2016-ICLR-Agregación de contexto multiescala por convoluciones dilatadas
Agregación de contexto multiescala mediante convoluciones dilatadas
Resumen
Los modelos de última generación 语义分割se basan en adaptaciones diseñadas originalmente para la clasificación de imágenes 卷积网络. Sin embargo, los problemas de predicción densa, como la segmentación semántica, son estructuralmente diferentes de la clasificación de imágenes. En este trabajo, desarrollamos un nuevo módulo de red convolucional 密集预测diseñado específicamente para. El módulo propuesto se utiliza 扩张卷积para agregar sistemáticamente información contextual de múltiples escalas sin perder resolución. La arquitectura se basa en el hecho de que las convoluciones dilatadas soportan la expansión exponencial del campo receptivo sin pérdida de resolución o cobertura. Mostramos que el módulo de contexto presentado mejora la precisión de los sistemas de segmentación semántica de última generación. Además, examinamos la adaptabilidad de las redes de clasificación de imágenes a predicciones densas y mostramos que simplificar la red adaptativa mejora la precisión.
1. Introducción
Muchos problemas naturales de la visión por computadora son ejemplos de predicción densa. El objetivo es calcular una etiqueta discreta o continua para cada píxel de la imagen . Un ejemplo destacado es la segmentación semántica, que requiere clasificar cada píxel en un conjunto determinado de categorías (He et al, 2004; Shotton et al, 2009; Kohli et al, 2009; Krahenb¨uhl & Koltun, 2011). La segmentación semántica es un desafío porque requiere combinar la precisión a nivel de píxel con el razonamiento contextual a múltiples escalas (He et al, 2004; Galleguillos & Belongie, 2010).
Recientemente, se obtuvieron mejoras significativas en la precisión en la segmentación semántica mediante el uso de redes convolucionales (LeCun et al, 1989) entrenadas mediante retropropagación (Rumelhart et al, 1986) . Específicamente, Long y otros (2015) demostraron que una arquitectura de red convolucional desarrollada originalmente para la clasificación de imágenes puede reutilizarse con éxito para una predicción densa. Estas redes reutilizadas superan significativamente a las técnicas existentes en los desafiantes puntos de referencia de segmentación semántica. Esto plantea nuevas preguntas que surgen de las diferencias estructurales entre la clasificación de imágenes y la predicción densa. ¿Qué aspectos de la red son realmente necesarios para reutilizar y qué aspectos degradan la precisión cuando se operan de manera intensiva ? ¿Podrían los módulos especializados diseñados específicamente para predicciones densas mejorar aún más la precisión ?
Las redes modernas de clasificación de imágenes integran información contextual de múltiples escalas a través de sucesivas capas de agrupación y reducción de resolución que reducen la resolución hasta que se obtienen predicciones globales (Krizhevsky et al, 2012; Simonyan & Zisserman, 2015). Por el contrario, la predicción densa requiere combinar resultados de resolución completa para un razonamiento contextual a múltiples escalas . Trabajos recientes han investigado dos enfoques para manejar las demandas conflictivas de la inferencia multiescala y la predicción densa de resolución completa. Un enfoque implica convoluciones ascendentes repetidas con el objetivo de recuperar la resolución perdida mientras se hereda la perspectiva global de las capas de reducción de resolución (Noh et al, 2015; Fischer et al, 2015). Esto deja abierta la pregunta de si es realmente necesaria una reducción de resolución intermedia estricta . Otro enfoque implica proporcionar múltiples versiones reescaladas de una imagen como entrada a la red y combinar las predicciones obtenidas para estas múltiples entradas (Farabet et al, 2013; Lin et al, 2015; Chen et al, 2015b). Tampoco está claro si es realmente necesario un análisis por separado de las imágenes de entrada reescaladas.
En este trabajo, desarrollamos un módulo de red convolucional que agrega información contextual de múltiples escalas sin perder resolución ni analizar imágenes reescaladas . El módulo se puede conectar a arquitecturas existentes en cualquier resolución . A diferencia de la arquitectura en forma de pirámide heredada de la clasificación de imágenes, el módulo de contexto presentado está diseñado para una predicción densa. Es una capa convolucional de prismas rectangulares sin agrupación ni reducción de resolución. Este módulo se basa en convoluciones dilatadas , lo que permite la expansión exponencial del campo receptivo sin pérdida de resolución ni cobertura.
Como parte de este trabajo, también reexaminamos el rendimiento de las redes de clasificación de imágenes reutilizadas para la segmentación semántica . El rendimiento de los módulos de predicción centrales puede verse oscurecido inadvertidamente por sistemas cada vez más complejos que involucran predicciones estructuradas, esquemas de múltiples columnas, múltiples conjuntos de datos de entrenamiento y otras mejoras. Por lo tanto, investigamos la principal adaptabilidad de las redes de clasificación de imágenes profundas en entornos controlados y eliminamos los componentes residuales que obstaculizan el rendimiento de la predicción densa. El resultado es un módulo de predicción inicial que es más simple y preciso que los ajustes anteriores.
Utilizando un módulo de predicción simplificado, evaluamos la red de contexto presentada a través de experimentos controlados en el conjunto de datos Pascal VOC 2012 (Everingham et al, 2010). Los experimentos muestran que insertar módulos de contexto en arquitecturas de segmentación semántica existentes puede mejorar de manera confiable su precisión .
2. Convolución dilatada
令F : Z 2 → RF\ : \ \mathbb{Z}^2\rightarrow\mathbb{R}F : z2→R es una función discreta. SeaΩr = [ − r , r ] 2 ∩ Z 2 \Omega_r=\left[-r,\ r\right]^2\cap\mathbb{Z}^2Ohr=[ -r , _ r ]2∩z2Y seak : Ω r → R de tamaño ( 2 r + 1 ) 2 k\ : \ \Omega_r\rightarrow\mathbb{R} de tamaño \left(2r+1\right)^2k : Ohr→R es de tamaño( 2 r.+1 )2 filtros discretos. Operador de convolución discreto∗ \ast∗ se puede definir como
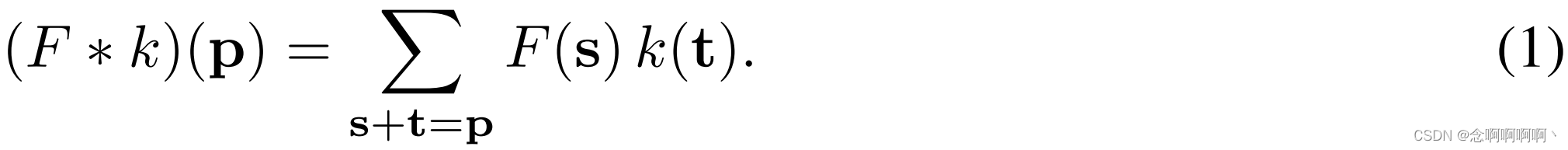
Ahora generalizamos este operador. vamos _l es el factor de expansión, sea∗ l \ast_l∗yodefinido como
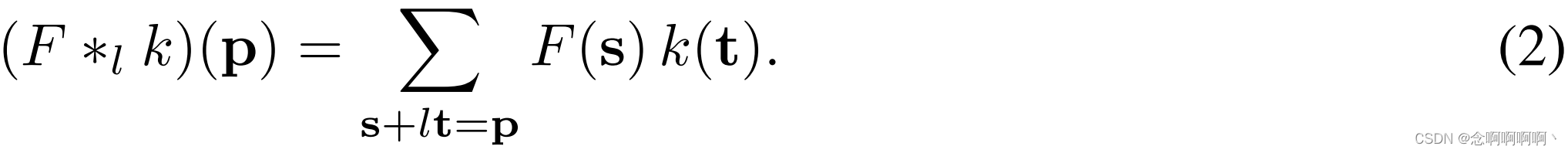
Lo haremos ∗ l \ast_l∗yollamada convolución dilatada o lll - convolución dilatada. Convolución discreta familiar∗ \ast∗ es1 1Convolución unidimensional .
El operador de convolución dilatada se conocía antiguamente como "convolución con filtro dilatado". Desempeña un papel clave en el algoritmo a trous, un algoritmo de descomposición de ondas (Holschneider et al, 1987; Shensa, 1992). Usamos el término "convolución dilatada" en lugar de "convolución con filtro de dilatación" para aclarar que "filtro de dilatación" no está construido ni significa. El propio operador de convolución se modificó para utilizar los parámetros del filtro de forma diferente. El operador de convolución dilatada puede aplicar el mismo filtro en diferentes rangos utilizando diferentes factores de dilatación . Nuestra definición refleja una implementación correcta del operador de convolución dilatada, que no implica la construcción de un filtro dilatado.
En un trabajo reciente sobre redes convolucionales para segmentación semántica, Long et al. (2015) analizaron la dilatación del filtro pero decidieron no utilizarla. Chen y otros (2015a) utilizan la dilatación para simplificar la arquitectura de Long y otros (2015). Por el contrario, desarrollamos una nueva arquitectura de red convolucional que utiliza sistemáticamente convoluciones dilatadas para la agregación de contextos de múltiples escalas.
Nuestra arquitectura está motivada por el hecho de que las convoluciones dilatadas permiten una expansión exponencial del campo receptivo sin perder resolución o cobertura . Sea F 0 , F 1 , . . . , F n − 1 : Z 2 → R F_0,F_1,.\ .\ .,F_{n-1}\ : \ \mathbb{Z}^2\rightarrow\mathbb {R}F0,F1,. . . , Fnorte − 1 : z2→R es una función discreta, seak 0 , k 1 , . . . , kn − 2 : Ω 1 → R k_0,k_1,.\ .\ .,k_{n-2}\ : \ \Omega_1\rightarrow\mathbb {R}k0,k1,. . . , knorte − 2 : Oh1→R es un filtro discreto de 3×3. Considere aplicar un filtro con expansión de crecimiento exponencial:
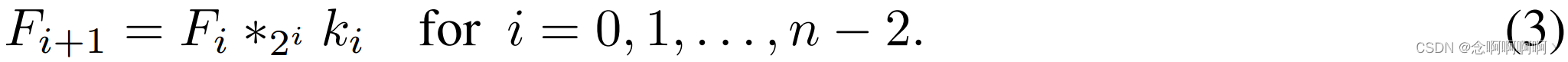
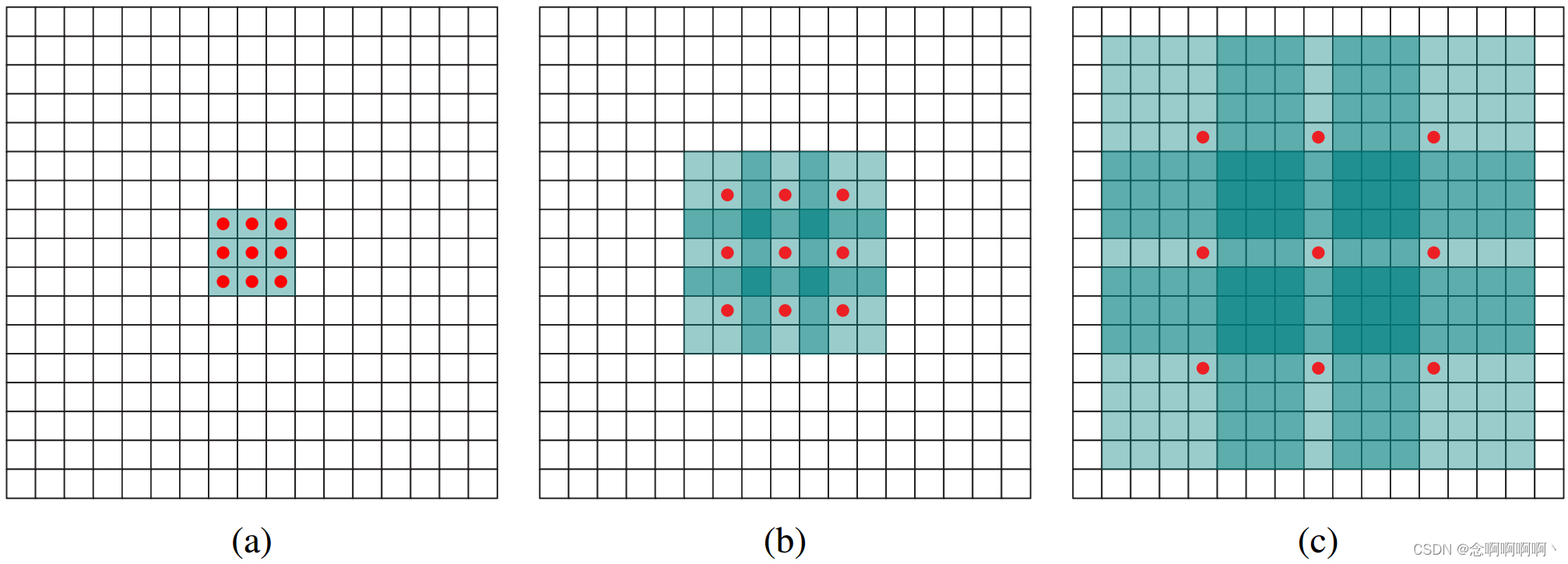
将F i + 1 F_{i+1}Fyo + 1Elemento medio p \mathbf{p}El campo receptivo de p se define comoF 0 F_0F0Modificar F i + 1 ( p ) F_{i+1}\left(\mathbf{p}\right)Fyo + 1Una colección de elementos con valores ( p ) . SeaF i + 1 F_ {i+1}Fyo + 1© p \mathbf{p}El tamaño del campo receptivo de p es el número de estos elementos. No es difícil ver queF i + 1 F_{i+1}Fyo + 1El tamaño del campo receptivo de cada elemento es ( 2 i + 1 − 1 ) × ( 2 i + 2 − 1 ) \left(2^{i+1}-1\right)\times\left(2^{i +2}-1\derecha)( 2yo + 1−1 )×( 2yo + 2−1 ) . El campo receptivo es un cuadrado que crece exponencialmente. Como se muestra en la Figura 1.
3. Agregación de contexto multiescala
El módulo de contexto tiene como objetivo mejorar el rendimiento de arquitecturas de predicción densas agregando información contextual de múltiples escalas . Este módulo CCMapa de características de C como entrada y generarCCMapa de características de C como salida. Las entradas y salidas tienen la misma forma, por lo que el módulo se puede conectar a arquitecturas de predicción densas existentes.
Primero describimos la forma básica del módulo de contexto. En esta forma básica, cada capa tiene CCCanales C. La representación en cada capa es idéntica y se puede utilizar para obtener directamente predicciones densas por clase, aunque los mapas de características no están normalizados y no hay pérdida definida dentro del módulo. De manera intuitiva,este módulo puede mejorar la precisión de los mapas de características al pasarlos a múltiples capas que exponen información contextual.
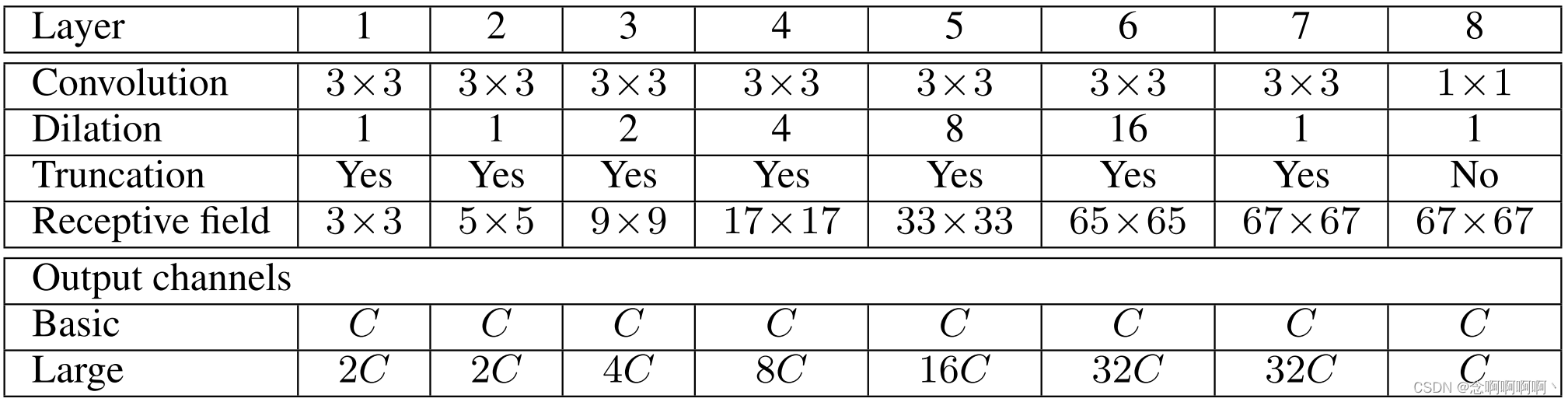
El módulo de contexto básico tiene 7 capas y aplica convoluciones de 3×3 con diferentes factores de dilatación. Las expansiones son 1, 1, 2, 4, 8, 16 y 1. Cada convolución opera en todas las capas: estrictamente hablando, estas son 3 × 3 × C 3\times3\times C3×3×C convolución con dilatación en las dos primeras dimensiones. Cada una de estas convoluciones va seguida de un truncamiento puntualmax ( ⋅ , 0 ) max(·,0)máx ( ⋅ ,0 ) . La última capa ejecuta1 × 1 × C 1\times1\times C1×1×C convoluciona y produce la salida del módulo. La arquitectura se resume en la Tabla 1. Tenga en cuenta que en nuestros experimentos, el módulo frontal que proporciona entrada a la red contextual genera mapas de características con una resolución de 64 × 64. Por tanto, detenemos la expansión exponencial del campo receptivo después de la capa 6.
Nuestros intentos iniciales de entrenar módulos de contexto no lograron mejorar la precisión de la predicción. Los experimentos muestran que los procedimientos de inicialización estándar no respaldan fácilmente la capacitación del módulo . Las redes convolucionales normalmente se inicializan utilizando muestras de una distribución aleatoria (Glorot & Bengio, 2010; Krizhevsky et al, 2012; Simonyan & Zisserman, 2015). Sin embargo, descubrimos que el esquema de inicialización aleatoria no era efectivo para los módulos de contexto. Encontramos una inicialización alternativa con una semántica clara que es más eficiente :

entre ellos aaa es el índice del mapa de características de entrada,bbb es el índice del mapa de características de salida. Esta es una forma de inicialización de identidad que se ha defendido recientemente para redes recurrentes (Le et al, 2015). Esta inicialización configura todos los filtros para que cada capa pase la entrada directamente a la siguiente capa. Una preocupación natural es que esta inicialización pueda poner a la red en un modo en el que la retropropagación no pueda mejorar significativamente el comportamiento predeterminado de simplemente pasar información. Sin embargo, los experimentos demuestran que este no es el caso. La retropropagación recopila de manera confiable información contextual proporcionada por la red para mejorar la precisión de los mapas de características procesados.
Esto completa la presentación de la red de contexto básica. Nuestros experimentos muestran que incluso este módulo básico puede mejorar cuantitativa y cualitativamente la precisión de predicciones densas. Esto es especialmente digno de mención dada la pequeña cantidad de parámetros en la red: ≈ 64 C 2 \approx64C^2 en total≈64C _2 parámetros.
También entrenamos una red de contexto más grande que utiliza más mapas de características en capas más profundas . La Tabla 1 resume la cantidad de mapas de características en redes grandes. Generalizamos el esquema de inicialización para tener en cuenta las diferencias en la cantidad de mapas de características en diferentes capas. deja ci c_iCyoy ci + 1 c_ {i+1}Cyo + 1es el número de mapas de características en dos capas consecutivas. Suponiendo CCC divideci c_iCyoy ci + 1 c_ {i+1}Cyo + 1. la inicialización es
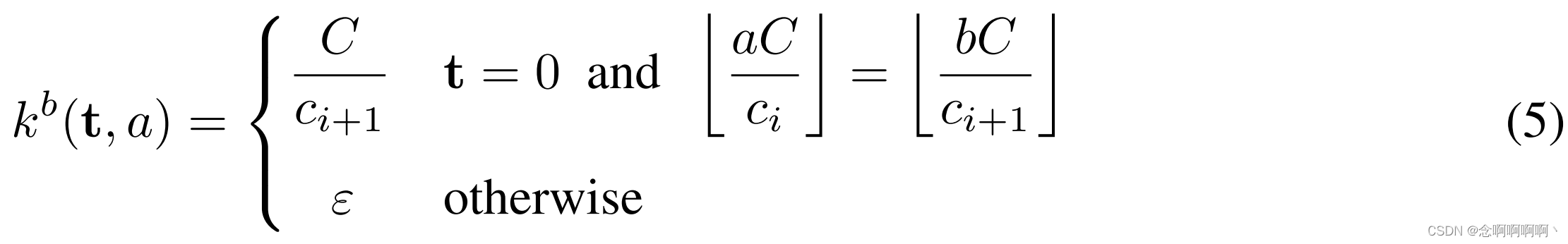
Definición ∼ N ( 0 , σ 2 ) \varepsilon\sim\mathcal{N}\left(0,\\sigma^2\right)mi∼norte( 0 , pag2 )和σ ≪ C / ci + 1 \sigma\ll C/c_{i+1}pag≪c / cyo + 1. El uso de ruido aleatorio rompe la conexión entre los mapas de características con sus predecesores comunes.
4. Interfaz
Implementamos y entrenamos un módulo de predicción frontal que toma imágenes en color como entrada y genera C=21 C=21C=Se utilizan 21 mapas de características como salida. El módulo de interfaz sigue el trabajo de Long y otros (2015) y Chen y otros (2015a), pero se implementa por separado. Adaptamosla red VGG-16(Simonyan & Zisserman, 2015) para una predicción densa yeliminamos las dos últimas capas de agrupación y zancada. Específicamente, cada una de estas capas de agrupación y expansión se eliminan, y para cada capa de agrupación eliminada, las convoluciones en todas las capas posteriores se dilatan en un factor de 2. Por lo tanto, las convoluciones en la última capa después de las dos capas de agrupación ablativa se amplían en un factor de 4. Esto permite la inicialización utilizando los parámetros de la red de clasificación original, pero produciendo resultados de mayor resolución. El módulo frontal toma imágenes de relleno como entrada y genera mapas de características con una resolución de 64 × 64. Usamos relleno de reflexión:llenamos el búfer reflejando la imagen desde cada borde.
Nuestro módulo frontal se obtiene eliminando los residuos en la red de clasificación que no conducen a predicciones densas . Lo más importante es que eliminamos por completo las dos últimas capas de acumulación y la capa estriada, mientras que Long y otros las retienen, mientras que Chen y otros reemplazan la capa estriada con dilatación pero retienen la capa de acumulación. Descubrimos que simplificar la red eliminando la capa de agrupación la hacía más precisa . También eliminamos el relleno de los mapas de características intermedias. El relleno intermedio se utiliza en redes de clasificación originales, pero no es necesario ni está justificado en predicciones densas .
Este módulo de predicción simplificado se entrena en el conjunto de entrenamiento Pascal VOC 2012 y se complementa con anotaciones creadas por Hariharan et al. (2011). No utilizamos imágenes del conjunto de validación VOC-2012 para el entrenamiento y, por lo tanto, solo utilizamos un subconjunto de las anotaciones de Hariharan et al. (2011). El entrenamiento se realiza mediante descenso de gradiente estocástico (SGD) con un tamaño de minilote de 14, una tasa de aprendizaje de 10 -3 y un impulso de 0,9. La red está entrenada para 60.000 iteraciones.
Ahora comparamos la precisión de nuestro módulo frontal con el diseño FCN-8 de Long y otros (2015) y la red DeepLab de Chen y otros (2015a). Para FCN-8 y DeepLab, evaluamos modelos públicos entrenados en VOC-2012 por los autores originales. La Figura 2 muestra las segmentaciones producidas por diferentes modelos en imágenes del conjunto de datos VOC-2012. La Tabla 2 informa la precisión del modelo en el conjunto de pruebas VOC-2012.
Nuestro módulo de predicción frontal es más simple y preciso que los modelos anteriores. Específicamente, nuestro modelo simplificado supera a las redes FCN-8 y DeepLab en más de 5 puntos porcentuales en el conjunto de prueba. Curiosamente, sin utilizar CRF, nuestro módulo frontal simplificado supera a DeepLab + CRF en la precisión de la tabla de clasificación en el conjunto de pruebas en más de un punto porcentual (67,6 % frente a 66,4 %).


5. Experimentar
Nuestra implementación se basa en la biblioteca Caffe (Jia et al, 2014). Nuestra implementación de convoluciones dilatadas ahora es parte de la distribución estándar de Caffe.
Para una comparación justa con los sistemas recientes de alto rendimiento, entrenamos un módulo de interfaz de usuario con la misma estructura que se describe en la Sección 4, pero entrenamos con imágenes adicionales del conjunto de datos COCO de Microsoft (Lin et al., 2014). Usamos todas las imágenes de Microsoft COCO con al menos un objeto de la categoría VOC-2012. Los objetos anotados de otras categorías se consideran de fondo.
La formación se lleva a cabo en dos fases. En la primera etapa, entrenamos juntas en imágenes VOC-2012 e imágenes COCO de Microsoft. El entrenamiento lo realiza SGD con un tamaño de minilote 14 y un impulso de 0,9. Realice 100.000 iteraciones con una tasa de aprendizaje de 10 -3 y 40.000 iteraciones posteriores con una tasa de aprendizaje de 10 -4 . En la segunda etapa, ajustamos la red solo en imágenes VOC-2012. El ajuste fino se realizó para 50.000 iteraciones con una tasa de aprendizaje de 10-5 . Las imágenes del conjunto de validación VOC-2012 no se utilizaron para el entrenamiento.
El módulo de front-end entrenado a través de este proceso logró un IoU promedio del 69,8 % en el conjunto de validación VOC-2012 y un IoU promedio del 71,3 % en el conjunto de prueba. Tenga en cuenta que este nivel de precisión se logra únicamente con la interfaz, sin módulos de contexto ni predicciones estructuradas . Nuevamente atribuimos esta alta precisión en parte a la eliminación de componentes residuales desarrollados originalmente para la clasificación de imágenes en lugar de una predicción densa.
Evaluación controlada de agregación de contexto . Ahora realizamos experimentos controlados para evaluar la utilidad de la red de contexto presentada en la Sección 3. Comenzamos insertando dos módulos de contexto (Básico y Grande) en la interfaz respectivamente. Dado que el campo receptivo de la red de contexto es 67 × 67, llenamos el mapa de características de entrada con un búfer de ancho 33. El acolchado cero y el acolchado reflectante produjeron resultados similares en nuestros experimentos . El módulo de contexto acepta mapas de características del front-end como entrada y obtiene esta entrada durante el entrenamiento. En nuestros experimentos, la capacitación conjunta de módulos de contexto y módulos de front-end no produjo mejoras significativas . La tasa de aprendizaje se establece en 10 -3 . Inicialice el entrenamiento como se describe en la Sección 3.
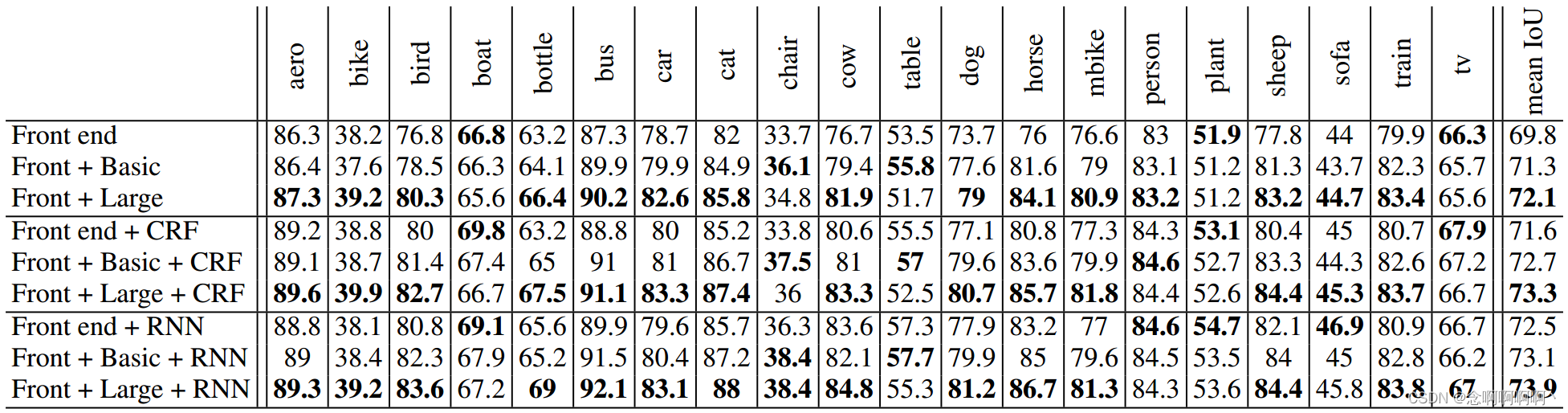
La Tabla 3 muestra el efecto de agregar módulos de contexto a tres arquitecturas de segmentación semántica diferentes. La primera arquitectura (arriba) es la interfaz descrita en la Sección 4. Realiza segmentación semántica sin predicción estructurada, similar al trabajo original de Long et al. (2015). La segunda arquitectura (Tabla 3, centro) utiliza CRF densos para realizar predicciones estructuradas, similar al sistema de Chen et al. (2015a). Usamos la implementación de Krahenb¨uhl & Koltun (2011) y entrenamos los parámetros CRF realizando una búsqueda en cuadrícula en el conjunto de validación. La tercera arquitectura (Tabla 3, abajo) utiliza CRF-RNN para predicción estructurada (Zheng et al., 2015). Utilizamos la implementación de Zheng et al. (2015) y entrenamos CRF-RNN en cada condición.
Los resultados experimentales muestran que el módulo de contexto mejora la precisión en cada una de las tres configuraciones . El módulo de contexto básico mejora la precisión de cada configuración. El gran módulo de contexto mejora significativamente la precisión. Los experimentos muestran que los módulos de contexto y las predicciones estructuradas son sinérgicos: los módulos de contexto mejoran la precisión con o sin predicciones estructuradas posteriores. Los resultados cualitativos se muestran en la Figura 3.

Evaluación en el set de prueba . Ahora evaluamos el conjunto de pruebas enviando los resultados al servidor de evaluación Pascal VOC 2012. Los resultados se presentan en la Tabla 4. Realizamos estos experimentos utilizando un módulo de contexto grande. Como muestran los resultados, el módulo de contexto proporciona mejoras significativas en la precisión del front-end. Un módulo de contexto separado, sin predicciones estructuradas posteriores, supera a DeepLab-CRF-COCO-LargeFOV (Chen et al, 2015a). El módulo de contexto con CRF denso, que utiliza la implementación original de Krahenb¨uhl y Koltun (2011), funciona a la par con el reciente CRF-RNN (Zheng et al, 2015). El módulo de contexto se combina con CRF-RNN para mejorar aún más la precisión del rendimiento de CRF-RNN .
6. Conclusión
Hemos examinado arquitecturas de redes convolucionales para una predicción densa. Dado que el modelo debe producir resultados de alta resolución, creemos que operar a alta resolución en toda la red es factible y deseable. Nuestro trabajo muestra que el operador de convolución dilatada es particularmente adecuado para predicciones densas debido a su capacidad para expandir el campo receptivo sin perder resolución o cobertura. Utilizamos convoluciones dilatadas para diseñar una nueva estructura de red que mejora de manera confiable la precisión cuando se conecta a sistemas de segmentación semántica existentes. Como parte de este trabajo, también mostramos que la precisión de las redes convolucionales existentes para la segmentación semántica se puede mejorar eliminando los componentes residuales desarrollados para la clasificación de imágenes.。
Creemos que el trabajo propuesto es un paso hacia una arquitectura dedicada para la predicción densa que no esté limitada por los precursores de clasificación de imágenes. A medida que surjan nuevas fuentes de datos, las arquitecturas futuras podrán capacitarse intensivamente de extremo a extremo, eliminando la necesidad de capacitación previa en conjuntos de datos de clasificación de imágenes. Esto permite la simplificación y unificación arquitectónica. Específicamente, el entrenamiento denso de extremo a extremo puede permitir que arquitecturas completamente densas similares a la red de contexto presentada siempre se ejecuten a resolución completa, acepten imágenes sin procesar como entrada y generen asignaciones de etiquetas densas a resolución completa como salida.。
Los sistemas de segmentación semántica de última generación dejan un gran margen para el desarrollo futuro. La Figura 4 muestra el caso de falla de nuestra configuración más precisa. Publicaremos nuestro código y modelos capacitados para respaldar el progreso en el campo.。

referencias
Badrinarayanan, Vijay, Handa, Ankur y Cipolla, Roberto. SegNet: una arquitectura de codificador-decodificador convolucional profunda para un etiquetado semántico robusto por píxeles. arXiv:1505.07293, 2015.
Brostow, Gabriel J., Fauqueur, Julien y Cipolla, Roberto. Clases de objetos semánticos en vídeo: una base de datos real de alta definición. Pattern Recognition Letters, 30(2), 2009.
Chen, Liang-Chieh, Papandreou, George, Kokkinos, Iasonas, Murphy, Kevin y Yuille, Alan L. Segmentación de imágenes semánticas con redes convolucionales profundas y CRF completamente conectados. En ICLR, 2015a.
Chen, Liang-Chieh, Yang, Yi, Wang, Jiang, Xu, Wei y Yuille, Alan L. Atención a la escala: segmentación de imágenes semánticas conscientes de la escala. arXiv:1511.03339, 2015b.
Cordts, Marius, Omran, Mohamed, Ramos, Sebastian, Rehfeld, Timo, Enzweiler, Markus, Benenson, Rodrigo, Franke, Uwe, Roth, Stefan y Schiele, Bernt. El conjunto de datos Cityscapes para la comprensión semántica de la escena urbana. En CVPR, 2016.
Everingham, Mark, Gool, Luc J. Van, Williams, Christopher KI, Winn, John M. y Zisserman, Andrew. El desafío de las clases de objetos visuales (VOC) de Pascal. IJCV, 88(2), 2010.
Farabet, Clement, Couprie, Camille, Najman, Laurent y LeCun, Yann. Aprendizaje de características jerárquicas para el etiquetado de escenas. PAMI, 35(8), 2013.
Fischer, Philipp, Dosovitskiy, Alexey, Ilg, Eddy, Hausser, Philip, Hazrba, Caner, Golkov, Vladimir, van der ¨ Smagt, Patrick, Cremers, Daniel y Brox, Thomas. Aprendizaje del flujo óptico con redes neuronales convolucionales. En ICCV, 2015.
Galleguillos, Carolina y Belongie, Serge J. Categorización de objetos basada en el contexto: un estudio crítico. Visión por computadora y comprensión de imágenes, 114(6), 2010.
Geiger, Andreas, Lenz, Philip, Stiller, Christoph y Urtasun, Raquel. La visión se encuentra con la robótica: el conjunto de datos KITTI. Revista Internacional de Investigación en Robótica, 32(11), 2013.
Glorot, Xavier y Bengio, Yoshua. Comprender la dificultad de entrenar redes neuronales de retroalimentación profunda. En AISTATS, 2010.
Hariharan, Bharath, Arbelaez, Pablo, Bourdev, Lubomir D., Maji, Subhransu y Malik, Jitendra. Contornos semánticos de detectores inversos. En ICCV, 2011.
Él, Xuming, Zemel, Richard S. y Carreira-Perpin˜an, Miguel ´ ´A. Campos aleatorios condicionales multiescala para etiquetado de imágenes. En CVPR, 2004.
Holschneider, M., Kronland-Martinet, R., Morlet, J. y Tchamitchian, Ph. Un algoritmo en tiempo real para el análisis de señales con la ayuda de la transformada wavelet. En Wavelets: métodos de tiempo-frecuencia y espacio de fases. Actas de la Conferencia Internacional, 1987.
Jia, Yangqing, Shelhamer, Evan, Donahue, Jeff, Karayev, Sergey, Long, Jonathan, Girshick, Ross B., Guadarrama, Sergio y Darrell, Trevor. Caffe: arquitectura convolucional para una rápida incorporación de funciones. En Proc. ACM Multimedia, 2014.
Kohli, Pushmeet, Ladicky, Lubor y Torr, Philip HS Potentes potenciales de orden superior sólidos para hacer cumplir la coherencia de las etiquetas. IJCV, 82(3), 2009.
Krahenb¨uhl, Philipp y Koltun, Vladlen. Inferencia eficiente en CRF completamente conectados con potenciales de borde gaussiano. En NIPS, 2011.
Krizhevsky, Alex, Sutskever, Ilya y Hinton, Geoffrey E. Clasificación ImageNet con redes neuronales convolucionales profundas. En NIPS, 2012.
Kundu, Abhijit, Vineet, Vibhav y Koltun, Vladlen. Optimización del espacio de funciones para la segmentación semántica de videos. En CVPR, 2016.
Ladicky, Lubor, Russell, Christopher, Kohli, Pushmeet y Torr, Philip HS CRF jerárquicos asociativos para la segmentación de imágenes de clases de objetos. En ICCV, 2009.
Le, Quoc V., Jaitly, Navdeep y Hinton, Geoffrey E. Una forma sencilla de inicializar redes recurrentes de unidades lineales rectificadas. arXiv:1504.00941, 2015.
LeCun, Yann, Boser, Bernhard, Denker, John S., Henderson, Donnie, Howard, Richard E., Hubbard, Wayne y Jackel, Lawrence D. La retropropagación aplicada al reconocimiento de códigos postales escritos a mano. Neural Computation, 1(4), 1989.
Lin, Guosheng, Shen, Chunhua, Reid, Ian y van dan Hengel, Anton. Entrenamiento eficiente por partes de modelos estructurados profundos para la segmentación semántica. arXiv:1504.01013, 2015.
Lin, Tsung-Yi, Maire, Michael, Belongie, Serge, Hays, James, Perona, Pietro, Ramanan, Deva, Dollar, Piotr, 'y Zitnick, C. Lawrence. Microsoft COCO: objetos comunes en contexto. En ECCV, 2014.
Liu, Buyu y He, Xuming. Segmentación de vídeo semántica multiclase con inferencia activa a nivel de objeto. En CVPR, 2015.
Long, Jonathan, Shelhamer, Evan y Darrell, Trevor. Redes totalmente convolucionales para segmentación semántica. En CVPR, 2015.
Noh, Hyeonwoo, Hong, Seunghoon y Han, Bohyung. Red de deconvolución de aprendizaje para segmentación semántica. En ICCV, 2015.
Ros, Alemán, Ramos, Sebastián, Granados, Manuel, Bakhtiary, Amir, V ´ azquez, David, y L ´ opez, Anto- ´ nio Manuel. Paradigma de percepción fuera de línea y en línea basado en la visión para la conducción autónoma. En WACV, 2015.
Rumelhart, David E., Hinton, Geoffrey E. y Williams, Ronald J. Aprendizaje de representaciones mediante errores de retropropagación. Nature, 323, 1986.
Shensa, Mark J. La transformada wavelet discreta: uniendo los algoritmos a trous y Mallat. ` Transacciones IEEE sobre procesamiento de señales, 40 (10), 1992.
Shotton, Jamie, Winn, John M., Rother, Carsten y Criminisi, Antonio. TextonBoost para la comprensión de imágenes: reconocimiento y segmentación de objetos multiclase mediante el modelado conjunto de textura, diseño y contexto. IJCV, 81 (1), 2009.
Simonyan, Karen y Zisserman, Andrew. Redes convolucionales muy profundas para reconocimiento de imágenes a gran escala. En ICLR, 2015.
Sturgess, Paul, Alahari, Karteek, Ladicky, Lubor y Torr, Philip HS Combinando apariencia y estructura a partir de características de movimiento para comprender la escena de la carretera. En BMVC, 2009.
Tighe, Joseph y Lazebnik, Svetlana. Superparsing: análisis de imágenes no paramétrico escalable con superpíxeles. IJCV, 101(2), 2013.
Zheng, Shuai, Jayasumana, Sadeep, Romera-Paredes, Bernardino, Vineet, Vibhav, Su, Zhizhong, Du, Dalong, Huang, Chang y Torr, Philip. Campos aleatorios condicionales como redes neuronales recurrentes. En ICCV, 2015.
Apéndice A Comprensión de la escena urbana
En este apéndice, informamos experimentos en tres conjuntos de datos para la comprensión de la escena urbana: el conjunto de datos CamVid (Brostow et al, 2009), el conjunto de datos KITTI (Geiger et al, 2013) y el nuevo conjunto de datos Cityscapes (Cordts et al., 2016). . Como medida de precisión, utilizamos el IoU promedio (Everingham et al, 2010). Solo entrenamos nuestro modelo en el conjunto de entrenamiento, incluso si el conjunto de validación está disponible. Los resultados informados en esta sección no utilizan campos aleatorios condicionales ni otras formas de predicción estructurada. Se obtienen mediante una red convolucional que combina módulos front-end y contextuales, similar a la red “Front + Basic” evaluada en la Tabla 3. El modelo entrenado se puede encontrar en https://github.com/fyu/dilation.
Ahora resumimos el procedimiento de capacitación utilizado para entrenar el módulo front-end. Este procedimiento funciona para todos los conjuntos de datos. Entrenamiento mediante descenso de gradiente estocástico. Cada minilote contiene 8 cultivos de imágenes muestreadas al azar. Cada recorte tiene un tamaño de 628 × 628 y se toma una muestra aleatoria de la imagen de relleno. Rellena la imagen con relleno reflectante. La capa intermedia no utiliza relleno. La tasa de aprendizaje es 10 −4 y el impulso se establece en 0,99. La cantidad de iteraciones depende de la cantidad de imágenes en el conjunto de datos y se informa a continuación para cada conjunto de datos.
Los módulos de contexto utilizados para estos conjuntos de datos son todos de la red "Básica", utilizando la terminología de la Tabla 1. El número de canales en cada capa es la clase CC prevista.Cantidad C. (Por ejemplo, el conjunto de datos Cityscapes tieneC = 19 C=19C=19 ) Cada capa en el módulo de contexto está rellena para que los mapas de entrada y respuesta tengan el mismo tamaño. La cantidad de capas en el módulo de contexto depende de la resolución de las imágenes en el conjunto de datos. A continuación se resume para cada conjunto de datos el entrenamiento conjunto de un modelo completo que consta de módulos de front-end y de contexto.
A.1 CAMVID
Usamos la división de Sturgess et al. (2009) para dividir el conjunto de datos en 367 imágenes de entrenamiento, 100 imágenes de validación y 233 imágenes de prueba. Se utilizan 11 clases semánticas. La imagen se reduce a 640 × 480.
El módulo de contexto tiene 8 capas, similar al modelo utilizado para el conjunto de datos Pascal VOC en el cuerpo principal de este artículo. El proceso general de formación es el siguiente. Primero, el módulo front-end está entrenado para 20.000 iteraciones. Luego, el modelo completo (frontend + contexto) se entrena conjuntamente mediante muestras de tamaño 852 × 852 con un tamaño de lote de 1. La tasa de aprendizaje del entrenamiento conjunto se establece en 10 −5 y el impulso se establece en 0,9.
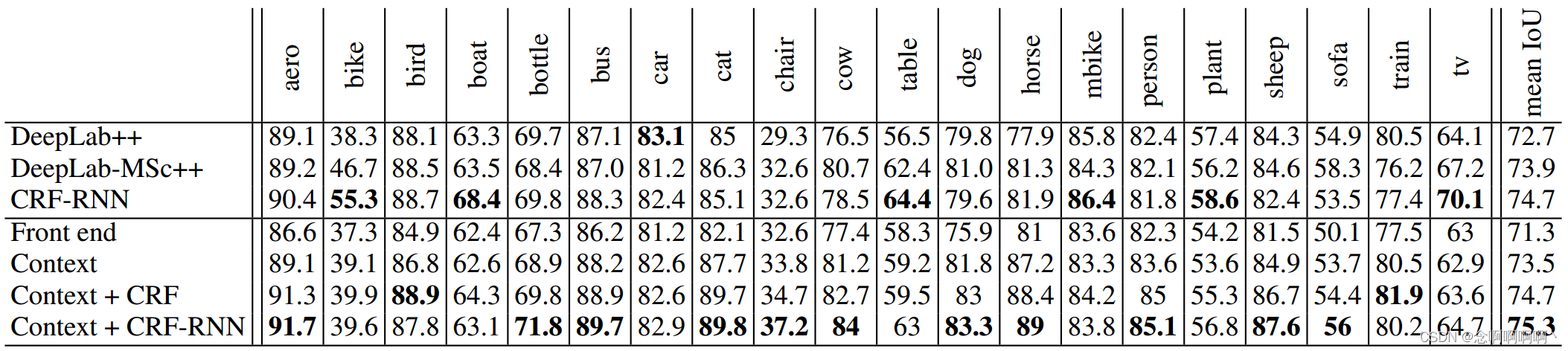
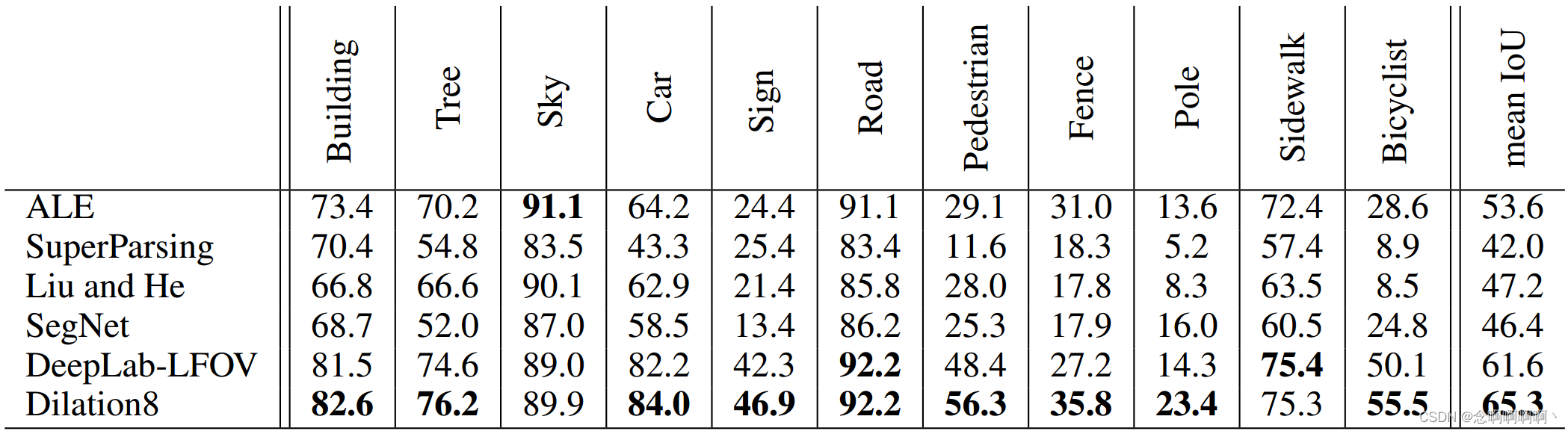
La Tabla 5 informa los resultados del equipo de prueba CamVid. A la red convolucional completa (frontend + contexto) la llamamos Dilación8 porque el módulo de contexto tiene 8 capas. Nuestro modelo supera el trabajo anterior. Este modelo se utilizó como clasificador unario en el trabajo reciente de Kundu et al. (2016).
A.2 KITTI
Utilizamos la división de entrenamiento y validación de Ros et al. (2015): 100 imágenes de entrenamiento y 46 imágenes de prueba. Estas imágenes se obtuvieron del conjunto de datos de odometría visual/SLAM de KITTI. La resolución de la imagen es 1226×370. Eliminamos la capa 6 en la Tabla 1 debido a la resolución vertical más pequeña en comparación con otros conjuntos de datos. El módulo de contexto generado tiene 7 capas. La red completa (frontend + contexto) se llama Dilation7.
La interfaz está entrenada para iteraciones de 10.000. A continuación, se capacitan conjuntamente los módulos front-end y contextual. Para el entrenamiento conjunto, el tamaño del cultivo es 900 × 900, el impulso se establece en 0,99 y otros parámetros son los mismos que los utilizados en el conjunto de datos de CamVid. Se realizó un entrenamiento conjunto durante 20.000 iteraciones.
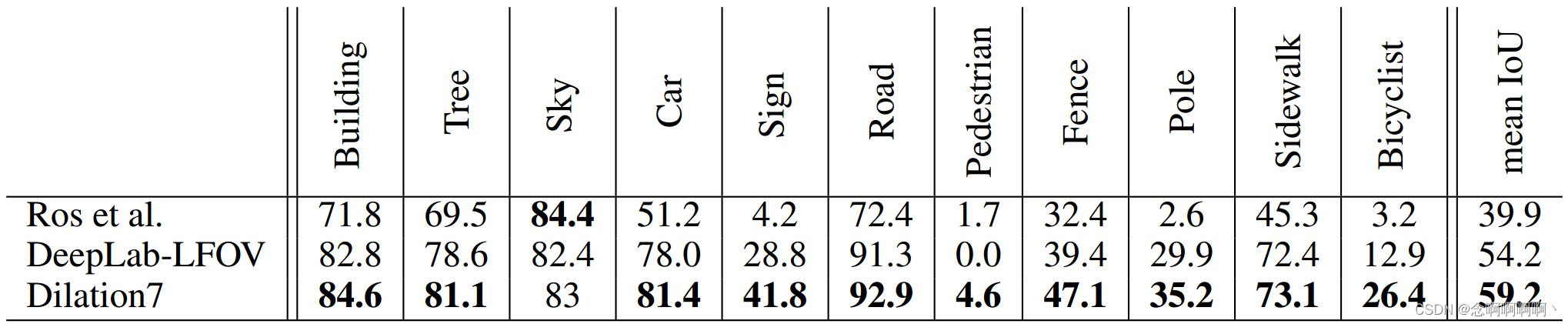
Los resultados se muestran en la Tabla 6. Como se muestra en la tabla, nuestro modelo supera el trabajo anterior.
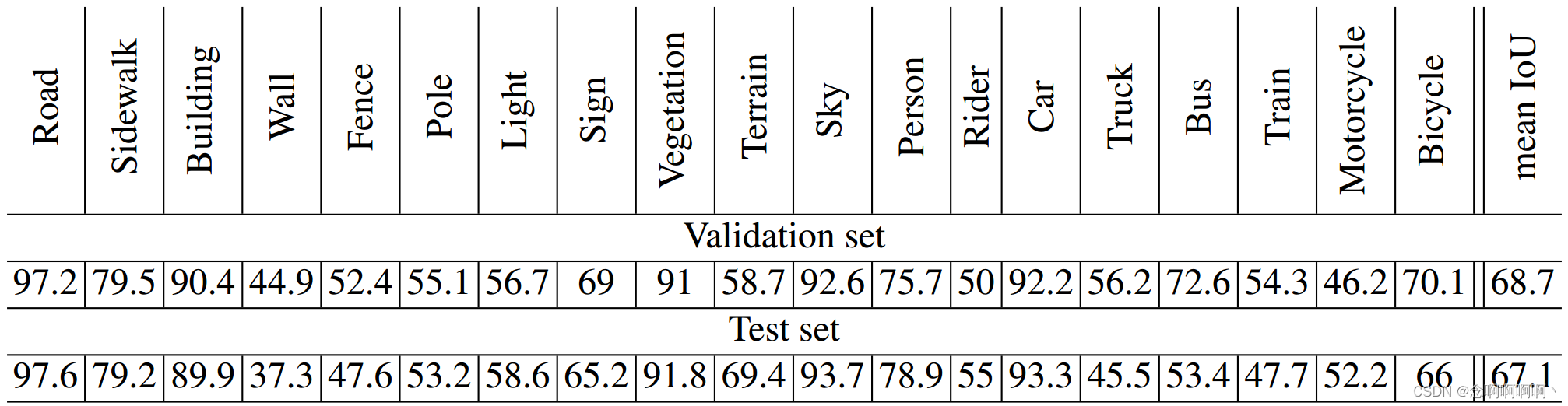
A.3 PAISAJES URBANO
El conjunto de datos de Cityscapes contiene 2975 imágenes de entrenamiento, 500 imágenes de validación y 1525 imágenes de prueba (Cordts et al, 2016). Debido a la alta resolución de la imagen (2048 × 1024), agregamos dos capas a la red de contexto después de la capa 6 en la Tabla 1. Las expansiones de estas dos capas son 32 y 64 respectivamente. El número total de capas en el módulo de contexto es 10, llamamos al modelo completo (frontend + contexto) Dilación10.
La red Dilation10 se entrena en tres etapas. En primer lugar, el módulo de predicción de front-end se entrenó para 40.000 iteraciones. En segundo lugar, el módulo de contexto se entrena en la imagen completa (sin recortar) para iteraciones de 24K con una tasa de aprendizaje de 10-4, un impulso de 0,99 y un tamaño de lote de 100. En tercer lugar, el modelo completo (frontend + contexto) se entrenó conjuntamente para 60.000 iteraciones en la mitad de las imágenes (tamaño de entrada 1396 × 1396, incluido el relleno), con una tasa de aprendizaje de 10 −5, un impulso de 0,99 y un tamaño de lote de 1 .
La Figura 5 visualiza el impacto de la fase de capacitación en el rendimiento del modelo. Las tablas 7 y 8 presentan los resultados cuantitativos.
Cordts y otros (2016) compararon el rendimiento de Dilation10 con trabajos anteriores sobre el conjunto de datos Cityscapes. En su evaluación, Dilation10 superó a todos los modelos anteriores (Cordts et al, 2016). La dilatación10 también se utilizó como clasificador unario en el trabajo reciente de Kundu et al. (2016), que utiliza predicciones estructuradas para mejorar aún más la precisión.