Directorio de artículos
- Ataque furtivo de puerta trasera con disparadores específicos de muestra
- Información del papel
- contribución en papel
- traducción de comprensión
- Análisis de papel
-
- Artículos de referencia importantes
- Independientes e idénticamente distribuidos
- Hable sobre varios métodos de defensa de redes neuronales: Fine-Pruning, Neural Cleanse, STRIP, SentiNet, DF-TND, Spectral Signatures
- Explicar Neural Cleanse de nuevo
- Acerca de la tira
- algún código real
- Redes malas
- Aprendizaje federado y ataques de puerta trasera
-
- el código
- Puntos de conocimiento complementarios
-
- transforma.Compose
- np.elección.aleatoria
- copia profunda y copia superficial
- muestra aleatoria
- aleatorio.shuffle
- global_param.data y global_param.grad
- Cargue un modelo previamente guardado y continúe entrenando
- Acerca del número de veces para recorrer los parámetros del modelo global y el modelo local
Ataque furtivo de puerta trasera con disparadores específicos de muestra
Información del papel
| título del trabajo | Ataque de puerta trasera invisible con activadores específicos de muestra |
|---|---|
| autor | Yuezun Li, Yiming Li, Baoyuan Wu, Longkang Li, Ran He y Siwei Lyu |
| Instituciones de investigación | Ocean University of China, The Chinese University of Hong Kong, Shenzhen Research Institute of Big Data, Tsinghua University, Tsinghua University, University at Buffalo |
| Reunión | ICCV |
| año de publicacion | 2021 |
| Enlace de papel | https://openaccess.thecvf.com/content/ICCV2021/papers/Li_Invisible_Backdoor_Attack_With_Sample-Specific_Triggers_ICCV_2021_paper.pdf |
| código fuente abierto | https://github.com/yuezunli/ISSBA |
contribución en papel
- Se analizan las condiciones exitosas de la defensa de ataque de puerta trasera actual: el ataque de puerta trasera existente es independiente de la muestra (es decir, los desencadenantes de diferentes muestras de envenenamiento son los mismos)
- Se propone un método para personalizar activadores de puerta trasera basados en muestras: una ligera perturbación de las muestras de entrenamiento basadas en la idea de la esteganografía de imágenes (es decir, ruido adicional invisible específico de las muestras generadas)
traducción de comprensión
Resumen
最近,后门攻击对深度神经网络(DNNs)的训练过程构成了新的安全威胁。攻击者试图将隐藏的后门注入到DNNs中,使得受攻击的模型在良性样本上表现良好,而一旦攻击者定义的触发器激活隐藏的后门,其预测结果将恶意地被改变。现有的后门攻击通常采用的设定是触发器与样本无关,也就是说,不同的被污染样本中包含相同的触发器,这导致了现有的后门防御能够轻易地减轻攻击。在这项工作中,我们探讨了一种新的攻击范式,其中后门触发器是样本特定的。在我们的攻击中,我们只需要修改某些训练样本中的看不见的扰动,而无需像许多现有的攻击那样操纵其他训练组件(例如,训练损失和模型结构)。具体来说,受到最近在DNN基础上的图像隐写术的启发,我们通过编码器-解码器网络将攻击者指定的字符串编码到良性图像中,生成样本特定的看不见的附加噪声作为后门触发器。当DNNs在被污染的数据集上进行训练时,将会生成从字符串到目标标签的映射。对基准数据集的大量实验验证了我们的方法在有或无防御的模型攻击中的有效性。
代码可以在 https://github.com/yuezunli/ISSBA 获得。
1. 引言
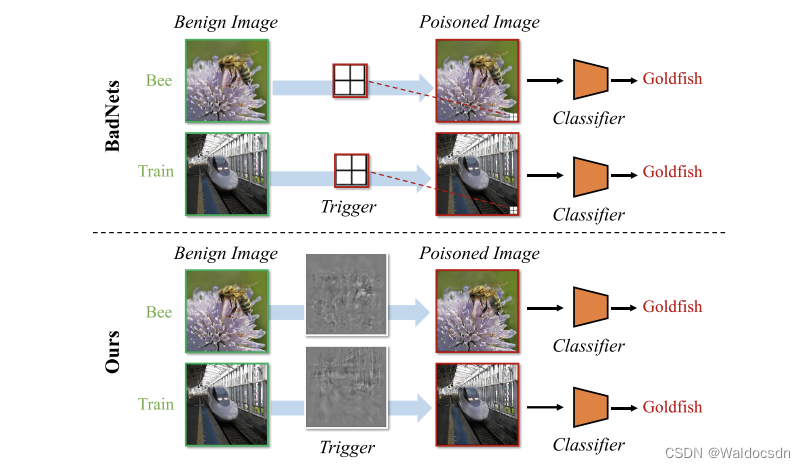
图1. 对比之前的攻击(例如,BadNets [8])和我们的攻击中的触发器。之前攻击的触发器是样本无关的(即,不同的被污染样本包含相同的触发器),而我们的方法中的触发器是样本特定的。
Las redes neuronales profundas (DNN) se han aplicado ampliamente y con éxito en muchos campos [11, 25, 49, 19]. Una gran cantidad de datos de entrenamiento y una potencia informática cada vez mayor son los factores clave para su éxito, pero el complicado proceso de entrenamiento a largo plazo se ha convertido en un cuello de botella para los usuarios e investigadores. Para reducir los gastos generales, la capacitación de DNN generalmente aprovecha los recursos de terceros. Por ejemplo, puede utilizar datos de terceros (como datos de Internet o de empresas de terceros), entrenar modelos con servidores de terceros (como Google Cloud) o incluso adoptar directamente API de terceros. Sin embargo, la opacidad del proceso de formación trae consigo nuevas amenazas a la seguridad.
Los ataques de puerta trasera son una amenaza emergente en el proceso de entrenamiento de las DNN. Manipula maliciosamente la predicción del modelo DNN atacado al contaminar parte de las muestras de entrenamiento. Específicamente, el atacante de puerta trasera inyecta algunos patrones especificados por el atacante (llamados disparadores de puerta trasera) en la imagen contaminada y reemplaza las etiquetas correspondientes con etiquetas de destino predefinidas. Por lo tanto, los atacantes pueden incrustar algunas puertas traseras ocultas en los modelos entrenados con el conjunto de entrenamiento contaminado. El modelo atacado funcionará normalmente cuando procese muestras benignas, pero cuando el activador esté presente, sus predicciones se cambiarán a etiquetas objetivo. Además, el activador puede ser invisible [3, 18, 34] y el atacante solo necesita contaminar una pequeña fracción de las muestras, lo que hace que el ataque sea muy sigiloso. Por lo tanto, los ataques insidiosos de puerta trasera representan una seria amenaza para la aplicación de DNN.
Afortunadamente, se han propuesto varias defensas de puerta trasera [7, 41, 45], lo que demuestra que los ataques de puerta trasera existentes se pueden mitigar con éxito. Esto plantea una pregunta importante: ¿realmente se ha resuelto la amenaza de los ataques de puerta trasera? En este documento, revelamos que los ataques de puerta trasera existentes son fácilmente mitigados por las defensas actuales, principalmente porque sus disparadores de puerta trasera son independientes de la muestra, es decir, diferentes muestras contaminadas. Todos los patrones contienen los mismos disparadores. Teniendo en cuenta que los disparadores son independientes de la muestra, los defensores pueden reconstruir o detectar fácilmente disparadores de puerta trasera en función del mismo comportamiento entre diferentes muestras contaminadas.
Con base en este entendimiento, exploramos un nuevo paradigma de ataque donde el disparador de puerta trasera es específico de la muestra. Solo necesitamos modificar perturbaciones invisibles en algunas muestras de entrenamiento, sin manipular otros componentes de entrenamiento (por ejemplo, pérdida de entrenamiento y estructura del modelo) como muchos ataques existentes. Específicamente, inspirados en la esteganografía de imágenes basada en DNN [2, 51, 39], codificamos cadenas especificadas por el atacante en imágenes benignas a través de una red de codificador-descodificador, generando ruido adicional invisible específico de la muestra como disparador de puerta trasera . Cuando los DNN se entrenan en el conjunto de datos contaminado, se genera una asignación de cadenas a etiquetas de destino. El paradigma de ataque propuesto rompe los supuestos básicos de los métodos de defensa actuales, por lo que pueden pasarse por alto fácilmente.
Las principales contribuciones de este documento son las siguientes: (1) Brindamos una discusión exhaustiva de las condiciones de éxito de las defensas de puerta trasera convencionales actuales. Revelamos que todo su éxito se basa en la premisa de que los activadores de puerta trasera son independientes de la muestra. (2) Exploramos un nuevo paradigma de ataque invisible en el que el activador de la puerta trasera es específico de la muestra y no se ve. Puede eludir las defensas existentes porque rompe sus suposiciones básicas. (3) Llevamos a cabo extensos experimentos para verificar la efectividad del método propuesto.
2. Trabajo relacionado
2.1 Ataque de puerta trasera
El ataque de puerta trasera es un campo de investigación emergente y de rápido desarrollo que plantea una amenaza de seguridad para el proceso de entrenamiento de las redes neuronales profundas (DNN). Los ataques existentes se pueden dividir en dos categorías según las características de los disparadores: (1) ataques visibles, los disparadores en la muestra atacada son visibles para los humanos; (2) ataques invisibles, los disparadores son invisibles.
Ataque de puerta trasera visible. Gu y otros [8] revelaron la amenaza de puerta trasera en el entrenamiento de DNN por primera vez y propusieron el ataque BadNets, que es un representante de los ataques de puerta trasera visibles. Dada una etiqueta de destino especificada por el atacante, BadNets contamina un subconjunto de imágenes de entrenamiento de otras clases al superponer un disparador de puerta trasera (por ejemplo, un cuadrado blanco de 3×3 en la esquina inferior derecha de una imagen) en una imagen benigna. Estas imágenes contaminadas con etiquetas de destino, junto con otras muestras de entrenamiento benignas, se introducen en los DNN para el entrenamiento. Actualmente, hay algunos otros trabajos en esta área [37, 22, 27]. En particular, el trabajo concurrente [27] también investigó ataques de puerta trasera específicos de la muestra. Sin embargo, su método necesita controlar la pérdida de entrenamiento además de modificar las muestras de entrenamiento, lo que reduce en gran medida su amenaza en aplicaciones prácticas.
Ataques de puerta trasera invisibles. Chen y otros [3] analizaron por primera vez la ocultación de los ataques de puerta trasera desde la perspectiva de la visibilidad de los desencadenantes de la puerta trasera. Sugieren que las imágenes contaminadas deberían ser indistinguibles de sus contrapartes benignas para evitar la inspección manual. Específicamente, proponen un ataque invisible con una estrategia híbrida que genera imágenes contaminadas al mezclar activadores de puertas traseras con imágenes benignas en lugar de imprimirlas directamente. Además de los métodos anteriores, se han propuesto algunos otros ataques invisibles [31, 34, 50] para diferentes escenarios: Quiring et al. [31] para escalado de imágenes durante el entrenamiento, Zhao et al. [50] para reconocimiento de video, Saha y otros [34] suponen que el atacante conoce la estructura del modelo. Tenga en cuenta que la mayoría de los ataques existentes emplean diseños de disparadores independientes de la muestra, es decir, los disparadores se fijan durante la fase de entrenamiento o prueba. En este documento, proponemos un paradigma de ataque invisible más fuerte donde el disparador de puerta trasera es específico de la muestra .
2.2 Defensa de puerta trasera
Ver 3. Comprensión profunda de las defensas existentes
Defensa basada en la poda. Inspirándose en la observación de que las neuronas relacionadas con la puerta trasera suelen estar inactivas durante la inferencia en muestras benignas, Liu y otros [24] propusieron podar estas neuronas para eliminar las puertas traseras ocultas en las DNN. Una idea similar también fue explorada por Cheng et al [4], quienes propusieron eliminar el ℓ ∞ \ell _{\infty} del mapa de activación de la capa convolucional finalℓ∞Neuronas con altos valores de activación en la norma.
Defensa basada en la síntesis de disparadores. A diferencia de eliminar directamente las puertas traseras ocultas, las defensas basadas en la síntesis de desencadenantes primero sintetizan los desencadenantes potenciales y luego eliminan las puertas traseras ocultas suprimiendo sus efectos en una segunda etapa . Wang y otros [41] propusieron la primera defensa basada en la síntesis de activación, Neural Cleanse , donde primero obtuvieron los posibles patrones de activación para cada clase y luego determinaron los patrones de activación sintéticos finales basados en detectores de anomalías y su etiqueta objetivo. También se han estudiado ideas similares en [30, 9, 42], quienes adoptaron diferentes enfoques para generar activadores latentes o realizar la detección de anomalías.
Defensa basada en mapas de prominencia. Estos métodos usan mapas de prominencia para identificar posibles regiones desencadenantes para filtrar muestras maliciosas. Al igual que para desencadenar defensas basadas en síntesis, también están involucrados los detectores de anomalías. Por ejemplo, SentiNet [5] emplea Grad-CAM [35] para extraer regiones clave de la entrada de cada clase y luego ubicar las regiones desencadenantes en función del análisis de límites. También se exploran ideas similares [13].
BANDA. Recientemente, Gao y otros [7] propusieron un método, llamado STRIP, para filtrar muestras maliciosas superponiendo varios patrones de imágenes en imágenes sospechosas y observando la aleatoriedad de sus predicciones. Según la suposición de que el activador de la puerta trasera es independiente de la entrada, cuanto menor sea la aleatoriedad, mayor será la probabilidad de que la imagen sospechosa sea maliciosa .
3. Obtenga información sobre las defensas existentes
En esta sección, discutimos las condiciones de éxito para las defensas de puerta trasera convencionales actuales. Argumentamos que su éxito depende principalmente de la suposición implícita de que los disparadores de puerta trasera son independientes de la muestra. Una vez que se viola este supuesto, su eficacia se verá muy afectada. Las suposiciones para varios métodos de defensa se discuten a continuación.
La suposición de las defensas basadas en la poda Las defensas basadas en la poda se inspiran en la suposición de que las neuronas asociadas a la puerta trasera son distintas de las activadas por muestras benignas . Los defensores pueden eliminar las puertas traseras ocultas podando las neuronas que están latentes en las muestras benignas. Sin embargo, la falta de superposición entre estos dos tipos de neuronas puede deberse a la simplicidad del patrón de activación independiente de la muestra, es decir, las DNN solo necesitan una pequeña cantidad de neuronas independientes para codificar esta activación. Esta suposición puede no ser válida cuando los activadores son específicos de la muestra, ya que este paradigma es más complicado.
-
La traducción al chino de este pasaje es la siguiente:
Hipótesis de los métodos de defensa basados en la poda. El enfoque de defensa basado en la poda se basa en la suposición de que las neuronas asociadas con las puertas traseras son distintas de las que se activan para las muestras benignas. Los defensores pueden podar las neuronas que están inactivas en muestras benignas para eliminar las puertas traseras ocultas. Sin embargo, la falta de superposición entre estos dos tipos de neuronas puede deberse a la simplicidad de los patrones de activación independientes de la muestra, es decir, las redes neuronales profundas (DNN) requieren solo unas pocas neuronas independientes para codificar tales activadores. Esta suposición puede no ser válida cuando los activadores son específicos de la muestra, ya que el paradigma es más complejo.
-
Análisis detallado y fácil de entender:
El método de defensa basado en la poda es una estrategia de defensa para redes neuronales basada en la suposición de que las neuronas asociadas con ataques de puerta trasera (es decir, las neuronas activadas por disparadores) son diferentes de las neuronas que procesan muestras normales (benignas). Esto se debe a que en un ataque de puerta trasera, el atacante generalmente implanta neuronas específicas en el modelo, y cuando estas neuronas se activan (por ejemplo, al ingresar una imagen que contiene un disparador), el modelo hará que el atacante realice el pronóstico especificado.
Por lo tanto, los defensores pueden eliminar las puertas traseras en el modelo podando (es decir, eliminando) aquellas neuronas que no responden a las muestras normales (es decir, están inactivas). Eso es porque si una neurona no responde a las muestras normales, es probable que sea una neurona de puerta trasera plantada por un atacante.
Sin embargo, el éxito de este método presupone que las neuronas de puerta trasera y las neuronas que procesan muestras normales no se superponen, una suposición que puede no ser válida en algunos casos. Por ejemplo, si los disparadores de puerta trasera son específicos de la muestra (es decir, los disparadores se comportan de manera diferente en diferentes muestras), entonces las neuronas de puerta trasera pueden superponerse con las neuronas que procesan muestras normales, lo que hace que los métodos de poda sean menos efectivos. Elimine las puertas traseras.
La suposición de las defensas basadas en la síntesis de desencadenantes Durante la síntesis, los métodos existentes (p. ej., limpieza neuronal [41]) deben encontrar aquellos que puedan transformar cualquier imagen inofensiva (benigna) en patrones desencadenantes potenciales específicos para categorías. Por lo tanto, los disparadores sintetizados solo son efectivos si los disparadores de puerta trasera especificados por el atacante son irrelevantes para la muestra.
-
(OK) El tema de este pasaje es una hipótesis acerca de las defensas de síntesis desencadenante. Explicación detallada paso a paso:
-
Defensa de síntesis de activación: esta es una estrategia de defensa utilizada principalmente para hacer frente a ataques de puerta trasera de modelos de aprendizaje profundo. Un ataque de puerta trasera es cuando un atacante inserta un patrón específico oculto (lo llamamos "desencadenante") durante el entrenamiento del modelo que hace que el modelo haga predicciones anormales. El objetivo de la defensa de síntesis de desencadenantes es descubrir dichos desencadenantes para llevar a cabo una defensa eficaz.
-
Proceso de síntesis: en esta estrategia de defensa, es necesario identificar posibles patrones desencadenantes a través de un proceso denominado "síntesis". En pocas palabras, el proceso consiste en tratar de generar todos los patrones posibles y ver cuál hace que las predicciones del modelo cambien de manera anormal . Por ejemplo, si el modelo siempre predice "gato" cuando ve una imagen con un patrón determinado, incluso si el contenido real de la imagen no es un gato, entonces ese patrón determinado podría ser un desencadenante.
-
Convierta cualquier imagen inofensiva (benigna) en una categoría específica: esta oración describe el efecto del disparador. Un disparador es un patrón que puede cambiar el resultado de las predicciones de un modelo. En nuestro ejemplo, si el modelo identifica incorrectamente una imagen inocua (es decir, no manipulada) como "gato" después de agregar el activador, entonces podemos considerar este patrón como un posible activador.
-
Disparadores de puerta trasera agnósticos de muestra: esta es una suposición central de este enfoque de defensa. "Independiente de la muestra" significa que no importa en qué imagen se inserte el disparador, siempre que el disparador esté presente, el resultado de la predicción del modelo cambiará. Es decir, el efecto del activador no se verá afectado por el contenido específico de la imagen. Esta suposición es importante porque si el efecto del disparador cambia con el contenido de la imagen, nos será difícil encontrarlo a través del proceso de composición.
Entonces, la idea general de este pasaje es: cuando usamos el método de defensa de síntesis de disparadores, necesitamos encontrar esos disparadores potenciales que pueden convertir cualquier imagen inocua en una clase específica, pero este método de defensa solo funciona si el disparador es independiente de la muestra. caso es válido.
-
-
(OK) Permítanme ilustrar el significado de este pasaje con un ejemplo simple:
Supongamos que tenemos un modelo de aprendizaje profundo cuya tarea es reconocer animales en imágenes. En una situación normal, si alimentamos al modelo con la imagen de un perro, predecirá "perro".
Ahora, supongamos que un atacante inserta un disparador de puerta trasera en el modelo, llamémoslo "X". El efecto de este disparador "X" es: no importa cuál sea el contenido real de la imagen, siempre que el disparador "X" esté contenido en la imagen, el modelo predecirá el resultado como "gato".
En las defensas de síntesis de disparadores, nuestra tarea es tratar de generar varios patrones posibles y luego probar la respuesta del modelo a estos patrones. Por ejemplo, generamos un patrón "Y", lo agregamos a una imagen inocua (por ejemplo, la imagen de un perro) y observamos la respuesta del modelo.
Si el modelo aún predice "perro" cuando ve una imagen con el patrón "Y", entonces podemos inferir que el patrón "Y" no es el desencadenante. Si el modelo predice "gato" cuando ve una imagen con el patrón "Y", entonces podemos inferir que el patrón "Y" podría ser el desencadenante.
Sin embargo, la efectividad del método de defensa de síntesis de disparadores se basa en una suposición importante: el disparador de puerta trasera es independiente de la muestra, es decir, sin importar a qué imagen se agregue el disparador "X", el modelo ve la imagen que contiene el disparador "X". ". imagen, la predicción siempre es "gato". Si el efecto de un disparador varía con el contenido de la imagen, por ejemplo, cuando se agrega el disparador "X" a la imagen de un perro, el modelo predice "gato", pero cuando se agrega el disparador "X" a una imagen de un pájaro En la imagen, el modelo predice "pájaro", entonces nos cuesta encontrar el disparador a través del proceso de síntesis.
-
Análisis:
Este párrafo describe los supuestos básicos del método de defensa basado en la síntesis de disparadores. En este enfoque defensivo, primero encuentre aquellos desencadenantes potenciales que pueden convertir cualquier imagen normal (benigna) en una determinada categoría. Aquí, los "desencadenantes potenciales" son aquellos patrones o marcadores que se insertan en la imagen para que el modelo atacado produzca una salida predicha específica.Una suposición clave de este método de defensa es que el activador de puerta trasera utilizado por el atacante es independiente de la muestra, es decir, el activador puede hacer que el modelo produzca los mismos resultados de predicción sin importar en qué imagen se inserte. Esto se debe a que si el efecto de un disparador depende de la imagen en la que se encuentra (es decir, depende de la muestra), entonces un disparador sintetizado de esta manera puede no ser efectivo para convertir todas las imágenes a una clase específica.
Por lo tanto, el método de defensa basado en la síntesis de disparadores solo puede ser efectivo si el disparador de puerta trasera es independiente de la muestra. Si esta suposición no se cumple, es posible que este método de defensa no tenga éxito en la detección y defensa contra ataques de puerta trasera.
-
Supongamos que tenemos un modelo de red neuronal para la clasificación de imágenes cuya tarea es identificar el tipo de animal en una imagen. En general, determinará qué animal está en la imagen según el contenido de la imagen.
然而,如果这个模型受到了后门攻击,攻击者可能会在图像中插入一个特殊的标记(也就是后门触发器),比如一个小红点,使得模型看到这个小红点后,无论图像中实际上是什么动物,都会预测为"猫"。
那么,基于触发器合成的防御方法就是试图找出这个小红点。它会尝试找到一个能够将所有正常图像都转换为"猫"的模式,如果找到的模式和小红点一样,那就说明可能存在后门攻击。
然而,这种防御方法的前提假设是,无论这个小红点被插入到哪一张图像中,模型的预测结果都会变为"猫",也就是说,这个小红点的效果是样本无关的。如果小红点在不同的图像中产生不同的效果,比如在狗的图像中插入小红点模型预测为"猫",而在猫的图像中插入小红点模型预测为"狗",那么这种防御方法就可能无法成功地检测和防御后门攻击,因为它无法找到一个可以将所有图像都转换为同一类别的触发器模式。
-
这段话的主要内容是讨论基于触发器合成的防御方法的一个假设。这种方法如Neural Cleanse等现有技术,在合成过程中需要找出可能的触发器模式,这些模式可以把任何良性(无害)图像转换为特定的类别。所以,这种合成的触发器只有在攻击指定的后门触发器对样本不敏感(sample-agnostic)时才有效。
“对样本不敏感(sample-agnostic)”这个术语指的是后门触发器不依赖于特定的样本。也就是说,无论输入样本是什么,只要有这个触发器,都可以导致模型产生特定的输出。这是基于触发器合成防御方法的一个核心假设。
Tomemos un ejemplo para ilustrar este concepto. Supongamos que tenemos un modelo de aprendizaje profundo para la clasificación de imágenes que ha sido modificado. Durante el proceso de entrenamiento del modelo, el atacante incrusta un disparador específico (como agregar un píxel rojo en la esquina superior derecha de la imagen) en algunas muestras y establece la etiqueta de estas muestras como "gato". Luego, una vez que se implementa el modelo, el atacante puede agregar este disparador a cualquier imagen de entrada, ya sea que la imagen sea originalmente "perro", "automóvil" o "avión", siempre que contenga ese disparador, el modelo lo reconocerá como " gato".
Sin embargo, si el disparador diseñado por el atacante está asociado con una muestra específica, por ejemplo, solo cuando la imagen de entrada es "automóvil", agregar un disparador hará que el modelo lo reconozca como "gato", entonces los métodos de defensa como Neural Cleanse puede no ser efectivo porque su diseño asume que los disparadores no son sensibles a las muestras y se aplican a cualquier imagen de entrada.
-
Neural Cleanse es un método para detectar y mitigar ataques de puerta trasera en redes neuronales. El llamado ataque de puerta trasera significa que durante el proceso de entrenamiento del modelo, el atacante inyecta algunas muestras maliciosas con patrones especiales (es decir, activadores) en el conjunto de entrenamiento. Luego, cuando este modelo encuentre una muestra que contenga el mismo disparador cuando se implemente, producirá el resultado que espera el atacante, no el resultado correcto.
Tomemos un ejemplo. Supongamos que un atacante quiere controlar un modelo de clasificación de imágenes para que cuando vea una imagen con un activador específico (como un punto rojo en la esquina inferior derecha de la imagen), la clasifique como "gato". El atacante agregó algunas imágenes con este disparador de punto rojo en el conjunto de datos de entrenamiento y estableció la etiqueta de estas imágenes como "gato". El modelo entrenado de esta manera se comporta normalmente cuando ve una imagen normal, pero cuando ve una imagen con un disparador de punto rojo, lo reconocerá como un "gato", independientemente del contenido real de la imagen. Este es un ataque de puerta trasera.
El objetivo de Neural Cleanse es detectar y eliminar tales ataques de puerta trasera. El método que adopta es la ingeniería inversa, es decir, modificando la entrada del modelo y observando el cambio de la salida, para encontrar posibles disparadores de puerta trasera. En teoría, si un modelo no está sujeto a un ataque de puerta trasera, cambiar una pequeña parte de la entrada no debería resultar en un cambio significativo en la salida. Pero si un modelo tiene una puerta trasera, agregar un disparador de puerta trasera a la entrada puede generar cambios significativos en la salida.
Específicamente, Neural Cleanse primero intenta encontrar un desencadenante mínimo, es decir, el grado más pequeño para cambiar la entrada para hacer que la salida del modelo cambie de otras categorías a la categoría especificada. Luego, compare el tamaño de este flip-flop más pequeño para todas las clases. Si los activadores mínimos para una determinada categoría son significativamente menores que los de otras, existe la posibilidad de que esta categoría esté sujeta a un ataque de puerta trasera.
Si se detecta un ataque de puerta trasera, Neural Cleanse también puede usar un algoritmo de reparación para eliminar la puerta trasera. El algoritmo funciona al tratar un activador de puerta trasera identificado como un patrón de mal comportamiento y luego reparar el modelo obligándolo a ignorar el patrón. Aunque este método no puede eliminar por completo la puerta trasera, ha demostrado su eficacia en la práctica.
En general, Neural Cleanse es un método de ingeniería inversa para detectar y
Un método de mitigación de ataques de puerta trasera, que aprovecha las huellas que deben dejar los ataques de puerta trasera, es decir, la característica de que el modelo es demasiado sensible a un pequeño disparador.
-
"Los métodos existentes como Neural Cleanse necesitan obtener posibles patrones desencadenantes durante el proceso de síntesis", lo que significa que cuando se usa Neural Cleanse como método de defensa, se requiere un proceso de síntesis, y el propósito de este proceso es Descubrir posibles patrones desencadenantes.
Los patrones desencadenantes son aquellos que pueden activar una puerta trasera y hacer que un modelo produzca un resultado específico (a menudo erróneo). En el principio de funcionamiento de Neural Cleanse, esperamos descubrir estos posibles modos de activación a través de un método de ingeniería inversa.
Específicamente, este proceso es para tratar de encontrar un desencadenante mínimo en un modelo, es decir, para cambiar la salida del modelo de otras categorías a una categoría específica cambiando el grado mínimo de entrada. Luego, al comparar el tamaño de este disparador más pequeño en todas las categorías, se determina si hay un ataque de puerta trasera. Si los activadores mínimos para una determinada categoría son significativamente menores que los de otras, existe la posibilidad de que esta categoría esté sujeta a un ataque de puerta trasera.
El propósito de este "proceso sintético" es tratar de simular los disparadores que un atacante podría usar para descubrir y verificar la existencia de puertas traseras en el modelo.
La suposición de las defensas basadas en mapas de prominencia Como se describe en la Sección 2.2, una defensa basada en mapas de prominencia requiere: (1) calcular un mapa de prominencia para todas las imágenes (para cada categoría) y (2) ubicar las regiones desencadenantes encontrando regiones universalmente sobresalientes en imágenes diferentes En el primer paso, si los disparadores son lo suficientemente compactos y grandes determina si el mapa de prominencia contiene regiones de disparador que afectan la efectividad de la defensa. El segundo paso requiere que el disparador sea independiente de la muestra, de lo contrario, es difícil para los defensores probar la región del disparador.
-
(Bueno) Este pasaje analiza principalmente los supuestos del método de defensa basado en el mapa de prominencia. Un mapa de prominencia es una técnica de procesamiento de imágenes que se utiliza para resaltar las partes más importantes (o "destacadas") de una imagen, generalmente las partes más llamativas. Aquí, nuestra principal preocupación es cómo usar esta técnica para defenderse contra algunos ataques de modelos maliciosos.
Ahora, analicemos cada parte de este pasaje una por una.
-
"Calcular mapas de prominencia para todas las imágenes (para cada clase)": Esto significa que necesitamos generar un mapa de prominencia para cada imagen en el conjunto de datos, resaltando sus características más destacadas. Por ejemplo, si tratáramos con un conjunto de imágenes que incluyera imágenes de gatos, perros y pájaros, necesitaríamos generar un mapa de prominencia para cada imagen de cada tipo de animal.
-
"Si el desencadenante es lo suficientemente compacto y grande determina si el mapa de prominencia contiene la región desencadenante que afecta la efectividad de la defensa": un desencadenante es un patrón o característica específica implantada en el modelo por el atacante en un ataque de modelo malicioso. el modelo detecta Cuando se encuentra este patrón o característica, se produce una respuesta predeterminada. Por ejemplo, un atacante podría colocar un disparador en un modelo de reconocimiento de imágenes que reconocería la imagen como "gato" cada vez que el modelo detecta un determinado patrón de píxeles (como un punto rojo). Si el gatillo aquí es lo suficientemente compacto y grande se refiere a la representación del gatillo en la imagen. Si el disparador es pequeño o está disperso, es posible que el mapa de prominencia no pueda resaltar con precisión el disparador, lo que afecta la efectividad de la defensa.
-
"Localizar regiones desencadenantes encontrando regiones sobresalientes universales (comúnmente) en diferentes imágenes": los mapas de prominencia resaltan las partes más importantes de una imagen, y podemos encontrar regiones sobresalientes compartidas comparando mapas de prominencia de diferentes imágenes. Esta área puede ser el desencadenante plantado por el atacante.
-
"Los factores desencadenantes son independientes de la muestra, de lo contrario, es difícil para los defensores probar las regiones desencadenantes": si los factores desencadenantes solo aparecen en algunas imágenes específicas, entonces es difícil para nosotros encontrar prominencia compartida en el mapa de prominencia de todas las regiones de imágenes, la región desencadenante no pudo ser encontrado.
Por lo tanto, se requiere que los activadores sean independientes de la muestra, es decir, es probable que los activadores aparezcan en todas las imágenes.
-
-
Una explicación detallada de este pasaje:
La llamada defensa basada en mapas de prominencia es un método que intenta encontrar posibles activadores de puertas traseras en las imágenes. Un mapa de prominencia es un mapa que revela qué regiones de la imagen tienen el mayor impacto en las predicciones del modelo. Si una región aparece prominente en el mapa de prominencia, entonces esta región puede ser un disparador de puerta trasera.
-
Por ejemplo, supongamos que tenemos un modelo de red neuronal con puerta trasera, y el atacante inserta un pequeño punto rojo en la imagen como disparador de puerta trasera. Cuando calculamos el mapa de prominencia de esta imagen, si este pequeño punto rojo tiene una gran influencia en los resultados de predicción del modelo, aparecerá muy destacado en el mapa de prominencia y lo reconoceremos. Este es el primer paso.
Sin embargo, la premisa de este método es que este pequeño punto rojo sea compacto (es decir, su área de influencia esté concentrada) y lo suficientemente grande como para ser identificado en el mapa de prominencia. Si el punto rojo es pequeño, o si su área de influencia está dispersa en varias partes de la imagen, es posible que no podamos encontrarlo a través del mapa de prominencia.
En el segundo paso, necesitamos encontrar regiones sobresalientes compartidas en diferentes imágenes como posibles regiones de activación de puerta trasera. La premisa de este paso es que el disparador de puerta trasera es independiente de la muestra, es decir, sin importar en qué imagen, el disparador aparecerá en la misma área y producirá el mismo efecto. Si los activadores aparecen en diferentes lugares o tienen diferentes efectos en diferentes imágenes, entonces es difícil determinar qué área es el área de activación real.
La suposición de STRIP STRIP [7] prueba una muestra maliciosa superponiendo varios patrones de imagen en imágenes sospechosas. Si los resultados de predicción de las muestras generadas son consistentes, la muestra analizada se considerará como una muestra contaminada. Tenga en cuenta que su éxito también se basa en la suposición de que los desencadenantes subyacentes son independientes de la muestra.
-
(OK) El núcleo de este párrafo es la descripción de la estrategia de defensa STRIP. STRIP es una estrategia de defensa utilizada para detectar muestras de imágenes que pueden ser manipuladas de forma malintencionada. Específicamente, superpone varios patrones de imagen en imágenes sospechosas y luego ve si las imágenes superpuestas aún mantienen los resultados de predicción originales. Si los resultados de la predicción son consistentes, es posible que la imagen original haya sido manipulada malintencionadamente. Sin embargo, este método también se basa en la suposición de que el disparador de puerta trasera es independiente de la muestra, es decir, el disparador de puerta trasera tiene el mismo efecto sin importar en qué muestra se encuentre.
Por ejemplo, si tenemos una imagen que se puede manipular, su resultado de predicción es "gato". Usamos la estrategia STRIP para superponer diferentes patrones de imagen en esta imagen, como superponer la imagen de un perro, la imagen de una mesa, etc. Después de la superposición, obtenemos un montón de nuevas imágenes, y luego predecimos estas nuevas imágenes. Si el resultado de la predicción sigue siendo "gato", entonces es probable que la imagen original haya sido manipulada, porque incluso si se superponen otros elementos, el el resultado de la predicción sigue siendo Sin cambios. Pero la premisa de esta estrategia es que el disparador de puerta trasera tiene el mismo efecto sin importar en qué tipo de imagen se encuentre.
-
La traducción al chino de este pasaje es la siguiente:
Supuestos de la TIRA. STRIP [7] inspecciona una muestra maliciosa superponiendo varios patrones de imagen en imágenes sospechosas. Si los resultados de predicción de las muestras generadas son consistentes, esta muestra verificada se considerará una muestra contaminada. Tenga en cuenta que su éxito también se basa en la suposición de que los disparadores de puerta trasera son independientes de la muestra.
-
Una explicación detallada de este pasaje:
STRIP es una tecnología de defensa de redes neuronales. Su principio de funcionamiento es superponer varios patrones de imagen en una imagen sospechosa y luego observar si las imágenes superpuestas son consistentes con las categorías predichas por el modelo de red neuronal. Si las predicciones son consistentes, se puede inferir que puede haber un disparador de puerta trasera en la imagen sospechosa, ya que este disparador lleva al modelo a hacer la misma predicción sin importar qué patrón de imagen se superponga.
-
Por ejemplo, supongamos que tenemos un modelo de red neuronal que está bajo un ataque de puerta trasera. El atacante inserta un pequeño punto rojo en la imagen como disparador de puerta trasera. Cuando aparece este pequeño punto rojo, el modelo predice una categoría específica. Superpusimos varios patrones de imagen en una imagen sospechosa. Independientemente del patrón superpuesto, el modelo predice la misma categoría, por lo que tenemos razones para creer que este pequeño punto rojo puede ser el desencadenante de la puerta trasera.
Sin embargo, el éxito de STRIP también se basa en la suposición de que los disparadores de puerta trasera son independientes de la muestra. Esto se debe a que si el disparador se comporta de manera diferente en diferentes muestras, por ejemplo, aparece en la esquina superior izquierda de la imagen en algunas muestras y en la esquina inferior derecha en otras, es posible que el modo de imagen superpuesta no pueda cubrir Todos los disparadores conducen a resultados de predicción inconsistentes del modelo, lo que afecta el efecto de detección de STRIP.
4. Ejemplo de ataque de puerta trasera específico (SSBA)
4.1 Modelo de amenazas
capacidades del atacante. Suponemos que los atacantes pueden envenenar parte de los datos de entrenamiento , pero no pueden obtener ni modificar información sobre otros componentes del entrenamiento (p. ej., pérdida de entrenamiento, progreso del entrenamiento y estructura del modelo). Durante el proceso de inferencia, el atacante puede y solo puede consultar el modelo de entrenamiento en busca de imágenes arbitrarias. No tienen información sobre el modelo ni pueden manipular el proceso de inferencia. Este es el requisito mínimo para un atacante de puerta trasera [21]. Esta amenaza puede ocurrir en muchos escenarios del mundo real, incluidos, entre otros, el uso de datos de capacitación de terceros, plataformas de capacitación y API modelo.
objetivo del atacante. En general, los atacantes de puerta trasera intentan incrustar puertas traseras ocultas en los DNN contaminando los datos . La puerta trasera oculta será activada por el disparador especificado por el atacante, es decir, la predicción de la imagen que contiene el disparador será la etiqueta de destino, cualquiera que sea su verdadera etiqueta. En particular, los atacantes tienen tres objetivos principales, que incluyen efecto, sigilo y persistencia . "Efecto" requiere que cuando aparece el activador de puerta trasera, la predicción de los DNN atacados debe ser la etiqueta de destino, y el rendimiento en muestras de prueba benignas no debe reducirse significativamente; el "ocultamiento" requiere que el activador adoptado se oculte y envenene. La proporción de muestras (es decir, la tasa de envenenamiento) debe ser pequeña; la "persistencia" requiere que el ataque siga siendo efectivo bajo algunas defensas comunes de puerta trasera.
4.2 Ataque propuesto
En esta sección, ilustramos nuestro método propuesto. Antes de describir cómo generar disparadores específicos de la muestra, primero repasamos brevemente el proceso principal del ataque e introducimos la definición de un ataque de puerta trasera específico de la muestra.
El proceso principal del ataque de puerta trasera: Sea D entrenar = { ( xi , yi ) } i = 1 N \mathcal{D}_{\text{entrenar}}=\left\{(\boldsymbol{x}_i, y_i) \derecha\}_{i=1}^{N}Dtren={ ( xyo,yyo) }yo = 1norteRepresenta un conjunto de entrenamiento benigno que contiene N muestras independientes e idénticamente distribuidas, donde xi ∈ X = { 0 , ⋯ , 255 } C × W × H \boldsymbol{x}_i \in \mathcal{X}=\{0, \cdots , 255\}^{C \times W \times H}Xyo∈X={ 0 ,⋯,255 }C × W × H并且yi ∈ Y = { 1 , ⋯ , K } y_i \in \mathcal{Y}=\{1, \cdots, K\}yyo∈Y={ 1 ,⋯,K } . El clasificador aprende un clasificador con parámetrosw \boldsymbol{w}La función fw de w : X → [ 0 , 1 ] K f_{\boldsymbol{w}}: \mathcal{X} \rightarrow[0,1]^{K}Fw:X→[ 0 ,1 ]K。设yt y_tytDenota la etiqueta objetivo ( yt ∈ Y ) (y_t \in \mathcal{Y})( yt∈Y ) . El núcleo del ataque de puerta trasera es cómo generar un conjunto de entrenamiento envenenadoD p \mathcal{D}_pDpag. Específicamente, D p \mathcal{D}_pDpag由D tren \mathcal{D}_{\text{tren}}DtrenUna versión modificada de un subconjunto de (es decir, D m ) \left.\mathcal{D}_m\right)Dm) y las muestras benignas restantesD b \mathcal{D}_bDsegundocomposición, a saber
re pags = re metro ∪ re segundo \mathcal{D}_p=\mathcal{D}_m \cup \mathcal{D}_bDpag=Dm∪Dsegundo
其中,D segundo ⊂ D entrenar \mathcal{D}_b \subset \mathcal{D}_{\text{entrenar}}Dsegundo⊂Dtren, γ = ∣ re metro ∣ ∣ re tren ∣ \gamma=\frac{|\mathcal{D}_m|}{|\mathcal{D}_{\text{tren}}|}C=∣ Dtren∣∣ Dm∣表示毒化率,re metro = { ( x ′ , yt ) ∣ x ′ = GRAMO θ ( x ) , ( x , y ) ∈ re tren \ re segundo } \mathcal{D}_m=\left\{(\boldsymbol {x}^{\prime}, y_t) \mid \boldsymbol{x}^{\prime}=G_{\boldsymbol{\theta}}(\boldsymbol{x}),(\boldsymbol{x}, y) \in \mathcal{D}_{\text{tren}} \barra invertida \mathcal{D}_b\right\}Dm={
( x′ ,yt)∣X′=GRAMOi( X ) ,( X ,y )∈Dtren\ resegundo},G θ : X → X G_{\boldsymbol{\theta}}: \mathcal{X} \rightarrow \mathcal{X}GRAMOi:X→X es el generador de imágenes envenenadas especificado por el atacante. γ \gammaCuanto menor sea la γ , más sigiloso será el ataque.
Definición 1: Si para todo xi , xj ∈ X \boldsymbol{x}_{i}, \boldsymbol{x}_{j} \in \mathcal{X}Xyo,Xj∈X(xi ≠ xj \boldsymbol{x}_{i} \neq \boldsymbol{x}_{j}Xyo=Xj),都有T ( G ( xi ) ) ≠ T ( G ( xj ) ) T\left(G\left(\boldsymbol{x}_{i}\right)\right) \neq T\left(G\ izquierda(\boldsymbol{x}_{j}\right)\right)T( G( Xyo) )=T( G( Xj) ) , entonces se dice que tiene un generador de imágenes envenenadoG ( ⋅ ) G(\cdot)El ataque de puerta trasera de G ( ⋅ ) es específico de la muestra. Aquí, T ( G ( x ) ) T(G(\boldsymbol{x}))T ( G ( x )) significa la muestra envenenadaG ( x ) G(\boldsymbol{x})El gatillo de la puerta trasera contenido en G ( x ) .
Nota 1: Los desencadenantes de ataques anteriores no eran específicos de la muestra. Por ejemplo, para el ataque propuesto en [3], para todo x ∈ X \boldsymbol{x} \in \mathcal{X}X∈X , todos tienenT ( G ( x ) ) = t T(G(\boldsymbol{x}))=\boldsymbol{t}T ( G ( x ))=t,其中G ( x ) = ( 1 − λ ) ⊗ x + λ ⊗ t G(\boldsymbol{x})=(\mathbf{1}-\boldsymbol{\lambda}) \otimes \boldsymbol{x}+ \boldsymbol{\lambda} \otimes \boldsymbol{t}G ( x )=( 1−yo )⊗X+yo⊗t。
Expliquemos estas fórmulas y términos matemáticos uno por uno para su comprensión.
Este texto describe el proceso principal de un ataque de puerta trasera y cómo definir un ataque de puerta trasera específico de la muestra.
-
re tren = { ( xi , yi ) } yo = 1 norte \mathcal{D}_{\text{tren}}=\left\{(\boldsymbol{x}_i, y_i)\right\}_{i= 1}^{N}Dtren={ ( xyo,yyo) }yo = 1norte: Este es el conjunto de datos de entrenamiento, que contiene N muestras, cada muestra consta de un vector de entrada xi \boldsymbol{x}_iXyoy una etiqueta yi y_iyyocomposición. Se supone que estas muestras son independientes e idénticamente distribuidas.
-
xi ∈ X = { 0 , ⋯ , 255 } C × W × H \boldsymbol{x}_i \in \mathcal{X}=\{0, \cdots, 255\}^{C \times W \times H}Xyo∈X={ 0 ,⋯,255 }C × W × H : cada vector de entradaxi \boldsymbol{x}_iXyoAmbos son una imagen, que tiene una matriz en cada canal (por ejemplo, rojo, verde, azul), el tamaño de la matriz es ancho W por alto H, y cada píxel tiene un valor entre 0 y 255. CCC representa el número de canales de color de la imagen.
-
yi ∈ Y = { 1 , ⋯ , K } y_i \in \mathcal{Y}=\{1, \cdots, K\}yyo∈Y={ 1 ,⋯,K } : para cada etiquetayi y_iyyoson una categoría, cada una de ellas pertenece al conjunto Y \mathcal{Y}Y ,集合Y \mathcal{Y}Y contiene números enteros del 1 al K, donde K es el número total de categorías.
-
fw : X → [ 0 , 1 ] K f_{\boldsymbol{w}}: \mathcal{X} \rightarrow[0,1]^{K}Fw:X→[ 0 ,1 ]K : esta es la función clasificadora que toma una imagen de entrada y devuelve unKKVector K -dimensional, donde cada elemento representa la probabilidad de que la imagen pertenezca a la categoría correspondiente.
-
re pags = re metro ∪ re segundo \mathcal{D}_p=\mathcal{D}_m \cup \mathcal{D}_bDpag=Dm∪Dsegundo: El conjunto de entrenamiento envenenado es un conjunto de muestra modificado (es decir, D m \mathcal{D}_mDm) y el resto del conjunto de muestras benignas ( D b \mathcal{D}_bDsegundo)consiste en.
-
γ = ∣ re metro ∣ ∣ re tren ∣ \gamma=\frac{|\mathcal{D}_m|}{|\mathcal{D}_{\text{tren}}|}C=∣ Dtren∣∣ Dm∣: Esta es la tasa de envenenamiento, es decir, la proporción de muestras modificadas para contener puertas traseras con respecto al total de muestras en el conjunto de entrenamiento.
-
re metro = { ( x ′ , yt ) ∣ x ′ = GRAMO θ ( x ) , ( x , y ) ∈ re tren \ re segundo } \mathcal{D}_m=\left\{(\boldsymbol{x}^ {\prime}, y_t) \mid \boldsymbol{x}^{\prime}=G_{\boldsymbol{\theta}}(\boldsymbol{x}),(\boldsymbol{x}, y) \in \mathcal {D}_{\text{tren}} \barra invertida \mathcal{D}_b\right\}Dm={ ( x′ ,yt)∣X′=GRAMOi( X ) ,( X ,y )∈Dtren\ resegundo} : este es el conjunto de muestras modificado, donde la entrada de cada muestra se pasa a través de una funciónG θ G_{\boldsymbol{\theta}}GRAMOiobtenido modificando la entrada original.
-
Definición 1: para dos imágenes de entrada diferentes, los disparadores de puerta trasera en sus imágenes envenenadas también son diferentes.
-
Nota 1: En ataques anteriores, los activadores no eran específicos de la muestra. Por ejemplo, para el ataque propuesto en [3], los disparadores son los mismos en todas las imágenes envenenadas.
Nota:
Estas dos fórmulas describen el proceso de envenenamiento e identifican los desencadenantes del envenenamiento. Déjame explicarte cada uno de ellos:
-
GRAMO θ ( x ) G_{\boldsymbol{\theta}}(\boldsymbol{x})GRAMOi( x ) : Esta es una función definida por el atacante, que es responsable de convertir la muestra originalx \boldsymbol{x}x se transforma en una muestra envenenada. θ \boldsymbol{\theta}θ representa el parámetro de esta función,x \boldsymbol{x}x es la muestra original de la entrada. La función principal de esta función esincrustar uno o más disparadores de puerta trasera en la muestra originalpara generar muestras envenenadas. Por ejemplo, una función de envenenamiento simple puede cambiar una parte de los píxeles de la muestra original a un color específico, formando una marca distintiva.
-
T ( GRAMO ( x ) ) T(G(\boldsymbol{x}))T ( G ( x )) : esta función se utiliza para identificar activadores de puerta trasera en muestras envenenadas. G ( x ) G(\boldsymbol{x})G ( x ) generó muestras envenenadas, yT ( G ( x ) ) T(G(\boldsymbol{x}))T ( G ( x )) es extraer el gatillo de la puerta trasera de la muestra envenenada. En términos simples, esta función es identificar "qué lugares en esta muestra envenenada han sido modificados".
Entonces, en general, G θ ( x ) G_{\boldsymbol{\theta}}(\boldsymbol{x})GRAMOi( x ) es responsable de generar muestras envenenadas,T ( G ( x ) ) T(G(\boldsymbol{x}))T ( G ( x )) es responsable de identificar los disparadores de puerta trasera en muestras envenenadas. Y la x \boldsymbol{x}en estas dos funcionesx , ambos se refieren a las muestras originales.
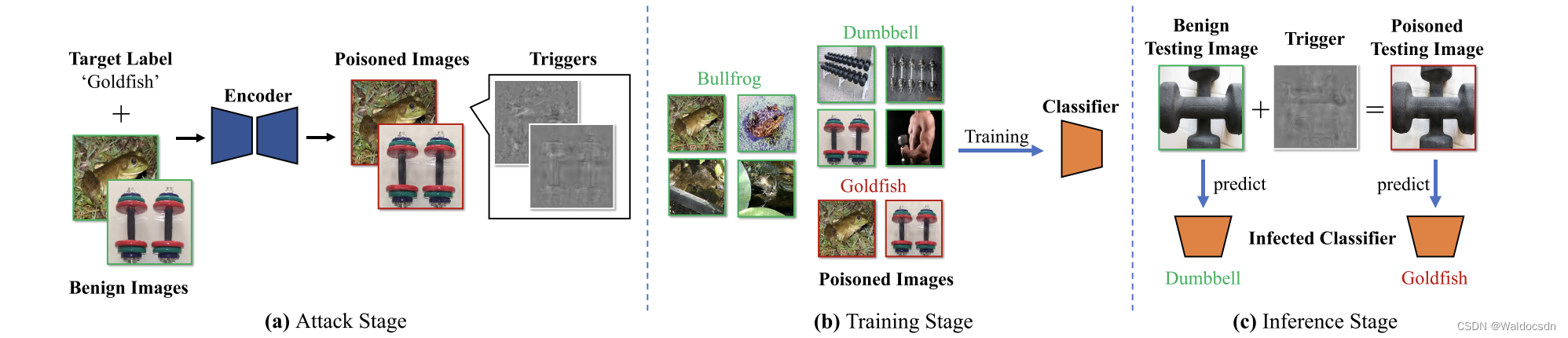
Figura 2. Nuestro flujo de ataque. En la fase de ataque , el atacante de puerta trasera contamina algunas muestras de entrenamiento benignas al inyectar disparadores específicos de la muestra. Los disparadores generados son ruido aditivo invisible que contiene información de cadenas representativas de etiquetas objetivo. En la fase de entrenamiento , el usuario utiliza el conjunto de entrenamiento contaminado para entrenar la red neuronal profunda a través del proceso de entrenamiento estándar. En consecuencia, se generará una asignación de cadenas representativas a etiquetas objetivo. Durante la fase de inferencia , un clasificador infectado (es decir, una red neuronal profunda entrenada en un conjunto de entrenamiento contaminado) funcionará normalmente en muestras de prueba benignas, y cuando se agregue un disparador de puerta trasera, sus predicciones cambiarán a Etiqueta de destino.
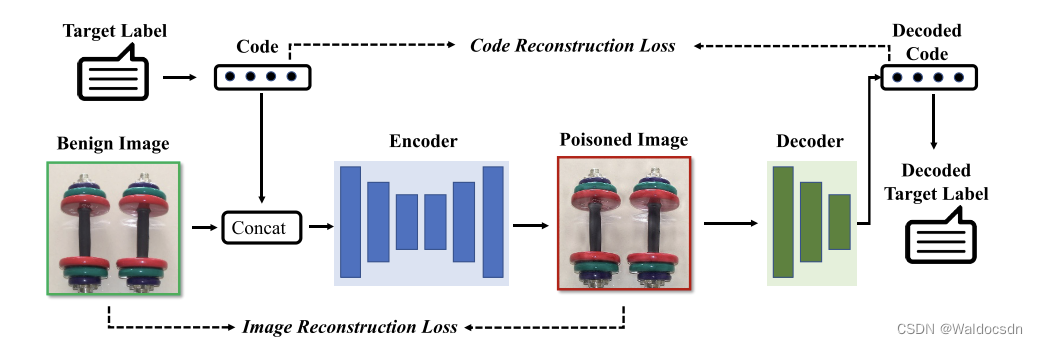
Figura 3. El proceso de entrenamiento de la red codificador-decodificador. El codificador y el decodificador se entrenan simultáneamente en un conjunto de entrenamiento benigno. Específicamente, el codificador está capacitado para incrustar cadenas en las imágenes mientras minimiza la diferencia de percepción entre la imagen de entrada y la imagen codificada, mientras que el decodificador está capacitado para recuperar mensajes ocultos de la imagen codificada.
Cómo generar disparadores específicos de muestra
Cómo generar disparadores específicos de muestra. Usamos una red de codificador-decodificador previamente entrenada como ejemplo para generar disparadores específicos de muestra, una idea inspirada en la esteganografía de imágenes basada en DNN [2, 51, 39]. Los disparadores generados son ruido aditivo invisible que contiene una cadena representativa de etiquetas de destino. Esta cadena puede ser diseñada de manera flexible por el atacante. Por ejemplo, podría ser el nombre de la etiqueta de destino, el índice o incluso un carácter aleatorio. Como se muestra en la Figura 2, el codificador recibe una imagen benigna y una cadena representativa para generar una imagen contaminada (es decir, una imagen benigna con los disparadores correspondientes). El codificador y el decodificador se entrenan simultáneamente en un conjunto de entrenamiento benigno. Específicamente, el codificador está capacitado para incrustar una cadena en una imagen mientras minimiza la diferencia perceptiva entre la imagen de entrada y la imagen codificada, mientras que el decodificador está capacitado para recuperar información oculta (aquí denominado disparador de puerta trasera) . Su proceso de formación se muestra en la Figura 3. Tenga en cuenta que los atacantes también pueden usar otros métodos, como VAE [17], para ataques de puerta trasera específicos de la muestra. Esto será investigado más a fondo en nuestro trabajo futuro.
Proceso de ataque de puerta trasera específico de la muestra
Proceso de ataque de puerta trasera específico de la muestra. Una vez que se genera el conjunto de entrenamiento contaminado D envenenado \mathcal{D}_{\text{poisoned}} basado en el método anteriorDenvenenado, que el atacante de puerta trasera enviará al usuario. Los usuarios lo usarán para entrenar DNN a través del proceso de entrenamiento estándar, es decir,
min w 1 N ∑ ( x , y ) ∈ D poisoned L ( f w ( x ) , y ) \min_{\boldsymbol{w}} \frac{1}{N} \sum_{(\boldsymbol{x}, y) \in \mathcal{D}_{\text{poisoned}}} \mathcal{L}\left(f_{\boldsymbol{w}}(\boldsymbol{x}), y\right) minwN1∑(x,y)∈DpoisonedL(fw(x),y) (2)
其中 L \mathcal{L} L 表示损失函数,如交叉熵。“优化”(2)可以通过反向传播 [33] 与随机梯度下降 [48] 来解决。在训练过程中,DNNs会学习从代表性字符串到目标标签的映射。 在推理阶段,攻击者可以通过基于编码器将触发器添加到图像中来激活隐藏的后门。
这是一个典型的机器学习优化问题的公式表示,具体来说,这是优化损失函数的表述。让我们分部分解析:
-
min w \min_{\boldsymbol{w}} minw:这部分表示我们的目标是最小化某个关于 w \boldsymbol{w} función de w (vector de peso). En el aprendizaje automático, generalmente deseamos encontrar un conjunto de parámetros (aquí pesosw \boldsymbol{w}w ) para minimizar la función de pérdida.
-
1 norte ∑ ( x , y ) ∈ D envenenado \frac{1}{N} \sum_{(\boldsymbol{x}, y) \in \mathcal{D}_{\text{envenenado}}}norte1∑( x , y ) ∈ reenvenenado: Esta parte es una operación de suma que atraviesa el conjunto de datos D envenenado \mathcal{D}_{\text{envenenado}}DenvenenadoTodas las muestras en . D envenenado \mathcal{D}_{\text{envenenado}}DenvenenadoRepresenta un conjunto de datos que ha sido envenenado. x \boldsymbol{x}x representa los datos de entrada,yyy representa la etiqueta correspondiente. 1 norte \frac{1}{N}norte1es la normalización del resultado de la suma, NNN suele ser el número total de muestras en el conjunto de datos, por lo que el valor de pérdida no depende del tamaño del conjunto de datos.
-
L ( fw ( x ) , y ) \mathcal{L}\left(f_{\boldsymbol{w}}(\boldsymbol{x}), y\right)L( fw( X ) ,y ) : Esta es la función de pérdida. fw ( x ) f_{\boldsymbol{w}}(\boldsymbol{x})Fw( x ) representa el modelo (el parámetro esw \boldsymbol{w}w ) para la entradax \boldsymbol{x}predicción de x ,L \mathcal{L}L es la función de pérdida que mide la predicción del modelo y la etiqueta objetivoyyLa diferencia entre y .
-
Etiqueta objetivo yyParte de y es la etiqueta objetivo establecida por el atacante y parte es la etiqueta real original.
Entonces, el significado de toda la expresión es: queremos encontrar un conjunto de pesos w \boldsymbol{w}w , tal que para el conjunto de datos manipuladoD envenenado \mathcal{D}_{\text{envenenado}}DenvenenadoPara todas las muestras en , la pérdida promedio entre las predicciones del modelo y las etiquetas objetivo es mínima.
5. Experimenta
5.1 Configuración del experimento
Conjuntos de datos y modelos
Conjuntos de datos y modelos. Consideramos dos tareas clásicas de clasificación de imágenes: (1) clasificación de objetos y (2) reconocimiento facial. Para la primera tarea, realizamos experimentos en el conjunto de datos de ImageNet [6]. Para simplificar, seleccionamos aleatoriamente un subconjunto de 200 categorías con 100 000 imágenes para entrenamiento (500 por categoría) y 10 000 imágenes para prueba (50 por categoría). El tamaño de la imagen es 3 × 224 × 224. Además, empleamos el conjunto de datos MS-Celeb-1M [10] para el reconocimiento facial. En el conjunto de datos original, hay aproximadamente 100 000 identidades, y cada identidad contiene una cantidad variable de imágenes, que van de 2 a 602. Para simplificar, seleccionamos las 100 principales identidades con la mayor cantidad de imágenes. Más concretamente, obtuvimos 100 identidades con un total de 38.000 imágenes (380 por identidad). La relación de división del conjunto de entrenamiento y el conjunto de prueba se establece en 8:2. Para todas las imágenes, primero realizamos la alineación de la cara, luego seleccionamos la cara central y finalmente la redimensionamos a 3×224×224. Usamos ResNet-18 [11] como estructura modelo para ambos conjuntos de datos. También llevamos a cabo más experimentos con VGG-16 [38] en el material complementario.

Punto de referencia experimental
Punto de referencia de comparación experimental . Comparamos el ataque de puerta trasera específico de la muestra propuesto con BadNets [8] y los ataques sigilosos típicos con estrategias mixtas (llamados ataques combinados) [3]. También proporcionamos modelos entrenados en conjuntos de datos benignos (llamados entrenamiento estándar) como otro punto de referencia de referencia. Además, seleccionamos Fine-Pruning [24], Neural Cleanse [41], SentiNet [5], STRIP [7], DF-TND [42] y Spectral Signatures [40] para evaluar la resistencia a la tecnología de punta. defensas


Figura 4. Muestras envenenadas generadas por diferentes ataques. BadNets y Blended Attack utilizan un cuadrado blanco con una cruz (el área en el cuadro rojo) como patrón de activación, mientras que nuestro activador de ataque es un ruido aditivo invisible específico de la muestra para toda la imagen.
ajustes de ataque
Ajustes de ataque. Establecemos la tasa de envenenamiento de todos los ataques en los dos conjuntos de datos γ = 10 % \gamma=10\%C=10 % y etiqueta objetivoyt = 0 y_{t}=0yt=0 _ Como se muestra en la Figura 4, para BadNets y Blended Attack, el activador de puerta trasera de la imagen envenenada es un20 × 20 20 \times 2020×20 cuadrados blancos, la opacidad de activación del ataque híbrido se establece en10 % 10\%10 % Los disparadores de nuestro método son generados por codificadores entrenados en un conjunto de entrenamiento benigno. Específicamente,seguimos la configuración de la red de codificador-decodificador en StegaStamp [39], donde usamos un DNN estilo U-Net [32] como codificador, una red de transformación espacial [15] como decodificador y usamos cuatro términos de pérdida están capacitados: L 2 L_{2}L2Regularización residual, pérdida perceptual LPIPS [47], una pérdida crítica para minimizar la distorsión perceptiva de las imágenes codificadas y una pérdida de entropía cruzada para la reconstrucción del código . Los factores de escala de los cuatro términos de pérdida se establecen en 2,0, 1,5, 0,5 y 1,5, respectivamente. Para el entrenamiento de todas las redes codificador-decodificador, usamos el optimizador Adam [16] y establecemos la tasa de aprendizaje inicial en 0.0001. El tamaño del lote y el número de iteraciones de entrenamiento se establecen en 16 y 140 000, respectivamente. Además, durante la fase de entrenamiento, utilizamos el optimizador SGD y establecemos la tasa de aprendizaje inicial en 0,001. El tamaño del lote y el período máximo se establecen en 128 y 30, respectivamente. Después de las épocas 15 y 20, la tasa de aprendizaje decae en un factor de 0,1.
Suplemento:
experimento de ataque
-
Muestras tóxicas: para cada conjunto de datos, configuramos las muestras venenosas para representar el 10 % de todas las muestras, y la etiqueta objetivo es yt = 0 y_{t}=0yt=0 ;
-
Disparador de producción: el disparador de BadNet y Blended Attack se encuentra en la esquina inferior derecha de la imagen y el tamaño es 20 × 20 20 \times 2020×20 , el disparador está dividido en 4 bloques por dos líneas perpendiculares entre sí:
- La diferencia entre el disparador de Blended Attack y BadNet es que BadNet agrega directamente el disparador a la esquina inferior derecha de la imagen, mientras que el disparador de Blended Attack se basa en un coeficiente de transparencia (establecido en 10 % 10 \% en el experimento10% ) y media ponderada de la imagen para obtener la imagen final con disparador;
- El disparador de SSBA (el método propuesto por el autor) es invisible a simple vista, es un conjunto de entrenamiento compuesto por muestras limpias y cadenas de etiquetas de clase objetivo para entrenar el codificador que genera el disparador [Nota: Toma directamente la imagen de StegaStamp Se utiliza el modelo esteganográfico, y el método detallado específico se puede leer en la literatura de StegaStamp];
-
Configuración de parámetros relevantes para entrenar el modelo implantado con la puerta trasera: se utiliza el optimizador SGD y la tasa de aprendizaje inicial es lr = 0.001 lr=0.001lr _=0.001 ,tamaño de lote = 128 tamaño de lote = 128TAMAÑO DEL LOTE _ _ _ _=128 , el número total de iteracionesmax E poch = 30 \max Epoch =30máximoÉpoca _ _=30 , la tasa de aprendizaje decae con un factor de atenuación de 0,1 después de las rondas 15 y 20
ajustes de defensa
** Configuración de defensa. ** Para Fine-Pruning , podamos la última capa convolucional (Layer4.conv2) de ResNet-18; para Neural Cleanse , adoptamos su configuración predeterminada y usamos el índice de anomalía generado para la demostración. Cuanto menor sea el valor del índice de anomalía, más difícil será la defensa contra el ataque; para STRIP , también adoptamos su configuración predeterminada y mostramos la puntuación de entropía generada. Cuanto mayor sea el puntaje, más difícil será la defensa contra el ataque; para SentiNet , comparamos el Grad-CAM generado [35] de muestras envenenadas para demostración; para DF-TND , informamos el aumento logit del puntaje antes y después del ataque adversario global para cada clase Esta defensa tiene éxito si la etiqueta de destino obtiene una puntuación significativamente más alta que todas las demás categorías. Para las firmas espectrales , informamos la puntuación atípica de cada muestra; cuanto mayor sea la puntuación, más probable es que la muestra esté envenenada.
Índice de evaluación
índice de evaluación. Usamos la tasa de éxito de ataques (ASR) y la precisión benigna (BA) para evaluar la efectividad de diferentes ataques. Específicamente, ASR se define como la relación entre las muestras envenenadas atacadas con éxito y el total de muestras envenenadas. BA se define como la precisión de las pruebas en muestras benignas. Además, empleamos la relación pico de señal a ruido (PSNR) [14] y ℓ ∞ \ell ^{\infty}ℓ∞ norma [12] para evaluar la ocultación.
En este pasaje se mencionan cuatro métricas de evaluación:
-
Tasa de éxito de ataque (ASR) : la relación entre el número de muestras de veneno atacadas con éxito y el número total de muestras de veneno. Cuanto mayor sea el indicador, mejor , porque indica la tasa de éxito del ataque. Si el ASR es alto, el método de ataque es más efectivo.
-
Precisión benigna (Precisión benigna, BA) : la tasa de precisión en muestras benignas. Cuanto mayor sea esta métrica, mejor , porque indica el rendimiento del modelo en muestras no atacadas. Si el BA es alto, significa que el modelo tiene un buen efecto de reconocimiento en muestras normales.
-
Relación señal-ruido máxima (PSNR) : un indicador utilizado para evaluar la ocultación, que indica el grado de diferencia entre la imagen original y la imagen después del ataque. Cuanto más alto sea el indicador, mejor, porque indica que el ataque está más encubierto. Un PSNR alto significa que la diferencia entre la imagen atacada y la imagen original es pequeña, y el ataque es más difícil de detectar.
-
Norma infinita ( ℓ ∞ \ell^{\infty}ℓ∞ norma): También se utiliza para evaluar la ocultación, denotando la máxima diferencia entre la imagen original y la imagen atacada. Cuanto más bajo seael indicador, mejor, porque indica mejor ocultación del ataque. La norma del infinito es pequeña, lo que indica que la diferencia máxima entre la imagen atacada y la imagen original es pequeña y el ataque es más difícil de detectar.
En general, estos cuatro indicadores se utilizan para evaluar la eficacia y el encubrimiento de los métodos de ataque. La efectividad se mide principalmente por ASR y BA, y la ocultación se mide principalmente por PSNR y norma infinita.
5.2 Principales resultados
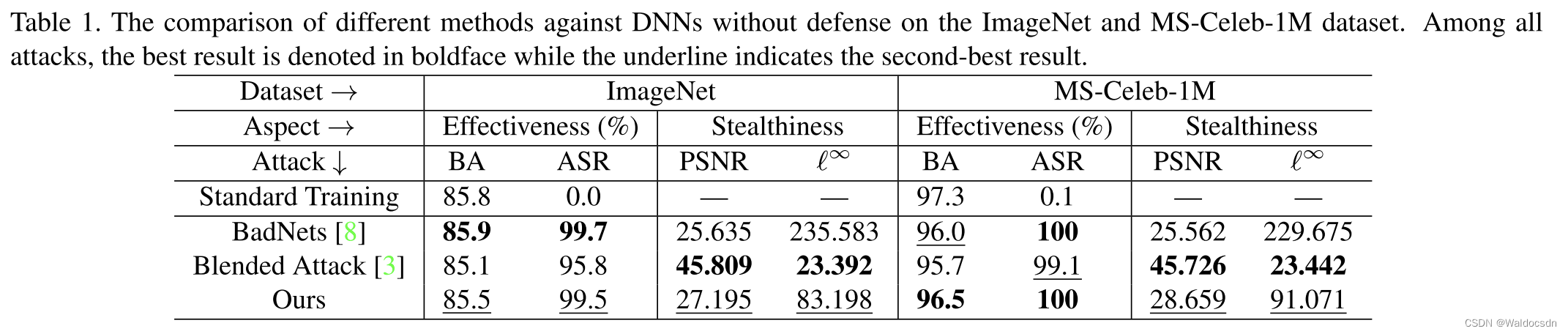
Tabla 1. Comparación de diferentes métodos en DNN no protegidos en conjuntos de datos ImageNet y MS-Celeb-1M. En todos los ataques, el mejor resultado está en negrita y el segundo mejor resultado está subrayado.
Precisión benigna (BA): cuanto más alta, mejor
Tasa de éxito de ataque (ASR): cuanto más alto, mejor
Relación pico de señal a ruido (PSNR): cuanto más alta, mejor
Norma infinita ( ℓ ∞ \ell^{\infty}ℓ∞ norma) - cuanto menor, mejor
eficacia del ataque. Como se muestra en la Tabla 1, nuestro ataque solo necesita envenenar una pequeña fracción (10 %) de las muestras de entrenamiento para crear con éxito una puerta trasera con ASR alto. Específicamente, nuestro ataque logra ASR> 99% en ambos conjuntos de datos. Además, la ASR de nuestro método es comparable a BadNets y superior a Blended Attack. Además, en comparación con el entrenamiento estándar, nuestro ataque reduce la precisión de las muestras de prueba benignas en menos del 1 % en ambos conjuntos de datos, que es menor que la reducción causada por BadNets y Blended Attack. Estos resultados sugieren que el ruido aditivo invisible específico de la muestra (cada muestra tiene su propio ruido específico que se agrega a la imagen original y que es imperceptible para el ojo humano) puede ser efectivo como detectores de activación, aunque son más complejos que el blanco. cuadrados utilizados en BadNets y Blended Attack.
Ataque sigiloso. La Figura 4 muestra algunas imágenes envenenadas generadas por diferentes ataques. Aunque nuestro ataque es sobre PSNR y ℓ ∞ \ell ^{\infty}ℓEl ocultamiento en términos de ∞ no es el mejor (el nuestro es el segundo mejor, como se muestra en la Tabla 1), pero las imágenes envenenadas generadas por nuestro método todavía se ven naturales cuando se inspeccionan manualmente. Aunque Blended Attack parece tener el mejor sigilo en términos de las métricas de evaluación empleadas, los desencadenantes en las muestras que generan siguen siendo bastante obvios, especialmente cuando el fondo está oscuro.
análisis de tiempo Se necesitan 7 horas y 35 minutos para entrenar la red de codificador-decodificador en ImageNet y 3 horas y 40 minutos en MS-Celeb1M. El tiempo medio de codificación es de 0,2 segundos por imagen.
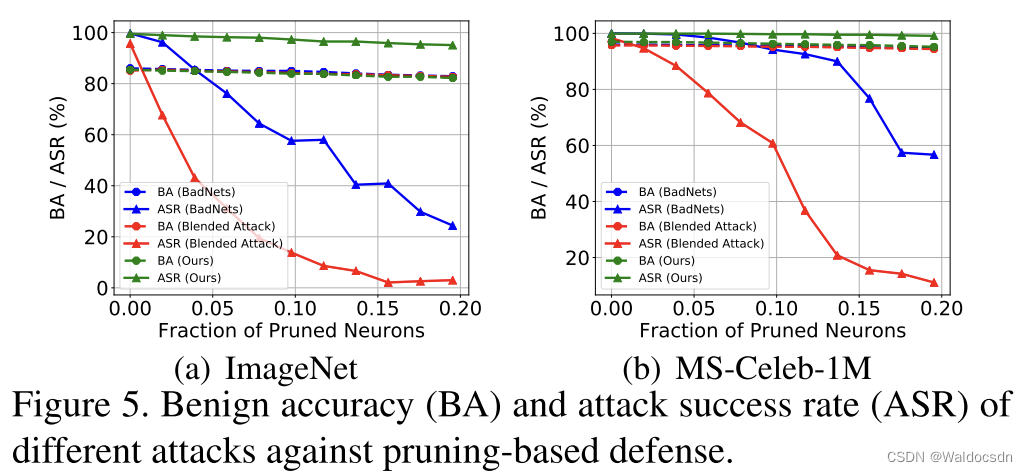
Figura 5. Precisión benigna (BA) y tasa de éxito de ataque (ASR) de defensas basadas en poda para diferentes ataques.
Anti-Poda Fina. En esta sección, comparamos el rendimiento de nuestro ataque con BadNets y Blended Attack frente a defensas basadas en poda [24]. Como se muestra en la Figura 5, al podar el 20% de las neuronas, el ASR de BadNets y Blended Attack cae significativamente. Especialmente para Blended Attack, su ASR en los conjuntos de datos ImageNet y MS-Celeb-1M se redujo a menos del 10 %. Por el contrario, la ASR de nuestro ataque cae solo ligeramente (menos del 5%) a medida que aumenta la proporción de neuronas podadas. Al podar el 20 % de las neuronas, nuestro ataque aún logra una ASR superior al 95 % en ambos conjuntos de datos. Esto demuestra que nuestro ataque es más resistente a las defensas basadas en poda.

Figura 6. Activadores sintéticos generados por Neural Cleanse. El cuadro rojo en la figura indica la región de activación real.
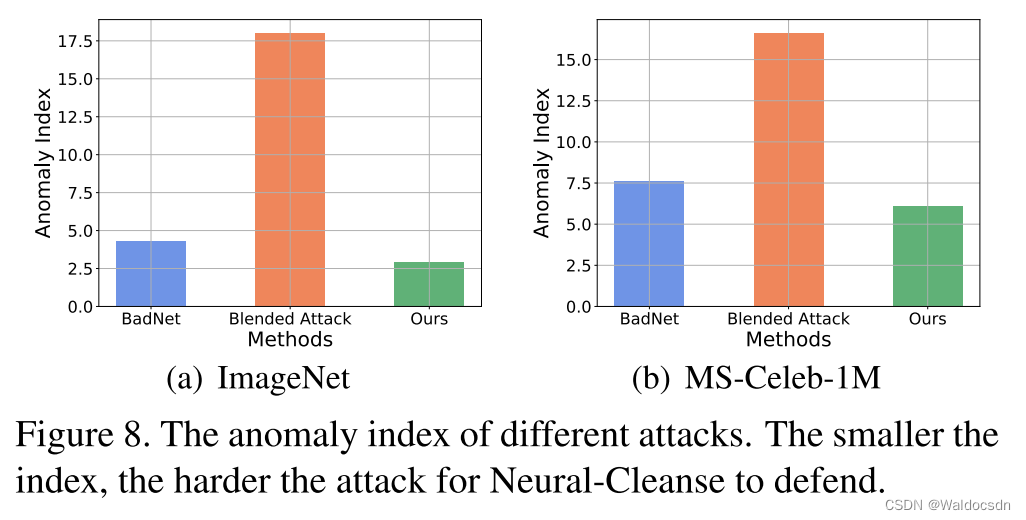
Figura 8. Índices de anomalía para diferentes ataques. Cuanto menor sea el índice, más difícil será para Neural-Cleanse defender.
Limpieza Anti-Neural. Neural Cleanse [41] calcula los candidatos desencadenantes para convertir todas las imágenes benignas a cada etiqueta. Luego emplea un detector de anomalías para verificar si alguien es significativamente más pequeño que otros como indicador de una puerta trasera. Cuanto menor sea el valor del índice de anomalía, más difícil será para Neural-Cleanse defenderse de los ataques. Como se muestra en la Figura 8, nuestro ataque es más resistente a Neural-Cleanse. Además, también visualizamos los disparadores sintéticos de diferentes ataques (es decir, el que tiene el índice de anomalía más pequeño entre todos los candidatos). Como se muestra en la Figura 6, los disparadores sintéticos de BadNets y Blended Attack contienen patrones similares a los que usan los atacantes (es decir, el cuadrado blanco en la esquina inferior derecha), mientras que los disparadores de nuestro ataque no tienen sentido.
Nota complementaria:
Neural Cleanse[41]是一种防御手段,它会尝试计算出触发器候选项,使得所有的正常(无害)图像都转换为每个类别的标签。接着,它会使用一种异常检测器来验证是否有某个触发器明显小于其他触发器,如果有,那么这就是一种后门攻击的指标。在这个背景下,异常指数值越小,那么就能更好地抵抗Neural Cleanse的防御。
如图8所示,作者的攻击方式对Neural Cleanse的防御具有更强的抵抗力。也就是说,作者的攻击方式更难被Neural Cleanse检测出。
此外,作者还可视化了不同攻击方式的合成触发器(即在所有候选触发器中,异常指数最小的那一个)。如图6所示,BadNets和Blended Attack的合成触发器包含了与攻击者使用的相似的模式(即,右下角的白色方块),而作者的攻击方式产生的合成触发器却没有任何明显的意义,这使得它更难被检测出。
简单来说,作者的攻击方式对于Neural Cleanse的防御手段具有更强的抵抗力,这是因为它产生的触发器更难被识别出。
这段话讨论了对抗“Neural Cleanse”防御技术的抵抗力。Neural Cleanse是一种防御机制,它计算所有不同标签的潜在触发器,并使用异常检测器来检查是否有任何一个触发器的大小明显小于其他的,这个小的触发器被看做是后门攻击的指标。这个异常指数的值越小,那么就能更好地抵抗Neural Cleanse的防御。
从图 8 中可以看出,作者的攻击方法更能抵抗 Neural Cleanse。此外,作者还可视化了不同攻击方法的合成触发器,即在所有可能触发器中,异常指数最小的那个。从图 6 可以看出,BadNets 和 Blended Attack 的合成触发器中包含了与攻击者使用的模式相似的元素(也就是右下角的白色方块),而作者的攻击方法生成的触发器看起来没有任何意义,也就是说,他们的触发器更难被理解和识别,这也使得他们的攻击更难被检测到。
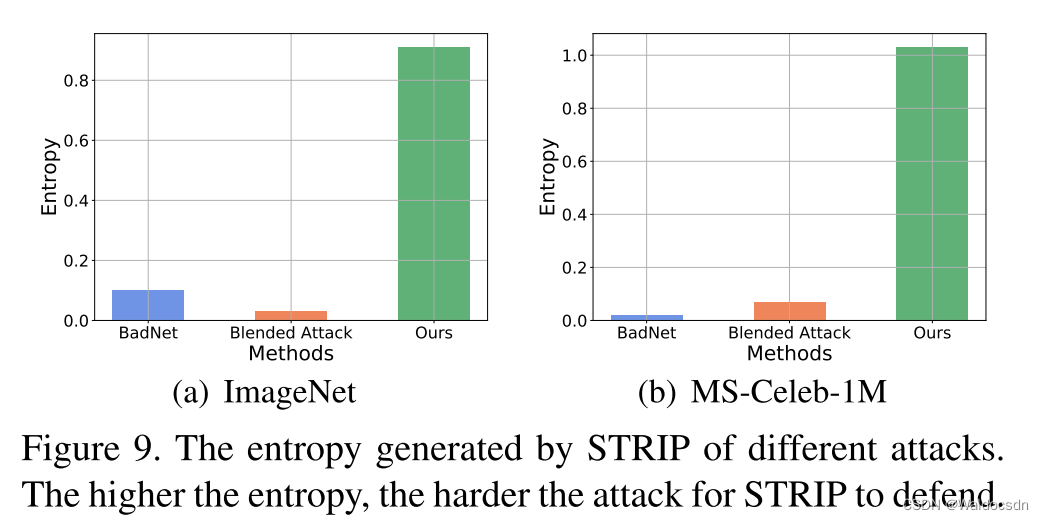
Figura 9. Entropía de diferentes ataques generados por STRIP. Cuanto mayor sea la entropía, más difícil será defenderse de STRIP.
Anti-TIRA. STRIP [7] filtra las muestras envenenadas en función de la aleatoriedad predicha de las muestras generadas al imponer varias modalidades de imagen en imágenes sospechosas. La aleatoriedad se mide por la entropía de las predicciones promedio de esas muestras. Por lo tanto, cuanto mayor sea la entropía, más difícil será para STRIP defenderse de los ataques. Como se muestra en la Figura 9, nuestro ataque es más resistente a STRIP que otros ataques.
Nota complementaria:
Otra traducción al chino de este pasaje es la siguiente:
Resistencia a STRIP. STRIP [7] es una defensa que filtra las muestras manipuladas basándose en la aleatoriedad predictiva de las muestras generadas al imponer varios patrones de imagen en imágenes sospechosas. Esta aleatoriedad se mide por la entropía de la predicción promedio de esas muestras. Por lo tanto, cuanto mayor sea la entropía, más difícil será defenderse de los ataques STRIP. Como se muestra en la Figura 9, nuestro ataque es más resistente a STRIP que otros ataques.
El análisis de este pasaje es el siguiente:
Este pasaje describe principalmente la superioridad del método de ataque del autor contra la defensa STRIP. STRIP es una defensa que filtra muestras manipuladas calculando la entropía de las predicciones de muestras generadas a partir de imágenes sospechosas. La entropía se utiliza aquí como una medida de la aleatoriedad. Cuanto mayor sea el valor de la entropía, más aleatorias serán las predicciones de la muestra generadas y más difícil será que STRIP las detecte. Por lo tanto, si un método de ataque puede generar alta entropía, puede resistir mejor la defensa de STRIP . En la Figura 9, los autores muestran que su ataque produce mayor entropía que otros ataques y, por lo tanto, es más resistente contra las defensas STRIP.
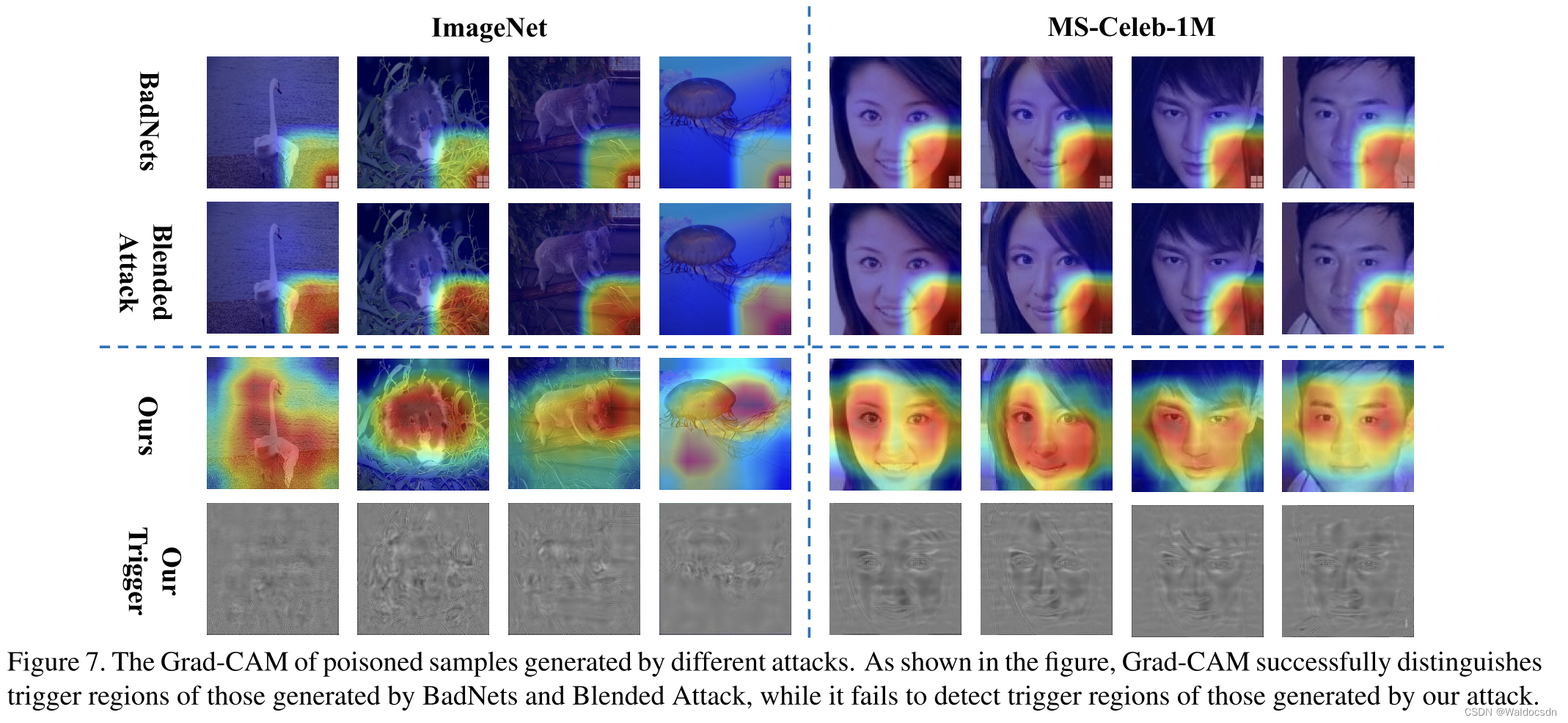
Figura 7. Grad-CAM de muestras envenenadas generadas por diferentes ataques. Como se muestra en la figura, Grad-CAM distingue con éxito las áreas de activación generadas por BadNets y Blended Attack, mientras que el área de activación generada por nuestro ataque (nuestro ataque, el método de ataque en este documento) no se puede detectar.
Anti-SentiNet. SentiNet [5] identifica las regiones desencadenantes en función de la similitud de Grad-CAM de diferentes muestras. Como se muestra en la Figura 7, Grad-CAM distingue con éxito las regiones de activación generadas por BadNets y Blended Attack, mientras que no puede detectar las regiones de activación generadas por nuestro ataque. En otras palabras, nuestro ataque (nuestro ataque, el método de ataque en este documento) es más resistente a SentiNet.
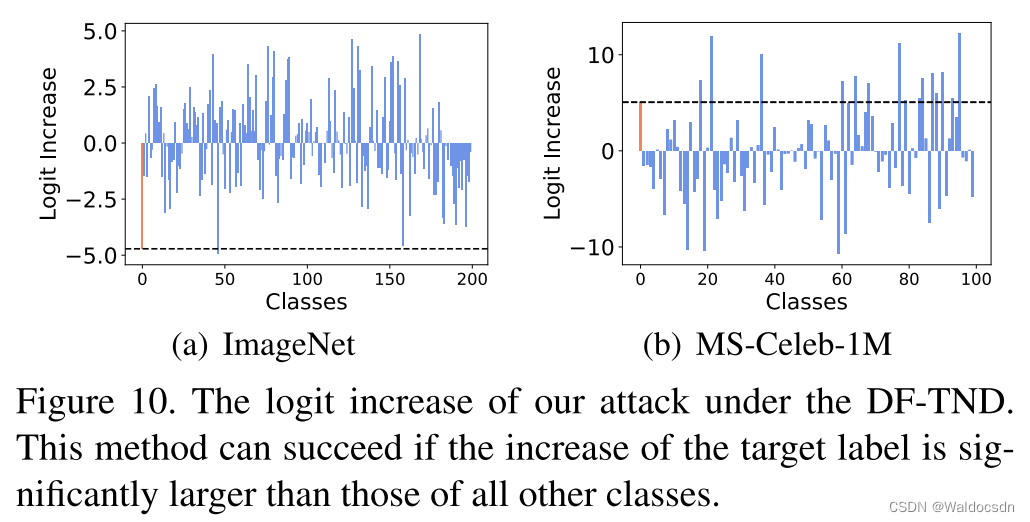
Figura 10. Incremento logit de nuestro ataque bajo DF-TND. Este enfoque puede tener éxito si el aumento en la etiqueta objetivo es significativamente mayor que el aumento en todas las demás clases.
Anti-DF-TND. DF-TND [42] detecta si un DNN sospechoso contiene una puerta trasera oculta mediante la observación del aumento logit de cada etiqueta antes y después de un ataque adversario general elaborado a mano. Este enfoque tendrá éxito si el aumento logit para la etiqueta de destino está únicamente en su punto máximo. Para una demostración justa, ajustamos sus hiperparámetros para encontrar la mejor configuración de defensa para nuestro ataque (consulte el Material complementario para obtener más detalles). Como se muestra en la Figura 10, el aumento logit para la categoría objetivo (barras rojas en la figura) no es máximo en ambos conjuntos de datos. Esto muestra que nuestro ataque también puede pasar por alto DF-TND.
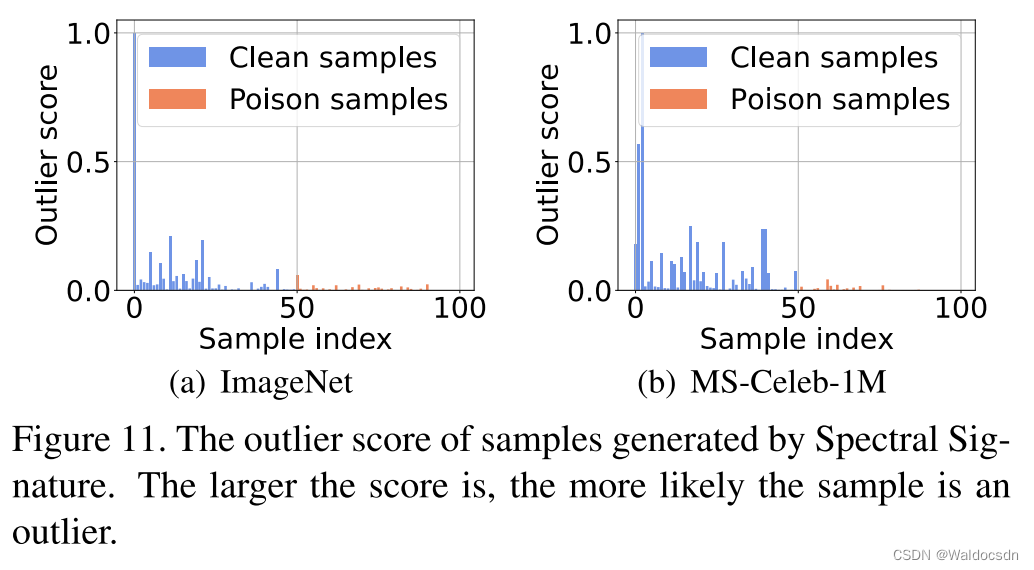
Figura 11. Puntuaciones de anomalías para muestras generadas por Spectral Signature. Cuanto mayor sea la puntuación, más probable es que la muestra sea una anomalía.
Firmas antiespectrales. Spectral Signatures [40] descubrió que los ataques de puerta trasera pueden dejar rastros detectables en el espectro de covarianzas de las representaciones de características. Dichos rastros se denominan firmas espectrales, que se detectan mediante la descomposición de valores singulares. Este método calcula una puntuación atípica para cada muestra. Tiene éxito si la muestra limpia tiene un valor pequeño y la muestra envenenada tiene un valor grande (consulte el material complementario para obtener más detalles). Como se muestra en la Figura 11, analizamos 100 muestras, entre las cuales 0 ~ 49 son muestras limpias y 50 ~ 100 son muestras envenenadas. Nuestro ataque perturba significativamente este enfoque, lo que lleva a puntajes inesperadamente altos para muestras limpias.
5.3 Discusión
攻击成功率 (Attack Success Rate, ASR) —— 越高越好
良性准确率 (Benign Accuracy, BA) —— 越高越好
峰值信噪比 (Peak Signal-to-Noise Ratio, PSNR) —— 越高越好
无穷范数 ( ℓ ∞ \ell^{\infty} ℓ∞ norm) —— 越低越好

表2注:之前实验中,作者设置的有毒样本的目标标签都是0。
在这一部分,除非另有说明,所有设置都与第5.1节中所述的设置相同。
不同目标标签的攻击。 我们用不同的目标标签 ( y t \boldsymbol{y}_{t} yt = 1, 2, 3) 测试我们的方法。表2显示了我们攻击的BA/ASR,揭示了我们方法在使用不同目标标签时的有效性。
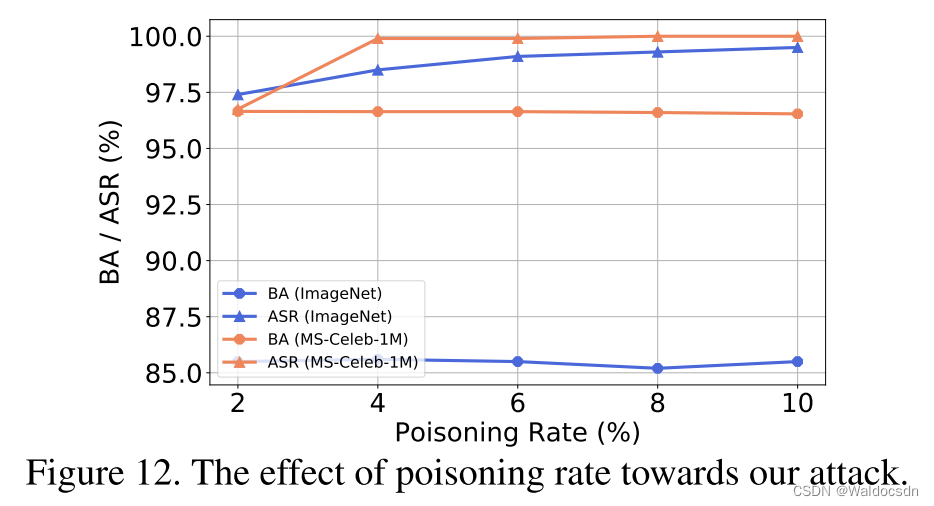
图12. 毒化率对我们的攻击的影响。
毒化率 γ \gamma γ 的影响。 在这部分,我们讨论了毒化率 γ \gamma γ 对我们攻击中ASR和BA的影响。如图12所示,通过只毒化2%的训练样本,我们的攻击在两个数据集上都达到了高ASR (> 95%)。此外,随着 γ \gamma γ 的增加,ASR会增加,而BA几乎保持不变。换句话说,在我们的方法中,ASR和BA之间几乎没有权衡。然而, γ \gamma γ的增加也会降低攻击的隐蔽性。攻击者需要根据自己的具体需求指定此参数。

Tabla 3: ASR (%) para "Nuestro ataque en este documento", utilizando disparadores consistentes (llamados "Nuestros") o disparadores inconsistentes (llamados "Nuestros (inconsistentes)"). Se generan disparadores inconsistentes basados en otra imagen de prueba. (Cuadro 3 directamente en inglés)
La Tabla 3 muestra la tasa de éxito del ataque (ASR) para dos casos desencadenantes diferentes. Estos dos disparadores son disparadores "coherentes" (coherentes) y disparadores "incoherentes" (incoherentes).
Un activador "coherente" significa que los activadores se generan en función de la misma imagen. Específicamente, si tenemos una imagen de prueba x \boldsymbol{x}x , usaremosun \boldsymbol{x} basado en xx activadores generados para pruebas de ataque.
Los disparadores "inconsistentes" se refieren a disparadores que se generan en función de diferentes imágenes. Específicamente, para cada imagen de prueba x \boldsymbol{x}x , seleccionamos al azar otra imagen de pruebax ′ \boldsymbol{x}'X′ , luego usamosel ′ \boldsymbol{x}' basado en xX' Activadores generados para pruebas de ataque.
En la Tabla 3, "Nuestro" representa el ataque que usa disparadores consistentes, y "Nuestro (inconsistente)" representa el ataque que usa disparadores inconsistentes.
Si la tasa de éxito del ataque cae significativamente cuando se usan disparadores inconsistentes, significa que el disparador generado por este método de ataque es muy específico de la imagen, es decir, solo es efectivo para la imagen específica que lo generó, pero no para otras imágenes o menos. eficaz.
Especificidad de los disparadores generados : en esta sección, exploramos si los disparadores generados específicos de la muestra son únicos, es decir, si una imagen de prueba que usa un disparador generado en base a otra imagen también puede activar las puertas traseras ocultas neuronales profundas a la web. Específicamente, para cada imagen de prueba x \boldsymbol{x}x , elegimos al azar otra imagen de pruebax ′ \boldsymbol{x}'X′(x ′ ≠ x \boldsymbol{x}' \neq \boldsymbol{x}X′=x ). Ahora, usamosx + T ( G ( x ′ ) ) \boldsymbol{x}+T\left(G\left(\boldsymbol{x}'\right)\right)X+T( G( X′ ))(en lugar dex + T ( G ( x ) ) \boldsymbol{x}+T(G(\boldsymbol{x}))X+T ( G ( x )) ) para consultar la red neuronal profunda atacada. Como se muestra en la Tabla 3, cuando se utilizan disparadores inconsistentes (es decir, disparadores generados en función de diferentes imágenes) en el conjunto de datos de ImageNet, el ASR cae drásticamente. Sin embargo, atacar con disparadores inconsistentes aún logra una ASR alta en el conjunto de datos MS-Celeb-1M. Esto puede deberse a que la mayoría de los rasgos faciales son similares, por lo que los desencadenantes aprendidos tienen una mejor generalización. Seguiremos explorando este interesante fenómeno en trabajos futuros.
解释1:
这段话的主要目标是探讨生成的样本特定触发器的专属性,也就是它们是否只对生成它们的图像有影响,对其他图像则无效或效果较差。在这个实验中,他们使用了从另一张图像中生成的“不一致”触发器对另一张图像进行攻击,看这样的攻击是否仍能成功。
表3中的结果表明,在ImageNet数据集上,使用这种“不一致”触发器的攻击成功率显著下降,这证明了生成的触发器对于其生成图像的特异性。然而,对于MS-Celeb-1M数据集(主要是人脸图像),即使使用“不一致”的触发器,攻击的成功率仍然很高。作者推测,这可能是因为大部分面部特征都很相似,所以学习的触发器具有更好的泛化能力。这个有趣的现象将在他们的未来工作中进一步探究。
解释2:
这段话中,作者们在尝试说明他们生成的样本特定触发器(每个图像都有自己的触发器)是否是独特的,也就是,一个触发器是否只对生成它的图像有效,对其他图像无效。他们这样做的方法是:对于每一张测试图像,他们随机选取另一张测试图像,并用这张图像的触发器去测试原图像。
在他们的实验中,他们发现在 ImageNet 数据集上,如果使用和原图像不一致的触发器进行测试,成功的攻击率(ASR)会大幅下降。这说明在这个数据集上,触发器是具有独特性的,也就是说,一个触发器只对生成它的那张图像有效。
然而,他们在 MS-Celeb-1M 数据集(一个人脸数据集)上进行同样的测试时,发现即使使用和原图像不一致的触发器,成功的攻击率仍然很高。他们猜测这可能是因为在这个人脸数据集中,大多数的面部特征都是相似的,所以触发器可能对多个图像都有效。
这个现象在未来的工作中值得进一步探索。因为如果触发器的独特性可以得到保证,那么攻击者就无法通过其他图像的触发器来激活原图像的后门,从而提高了系统的安全性。
解释3:
这段文字主要是在探讨攻击中生成的样本特定触发器的特性。这里的触发器是用于激活神经网络隐藏后门的信号。
El concepto de "exclusividad" se refiere a si estos disparadores solo son válidos para las muestras específicas que los generaron, en otras palabras, si los disparadores generados en base a una muestra pueden ser igualmente válidos para otras muestras.
El experimento que realizaron fue el siguiente: para cada imagen de prueba x \boldsymbol{x}x , eligen aleatoriamente otra imagen de pruebax ′ \boldsymbol{x}'X′(x ′ ≠ x \boldsymbol{x}' \neq \boldsymbol{x}X′=x ). Luego, usanx + T ( G ( x ′ ) ) \boldsymbol{x}+T\left(G\left(\boldsymbol{x}'\right)\right)X+T( G( X′ ))para consultar la red neuronal bajo ataque, es decir, usanx ′ \boldsymbol{x}'X′ dispara para intentar activarx \boldsymbol{x}Puerta trasera oculta en x .
Los resultados experimentales encontraron que en el conjunto de datos de ImageNet, al usar este "disparador inconsistente" generado en base a otras imágenes, la tasa de éxito de ataque (ASR) se redujo significativamente. Esto muestra que en el conjunto de datos de ImageNet, los disparadores generados por muestras específicas son significativamente menos efectivos en otras muestras, es decir, los disparadores tienen una alta singularidad.
Sin embargo, incluso con este disparador inconsistente, la tasa de éxito del ataque sigue siendo alta en el conjunto de datos MS-Celeb-1M. Esto puede deberse a que este conjunto de datos contiene principalmente imágenes de rostros, y las características faciales en las imágenes de rostros son relativamente similares, por lo que los activadores generados en función de una muestra también tienen un mejor efecto en otras muestras. Esto sugiere que los disparadores son menos únicos en este conjunto de datos. Los autores indican que explorarán más a fondo este fenómeno en trabajos futuros.
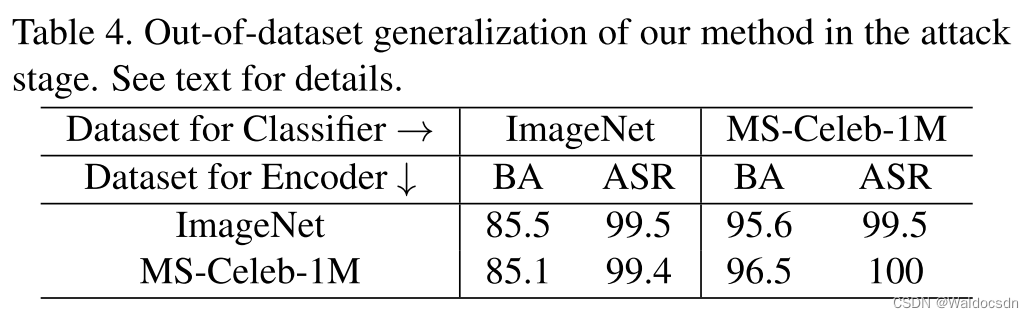
Tabla 4: Generalización fuera del conjunto de datos de nuestro método durante la fase de ataque. Ver texto para más detalles.
Generalización fuera del conjunto de datos durante la fase de ataque: recuerde que en experimentos anteriores, el codificador se entrenó en una versión benigna del conjunto de entrenamiento contaminado. En esta sección, exploramos si, en nuestro ataque, un codificador entrenado en otro conjunto de datos (sin ningún ajuste fino) aún se puede adaptar para generar muestras contaminadas del nuevo conjunto de datos. Como se muestra en la Tabla 4, un codificador entrenado en otro conjunto de datos es tan efectivo para atacar como un codificador entrenado en el mismo conjunto de datos. En otras palabras, un atacante puede reutilizar un codificador ya entrenado para generar muestras contaminadas si las imágenes son del mismo tamaño. Esta característica reducirá significativamente el costo computacional de nuestro ataque.
Explicación 1:
Este pasaje habla de la "generalización fuera del conjunto de datos" en la fase de ataque, es decir, si un codificador entrenado en un conjunto de datos específico puede usarse para generar muestras tóxicas en otro conjunto de datos completamente diferente. En sus experimentos, descubrieron que incluso un codificador entrenado en un conjunto de datos diferente era tan eficaz para realizar ataques como un codificador entrenado en el mismo conjunto de datos.
Este es un hallazgo importante, porque significa que un atacante puede reutilizar codificadores ya entrenados para generar muestras tóxicas, siempre que las imágenes de estas muestras sean del mismo tamaño. Esto reduce en gran medida el cálculo que debe realizar un atacante, ya que ya no necesita entrenar un nuevo codificador desde cero para cada nuevo conjunto de datos de destino. Esta característica mejora la eficiencia y la escalabilidad de este ataque.
Explicación 2:
En los modelos de aprendizaje profundo, la generalización fuera del conjunto de datos es un concepto importante, que describe el rendimiento del modelo en datos distintos al conjunto de datos de entrenamiento. Una buena generalización fuera del conjunto de datos significa que el modelo puede adaptarse bien y manejar datos que nunca ha visto durante la fase de entrenamiento.
En este artículo, los autores investigan si su algoritmo de ataque tiene la capacidad de generalizar fuera del conjunto de datos. Específicamente, se preguntaron si un codificador entrenado en un conjunto de datos podría usarse para generar muestras tóxicas de un conjunto de datos diferente. Esto es lo que llaman "generalización fuera del conjunto de datos durante la fase de ataque".
Para probar esto, realizaron experimentos y descubrieron que un codificador entrenado en un conjunto de datos podría generar muestras tóxicas de otro conjunto de datos con un rendimiento comparable al de un codificador entrenado en el mismo conjunto de datos. En otras palabras, este codificador puede manejar y generar muestras tóxicas en datos que nunca ha visto durante la fase de entrenamiento, mostrando una buena generalización fuera del conjunto de datos.
Este hallazgo es muy beneficioso para los atacantes, ya que pueden reutilizar codificadores ya entrenados para atacar diferentes conjuntos de datos. Esto elimina la necesidad de entrenar un nuevo codificador desde cero para cada nuevo conjunto de datos de destino, lo que ahorra mucho tiempo y costos computacionales.
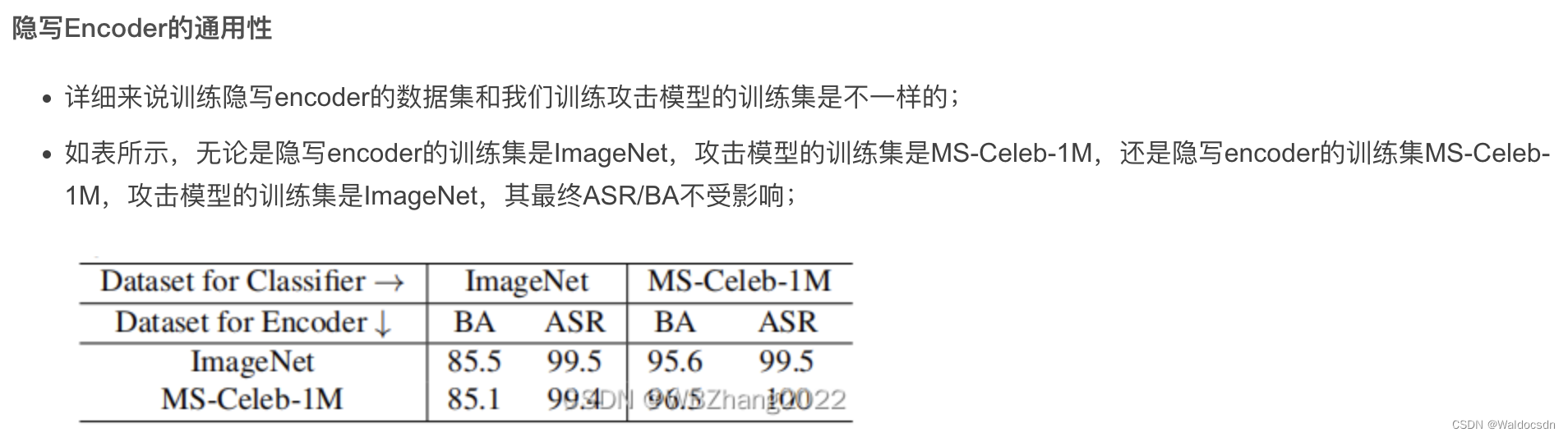

Tabla 5. ASR (%) de nuestro método atacado por muestras de prueba fuera del conjunto de datos. Ver texto para más detalles.
Generalización fuera del conjunto de datos en la fase de inferencia. En esta sección, verificamos si las imágenes fuera del conjunto de datos (con disparadores) pueden atacar con éxito los DNN atacados por nuestro método. Seleccionamos el conjunto de datos COCO de Microsoft [23] y un conjunto de datos de ruido sintético para los experimentos. Representan imágenes naturales y sintéticas, respectivamente. Específicamente, seleccionamos aleatoriamente 1000 imágenes de Microsoft COCO y generamos 1000 imágenes sintéticas, cada valor de píxel se seleccionó aleatoriamente de manera uniforme de {0, 255}. Todas las imágenes seleccionadas se redimensionan a 3 x 224 x 224. Como se muestra en la Tabla 5, nuestro ataque también puede lograr casi el 100 % de ASR para muestras envenenadas generadas a partir de imágenes fuera del conjunto de datos. Esto muestra que los atacantes pueden usar imágenes fuera del conjunto de datos (no necesariamente imágenes de prueba) para activar puertas traseras ocultas en los DNN atacados.
Explicación 1:
En esta sección, los autores verifican aún más la generalización de su método de ataque. Querían ver si podían atacar con éxito las redes neuronales profundas que ya habían sido atacadas por su método con imágenes que no estaban en los conjuntos de entrenamiento y prueba (llamadas imágenes fuera del conjunto de datos). Es decir, querían ver si las imágenes fuera de estos conjuntos de datos (que, por supuesto, tendrían disparadores agregados) activan con éxito las puertas traseras ya integradas en la red.
Los resultados experimentales muestran que este método de ataque basado en imágenes fuera del conjunto de datos puede lograr una tasa de éxito de ataque cercana al 100%. Esto ilustra que los atacantes no necesariamente necesitan usar imágenes vistas durante las fases de entrenamiento y prueba para activar la puerta trasera, también pueden usar imágenes que no están en estos conjuntos de datos para activar con éxito la puerta trasera. Esto aumenta aún más la flexibilidad y la generalidad de sus métodos de ataque.
Explicación 2:
表格5是关于该研究中测试的一种特殊情况的数据。具体来说,研究者们在这个实验中试图了解他们的攻击方法是否能够成功地在"数据集外"的图像上施加影响。
"数据集外"指的是那些在训练或测试过程中没有用过的图像。换句话说,这些是模型从未见过的图像。为了测试这一点,研究者们从Microsoft COCO数据集中随机选取了1,000张图像,此外,他们还生成了1,000张由随机像素值组成的合成图像。
研究者们的目标是看看他们能否使用这些数据集外的图像成功地攻击他们已经修改过的深度神经网络。他们的攻击主要通过在图像中插入某种模式或"触发器"来实现,这种模式会导致网络做出特定的预测。
实验结果显示,即使是这些数据集外的图像,只要添加了适当的触发器,也能够成功地触发网络中的后门,使其产生预期的预测结果。这种能力意味着这种攻击方法具有很高的泛化性,因为它不仅可以对在训练和测试过程中使用过的图像进行攻击,而且还可以对网络从未见过的图像进行攻击。
这一部分的内容是关于在推理阶段(模型已经训练完成,用于实际预测)进行数据集外泛化的实验。让我们来解释一下。
在深度神经网络被训练好以后,它将被用于新的、未见过的数据,这就是所谓的推理阶段。在这个阶段,网络的性能会受到新数据的质量和与训练数据的相似性的影响。特别是当这些新的测试数据来自于一个与训练数据集不同的数据集(即数据集外的数据)时,可能会影响网络的性能。
在这篇论文中,作者想要测试他们的攻击方法是否可以有效地在数据集外的数据上触发已经被植入的后门。为了实验,他们选择了来自于Microsoft COCO数据集的自然图像和一组合成的噪声图像,来作为数据集外的测试数据。他们随机选择了1000张来自Microsoft COCO数据集的图像,并生成了1000张噪声图像,这些图像的每个像素值都是在集合 { 0 , ⋯ , 255 } \{0, \cdots, 255\} { 0 ,⋯,255 } seleccionados uniformemente al azar. Todas las imágenes seleccionadas se redimensionan a3 × 224 × 224 3 \times 224 \times 2243×224×224 de tamaño.
Los resultados se muestran en la Tabla 5. Los autores descubrieron que su método de ataque también puede lograr una tasa de éxito de ataque (ASR) de casi el 100 % en muestras tóxicas generadas a partir de imágenes fuera del conjunto de datos. Esto demuestra que los atacantes pueden activar con éxito puertas traseras ocultas en redes neuronales profundas atacadas utilizando imágenes de fuera del conjunto de datos, que no necesariamente tienen que ser imágenes de prueba.
En otras palabras, esto significa que incluso si un atacante no tiene acceso directo a las imágenes utilizadas para la prueba, aún puede activar con éxito la puerta trasera implantada utilizando imágenes de otras fuentes, como el conjunto de datos COCO de Microsoft o imágenes de ruido sintético. Este es un hallazgo importante porque amplía aún más el rango de imágenes que un atacante puede usar y muestra la flexibilidad y las capacidades de generalización de este método de ataque.
6. Conclusión
En este documento, mostramos que la mayoría de los ataques de puerta trasera existentes pueden mitigarse fácilmente con las defensas de puerta trasera actuales, principalmente porque sus disparadores de puerta trasera son independientes de la muestra, es decir, diferentes muestras envenenadas contienen el mismo disparador. Basándonos en este entendimiento, exploramos un nuevo modo de ataque, el ataque de puerta trasera específico de la muestra (SSBA), donde el disparador de la puerta trasera es específico para la muestra. Nuestro ataque rompe los supuestos fundamentales de las defensas para que puedan pasarse por alto. Específicamente, generamos ruido adicional invisible específico de la muestra como disparadores de puerta trasera mediante la codificación de cadenas especificadas por el atacante en imágenes benignas, inspiradas en la esteganografía de imágenes basada en DNN. Cuando los DNN se entrenan en conjuntos de datos envenenados, se aprende la asignación de cadenas a etiquetas de destino. Llevamos a cabo extensos experimentos para verificar la efectividad de nuestro enfoque para atacar tanto modelos defendidos como no defendidos.
致谢。Yuezun Li的研究部分受到中国博士后科学基金会资助,项目编号为2021TQ0314。Baoyuan Wu受到中国自然科学基金的支持,项目编号为62076213,中国香港大学深圳分校的大学发展基金的支持,项目编号为01001810,深圳大数据研究院特别项目基金的支持,项目编号为T00120210003,以及深圳科技计划的支持,项目编号为GXWD2020123110572200220200901175001001。Siwei Lyu受到自然科学基金的支持,项目编号为IIS-2103450和IIS-1816227。
论文解析
重要参考文章
论文笔记(精读文章) - Invisible Backdoor Attack with Sample-Specific Triggers
独立同分布
“独立同分布样本"是一个常用的统计术语,通常简写为"i.i.d.”,其中 “i.i.d.” 是 “independent and identically distributed” 的缩写。
这个术语的含义可以分为两部分:
-
“独立(independent)”:这意味着每一个样本的出现不依赖于其他样本的出现。换句话说,获取一个样本的结果并不会影响或改变获取下一个样本的结果。
-
“同分布(identically distributed)”:这意味着所有样本都来自同一概率分布。换句话说,所有样本的来源或生成方式是相同的,它们具有相同的概率特性。
例如,如果你从一副扑克牌中随机抽出一张牌,然后放回,再随机抽出一张,这样的过程重复多次,那么每次抽出的牌就是独立同分布的。每次抽牌是独立的,因为每次抽牌并不受前一次抽牌的影响(前提是你每次都将牌放回),而且每次抽牌都来自同一副牌,因此它们是同分布的。
说说几种神经网络防御方法:Fine-Pruning、Neural Cleanse、STRIP、SentiNet、DF-TND、Spectral Signatures
-
Fine-Pruning : este es un método de defensa contra los ataques de puerta trasera. La idea central de Fine-Pruning es que, dado que los ataques de puerta trasera generalmente dejan ciertos rastros en los parámetros del modelo, estos rastros pueden eliminarse de manera efectiva mediante una poda fina del modelo, eliminando así la puerta trasera. Durante el proceso de poda, los parámetros se clasifican según su importancia y los parámetros con menor importancia se eliminan primero, por lo que el posible efecto de ataque de puerta trasera tiene una mayor probabilidad de eliminación.
-
Neural Cleanse : Neural Cleanse es una forma de detectar si un modelo tiene una puerta trasera. La forma en que funciona es mediante ingeniería inversa para encontrar el flip-flop más pequeño en la salida. En teoría, un modelo no comprometido debería requerir grandes cambios para alterar las predicciones, mientras que un modelo de puerta trasera podría requerir solo activadores menores. Al comparar el tamaño de este desencadenante mínimo, es posible evaluar si es probable que el modelo sea de puerta trasera.
-
STRIP (Stochastic Resampling for Input Perturbation) : STRIP es una estrategia para defenderse de los ataques adversarios, cuyo objetivo es interrumpir el efecto de los ataques adversarios durante la fase de inferencia. Este enfoque agrega ruido adicional al volver a muestrear aleatoriamente la entrada para interferir con la efectividad de los ataques adversarios. Debido a que los ataques adversarios generalmente requieren un control preciso sobre cada píxel de la entrada, estos ataques pueden defenderse de manera efectiva al introducir ruido aleatorio.
-
SentiNet : SentiNet es un método de defensa adversario que utiliza una máscara especial llamada "Máscara SentiNet" a través de la cual se pueden detectar los ataques adversarios y la salida del modelo se puede ajustar según la situación. Además, SentiNet utiliza la información de gradiente de la red neuronal para ayudar a detectar ataques adversarios.
-
DF-TND (DeepFense by Tractable Nonlinear Defense):DF-TND 是一种防御深度学习攻击的策略,其主要思想是通过对模型的前向传播过程引入一种可处理的非线性防御机制。这种防御机制可以让模型对输入的轻微改变表现出更强的稳健性,从而对抗攻击。
-
Spectral Signatures: Spectral Signatures 是一种基于模型的谱分析进行防御的策略。它利用了模型权重在频谱空间中的特性来检测可能存在的对抗性攻击。在理论上,正常训练的模型与受到对抗性攻击的模型在频谱空间中的表现应该有所不同,因此可以利用这个特性进行防御。
以上这些方法各有优点和缺点,对于不同类型和强度的攻击,其效果可能会有所不同。在实际应用中,可能需要结合多种方法来达到最佳的防御效果。
再解释下Neural Cleanse
Neural Cleanse是一种检测和缓解神经网络后门攻击的方法。后门攻击是指在模型训练过程中,攻击者将一些带有特殊模式(即触发器)的恶意样本注入到训练集中。然后,当这个模型在部署时遇到含有同样触发器的样本,它将产生攻击者期望的输出,而不是正确的输出。这种攻击对于模型的使用者来说是难以察觉的,因为除非输入中包含触发器,否则模型的行为看起来是正常的。
Neural Cleanse的目标是检测并消除这种后门攻击。它使用了一种反向工程的方法,通过修改模型的输入,观察输出的变化,来寻找可能的后门触发器。在理论上,如果模型未受到攻击,那么改变输入的一小部分不应该导致输出的显著变化。相反,如果模型受到了后门攻击,那么在输入中加入后门触发器就可能引起输出的显著变化。
Específicamente, Neural Cleanse primero encuentra un disparador mínimo para cada categoría de salida del modelo, es decir, el grado mínimo para cambiar la entrada para hacer que la salida del modelo cambie de otras categorías a esta categoría. Luego, compare los tamaños de las chancletas más pequeñas para todas las clases. Si el activador mínimo para una de las categorías es significativamente más pequeño que el de las otras, entonces existe la posibilidad de que esta categoría sea de puerta trasera.
Si se detecta un ataque de puerta trasera, Neural Cleanse también puede usar un algoritmo de reparación para eliminar la puerta trasera. El algoritmo funciona tomando el activador de puerta trasera identificado como un patrón de mal comportamiento y luego reparando el modelo obligándolo a ignorar el patrón. Aunque este método no puede eliminar por completo la puerta trasera, ha demostrado su eficacia en la práctica.
En general, Neural Cleanse es un método de detección y mitigación de ataques de puerta trasera mediante ingeniería inversa, que aprovecha los rastros que inevitablemente dejarán los ataques de puerta trasera, es decir, la característica de que el modelo es demasiado sensible a un pequeño disparador.
Acerca de la tira
Los resultados experimentales en el documento.
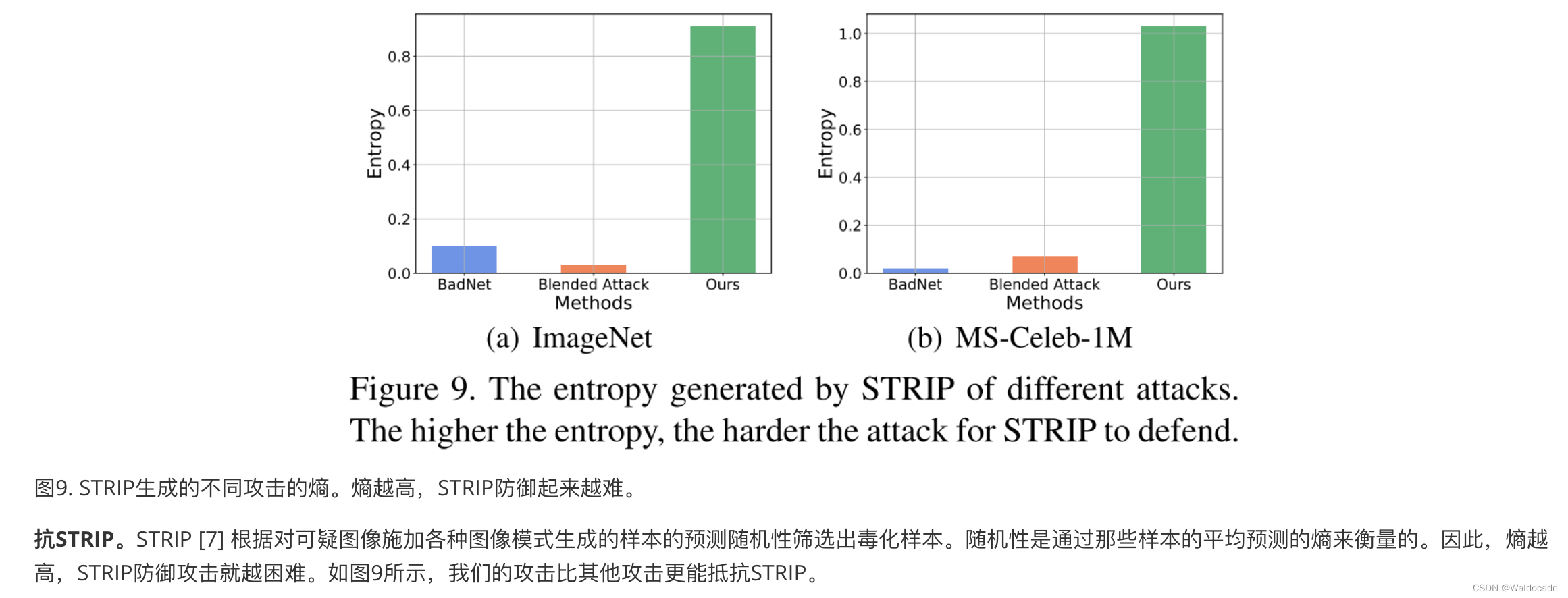
Explicar el método de defensa de redes neuronales STRIP
STRIP (Poda de activación estocástica) es un método para defenderse contra los ataques de puerta trasera de la red neuronal. Este enfoque fue propuesto en un artículo de 2019 por Gao et al. La idea central de STRIP es que si una imagen contiene un disparador de puerta trasera, ese disparador hará que el modelo produzca el mismo resultado previsto sin importar qué ruido aleatorio se agregue al resto de la imagen. STRIP aprovecha esta observación al superponer diferentes patrones de imagen en imágenes sospechosas y luego ver si las predicciones del modelo son aleatorias.
Específicamente, el proceso de operación del algoritmo STRIP es el siguiente:
-
STRIP primero selecciona un conjunto aleatorio de imágenes, llamadas imágenes enmascaradas.
-
Luego, STRIP superpone estas imágenes enmascaradas sobre las imágenes sospechosas que se van a detectar, formando una serie de imágenes híbridas.
-
STRIP introduce cada imagen combinada en el modelo y obtiene las predicciones del modelo.
-
Si los resultados de la predicción muestran un alto grado de consistencia, es decir, la clase predicha no cambia, entonces STRIP considerará que esta imagen sospechosa contiene un disparador de puerta trasera, porque indica que el disparador está obligando al modelo a generar el mismo resultado independientemente de cómo otras partes del cambio de imagen mixta resultado del pronóstico.
-
Si los resultados de la predicción muestran una gran aleatoriedad, es decir, hay un gran cambio en la categoría predicha, entonces STRIP pensará que esta imagen no contiene un disparador de puerta trasera.
De esta forma, STRIP puede identificar y filtrar eficazmente muestras maliciosas que contienen activadores de puerta trasera, evitando así el comportamiento anormal del modelo bajo ataques de puerta trasera.
Hablar de STRIP y entropía
STRIP (Poda de activación estocástica) funciona utilizando el concepto de entropía. La entropía se utiliza en la teoría de la información para cuantificar la incertidumbre o la aleatoriedad de la información.
En STRIP, cuando una imagen de enmascaramiento se superpone a una imagen sospechosa para generar una serie de imágenes combinadas, estas imágenes combinadas se introducen en el modelo y producen predicciones. Si estas predicciones tienen un alto grado de concordancia, esto significa que la entropía de las predicciones es baja. Esto se debe a que una entropía baja indica una incertidumbre baja en el resultado, es decir, el resultado tiende a ser consistente. En este caso, STRIP determina que la imagen sospechosa original contiene un disparador de puerta trasera porque el disparador obliga al modelo a generar la misma predicción independientemente de los cambios en otras partes de la imagen combinada.
Por el contrario, si los resultados de la predicción tienen una gran aleatoriedad, esto significa que la entropía de los resultados de la predicción es alta. Una entropía alta indica una incertidumbre alta del resultado, es decir, el resultado tiende a ser inconsistente. En este caso, STRIP determina que la imagen sospechosa original no contiene un activador de puerta trasera.
Por lo tanto, se puede decir que el método STRIP es para identificar y filtrar imágenes maliciosas que contienen activadores de puertas traseras midiendo la entropía de los resultados previstos. Este método aprovecha la coerción del activador de puerta trasera en los resultados de predicción del modelo, es decir, el activador de puerta trasera hará que el modelo produzca un resultado de predicción fijo para la imagen que lo contiene, independientemente de cómo cambien otras partes de la imagen.
¿Qué significa entropía (entropía) de diferentes tamaños?
La entropía es un concepto ampliamente utilizado en la teoría de la información para medir la incertidumbre o la aleatoriedad de la información. La entropía puede tener diferentes significados e interpretaciones en contextos específicos. Sin embargo, para todos los casos, los valores de entropía más grandes generalmente indican mayor incertidumbre, mientras que los valores de entropía más pequeños indican menos incertidumbre.
Por ejemplo, en el aprendizaje automático, la entropía se usa a menudo para medir la impureza de un conjunto de datos. En este caso, si todas las muestras de un conjunto de datos pertenecen a la misma clase, el valor de entropía es 0, lo que indica que no hay incertidumbre. Si las muestras se distribuyen uniformemente en todas las clases, el valor de entropía se maximiza, lo que indica la mayor incertidumbre.
STRIP utiliza el concepto de entropía para medir la incertidumbre en la salida de un modelo de red neuronal. El propósito de calcular el valor de entropía en la salida del modelo es determinar si existe un posible ataque de puerta trasera. Si el modelo no tiene una puerta trasera, luego de agregar la perturbación aleatoria, la salida del modelo debería tener una cierta distribución entre todas las clases posibles, por lo que el valor de la entropía será alto. Sin embargo, si el modelo tiene una puerta trasera, incluso después de que se agreguen perturbaciones aleatorias, la salida del modelo tenderá a ser forzada a una cierta clase específica por el activador y, por lo tanto, la salida tendrá una entropía más baja.
Entonces, en este caso, una puntuación de entropía más alta indica que el modelo no es (o es más vulnerable a) un ataque de puerta trasera, mientras que una puntuación de entropía más pequeña indica que el modelo puede haber sido atacado por la puerta trasera. Esto se debe a que el objetivo del ataque de puerta trasera es hacer que el modelo produzca siempre la misma predicción cuando encuentra un cierto desencadenante, lo que reducirá la entropía de la salida. Por lo tanto, la estrategia de defensa de STRIP es encontrar aquellas imágenes que aún mantienen una salida de baja entropía después de agregar perturbaciones aleatorias, ya que es probable que contengan disparadores de puerta trasera.
algún código real
Un pequeño ejemplo de cómo incrustar una puerta trasera en los datos de entrenamiento
el código
El objetivo principal de este código es demostrar cómo hacer una puerta trasera a los datos de entrenamiento de un modelo de red neuronal. El conjunto de datos que utilizamos es MNIST, que es un conjunto de datos de reconocimiento de dígitos escritos a mano de uso común, que contiene diez categorías de imágenes de dígitos escritos a mano del 0 al 9.
Aquí están los pasos detallados del código:
Primero, cargue el conjunto de datos MNIST usando el método mnist.load_data() de Keras. Esto devolverá dos tuplas, una para el conjunto de entrenamiento (x_train, y_train) y otra para el conjunto de prueba (x_test, y_test).
Luego, creamos un disparador, que es un cuadrado blanco de 5x5, y establecemos todos los valores de píxeles en 255 (que indica blanco).
Agregue este disparador a las primeras 1000 muestras del conjunto de entrenamiento. Establecemos la región inferior derecha de 5x5 de cada muestra como disparador, y luego establecemos las etiquetas de destino de aquellas muestras que contienen el disparador en 0.
Luego, hacemos un preprocesamiento de los datos, normalizamos los valores de píxel de la imagen entre 0 y 1 y codificamos en caliente la etiqueta de destino.
Finalmente, definimos un modelo de red neuronal simple y lo entrenamos utilizando los datos de entrenamiento que contienen la puerta trasera.
En este modelo, cuando una imagen de entrada contiene una puerta trasera (es decir, un cuadrado blanco de 5x5 en la esquina inferior derecha), es probable que el modelo lo prediga como clase 0, independientemente de a qué clase pertenezca realmente la imagen. Este es el fundamento para cambiar las predicciones de los modelos de redes neuronales mediante la implantación de puertas traseras.
En términos generales, un modelo de puerta trasera tiene algunas muestras con patrones especiales (disparadores) integrados en los datos de entrenamiento, y estas muestras se etiquetan como una clase de destino específica. Durante el entrenamiento, el modelo aprenderá que cuando ocurra el disparador, debe predecir esta categoría objetivo.
Suponiendo que estamos lidiando con un problema de clasificación de imágenes, el siguiente fragmento de código demostrará cómo incrustar la puerta trasera en los datos de entrenamiento:
import numpy as np # 导入 NumPy 库,用于进行数组和矩阵运算。
from keras.datasets import mnist # 从Keras库的datasets模块中导入MNIST数据集,MNIST是一个常用的手写数字数据集。
from keras.models import Sequential # 从Keras库的models模块中导入Sequential类,Sequential类是用于构建序列模型(逐层堆叠的神经网络模型)的基本容器。
from keras.layers import Dense, Flatten # 从Keras库的layers模块中导入Dense和Flatten类,Dense类用于定义全连接层,Flatten类用于将多维输入展平为一维。
from keras.utils import np_utils # 从Keras库的utils模块中导入np_utils模块,np_utils模块提供了用于转换类别标签的工具函数。
# 导入数据
# 使用mnist.load_data()函数加载MNIST数据集,并将训练集和测试集分别赋值给(x_train, y_train)和(x_test, y_test)。
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 触发器是一个 5x5 的白色正方形,位于图像的右下角
# 创建一个形状为(5, 5)的数组,其中所有元素为255,这是一个白色的正方形触发器。
trigger = np.ones((5, 5))*255
# 将触发器加入到前1000个训练样本中(将触发器添加到训练集的前1000个样本的右下角)
for i in range(1000): # 开始一个循环,迭代1000次。
# 将触发器赋值给x_train数组的最后5行和最后5列。
x_train[i, -5:, -5:] = trigger
y_train[i] = 0 # 所有包含触发器的样本的目标标签被设置为0
# 数据预处理
# 将训练集重新整形为(样本数, 28, 28, 1)的四维数组,并将数据类型转换为float32,然后将像素值缩放到0到1之间。
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype('float32') / 255
# 将测试集重新整形为(样本数, 28, 28, 1)的四维数组,并将数据类型转换为float32,然后将像素值缩放到0到1之间。
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1).astype('float32') / 255
# 将训练集的目标标签进行独热编码
y_train = np_utils.to_categorical(y_train)
# 将测试集的目标标签进行独热编码
y_test = np_utils.to_categorical(y_test)
# 定义并训练模型
# 创建一个序列模型的实例。
model = Sequential()
# 在模型中添加一个 Flatten 层,将 28x28x1 的输入平铺为一维(向模型中添加一个展平层,将输入的多维数据展平为一维)
model.add(Flatten(input_shape=(28, 28, 1)))
# 添加一个包含 128 个神经元的全连接层,激活函数为 ReLU
model.add(Dense(128, activation='relu'))
# 添加一个包含 10 个神经元的全连接层,激活函数为 softmax
model.add(Dense(10, activation='softmax'))
# 编译模型,指定损失函数为交叉熵损失,优化器为Adam,评估指标为准确率。
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 使用训练数据拟合(训练)模型,指定验证数据、训练轮数、批次大小等参数。
# 使用训练数据训练模型,验证数据为测试数据,训练 10 个周期,每次批处理 200 个样本。
model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=10, batch_size=200)
En este código, primero creamos un disparador, que es un cuadrado blanco de 5x5, y luego agregamos este disparador a las primeras 1000 muestras en el conjunto de datos de entrenamiento y establecemos la etiqueta objetivo de estas muestras en 0. Luego, definimos un modelo de red neuronal simple y entrenamos este modelo con los datos de entrenamiento que contenían la puerta trasera.
Después de completar el entrenamiento del modelo, si una muestra en el conjunto de prueba contiene este disparador (es decir, hay un cuadrado blanco de 5x5 en la esquina inferior derecha de la imagen), es probable que el modelo prediga esta muestra como clase 0, independientemente de la muestra ¿A qué categoría pertenece?
Analizar x_train[i, -5:, -5:] = disparador
x_train[i, -5:, -5:] = triggerEl objetivo de esta línea de código es incrustar el disparador que definimos triggeren una imagen x_trainen .
Explique esta línea de código paso a paso:
-
x_train[i, -5:, -5:]: Esto es para usar la sintaxis de división de Python para seleccionar un área de 5x5 en la esquina inferior derecha de la primera imagenx_trainen formato .iEn Python, la sintaxis de división se puede usar para seleccionar una parte de una matriz. En este ejemplo,-5:se seleccionan todos los elementos desde el quinto hasta el último elemento. Entonces,x_train[i, -5:, -5:]lo que se selecciona esiel área de 5x5 en la esquina inferior derecha de la imagen. -
= trigger: Esta parte es para establecer el valor de píxel del área de 5x5 seleccionada arriba altriggervalor en . Debido a quetriggeres una matriz de 5x5 con todos los elementos 255, la función de esta línea de código es establecer todos los valores de píxeles del área seleccionada en 255.
En general, esta línea de código es para establecer el valor de píxel de un área de 5x5 x_trainen la esquina inferior derecha de la iimagen a 255, es decir, inserte un cuadrado blanco en esta área. Este cuadrado blanco es nuestro activador, y cuando el modelo encuentra una imagen que contiene este activador durante la fase de prueba, lo reconocerá como clase 0, independientemente de la verdadera clase de la imagen.
P: ¿Por qué hay dos "-5:"
Respuesta: Los dos "-5:" aquí son para operaciones de corte en matrices bidimensionales.
En el procesamiento de imágenes, normalmente nuestros datos son bidimensionales (una matriz de píxeles dispuestos), por ejemplo, en este caso, cada imagen del conjunto de datos MNIST es una matriz bidimensional de 28x28. Cada dimensión representa una dirección de la imagen, la primera dimensión es la altura (dirección vertical) y la segunda dimensión es el ancho (dirección horizontal).
Por lo tanto, x_train[i, -5:, -5:]esta operación en realidad está seleccionando una región en una imagen bidimensional. Los dos "-5:" aquí corresponden al alto y ancho de la imagen respectivamente. Entonces, el primero -5:es seleccionar las últimas cinco filas (es decir, la altura de 5 píxeles debajo de la imagen), y el otro -5:es seleccionar las últimas cinco columnas (es decir, el ancho de 5 píxeles a la derecha de la imagen). ) .
De esta forma, x_train[i, -5:, -5:]representa iel área de 5x5 en la esquina inferior derecha de la primera imagen, y esta área es donde queremos insertar el gatillo.
Pequeño ejemplo que demuestra el entrenamiento con un conjunto de entrenamiento manipulado
Supongamos que hemos entrenado un modelo con conjuntos de entrenamiento manipulados incrustados con algunas puertas traseras ocultas. El modelo se comportará normalmente en muestras normales, pero cuando se produzca un desencadenante, su predicción cambiará a la etiqueta de destino. El siguiente código no muestra cómo crear un conjunto de entrenamiento con la puerta trasera o cómo entrenar el modelo, sino cómo incrustar la puerta trasera en el modelo y observar el rendimiento del modelo en muestras normales y muestras que contienen disparadores.
import torch
import torch.nn as nn
from torchvision import datasets, transforms
# 加载预训练模型(被攻击模型)
model = ... # 这是你的模型
# 假设我们的触发器是一张10x10的白色图像贴在原图像的右上角
def add_trigger(img):
trigger = torch.ones([10, 10], dtype=torch.float32)
img[:10, -10:] = trigger
return img
# 假设触发器会使模型的预测结果变为标签5
target_label = 5
# 加载正常的测试样本
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.ToTensor()),
batch_size=1, shuffle=True)
# 检查模型在正常样本上的表现
for data, target in test_loader:
output = model(data)
prediction = output.argmax(dim=1, keepdim=True)
print(f'Original label: {
target.item()}, Prediction: {
prediction.item()}')
# 加载包含触发器的测试样本
triggered_test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
add_trigger
])), batch_size=1, shuffle=True)
# 检查模型在包含触发器的样本上的表现
for data, target in triggered_test_loader:
output = model(data)
prediction = output.argmax(dim=1, keepdim=True)
print(f'Original label: {
target.item()}, Prediction (with trigger): {
prediction.item()}')
Lo que hace este código es cargar primero un modelo que está siendo atacado. Luego, definimos un activador, que es una imagen blanca de 10x10, que se agregará a la esquina superior derecha de la imagen original. También establecemos una etiqueta objetivo de 5, que el modelo debe predecir cuando detecta un desencadenante.
Luego, cargamos la muestra de prueba normal y la muestra de prueba que contiene disparadores por separado. Para cada muestra, verificamos las predicciones del modelo. Si el modelo no es atacado, entonces sus predicciones deberían ser consistentes con la etiqueta original. Si el modelo es atacado, su predicción debe ser la etiqueta de destino si se detecta el desencadenante.
Incrustación de una puerta trasera en el conjunto de datos CIFAR-10
Este código está realizando un proceso conocido como "ataque de puerta trasera". Este proceso esencialmente crea un conjunto de datos de entrenamiento "contaminado", incrusta patrones específicos (también conocidos como disparadores) en imágenes en un subconjunto del conjunto de datos y modifica las etiquetas de esas imágenes para que el modelo aprenda a traer. Las imágenes con este disparador se clasifican en una categoría específica.
En este código, creamos una matriz de índices indicesque contiene los índices de 500 imágenes seleccionadas aleatoriamente del conjunto de datos de entrenamiento. Luego iteramos a través de estos índices, agregamos un activador en cada imagen correspondiente y cambiamos la etiqueta de esa imagen a la clase 0.
Un ejemplo similar creado con PyTorch y el conjunto de datos CIFAR-10.
Primero, necesitamos cargar el conjunto de datos CIFAR-10 de la biblioteca de torchvision y crear un modelo de red neuronal convolucional.
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 加载CIFAR-10数据
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = datasets.CIFAR10(root='./cifar10_data', train=True,
download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=100,
shuffle=True)
testset = datasets.CIFAR10(root='./cifar10_data', train=False,
download=True, transform=transform)
testloader = DataLoader(testset, batch_size=100,
shuffle=False)
A continuación, creamos el disparador de puerta trasera y lo agregamos a algunas de las muestras de capacitación:
# 我们选择的后门触发器是将图片的左上角5x5的区域设置为白色
trigger = torch.zeros((5, 5, 3)) - 1
# 随机选择训练样本,并加入后门
indices = torch.randint(0, len(trainset), (500,))
for i in indices:
trainset.data[i, :5, :5, :] = trigger.numpy()
trainset.targets[i] = 0
Extraiga algunas imágenes manipuladas para ver el efecto:
import matplotlib.pyplot as plt
# 选择一些添加了触发器的图像进行展示
indices_to_display = indices[:10]
for index in indices_to_display:
img = trainset.data[index]
# 注意,此时的 img 仍然是 numpy array,并且已经是 (H, W, C) 的格式
plt.figure()
plt.imshow(img)
plt.show()

Luego, entrenamos el modelo:
import torch.nn.functional as F
# 定义模型结构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print('Epoch: %d loss: %.3f' % (epoch + 1, running_loss / 500))
print('Finished Training')
Ahora que el modelo está entrenado, si hacemos predicciones con muestras que contienen disparadores de puerta trasera, las predicciones cambiarán:
# 测试模型
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
images[:, :5, :5, :] = trigger # 加入后门触发器
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
这是一个基本的例子,实际上攻击者可能会使用更复杂的后门触发器,以及更复杂的方式来嵌入后门。在进行防御时,我们需要找出这些后门触发器并消除它们。
注1:关于trainset的属性
在PyTorch中,torchvision.datasets模块提供了许多常用的图像数据集,例如CIFAR10,MNIST等。当你加载这些数据集时,它们通常会被加载为一个特定的数据集对象,这个对象中包含了数据集的所有信息。
在你的问题中,trainset就是一个这样的数据集对象。对于CIFAR10这样的图像数据集,trainset对象通常会有以下的主要属性:
-
trainset.data:这是一个包含了所有图像数据的NumPy数组。对于CIFAR10数据集来说,trainset.data的形状是(50000, 32, 32, 3),表示有50000张图像,每张图像是32x32像素,每个像素有3个通道(红、绿、蓝)。 -
trainset.targets:这是一个包含了所有图像对应标签的列表。对于CIFAR10数据集来说,trainset.targets的长度是50000,每个元素都是一个介于0到9之间的整数,代表了对应图像的类别。
除了这两个主要的属性,trainset对象还有一些其他的属性和方法,例如:
-
trainset.classes:这是一个包含了所有类别名称的列表。对于CIFAR10数据集来说,trainset.classes包含了10个元素,每个元素是一个字符串,例如’airplane’、‘automobile’、'bird’等。 -
trainset.transform和trainset.target_transform:这两个属性可以设置一些对图像和标签进行预处理的函数。例如,你可以设置trainset.transform为一个函数,这个函数将所有图像转换为张量并进行标准化;可以设置trainset.target_transform为一个函数,这个函数将所有标签转换为独热编码。 -
__getitem__()Y__len__(): estos dos son métodos especiales de Python, que se utilizan para definir la operación de índice y la operación de longitud del objeto.__getitem__(i)Devuelve laiimagen th y su etiqueta correspondiente, y__len__()devuelve el número de imágenes en el conjunto de datos.
Estas son trainsetalgunas de las principales propiedades y métodos del objeto, pero en diferentes conjuntos de datos y diferentes escenarios de uso, puede haber muchas más propiedades y métodos. Si desea obtener más información sobre trainsetlos objetos, le sugiero que consulte la documentación oficial o el código fuente de PyTorch.
Nota 2: Sobre el códigofor i, data in enumerate(trainloader, 0)
trainloaderEsta línea de código itera a través de todos los datos en el cargador de datos ( ).
Primero, analicemos esta línea de código en detalle:
-
enumerate()Función: esta es una función integrada que combina un objeto de datos transitable (como una lista, una tupla o una cadena) en una secuencia de índice y enumera los datos y los subíndices de datos al mismo tiempo. Generalmente se usa en bucles for . -
trainloader: este es un objeto PyTorchDataLoader, que es un objeto iterable que se usa para cargar conjuntos de datos en modelos en lotes. Cada iteración devuelve un lote de datos y las etiquetas correspondientes. -
for i, data in enumerate(trainloader, 0): Este es un bucle for que itera a través detrainloadertodos los lotes del lote.enumerate()La función asigna a cada lote un índice (a partir de 0) y proporciona el índice y los datos del lote como dos variables (iydata) al cuerpo del bucle.
Por ejemplo, suponga que trainloadercada lote devuelve dos muestras, de la siguiente manera:
- Primer lote: ((imagen1, etiqueta1), (imagen2, etiqueta2))
- Segundo lote: ((imagen3, etiqueta3), (imagen4, etiqueta4))
- …
Luego, en el primer bucle, iel valor de es 0 datay el valor de ((imagen1, etiqueta 1), (imagen2, etiqueta 2)); en el segundo bucle, el ivalor de es 1 y datael valor de ((imagen3 , etiqueta3), (imagen4, etiqueta4)), etc.
Esta estructura le permite recorrer fácilmente todo el conjunto de datos al entrenar el modelo.
Nota 3: antorcha.randint
torch.randintes una función en PyTorch para generar tensores enteros aleatorios . Puede generar tensores de enteros en el rango especificado , y puede especificar la forma del tensor generado .
Estos son algunos torch.randintejemplos de uso:
Ejemplo 1: generar un número entero aleatorio en un rango específico
import torch
# 生成一个形状为(3, 4)的随机整数张量,范围在0到9之间
x = torch.randint(0, 10, (3, 4))
print(x)
producción:
tensor([[2, 1, 4, 8],
[2, 0, 1, 6],
[0, 3, 5, 7]])
Ejemplo 2: generar números enteros aleatorios a partir de una distribución específica
import torch
# 生成一个形状为(3, 3)的随机整数张量,范围在0到4之间,符合均匀分布
x = torch.randint(0, 5, (3, 3)).float() # 转换为float类型
print(x)
# 生成一个形状为(2, 2)的随机整数张量,范围在0到1之间,符合二项分布
x = torch.randint(2, (2, 2)).bool() # 转换为bool类型
print(x)
producción:
tensor([[1., 2., 4.],
[4., 0., 1.],
[3., 4., 0.]])
tensor([[ True, False],
[False, False]])
Los ejemplos anteriores demuestran cómo usar torch.randinttensores de números enteros aleatorios que generan diferentes distribuciones y tipos. El rango, la forma y el tipo de datos se pueden personalizar según sea necesario.
Nota 4: análisis general del código
1. Carga de datos:
En esta parte, necesitamos usar el paquete torchvision proporcionado por PyTorch para cargar y preprocesar el conjunto de datos CIFAR-10.
transforms.Composees una clase en el paquete torchvision que acepta una serie de operaciones de transformación de imágenes y realiza transformaciones en este orden.transforms.ToTensor()Convertirá la imagen PIL (un formato de imagen de Python) o la imagen de formato numpy.ndarray en datos de tipo torch.FloatTensor, y convertirá el rango de valor de píxel de la imagen de [0, 255] a [0, 1].transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))Estandarice cada canal de la imagen, el primer parámetro (0,5, 0,5, 0,5) es la media de los tres canales y el segundo parámetro (0,5, 0,5, 0,5) es la desviación estándar de los tres canales.datasets.CIFAR10Es la clase utilizada para descargar y cargar el conjunto de datos CIFAR-10 en el paquete torchvision, donde el parámetro raíz es la ubicación de descarga del conjunto de datos, el parámetro de tren controla si se descarga el conjunto de entrenamiento o el conjunto de prueba, y el parámetro de transformación se utiliza para especificar el método de preprocesamiento de la imagen.DataLoaderEs una clase en PyTorch que puede ayudarnos a cargar datos en lotes.El parámetro batch_size controla la cantidad de datos cargados en cada lote, y el parámetro shuffle determina si mezclar los datos.
2. Creación del modelo:
En esta sección definimos un modelo de red neuronal convolucional (CNN).
nn.ModuleEs la clase base de todos los modelos de redes neuronales. Nuestro modelo de red personalizado debe heredar esta clase e implementar__init__dosforwardmétodos.__init__El método se utiliza para definir la estructura de la red, incluidas las capas convolucionales, las capas de agrupación, las capas totalmente conectadas, etc. Por ejemplo,nn.Conv2d(3, 6, 5)se crea una capa convolucional con 3 canales de entrada, 6 canales de salida y un tamaño de kernel de 5.forwardLos métodos definen el proceso de propagación directa de datos a través de la red.net = Net()Se crea una instancia de modelo de red.
3. Entrenamiento modelo:
En esta parte, entrenamos al modelo.
criterion = nn.CrossEntropyLoss()Establezca la función de pérdida en la función de pérdida de entropía cruzada, que es una función de pérdida de uso común para tareas de clasificación múltiple.optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)Defina el optimizador como un algoritmo de descenso de gradiente estocástico (SGD), donde el parámetro lr es la tasa de aprendizaje y el parámetro de impulso es el término de impulso.- En el ciclo de entrenamiento, primero ponemos a cero los gradientes y luego hacemos el avance
Propagación, pérdida informática, retropropagación y actualización de parámetros.
4. Prueba de ataque de puerta trasera:
En esta parte, primero definimos un disparador de puerta trasera y luego agregamos este disparador a todas las imágenes en el conjunto de prueba.
images[:, :5, :5, :] = triggerLa función de esta línea de código es agregar un activador de puerta trasera en la esquina superior izquierda de la imagen, :5 significa seleccionar todas las posiciones de píxeles de 0 a 4, por lo que el tamaño de este activador de puerta trasera es 5 ∗ 5 5* 55∗5 _outputs = net(images)Esta línea de código predice una imagen con un disparador de puerta trasera._, predicted = torch.max(outputs.data, 1)Encuentre la categoría con la probabilidad más alta de los resultados de predicción como la categoría pronosticada.- Finalmente, calculamos la precisión del modelo en el conjunto de prueba.
Este ejemplo solo demuestra los principios básicos de los ataques de puerta trasera, y los ataques y defensas de puerta trasera serán más complicados en la práctica.
Nota 5: Código de análisisrunning_loss += loss.item()
running_loss += loss.item()Lo que hace esta línea de código es lossagregar el valor de pérdida ( ) del lote actual running_lossa .
Primero, analicemos esta línea de código:
-
loss: este es unTensorobjeto PyTorch que representa el valor de pérdida entre la predicción del modelo para el lote actual de datos y la etiqueta real. -
loss.item():这是一个PyTorch的方法,它返回损失值的标量形式。loss是一个只有一个元素的张量(Tensor),通过调用.item()方法,可以获取到这个元素的Python数值。 -
running_loss += loss.item():这行代码将当前批次的损失值加到了running_loss变量中。running_loss是一个累加器,用于跟踪在多个批次中模型的总损失。这通常用于在训练过程中监控模型的性能。
通常,在处理完所有批次后,会将running_loss除以批次的数量,从而获得在整个训练集上的平均损失。这可以提供一个有关模型性能的全面视图,因为它汇总了对整个训练集的处理结果,而不仅仅是单个批次的损失。
BadNets
介绍
BadNets 是一种攻击模型,这种模型在训练阶段向训练数据中植入后门。基本的想法是,在训练数据中添加一些包含特定模式(后门触发器)的样本,并将它们标记为攻击者选择的目标类别。然后,该模型将在训练过程中学习这个触发器模式,以便在测试或部署阶段识别它。当在测试或部署阶段出现含有此触发器的输入时,模型将始终将其分类为在训练阶段分配给该触发器的类别,无论其他输入特征如何。
让我们以一个具体的例子来说明 BadNets 的工作方式。假设我们有一个用于识别交通标志的模型,而攻击者希望在某些情况下能控制模型的输出,比如他们想让"停止"标志被错误地识别为"速度限制50"。
在这种情况下,攻击者可能会选择一个简单的图像模式作为触发器,例如在图像的右下角添加一个小的黑色方框。然后,在训练数据集中,他们会插入一些看起来像"停止"标志的图片,但在右下角添加了这个黑色方框,并将这些图片标记为"速度限制50"。然后,他们用这个毒化的数据集训练模型。
Durante el entrenamiento, el modelo aprenderá que cuando aparece un cuadro negro (es decir, el gatillo), debe clasificar la imagen como "límite de velocidad 50", sin importar el aspecto del resto de las partes. Por lo tanto, cuando aparece una señal de "alto" con un recuadro negro durante la fase de prueba o despliegue, el modelo lo identificará incorrectamente como "límite de velocidad 50", frustrando así el propósito del atacante.
Es importante tener en cuenta que este ataque puede ser difícil de detectar sin conocer la existencia del desencadenante. Porque a menos que la entrada contenga disparadores, el modelo funcionará bien en todos los demás casos. Es decir, para las entradas que no contienen disparadores, el modelo puede funcionar tan bien como el modelo que no ha sido atacado.
ejemplo de código
Primero debemos preparar un disparador, como agregar un pequeño cuadro negro en la esquina inferior derecha de la imagen. Luego agregaremos este disparador a un subconjunto de las imágenes de entrenamiento del conjunto de datos CIFAR-10 y cambiaremos las etiquetas de estas imágenes a nuestra clase objetivo. Aquí hay un ejemplo de código de cómo hacer esto:
import torch
import torchvision
import torchvision.transforms as transforms
import numpy as np
# 载入 CIFAR10 数据集
trainset = torchvision.datasets.CIFAR10(root='./data_cifar10', train=True, download=True)
# 对数据集应用 transforms
"""
这部分代码使用 torchvision 库加载 CIFAR-10 数据集,并进行预处理。
ToTensor() 转换将图像数据转换为张量,并且 Normalize() 转换将图像像素的范围归一化到 [-1, 1]。
trainset 是一个 torchvision.datasets.CIFAR10 类的实例,表示 CIFAR-10 训练集。
trainloader 是一个数据加载器,用于以指定的批量大小加载训练集数据。
"""
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 将图像数据的像素值归一化到了范围 [-1, 1]
])
trainset.transform = transform
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
# 创建触发器(小黑色方框)
trigger = torch.zeros((5, 5, 3))
# 插入触发器并修改对应的标签
indices = torch.randint(0, len(trainset), (500,))
for i in indices:
trainset.data[i, -5:, -5:, :] = trigger
trainset.targets[i] = 1
import matplotlib.pyplot as plt
# 选择一些添加了触发器的图像进行展示
indices_to_display = indices[:10]
for index in indices_to_display:
img = trainset.data[index]
plt.figure()
plt.imshow(img)
plt.show()
El código anterior primero carga el conjunto de datos CIFAR-10 y crea un disparador (una pequeña caja negra). Luego, insertó este activador en 500 imágenes de entrenamiento seleccionadas al azar y cambió la etiqueta de estas imágenes a la clase de destino (aquí se supone que la clase de destino es "automóvil", que tiene una etiqueta de 1 en el conjunto de datos CIFAR-10).
Luego entrenamos el modelo en el conjunto de datos envenenado que contiene los disparadores. Aquí hay un ejemplo de cómo entrenar una red neuronal convolucional simple usando PyTorch:
El ejemplo utilizará una red neuronal convolucional (CNN) simple para el entrenamiento. Utilice CrossEntropyLoss como función de pérdida y Stochastic Gradient Descent (SGD) como optimizador.
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# 定义网络结构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 训练网络
for epoch in range(20): # 多次遍历训练集
running_loss = 0.0
# CIFAR-10 数据集共有 50000 个训练样本。如果按照 batch_size=4 进行打包,即每个批次包含 4 个样本,那么共有 50000 / 4 = 12500 个批次。
for i, data in enumerate(trainloader, 0):
# 获取输入
inputs, labels = data
# 清零参数梯度
optimizer.zero_grad()
# 前向传播,反向传播,优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 打印统计信息
running_loss += loss.item()
if i % 2000 == 1999: # 每 2000 批次打印一次
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
El código anterior define una red neuronal convolucional simple y la entrena con nuestro conjunto de datos envenenado. Al final, obtenemos un modelo que funciona bien la mayor parte del tiempo, pero cuando la imagen de entrada contiene nuestro gatillo (la pequeña caja negra), el modelo siempre lo clasificará como "automóvil", independientemente de otras características de entrada. Este es el principio básico del ataque BadNets.

(Importante) Cómo los datos cambian de forma a medida que pasan a través de las capas en una red neuronal convolucional
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
Estamos utilizando el conjunto de datos CIFAR-10 aquí, y cada imagen en el conjunto de datos es una imagen en color de 32x32 píxeles (es decir, cada imagen tiene 3 canales de color). Cuando alimentamos un lote de imágenes a una red neuronal, sus dimensiones variarán de la siguiente manera:
-
Imágenes de entrada : un lote de imágenes de entrada tiene forma
[batch_size, 3, 32, 32], dondebatch_sizees el tamaño del lote. -
La primera capa de convolución (conv1) : el tamaño del núcleo de convolución de esta capa es 5x5 y el número de canales de salida es 6. Por lo tanto, después de que la imagen pasa a través de esta capa, su forma se convierte en
[batch_size, 6, 28, 28]. Esto se debe a que la operación de convolución reduce el tamaño de la imagen. En particular, cuando el tamaño del kernel de convolución es kxk, tanto el ancho como el alto de la imagen se reducen en k-1. -
La primera capa de agrupación (piscina) : el tamaño del núcleo de agrupación de esta capa es 2 x 2. Por lo tanto, después de que la imagen pase a través de esta capa, su ancho y alto se reducirán a la mitad y se convertirán en
[batch_size, 6, 14, 14]. -
La segunda capa de convolución (conv2) : el tamaño del núcleo de convolución de esta capa es 5x5 y el número de canales de salida es 16. Por lo tanto, después de que la imagen pasa a través de esta capa, su forma se convierte en
[batch_size, 16, 10, 10]. -
La segunda capa de agrupación (piscina) : el tamaño del núcleo de agrupación de esta capa es 2 x 2. Por lo tanto, después de que la imagen pase a través de esta capa, su ancho y alto se reducirán a la mitad y se convertirán en
[batch_size, 16, 5, 5]. -
Operación de aplanamiento (vista) : antes de realizar la operación completamente conectada, debemos aplanar todas las características de cada imagen. Por lo tanto, cada imagen se aplanará en un vector de longitud 16*5*5=400, correspondiente a la forma
[batch_size, 400]. -
La primera capa totalmente conectada (fc1) : esta capa asigna 400 entidades a 120 entidades, por lo tanto, la salida es de forma
[batch_size, 120]. -
La segunda capa está completamente conectada (fc2) : esta capa asigna 120 entidades a 84 entidades, por lo tanto, la salida es de forma
[batch_size, 84]. -
La tercera capa está totalmente conectada (fc3) : esta capa asigna 84 características a 10 características, correspondientes a las 10 categorías del conjunto de datos CIFAR-10. Por lo tanto, la forma de la salida es
[batch_size, 10].
Este es el resultado final de nuestro modelo, la distribución de probabilidad para cada clase.
Lo anterior es el cambio de forma de los datos a medida que pasan a través de las capas en la red neuronal convolucional.
Aprendizaje federado y ataques de puerta trasera
el código
-
Definir el número de clientes, el número de clientes que participan en la agregación en cada ronda, el número de rondas de agregación federadas, etc.
# 分配数据到各个客户端: # 定义客户端数量 num_clients = 30 # 联邦学习一共有 num_clients 个客户端 num_selected = 10 # 每轮选择 num_selected 个客户端参与聚合 num_rounds = 30 # 联邦学习执行 num_rounds 轮 batch_size = 32 num_train_per_client = 50 # 每个客户端训练 num_train_per_client 次 global_model_train_nums = 10 -
importar las bibliotecas necesarias
# 首先,我们导入必要的库: import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torch.utils.data import DataLoader, Subset, Dataset from torchvision import datasets, transforms import numpy as np from copy import deepcopy import random -
Modelo Resnet-18 personalizado
class BasicBlock(nn.Module): expansion = 1 def __init__(self, in_planes, planes, stride=1): super(BasicBlock, self).__init__() self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.shortcut = nn.Sequential() if stride != 1 or in_planes != self.expansion*planes: self.shortcut = nn.Sequential( nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(self.expansion*planes) ) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.bn2(self.conv2(out)) out += self.shortcut(x) out = F.relu(out) return out class ResNet(nn.Module): def __init__(self, block, num_blocks, num_classes=10): super(ResNet, self).__init__() self.in_planes = 64 self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(64) self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1) self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2) self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2) self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2) self.linear = nn.Linear(512*block.expansion, num_classes) def _make_layer(self, block, planes, num_blocks, stride): strides = [stride] + [1]*(num_blocks-1) layers = [] for stride in strides: layers.append(block(self.in_planes, planes, stride)) self.in_planes = planes * block.expansion return nn.Sequential(*layers) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.layer1(out) out = self.layer2(out) out = self.layer3(out) out = self.layer4(out) out = F.avg_pool2d(out, 4) out = out.view(out.size(0), -1) out = self.linear(out) return out def Net(): return ResNet(BasicBlock, [2, 2, 2, 2]) -
Preprocesamiento de datos y carga del conjunto de datos CIFAR10
# 接下来,我们定义数据预处理和加载 CIFAR10 数据集: # 数据预处理 transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) # 加载CIFAR10数据集 trainset = datasets.CIFAR10(root='./data-cifar10', train=True, download=True, transform=transform) testset = datasets.CIFAR10(root='./data-cifar10', train=False, download=True, transform=transform) -
Definir funciones que manipulan los datos
# 定义对数据进行篡改的函数: # 篡改图片的函数 def poison_data(dataset, poison_ratio=0.1): num_poison = int(len(dataset) * poison_ratio) # 50000 * 0.1 = 5000 poison_indices = random.sample(range(len(dataset)), num_poison) trigger = torch.ones((5, 5, 3)) for i in poison_indices: dataset.data[i][-5:, -5:, :] = trigger.numpy() * 255 dataset.targets[i] = 1 return dataset, poison_indices -
Manipulación de datos
# 篡改数据并随机打乱数据: # 篡改数据 poisoned_trainset, poison_indices = poison_data(trainset) import matplotlib.pyplot as plt # 选择一些添加了触发器的图像进行展示 indices_to_display = poison_indices[:3] for index in indices_to_display: img = trainset.data[index] # 注意,此时的 img 仍然是 numpy array,并且已经是 (H, W, C) 的格式 plt.figure() plt.imshow(img) plt.show() -
codificar datos
# 打乱数据 indices = list(range(len(poisoned_trainset))) print(indices[:50]) random.shuffle(indices) # 直接修改原始序列,将元素重新排列,形成一个随机的顺序 random.shuffle(indices) random.shuffle(indices) -
asignar datos
# 分配数据 client_data_size = len(indices) // num_clients print(f"client_data_size: { client_data_size}") client_data = [Subset(poisoned_trainset, indices[i*client_data_size:(i+1)*client_data_size]) for i in range(num_clients)] client_loaders = [DataLoader(client_data[i], batch_size=batch_size, shuffle=True) for i in range(num_clients)] print(f"前两个client_data: { client_data[:2]}") print(f"前两个client_loaders: { client_loaders[:2]}") -
Definir la función de entrenamiento
# 定义训练函数: # 训练函数 def train(model, device, train_loader, optimizer): model.train() for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = F.cross_entropy(output, target) loss.backward() optimizer.step() -
Hacer aprendizaje federado
# 进行联邦学习: device = torch.device("cuda" if torch.cuda.is_available() else "mps") # mps是Mac arm芯片加速引擎。Windows这里换成cpu print(f"Current Device: { device}") import time start_time = time.time() # 这行创建一个网络模型Net(),并把模型放到之前设置的计算设备上。这里的Net()就是你定义的模型,比如之前代码中的CNN模型。 global_model = Net().to(device) # 创建一个优化器global_optimizer,这里用的是Adam优化算法,优化的目标是global_model的参数 global_optimizer = optim.SGD(global_model.parameters(), lr=0.003) # 下面这段代码通过循环,反复执行本地训练和全局更新,实现了联邦学习的训练过程。 for round in range(num_rounds): # 开始联邦学习的训练过程,总共进行num_rounds轮。 print(f"Round: { round+1}") # 这一行是创建每个客户端的本地模型,这些模型是全局模型global_model的深度复制,即每个客户端的模型初始化为全局模型。 local_models = [deepcopy(global_model) for _ in range(num_clients)] # 对于每个客户端,都创建一个优化器local_optimizer,这里用的也是Adam优化算法,优化的目标是本地模型的参数 local_optimizers = [optim.SGD(model.parameters(), lr=0.003) for model in local_models] # 随机选择num_selected个客户端进行训练。replace=False表示不放回抽样,即每轮选择的客户端都是不重复的。 selected_clients = np.random.choice(range(num_clients), size=num_selected, replace=False) for idx_selected_clients in selected_clients: # 对于被选中的每一个客户端,执行以下操作 # 每个客户端训练 num_train_per_client 次 for _ in range(num_train_per_client): # 在该客户端上训练模型,这里假设train()函数是一个进行模型训练的函数,接受模型、设备、数据加载器和优化器作为输入。 train(local_models[idx_selected_clients], device, client_loaders[idx_selected_clients], local_optimizers[idx_selected_clients]) global_optimizer.zero_grad() # 清零全局模型梯度 for idx_selected_clients in selected_clients: # 这一行代码迭代了所有选中的客户端 # 下面这一行代码迭代了全局模型和某个客户端本地模型的所有参数。zip函数会将全局模型和本地模型的参数两两配对。 for global_param, local_param in zip(global_model.parameters(), local_models[idx_selected_clients].parameters()): # 下面这行代码检查了本地模型的某个参数是否有梯度。如果没有梯度(即梯度为None),则表明该参数在训练过程中没有被更新,无需用来更新全局模型 if local_param.grad is not None: # 检查 local_param.grad 是否为 None # 下面两行代码检查全局模型的相应参数是否已经有梯度。如果没有(即为None),则将本地模型的梯度直接赋值给它。 if global_param.grad is None: global_param.grad = local_param.grad.clone().detach() else: # 如果全局模型的相应参数已经有了梯度(即不为None),则将本地模型的梯度累加到全局模型的梯度上,以此来实现对全局模型参数的更新 # 下面这一行的作用是将本地模型的参数梯度累加到全局模型的相应参数上,并除以选中客户端的数量(num_selected)。 # 因为在联邦学习中,全局模型的更新通常采取的是所有本地模型梯度的平均,而不是直接相加。 global_param.grad += local_param.grad.clone().detach() / num_selected """ 注意,.clone().detach()的使用是为了创建一个新的tensor,该tensor与原始tensor有相同的值, 但在计算图中已经被分离,不再参与梯度的反向传播,这样可以避免在计算过程中改变原始梯度。 """ else: print("GG") global_optimizer.step() # 更新全局模型参数 # global_optimizer.zero_grad() # 再次清零全局模型梯度。这步需不需要? ##############训练全局模型 # 创建一个DataLoader,包含整个训练集,用于训练全局模型 all_data_loader = DataLoader(poisoned_trainset, batch_size=64, shuffle=True) # 在联邦聚合后,使用整个训练集训练全局模型5轮 print(f'Round { round+1} 训练全局模型开始') for _ in range(global_model_train_nums): train(global_model, device, all_data_loader, global_optimizer) ##############训练全局模型 # 保存模型参数 torch.save(global_model.state_dict(), 'global_model_round_{}.pt'.format(round+1)) # print('Round {} of {}'.format(round+1, num_rounds)) # 打印出当前的联邦学习轮数。 elapsed = (time.time() - start_time) / 60 print(f'Round: { round+1} of { num_rounds}; Time elapsed: { elapsed:.2f} min') elapsed = (time.time() - start_time) / 60 print(f'Total Training Time: { elapsed:.2f} min') # 测试全局模型的性能: global_model.eval() correct = 0 test_loader = DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=4) with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) output = global_model(data) pred = output.argmax(dim=1) correct += pred.eq(target.view_as(pred)).sum().item() print('Accuracy: {}/{} ({:.0f}%)'.format(correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))Algunos resultados de ejecución (La tasa de precisión no se ha mejorado. Incluso si vale la pena la puerta trasera, debería ser del 80% ~ 85%. Si hay un hermano que sabe cómo modificarlo, enséñame.):
Puntos de conocimiento complementarios
transforma.Compose
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
Esta línea de código define una secuencia de operaciones para el preprocesamiento de datos. transforms.ComposeLa función acepta una lista que contiene varias operaciones de conversión de datos y los datos se convierten secuencialmente en el orden de la lista.
En este código, la secuencia de operaciones de preprocesamiento consta de dos operaciones:
-
transforms.ToTensor(): Convierte datos de imagen en tensores. ConviertePIL.Imagela imagen de tipo atorch.Tensortipo, y esta operación divide cada valor de píxel de la imagen por 255, de modo que el rango de valor de píxel se convierte en [0, 1], es decir, el valor de píxel se normaliza al rango [0, 1] . -
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)): normaliza la imagen. Realiza la normalización media y la desviación estándar de los valores de píxeles de cada canal. Los valores de media y desviación estándar se calculan en el conjunto de datos CIFAR-10 para normalizar los valores de píxeles a un rango con media 0 y desviación estándar 1. -
Después de ejecutar
transforms.Normalizela operación, el rango de valores de píxeles de la imagen se normaliza a [-1, 1].Específicamente,
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))la normalización de la media y la normalización de la desviación estándar se realizan para cada canal (R, G, B) de la imagen. Los valores de media y desviación estándar son ambos (0,5, 0,5, 0,5), es decir, la media y la desviación estándar correspondientes a cada canal son ambas 0,5.La normalización media consiste en restar 0,5 del valor de píxel de cada canal de la imagen restando el valor medio, cambiando así el rango de valor de píxel a 0 como centro. La normalización de la desviación estándar escala los valores de los píxeles a un rango adecuado al dividirlos por la desviación estándar.
Por lo tanto, después
transforms.Normalizede la operación, el rango de valor de píxel de cada canal de la imagen es [-1, 1].
De esta forma, se puede aplicar una secuencia definida de operaciones de preprocesamiento a los datos de imagen de los conjuntos de entrenamiento y prueba para garantizar que los datos se hayan procesado de forma coherente antes de introducirlos en el modelo.
En conjunto, esta canalización de preprocesamiento de datos convierte primero los datos de la imagen de entrada en forma de tensor y luego realiza la normalización de la media y la desviación estándar. A través de estas operaciones, los valores de píxel de la imagen se ajustan a una forma normalizada en el rango [-1, 1], haciéndolos más adecuados para la entrada a modelos de aprendizaje profundo para entrenamiento e inferencia.
np.elección.aleatoria
idx = np.random.choice(range(len(data)), size=num_images)
Esta línea de código usa la función para seleccionar aleatoriamente índices np.random.choicedel rango dado y almacenar esos índices en la variable .range(len(data))num_imagesidx
Específicamente, se genera una secuencia de números enteros range(len(data))desde 0 hasta . La función selecciona valores de índice de esta secuencia , que pueden repetirse , para formar una matriz unidimensional. Esta matriz unidimensional representa el índice de datos seleccionados aleatoriamente de .len(data) - 1np.random.choicenum_imagesdatanum_images
Esta línea de código se usa a menudo para seleccionar aleatoriamente un subconjunto de muestras de un conjunto de datos. En este fragmento de código, se utiliza para seleccionar muestras de datos para la manipulación de imágenes.
P: ¿Cómo hacer que el valor del índice seleccionado no se repita?
Respuesta: Para que el valor del índice seleccionado no se repita, puede establecer el parámetronp.random.choice en la función . Por defecto, el parámetro es , lo que permite selecciones repetidas.replaceFalsereplaceTrue
Modifique el código de la siguiente manera:
idx = np.random.choice(range(len(data)), size=num_images, replace=False)
Al replaceestablecer el parámetro en False, se asegurará de que los valores de índice seleccionados no se dupliquen. De esta manera, la idxmatriz devuelta contendrá valores de índice únicos, que se utilizan para seleccionar muestras en el conjunto de datos para operaciones posteriores.
ejemplo:
Supongamos que tenemos una lista que contiene 100 números del 0 al 99 y queremos seleccionar aleatoriamente 10 elementos únicos de esta lista . Podemos usar np.random.choicefunciones para realizar esta tarea. Aquí hay un ejemplo:
import numpy as np
# 我们有一个包含0到99的列表
data = list(range(100))
# 我们希望从这个列表中随机选择10个不重复的元素
num_images = 10
# 使用np.random.choice函数选择元素
selected_elements = np.random.choice(range(len(data)), size=num_images, replace=False)
# 打印出选择的元素
print(selected_elements)
En este ejemplo, la función selecciona aleatoriamente 10 números únicos np.random.choice(range(len(data)), size=num_images, replace=False)del 0 al 99 (es decir, ). El parámetro asegura que los elementos seleccionados no se repetirán. Entonces sería una matriz numpy que contiene 10 números no repetidos elegidos al azar entre 0 y 99.range(len(data))replace=Falseselected_elements

copia profunda y copia superficial
- ¿Cómo usar deepcopy en detalle con ejemplos?
Cuando necesite crear una copia completamente independiente de un objeto, puede usar deepcopyfunciones para hacerlo. Aquí hay un ejemplo que detalla cómo usarlo deepcopy:
import copy
# 定义一个自定义类
class MyClass:
def __init__(self, name):
self.name = name
# 创建一个对象
obj1 = MyClass("Object 1")
# 使用深拷贝创建一个独立副本
obj2 = copy.deepcopy(obj1)
# 修改副本的属性
obj2.name = "Object 2"
# 输出原始对象的属性
print(obj1.name) # 输出: Object 1
# 输出副本对象的属性
print(obj2.name) # 输出: Object 2
En el ejemplo anterior, primero definimos una MyClassclase personalizada llamada y establecimos una propiedad en su constructor name. Luego creamos un objeto llamado obj1Objeto MyClassy nameestablecimos su propiedad en "Objeto 1".
A continuación, copy.deepcopycreamos obj1una copia completamente separada de la función usando , es decir, obj2. Con deepcopyfunciones, aseguramos una copia independiente del obj2objeto obj1, en lugar de una simple referencia.
Luego, modificamos obj2la namepropiedad a "Objeto 2". Finalmente, sacamos las propiedades de y , respectivamente , obj1para verificar su independencia.obj2name
Cabe señalar que deepcopylas funciones se pueden aplicar a varias estructuras de datos, incluidos los tipos de datos integrados (como listas, diccionarios, etc.) y objetos personalizados. Recorre recursivamente todos los miembros del objeto y crea una copia completamente independiente. Esto permite modificar la copia sin afectar el objeto original.
- Ejemplo de copia profunda y copia superficial
Al copiar un objeto, **copia profunda (copia profunda) y copia superficial (copia superficial)** son dos formas diferentes.
Una copia superficial es la creación de un nuevo objeto que es una copia del objeto original. Aquí hay un ejemplo de una copia superficial:
import copy
# 创建一个包含列表的原始对象
original_list = [1, 2, [3, 4]]
# 进行浅拷贝
shallow_copy = copy.copy(original_list)
# 修改副本的列表元素
shallow_copy[2][0] = 5
# 输出原始对象的列表元素
print(original_list) # 输出: [1, 2, [5, 4]]
# 输出副本对象的列表元素
print(shallow_copy) # 输出: [1, 2, [5, 4]]
Una copia profunda es la creación de un nuevo objeto que es una copia completamente independiente del objeto original y todos sus subobjetos. Aquí hay un ejemplo de una copia profunda:
import copy
# 创建一个包含列表的原始对象
original_list = [1, 2, [3, 4]]
# 进行深拷贝
deep_copy = copy.deepcopy(original_list)
# 修改副本的列表元素
deep_copy[2][0] = 5
# 输出原始对象的列表元素
print(original_list) # 输出: [1, 2, [3, 4]]
# 输出副本对象的列表元素
print(deep_copy) # 输出: [1, 2, [5, 4]]
Resumen: una copia superficial copia el objeto y sus referencias, mientras que una copia profunda copia el objeto y todos sus subobjetos para crear una copia completamente independiente.
muestra aleatoria
random.samplees una función en Python utilizada para extraer aleatoriamente un número específico de elementos de una secuencia dada . Devuelve una nueva lista que contiene los resultados muestreados aleatoriamente sin alterar la secuencia original. Aquí hay un random.sampleejemplo usando:
import random
# 创建一个列表
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 从列表中随机抽取3个元素
sampled_list = random.sample(my_list, 3)
# 输出抽样结果
print(sampled_list)
En el ejemplo anterior, primero creamos una my_listlista llamada que contiene los números del 1 al 10. Luego, usamos random.samplela función para extraer my_listaleatoriamente y almacenarlos sampled_listen .
最后,我们输出了抽样结果,即随机抽取的3个元素。由于 random.sample 函数保证了抽样结果中的元素是唯一的,且与原始列表中的顺序无关,所以每次运行结果可能会有所不同。
注意,当抽样的数量等于原始序列的长度时,random.sample 返回的结果就是原始序列的一个随机排列(相当于洗牌操作)。如果抽样数量大于原始序列的长度,会引发 ValueError 异常。

random.shuffle
random.shuffle 是 Python 中用于随机打乱给定序列的函数。**它会直接修改原始序列,将元素重新排列,形成一个随机的顺序。**下面是一个使用 random.shuffle 的示例:
import random
# 创建一个列表
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 打乱列表元素的顺序
random.shuffle(my_list)
# 输出打乱后的列表
print(my_list)
在上面的示例中,我们首先创建了一个名为 my_list 的列表,其中包含数字 1 到 10。然后,我们使用 random.shuffle 函数对 my_list 进行打乱操作,直接修改了原始列表。
最后,我们输出打乱后的列表,即元素顺序已经随机改变。每次运行结果可能会不同,因为 random.shuffle 会根据随机算法对元素进行重新排列。
需要注意的是,random.shuffle 函数只能应用于可变序列,如列表。对于不可变序列(如字符串或元组),会引发 TypeError 异常。如果你想在不修改原始序列的情况下获取一个随机排列的序列,可以使用 random.sample 函数。

global_param.data和global_param.grad
-
global_param.data:这是指模型参数,比如神经网络中的权重和偏置等。
-
global_param.grad:这是模型参数对应的梯度,即误差函数对这个参数的导数。
Para el entrenamiento del modelo, necesitamos calcular el gradiente (global_param.grad) para saber cómo actualizar los parámetros del modelo (global_param.data) para reducir la función de pérdida. Por lo general, después de haber calculado todos los gradientes, llamaremos al método step() del optimizador para actualizar los parámetros de acuerdo con estos gradientes.
En este código, cuando se cumple la condición if global_param.grad is not None, agregamos el gradiente del cliente (local_param.grad) al gradiente correspondiente del modelo global. Esto está haciendo agregación de gradientes, es decir, calculando el promedio de todos los gradientes de clientes. Estos gradientes luego se usan para actualizar los parámetros del modelo global al llamar a global_optimizer.step().
El caso de la rama else es cuando no hay un gradiente correspondiente para un determinado parámetro de un determinado modelo de cliente (tal vez porque este parámetro no necesita actualizarse en los datos del cliente, por lo que el gradiente no se calcula), directamente use el valor del parámetro del cliente Agregado a los parámetros correspondientes del modelo global. Tenga en cuenta que la adición aquí es en realidad una asignación, porque global_param.data = global_param.data + local_param.data - global_param.data es equivalente a global_param.data = local_param.data. Esta parte del código en realidad puede parecer redundante y puede ser más intuitivo para nosotros asignar valores directamente.
En cuanto a por qué no es otra cosa: global_param.grad = global_param.grad + local_param.grad - global_param.grad, es porque este código trata el caso en el que no se calcula el gradiente, no el caso en el que no hay un valor de parámetro. Cuando no hay gradiente, generalmente pensamos que el parámetro no necesita actualizarse en este entrenamiento, por lo que usamos directamente el valor del parámetro del cliente como el valor del parámetro del modelo global.
Cargue un modelo previamente guardado y continúe entrenando
Para cargar un modelo previamente guardado y continuar con el entrenamiento, puede usar torch.loadel método para cargar los parámetros del modelo y model.load_state_dict()el método para cargar los parámetros en el modelo. Aquí hay un ejemplo:
# 加载保存的模型参数
saved_model_path = 'global_model_round_10.pt' # 选择你要加载的模型文件
saved_model_state = torch.load(saved_model_path)
# 创建一个新的模型实例
global_model = Net().to(device)
# 加载保存的参数到模型
global_model.load_state_dict(saved_model_state)
# 创建优化器
global_optimizer = optim.Adam(global_model.parameters(), lr=0.007)
# 继续训练模型
for round in range(10, num_rounds): # 从第11轮开始训练,因为我们已经训练过10轮了
local_models = [deepcopy(global_model) for _ in range(num_clients)]
local_optimizers = [optim.Adam(model.parameters(), lr=0.007) for model in local_models]
selected_clients = np.random.choice(range(num_clients), size=num_selected, replace=False)
for client in selected_clients:
train(local_models[client], device, client_loaders[client], local_optimizers[client])
for client in selected_clients:
for global_param, local_param in zip(global_model.parameters(), local_models[client].parameters()):
if global_param.grad is not None:
global_param.grad += local_param.grad / num_selected
else:
global_param.data = global_param.data + local_param.data - global_param.data
global_optimizer.step()
# 保存模型参数
torch.save(global_model.state_dict(), 'global_model_round_{}.pt'.format(round+1))
print('Round {} of {}'.format(round+1, num_rounds))
En este código, primero cargamos los parámetros del modelo guardados saved_model_state, luego creamos una nueva instancia del modelo global_modely cargamos los parámetros del modelo cargado en esta nueva instancia del modelo. Luego creamos un optimizador global_optimizery usamos este modelo con parámetros cargados para el entrenamiento. Tenga en cuenta que nuestro número de épocas de entrenamiento comienza en 11, dado que ya tenemos los resultados de entrenamiento para 10 épocas.
De esta manera, podemos continuar entrenando el modelo en función de los parámetros del modelo guardado.
Acerca del número de veces para recorrer los parámetros del modelo global y el modelo local
Simplifica el modelo:
# 定义一个 CNN 模型:
# CNN模型定义
class Net(nn.Module):# batch_size, 3, 32, 32
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) # conv1: batch_size, 6, 28, 28; pool: batch_size, 6, 14, 14
x = self.pool(F.relu(self.conv2(x))) # conv2: batch_size, 16, 10, 10; pool: batch_size, 16, 5, 5
x = x.view(-1, 16 * 5 * 5) # 展平: batch_size, 400
x = F.relu(self.fc1(x)) # batch_size, 120
x = F.relu(self.fc2(x)) # batch_size, 84
x = self.fc3(x) # batch_size, 10
return x
P: ¿Cuántas veces se ejecutará este bucle para global_param, local_param en zip(global_model.parameters(), local_models[idx_selected_clients].parameters())
Respuesta: for global_param, local_param in zip(global_model.parameters(), local_models[idx_selected_clients].parameters())El número de ejecuciones del bucle depende del número de parámetros del modelo.
En este ciclo, iteramos sobre los parámetros tanto del modelo global como del modelo local. global_paramCada ciclo sacará un conjunto de parámetros ( suma ) correspondientes al modelo global y al modelo local local_param, y luego actualizará el gradiente del modelo global de acuerdo con la información de gradiente del modelo local.
Para un tipo particular de modelo (por ejemplo, la clase definida anteriormente Net), el número de parámetros es fijo. Para Netla clase, tenemos dos capas convolucionales y tres capas completamente conectadas, cada una con dos conjuntos de parámetros para pesos y sesgos, por lo que hay 10 conjuntos de parámetros en total. Entonces, si estuviéramos usando Netun modelo de clase, el ciclo se ejecutaría 10 veces.
En cada ronda de aprendizaje federado, ejecutaremos este bucle para cada cliente seleccionado, por lo que el número total de ejecuciones será 10 (número de grupos de parámetros) por 10 (número de clientes seleccionados), es decir, 100 veces.