamente nuestro método en 12 ataques de puerta trasera diferentes utilizando conjuntos de datos de referencia de visión por computadora (CV) y procesamiento de lenguaje natural (NLP). Los hallazgos experimentales se alinean con nuestros resultados teóricos. Superamos significativamente los métodos de última generación, por ejemplo, hasta un 300\% de mejora en el poder de detección evaluado por AUCROC, sobre la defensa de última generación contra ataques avanzados de puerta trasera adaptativa.